






 本文详细介绍了字符编码的发展历程,从ASCII到Unicode,再到UTF的各种变体。探讨了不同编码的存储需求和优缺点,例如ASCII的7位编码,Unicode的16位和32位形式,以及UTF-8的可变长度编码如何节省空间。还涉及到编码转换的实际操作,如GBK到UTF-8的转换,并展示了Python中进行编码和解码的方法。
本文详细介绍了字符编码的发展历程,从ASCII到Unicode,再到UTF的各种变体。探讨了不同编码的存储需求和优缺点,例如ASCII的7位编码,Unicode的16位和32位形式,以及UTF-8的可变长度编码如何节省空间。还涉及到编码转换的实际操作,如GBK到UTF-8的转换,并展示了Python中进行编码和解码的方法。
参考:
讲的很好啊ovo
02_08_bytes_01_字符集和编码_哔哩哔哩_bilibili
字符集合编码
0 1(高低电平) => 101010101 => 二级制转化为十进制
如何进行存储文字信息:类似与摩斯密码
ASCII
编排了128个文字符号与特殊操作符,只需要7个0和1就可以表示(2^7=128),预留了一个拓展位
01111111 ==> 1 byte =8bit
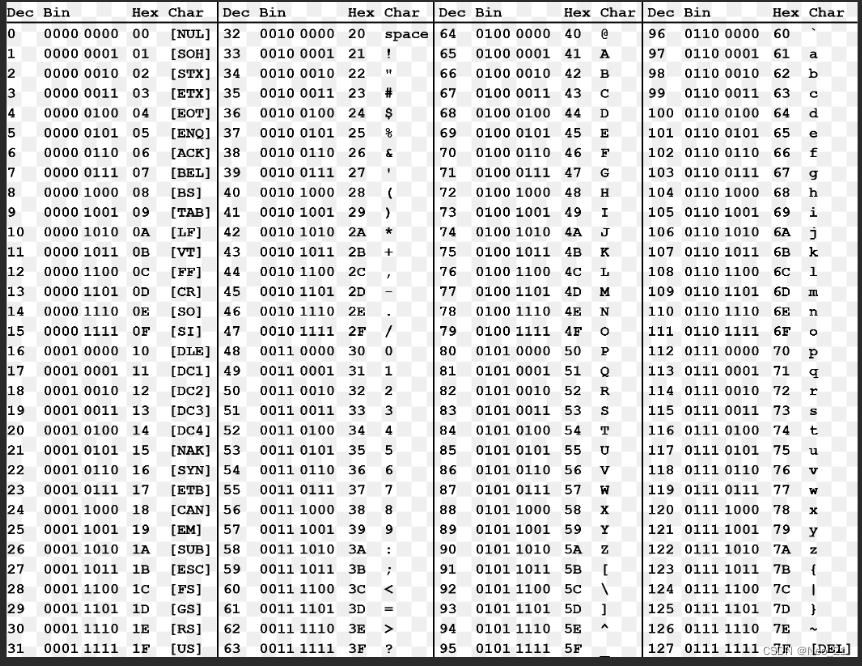
ANSI
ASCII肯定不够对于像中文这样的复杂语言。ANSI提供一套标准,每个字符16bit ,2byte
00000000 01111111 2^16=65536个字符
到了中国gb2313编码,gbk(国标扩充码)Windows默认编码,包含了ASCII。
到了台湾big5编码
Unicode
万国码,早期Unicode没有意识到有好多汉字信息,使用UCS-2 2个字节,固定了编码长度。
扩充使用,UCS-4 4给字节
00000000 00000000 00000000 01111111
缺点:存储和传输浪费空间,小文件要占很大的空间
utf
unicode的实践,可变长的编码,节约空间。
utf-8 :最短的字节长度8
英文:8bit 1个字节
欧洲文字:16bit 2个字节
中文: 24bit(位) 3个字节 理论上2^24=16777216个汉字
00000000 00000000 00000000 ~ 11111111 11111111 11111111
utf-16:最短的字节长度16
gbk和utf-8不能互相直接转化
使用
在内存中运用Unicode,更方便处理。
python内存中的是Unicode编码。
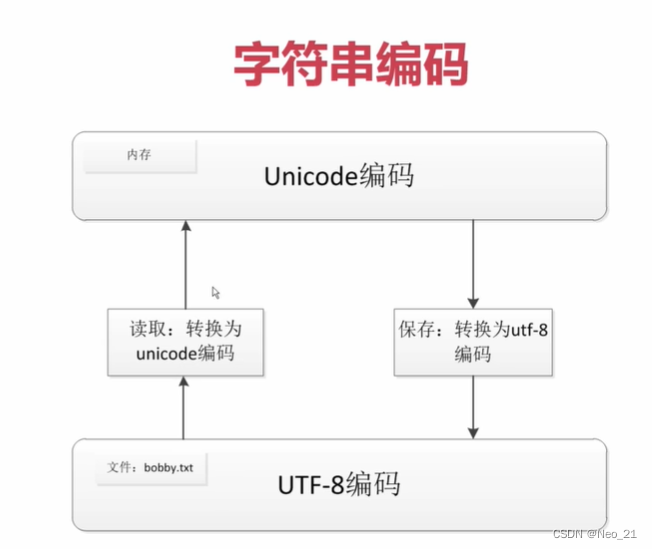
解码
常见的数据单位是bytes
s = "周杰伦"
bs = s.encode("gbk") #b'xxxx' bytes类型
print(bs) #转化位gbk,6个字节
bs2 = s.encode("utf-8")
print(bs2) #转化位utf-8,9个字节
//terminal
b'\xd6\xdc\xbd\xdc\xc2\xd7'
b'\xe5\x91\xa8\xe6\x9d\xb0\xe4\xbc\xa6'
把gbk的字节转化位utf-8的字节
bs =b'\xd6\xdc\xbd\xdc\xc2\xd7'
s = bs.decode("gbk")
print(s)
s2 = s.encode("utf-8")
print(s2)
//terminal
b'\xe5\x91\xa8\xe6\x9d\xb0\xe4\xbc\xa6'
















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









