




 本文深入探讨了MoE(混合专家系统)和Transformer两种神经网络架构。MoE允许根据数据特性训练多个专家模型,通过门控机制结合输出。Transformer则利用自注意力机制和前馈网络进行信息处理,常用于序列到序列任务。文中还介绍了Evolved Transformer,它是通过神经架构搜索优化的Transformer变体,展现出更高的效率和性能。
本文深入探讨了MoE(混合专家系统)和Transformer两种神经网络架构。MoE允许根据数据特性训练多个专家模型,通过门控机制结合输出。Transformer则利用自注意力机制和前馈网络进行信息处理,常用于序列到序列任务。文中还介绍了Evolved Transformer,它是通过神经架构搜索优化的Transformer变体,展现出更高的效率和性能。
2021SC@SDUSC
lingvo.core.layers_with_attention
class MoEFeedforwardLayer(base_layer.BaseLayer)
MoE Mixture of Experts
混合专家系统(MoE)是一种神经网络,也属于一种combine的模型。适用于数据集中的数据产生方式不同。不同于一般的神经网络的是它根据数据进行分离训练多个模型,各个模型被称为专家,而门控模块用于选择使用哪个专家,模型的实际输出为各个模型的输出与门控模型的权重组合。各个专家模型可采用不同的函数(各种线性或非线性函数)。混合专家系统就是将多个模型整合到一个单独的任务中。
混合专家系统有两种架构:competitive MoE 和cooperative MoE。competitive MoE中数据的局部区域被强制集中在数据的各离散空间,而cooperative MoE没有进行强制限制。
对于较小的数据集,该模型的表现可能不太好,但随着数据集规模的增大,该模型的表现会有明显的提高。
源码:
def __init__(self, params):
super().__init__(params)
p = self.params
moe_builder = p.moe_builder_p.Instantiate()
moe_layer_p = moe_builder.EncoderLayer(
p.name,
moe_builder.MoE(p.name),
residual_weight=p.fflayer_residual_weight)
self.CreateChild('moe_fflayer', moe_layer_p)
class TransformerLayer(base_layer.BaseLayer)
应用自注意力机制,之后进行前馈网络和层规范化。使用每个连续层之间的残差连接。特别是,在层输入和 attention 输出,从 attention 输出(前馈神经网络输入)到前馈神经网络输出的过程中增加残差。
源码:
def __init__(self, params):
super().__init__(params)
p = self.params
assert p.name
assert p.source_dim
if p.is_decoder:
tf.logging.warning('TransformerLayer.is_decoder is deprecated.')
p.has_aux_atten = True
p.mask_self_atten = True
初始化多头自注意
params = p.tr_atten_tpl.Copy()
params.name = 'multihead_self_atten'
params.source_dim = p.source_dim
params.packed_input = p.packed_input
params.is_masked = p.mask_self_atten
self.CreateChild('self_atten', params)
if p.has_aux_atten:
初始化 masker 多头注意力机制
params = (
p.tr_atten_tpl.Copy()
if p.tr_aux_atten_tpl is None else p.tr_aux_atten_tpl.Copy())
params.name = 'multihead_atten'
params.source_dim = p.source_dim
params.packed_input = p.packed_input
if hasattr(params.atten_tpl, 'num_post_proj'):
params.atten_tpl.num_post_proj = p.num_aux_atten_post_proj
self.CreateChild('atten', params)
初始化前馈层
params = p.tr_fflayer_tpl.Copy()
params.name = 'tr_fflayer'
params.input_dim = p.source_dim
params.output_dim = p.output_dim
self.CreateChild('fflayer', params)
类方法
def FProp(self, theta, source_vecs, source_paddings, aux_vecs=None, aux_paddings=None, source_segment_id=None, aux_segment_id=None, **kwargs)
’ source_vecs ‘和’ source_padding ‘都被假设来自下一层的激活。当在 encoder 中使用TransformerLayer时(该层的默认行为)’ source_* ‘张量对应于前一个编码器层的输出。此外,键、值和查询都是从’ source_vecs '派生的。当 TransformerLayer 在 decoder 中使用时(has_aux_atten=True), ’ source_* ’ 张量对应于前一个解码器层的输出,并用作查询。
在解码器中使用’ TransformerLayer ‘时,(has_aux_atten=True), 必须提供’ aux_* ‘张量辅助输入, 然后对应于最顶层的encoder输出,并被第二个’ TransformerAttentionLayer '用作键和值。
不管encoder还是decoder,查询总是假设来自下面的层的激活函数,特别是’ source_vecs '。
参数列表 :
- theta:
.NestedMap对象,该对象包含此层及其子层的权重值。 - source_vecs: [source_time, source_batch, dim].
- source_paddings: [source_time, source_batch]
- aux_vecs: [aux_time, aux_batch, dim]
- aux_paddings: [aux_time, aux_batch]
- source_segment_id: [source_time, source_batch]
- aux_segment_id: [aux_time, aux_batch]
- **kwargs: 可以是attention层的可选参数,例如。attention投射指数的张量。
源码
def FProp(self,
theta,
source_vecs,
source_paddings,
aux_vecs=None,
aux_paddings=None,
source_segment_id=None,
aux_segment_id=None,
**kwargs):
p = self.params
if p.packed_input:
assert source_segment_id is not None, ('Need to specify segment id for '
'packed input.')
with tf.name_scope('self_atten'):
atten_vec, atten_prob = self.self_atten.FProp(
theta.self_atten,
source_vecs,
source_paddings,
query_segment_id=source_segment_id)
if p.has_aux_atten:
assert aux_vecs is not None
assert aux_paddings is not None
with tf.name_scope('aux_atten'):
atten_vec, atten_prob = self.atten.FProp(theta.atten, atten_vec,
aux_paddings, aux_vecs,
source_segment_id,
aux_segment_id, **kwargs)
with tf.name_scope('fflayer'):
h = self.fflayer.FProp(theta.fflayer, atten_vec, source_paddings)
if p.tr_post_ln_tpl:
with tf.name_scope('layer_norm'):
h = self.layer_norm.FProp(theta.layer_norm, h)
return h, atten_prob
类
class EvolvedTransformerEncoderBranchedConvsLayer(base_layer.BaseLayer)
ET
使用神经架构搜索的方法,为 seq2seq 任务找到了一种比Transformer更好的前馈网络架构。架构搜索是基于Transformer进行演进,最终得到的Evolved Transformer 的新架构在四个成熟的语言任务(WMT 2014 英德、WMT 2014 英法、WMT 2014 英捷及十亿词语言模型基准(LM1B))上的表现均优于原版 Transformer。在用大型模型进行的实验中,Evolved Transformer 的效率(FLOPS)是 Transformer 的两倍,而且质量没有损失。在更适合移动设备的小型模型(参数量为 7M)中,Evolved Transformer 的 BLEU 值高出 Transformer 0.7。
ET的搜索空间
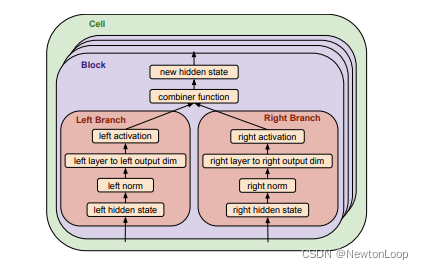
一个模型包含encoder和decoder,各包含若干个单元,编码器的单元包含6个模块,解码器的单元包含8个模块。每个模块分左右两个分支,各自接受一个隐藏状态作为输入。按照层次从低到高分支搜索项分为:input、normalization、layer、output dimension和activation。左右分支通过combiner function合并为新的隐藏状态作为输出。
参考论文 : The Evolved Transformer
源码
def __init__(self, params):
super().__init__(params)
p = self.params
assert p.name
assert p.input_dim
初始化第一层准则函数
params = p.ln_tpl.Copy()
params.name = 'first_layer_norm'
params.input_dim = p.input_dim
self.CreateChild('first_layer_norm', params)
初始化第二层准则函数
params = p.ln_tpl.Copy()
params.name = 'second_layer_norm'
params.input_dim = p.input_dim * 4
self.CreateChild('second_layer_norm', params)
初始化密度层
params = p.dense_tpl.Copy()
params.name = 'dense_layer'
params.input_dim = p.input_dim
params.activation = p.activation
params.output_dim = p.input_dim * 4
self.CreateChild('dense_layer', params)
初始化标准conv
params = p.conv_tpl.Copy()
params.name = 'conv_layer'
params.bias = True
params.batch_norm = False
params.activation = p.activation
params.filter_stride = (1, 1)
params.filter_shape = (3, 1, p.input_dim, int(p.input_dim / 2))
self.CreateChild('conv_layer', params)
初始化分离相关系数
params = p.separable_conv_tpl.Copy()
params.name = 'separable_conv_layer'
params.bias = True
params.batch_norm = False
params.activation = 'NONE'
params.filter_stride = (1, 1)
params.filter_shape = (9, 1, int(p.input_dim * 4), p.input_dim)
self.CreateChild('separable_conv_layer', params)
初始化dropout
dropout_tpl = p.dropout_tpl.Copy()
self.CreateChild('dropout', dropout_tpl)


















 1425
1425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









