



1 目标
尝试在openEuler riscv上使用llama.cpp进行大模型推理
2 环境说明
- 系统:openEuler 2403 riscv
- cpu:SG2042
- python:3.11
3 操作步骤
3.1 模型下载
创建并激活虚拟环境
$ python3 -m venv --site-system-packages venv
$ source venv/bin/activate
创建模型保存目录
$ mkdir models
方法一:从HuggingFace上下载模型
安装transformers库,默认会同时安装huggingface-hub
$ pip install transformers
下载模型
$ huggingface-cli download --resume-download meta-llama/Meta-Llama-3-8B-Instruct --local-dir ./models/Meta-Llama-3-8B-Instruct
可能会由于网络问题造成下载失败
方法二:从魔搭ModelScope上下载模型
$ pip install modelscope
$ modelscope download --model LLM-Research/Meta-Llama-3-8B-Instruct --local_dir ./models/Meta-Llama-3-8B-Instruct
下载成功且速度较快
3.2 llama.cpp使用
安装llama.cpp(C/C++环境)
$ git clone https://github.com/ggerganov/llama.cpp
$ cd llama.cpp
CPU Build:
使用CMake构建llama.cpp:
$ cmake -B build
$ cmake --build build --config Release
安装模型转换所需依赖
$ pip install -r requirements.txt
出现依赖问题

源码编译pytorch 2.2.1,参考pytorch riscv源码编译文档,再次尝试安装依赖发现仍出现该问题,在llama.cpp/requirements/requirements-convert_hf_to_gguf.txt和llama.cpp/requirements/requirements-convert_hf_to_gguf_update.txt两个文件中注释掉以下内容
torch~=2.2.1
再次尝试安装依赖即可安装成功

转换HF模型为GGUF格式(FP16)
$ python convert_hf_to_gguf.py ../models/Meta-Llama-3-8B-Instruct
在SG2042上转换过程用时约为15分钟,转换成功后会在模型路径下生成一个.gguf文件
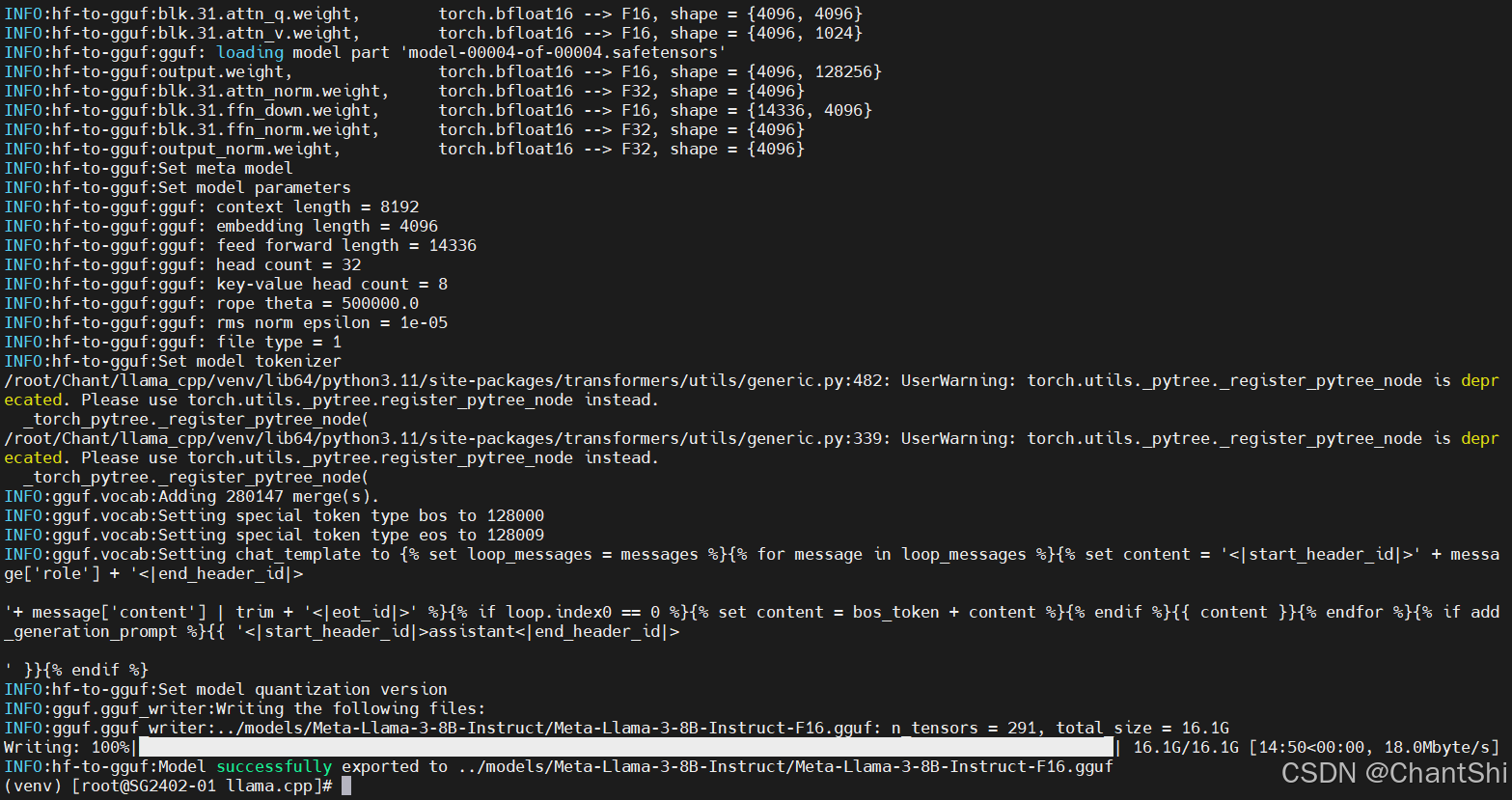
转换后的文件大小约为16G
GGUF模型量化
# 量化命令格式
$ llama-quantize your_model.gguf res_model.gguf quantize_type
# 示例: Q4_K_M 量化
$ ./build/bin/llama-quantize ../models/Meta-Llama-3-8B-Instruct/Meta-Llama-3-8B-Instruct-F16.gguf ../models/Meta-Llama-3-8B-Instruct/Meta-Llama-3-8B-Instruct-F16_q4km.gguf Q4_K_M
量化完成
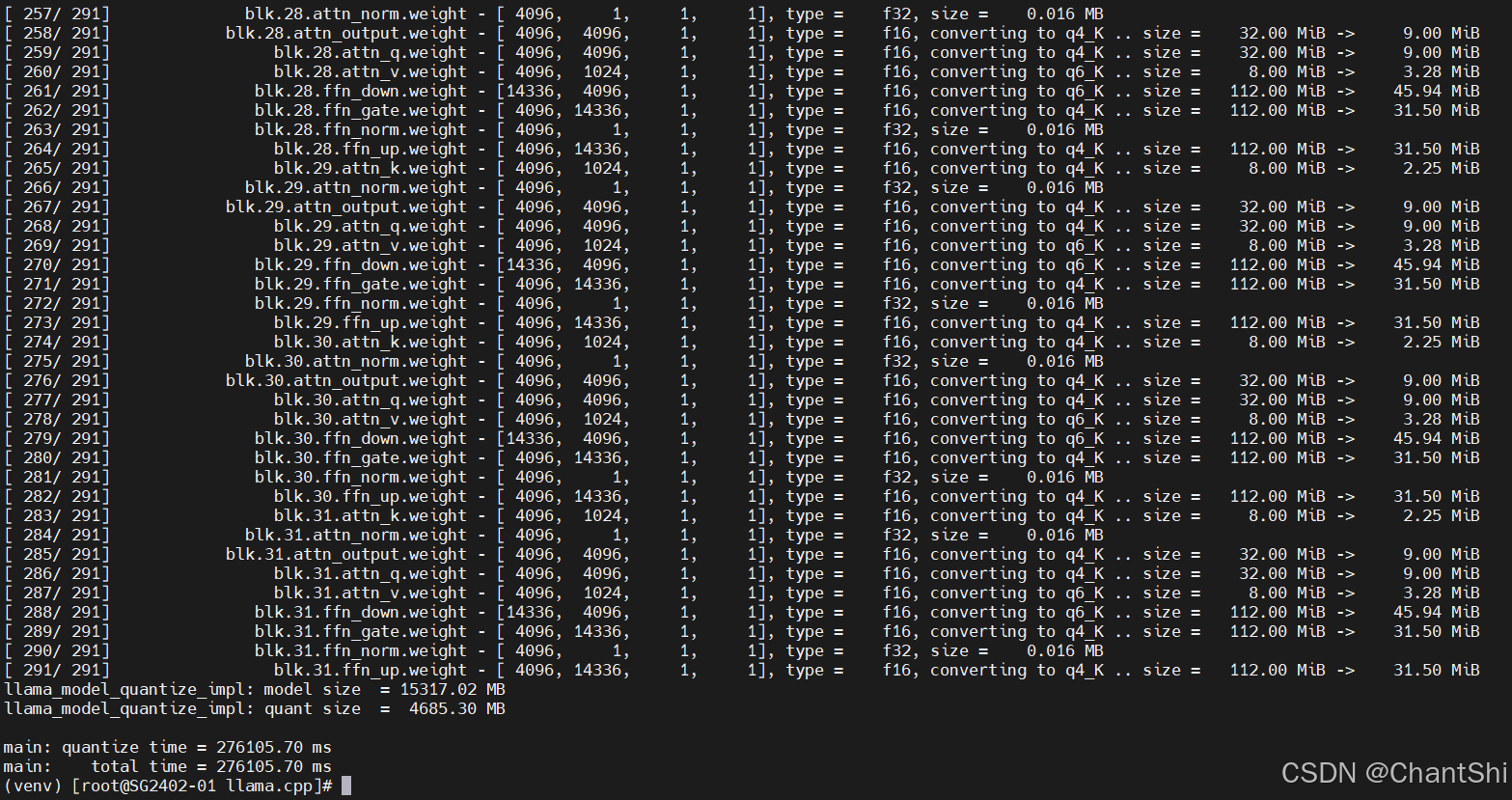
量化后模型大小约为4.6G
模型部署,在CPU上运行llm模型推理
# CPU
$ ./build/bin/llama-cli -m ../models/Meta-Llama-3-8B-Instruct/Meta-Llama-3-8B-Instruct-F16_q4km.gguf -cnv -p "You are a helpful assistant"
参数说明:
- -m:模型路径
- -cnv:交互模式,将保留上下文,可以连续对话
- -p:启动生成的提示信息
运行结果
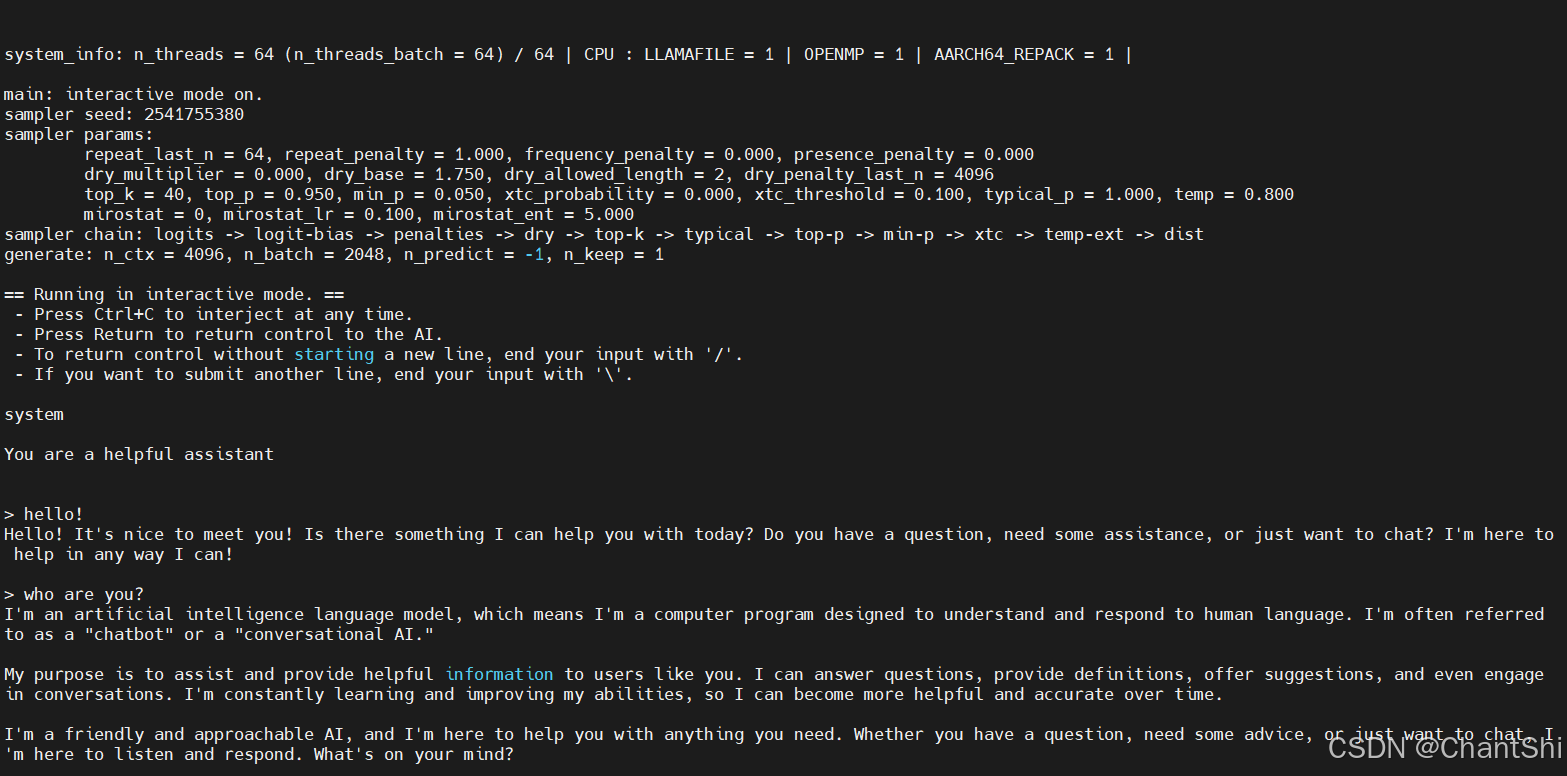
使用中文提示

4 总结
在openEuler riscv上可以成功使用llama.cpp进行LLM模型转换、量化和推理。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









