




 随着大数据业务发展,Hive数仓体系难以满足需求。网易数帆基于Apache Iceberg研发了流式湖仓Arctic,它提供多种功能,实现流批一体。Arctic对Hive有高度兼容性,支持数据、元数据等层面兼容,还能实现数据同步、存量表升级等,通过网易云音乐案例展现了其实践优势。
随着大数据业务发展,Hive数仓体系难以满足需求。网易数帆基于Apache Iceberg研发了流式湖仓Arctic,它提供多种功能,实现流批一体。Arctic对Hive有高度兼容性,支持数据、元数据等层面兼容,还能实现数据同步、存量表升级等,通过网易云音乐案例展现了其实践优势。

背景
随着大数据业务的发展,基于 Hive 的数仓体系逐渐难以满足日益增长的业务需求,一方面已有很大体量的用户,但是在实时性,功能性上严重缺失;另一方面 Hudi,Iceberg 这类系统在事务性,快照管理上带来巨大提升,但是对已经存在的 Hive 用户有较大的迁移成本,并且难以满足流式计算毫秒级延迟的需求。为了满足网易内外部客户对于流批一体业务的需求,网易数帆基于 Apache Iceberg 研发了新一代流式湖仓,相较于 Hudi,Iceberg 等传统湖仓,它提供了流式更新,维表 Join,partial upsert 等功能,并且将 Hive,Iceberg,消息队列整合为一套流式湖仓服务,实现了开箱即用的流批一体,能帮助业务平滑地从 Hive 过渡到 Streaming Lakehouse。
什么是 Arctic
Arctic 是搭建在 Apache Iceberg 之上的流式湖仓服务 ( Streaming LakeHouse Service )。相比 Iceberg、Hudi、Delta 等数据湖,Arctic 提供了更加优化的 CDC,流式更新,OLAP 等功能,并且结合了 Iceberg 高效的离线处理能力,Arctic 能服务于更多的流批混用场景。Arctic 还提供了包括结构自优化、并发冲突解决、标准化的湖仓管理功能等,可以有效减少数据湖在管理和优化上负担。
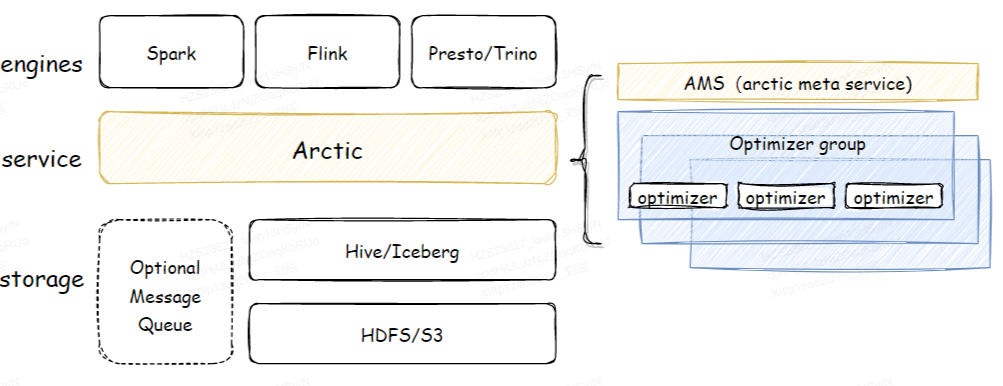
Arctic Table 依赖 Iceberg 作为基础表格式,但是 Arctic 没有倾入 Iceberg 的实现,而是将 Iceberg 做为 lib 使用,同时 Arctic 作为专门为流批一体计算设计的流式湖仓,Arctic Table 还封装了消息队列作为表的一部分,在流式计算场景下可以提供更低的消息延迟,并且提供了流式更新,主键唯一性保证等功能。
流体一批的解决方案
在实时计算中,由于低延迟的要求,业务通常采用 Kafka 这类消息队列作为流表方案,但是在离线计算中,通常采用 Hive 作为离线表,并且由于消息队列不支持 AP 查询,通常还需要额外的 OLAP 系统如 Kudu 以支持实时计算链接的最终数据输出。这就是典型的 Lambda 架构:

这套架构最明显的问题就是多套系统带来的运维成本和重复开发带来的低效率,其次就是两套系统同时建模带来的语义二义性问题,并且真实生产场景中,还会出现实时和离线视图合并的需求,或者引入 KV 的实时维表关联的需求。
Arctic 的核心目标之一,就是为业务提供基于数据湖的去 Lambda 化,业务系统使用 Arctic 替代 Kafka 和Hive,实现存储底座的流批一体。

为此 Arctic 提供了以下功能:
Messa
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1031
1031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











