



高并发内存池的逻辑梳理
简介
在高性能服务器编程中,频繁的内存分配与释放往往成为系统性能瓶颈,尤其在多线程场景下,传统 malloc/free 存在严重的锁竞争和内存碎片问题。为解决这一瓶颈,Google 提出了高效的内存分配器 —— tcmalloc(Thread-Caching Malloc)。
本博客将从原理出发,实现一个仿 tcmalloc 的高并发内存池模型,并逐步拆解以下关键组件:
ThreadCache:线程私有的对象缓存池,实现无锁内存复用。
CentralCache:中央缓冲区,协调线程之间的内存共享。
PageCache:页级内存管理器,从系统批量申请内存,并进行分割与回收。
SpanList/Freelist:维护固定大小对象的空闲链表,实现快速分配与回收。
对象分级(Size Class:对小对象按大小分层管理,提升缓存命中率,降低碎片。
通过模拟 tcmalloc 的核心架构,我们将实现一个支持高并发、低碎片、高吞吐的内存分配器,助力你深入理解内存管理底层机制,为打造高性能 C++ 系统奠定基础。
引入:
malloc/free 的性能瓶颈
频繁的系统调用
每次调用 malloc 或 free 时,底层会涉及到系统的内存管理,特别是操作系统的内存分配机制(如 brk、mmap)。这会涉及到内核态和用户态的切换,造成额外的性能开销。
锁机制
在多线程环境中,malloc 和 free 需要通过加锁来确保线程安全,防止多个线程同时访问堆内存分配器。这种锁机制通常采用全局锁(如互斥锁)。
内碎片和外碎片问题
在 C++ 中,内存分配通常依赖操作系统提供的 malloc/free接口。然而在频繁的内存申请与释放中,我们很容易遇到两个经典问题:内碎片(Internal Fragmentation) 和 外碎片(External Fragmentation)。
内碎片:当我们申请的内存小于分配器实际分配的大小时,未被使用的部分就形成了内碎片。例如申请 10 字节却分配了 16 字节,剩下的 6 字节就被浪费了。
解决方案:按需切块 + 精细分级 + 内存复用
外碎片:随着内存分配和释放的交错进行,原本连续的大块内存被切割成多个不连续的小块,虽然总体可用内存仍然充足,但由于分散,可能无法满足一次较大的分配请求。
解决方案:大块预分配 + 按类管理 + 动态合并

定长内存池(解决:频繁申请/释放固定大小对象时的性能问题和内存碎片问题)
实现逻辑:

成员变量
1. char* _memory
作用:指向从系统申请的大块内存的起始地址。
原因:为了避免频繁调用 malloc/free,池化内存管理会一次性申请一大块内存。使用 char* 是为了按字节操作内存,方便灵活划分个固定大小的小块。后续从这块大内存中“切出”若干个定长块用于对象构造。
2. size_t _remainBytes
作用:记录 _memory 中剩余可以分配的字节数。
原因:用于判断当前内存块是否还能继续切出对象。若不够,就再次申请新的大内存块(扩容)。提高分配效率,避免浪费。
3. void* _freeList
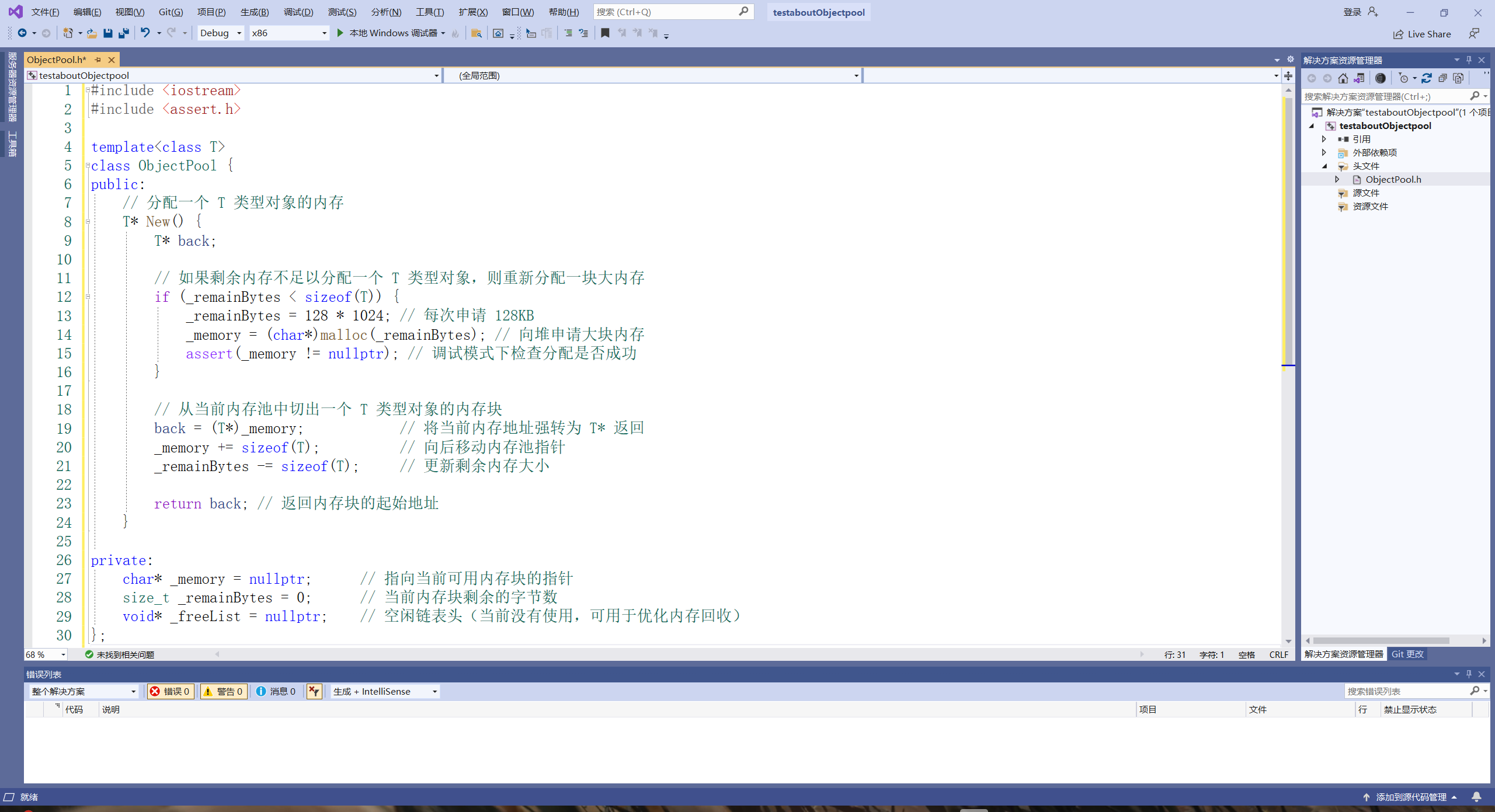
作用:空闲对象链表的头指针,指向可以重复利用的空闲内存块。
原因:每次 Delete 后,把对象插入这个链表,实现内存复用。每次 New 优先从 _freeList 取出空闲块。减少系统调用次数,避免频繁分配/释放带来的开销。
实现
关于Detele:

怎么链接: 我们会想到结构体指针,如果模板类是有结构体指针,那就非常好链接,如果没有结构体指针, 解决思路:用 void** 强制模拟**“结构体指针”的行为;

为什么是 void**?
obj 对应内存的前 sizeof(void) 字节,想要把它当成一个“指针变量”,存入 _freeList(一个指针)
把 obj 强转为 void**,就代表 “我要把 obj 的内存当作一个 void* 类型变量的地址”然后解引用 *,就表示“我要往这个变量里写一个地址”。
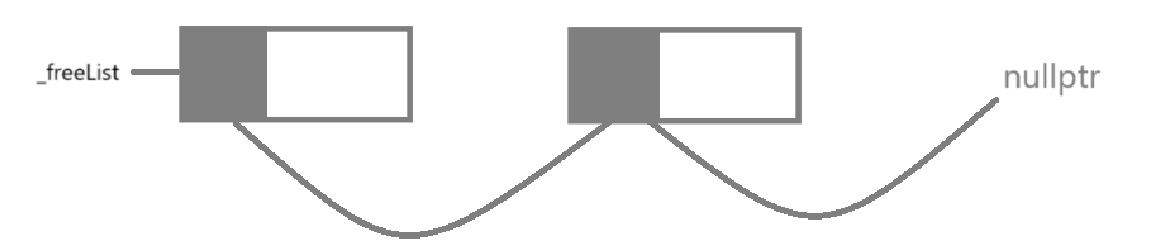
补充New: 加上_freeList 此时的空间可以复用

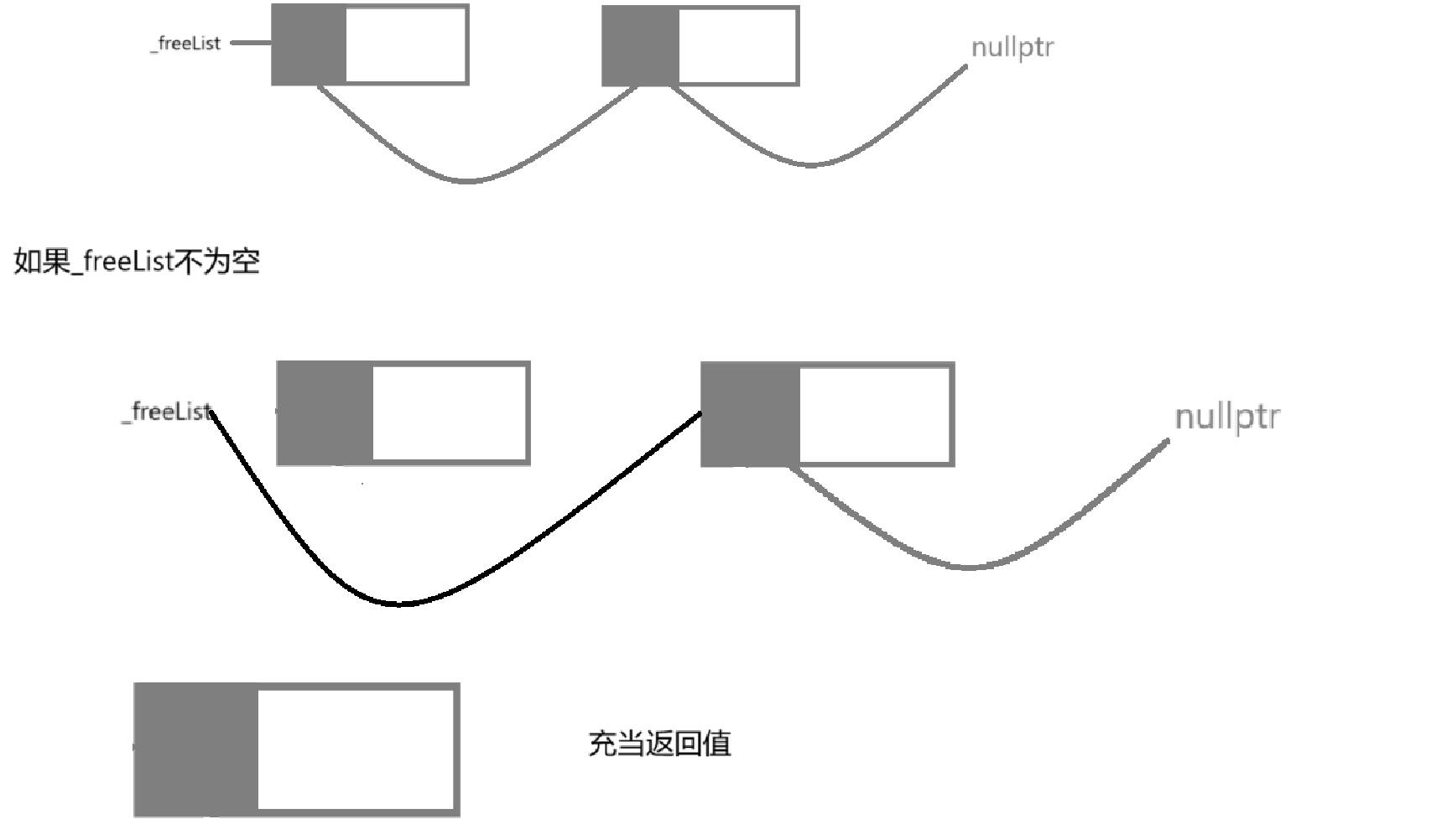
注意事项: 如果 sizeof(T) < sizeof(void*)
T 是 char,sizeof(T) = 1,而 void* 在 64 位系统下通常是 8 个字节,你现在只分了一字节,但你试图写入一个 8 字节的地址,会造成:越界写内存,内存破坏(UB)
解决方案:
✨ 方式一:强制保证内存块大小 >= 指针大小
size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);
✨ 方式二:使用 union 避免这个问题(更安全封装)
union Node {
T data;
Node* next;
};
这样就能让每个节点中同时有空间存 T 和一个 next 指针,避免了裸写内存。
这里采用方式一:
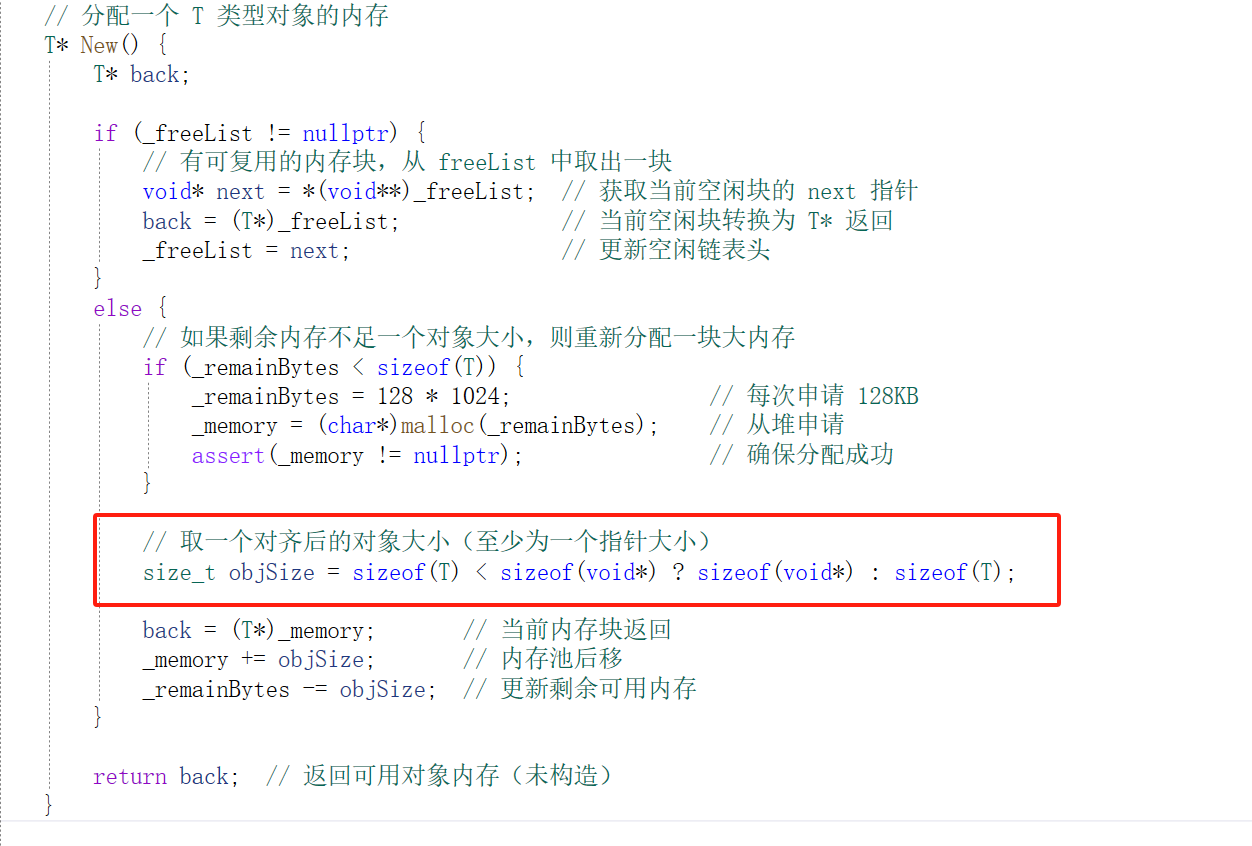
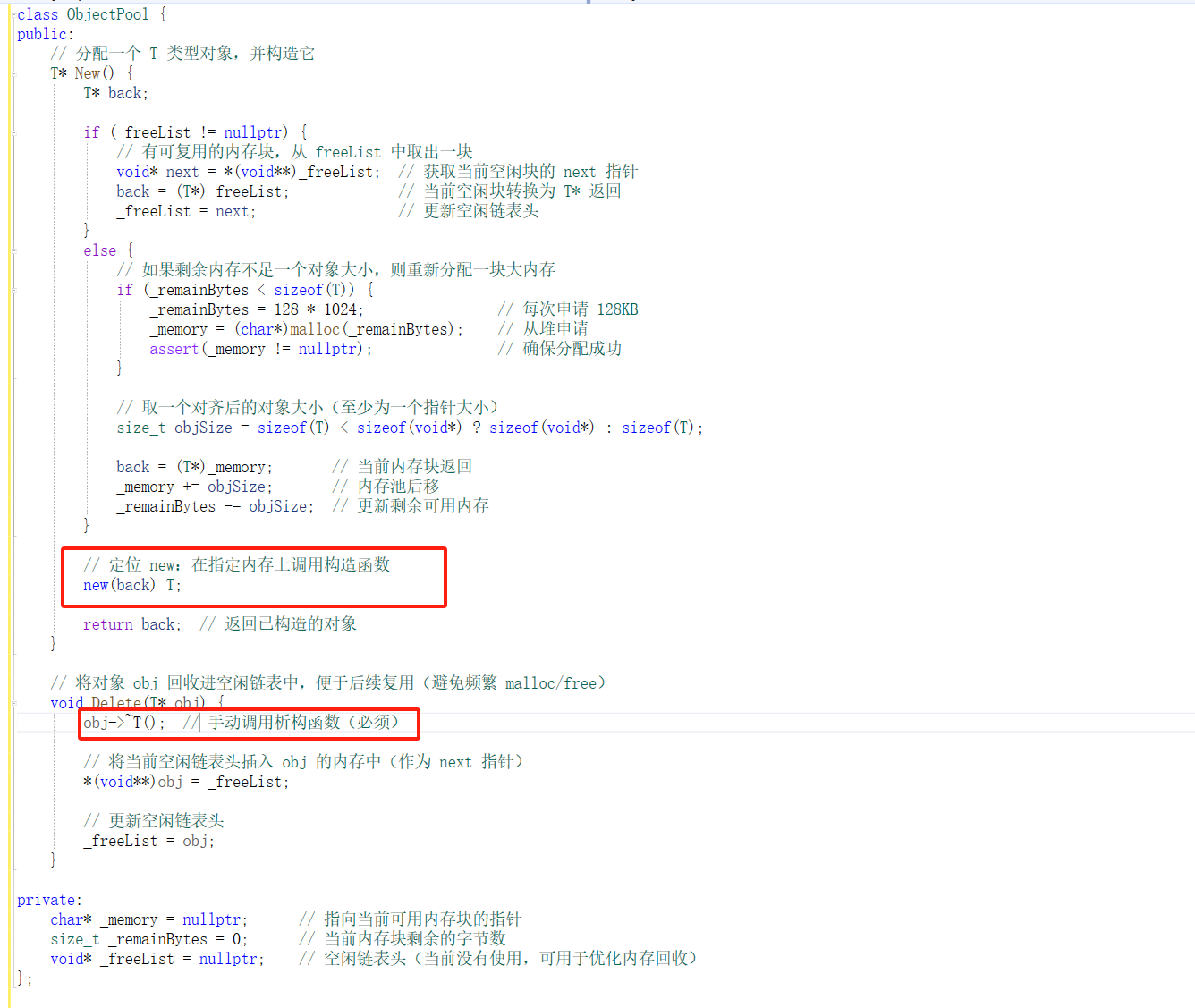
这里我们只是进行了内存分配 内存分配 ≠ 构造对象 这个New不会调用构造函数,比如如果 T 是个有成员变量、构造逻辑的类,它们都没初始化。
补充定位 new(placement new)
定位 new(placement new)语法如下:
new (address) Type(args...);
它的作用是:
在指定的内存地址 address 上调用构造函数,构造一个对象,而不会额外申请内存。
简述整体框架
高性能内存分配器通常采用 三层结构,分别是:
ThreadCache → CentralCache → PageCache → 操作系统
ThreadCache(线程缓存层)
每个线程独立拥有一个 ThreadCache,管理多个 FreeList;
用于分配/释放小对象(如 <= 256KB);
内存复用,避免频繁 malloc/free;
无锁操作,效率极高。
如果本地空了/满了,则与 CentralCache 协调。
CentralCache(中心缓存层)
所有线程共享,负责管理“批量小对象”的分配;
按对象大小分类维护多个 SpanList,每个 Span 是一段连续页(Page)切分的小块;
为 ThreadCache 批量供货或接收回收的内存。
为 ThreadCache 分配一个 Span;
当某个 size class 对应的 SpanList 为空(没有可分配的小对象)时,CentralCache 就会向 PageCache 请求一段新的 Span(即若干页)。
回收过多小对象时合并 Span 并还回 PageCache。
PageCache(页缓存层)
管理系统大块内存(页为单位);
将内存按页划分为 Span 结构(若干连续页);
接收或释放 Span 给操作系统(如 mmap/sbrk)。
ThreadCache
↓ 没有小对象
CentralCache
↓ 没有空闲 Span
PageCache
↓ 没有可用页
系统(mmap/sbrk)
ThreadCache的部分实现
ThreadCache
├── FreeList[0] → 管 8B 对象
├── FreeList[1] → 管 16B 对象
├── FreeList[2] → 管 24B 对象
...
├── FreeList[15] → 管 128B 对象(8B 对齐段结束)
├── FreeList[16] → 管 144B 对象
...
├── FreeList[71] → 管 1024B 对象(16B 对齐段结束)
├── ...
└── FreeList[207] → 管 256KB 对象(最大管理范围)
这里的Freelist 管理的对象和定长内存池的_freelist 差不多,如果1到256kb每个都设计一个_freelist来链接就会很多(256*1024=262144),每个 FreeList 至少占 8 字节(甚至更多),262144 * 8 = 2MB+ 的元数据,仅用于记录自由链表!更别说每个 FreeList 还要实际缓存对象,造成严重的 内存浪费 & 内存碎片,实际应用中对象大小不是连续变化的常见的对象大小是离散的,比如:8B、16B、24B、32B…或 64、128、256、512、1024…所以设计里只要预设几个“常用大小等级”就足够了 。
具体是怎么设计的
整体控制在最多10%左右的内碎片浪费
[1,128] 8 byte 对齐 freelist[0,16)
[129,1024] 16 byte 对齐 freelist[16,72)
[1025,8192] 128 byte 对齐 freelist[72,128)
[8193,65536] 1024 byte 对齐 freelist[128,184)
[65537,262144] 8KB 对齐 freelist[184,208)
为什么这样设计:
对于内存管理器来说,碎片的核心来源是“对齐导致的浪费”。比如你只需要 130 字节,内存池却给你 144 字节(因为是 16B 对齐的),那多出来的 14 字节就是碎片,14占144约为十分子一。对齐越粗,浪费越多,所以小对象用小对齐,大对象用大对齐:
ThreadCache 使用分段对齐 + 指数增长的策略,最大程度减少内碎片,同时用最小代价管理小对象内存,从而实现高性能的内存分配。
现在来设计这个类:
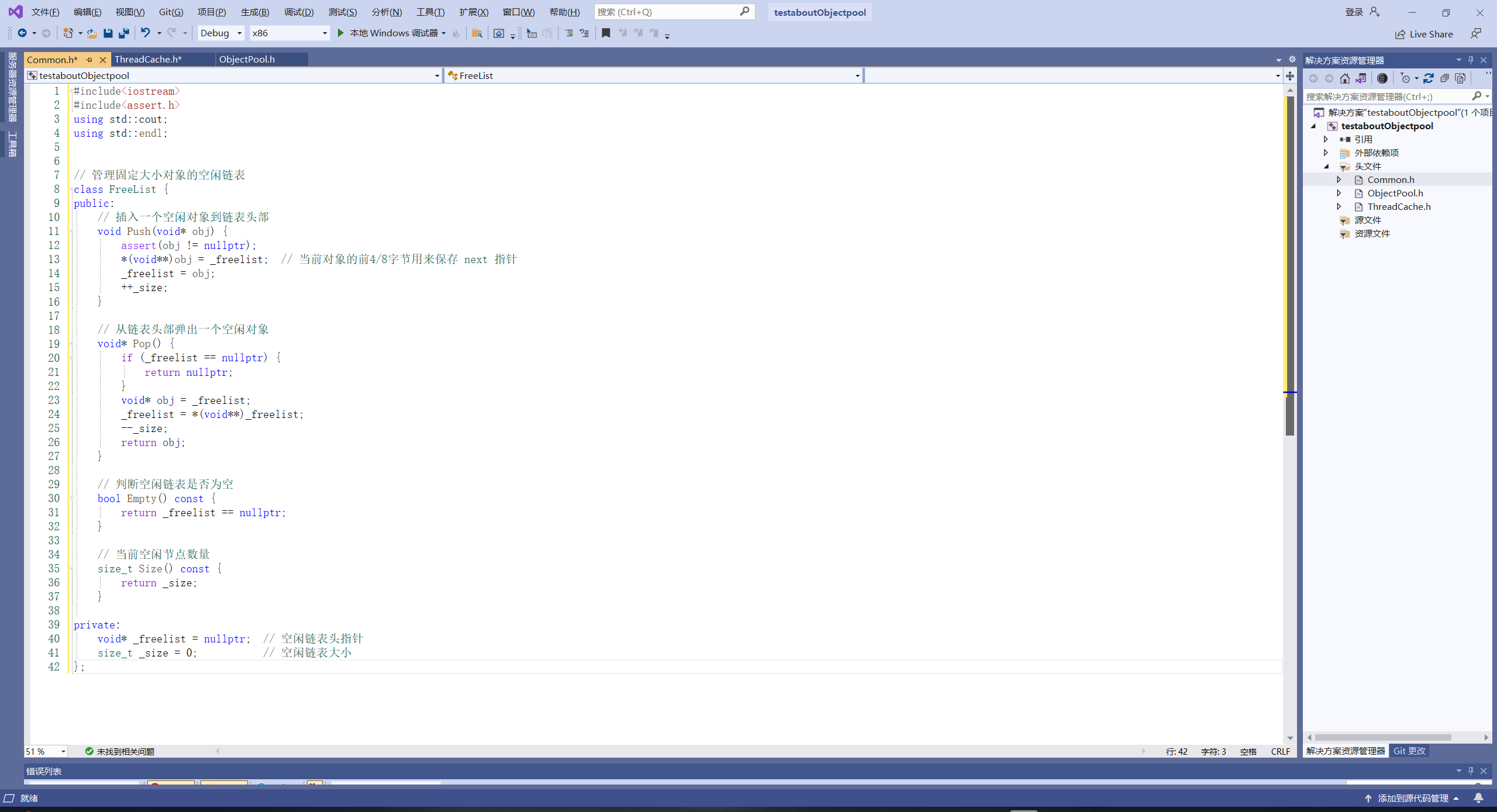
先设计Freelist:
#include<iostream>
#include<assert.h>
using std::cout;
using std::endl;
// 管理固定大小对象的空闲链表
class FreeList {
public:
// 插入一个空闲对象到链表头部
void Push(void* obj) {
assert(obj != nullptr);
*(void**)obj = _freelist; // 当前对象的前4/8字节用来保存 next 指针
_freelist = obj;
++_size;
}
// 从链表头部弹出一个空闲对象
void* Pop() {
if (_freelist == nullptr) {
return nullptr;
}
void* obj = _freelist;
_freelist = *(void**)_freelist;
--_size;
return obj;
}
// 判断空闲链表是否为空
bool Empty() const {
return _freelist == nullptr;
}
// 当前空闲节点数量
size_t Size() const {
return _size;
}
private:
void* _freelist = nullptr; // 空闲链表头指针
size_t _size = 0; // 空闲链表大小
};
设计TreadCache:
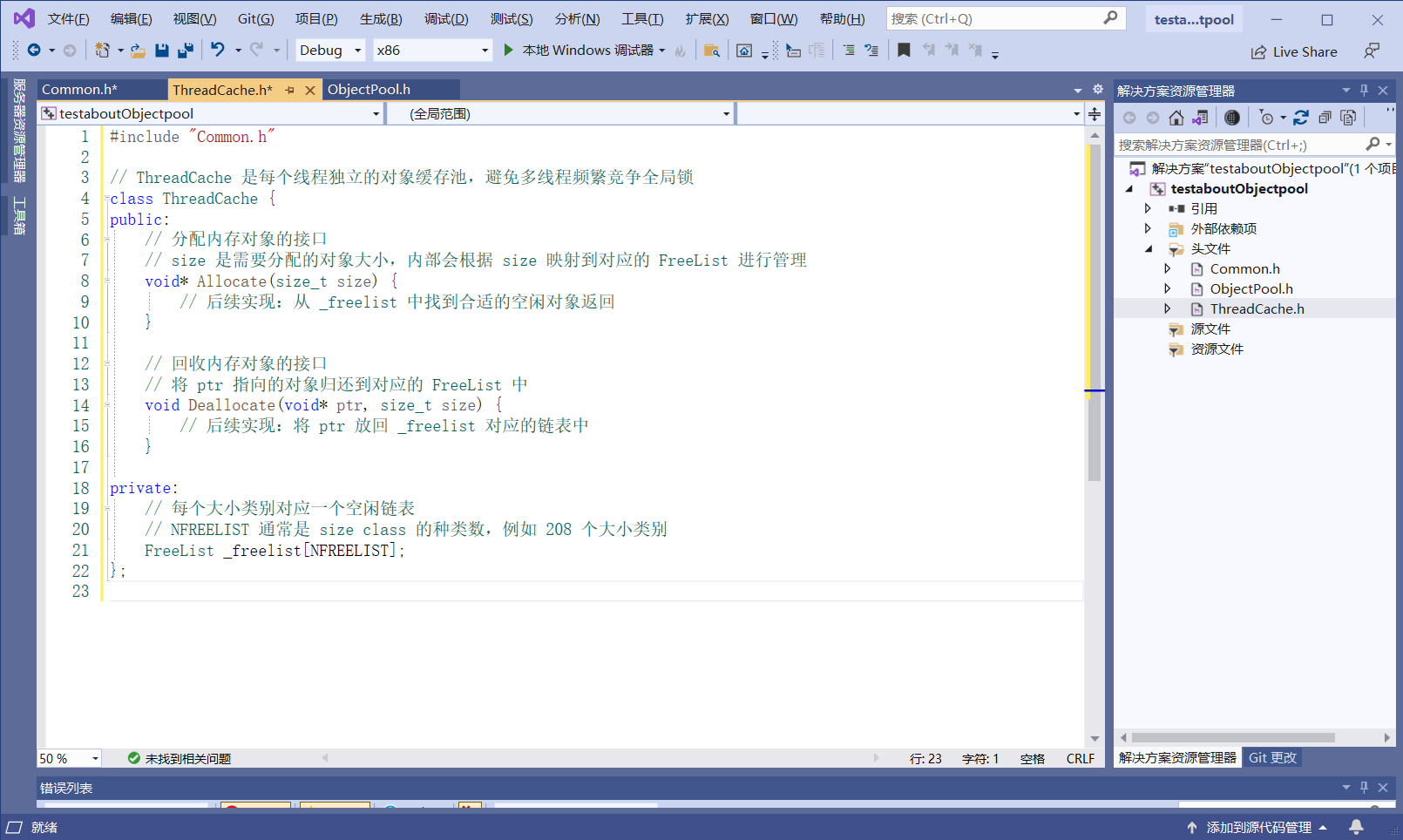
设计部分组件:
1.最大对齐字节数:

2.FreeList的下标计算:

把这两个函数写成静态成员函数
实现ThreadCache函数功能:
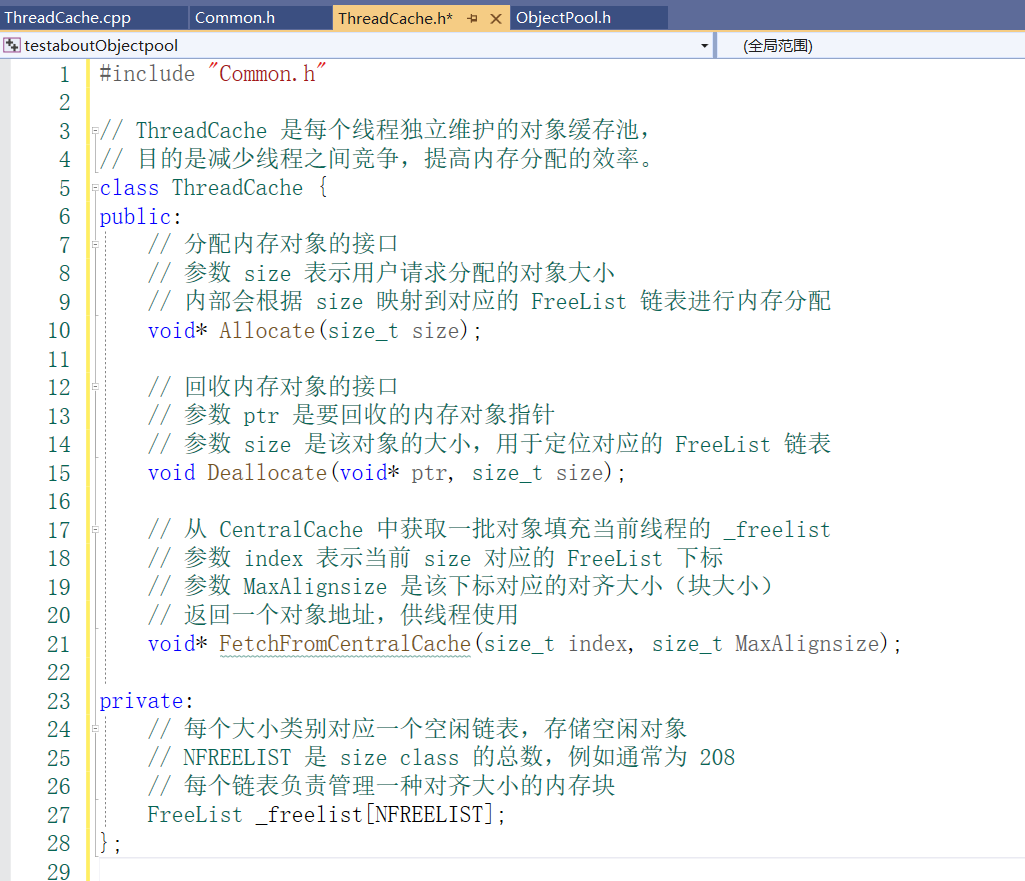
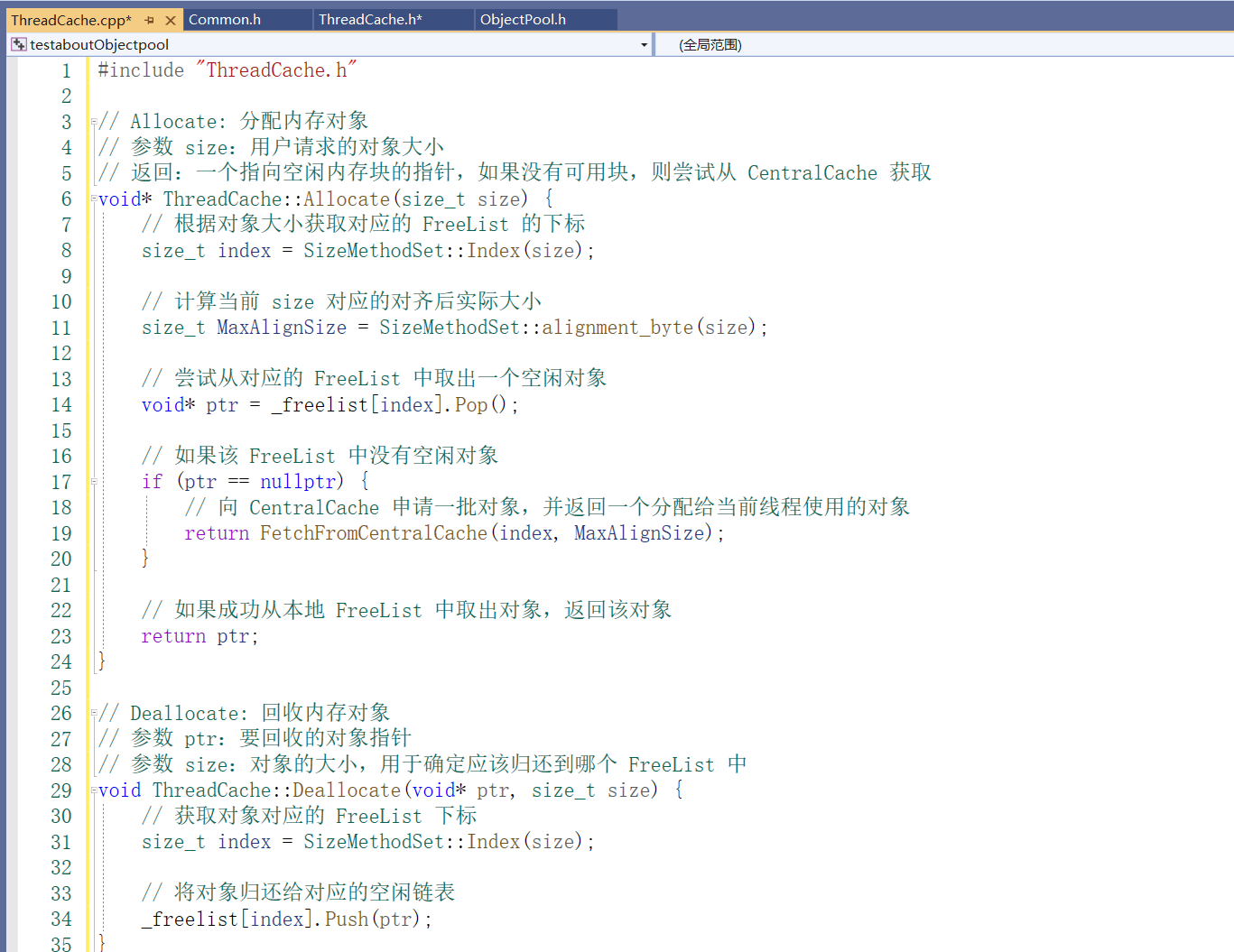
每个线程独立拥有一个 ThreadCache, 线程局部存储(TLS,Thread Local Storage),它确保每个线程都拥有一个独立的 ThreadCache 实例。
-
__declspec(thread) 的作用
__declspec(thread) 是一个 Microsoft 特有的修饰符,它用于指示某个变量是线程局部的,即每个线程都有该变量的独立副本。使用 __declspec(thread) 修饰的变量会被存储在特定的内存区域中,每个线程在运行时会有自己的副本,而不是共享同一个变量。
具体而言,__declspec(thread) 的作用是:
线程独立性:每个线程都有自己的 ThreadCache 指针副本。线程之间不会相互影响,避免了多线程环境下的共享数据竞争问题。
内存优化:线程局部存储允许每个线程存储特定的数据,而不需要全局数据同步,从而提高多线程应用程序的效率。 -
static 关键字的作用
static 关键字通常用于声明静态变量,表示该变量的生命周期是全局的,即程序运行期间一直存在,但它的作用范围是限定在当前的源文件或类的内部。在类内部使用 static 声明变量时,它会属于该类本身,而不是某个具体的对象。
对于 __declspec(thread) 修饰的静态变量,每个线程都会有它的独立副本,而不是共享同一个变量。因此,即便它是静态的,__declspec(thread) 会确保每个线程有独立的内存副本。
Central Cache(部分功能实现)
🎯 它的职责包括:
给 ThreadCache 批量提供小块内存。
回收 ThreadCache 多余的小块内存。
从 PageCache 获取大块页并拆分成小块(小对象)。
把不再使用的小块所在的 Span 还给 PageCache。
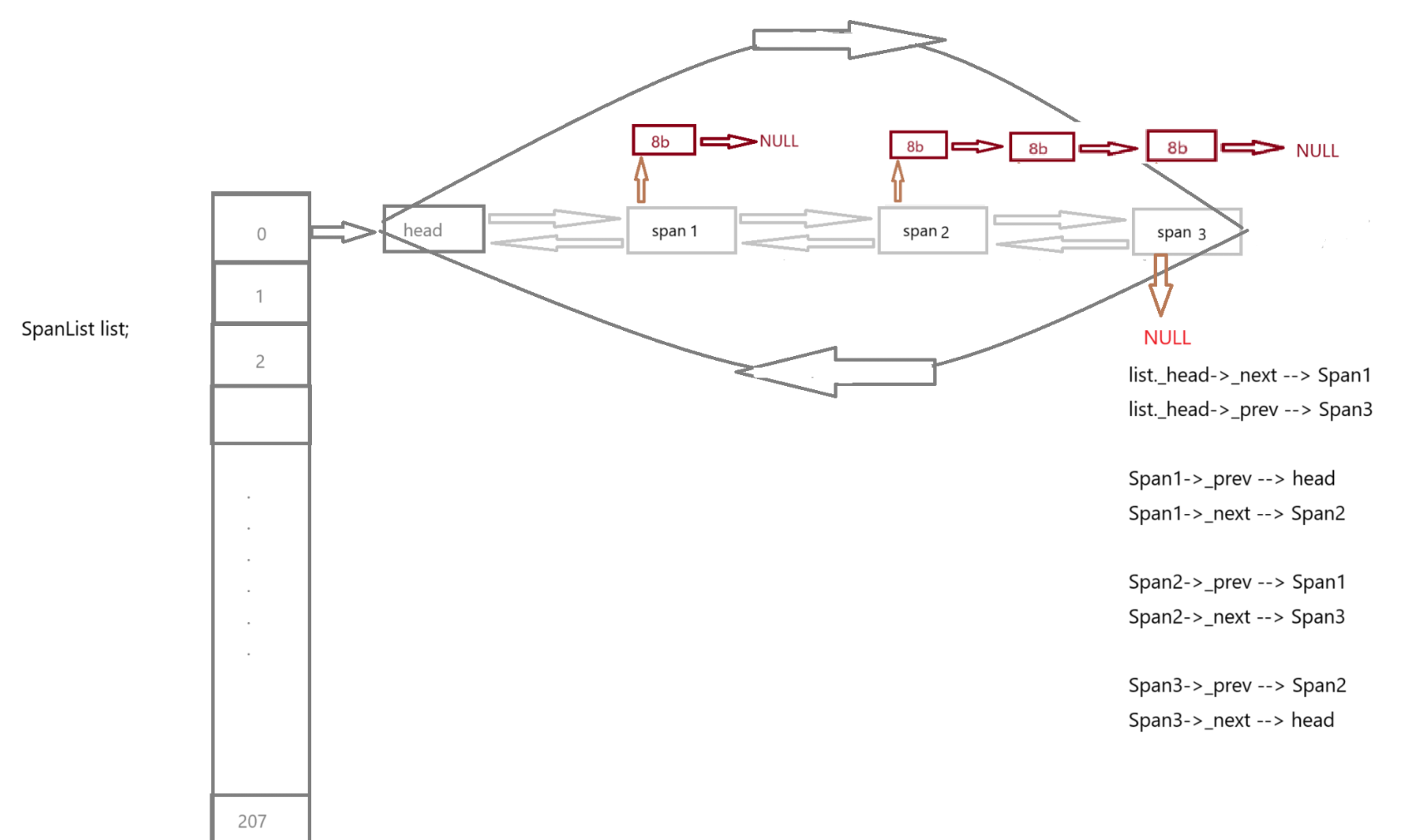
设计span:
Span 是内存分配器中一个管理连续页(Page)的结构,它将页划分成多个小块,对应某个大小类(size class)的内存需求。
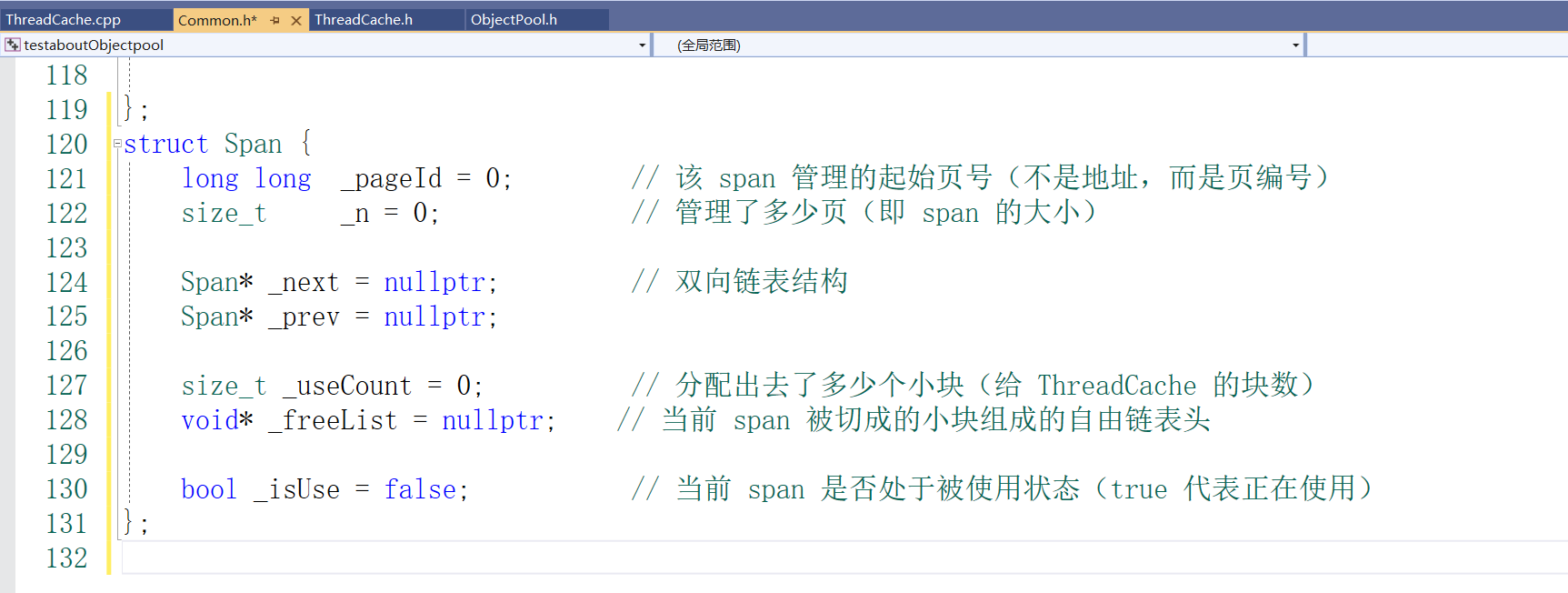
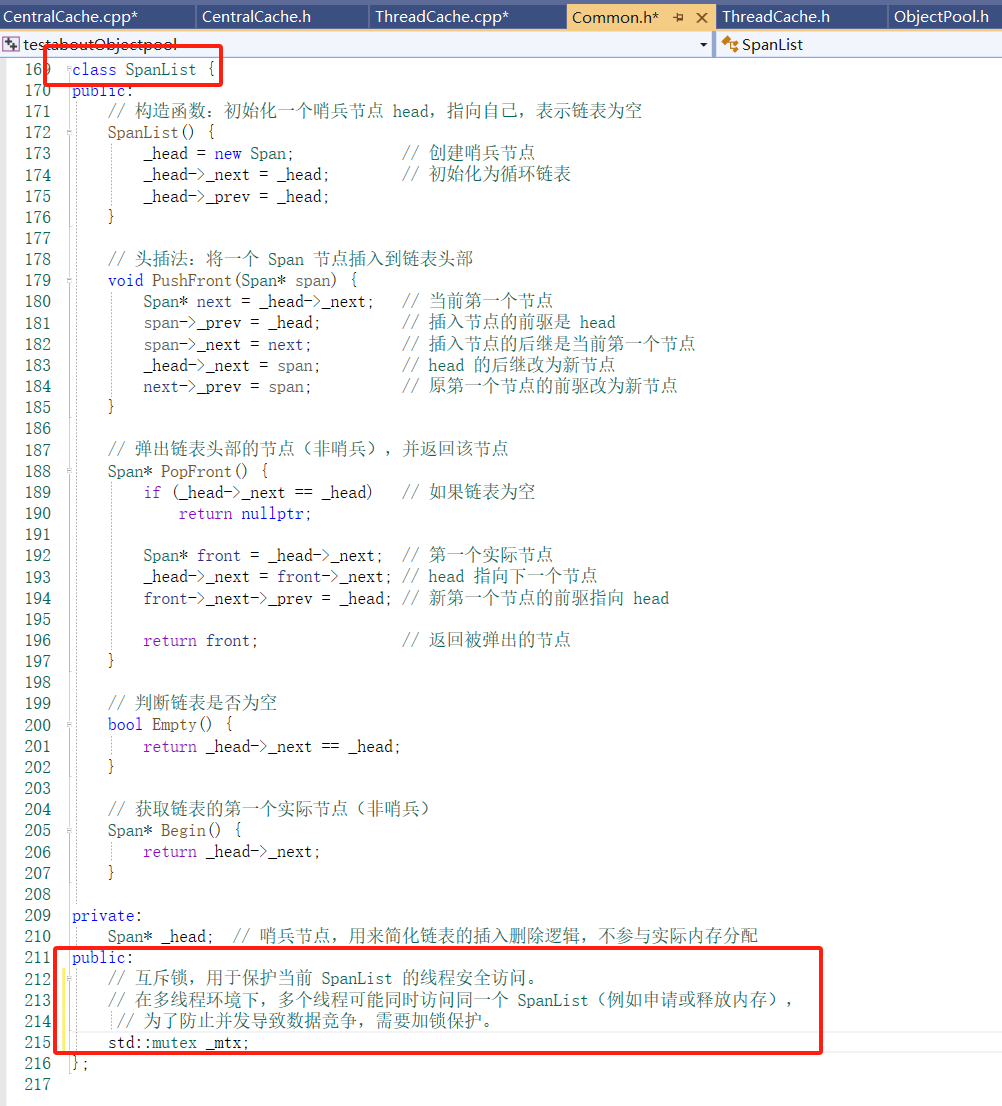
设计SpanList:
SpanList 是用来管理一类大小的多个 Span 的双向链表结构。
每个 SpanList 管理的是一类特定大小(如 4B、8B、16B、32B …)的内存块。
它内部维护一个 带头结点的双向循环链表,每个节点是一个 Span*。
存储位置在 CentralCache::_spanLists[NFREELIST] 中。

设计CentralCache:
管理多个大小类的内存块,每个大小类由一个 SpanList 维护。
维护多个 Span 的双向链表,Span 中的页被切成固定大小的小块,供 ThreadCache 批量申请。
如果 SpanList 中没有空闲块,就从 PageCache 获取页构建新的 Span。
回收使用完的 Span,若空闲则合并还给 PageCache。
补充: CentralCache 是所有 ThreadCache 的 中间共享层。所有线程在本地的 ThreadCache 不足时,都会来找CentralCache 分配/回收内存。所以:必须全局唯一,否则每个线程有一个自己的 CentralCache,就失去了共享和集中管理的意义。推荐使用单例模式。
CentralCache 的成员函数的设计:
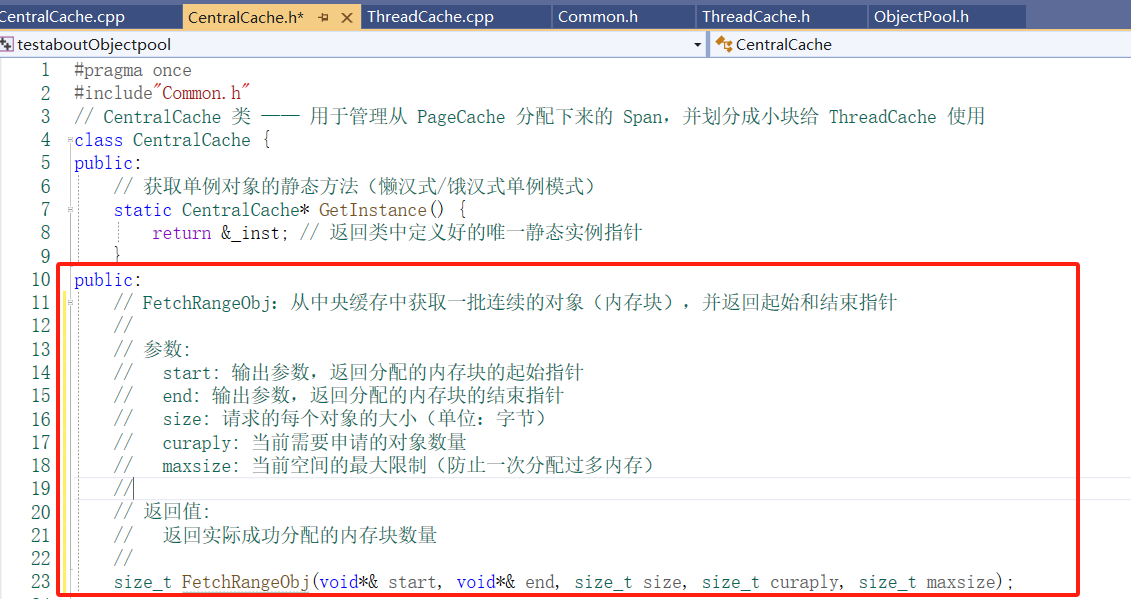
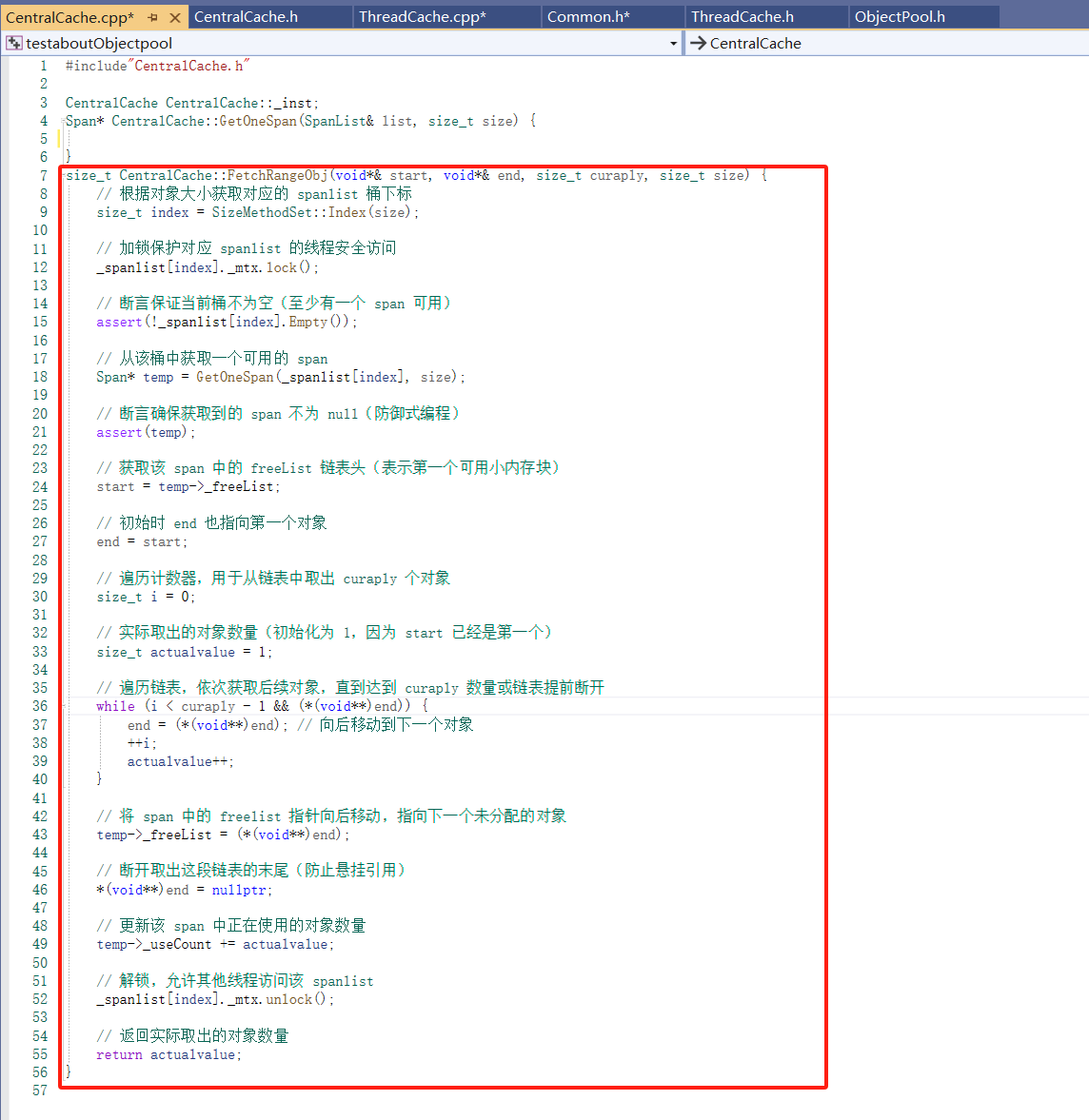
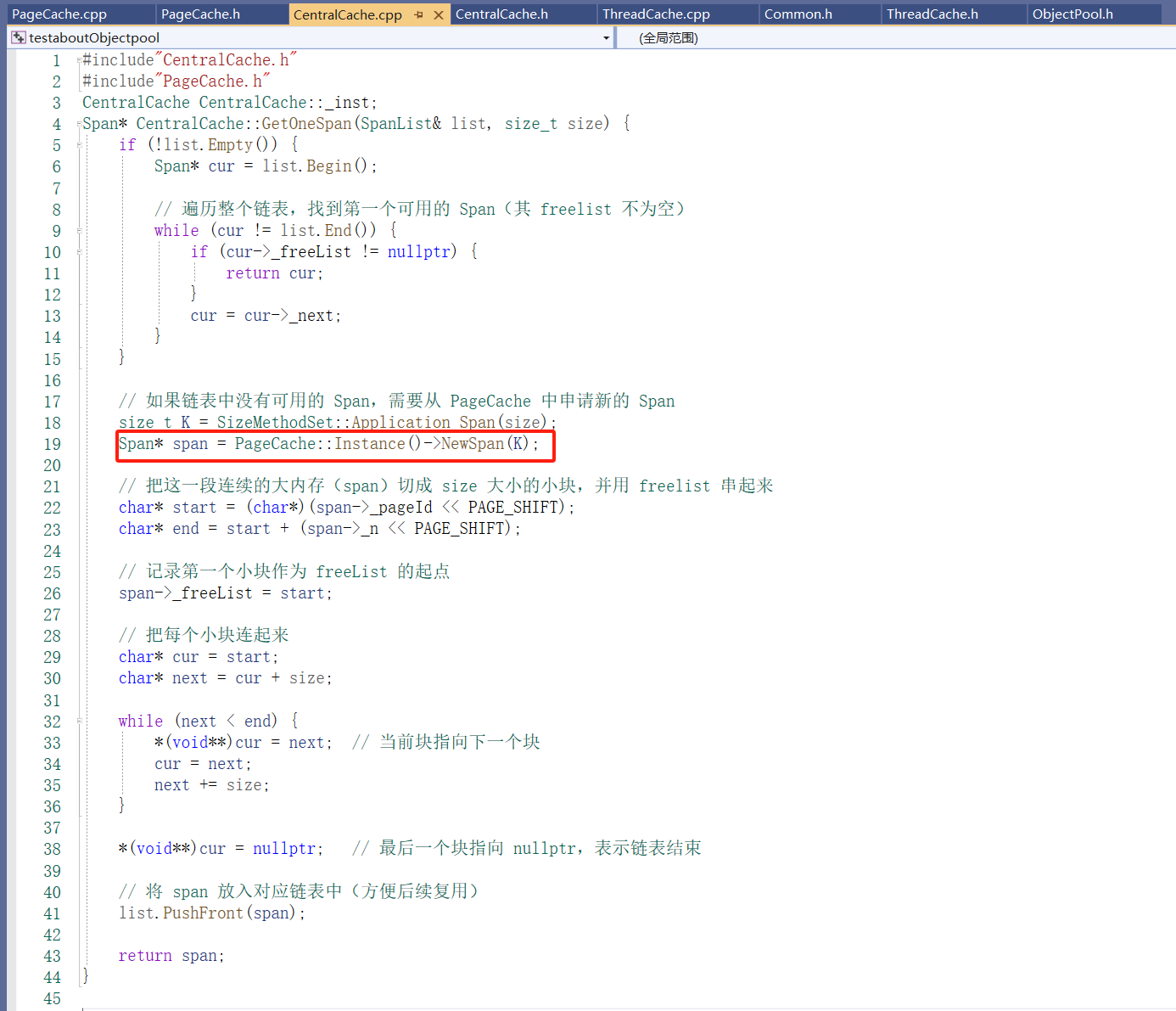
前面在ThreadCache的成员函数没有实现 void* FetchFromCentralCache(size_t index, size_t MaxAlignsize)(当当前线程的 自由链表中没有足够的小块内存(FreeList 空了),就会从 CentralCache 中批量获取小块内存回来,挂到自己的 FreeList 中,用来后续分配。)此时就要设计一个成员函数 FetchRangeObj 用来实现 批量从某个 Span 中切出多个小块对象 给 ThreadCache;
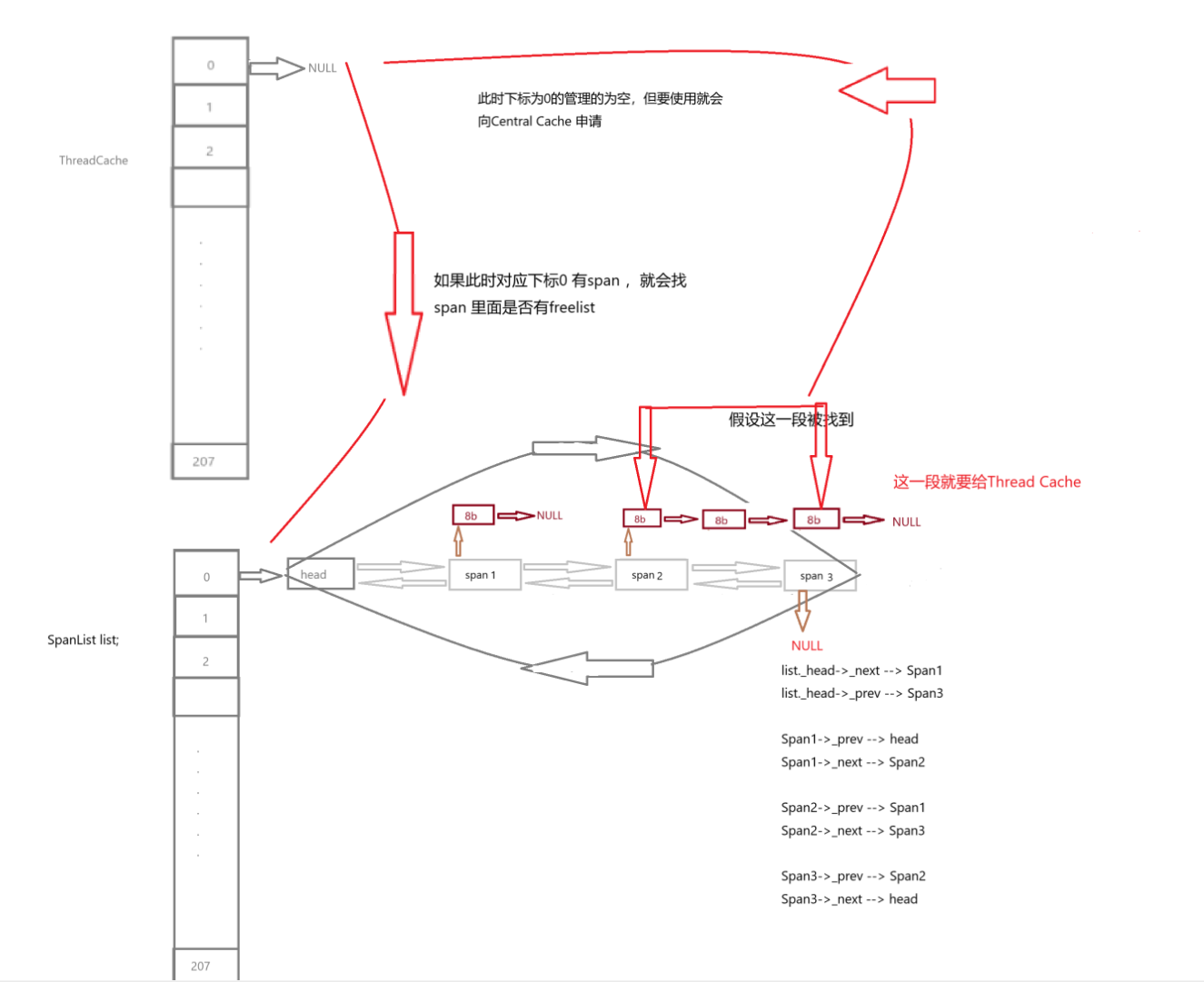
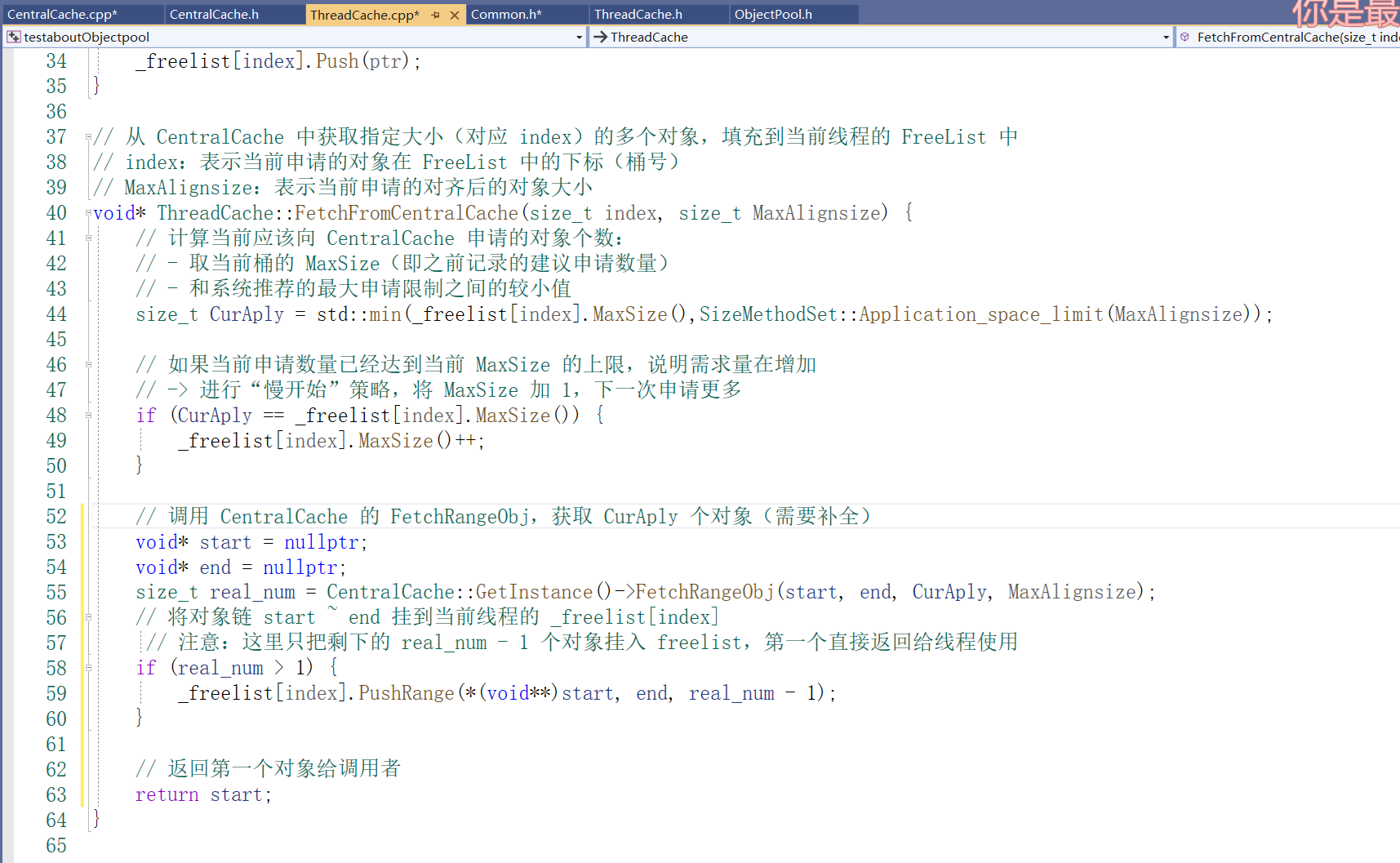
如果 ThreadCache 每次向 CentralCache 申请内存时:
分配太少 → 频繁请求,影响性能。
分配太多 → 用不完,浪费内存(产生碎片)。
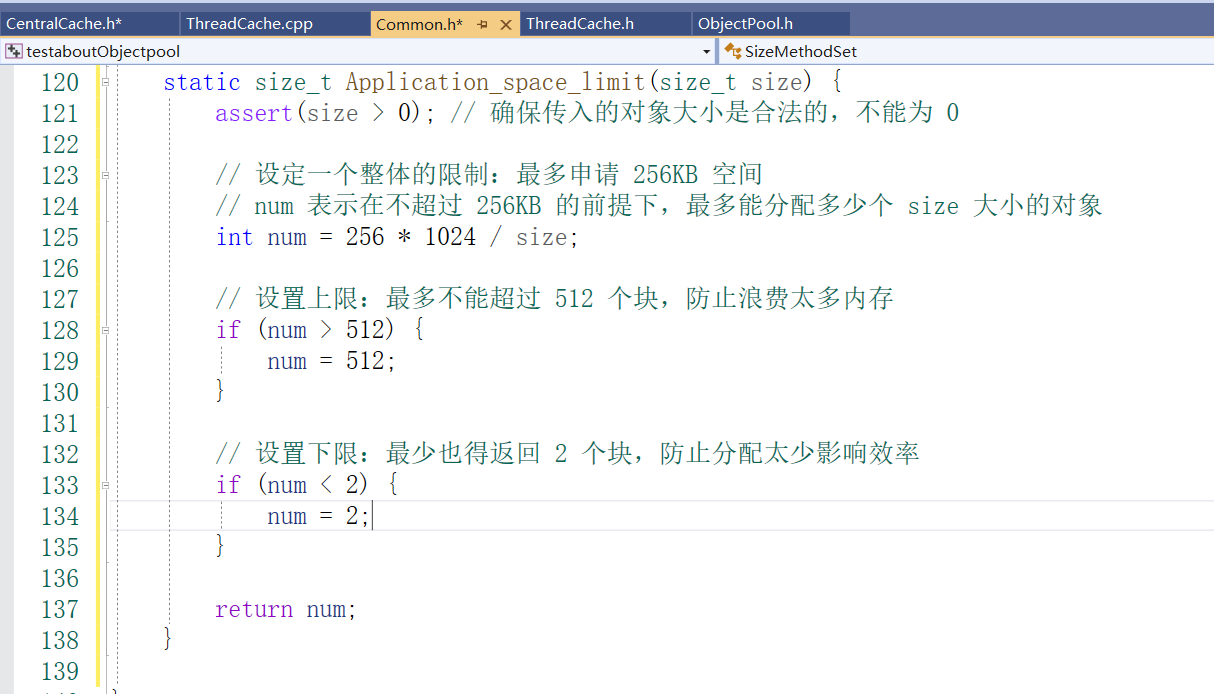
借鉴网络拥塞控制的思想,设计一个渐进式增大请求数量的策略。在Common.h 的SizeMethodSet类添加Application_space_limit:
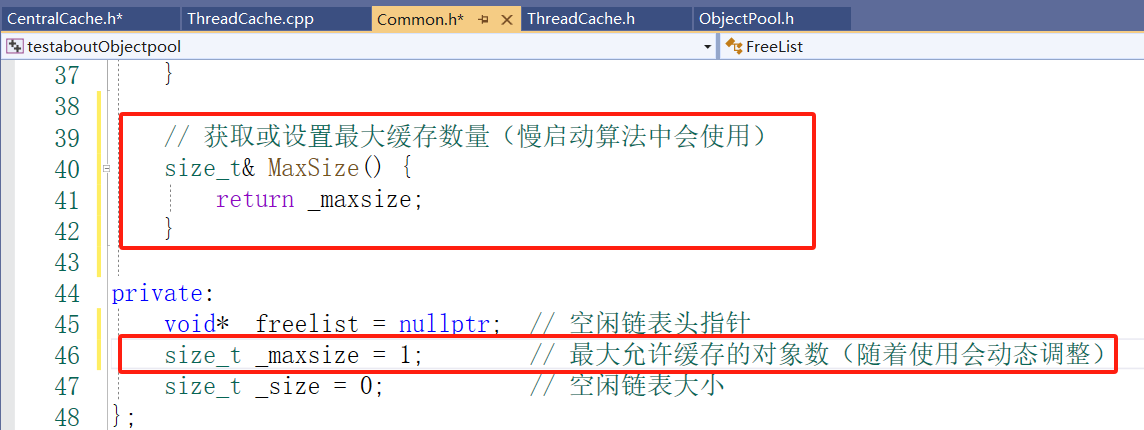
在Freelist 类添加方法MaxSize:
部分实现 ThreadCache的 FetchFromCentralCache:
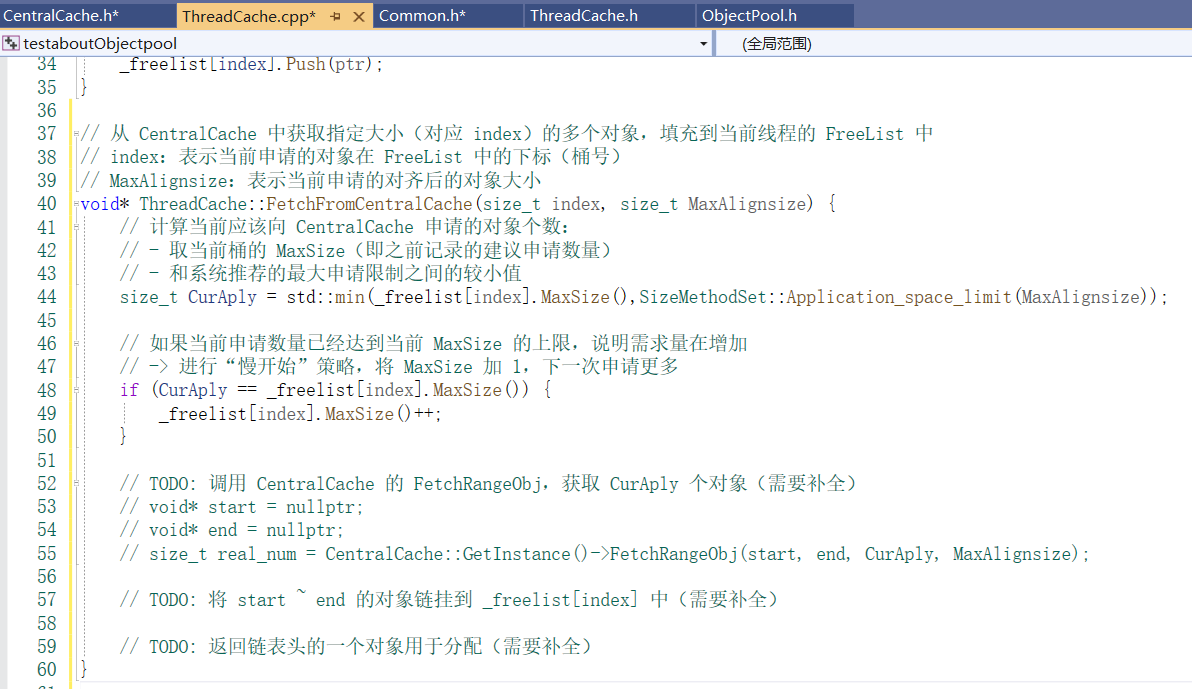
CentralCache的部分功能实现:
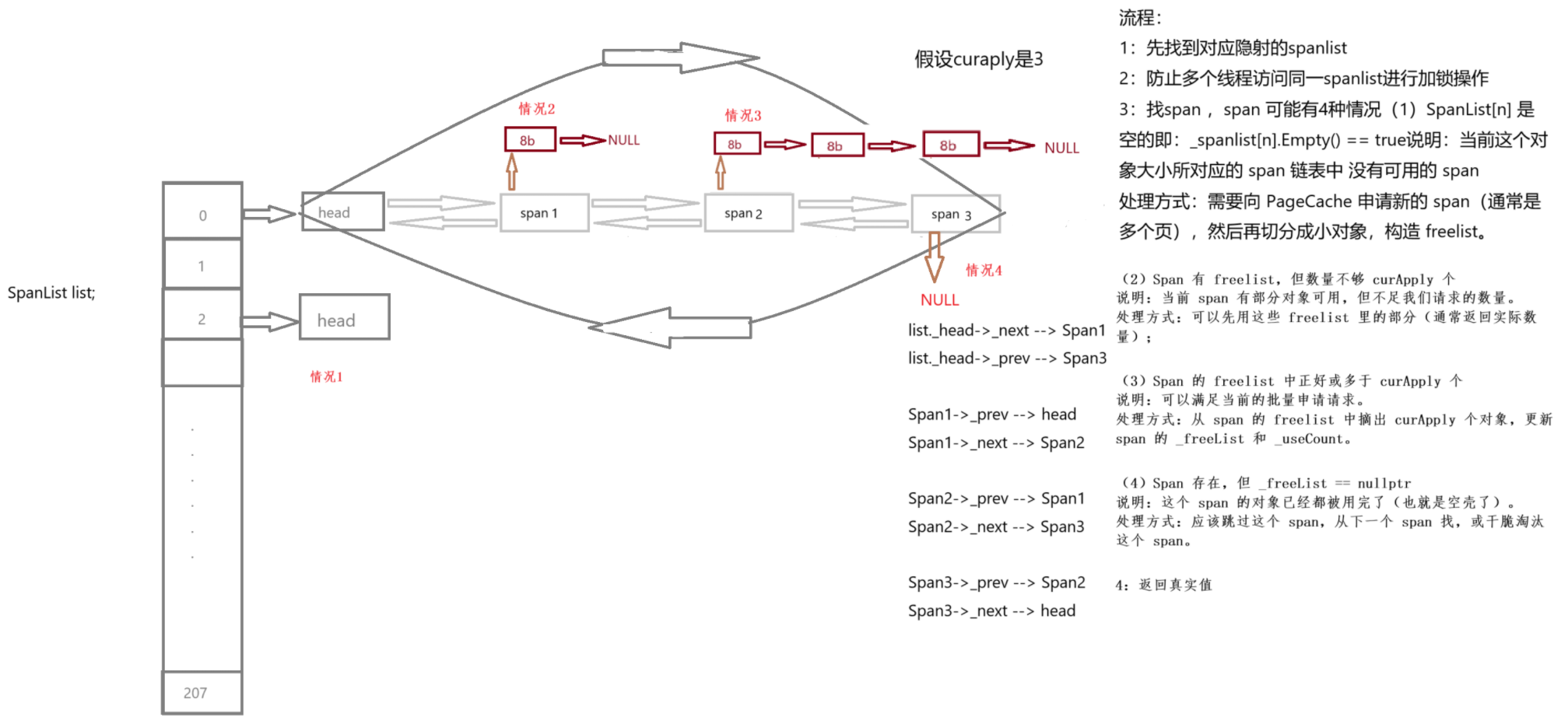
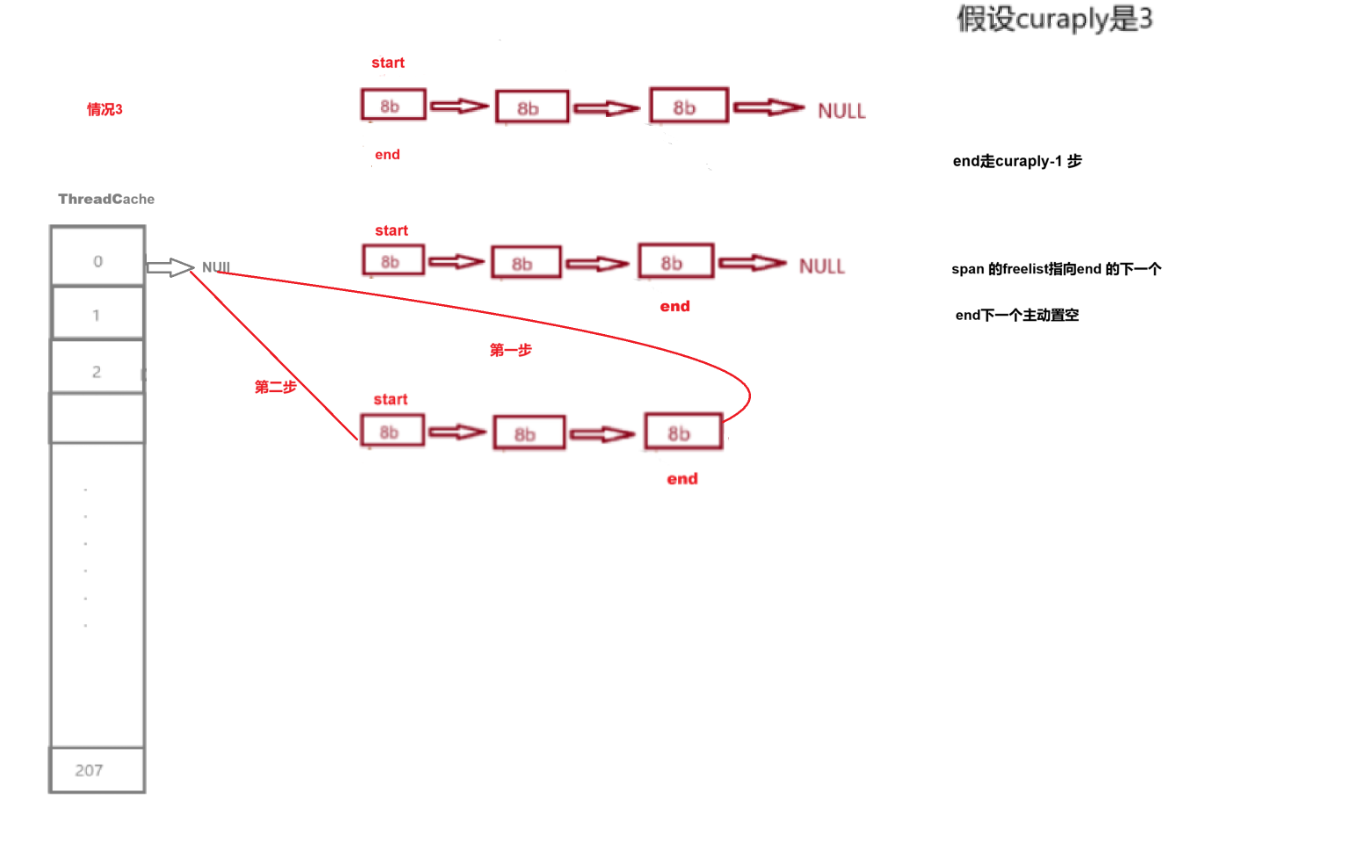
情况二差不多,遇到end的下一位为NULL就停止操作。
为spanlist[index] 加锁:
实现FetchRangeObj:涉及到获取一个有效的span(GetOneSpan)没有实现
实现ThreadCache的FetchFromCentralCache:
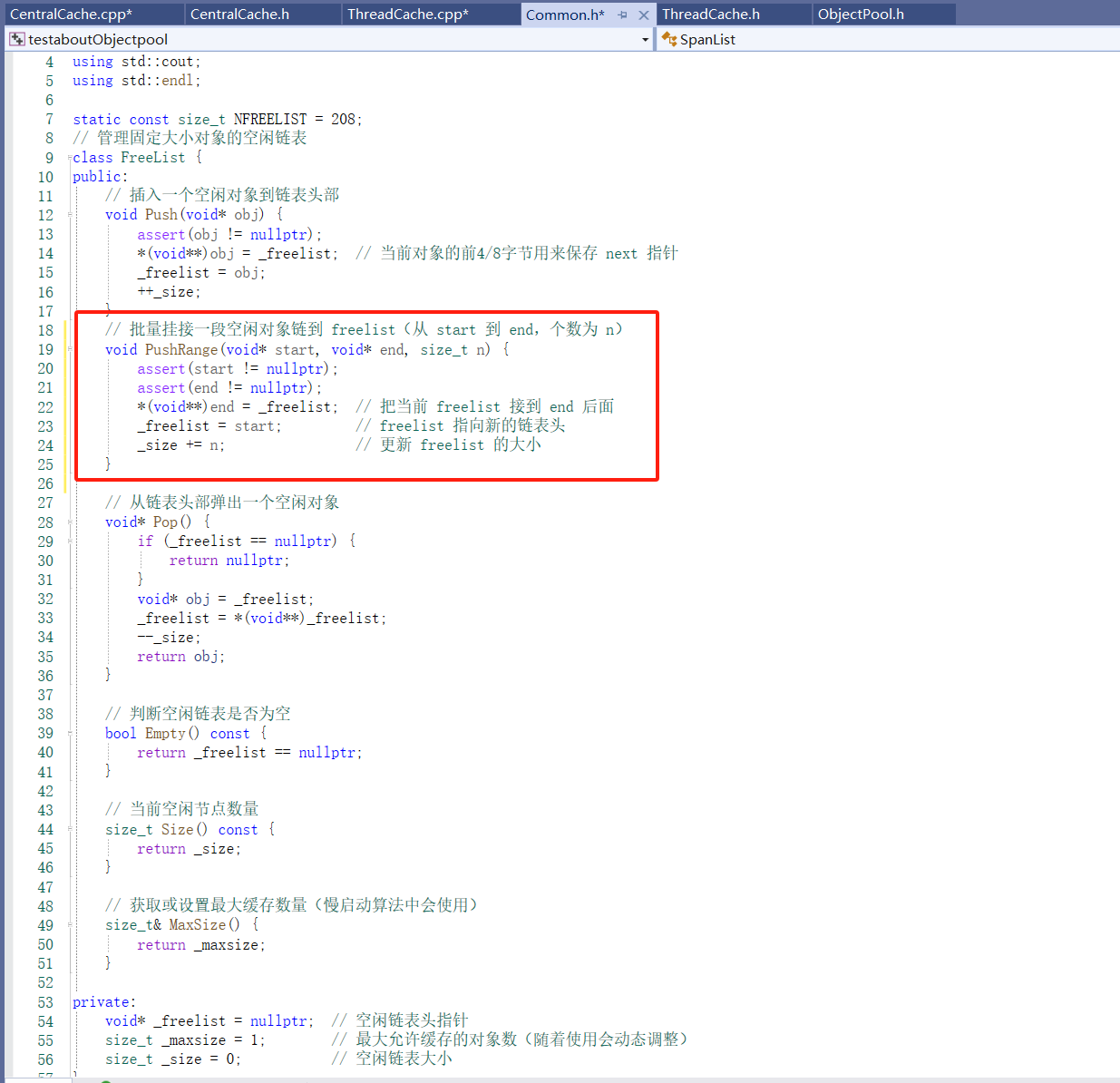
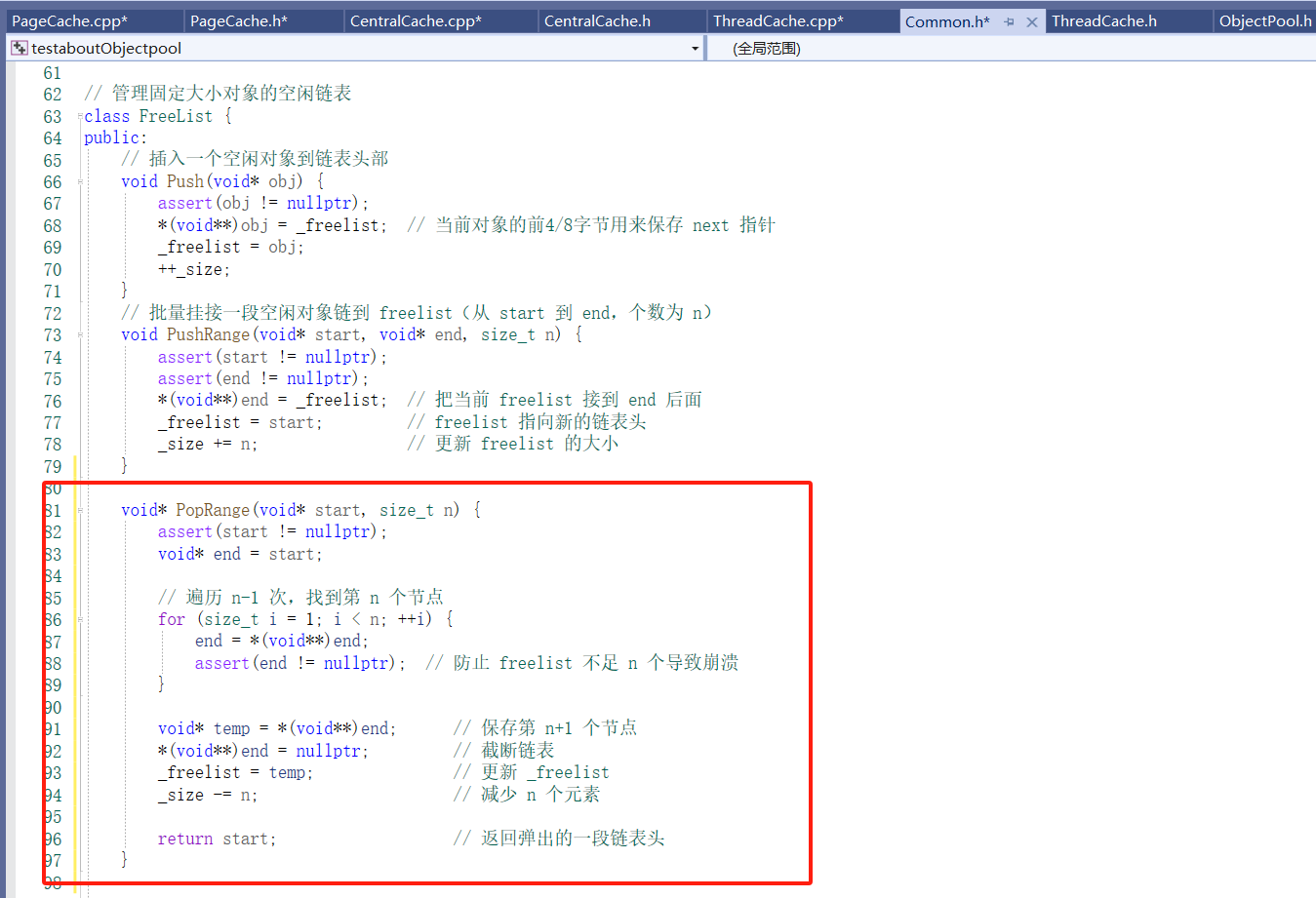
先实现PushRange将对象链 start ~ end 挂到当前线程的 _freelist[index]:
PageCache部分实现:
PageCache 的主要职责:
向操作系统申请内存页(通常通过 mmap / VirtualAlloc 等系统调用)。
以页为单位管理内存块(即 Span,每个 Span 管理连续的页)。
按需将页分配给 CentralCache 使用。
回收并合并空闲 Span,减少碎片化,提高复用率。
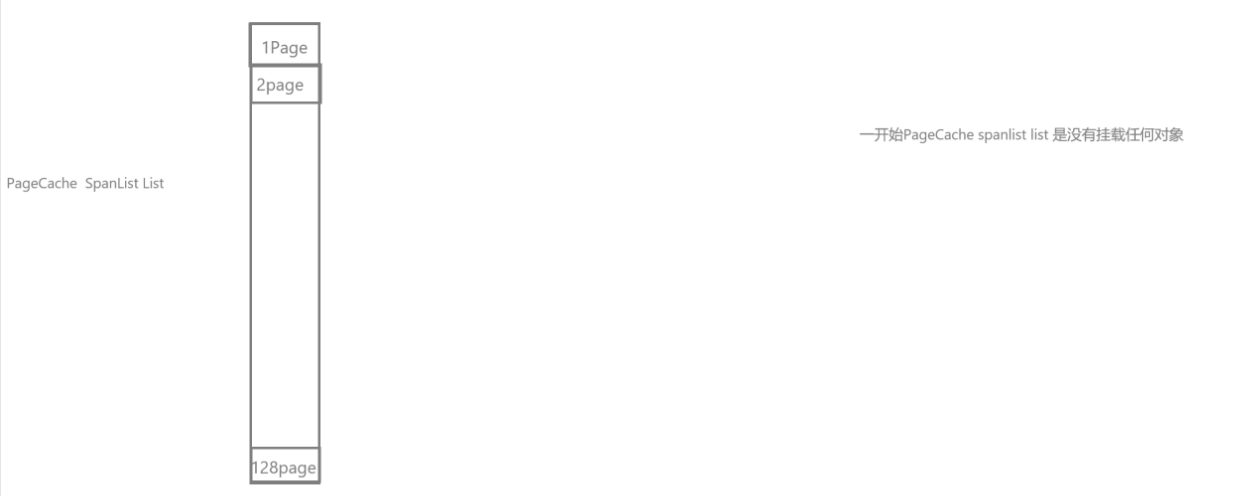
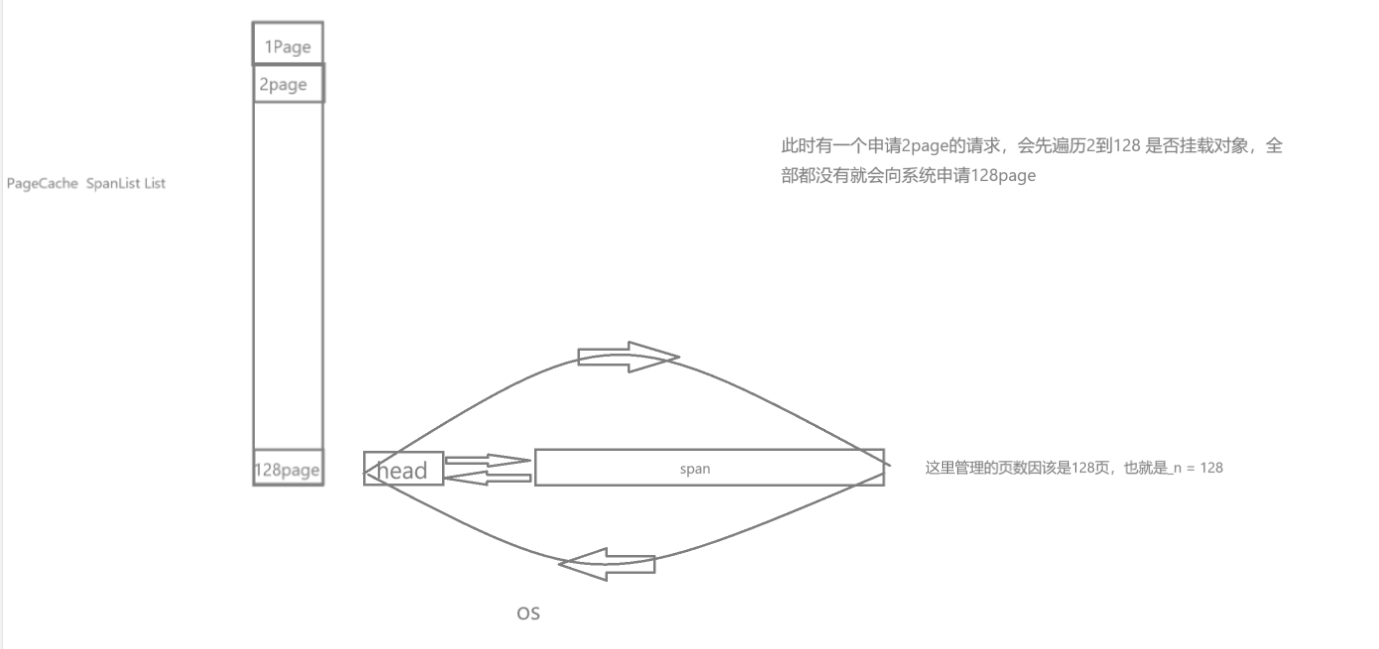
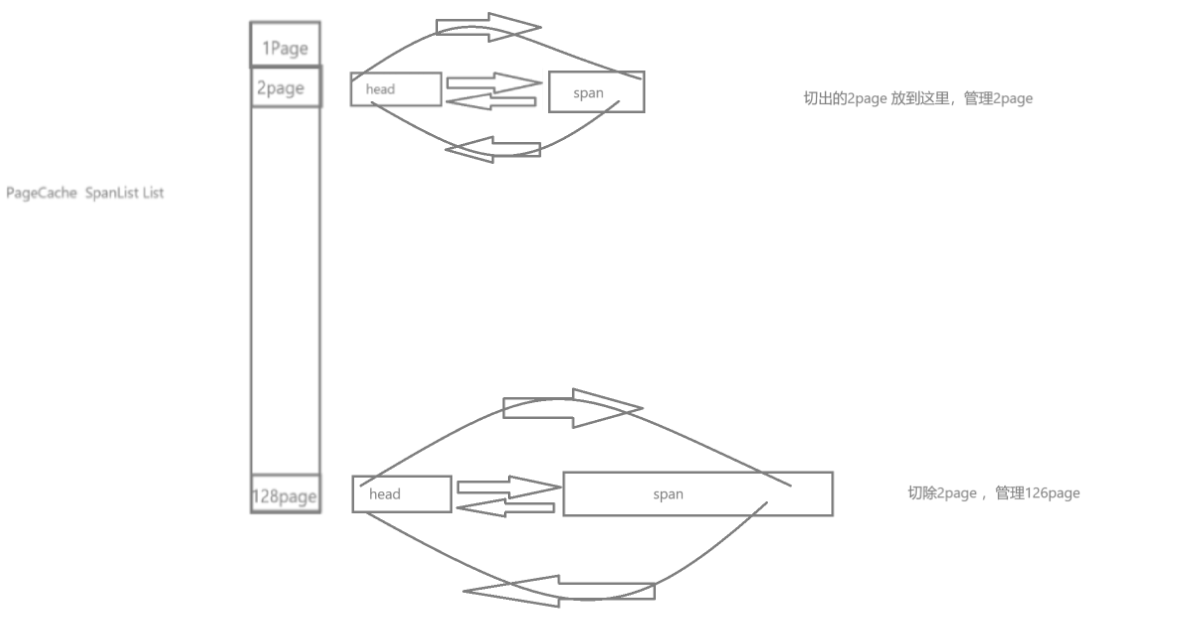
设计成员变量:设计为单例模式,
PageCache 的职责是统一管理所有大块页(以页为单位,比如 8KB、64KB、128KB ……);
所有线程最终都需要向 PageCache 申请和释放页;
如果它不是全局唯一的,每个线程都有一个自己的 PageCache,就完全**失去了“统一协调内存”**的目的。
PageCache设置锁:
_spanlist[n] 是一个链表,里面存放的是 Span*:当你向 PageCache 要 n 页时,它要:找到 _spanlist[n]把里面的某个 Span 弹出来(改链表)当你释放一个 Span 时,它会:把 Span 挂回 _spanlist[n](改链表) 这些操作会修改 _spanlist[n] 链表的结构,所以要加锁的是“整个桶”的读写。
补一句:CentralCache 为什么加在 Span 里?
在 CentralCache 中,Span 是共享的:多个线程可能会从同一个 Span 的 freelist 中分配对象;所以要在 Span 里加锁,保护小对象的 freelist;这个锁只保护 对象链表(小对象),不是链表结构。
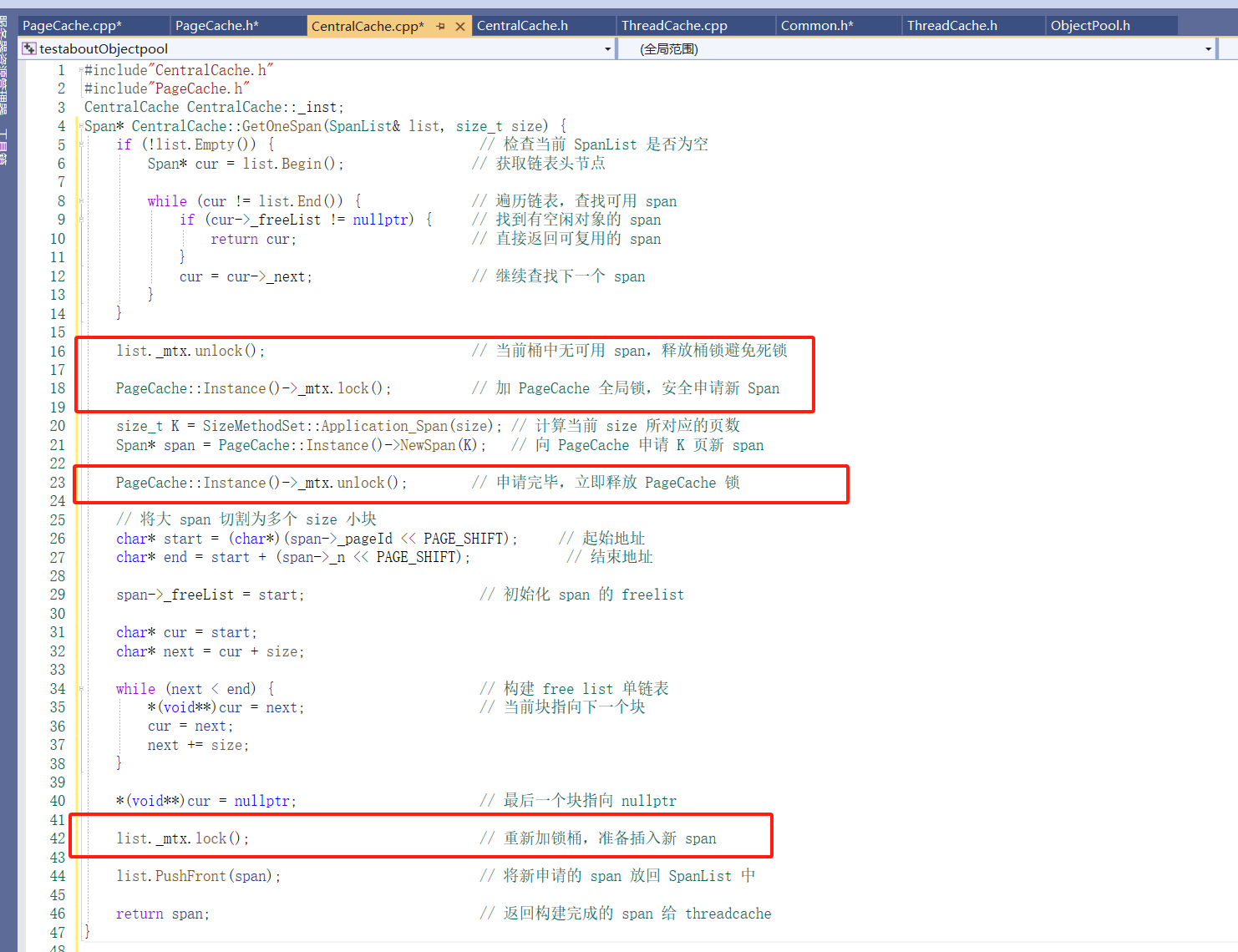
实现CentralCache 的GetOneSpan:
补充实现:SpanList 的部分功能:

补充实现: SizeMethodSet 类实现应该向PageCache 要多少的Span的方法:

向PageCache申请Span的流程:
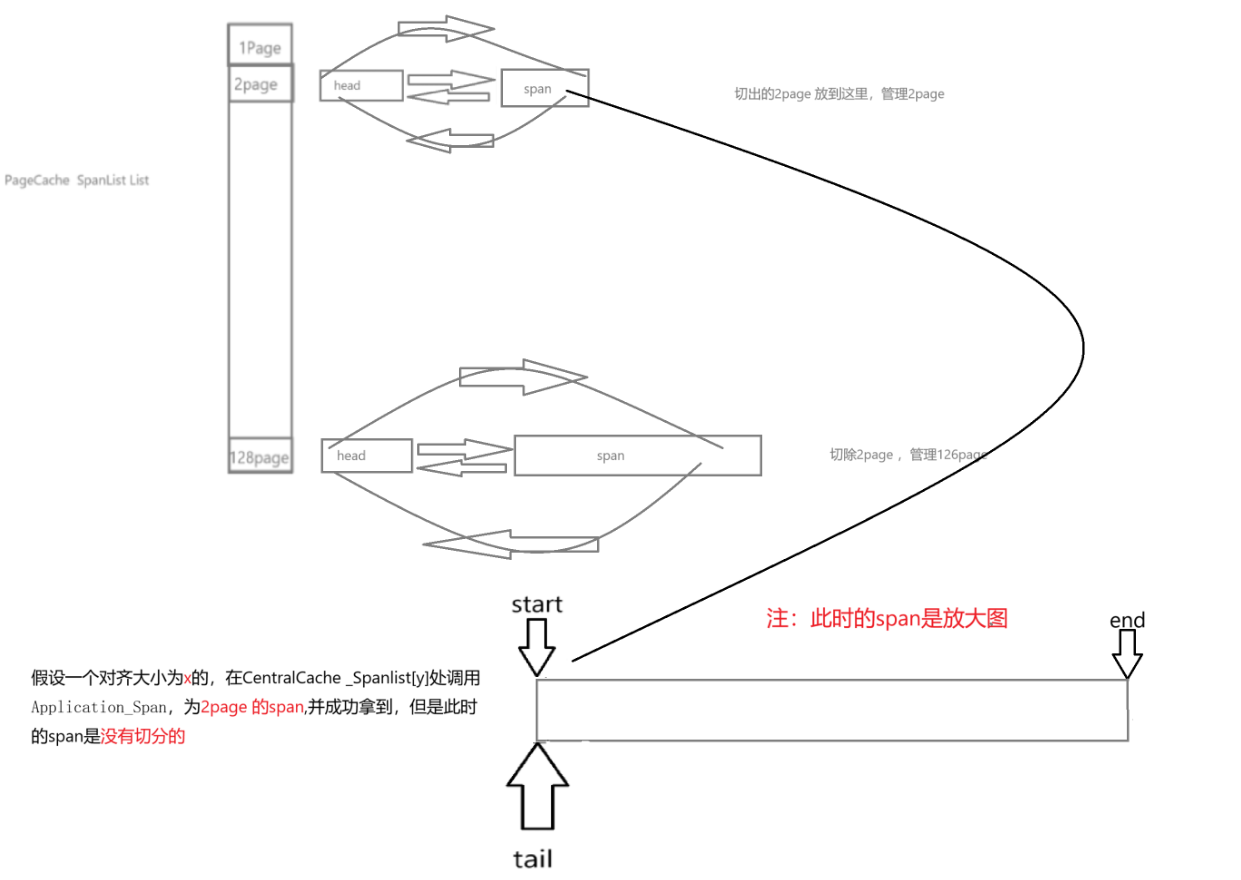
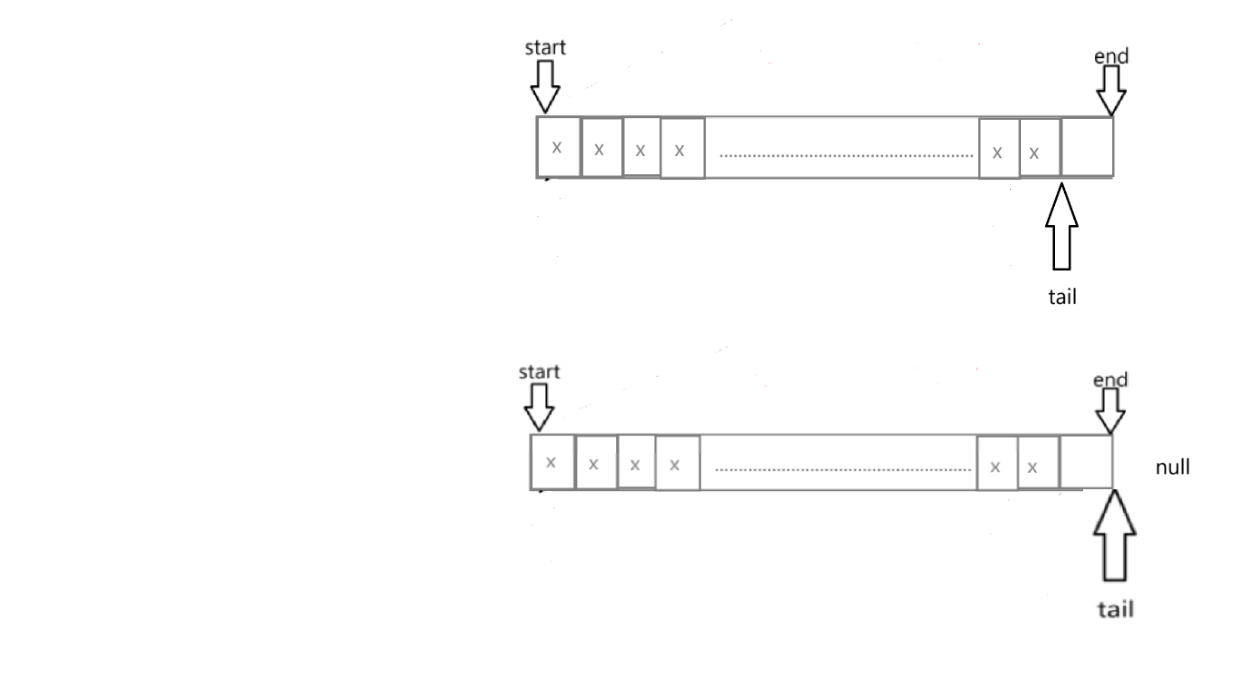
CentralCache 的GetOneSpan的部分实现:没有实现NewSpan;
PageCache成员函数NewSpan的部分实现:
优先尝试从 _spanlist[n] 中复用已有的 Span;
如果没有,就从更大的 Span 拆分;
如果还是没有,就向系统申请新的大页块,再拆分。
补充:由于我们申请的时候是申请的页为单位的申请,此时寻常的malloc 和free 就不行了,window 实现模拟操作系统的页面级内存管理。
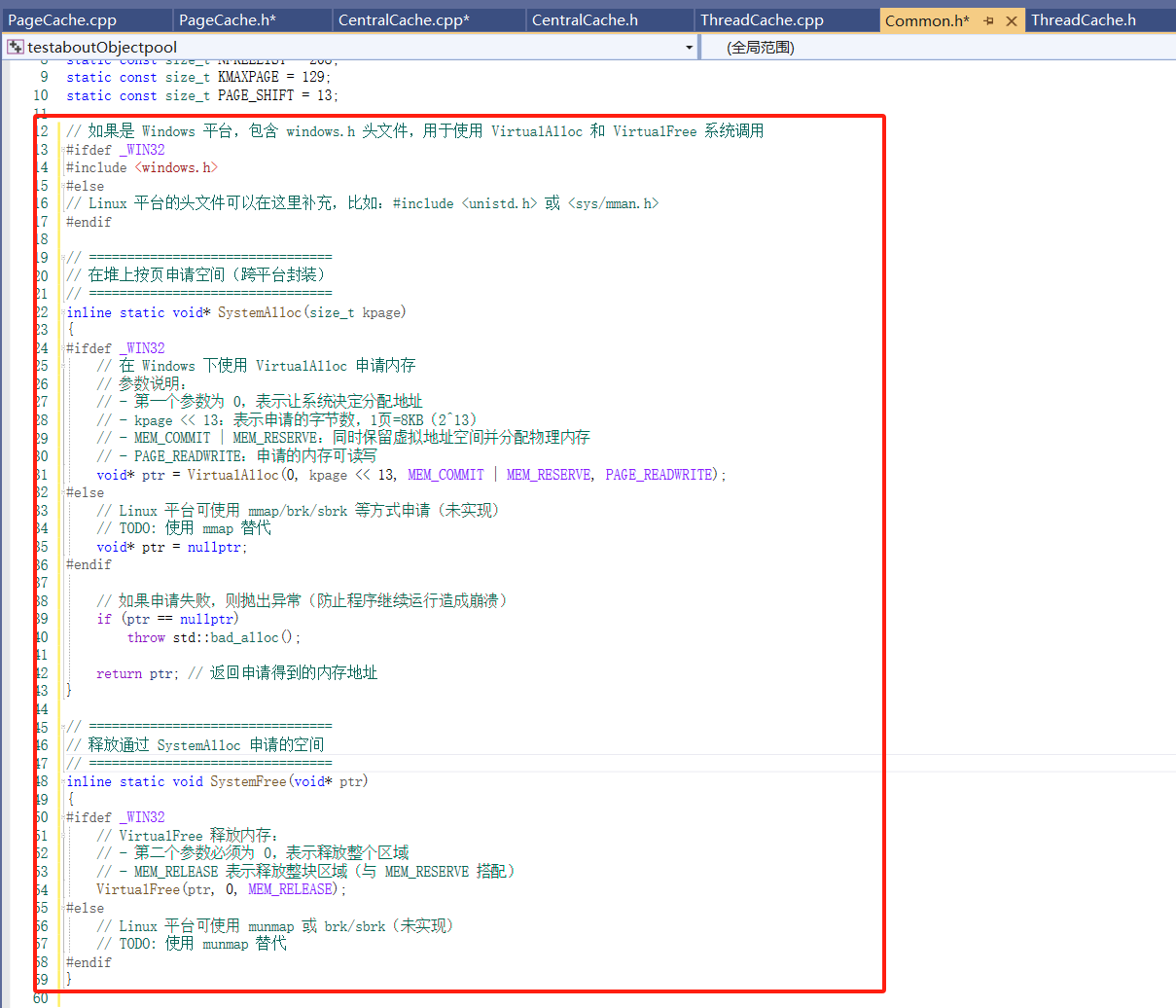
实现NewSpan:
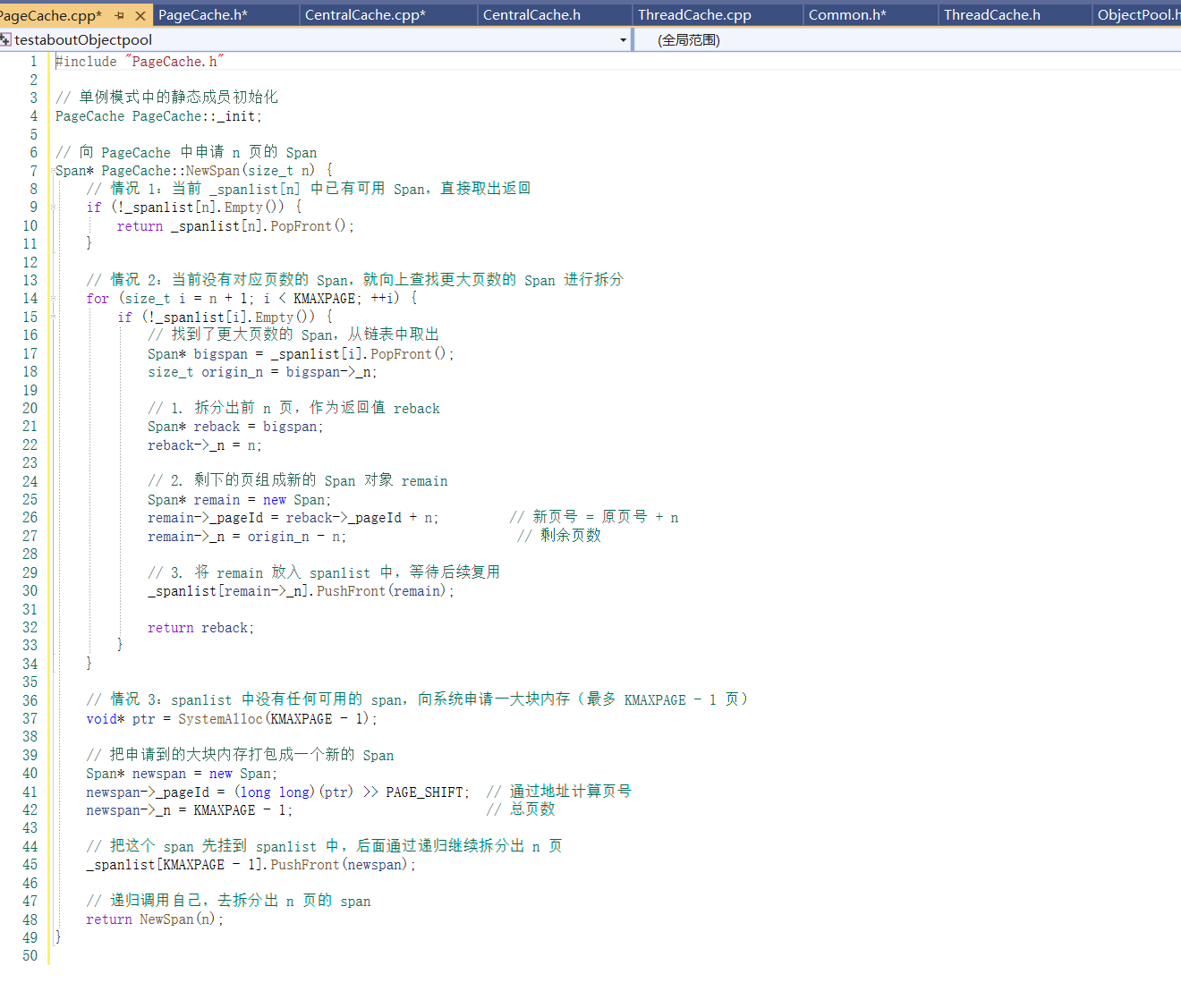
在 CentralCache 调用 PageCache::NewSpan 获取新 Span 时,加锁顺序和时机非常关键,目的是确保线程安全的同时避免死锁:
先释放 CentralCache 中桶的互斥锁(list._mtx),因为后续申请 Span 的过程中可能比较耗时,不应该长时间持有桶锁,避免影响其他线程将释放对象挂载到对应桶中。
再给 PageCache 加全局锁(PageCache::_mtx),这是为了保护 _spanlist 这个跨线程共享结构,避免多个线程同时修改 span 列表。
执行 NewSpan 逻辑,其中包括可能的拆分操作,或向系统申请新页的递归调用。
执行完 NewSpan 后,立即释放 PageCache 的锁,减少锁持有时间,提升并发性能。
最后,在重新将新申请的 span 插入 CentralCache 桶(SpanList)时重新加锁,以保证链表结构在插入过程中的一致性和线程安全。
❗为什么不在 NewSpan 内部加锁?
因为 NewSpan 有递归调用逻辑,如果加锁后递归,锁得不到释放会导致死锁。所以锁应该在调用前加,在递归结束后释放,而不是在函数内部封装加锁。
ThreadCache 的释放逻辑(平衡调度)
🌟 本质解释:
当线程从 ThreadCache 中释放对象时,会先挂到当前线程的 _freelist。
但如果 _freelist 太长,就触发回收机制,把一部分对象批量释放回 CentralCache
避免 ThreadCache 持有太多内存 ,否则会内存爆涨,造成浪费
增加 CentralCache 的复用率 ,被其他线程复用,提高系统整体内存利用
控制本地缓存大小,保持每个线程占用内存可控
批量释放提高效率 , 一次处理多个对象,减少锁竞争和系统调用频率
ThreadCache::Free(object)
└─ 将对象挂回对应 size 的 freelist
└─ 若 freelist 太长(超过 MaxSize),则触发回收
└─ 从 freelist 拆下一批对象(如20个)
└─ 调用 CentralCache::ReleaseListToSpans 批量回收
└─ 根据每个对象找到所属 Span,挂回 span->_freeList
└─ 若该 span 全部空闲,则还回 PageCache
功能:头删除范围_freelist实现:
ThreadCache 的回收实现:

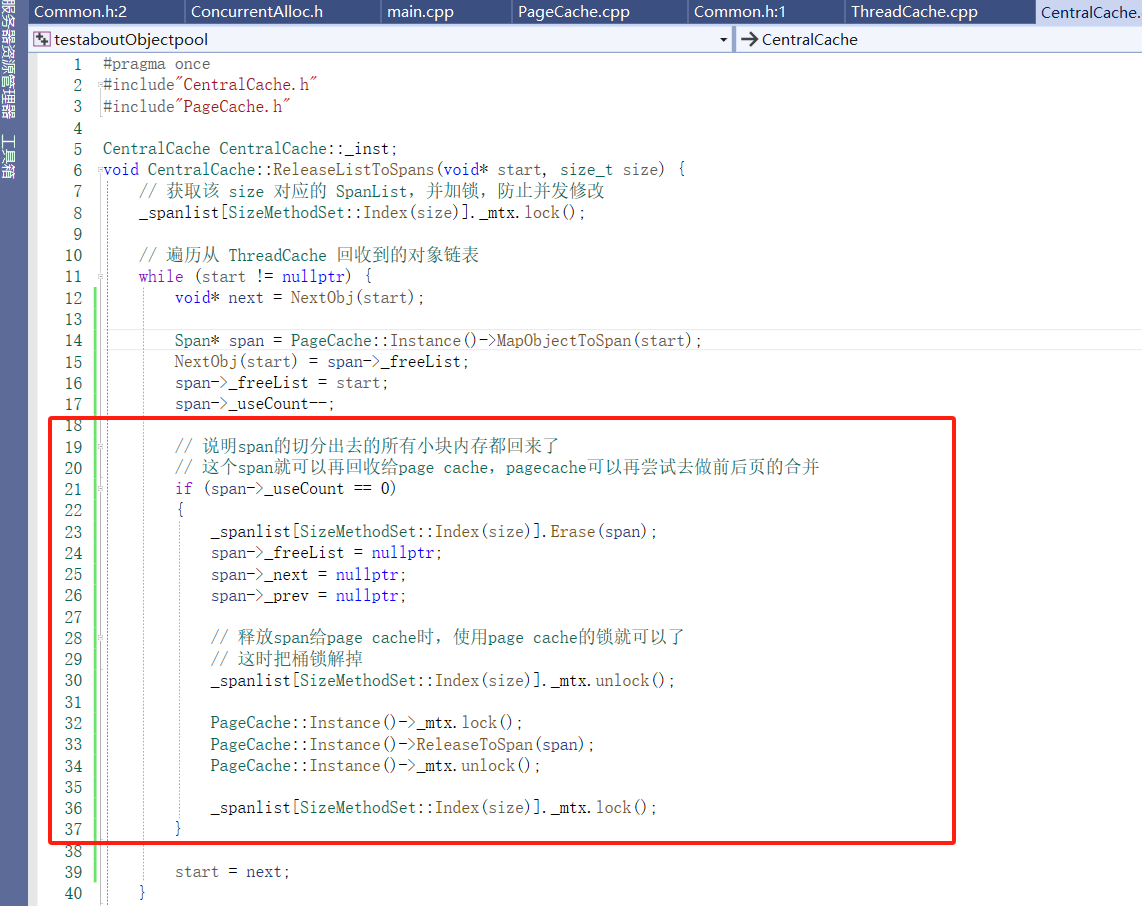
CentralCache的释放逻辑:
在设计高性能内存分配器时,我们引入了 Span 的概念,一个 Span 代表一段连续的页(Page),用于统一管理这段内存。而这些内存最终会被切分成很多小块,供 ThreadCache 分配。
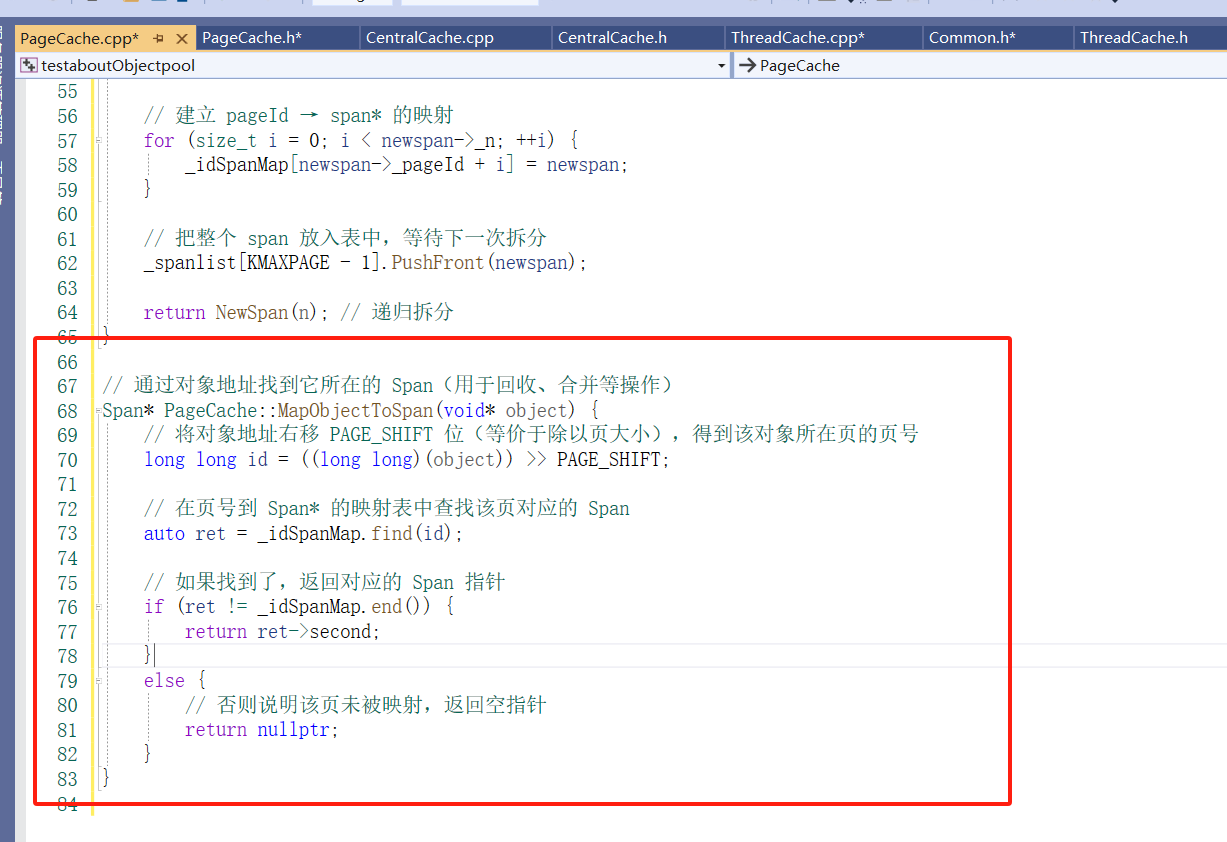
那么问题来了:当 ThreadCache 回收一个小块对象(比如 Deallocate 的时候),你拿到的是一个 void* ptr,只是一个裸地址。你怎么知道它属于哪个 Span 呢?
当然我们可以遍历这个CentralCache 的对应桶的span,只需要拿(块空间的地址>>13)和span的管理页的页号范围进行比较,在span管理的页范围中的就说明这个块在这个span中,但时间复杂度太高,这就需要一种“地址 → 管理者”的反向查询机制。
Span 生命周期在 PageCache 中统一管理
只有 PageCache 知道一个 Span 何时被创建、拆分、回收。,所以我们要在PageCache设立这个hash。
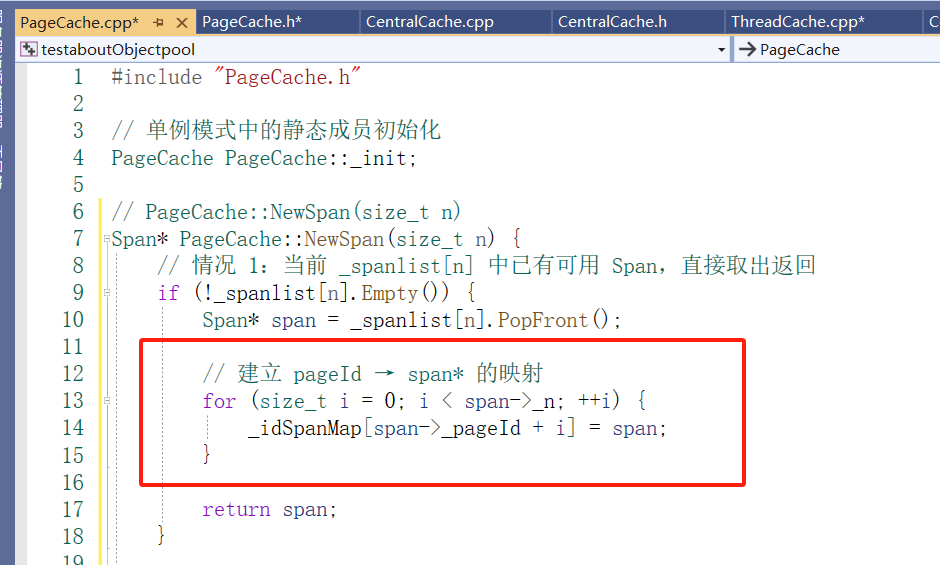

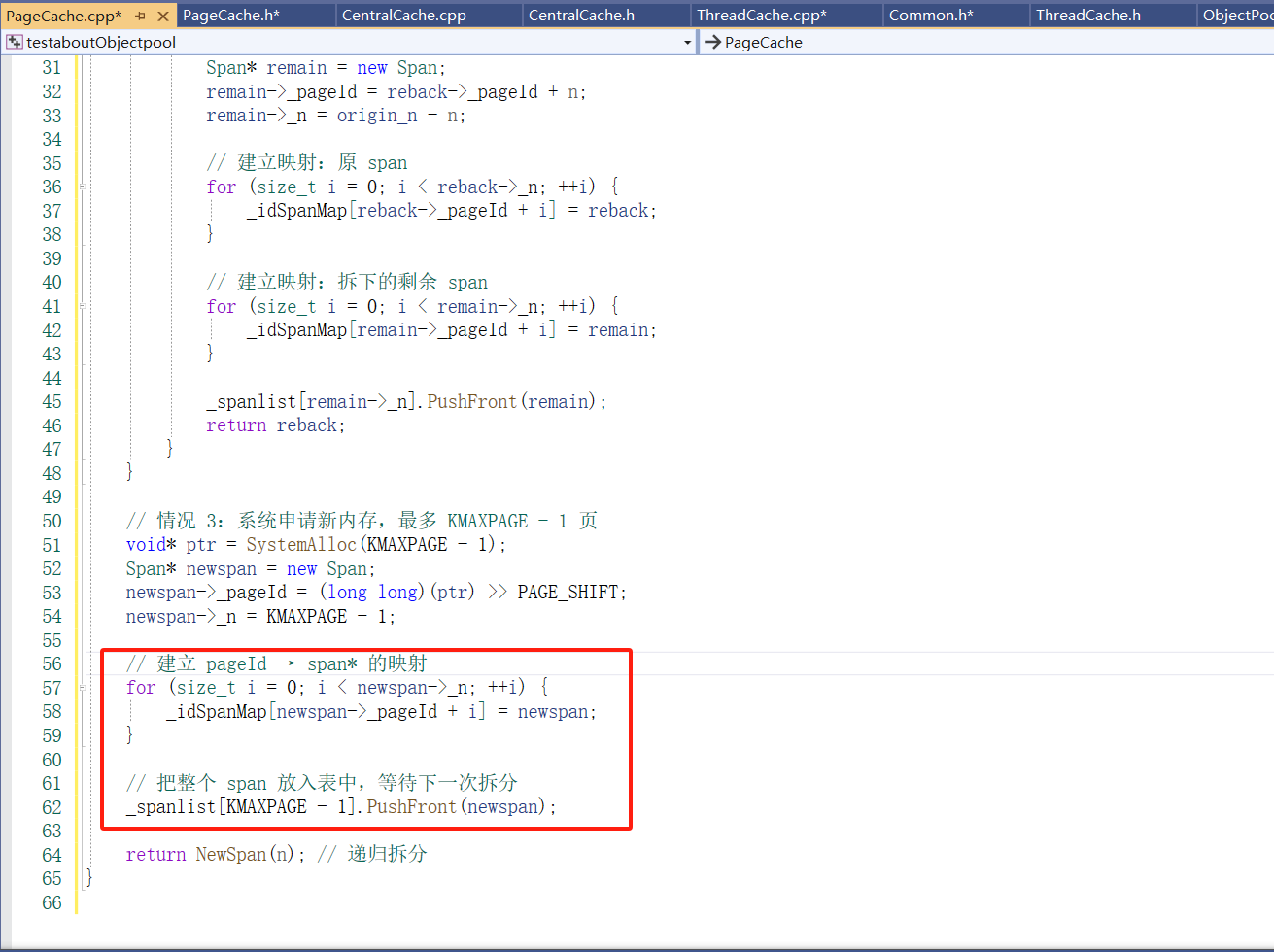
封装:映射功能的实现
CentralCache的ReleaseListToSpans的实现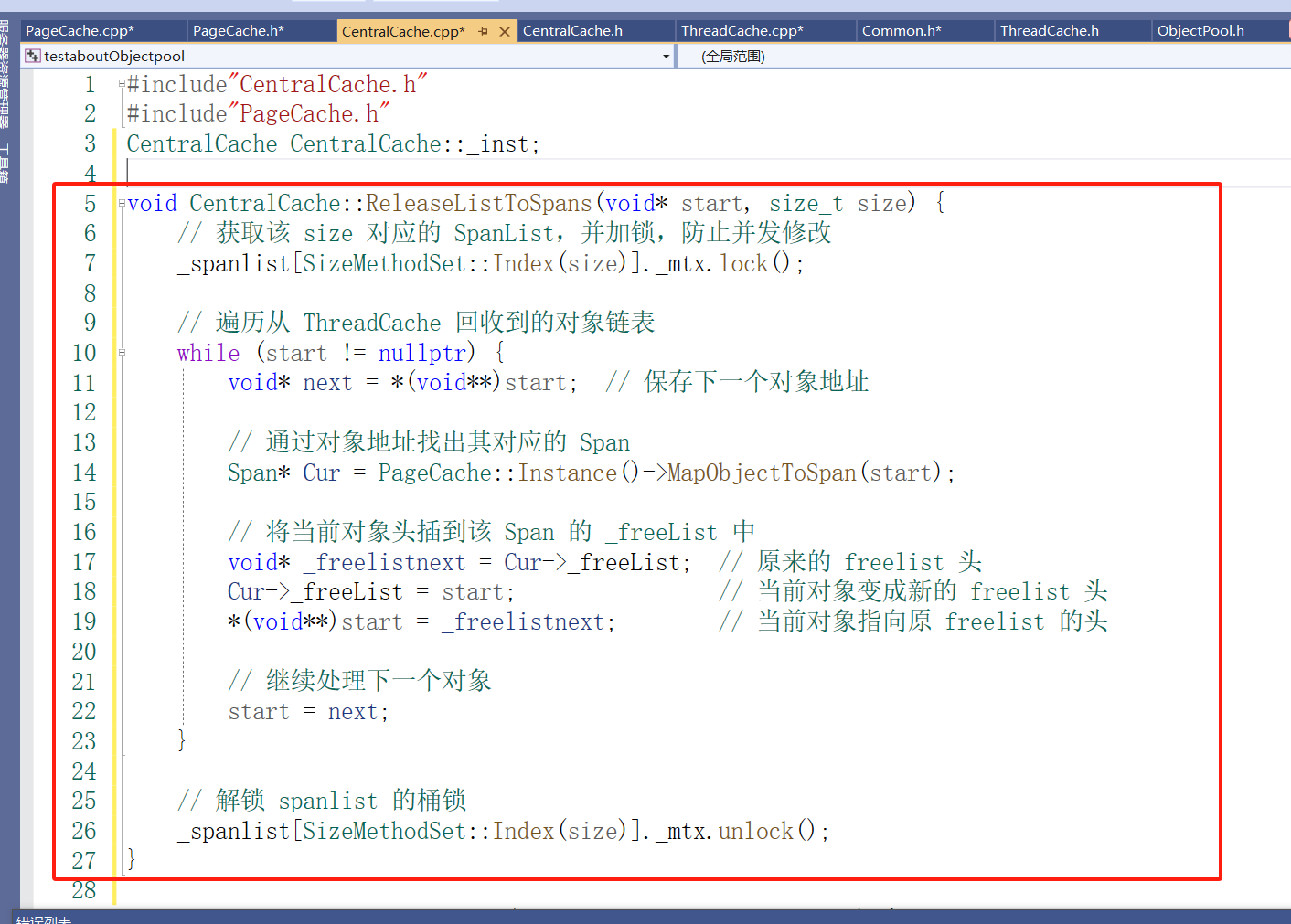
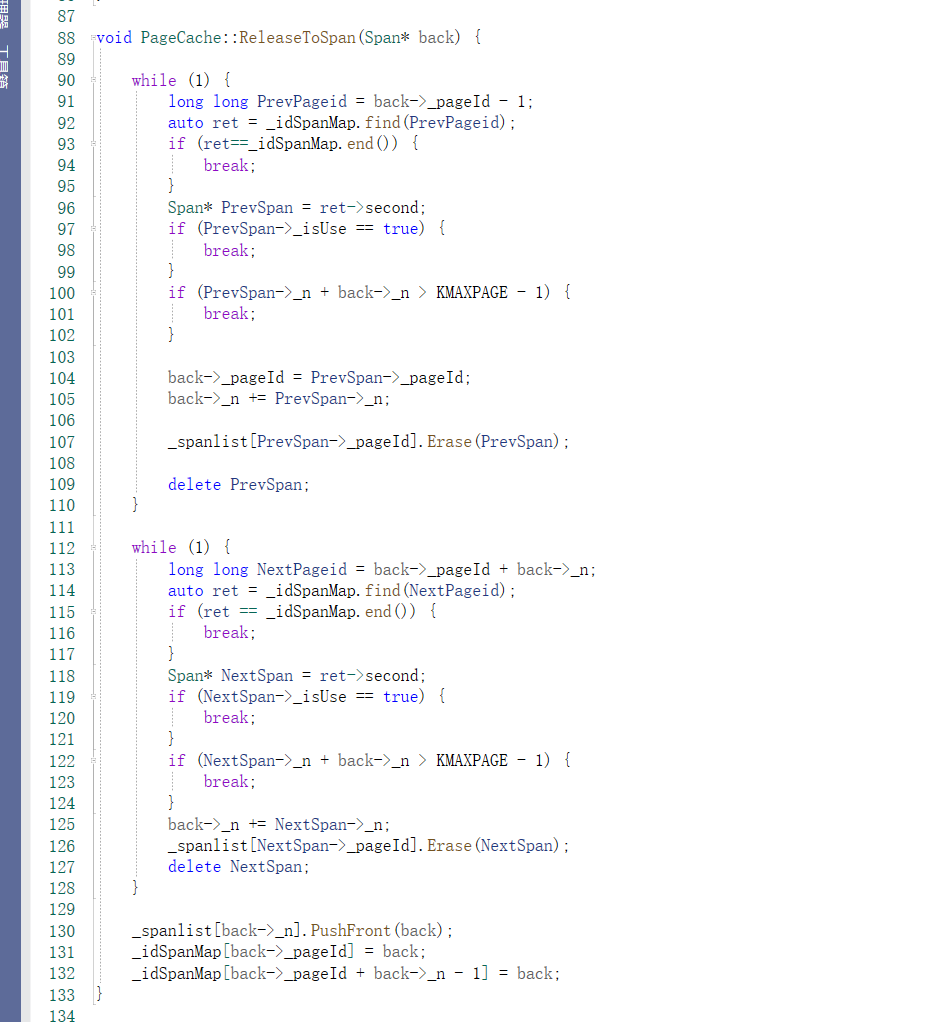
PageCache的回收逻辑:
PageCache 的回收机制主要是基于回收到的内存块(由 ThreadCache 归还的内存块),将这些内存块重新组织成 Span 对象,并将其重新放回 PageCache 中,以便后续使用。回收操作主要包括以下几个步骤:
通过 ThreadCache 回收到对象: 每当线程使用完一块内存时,会将这块内存归还给自己的 ThreadCache,在 ThreadCache 中进行回收操作。
将内存块插入到 Span 的 _freeList: 每块内存在归还时,会根据其大小找到对应的 Span,并将内存块插入到 Span 对应的 _freeList 中。
当 Span 的使用计数为 0 时: 当 Span 中所有的对象都归还后,useCount 变为 0,这时该 Span 被认为是空闲的,可以被回收到 PageCache 中。
归还给 PageCache: 当 Span 空闲时,它会被归还给 PageCache,如果 Span 占用的是最大页数的内存块,则直接释放内存。如果是较小的 Span,则将其放入 PageCache 中,等待下一次分配。
Step 1: 初始状态
+--------------------+ +--------------------+ +--------------------+
| Span A | | Span B | | Span C |
| _pageId=0 | | _pageId=3 | | _pageId=6 |
| _n=2 | | _n=3 | | _n=2 |
+--------------------+ +--------------------+ +--------------------+
由于前面在newspan中,剩下的span 存储首位页号跟尾页号的映射,此时的左合并就找Span->_pageId-1进行和并
右合并就找span->_pageId+span->_n
Step 2: 左合并 (Span A 和 Span B)
+--------------------+ +--------------------+
| Span AB | | Span C |
| _pageId=0 | | _pageId=6 |
| _n=5 | | _n=2 |
+--------------------+ +--------------------+
Span->_pageId-1进行和并
Step 3: 右合并 (Span AB 和 Span C)
+--------------------+
| Span ABC |
| _pageId=0 |
| _n=8 |
+--------------------+
span->_pageId+span->_n 进行和并
但是,我不知道哪些span 在Central Cache ,此时就要用到成员变量_isuse ,在NewSpan 给CentralCache时就要
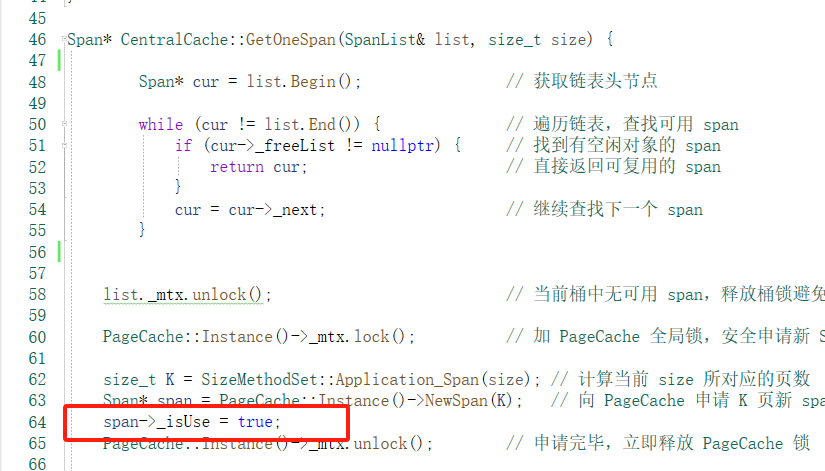
当 Span 中所有的对象都归还后,useCount 变为 0,这时该 Span 被认为是空闲的,可以被回收到 PageCache 中。
提前把这个解锁:和前面NewSpan 加锁的逻辑是一样的
逻辑实现:
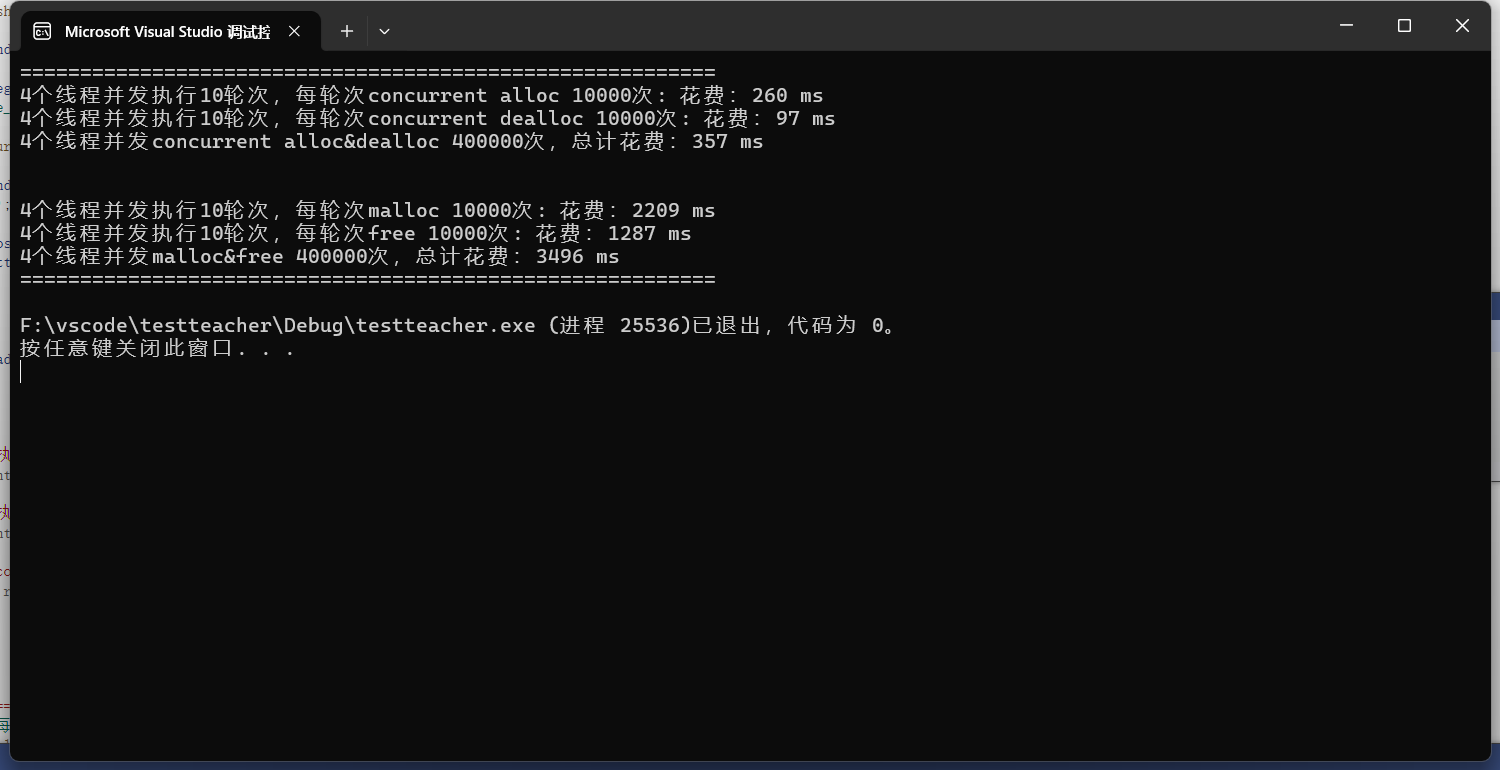
测试结果:

















 2554
2554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









