




前言
在构建 RAG(Retrieval-Augmented Generation)知识库时,n8n 作为强大的工作流自动化工具,结合 Qdrant 向量数据库,可以提供一个高效的解决方案。然而,在实际使用过程中,我们可能会遇到数据格式兼容性和文本分割的问题,特别是当我们使用自定义创建的 Qdrant Collections 时。
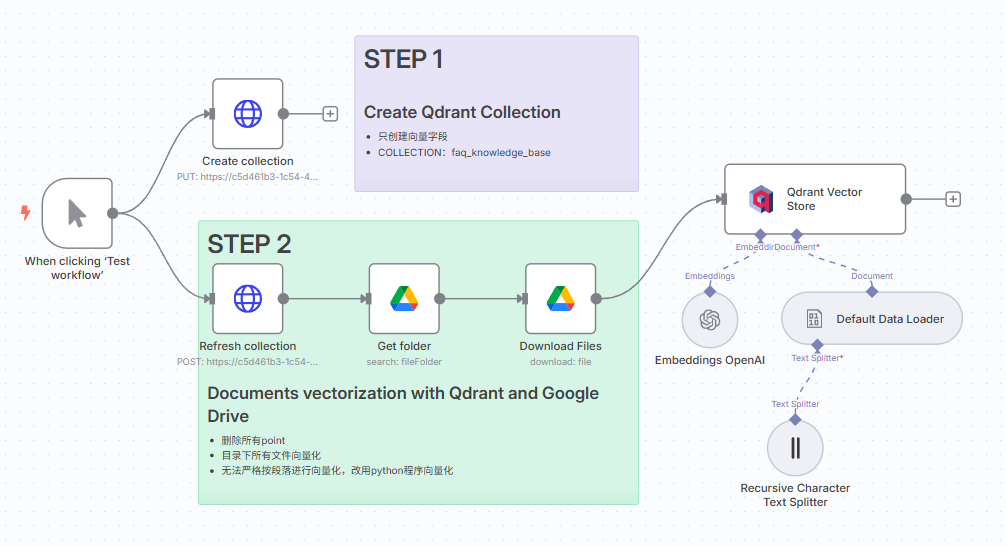
问题发现
在使用 n8n 的 Qdrant 集成时,我发现了两个关键问题:
- 自己创建的 Qdrant Collections 无法与 n8n 的 Qdrant 节点正常协作
- n8n Recursive Character Text Splitter 不支持完全按段落分割进行向量化
经过深入分析,发现问题的根源在于数据格式的不匹配和文本分割策略的局限性。
核心问题分析
问题一:数据格式兼容性
n8n 中的 Qdrant 集成对数据格式有特定的要求。它期望的 payload 结构遵循以下格式:
{
"content": "文档内容",
"metadata": {
"source": "blob",
"blobType": "text/plain",
"loc": {
"lines": {
"from": 起始行号,
"to": 结束行号
}
}
}
}问题二:文本分割限制
n8n 的 Recursive Cha
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 923
923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











