




参考:【NLP】Transformer模型原理详解 - 知乎
从RNN到“只要注意力”——Transformer模型 - 知乎
Attention机制提出后,加入attention的Seq2seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合RNN和attention的模型。之后google又提出了解决Seq2Seq问题的Transformer模型,用全attention的结构代替了lstm,在翻译任务上取得了更好的成绩。
Attention原理:
从RNN到“只要注意力”——Transformer模型 - 知乎
1. 模型结构
和大多数seq2seq模型一样,transformer也是由encoder和decoder组成。
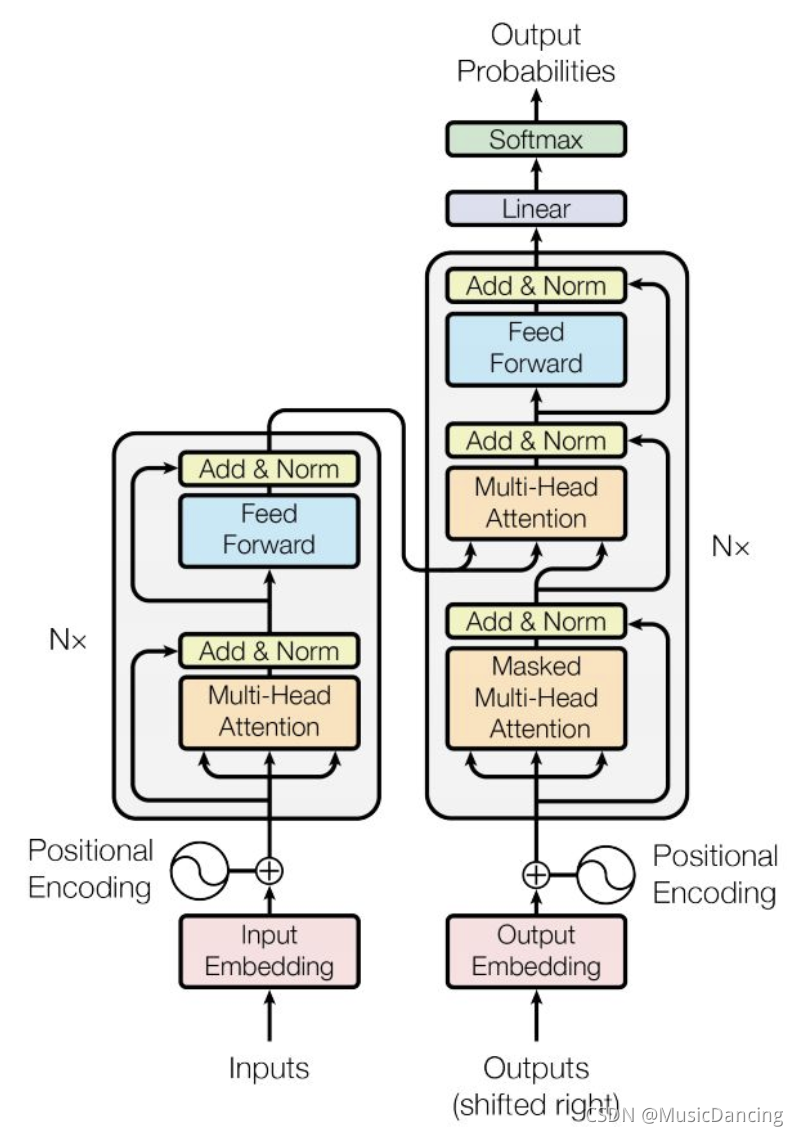
其中,解码器的输入output(shifted right)是指目标句子,但被mask掉未来的token,也就是mask矩阵的右上角都不可见。(这个结构是做翻译任务,目标句子相当于ground truth)。
在训练时,解码器的输入是按照目标词进行监督的,这里是有问题的,叫exposure bias,有不少研究是解决这块。
output的embedding与input一样,是两个向量(词/字向量+位置向量)的和,看了一下文章词/字embedding是自己学来的,在训练时更新,而且output和input的embedding权重是一样的,也就是在input中如果把“我”embedding成(0,1)向量,那output中的“我”也是(0,1)。
encoder的output是source sentence的编码,不需要再经过embedding,直接输入的decoder,需要过embedding的是target sentence,只在训练时有,因为在训练decoder时,0到t-1步都需要用ground truth,而预测时不需要ground truth。
1.1 Encoder
&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1032
1032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









