




 文章介绍了One-ShotFederatedLearning方法,通过集成学习和知识聚合在单轮通信中优化全局模型,提高AUC。研究特别关注了二元分类任务中的凸模型,如SVM,同时扩展到非凸模型。文中还探讨了半监督设置下的模型蒸馏策略,以减少通信和保护隐私。
文章介绍了One-ShotFederatedLearning方法,通过集成学习和知识聚合在单轮通信中优化全局模型,提高AUC。研究特别关注了二元分类任务中的凸模型,如SVM,同时扩展到非凸模型。文中还探讨了半监督设置下的模型蒸馏策略,以减少通信和保护隐私。
《One-Shot Federated Learning》论文阅读
Accepted by NeurIPs 2018
Overview
我们提出了一次性联邦学习,其中中央服务器在单轮通信中通过联邦设备网络学习全局模型。我们的方法利用集成学习和知识聚合,AUC 相对于本地基线平均相对增益 51.5%,并接近了全局理想模型(无法达到)的90.1%。
Methods
我们提出了on-device监督设置的集成方法,并在半监督设置中通过蒸馏扩展了这些方法。???
我们的演示重点是用于二元分类任务的凸模型(核化支持向量机)。然而,所讨论的方法非常通用,并且可以很容易地扩展到非凸模型(例如深度网络)。
Hinge loss(铰链损失)是一种用于支持向量机(SVM)和一些其他分类算法的损失函数,通常用于大间隔分类问题。它的主要目的是测量模型的预测与实际标签之间的间隔,从而帮助模型找到一个能够在最大化分类间隔的同时正确分类样本的决策边界。
Hinge loss对于每个样本的计算方式如下:
- 对于一个样本(x,y),其中 x 是特征向量,y 是对应的真实标签(通常为+1或-1,表示两个类别)。
- 模型对于该样本的预测值记作 f(x),这个值可以是线性函数(如 w·x + b,其中 w 是权重向量,b 是偏置项)。
- Hinge loss 的计算方式如下:
- HingeLoss=max(0,1−y∗f(x))Hinge Loss = max(0, 1 - y * f(x))HingeLoss=max(0,1−y∗f(x))
Ensemble (Supervised)

SVM知识暂时不自学,ML课程学习!!!!!!!!!!!
其中 φ(Xt)Tφ(Xt)φ(X_t)^T φ(X_t)φ(Xt)Tφ(Xt) 可以使用“核技巧”用 k(Xt;Xt)k(X_t; X_t)k(Xt;Xt) 替换。所有设备都使用 RBF 核。我们将在设备 t 上学习的本地模型表示为 ftf_tft,其中 ft(x)=wtTxf_t(x) = w^T _t xft(x)=wtTx。
完成后,设备将本地模型 ftf_tft 发送到中央服务器。给定来自网络中设备的 f1,...,fmf_1,...,f_mf1,...,fm,中央服务器策划一个由 k≤mk ≤ mk≤m 模型组成的集合。
Strategies for ensemble selection:
- 交叉验证(CV)选择: 设备只有在其本地验证数据上达到一定的基准性能(如 ROC AUC)时,才会共享其本地模型,而基准性能由服务器事先确定。服务器从这些本地模型的子集中组合出 k 个性能最好的模型。
- 数据选择: 设备只有在拥有一定基线数量的本地训练数据时,才会共享其本地模型,而基线则由服务器事先确定。服务器从这些本地模型中选取前 k 个最大的数据集进行模型组装。
- 随机选择: 服务器从网络中随机选择 k 个设备,并从相应的本地模型中创建一个集合模型。
ROC AUC stands for "Area Under the ROC Curve."
kkk 个设备模型的最终集成 FkF_kFk 是通过对每个模型的预测进行平均.
NIST 全称为 NIST Speical Database 19,全数据集包含了 80 多万张图片
MNIST 则是 NIST 数据集的缩减版,因为 NIST 数据集的存储方式,及数据分类构成比较难用,而 MNIST 作为 NIST 的子集,则图片量更少,且仅含有数字,更易操作。
Extended MNIST (EMNIST), MNIST 被大家熟知,但是目前 MNIST 上的精度已经很高了,一个好的数据集应该更具挑战性,所以推出了 EMNIST ,一个在手写字体分类任务中更有挑战的 Benchmark。
原文链接:https://blog.youkuaiyun.com/Chris_zhangrx/article/details/86516331Federated Extended MNIST (FEMNIST),FEMNIST是FL的Benchmark “LEAF” 里的其中一个开源数据集,该数据集基于EMNIST进行划分,可以选择iid或non-iid的划分方式,non-iid的划分是基于不同writer的,因此能够实现更加贴合实际的non-iid分布。
Distillation (Semi-Supervised):
Distillation
模型蒸馏(Model Distillation)是一种用于训练小型模型以模仿大型模型的技术,从而在保持相对较高性能的同时减小模型的尺寸和计算资源需求.
- 教师模型:这是一个大型、强大的模型,通常在性能上表现良好。这可以是深度神经网络的各种架构,如BERT、GPT或ResNet等。教师模型被用来生成预测,以及提供用于训练学生模型的目标。
- 学生模型:这是一个相对较小的模型,通常具有更少的参数和计算资源需求。学生模型的目标是在尽量减小模型大小的同时,尽可能精确地模拟教师模型的行为。
- 软标签:为了将教师模型的知识传递给学生模型,不仅使用教师模型的预测作为训练目标,还使用了称为“软标签”的概率分布。软标签是教师模型在给定输入上的预测概率分布,通常是经过 温度参数 调节的
Softmax输出。这些概率分布提供了比硬标签(单个类别)更丰富的信息,有助于学生模型更好地理解任务。- 温度参数:用于调整教师模型生成的软标签分布的熵(entropy)。较高的温度会使分布更平滑,即每个类别的概率更接近,这有助于提供更多的信息,但也增加了训练的难度。较低的温度会使分布更集中,即某些类别的概率较高,这有助于稳定训练,但可能会损失一些信息。
- 蒸馏损失函数:蒸馏损失函数是用来衡量学生模型的预测与教师模型的预测(软标签)之间的差异。通常使用交叉熵损失来衡量它们之间的相似性。
当 kkk 很大时,将 FkF_kFk(集成模型) 传送到每个设备(并执行推理)可能是不可行的。**当中央服务器可以访问未标记的公共代理数据时,FkF_kFk 可以通过蒸馏压缩为更小的模型 f′f'f′ 。**在传统的蒸馏中,通过使用教师网络输出的类概率标记的数据来训练学生,将来自“教师”模型的知识转移到“学生”模型。我们提出了一种适用于SVM二元分类的修改方法。对于代理数据x1′,...,xl′x^{'}_1, ...,x^{'}_lx1′,...,xl′,我们生成相应的“软”标签 Fk(x1′),...,Fk(xl′)F_k (x^{'}_1), ...,F_k (x^{'}_l)Fk(x1′),...,Fk(xl′)。特别是,我们通过最小化学生和教师对代理数据预测的 L2L2L2 差异来执行(对偶???)蒸馏:[we perform distillation in the dual by minimizing the L2L2L2 difference in predictions between the student and teacher on the proxy data:]
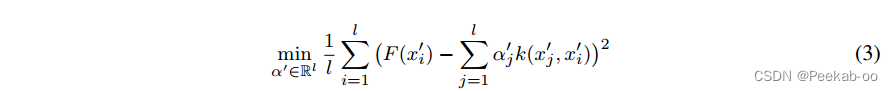
- x’1,…,x’l are the unlabeled proxy data points
- Fk(x’i) is the prediction of the ensemble model Fk on proxy data point x’i
- f’ is parameterized by coefficients α’1,…,α’l
- k(x’j, x’i) is the kernel similarity between two data points
- The objective is to minimize the L2 distance between the predictions of f’ and Fk on the proxy data
以生成经过提炼的模型 f′(x)=∑i=1lαiϕ(xi′)f'(x)=\sum_{i=1}^l \alpha_i \phi (x_i')f′(x)=∑i=1lαiϕ(xi′)。当设备之间共享本地模型存在隐私问题时(例如,双 SVM 需要共享本地支持向量),蒸馏不仅有助于压缩模型,还能实现保护隐私的学习。
Result
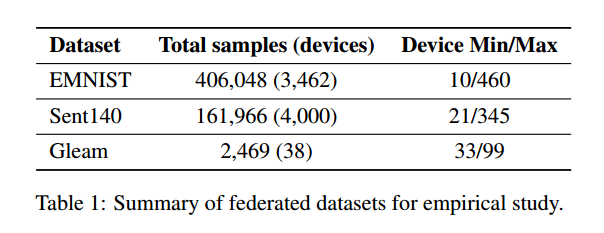
我们将每个设备的本地数据分成 50/40/10 的训练-测试-验证部分。在构建集成时,我们仅考虑来自具有最少本地样本数量的设备的分类器(Gleam/Sent140 为 30,EMNIST 为 60)(策略2)。数据点较少的设备不太可能学习到信息丰富的本地模型。强制执行此阈值可以简化中央服务器的整体构建,减少所需的通信,并减轻数据缺乏设备上的工作负载。我们选择 k = 1, 10, 50, 100 个客户端模型的集成,并根据两个基线进行评估:

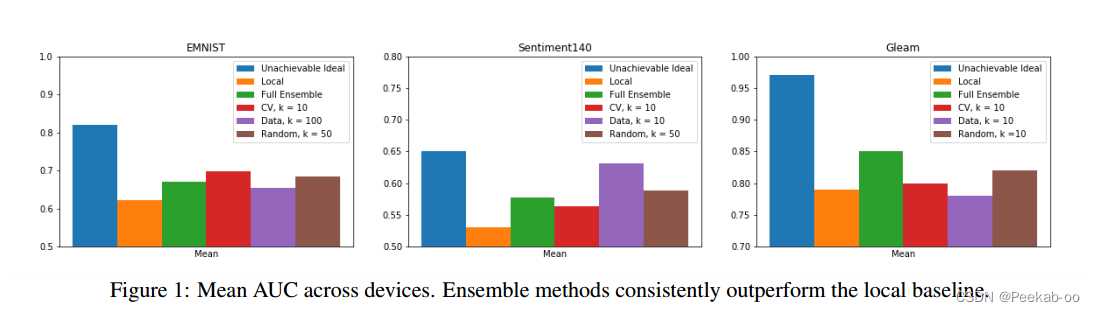
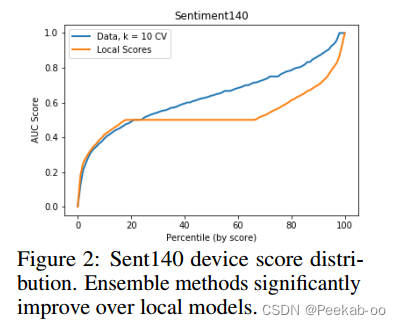
图 1 比较了每种选择策略的最佳 k 的平均 AUC(跨设备)、基线方法和由所有设备模型组成的完整集合。对于随机集合,我们报告了 5 次不同试验的平均值。我们发现,集成方法优于本地基线方法,而且除 Gleam(设备相对较少)外,选择集成优于完全集成。通过分析 Sent140 的设备得分分布(图 2),我们发现集成方法与性能较高的本地模型相匹配,同时性能也优于性能中等偏低的本地模型。【看不懂】
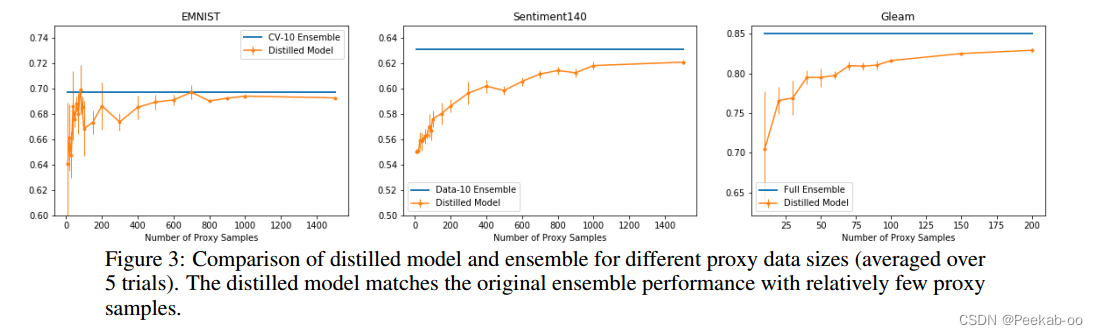
在半监督设置中,我们通过对所有设备的验证数据进行采样来生成代理数据。对于每个数据集,我们都会提炼出性能最好的集合,并随着代理数据规模的增加,将提炼出的模型与集成模型进行比较(图 3)。我们发现,在代理样本数量相对较少的情况下,提炼出的模型可以大致达到原始集合的性能。

















 872
872




 到【灌水乐园】发言
到【灌水乐园】发言







