







首先我们来认识一下什么是哈希表??
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
哈希表hashtable(key,value) 就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。(或者:把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数)。 而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位。
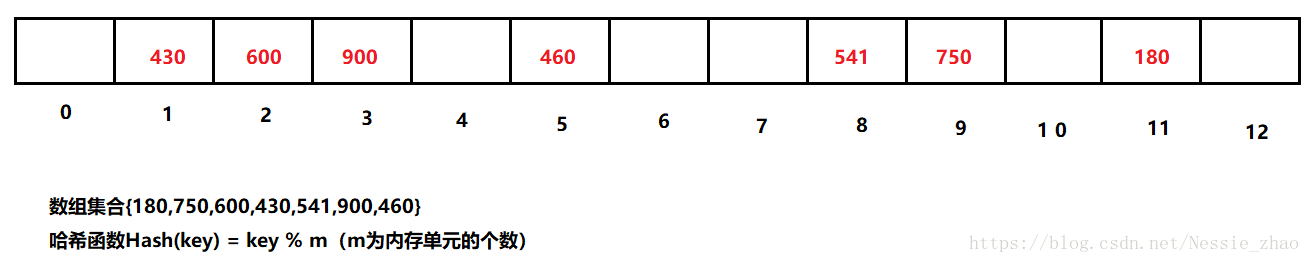
用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度较快
- 但是哈希表在建立时会发生冲突,对于一些无法避免的冲突有以下几种处理办法:
1.开放定址法
H(key) = (H(key) + d)MOD m(其中m为哈希表的表长,d为一个增量)
当得出的哈希地址产生冲突时,选取以下3种方法中的一种获取d的值,然后继续计算,直到计算出的哈希地址不再冲突为止
(1)线性探测法:d = 1,2,3,….m-1
当遇到冲突时,从发生冲突位置起,每次+1,向右探测,直到有空闲的位置为止
(2)二次探测法:d = 12,-12,22,-22……………….
当遇到冲突时,从发生冲突的位置起,按照+12,-12,+22,…如此探测,直到有空闲的位置
(3)伪随机数探测法:d =伪随机数
当遇到冲突时,从发生冲突的位置起,每次加上一个随机数,直到探测到空闲的位置结束
2.再哈希法
当通过哈希函数求得的哈希地址同其他关键字产生冲突时,使用另一个哈希函数计算,直到冲突不再发生
3.链地址法
将所有产生冲突的关键字所对应的数据全部存储在同一个线性链表中
4.建立一个公共溢出区
建立两张表,一张为基本表,另一张为溢出表。基本表存储没有发生冲突的数据,当关键字由哈希函数生成的哈希地址产生冲突时,就将数据填入溢出表 - 开散列法又叫链地址法
开散列法:首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头节点存储在哈希表中
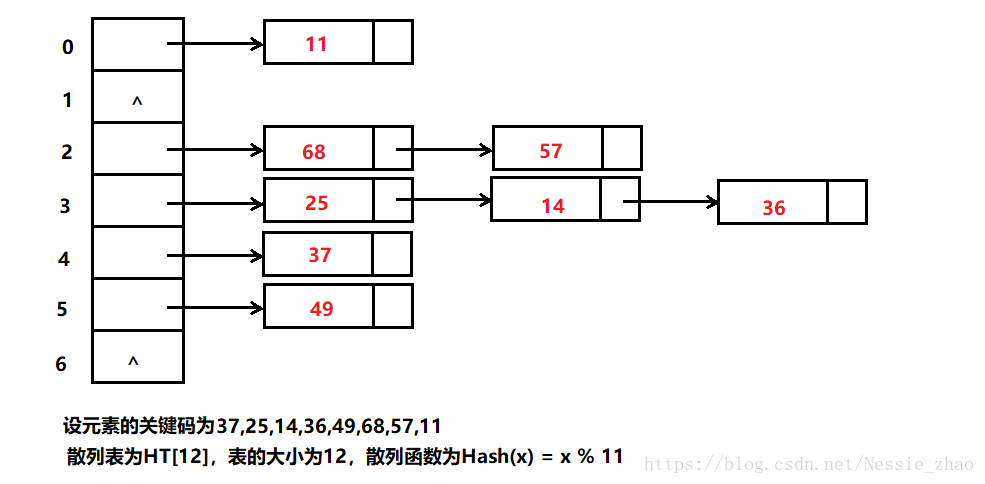
下面是两种方法实现哈希表:
1.线性探测法实现
.h文件
#pragma once
#include<stdio.h>
#include<stddef.h>
//我们此处存放的hash表期望存储的数据是键值对这样的结构
#define HashMaxSize 1000
typedef enum
{
Empty,//空状态
Deleted,//被删除的状态
Valid,//有效状态
}Stat;
typedef int KeyType;
typedef int ValType;
typedef size_t (*HashFunc)(KeyType key);
//这个结构体表示hash表中的一个元素
//这个元素中同时包含了键值对
typedef struct HashElem
{
KeyType key;
ValType value;
Stat stat;
}HashElem;
//[0,size)这个区间就不能表示hash表中有效元素
typedef struct HashTable
{
HashElem data[HashMaxSize];
size_t size;
HashFunc func;//这是一个函数指针
}HashTable;
(1)初始化哈希表
size_t HashFuncDefault(KeyType key)
{
return key % HashMaxSize;
}
void HashInit(HashTable* ht,HashFunc hash_func)
{
ht->size = 0;
ht->func = hash_func;
size_t i = 0;
for(;i < HashMaxSize;++i)
{
ht->data[i].stat = Empty;
}
return;
}
void TestInit()
{
TEST_HEADER;
HashTable ht;
HashInit(&ht,HashFuncDefault);
printf("size expected 0,actual %lu\n",ht.size);
printf("func expected %p,actual %p\n",HashFuncDefault,ht.func);
}(2)销毁哈希表
void HashDestroy(HashTable* ht)
{
ht->size = 0;
ht->func = NULL;
size_t i = 0;
for(;i < HashMaxSize;++i)
{
ht->data[i].stat = Empty;
}
return;
}
void TestDestroy()
{
TEST_HEADER;
HashTable ht;
HashInit(&ht,HashFuncDefault);
HashDestroy(&ht);
printf("size expected 0,actual %lu\n",ht.size);
printf("func expected NULL,actual %p\n",ht.func);
}(3)向哈希表中插入一个元素
void HashInsert(HashTable* ht,KeyType key,ValType value)
{
if(ht == NULL)
{
//非法输入
return;
}
//判定hash表是否能够继续插入元素(根据负载因子)
//假设此处我们把负载因子定义成0.8
if(ht->size >= 0.8 * HashMaxSize)
{
//发现当前的hash表已经达到负载因子的上限,插入失败
return;
}
//根据key来计算offset
size_t offset = ht->func(key);
//从offset位置开始线性的向后查找,找到第一个状态为Empty的位置进行插入
while(1)
{
if(ht->data[offset].stat != Valid)//找到一个合适的位置
{
ht->data[offset].key = key;
ht->data[offset].value = value;
ht->data[offset].stat = Valid;
++ht->size;
return;
}
//遇到key值相同的插入失败
else if(ht->data[offset].stat == Valid && ht->data[offset].key == key)
{
return;
}
else
{
++offset;
if(offset >= HashMaxSize)
{
offset = 0;
}
}
}
return;
}
void HashPrint(HashTable* ht,const char* msg)
{
printf("[%s]\n",msg);
size_t i = 0;
for(;i < HashMaxSize;++i)
{
if(ht->data[i].stat == Empty)
{
continue;
}
printf("[%lu %d : %d]\n",i,ht->data[i].key,ht->data[i].value);
}
return;
}
void TestInsert()
{
TEST_HEADER;
HashTable ht;
HashInit(&ht,HashFuncDefault);
HashInsert(&ht,1,1);
HashInsert(&ht,1,10);
HashInsert(&ht,2,2);
HashInsert(&ht,1001,11);
HashInsert(&ht,1002,12);
HashPrint(&ht,"插入若干个元素");
}(4)根据key值查找一个元素是否在哈希表中,如果存在返回value值
int HashFind(HashTable* ht,KeyType key,ValType* value)
{
if(ht == NULL)
{
//非法输入
return 0;
}
if(ht->size == 0)
{
//空的hash表
return 0;
}
//根据key算出offset
size_t offset = ht->func(key);
//从offset开始往后进行查找,每次取到一个元素,和key进行比较
while(1)
{
//如果找到key相同的元素,查找成功,并把value返回
if(ht->data[offset].key == key && ht->data[offset].stat == Valid)
{
*value = ht->data[offset].value;
return 1;
}
//如果是一个空位置,则查找失败
else if(ht->data[offset].stat == Empty)
{
return 0;
}
//如果此时key不相等,就继续向后查找
else
{
++offset;
offset = offset > HashMaxSize ? 0 : offset;
}
}
return 0;
}
void TestFind()
{
TEST_HEADER;
HashTable ht;
HashInit(&ht,HashFuncDefault);
HashInsert(&ht,1,1);
HashInsert(&ht,1,10);
HashInsert(&ht,2,2);
HashInsert(&ht,1001,11);
HashInsert(&ht,1002,12);
ValType value;
int ret = HashFind(&ht,1002,&value);
printf("ret expected 1,actual %d\n",ret);
printf("value expected 12,actual %d\n",value);
}(5)根据key值删除哈希表中的某个元素
void HashRemove(HashTable* ht,KeyType key)
{
if(ht == NULL)
{
//非法输入
return;
}
if(ht->size == 0)
{
//空的hash表
return;
}
//根据key计算offset
size_t offset = ht->func(key);
//从offset开始判定当前元素的key和要删除的key是否相等
while(1)
{
if(ht->data[offset].key == key && ht->data[offset].stat == Valid)
{
//如果相等的话就把它标记为Deleted
ht->data[offset].stat = Deleted;
--ht->size;
return;
}
else if(ht->data[offset].stat == Empty)
{
//如果当前的状态为空,那就在hash表中没找到,删除失败
return;
}
else
{
//线性探测查找下一个元素
++offset;
offset = offset > HashMaxSize ? 0 : offset;
}
}
return;
}
void TestRemove()
{
TEST_HEADER;
HashTable ht;
HashInit(&ht,HashFuncDefault);
HashInsert(&ht,1,1);
HashInsert(&ht,1,10);
HashInsert(&ht,2,2);
HashInsert(&ht,1001,11);
HashInsert(&ht,1002,12);
ValType value;
int ret = HashFind(&ht,1002,&value);
printf("ret expected 1,actual %d\n",ret);
printf("value expected 12,actual %d\n",value);
HashRemove(&ht,1002);
ret = HashFind(&ht,1002,&value);
printf("ret expected 0,actual %d\n",ret);
}2.链地址法实现哈希表(哈希桶)
.h文件
#pragma once
#include<stdio.h>
#include<stddef.h>
#define HashMaxSize 1000
typedef int KeyType;
typedef int ValType;
typedef size_t (*HashFunc)(KeyType key);
//此结构体相当于是一个链表的节点
typedef struct HashElem
{
KeyType key;
ValType value;
struct HashElem* next;
}HashElem;
typedef struct HashTable
{
//如果我们的hash桶上的链表是一个不带头节点的链表(保存指针)
//类型就用HashElem*
//如果我们的hash桶上的链表是一个带头节点的链表(保存节点)
//类型就用HashElem
HashElem* data[HashMaxSize];
size_t size;
HashFunc func;
}HashTable;
创建和销毁节点
HashElem* CreateElem(KeyType key,ValType value)
{
HashElem* new_node = (HashElem*)malloc(sizeof(HashElem));
new_node->key = key;
new_node->value = value;
new_node->next = NULL;
return new_node;
}
void DestroyElem(HashElem* node)
{
free(node);
return;
}(1)初始化哈希表
size_t HashFuncDefault(KeyType key)
{
return key % HashMaxSize;
}
void HashInit(HashTable* ht,HashFunc hash_func)
{
if(ht == NULL)
{
return;
}
ht->size = 0;
ht->func = hash_func;
size_t i = 0;
for(;i < HashMaxSize ;++i)
{
ht->data[i] = NULL;
}
return;
}
void TestInit()
{
TEST_HEADER;
HashTable ht;
HashInit(&ht,HashFuncDefault);
printf("size expected 0,actual %lu\n",ht.size);
printf("func expected %p,actual %p\n",HashFuncDefault,ht.func);
}(2)销毁哈希表
void HashDestroy(HashTable* ht)
{
if(ht == NULL)
{
//非法输入
return;
}
ht->size = 0;
ht->func = NULL;
size_t i = 0;
//遍历所有的链表然后进行释放
for(;i < HashMaxSize;++i)
{
HashElem* cur = ht->data[i];
while(cur != NULL)
{
HashElem* next = cur->next;
DestroyElem(cur);
cur = next;
}
}
return;
}(3)向哈希表中插入一个元素
HashElem* HashBucketFind(HashElem* head,KeyType to_find)
{
HashElem* cur = head;
for(;cur != NULL;cur = cur->next)
{
if(cur->key == to_find)
{
break;
}
}
return cur == NULL ? NULL : cur;
}
void HashInsert(HashTable* ht,KeyType key,ValType value)
{
if(ht == NULL)
{
return;
}
//根据key算出offset
size_t offset = ht->func(key);
//在offset对应的链表中查找看当前的key是否存在
HashElem* ret = HashBucketFind(ht->data[offset],key);
if(ret != NULL)
{
//如果返回值不为空,就说明已经存在当前key
//如果存在就认为插入失败
return;
}
//如果不存在就采用头插的办法
HashElem* new_node = CreateElem(key,value);
new_node->next = ht->data[offset];
ht->data[offset] = new_node;
++ht->size;
return;
}
void HashPrint(HashTable* ht,const char* msg)
{
printf("[%s]\n",msg);
size_t i = 0;
for(;i < HashMaxSize ;++i)
{
if(ht->data[i] == NULL)
{
continue;
}
printf("i = %lu\n",i);
HashElem* cur = ht->data[i];
for(;cur != NULL;cur = cur->next)
{
printf("[%d : %d] ",cur->key,cur->value);
}
printf("\n");
}
return;
}
void TestInsert()
{
TEST_HEADER;
HashTable ht;
HashInit(&ht,HashFuncDefault);
HashInsert(&ht,1,1);
HashInsert(&ht,1,10);
HashInsert(&ht,2,2);
HashInsert(&ht,1001,11);
HashInsert(&ht,1002,12);
HashPrint(&ht,"插入若干个元素");
}(4)根据key值查找一个元素是否在哈希表中,如果存在返回value值
int HashFind(HashTable* ht,KeyType key,ValType* value)
{
if(ht == NULL || value == NULL)
{
return 0;
}
//根据key算出offset
size_t offset = ht->func(key);
HashElem* ret = HashBucketFind(ht->data[offset],key);
if(ret == NULL )
{
return 0;
}
*value = ret->value;
return 1;
}
void TestFind()
{
TEST_HEADER;
HashTable ht;
HashInit(&ht,HashFuncDefault);
HashInsert(&ht,1,1);
HashInsert(&ht,1,10);
HashInsert(&ht,2,2);
HashInsert(&ht,1001,11);
HashInsert(&ht,1002,12);
int ret = 0;
ValType value;
ret = HashFind(&ht,1002,&value);
printf("ret expected 1 ,actual %d\n",ret);
printf("value expected 12,actual %d\n",value);
}(5)根据key值删除哈希表中的某个元素
int HashBucketFindEx(HashElem* head,KeyType to_find,HashElem** pre_node,HashElem** cur_node)
{
HashElem* pre = NULL;
HashElem* cur = head;
for(;cur != NULL;pre = cur,cur = cur->next)
{
if(cur->key == to_find)
{
break;
}
}
if(cur == NULL)
{
return 0;
}
*pre_node = pre;
*cur_node = cur;
return 1;
}
void HashRemove(HashTable* ht,KeyType key)
{
if(ht == NULL)
{
return;
}
if(ht->size == 0)
{
return;
}
//根据key算出offset
size_t offset = ht->func(key);
//通过offset找到对应的链表
//在链表中找到指定的元素,并进行删除
HashElem* pre =NULL;
HashElem* cur = NULL;
int ret = HashBucketFindEx(ht->data[offset],key,&pre,&cur);
if(ret == 0)
{
//没找到,删除失败
return;
}
if(pre == NULL)
{
//要删除的元素是链表的头结点
ht->data[offset] = cur->next;
}
else
{
//要删除的点不是链表的头结点
pre->next = cur->next;
}
DestroyElem(cur);
--ht->size;
return;
}
void TestRemove()
{
TEST_HEADER;
HashTable ht;
HashInit(&ht,HashFuncDefault);
HashInsert(&ht,1,1);
HashInsert(&ht,1,10);
HashInsert(&ht,2,2);
HashInsert(&ht,1001,11);
HashInsert(&ht,1002,12);
int ret = 0;
ValType value;
ret = HashFind(&ht,1002,&value);
printf("ret expected 1 ,actual %d\n",ret);
printf("value expected 12,actual %d\n",value);
HashRemove(&ht,1002);
ret = HashFind(&ht,1002,&value);
printf("ret expected 0 ,actual %d\n",ret);
}
















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









