




 RDD缓存可以提高数据处理效率,当数据被多次使用或计算复杂时适用。cache和persist是缓存方法,后者支持更多缓存级别,如内存、磁盘。缓存不会立即执行,而是在action操作时触发。清除缓存可通过unpersist或程序结束。
RDD缓存可以提高数据处理效率,当数据被多次使用或计算复杂时适用。cache和persist是缓存方法,后者支持更多缓存级别,如内存、磁盘。缓存不会立即执行,而是在action操作时触发。清除缓存可通过unpersist或程序结束。
1. RDD缓存机制是什么?
把RDD的数据缓存起来,其他job可以从缓存中获取RDD数据而无需重复加工。
2. 如何对RDD进行缓存?
有两种方式,分别调用RDD的两个方法:persist 或 cache。
注意:调用这两个方法后并不会立刻缓存,而是有action算子触发时才会缓存。
3. persist 和 cache有什么区别?
二者的区别在于缓存级别上:
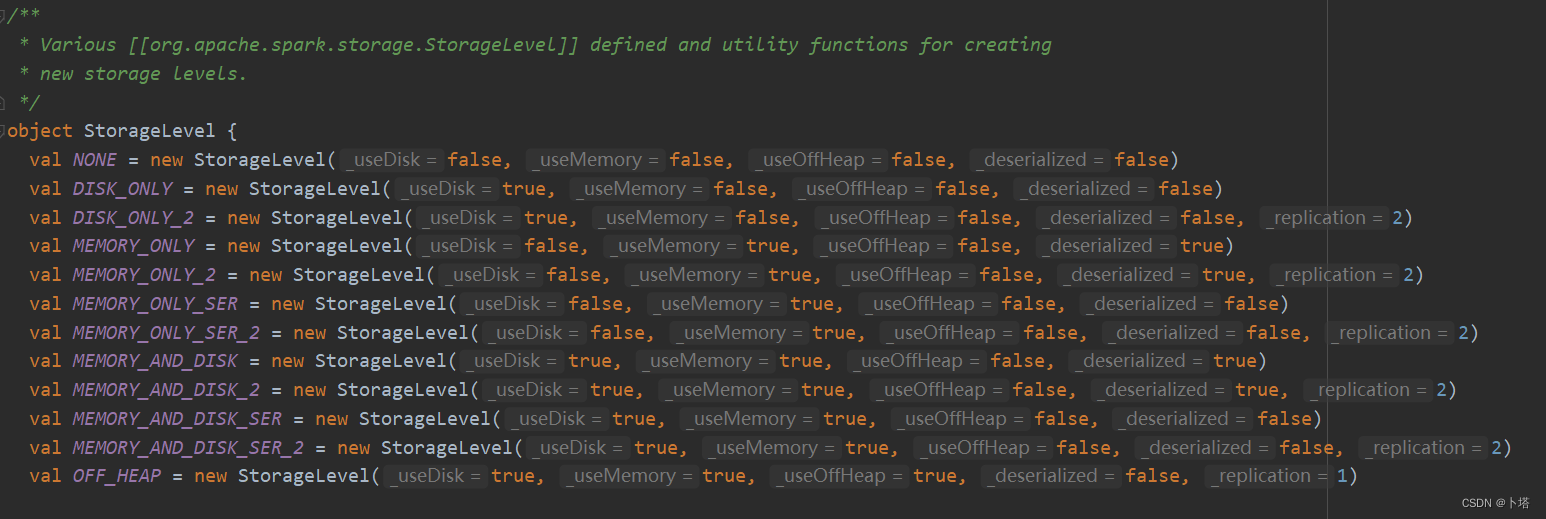
persist有多种缓存方式,如缓存到内存,缓存到磁盘等。
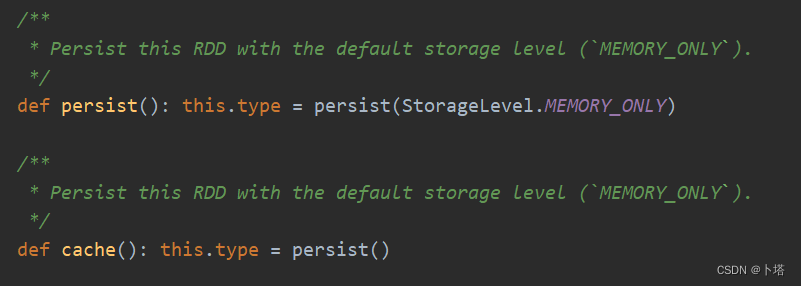
cache只缓存到内存,且实际是调用了persist方法。
两种方法的源码及缓存RDD的缓存级别如下:
4. 何时需要缓存RDD?
有两种情况:
- RDD被后续多个job用到;
- RDD的计算过程复杂。
5. 如何清除RDD缓存?
有两种方式:
- 应用程序结束后,缓存自动清除;
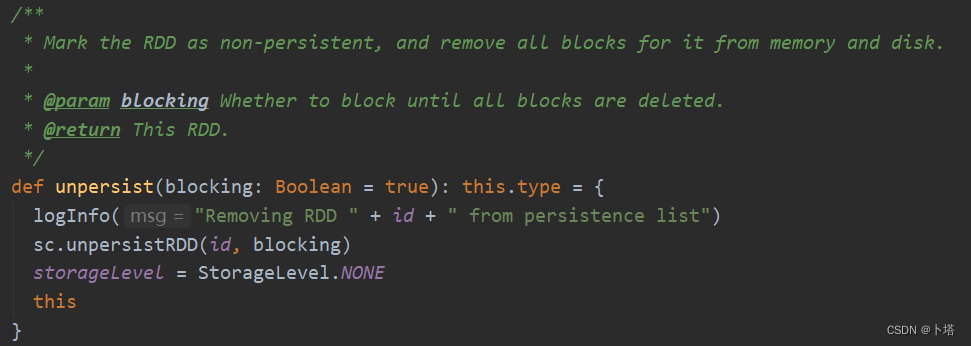
- 调用unpersist方法,源码如下:
–The End–

















 1404
1404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









