




1. 简介
Spark SQL在Hive兼容层面仅依赖HiveQL解析、Hive元数据,即从HQL被解析成抽象语法树AST起,就全部由Spark SQL接管了。Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责。Spark SQL架构 如下:
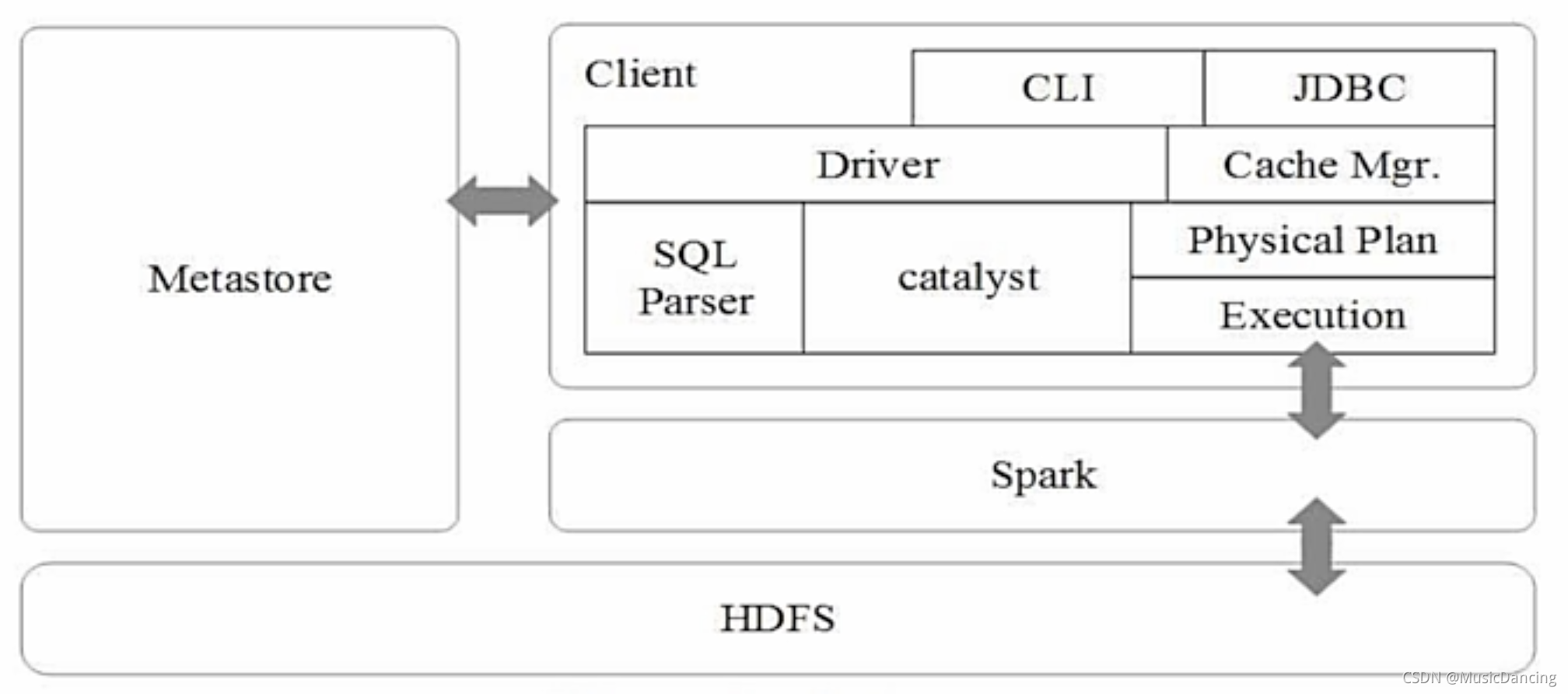
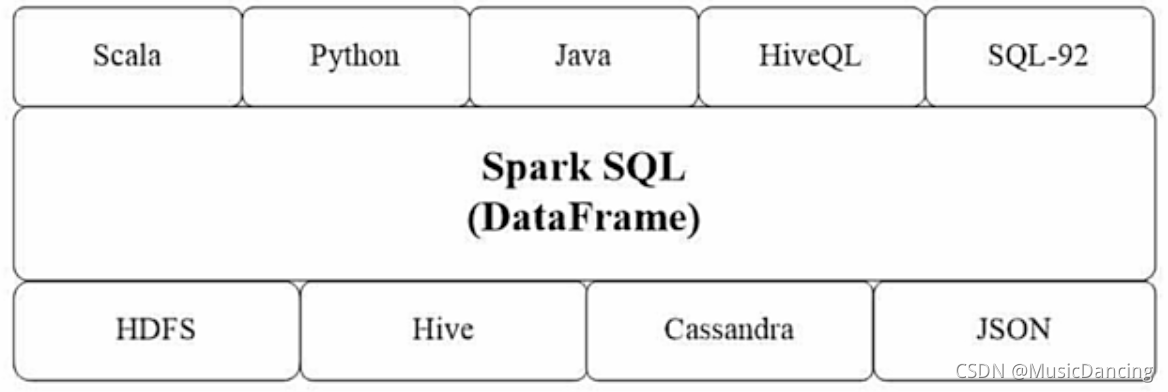
Spark SQL增加了DataFrame(带有Schema信息的RDD),可以直接执行SQL语句,数据既可以来自RDD,也可以来自Hive、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据。
Spark SQL目前支持Scala、Java、Python3种语言,支持SQL-92规范。
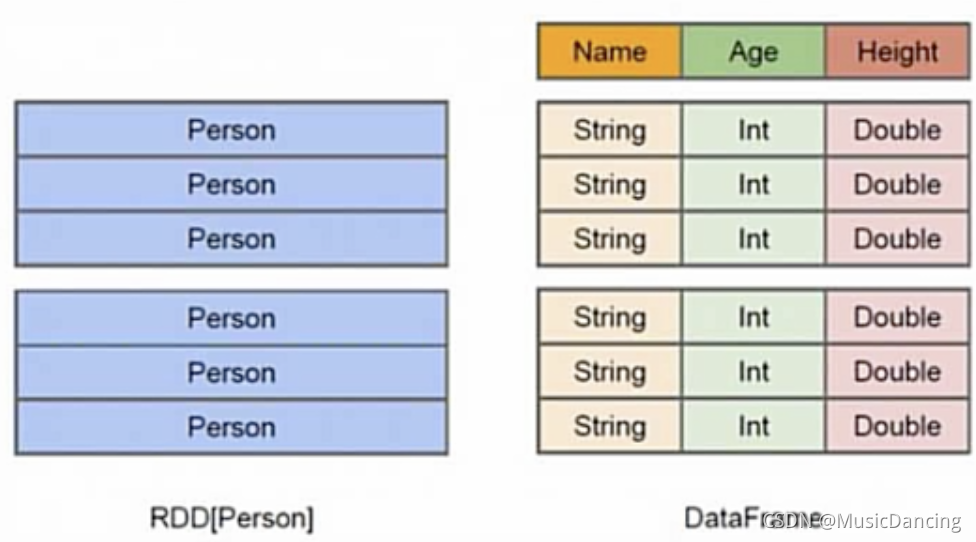
2. DataFrame与RDD的区别
1. DF让Spark具备了处理大规模结构化数据的能力,不仅比RDD转化方式更加简单易用,而且计算性能更高;
2. Spark能够轻松实现从MySQL到DF的转化,并且支持SQL查询;
3. RDD是分布式的Java对象的集合,但对象内部结构对RDD而言是不可知的;
4. DF是一种以RDD为基础的分布式数据集,提供了详细的结构信息。
3. DataFrame的创建
2.0版本后,Spark使用SparkSession 接口代替了(1.6版本中的)SQLContext及HiveContext 接口来实现其对数据加载、转换、处理等功能。支持从不同数据源加载数据,转换成DF,并支持把DF转换成SQLContext自身中的表,以便使用SQL语句。
读json文件到DF
import org.apache.spark.sql.SparkSession
object SimpleApp {
def main(args: Array[String]): Unit = {
val file = "file:///usr/local/spark/people.json"
val spark = SparkSession.builder().getOrCreate()
// 隐式转换,使支持RDDs转换为DataFrames及后续sql操作
import spark.implicits._
val df = spark.read.json(file)
df.show()
}
}一些常用操作
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









