




 本文介绍了如何使用Scala进行Spark项目开发,包括设置Scala SDK、打包jar包以及在线上运行Spark SQL查询。同时,讲解了读写Hive表数据,特别是写入分区表的操作流程。
本文介绍了如何使用Scala进行Spark项目开发,包括设置Scala SDK、打包jar包以及在线上运行Spark SQL查询。同时,讲解了读写Hive表数据,特别是写入分区表的操作流程。
1. 自定义数据生成查询表
package com.zz.spark.sparksql
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 自定义DataFrame注册成数据表,查询数据表
*/
object Demo1 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Demo1")
.master("local")
.getOrCreate()
val df: DataFrame = spark.createDataFrame(
Seq(("zhangsan", 22), ("lisi", 33), ("wangwu", 44))
).toDF("name", "age")
df.show()
df.createTempView("t_user")
val result: DataFrame = spark.sql("select * from t_user where age=33")
result.show()
spark.close()
}
}
1.1 目录结构&本地运行
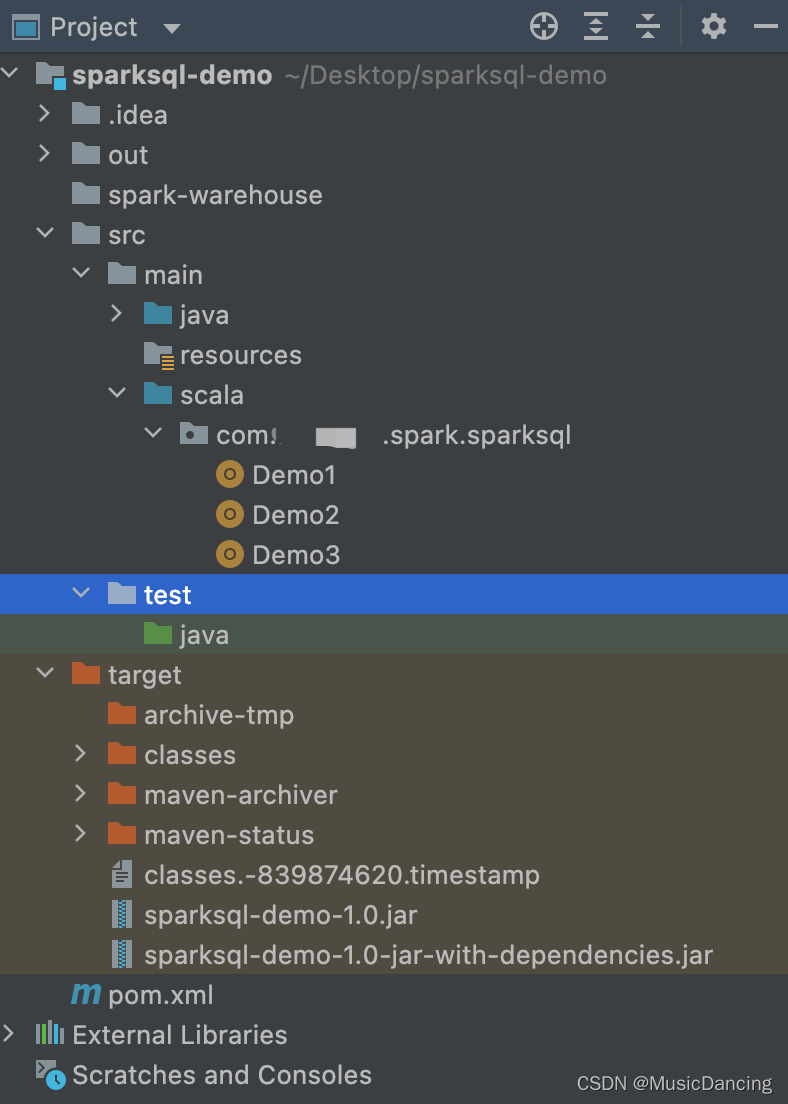
项目导入后,需进行Scala SDK配置。scala 版本别太高,2.11.x 即可。
step.1: [File] --> [Project Structure]
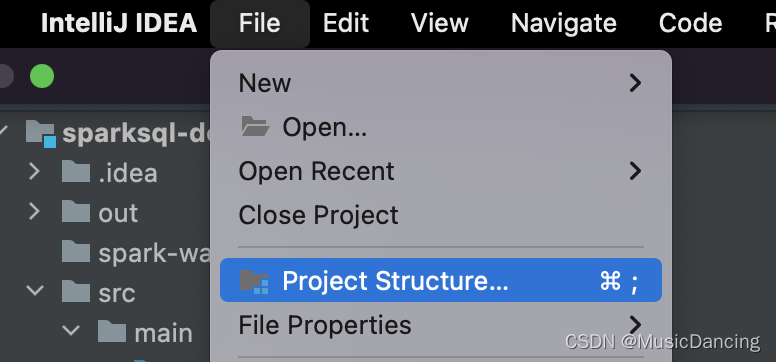
step.2: [Nodules] --> [Dependencies] --> [Library] --> [Scala SDK]
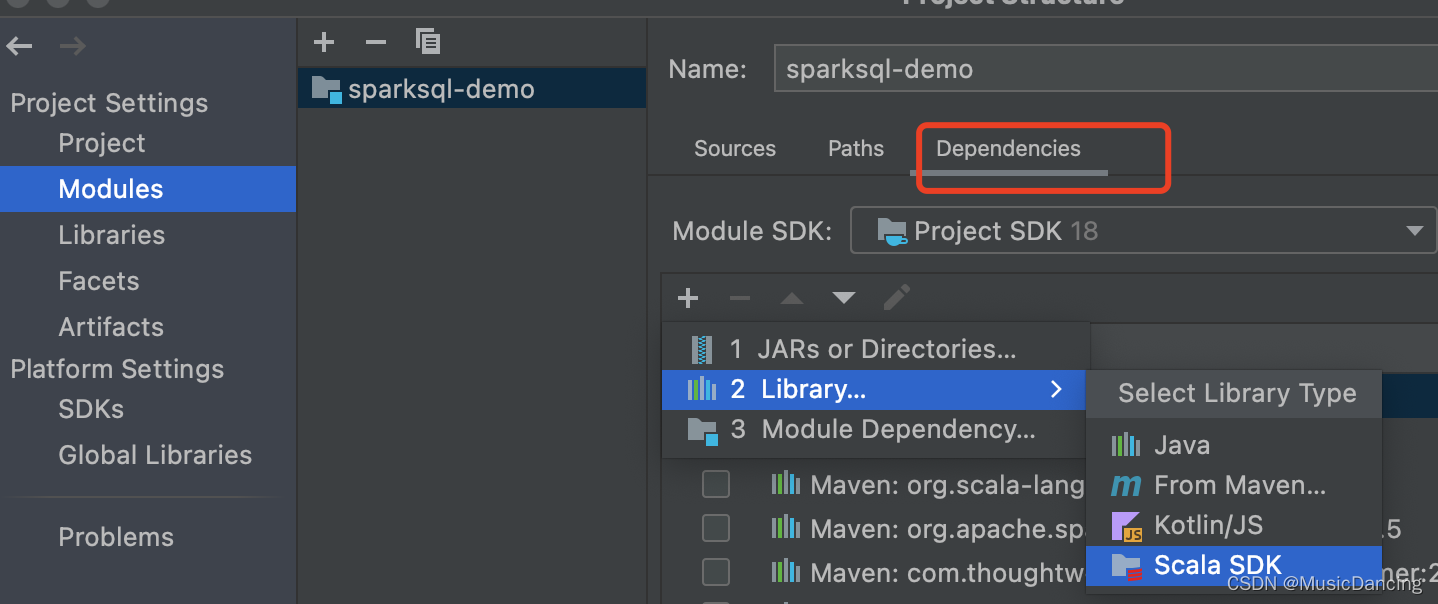
step.3: [2.11.8] --> [ok]
step.4: 确保本地运行无误即可
1.2 打包jar包
step.1 点击右侧的[Maven]
先点击[clean]清空之前的maven 打包文件。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2989
2989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









