




1. 安装Spark
2. 在Spark shell中运行代码
Spark Shell本身就是一个Driver,Driver包mian()和分布式数据集。
启动Spark Shell 命令:
./bin/spark-shell --master <master-url>
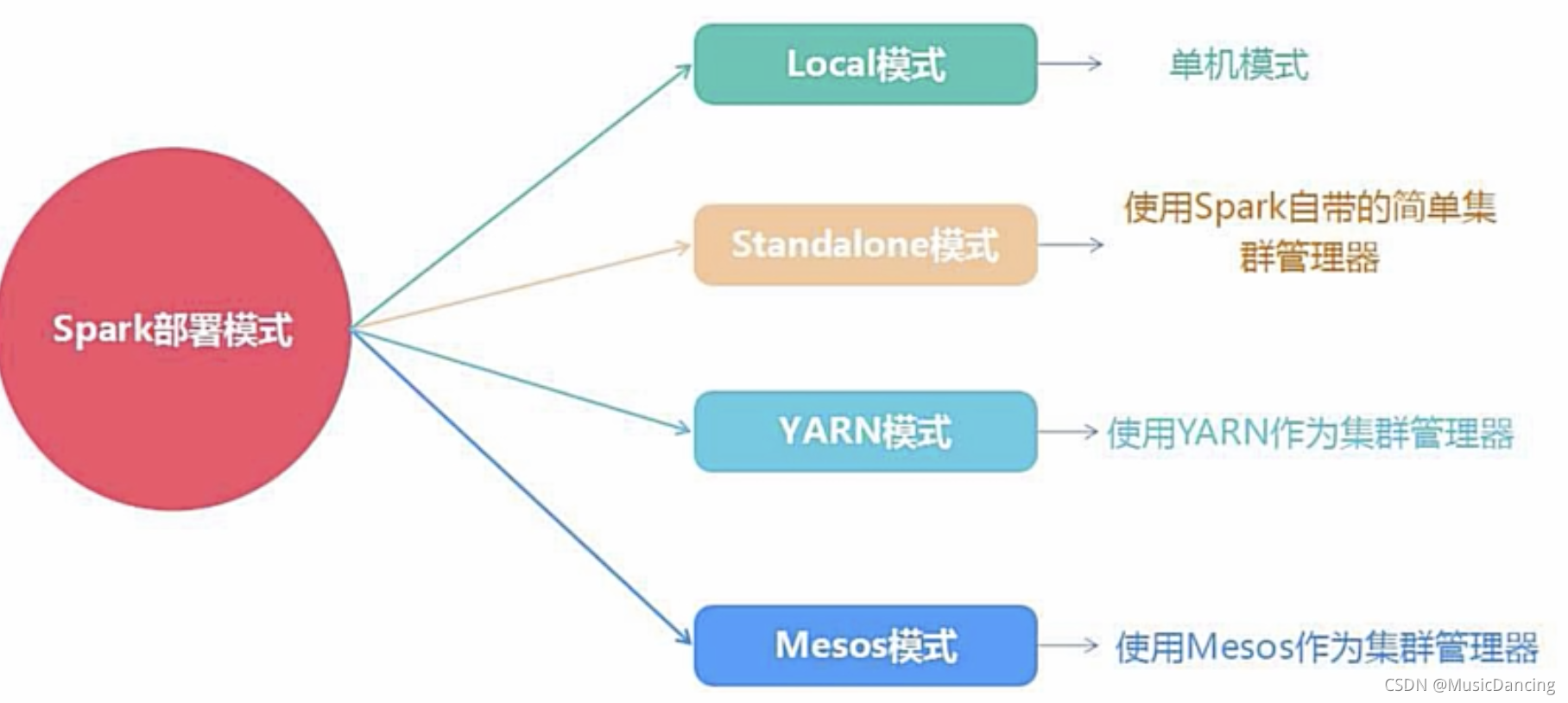
Spark的运行模式取决于传递给SparkContext的Master URL的值,可以有如下选择:
1. local 使用一个Worker线程来本地化运行Spark,非并行。默认模式。
2. local[*] 使用逻辑CPU个数数量的线程来本地化运行Spark。
3. local[K] 使用K个Worker线程来本地化运行Spark(理想情况下K应该根据运行机器的CPU核数设定)。
4. spark://HOST:PORT 连接到指定的Spark standalone master,默认端口7077。
5. yarn-client 以客户端模式连接Yarn集群,集群位置在HADOOP_CONF_DIR环境变量中。
6. yarn-cluster 以集群模式连接Yarn集群。
7. mesos://HOST:PORT 连接到指定的Mesos集群,默认端口5050。
在Spark中采用本地模式启动Spark Shell命令主要包括以下参数:
--master 表示要连接的master,如local[*]表示使用本地模式,其中*表示需要使用几个CPU Core(启动几个线程)模拟Spark集群;
--jars 用于把相关的jar包添加到CLASSPATH中,多个jar包可使用“,”连接。
比如要采用本地模式,在4个CPU核心上运行spark-shell
cd /usr/local/spark
./bin/spark-shell --master local[4] --jars co 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









