







一.数据容器
1.作用:
批量存储,使用多份数据
2.定义:
一种可以容纳多份数据的数据类型,容纳的每一份数据被称为一个元素,每一个元素都可以是任意类型的数据,如字符串,数字,布尔等
3.数据容器的划分
数据容器根据特点的不同(是否支持重复元素,是否可以修改,是否有序等等)划分为五类
分别为:列表(list),元组(tuple),字符串(str),集合(set),字典(dict)
二.列表(list)
1.列表的定义方式
(1).字面量
[元素1, 元素2, 元素3, ...]
(2).定义变量
变量名称 = [元素1, 元素2, 元素3, ...]


(3).定义空列表
变量名称 = []
变量名称 = list()
列表内的每一个数据都被称为元素,其中以[]作为标记,并且列表中的每一个元素用逗号隔开
注意:
1.列表可以一次性存储多个数据,并且可以为不同的数据类型支持嵌套
2.列表的下标索引
(1).作用:
使用下标索引从列表中取出特定位置的数据
(2).下标索引的顺序:
正向:
列表中的每一个元素都有其位置所对应的下标索引,排序方式为从前往后,从0开始每次递增1
反向:
反向索引是从后往前,从-1开始每次递减1(-1为列表中最后的元素)


注意:
1.嵌套列表中同样可以使用下标索引,即,首先通过第一层列表的下表索引找到存于第一层列表中的第二层列表,然后使用第二曾列表的下标索引获取第二层列表中的元素
2.列表的常用操作(方法)
列表可以:
(1).定义
(2).使用下标索引获取值
列表的功能:
(1).插入元素
(2).删除元素
(3).清空列表
(4).修改元素
(5).同级元素个数
等等
列表的查询功能(方法):
函数是一个封装的代码单元,可以提供特定的功能
在Python中如果将函数定义为class(类)的成员,那么函数就会被称为方法
方法和函数的功能一样,有传入参数,返回值,只是方法的调用方式不同
(1).函数的调用:
方法名(传入的参数)
(2).方法的调用
创建的类的成员.调用的方法名(传入的参数)
列表的查询功能:
(1).查询某元素的下标:
功能:查询指定元素在列表中的下标,如果找不到,那么就会报错
语法:列表名.index(要查询的元素的值)


列表的修改功能:
功能:修改指定位置的元素值
语法:列表[下标] = 要修改的值
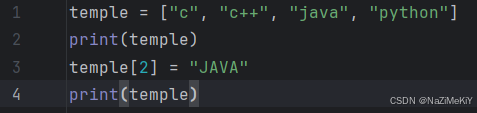

插入元素:
功能:在指定的下标位置插入指定的元素
语法:列表名.insert(下标,要插入的元素)
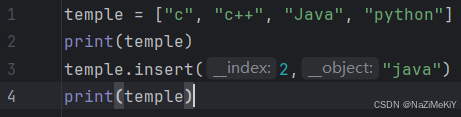

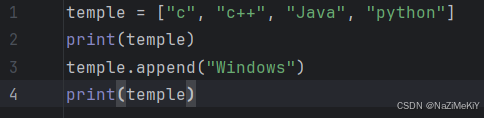
追加元素:
功能:将指定元素追加到列表的尾部
语法:列表名.append(要添加的元素)

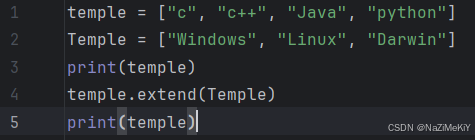
追加数据容器:
功能:将数据容器中的所有数据都追加到当前数据容器的末尾
语法:数据容器名.extend(要追加的数据容器名)

删除元素:
功能:删除指定下标上的元素
语法1:del 列表名[下标]
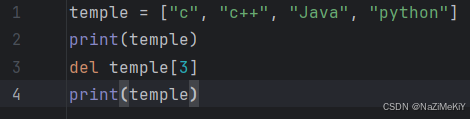

语法2:列表名.pop(下标)
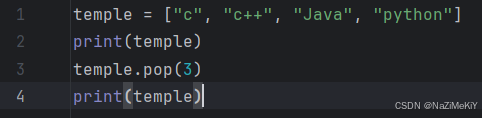

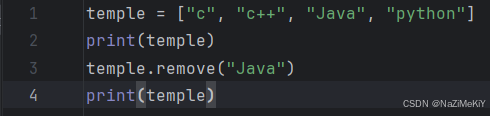
删除元素:
功能:删除某元素在列表中的第一个匹配项
语法:列表名.remove(元素)

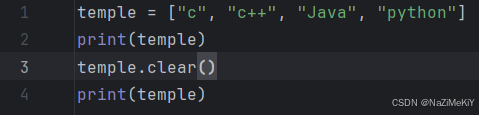
清空列表:
功能:清空列表中的所有内容,将其变为一个空列表
语法:列表名.clear()

统计元素数量:
功能:统计某元素在列表内的数量
语法:列表名.count(元素)


三.列表的遍历
while循环:
既然数据容器可以存储多个元素,那么,就会有需求从容器内依次取出元素进行操作,而将容器内的元素依次取出进行处理的行为被称为遍历和迭代
1.语法:
index = 0
while index < len(列表):
元素 = 列表[idnex]
对元素进行处理
index += 1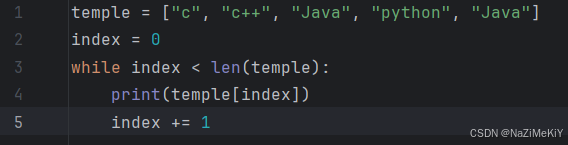
for循环遍历列表:
对比while循环,其实for循环更加适合对数据容器进行遍历
1.语法:
for 临时变量 in 数据容器:
对临时变量进行处理在for循环中我们每次都从数据容器中依次取出元素并且将其赋值到临时变量上,在每一次的循环中我们都可以对获取到的元素进行处理

while循环和for循环的对比:
1.在循环控制上:
while循环可以自定义循环条件并自行控制
for循环不可以自定义循环条件,只能一个个依次从数据容器中取出数据
2.在无限循环上:
while循环可以通过条件控制做到无限循环
for循环则在理论上不可以,因为被遍历的容器的容量不是无限的
3.在使用场景上:
while循环适用于任何想要循环的场景
for循环适用于便利数据容器的场景或者简单的固定次数的循环场景
四.数据容器(tuple)元组
元组同列表一样,都是可以封装多个,不同类型的元素在内,但是元组一旦定义完成就不可修改
所以在我们需要在程序内封装数据,又不希望封装的数据被篡改时,元组就非常合适了
1.元组的定义方式:
(1).定义元组字面量
(元素1, 元素2, 元素3, ..., 元素n)
(2).定义元组变量
变量名称 = (元素1, 元素2, ..., 元素n)
(3).定义空元组
方式1:
变量名称 = ()
方式2:
变量名称 = tuple()
注意:
1.如果元组中只有一个数据,那么这个数据后面必须要添加逗号,否则这就不是一个元组了
2.元组的创建中也同样支持嵌套(一个元组中嵌套另一个元组)
2.元组的相关操作
(1).index()
功能:查找某个数据,如果数据存在则返回对应的下标,否则报错
语法:元组名.index(查找的元素)


(2).count()
功能:统计某个数据在当前元组出现的次数
语法:元组名.count(要计算的元素)


注意:
1.元组的内容是不可修改的,否则会报错
2.可以修改元组内list(列表)的内容(在元组中嵌套了列表的情况)
(3).len()
功能:统计元组内的元素个数
语法:len(元组名)


3.元组的遍历
while循环:
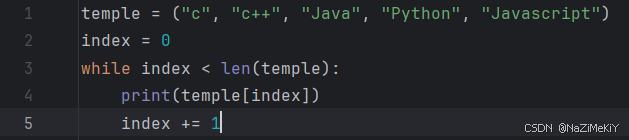
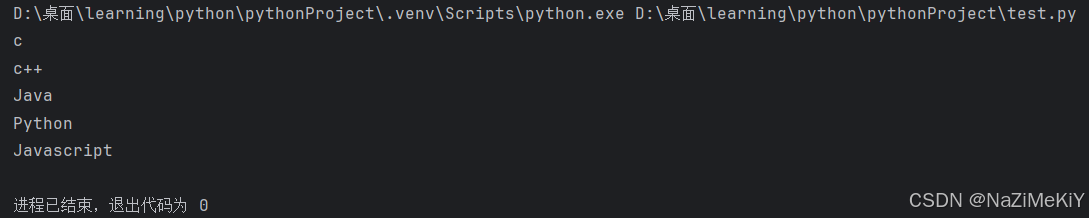
for循环:

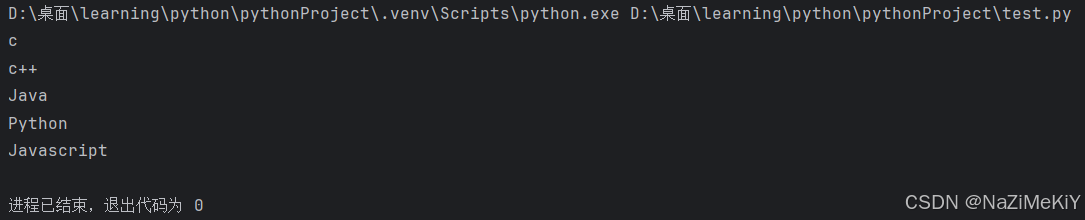
4.元组的特点:
(1).可以容纳多个不同类型的数据
(2).数据都是有序存储的
(3).允许数据重复存在
(4).不可以修改元组的数据
(5).支持循环
五.数据容器str(字符串)
字符串是字符的容器,一个字符串可以存放任意数量的字符
1.字符串的下标(索引)
和其他容器一样,字符串也可以通过下标进行访问
(1).从前向后,下标从0开始
(2).从后往前,下标从-1开始
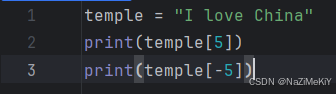

注意:
1.字符串是一个无法修改的数据容器,所以一系列的对字符串的修改操作都是无法完成的,如果必须要做,那么只能获得一个新的字符串,已经定义好的字符串是绝对无法修改的
2.字符串的常用操作
(1).查找特定字符串
功能:查找特定字符串的下标索引值
语法:字符串名.index(要查找的字符串)


(2).字符串的替换
功能:将字符串内的全部字符串1替换为字符串2
语法:字符串名.replace(字符串1,字符串2)


注意:在这里并不是对原有的字符串进行了修改,而是获得了一个新的字符串
(3).字符串的分割
功能:按照指定的分隔符字符串将字符串划分为多个字符串并存入列表对象中
语法:字符串名.split(分隔符字符串)


注意:原有的字符串没有改变,只是得到了一个新的列表对象
(4).字符串的规整操作
功能:去除前后的指定字符串
语法:字符串名.strip(要去除的字符串)


注意:虽说括号中的是要去除的字符串,但实际上是根据传入的每一个字符进行一个个的匹配,然后删除的,所以顺序并不会受影响
(5).统计字符串
功能:统计字符串内某字符串的出现次数
语法:字符串名.count(要统计的字符串)
(6).统计字符个数
功能:统计字符串中的字符个数
语法:len(要统计的字符串)


3.字符串的遍历
(1).while循环
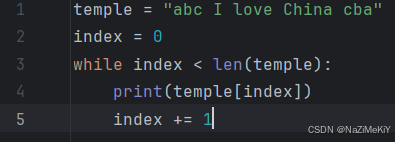
(2).for循环
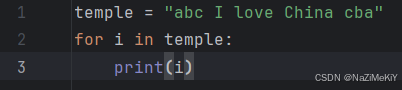
六.数据容器的切片操作
1.序列的概念:
序列是指内容连续,有序,可使用下标索引的一系列容器(列表,元组,字符串)
2.切片
序列都是支持切片操作的
(1).切片操作的定义:
从一个序列中,取出一个子序列
(2).语法:
序列[起始下标:结束下标:步长]
表示从序列中的指定位置开始,依次取出元素,到指定位置结束,得到一个新序列
起始下标表示从何处开始,可以留空,留空视作从头开始
结束下标表示从何处结束,可以留空,留空视作截取到结尾
步长表示依次取元素的间隔,如步长1表示一个个取元素,步长2表示每次跳过一个元素...(步长值可以为负,表示从后往前取值)


注意:切片操作不会影响到原序列本身,而是会得到一个新的序列
七.数据容器set(集合)
1.集合的应用场景:
在上文所介绍的数据容器中都是支持重复元素的,那么如果在当前的应用场景中对内容进行去重处理时,上文所提到的数据容器就不方便了。
而集合最主要的特点就是不支持重复元素(自带去重功能),并且内容无序
2.集合的定义
(1).定义集合字面量:
{元素1, 元素2, ..., 元素n}
(2).定义集合变量:
变量名称 = {元素1, 元素2, ..., 元素n}
(3).定义空集合:
变量名称 = set()


3.集合的常用操作——修改
因为集合是无序的,所以集合不支持下标索引访问,但是集合是可以修改的
(1).添加新元素
功能:在集合中添加新元素
语法:集合名.add(要添加的元素)


(2).移除元素
功能:将指定元素从集合中移除
语法:集合名.remove(要移除的元素)


注意:会移除集合中所有满足条件的元素
(3).从集合中随机取出元素
功能:从集合中随机取出一个元素,同时集合本身会被修改,该元素被移除
语法:集合名.pop()


(4).清空集合
功能:清空集合中所有的元素
语法:集合名.clear()


(5).取出两个集合的差集
功能:取出集合1和集合2的差集(集合1有而集合2没有的)
语法:集合1.difference(集合2)


注意:使用这个方法之后是得到了一个新的集合,原有的集合1和集合2不变
(6).消除两个集合的差集
功能:对比集合1和集合2,在集合1内删除和集合2相同的元素
语法:集合1.difference_update(集合2)
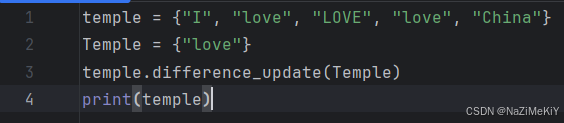

注意:集合1被修改,而集合2不变
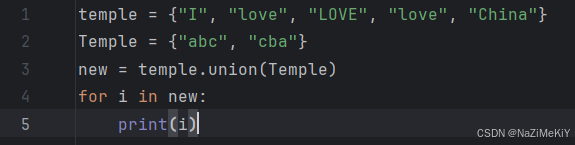
(7).合并两个集合
功能:将集合1和集合2组合成新集合
语法:集合1.union(集合2)


注意:最后是得到了一个新集合,集合1和集合2不变
(8).计算集合长度
功能:计算出集合中存入的元素的个数
语法:len(集合)
4.遍历集合
因为集合并不支持下标索引,所以我们没有办法通过下标索引的方式,即while循环对其进行遍历,但是可以使用for循环一个一个地取出其中的元素,最后完成遍历
八.数据容器dict(字典,映射)
1.字典的应用场景:
我们可以通过key,取到对应的value值
2.字典的定义:
(1).定义字典字面量
[key1: value1, key2: value2, ..., keyn, valuen]
(2).定义字典变量
字典名 = {key1: value1, key2: value2, ..., keyn, valuen}
(3).定义空字典
字典名 = {}
或
字典名 = dict{}
3.取出字典中的数据
字典和集合一样,不可以使用下标索引,但是可以通过key值获取对应的value值


4.字典的嵌套
字典的key和value可以是任意类型数据(key不可以是字典)
所以字典是可以嵌套的


5.字典的常用操作
(1).新增元素
功能:原字典被修改,新增加元素
语法:字典名[key] = value


(2).更新元素
功能:字典被修改,元素被更新
语法:字典名[key] = value
注意:因为字典中的key不可以重复,所以对已存在的key进行上述操作就会变为更新value值
(3).删除元素
功能:获得指定key的value,同时字典被修改,指定key的数据被删除
语法:字典名.pop(要删除的key值)


(4).清空字典
功能:字典被修改,元素被清空
语法:字典名.clear()
(5).获取全部的key值
功能:得到字典中全部的key值
语法:字典名.keys()


(6).计算字典的元素数量
功能:计算存在于字典中的所有元素的数量
语法:len(字典名)
6.字典的遍历
因为字典同样不支持下标索引,所以只能使用for循环对字典进行遍历

九.容器的通用操作
1.max(容器名)
获取容器内最大元素
2.min(容器名)
获取容器内最小元素
3.len(容器名)
计算容器内元素个数
4.list(容器名)
将容器转换为列表
5.tuple(容器名)
将容器转换为元组
6.str(容器名)
将容器转换为字符串
7.set(容器名)
将容器转换为集合
8.sorted(序列,[reverse = True])
排序,后面的reverse = True表示降序,False则为升序,得到一个排序完成的列表


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









