







 本文档详细介绍了MongoDB的基本操作,包括创建数据集、插入数据、更新数据、删除数据以及各种查询方法,如条件查询、分组查询、重复值查询和JSON查询。示例代码展示了如何执行这些操作,帮助读者掌握MongoDB数据库的日常使用。
本文档详细介绍了MongoDB的基本操作,包括创建数据集、插入数据、更新数据、删除数据以及各种查询方法,如条件查询、分组查询、重复值查询和JSON查询。示例代码展示了如何执行这些操作,帮助读者掌握MongoDB数据库的日常使用。
1简介
mongodb是一个存储json的数据库(以下内容参考菜鸟教程)
2安装链接
3图形工具
官网提供了图形化界面工具
4常用数据类型

5操作以及知识点
建数据集
mongodb的数据集相当于mysql的表
语法:
db.createCollection(name, options);
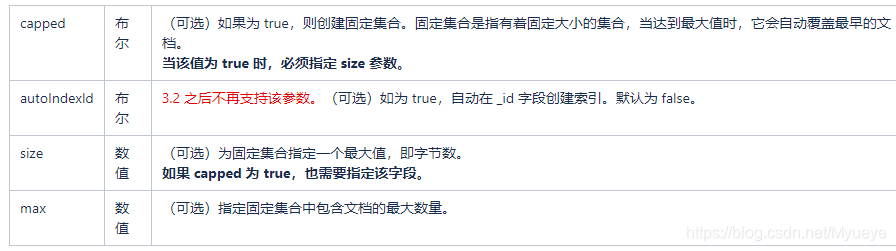
name: 要创建的集合名称
options: 可选参数, 指定有关内存大小及索引的选项
options
:例子:新建一个名为 col的数据集
db.createCollection("col");
插入数据
语法:
db.COLLECTION_NAME.insert(document) 或 db.COLLECTION_NAME.save(document)
save():如果 _id 主键存在则更新数据,如果不存在就插入数据。该方法新版本中已废弃,可以使用 db.collection.insertOne() 或 db.collection.replaceOne() 来代替。
insert(): 若插入的数据主键已经存在,则会抛 org.springframework.dao.DuplicateKeyException 异常,提示主键重复,不保存当前数据。
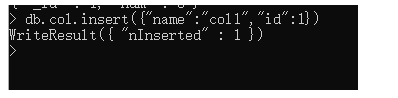
例子: 往col插入一个json数据
db.col.insert({"name":"col1","id":1})
更新数据
语法:
db.collection.update(
< query>,
< update >,
{
upsert: ,
multi: ,
writeConcern:
}
)
query : update的查询条件,类似sql update查询内where后面的。
update : update的对象和一些更新的操作符(如
,
,
,inc…)等,也可以理解为sql update查询内set后面的
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别。
例子: 更新col数据集的数据
db.col.update({"id":1},{$set:{"name":"new_name"}})

以上语句只会修改第一条发现的文档,如果要修改多条相同的文档,则需要设置 multi 参数为 true
db.col.update({"id":1},{$set:{"name":"name"}},{multi:true})

删除数据
语法:
db.collection.remove(
< query >,
{
justOne: < boolean >,
writeConcern: < document >
}
)
query :(可选)删除的文档的条件。
justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。
writeConcern :(可选)抛出异常的级别
例子: 删除col数据集的数据
db.col.remove({"id":1})
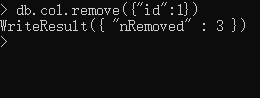
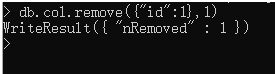
以上语句会把所有字段id=1的数据删除,如果只需要删除一条,则
db.col.remove({"id":1},1)
如果想把整个数据集的数据删除,则
db.col.remove({})
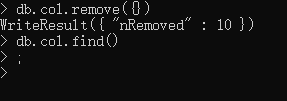
条件查询
语法:
db.collection.find(query, projection) 或者 db.collection.find(query, projection).pretty()
query :可选,使用查询操作符指定查询条件
projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
pretty() 方法以格式化的方式来显示所有文档。
query语法格式

and条件: find() 方法可以传入多个键(key),每个键(key)以逗号隔开.
or条件: 使用了关键字 $or 一个关键字数组组合成
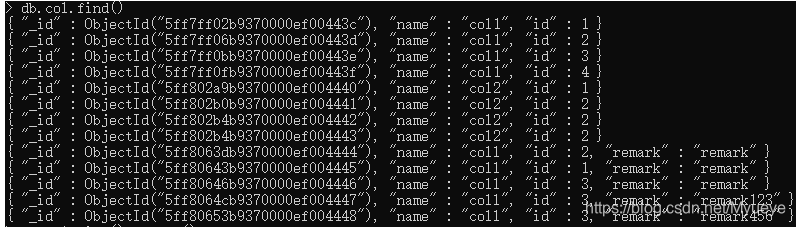
查询col数据集的全部数据:
db.col.find()
查询col里id字段大于2的数据
db.col.find( { "id" : { $gt : 2 } } )

查询col里id大于2并且name 为coll的数据(and条件)
db.col.find( {"id" : { $gt:2 } , "name":"col1" } )

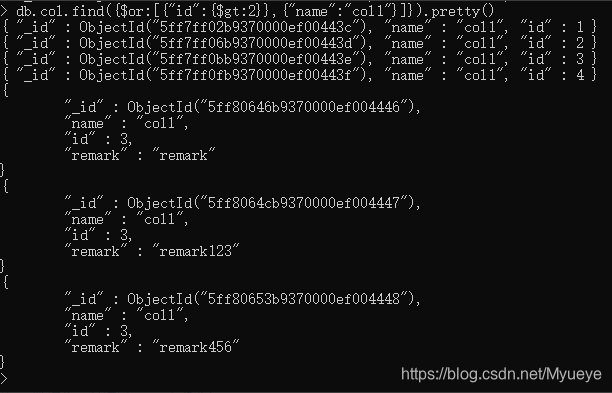
查询 col里id大于2或者name 为coll的数据(or条件)
db.col.find(
{
$or: [ {"id":{$gt:2} }, {"name":"col1"} ]
}
).pretty()
分组查询
语法:
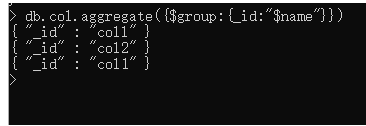
查询clo数据集,并通过name字段分组
db.col.aggregate({$group:{_id:"$name"}})
查询结果如下
查询clo数据集,通过name字段分组,并统计组内数据数
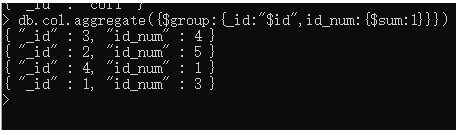
db.col.aggregate({$group:{_id:"$ id",id_num:{$sum:1}}})
查询结果如下:
重复值查询
根据id进行分组,而后统计该组内的数量num(该字段可自定义名称),而后使用$match进行过滤数据:将num大于1的进行过滤
db.col.aggregate({$ group:{_id:"$ id",num:{$ sum:1}}},{$match:{num:{$gt:1}}})

JSON查询
销售订单表中,销售员是一个json结构,{empId,empIcon,empName};
查找销售员=>当前用户的所有订单。
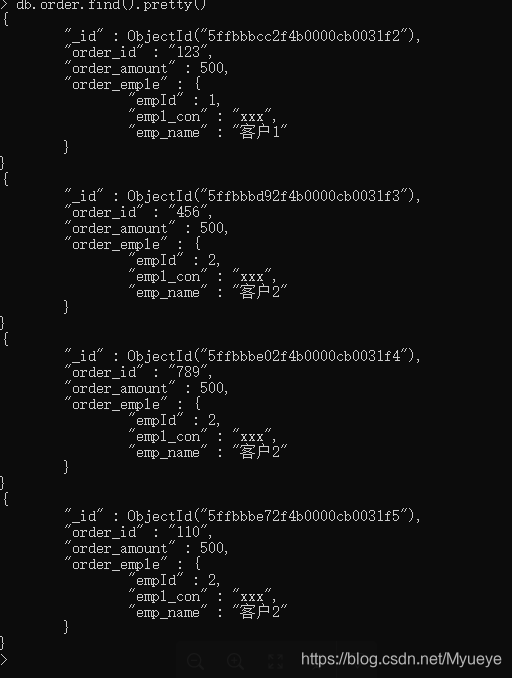
查找当前订单表所有信息:
db.order.find().pretty()
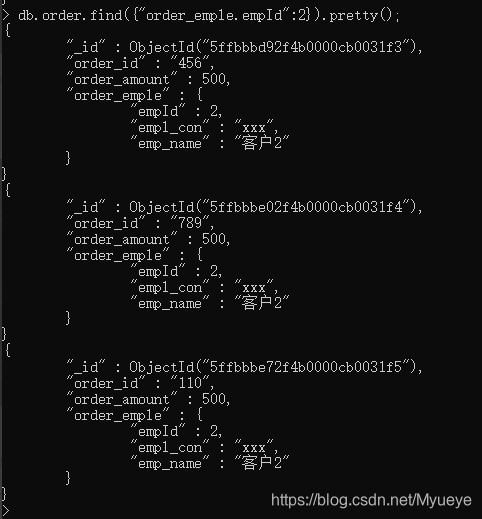
根据用户的id查找对应的所有订单数据:
db.order.find( {"order_emple.empId":2} ).pretty();
Json的gropu查询
人口表有两个字段:人口数量及地区;其中地区是json类型,有省、市、地三个字段。 分别按省、市、地分组统计人口数量
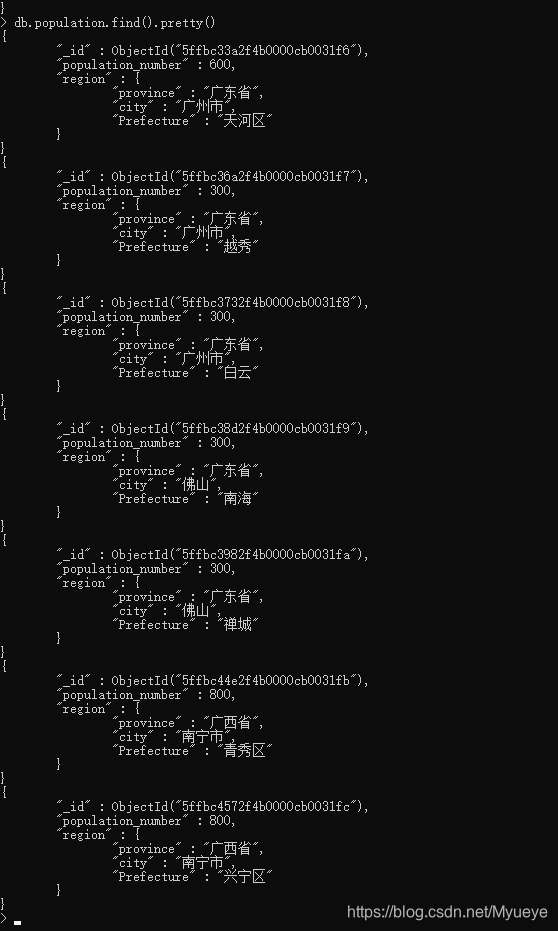
查询人口表所有数据:
db.population.find().pretty()
根据省份分组查询:
db.population.aggregate({$group:{_id:"$region.province",total:{$sum:"$population_number"}}}).pretty()

根据市级分组查询:
db.population.aggregate({$group:{_id:"$region.city",total:{$sum:"$population_number"}}}).pretty()

根据市级分组查询广东内人口:
db.population.aggregate([{$match:{"region.province":"广东省"}},{$group:{_id:"$region.city",total:{$sum:"$population_number"}}}]).pretty()

根据地区分组查询:
db.population.aggregate({$group:{_id:"$region.Prefecture",total:{$sum:"$population_number"}}}).pretty()


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









