




1. RDD编程概述
1.1 RDD创建
1.1.1 textFile(URI) 从文件系统中加载数据创建RDD
import org.apache.spark.sql.SparkSession
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("wc")
.master("local")
.getOrCreate()
import spark.implicits._
// 1. 从本地文件系统中加载
var inputPath = "/Users/zz/Desktop/data/aa.txt"
// var inputPath = "file:///Users/zenmen/Desktop/pom.xml"
// val rdd = spark.read.textFile(inputPath)
val rdd = spark.sparkContext.textFile(inputPath)
rdd.take(3).foreach(println)
// 2. 从分布式文件系统HDFS中加载
var inputPath = "hdfs://localhost:9000/user/hadoop/aa.txt"
var inputPath = "/user/hadoop/aa.txt"
spark.stop()
}
}
1.1.2 parallelize() 通过并行集合(数组)创建RDD
val arr = Array(1, 2, 3, 4)
// 也可以是list
val list = List(1, 2, 3, 4)
val rdd = spark.sparkContext.parallelize(arr)
rdd.take(3).foreach(println)
// 处理成字符串
val aa = rdd.collect().mkString("_")
// 1_2_3_4
1.2 RDD操作
1.2.1 转换操作
注意:RDD转换操作是懒加载的!
一些常见的转换操作:
1. filter(func): 筛选出满足func()的元素,并返回一个新的数据集。
2. map(func): 将每个元素传递到func()中,并将结果返回一个新的数据集。
3. flatmap(func): 与map()相似,但每个输入元素都可以映射到0或多个输出结果。
4. groupByKey(): 应用于k-v数据集时,返回一个新的(K, Iterable)形式的数据集。
5. reduceByKey(func): 应用于k-v数据集时,返回一个新的k-v数据集,其中每个值是将key传递到func()进行聚合。
1.2.2 行动操作
遇到Action时,Spark才会从文件中加载数据,完成一系列Transformation,计算得到结果。
一些常见的行动操作:
1. count() 返回数据集中的元素个数;
2. collect() 以数组的形式返回数据集中的所有元素;
3. first() 返回第一个元素;
4. take(n) 以数组形式返回数据集中前n个元素;
5. reduce(func) 通过func()聚合数据集中的元素(输入两个参数并返回一个值);
6. foreach(func) 将数据集中的每个元素传递到func()中运行。
1.2.3 惰性机制及应用举例
val inputPath = "/Users/zz/Desktop/aa.sh"
val rdd = spark.sparkContext.textFile(inputPath)
// 统计文本字数
val rdd2 = rdd.map(_.length)
val total = rdd2.reduce(_+_)
println(total)
// 统计文件中包含“http”的行
val cnt = rdd.filter(_.contains("http")).count()
// 找出文件中单行文本所包含的单词数量的最大值
val max = rdd.map(_.split(" ").size).reduce((a,b) => if(a>b) a else b)
或
val max = rdd.map(_.split(" ").size).max()
当遇到reduce时,才真正触发计算,这时,Spark会把计算分解成多个任务在不同的机器上执行,每台机器运行属于它自己的map和reduce,最后把结果返回给Driver。
1.3 持久化
通过持久化(缓存)机制避免重复计算的开销,使用persist()对一个RDD标记为持久化。注意,这里并不会马上计算生成RDD并持久化,而是要遇到第一个行动操作触发真正计算后,才会把计算结果进行持久化。持久化后的RDD将会被保留在计算节点的内存中被后面的Action重复使用。
persist()中持久化级别参数:
1. MEMORY_ONLY: 将RDD作为反序列化的对象存储于JVM中,如果内存不足,就要按照LRU原则替换缓存中的内容。
2. MEMORY_AND_DISK: 将RDD作为反序列化的对象存储于JVM中,如果内存不足,超出的分区将会被存放在硬盘上。
将持久化的RDD从缓存中移除: unpersist()。
一般而言,使用cache() 时,会调用persist(MEMORY_ONLY)。
val rdd = spark.sparkContext.textFile(inputPath)
rdd.cache() // 这里并不会缓存rdd,还没计算生成
println(rdd.count()) // 第一次Action,这时才会把rdd放到缓存中
println(rdd.collect().mkString(",")) // 第二次Action,不需要触发从头到尾的计算,会使用缓存中的rdd。
1.4 分区
RDD通常很大,会被分成很多个分区,分别保存在不同节点上。
优点
1. 增加并行度;
2. 减少通信开销。
1.4.1 分区原则
分区的个数尽量等于集群中cpu核心(core)数目,对于不同Spark部署模式而言,都可以通过设置spark.default.parallelism=N,来配置默认分区数目。
1. 本地模式:默认本地机器的CPU数目,也可以设置local[N];
2. Apache Mesos:默认分区为8;
3. Standalone YARN:默认值=max("集群中所有CPU core数目总和", 2);
1.4.2 分区方法
1. sc.textFile(path, N)
// 默认分区数为min(defaultParallelism,2),其中defaultParallelism=spark.default.parallelism
val rdd = spark.sparkContext.textFile(inputPath, 2)
println(rdd.partitions.size)
val arr = Array(1, 2, 3, 4)
// 默认分区数为spark.default.parallelism
val rdd1 = spark.sparkContext.parallelize(arr, 2)
println(rdd1.partitions.size)
如果从HDFS读文件,则分区数为文件分片数(比如:128M/片)。
2. rdd.repartition(N)
val rdd3 = rdd.repartition(4)
println(rdd3.partitions.size)
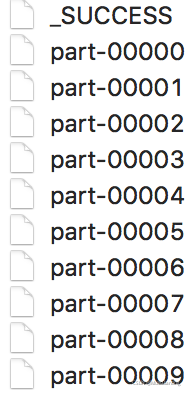
实例: 根据key的最后一位数字,写到不同的文件。
0 part-00000
1 part-00001
2 part-00002
import org.apache.spark.sql.SparkSession
import org.apache.spark.Partitioner
class UsridPartitioner(num: Int) extends Partitioner{
override def numPartitions: Int = num
override def getPartition(key: Any): Int = {
key.toString.toInt % 10
}
}
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("wc")
.master("local")
.getOrCreate()
// 模拟5个分区的数据
val data = spark.sparkContext.parallelize(1 to 10, 5)
// 根据尾号转变为10个分区,写入到10个文件
data.map((_,1))
.partitionBy(new UsridPartitioner(10))
.map(_._1).saveAsTextFile("/Users/zenmen/Desktop/output")
spark.stop()
}
}
output文件夹内容:
1.4.3 打印元素
rdd.foreach(println)
rdd.map(println)
当采用本地模式local在单机上执行时,这些语句会打印出一个RDD中的所有元素。但当采用集群模式执行时,在worker节点上执行打印语句是输出到worker节点上的stdout中,而不是输出到任务控制节点Driver Program中,因此,Driver Program中的stdout是不会显示打印语句的这些输出内容的。
使用collect()可以把所有worker节点上的打印输出信息显示到Driver Program中。但由于collect()会把各个worker节点上的所有RDD元素都抓取到Driver Program中,因此,当需要打印RDD的部分元素时,可以采用rdd.take(100).foreach(println)。
2. Pair RDD
可以从文件中加载,使用map(x => (x,1))生成。
pair RDD的一些常用操作
2.1 reduceByKey(func)
用于对每个key对应的多个value进行merge操作,且能够在本地先进行merge操作,且merge操作能通过函数定义。
val rdd = spark.sparkContext.textFile(inputPath)
val pairRDD = rdd
.flatMap(_.split(" "))
.map((_,1))
val pairRDD_new = pairRDD.reduceByKey(_+_)
pairRDD_new.foreach(println)
当采用reduceByKey时,Spark可以在每个分区移动数据之前将待输出数据与一个公用的key结合。
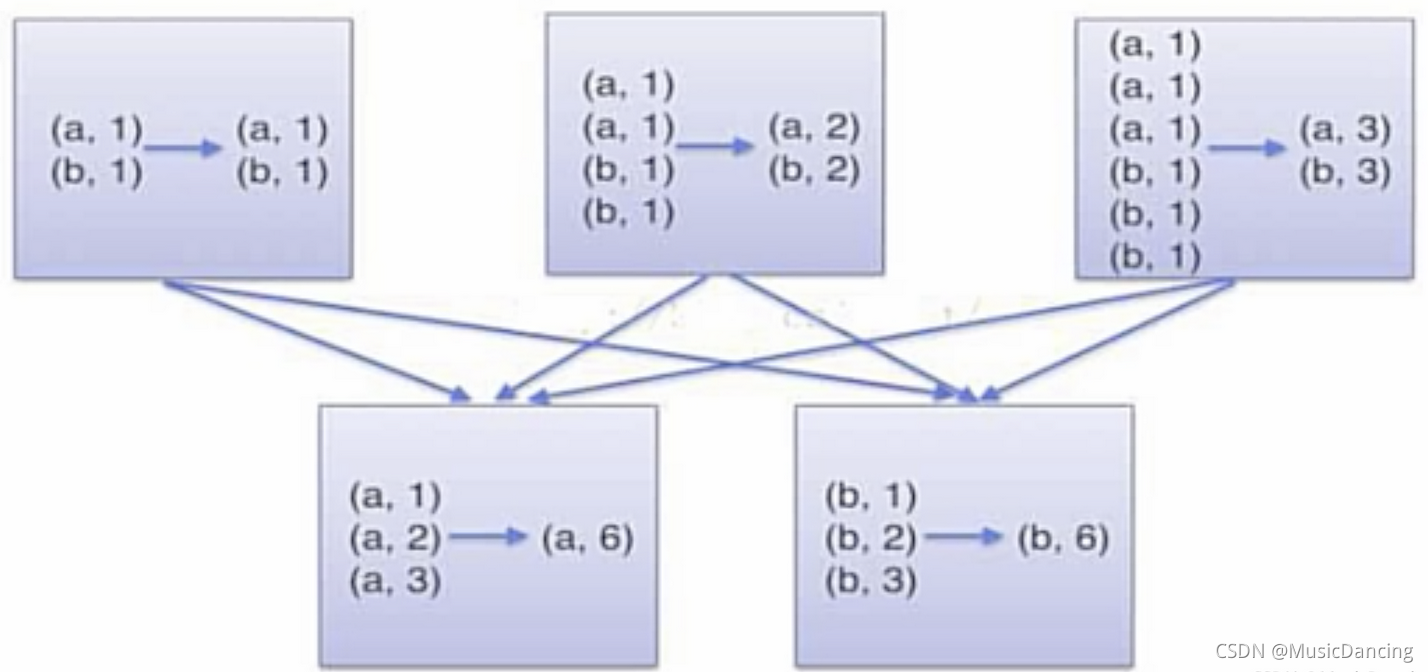
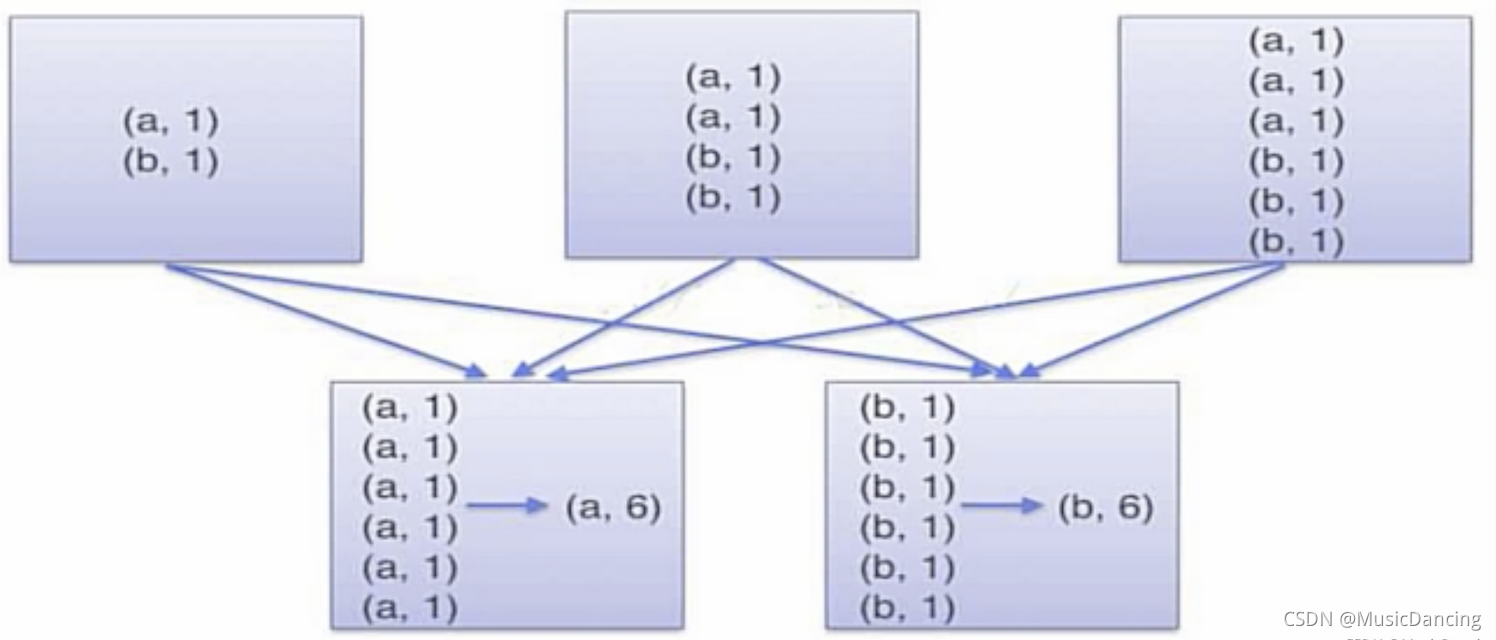
2.2 groupByKey()
用于对相同key的value进行分组,每个key对应生成一个sequence,本身不能定义函数,需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作。
val pairRDD_new = pairRDD
.groupByKey()
.map(t => (t._1, t._2.sum))
pairRDD_new.foreach(println)
当采用groupByKey时,由于它不接收函数,Spark只能先将所有的k-v都移动,这样导致集群节点之间的开销很大,传输延迟。
2.3 keys、values、sortByKey()
val pairRDD_new = pairRDD.reduceByKey(_+_)
val rdd = pairRDD_new.keys
val rdd = pairRDD_new.values
// 默认升序
val rdd = pairRDD_new.groupByKey()
// 降序
val rdd = pairRDD_new.groupByKey(false)
// 按值降序
val rdd = pairRDD_new
.sortBy(_._2,false)
.collect()
或
rdd = pairRDD_new
.map(t => (t._2,t._1))
.sortByKey(false)
.map(t => (t._2, t._1))
rdd.foreach(println)
2.4 mapValues(func)
对值加1
val rdd = pairRDD.mapValues(_+1)
2.5 join
jion表示内链接,与sql join一致。
val arr1 = Array(("spark",1), ("spark",2), ("hadoop",1), ("hadoop",2))
val arr2 = Array(("spark", "fast"))
val pairRDD1 = spark.sparkContext.parallelize(arr1)
val pairRDD2 = spark.sparkContext.parallelize(arr2)
val rdd1 = pairRDD1.join(pairRDD2)
rdd1.foreach(println)
// (spark,(1,fast))
// (spark,(2,fast))
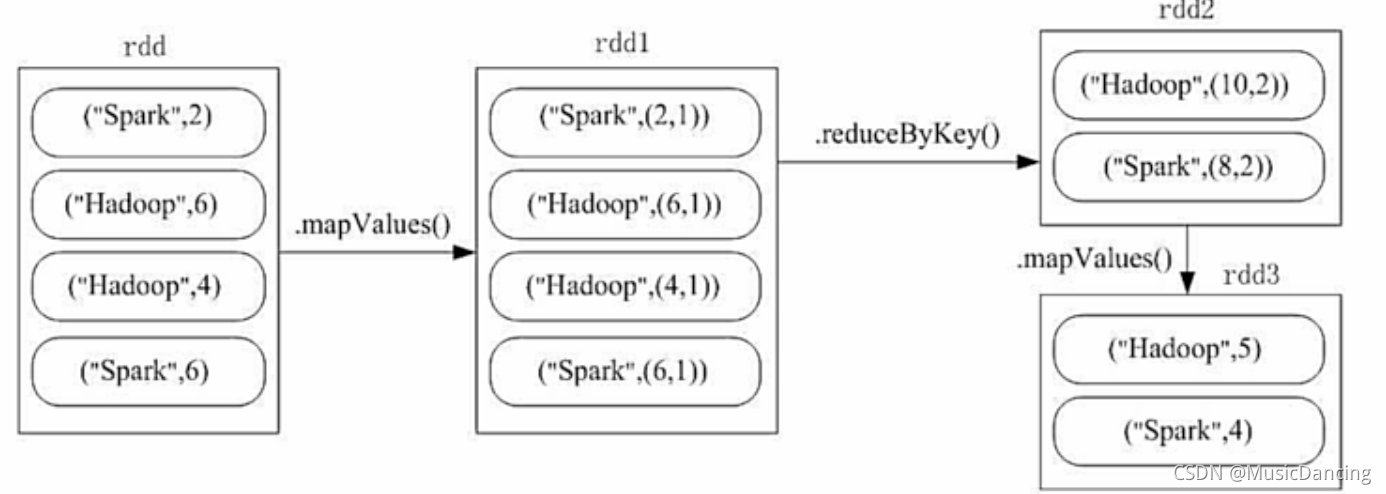
2.6 combineByKey
一个实例
计算图书的日均销量(key表示图书名称,value表示单日销量)
val arr = Array(("spark",2), ("spark",6), ("hadoop",4), ("hadoop",6))
val pairRDD = spark.sparkContext.parallelize(arr)
val rdd = pairRDD
.mapValues((_,1)) // 将值映射为(销量,天数)
.reduceByKey((x,y) => (x._1+y._1,x._2+y._2)) // x._1表示第一条的第一个,y._2表示第二条的第二个
.mapValues(x => (x._1/x._2))
.collect()
rdd.foreach(println)
// (spark,4)
// (hadoop,5)
3. 共享变量
Spark中两个重要抽象分别是RDD和共享变量。
当Spark在集群的多个不同节点的多个任务上并行运行一个函数时,它会把函数中涉及到的每个变量在每个任务上都生成一个副本。但有时候,需要在多个任务之间共享变量,或者在任务Task和任务控制节点(Driver Program)之间共享变量。为此Spark提供了两种类型的变量:
1. 广播变量(broadcast variables)
用来把变量在所有节点的内存之间进行共享。
2. 累加器(accumulators)
支持在所有不同节点之间进行累加计算(如计数或求和等)。
3.1 广播变量
允许在每台机器上缓存一个只读的变量,而不是为机器上的每个任务都生成一个副本。
Action 操作会跨越多个阶段stage,对于每个stage内的所有任务所需要的公共数据,Spark都会进行广播。
val arr = Array(1, 2, 3)
// 将一个普通变量包装成一个广播变量
val broadcast_var = spark.sparkContext.broadcast(arr)
// 获得该广播变量的值
println(broadcast_var.value)
这个广播变量被创建后,集群中任何函数都应该使用该广播变量的值,这样就避免把原普通变量分发到这些节点上。另外,一旦广播变量创建后,原普通变量的值就不能再发生修改,从而确保所有节点都获得这个广播变量的相同的值。
实现数组中元素变为3倍。
// 可以是任意类型变量
val broadcast_var = spark.sparkContext.broadcast(3)
val list = List(1, 2, 3, 4, 5)
val rdd = spark.sparkContext.parallelize(list)
val result = rdd.map(_*broadcast_var.value)
result.foreach(println)
3.2 累加器
累加器是仅仅被相关操作累加的变量,通常可以被用来实现计数器counter和求和sum。
Spark原生地支持数值型的累加器,也可以编写对新类型的支持。
一个数值型的累加器,可以通过调用sc.longAccumulator()或者sc.doubleAccumulator()来创建运行在集群中的任务,就可以通过add()来把数值累加到累加器上,但这些任务只能做累加操作,不能读取累加器的值,只有任务控制节点(Driver Program)可以使用value方法来读取累加器的值。
val accum = spark.sparkContext.longAccumulator("my acc")
val arr = Array(1, 2, 3, 4)
val rdd = spark.sparkContext.parallelize(arr)
rdd.foreach(accum.add(_))
println(accum.value)
// 10

















 4419
4419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









