



 本文深入探讨了Python中while循环的使用方法,包括基本语法、continue和break语句的应用,以及如何创建无限循环和理解while...else结构。通过具体代码示例,读者可以掌握循环控制的技巧,提高编程效率。
本文深入探讨了Python中while循环的使用方法,包括基本语法、continue和break语句的应用,以及如何创建无限循环和理解while...else结构。通过具体代码示例,读者可以掌握循环控制的技巧,提高编程效率。
课程学习笔记总结


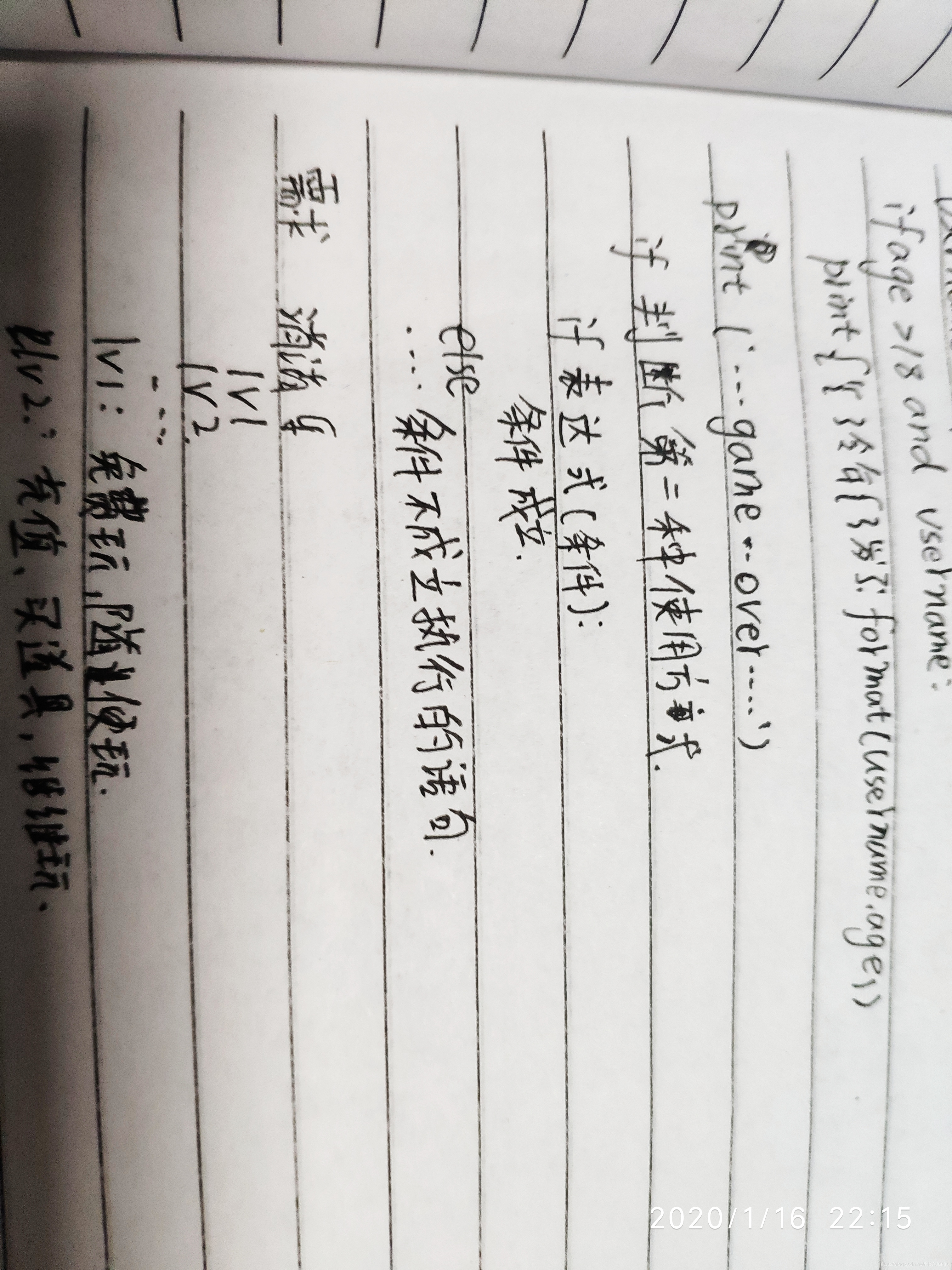





 补充代码段
补充代码段
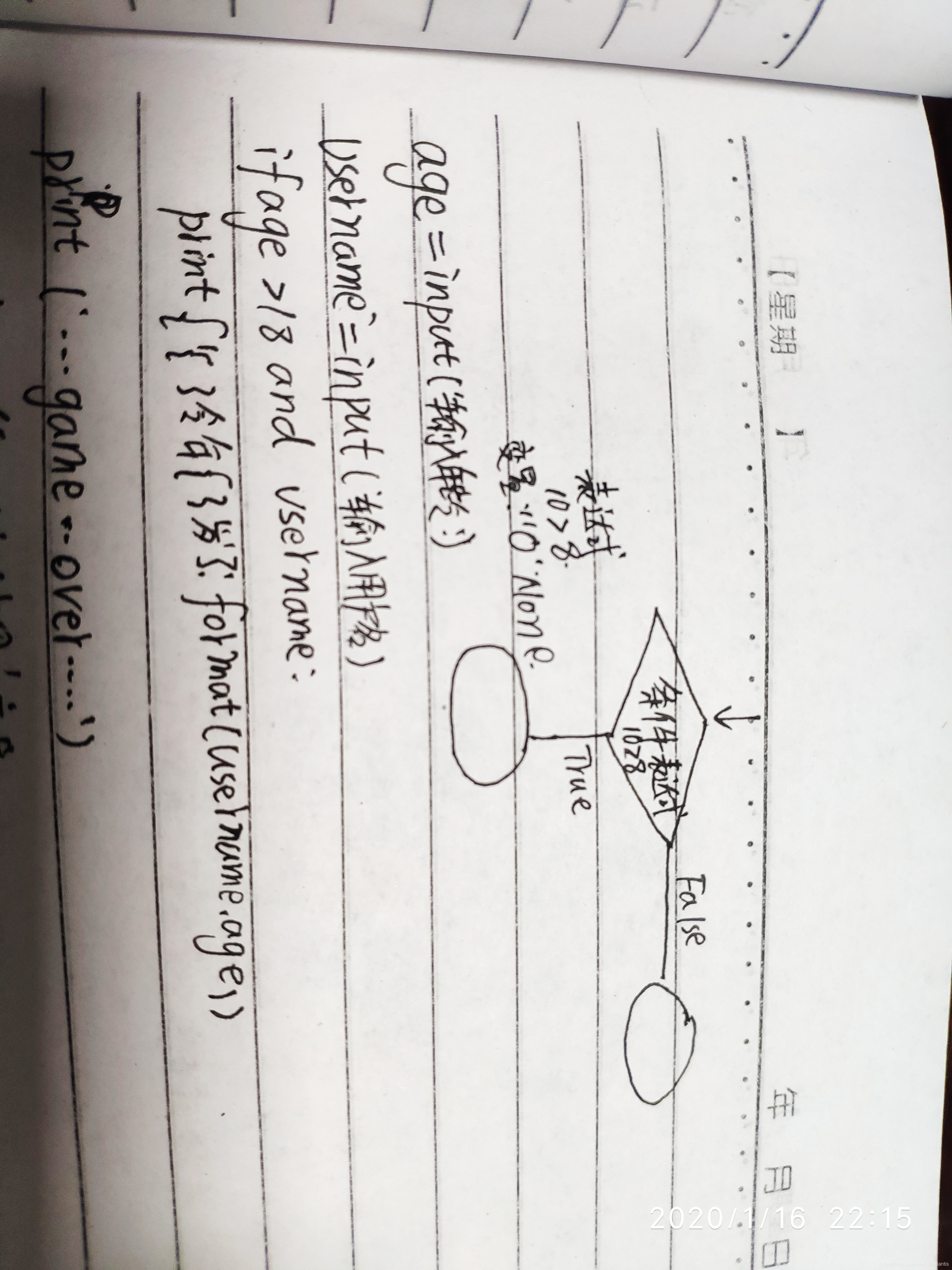
count = 0
while (count < 9):
print ‘The count is:’, count
count = count + 1
print “Good bye!”
continue 和 break 用法
i = 1
while i < 10:
i += 1
if i%2 > 0: # 非双数时跳过输出
continue
print i # 输出双数2、4、6、8、10
i = 1
while 1: # 循环条件为1必定成立
print i # 输出1~10
i += 1
if i > 10: # 当i大于10时跳出循环
break
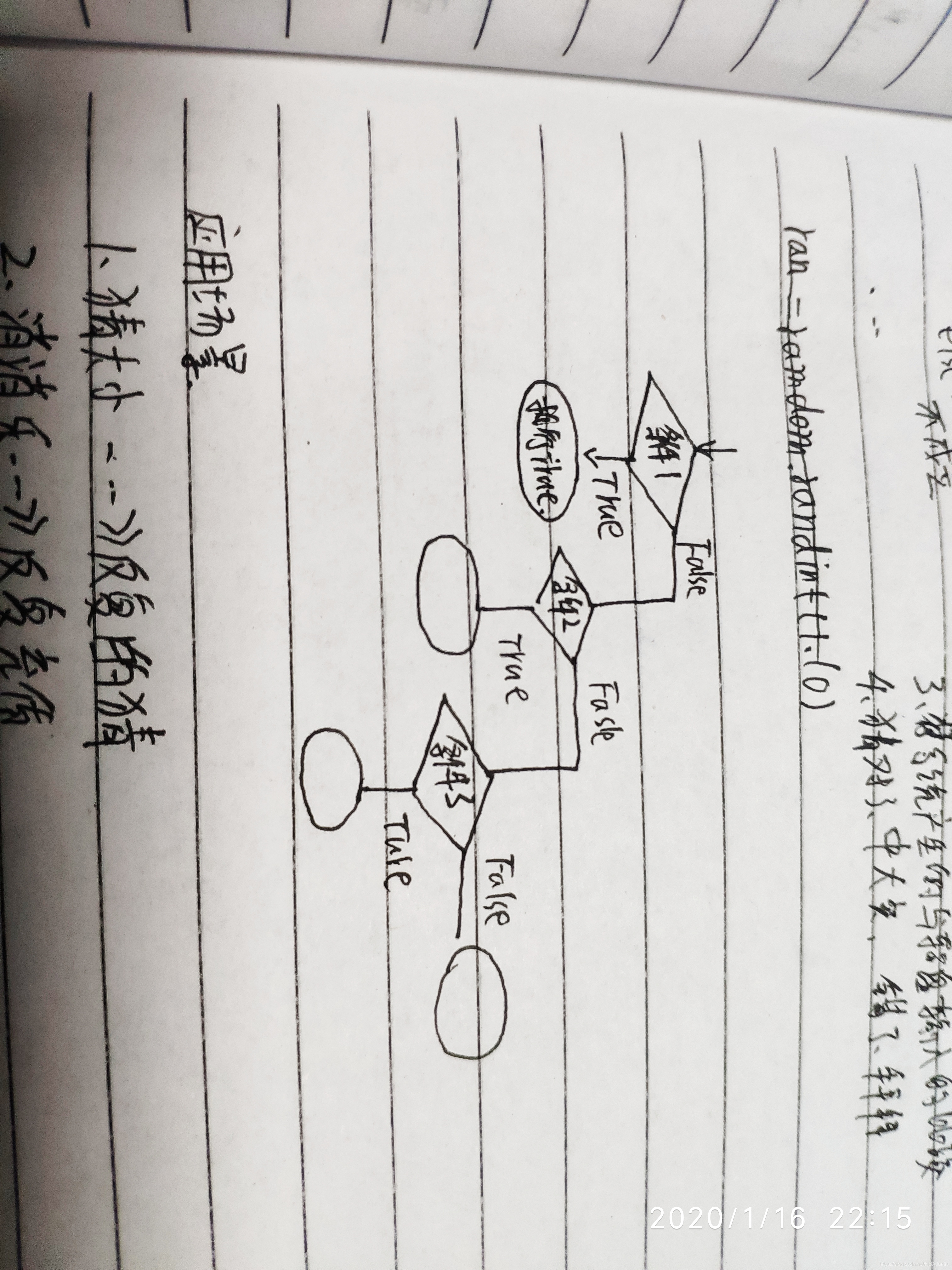
无限循环
如果条件判断语句永远为 true,循环将会无限的执行下去,如下实例:
实例
var = 1
while var == 1 : # 该条件永远为true,循环将无限执行下去
num = raw_input(“Enter a number :”)
print "You entered: ", num
print “Good bye!”
在 python 中,while … else 在循环条件为 false 时执行 else 语句块
count = 0
while count < 5:
print count, " is less than 5"
count = count + 1
else:
print count, " is not less than 5"



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









