




 本文介绍了如何利用R语言的parallel包中的mclapply函数实现并行计算,以提高处理大规模数据的效率。通过设置并发任务数,结合互斥锁同步机制,确保多线程安全地访问共享内存,实现任务的并发执行。示例中展示了如何在单个R进程中创建多个子线程,以并发处理多个单细胞RNA测序数据集的降维运算,充分利用多核CPU资源,达到计算资源的饱和利用。
本文介绍了如何利用R语言的parallel包中的mclapply函数实现并行计算,以提高处理大规模数据的效率。通过设置并发任务数,结合互斥锁同步机制,确保多线程安全地访问共享内存,实现任务的并发执行。示例中展示了如何在单个R进程中创建多个子线程,以并发处理多个单细胞RNA测序数据集的降维运算,充分利用多核CPU资源,达到计算资源的饱和利用。
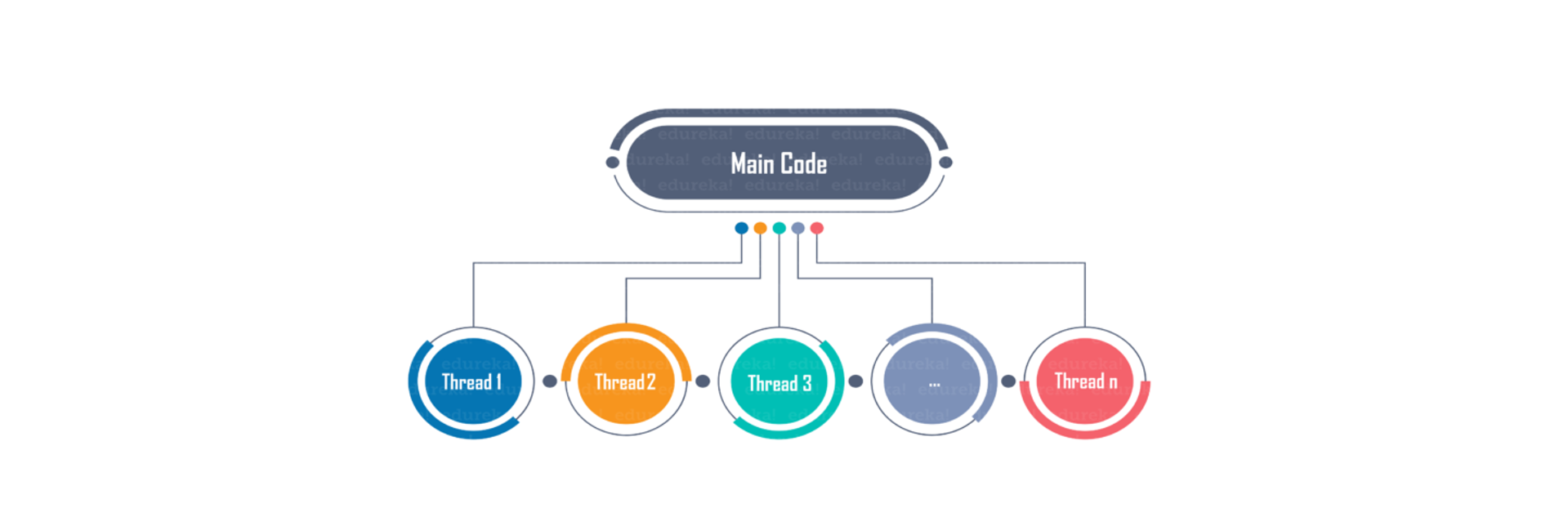
R语言运行在CPU单核单线程上,提高计算效率可以通过并行包:parallel实现,该包属于base包,不需要额外安装。
parallel::mclapply 函数是 lapply 的并发版本,可以自定义进程数发挥多CPU核心的优势。“mc”代表“多核”,此函数将 lapply 任务分配到多个 CPU 内核创建多线程的形式并发执行。
线程作为进程的一个执行流,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位,线程的优势是提高应用程序响应;使多CPU系统更加有效。操作系统会保证当线程数不大于CPU数目时,不同的线程运行于不同的CPU上。
###step.1创建任务环境各种变量
{
library(Seurat);library(dplyr);set.seed(123)
infiles <- dir(path = ".",pattern = "*_raw.rds", full.names = TRUE,recursive = T)
scRNAlist <- lapply(infiles, readRDS) #创建数据集list,用于并行运算,本次测试的scRNAlist包含5个数据对象
rank_i <- bigmemory::big.matrix(1,1,init = 0) #创建共享内存变量,该变量可被所有线程修改,本测试用此变量统计任务完成顺序
m <- synchronicity::boost.mutex() #创建互斥锁,防止共享内存变量被多个线程同时修改引发异常
}
###step.2并行运算任务基于parallel::mclapply函数,通过mc.cores = 3设置同时并发的任务数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 2368
2368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











