




 该博客探讨了年龄预测模型的优化策略,包括使用w2v进行applist的词向量表示,调整app权重分布以提升40-50年龄段预测准确性,增加app一级分类特征,以及引入income特征来提高预测精度。通过这些方法,模型在不同数据集上的预测准确率有所提升。
该博客探讨了年龄预测模型的优化策略,包括使用w2v进行applist的词向量表示,调整app权重分布以提升40-50年龄段预测准确性,增加app一级分类特征,以及引入income特征来提高预测精度。通过这些方法,模型在不同数据集上的预测准确率有所提升。
1. w2v 提取app词向量
使用w2v模型进行训练,将applist转换为32维词向量,输入xgb模型进行训练,准确度与直接使用applist进行训练的准确度没有明显区别。但是从实际意义上出发,经过词向量训练得到的applist的语义信息不与applist完全相关,后续可以作为累加特征使用。
2. 修改app权重分布
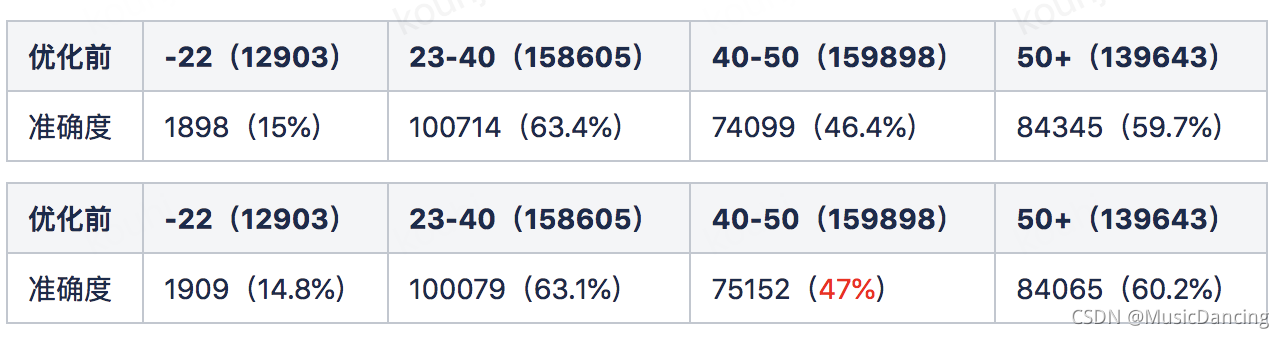
优化目的:通过对40-50年龄段的badcase挖掘applist,提升xgb模型对40-50岁年龄段的预测准确度。
优化思路:获取到训练阶段的各个特征权重,再乘以特征的权重矩阵,就可以增加某些特征在损失函数中的权重,就达到了放大特征效果的目的。
优化结果:训练数据200w,预测数据47w,预测正确26.6w(56.59%)+0.6%
3. 增加app分类
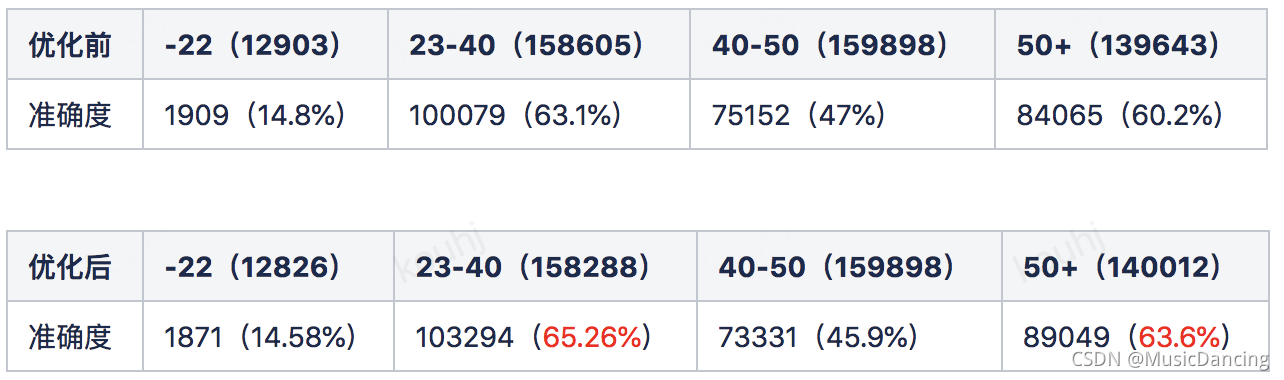
获取applist中各个app对应的一级分类标签first_cat.
优化目的:增加用户下载的applist的描述特征,提高年龄4段的预测准确率。
对app所属类别在训练集中的分布情况(200w训练数据)

优化思路:对用户下载的app所属类别进行统计,如用户下载的app中哔哩哔哩和爱奇艺属于视频类app,同花顺属于理财类,今日头条属于新闻类,则得到用户的app类别特征:视频类app:2;理财类app:1;新闻类app:1。
优化结果:训练数据200w,预测数据47w,预测正确26.7w(56.81%)+0.3%
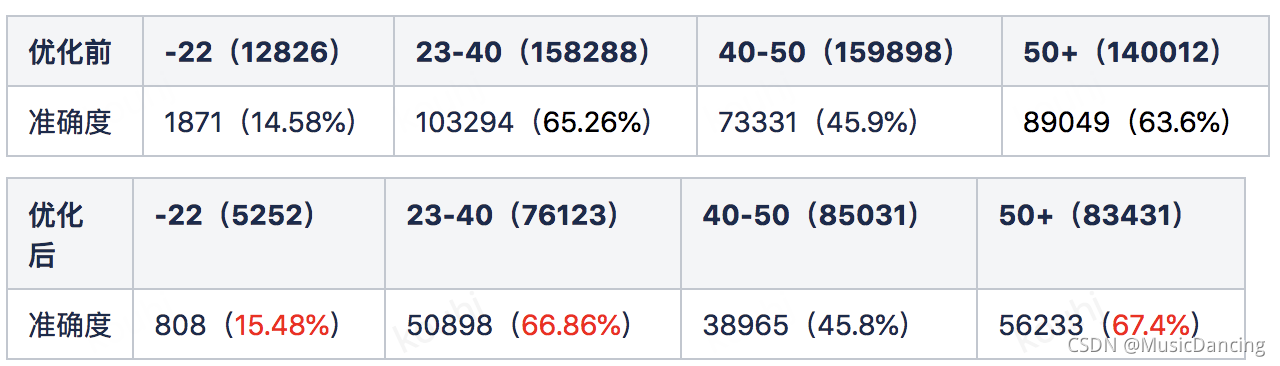
4. 增加income特征
优化思路:通过常识判断用户的年龄与收入成比例关系进行数据分析,根据上述对income和age的统计情况可以看出,income为top1人群收入中年龄大于40岁所占比例较大,随着income取10,25,50,100时,年龄阶层向年龄小的方向移动;同时income的取值情况符合基本常识,故增加用户的income特征增加income特征。
优化结果:训练数据100w,预测数据25w,预测正确14.7w(58.81%)+2%

















 8476
8476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









