




构造介绍
概述
11级流水线各级介绍如下:
IF1 取指令1
IF2 取指令2
D1 译码
I1 发射缓冲区
I2 发射决定区
RF 寄存器文件
B1 分支结果计算
E1 执行
M1 访存
RB1 重排序区
W 写回
在此可以立即指出一个缺陷,分支结果计算过晚,刷新代价可能很高,分支预测只能有限改善这一情况。
第二个缺陷,乱序执行的设计纯属本人凭想象力和有限的资料完成,堆砌了大量的组合逻辑,性能可能很低,可惜后来才看到记分牌算法和重命名寄存器的内容。
第三个缺陷,没有设计阻塞。在I2发射决定区会将一切被认为有可能引发阻塞的指令暂缓发射,这主要严重降低了对内存读写指令的执行效率,具体原理后续阐述。
各级介绍
介绍不按照流水线顺序,而是按照概念展开的顺序。
D1
在这一级,32位指令会被转化成64位的控制信号和数据,称为signalset。signalset被分为两类:t1和t2,这两类有相同和相异部分。下面给出signalset中各个位的含义。
相同部分:
| Ist1 | Ist2 | Isls | l/s | IsActive |
|---|---|---|---|---|
| [63] | [62] | [61] | [60] | [59] |
| rt r/w | rd En | rs | rt | rd |
|---|---|---|---|---|
| [58] | [57] | [4:0] | [9:5] | [14:10] |
Ist1:若为1,则为t1型signalset
Ist2:若为1,则为t2型signalset
Isls:若为1,则是需要对内存进行读写的signalset
l/s:若为1,则写入内存,否则读取内存。
IsActive:若为1,则signalset有效
rt r/w:若为1,rt字段为要写入的寄存器编号,否则为读取
rd En:若为1,rd字段为要写入的寄存器编号,否则rd字段无意义
rs:读取的寄存器编号
rt:读/写的寄存器编号
rd:写入的寄存器编号
不同部分:
t1:
| branchtype | iden | IsPre | PreRes | Cst32 |
|---|---|---|---|---|
| [51:49] | [48:44] | [43] | [42] | [41:10] |
branchtype:跳转指令类型
| bltz | bgez | beq | bne | blez | bgtz | jr/jalr | j/jal |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
iden:在分支预测器循环队列中的序号
IsPre:若为1,说明该条指令进行过预测
PreRes:若为1,说明预测结果为跳转,否则不跳转
Cst32:存储32位常数,对于jal/jalr,是将要写入31号寄存器的数值,否则是PC+4+SignImm
t2:
| ShifterSrcA | ImmExt | ResultSrc | InputSign | ShifterSrcB |
|---|---|---|---|---|
| [39] | [38] | [37:36] | [35] | [34:33] |
| ALUSrc | ShifterCtrl | ALUCtrl | Imm11 |
|---|---|---|---|
| [32:31] | [30:29] | [28:26] | [25:15] |
ShifterSrcA:若为1,则Shifter第一个操作数来自rt寄存器,否则来自拓展立即数
ImmExt:若为1,立即数拓展方式为符号拓展,否则为零拓展
ResultSrc:若为0,E1级输出结果来自ALU的计算结果,否则来自Shifter
InputSign:若为1,则ALU将输入视为符号数处理(slt等),并且溢出判断标准为符号数运算标准(add,addi等),否则按照无符号数处理
ShifterSrcB:若为0,则Shifter第二个操作数来自shamt字段,否则若为1,则Shifter第二个操作数来自rs寄存器,否则若为2,则Shifter第二个操作数为16(lui),否则Shifter第二个操作数为0
ALUSrc:若为0,则ALU第二个操作数来自rt寄存器,否则若为1,则ALU第二个操作数来自拓展立即数,否则ALU第二个操作数为0
ShifterCtrl:控制Shifter进行的运算类型
| left logical | right logical | right arithmetic |
|---|---|---|
| 0 | 1 | 2/3 |
ALUCtrl:控制ALU进行的运算类型
| and | or | add | slt | xor | nor | sub |
|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3/7 | 4 | 5 | 6 |
Imm11:原指令的[10:0]位
经过处理得到的64位信号,绝大多数可以直接用于后续的控制信号。
I1
在这一级,主要维护一条循环队列(发射缓冲区),要实现的功能有:
1.如果队列未满,从D1级接收两条signalset,否则阻塞前序三级,直到队列有空位。
2.如果B1级产生了分支预测错误信号,则刷新队列中这条跳转指令后序的指令。
3.如果RB1级提交了队首的若干条指令,则去除队首的这部分指令。
队列最大容量为16条指令。队列的进出实质上通过修改指向队首的指针front和队尾指针rear实现,front的修改权属于RB1级,rear的修改权属于I1级。
由于早期设计有些部分考虑不当,因此有以下特性:
1.分支指令如果触发刷新,会连同自身一起被刷新,但不触发刷新时会正常走完发射至提交的全流程。
2.rear的值只可能为偶数,当一条分支指令触发刷新时,有可能在队列中产生一个气泡补位。
3.front和rear被设定为5位信号,指定一段左闭右开区间,这是当时对于队列装满和队列为空无法区别的修补方案。
具体实现详见源代码部分。
I2
在这一级,主要维护发射缓冲区中每条指令的发射状态(未发射、发射未到达,到达等待提交),以及发射后已经经历的周期数,藉此判断一条指令是否具有相关性问题和重定向问题,得出是否可以发射的判断。
也是在这一级,我放弃了对处理器最终频率的追求,因为I2涉及的组合逻辑被设计的有些复杂,凭我浅薄的知识判断I2级或将成为最慢级并远超其他级,因此最后呈现出来的深流水线,更多原因并非提高效率而仅是将功能分开,避免自己思维混乱。能跑就行,以后有空再优化I2的逻辑吧。
具体如何判断一条指令是否具有相关性问题和重定向问题呢?
下述的“写入指令”“读取指令”都指的是仅对一个寄存器或整个内存空间而言的写入和读取。
首先是相关性问题。RAR和WAW都不会是问题。RAR不是问题很好理解,WAW不产生问题的原因是:改变体系结构状态的操作(写寄存器、内存)会由RB1级按正确的先后顺序提交,这也是为了后续如果添加中断方便改进:我们总是希望中断以前的指令准确的改变体系结构状态,中断以后的指令完全不改变体系结构状态。WAR和RAW会产生问题。WAR产生相关性问题的原因是,如果写入指令提前到读取指令之前,后续读取指令会读取到错误的值,当然有特例:如果能保证写入指令提交之前,他前序的所有读取指令已经发射并正确通过读取体系结构状态的级,那么一条写入指令可以提前到这些读取指令之前发射。这个特例的判断和实现较复杂,因此最终对于WAR相关性问题的处理是一刀切的:写入指令绝对不会提前到读取指令之前发射。RAW相关性问题的处理同样一刀切,且没有特例:一条读取指令提前到写入指令之前几乎不可能存在办法使其读取到正确数值。
其次是重定向问题。首先给出重定向路径图:
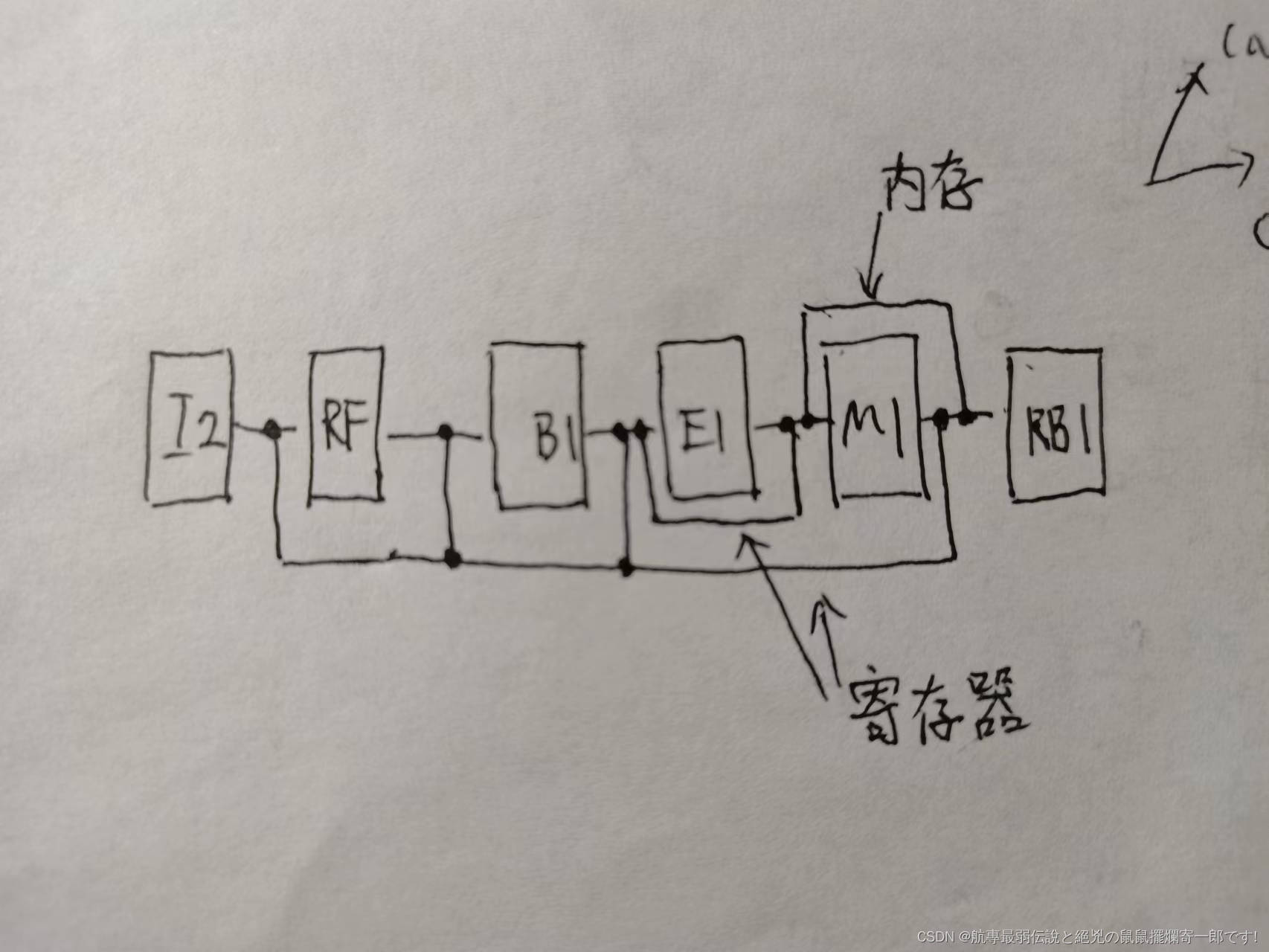
对于寄存器数据有4条重定向路径,从RB1级分别到RF级,B1级,E1级3条,从M1级到E1级1条。
对于内存数据有1条重定向路径,从RB1级到M1级。
所有重定向路径,因为结尾都位于一级的起始,开始都位于一级的起始而非走完这一级的组合逻辑部分的末尾,这是为了缩短关键路径提高效率,很好理解。
重定向需要判断的问题是:按照顺序先后发射的一条写入指令和一条读取指令,写入指令尚未提交,那么读取指令发射后究竟是否存在可能提前得到将要写入的值?得到的时机是否正确?
先回答第一个问题。以寄存器数据为例,从重定向路径可知,对一个寄存器来讲,只要在这条读取指令之前的最近的写入指令已经发射,并且周期差在+1到+4,就可能从重定向路径获得即将写入的值。
再回答第二个问题。同样以寄存器数据为例,从重定向路径可知,对一个寄存器来讲,如果读取指令是一条branch类指令,那么要想在其得出结果(B1级结束)之前得到正确的寄存器值,周期差一定要大于等于+3。如果一条写入指令想要回馈正确的值给后续的指令,而巧合地是这是一条load类指令,那么周期差一定不能恰为1:因为只有走完M1级,load类指令才能读取到将要写入寄存器的正确的值,也就是从RB1级开始的重定向路径,只能为周期差+2到+4的读取指令提供正确数据支持。
这里可以回答上述第三缺陷,因为没有设计发射后的阻塞,所以为了保证绝对正确,对内存的读取和写入总是将内存视为一个整体,因为具体知道读写内存的哪个位置至少是E1级以后的事情,但一般情况程序并不会总是读写内存的同一个具体位置,将阻塞的逻辑融合到I2级,导致了很多不冲突的内存读写等待浪费了大量周期。这个缺陷的原因是当时刚接触流水线不久,对各种特性了解不足,忘记阻塞了。
具体实现详见源代码部分。
RF
这一级相对简单,最大的改动是增加了读取端口和写入端口,原因是超标量。当然,需要注意两个写入口写入同一位置时有优先级关系,这是因为RB1级提交的两条写回指令如果是对同一寄存器的写入的话,后序的指令是本次写回完成后寄存器真正的值,是高优先级。
B1
在这一级,主要处理6种branch指令和jr/jalr。
首先解决一个前置问题,jal指令。它需要向31号寄存器写入PC+4,因此D1级生成的signalset中必须包含这个值并存入I1级的发射缓冲区中;它的跳转目标是{(PC+4)[31:28],addr,2’b00},也需要保存在signalset中。问题产生:signalset只有64位,在存储完这2个32位值后,就没有剩余的位存储其它控制信号了。解决方案:j和jal的跳转目标在IF2级给出到IF1级,提前完成跳转,节省了32位跳转目标,既正确解决了上述问题,还节省了预测错误代价。
前置问题解决方案是对为什么B1级不处理j和jal的解答。剩下的8种指令,branch可能预测错误,可能预测正确,jr/jalr可以理解为必然预测错误。
所以B1级完成的任务有两点:
1.预测错误时,通知前序级刷新指令,并向IF1级送去正确PC值。
2.预测错误,并且分支预测器确实给出预测的,向分支预测器送去预测错误的指令在预测器循环队列中的序号以及错误为和,使分支预测器正确状态转移。
具体实现详见源代码部分。
E1
这一级同样任务简单,主要是两种运算单元ALU和Shifter完成运算,再选择正确的结果输出,后续可以添加乘法单元等。
M1
这一级实现读写内存的功能,和RF的特点相似,写回同一位置时同样有优先级。
额外的,这一级着手生成最终RB1中写回缓冲区存储的写回信号,共66位。
RB1
在这一级,维护一条等待提交循环队列(提交缓冲区),与I1级中的发射缓冲区队列位置完全对应,记录发射缓冲区每条指令对应的是否到达等待提交状态和写回信号,每次从队首开始检查,若可以提交则提交,还要保证提交按序进行,最大提交能力为两条寄存器写入信号和两条内存写入信号。
额外的,一条指令的结果到达RB1级,就一定可以存入提交缓冲区吗?答案是否定的,在B1级产生的预测错误刷新信号可能需要刷新掉一条已发射指令(例如RF级),因此signalset中有IsActive信号,只有为1时,说明是一条应当被提交的指令,被刷新时,IsActive置0。
具体实现详见源代码部分。
IF2
在这一级,实现的功能有两点:
1.根据IF1输出的PC值,取出PC和PC+4位置的两条指令。
2.若指令为j/jal,向IF1返回跳转目标完成跳转,并在特定情况下刷新掉并行的另一条指令。
IF1
在这一级,实现的功能是更新PC值。
通过上述各级功能,已经可以对IF1的PC值来源有明确认知:
1.PC+8
2.B1级判断预测错误时产生的跳转目标
3.IF2级特殊处理j/jal时产生的跳转目标
显然,优先级2>3>1。
W
写回级没有具体的模块,就如同《数字设计和计算机体系结构》上写回级不具有属于自己阶段的状态寄存器一样,可以理解为RB1级输出的写回信号到RF级或到M1级的组合逻辑部分就是写回级W。
源代码
IF1
module IF1(
input CLK,
input RST,
input EN,
input Err,
input [31:0] PCBranch,
input IsJump,
input [31:0] JumpDst,
output reg [31:0] PC
);
wire PCSrc=Err|IsJump;
wire [31:0] PCDst=
(Err)?PCBranch:
(IsJump)?JumpDst:0;
always @(posedge CLK, posedge RST)
begin
if(RST) PC<=0;
else if(PCSrc) PC<=PCDst;
else if(EN) PC<=PC+8;
else PC<=PC;
end
endmodule
IF2
module IF2(
input CLK,
input RST,
input EN,
input CLR,
input [31:0] PC,
input IsPredict,
input Err,
input [4:0] idf,
output IsJump,
output [31:0] JumpDst,
output reg [31:0] Ins1,
output reg [38:0] signal1,
output reg IsActive1,
output reg [31:0] Ins2,
output reg [38:0] signal2,
output reg IsActive2
);
integer h;
integer i;
integer j;
integer k;
reg flag;
reg bb1;
reg bb2;
reg pb1;
reg pb2;
reg [4:0] idf1;
reg [4:0] idf2;
reg [31:0] ROM [0:1023];
reg [33:0] Predictor [0:31];
reg [4:0] rear;
wire [4:0] rearA1=rear+1;
wire [4:0] rearA2=rear+2;
wire [31:0] PCA4=PC+4;
wire [31:0] PCA8=PC+8;
wire [9:0] A1=PC[11:2];
wire [9:0] A2=PCA4[11:2];
wire [31:0] I1=ROM[A1];
wire [31:0] I2=ROM[A2];
wire [31:0] cst321;
wire [31:0] cst322;
wire [38:0] s1={cst321,idf1,bb1,pb1};
wire [38:0] s2={cst322,idf2,bb2,pb2};
wire j1=(I1[31:26]==6'b000010||I1[31:26]==6'b000011)?1'b1:1'b0;
wire j2=(I2[31:26]==6'b000010||I2[31:26]==6'b000011)?1'b1:1'b0;
wire b1=(I1[31:26]==6'b000001||(I1[31:26]>6'b000011&&I1[31:26]<6'b001000))?1'b1:1'b0;
wire b2=(I2[31:26]==6'b000001||(I2[31:26]>6'b000011&&I2[31:26]<6'b001000))?1'b1:1'b0;
assign IsJump=(j1||j2||pb1||pb2)?1:0;
assign JumpDst=
(j1)?{PCA4[31:28],I1[25:0],2'b00}:
(pb1)?PCA4+{
{14{I1[15]}},I1[15:0],2'b00}:
(j2)?{PCA8[31:28],I2[25:0],2'b00}:
(pb2)?PCA8+{
{14{I2[15]}},I2[15:0],2'b00}:0;
assign cst321=
(b1)?PCA4+{
{14{I1[15]}},I1[15:0],2'b00}:PCA4;
assign cst322=
(b2)?PCA8+{
{14{I2[15]}},I2[15:0],2'b00}:PCA8;
always @(*)
begin
bb1=0;
pb1=0;
idf1=0;
for(j=0;j<32;j=j+1)
begin
if(bb1==0&&Predictor[j][31:0]==PC)
begin
bb1=1;
pb1=Predictor[j][33];
idf1=j;
end
else
begin
bb1=bb1;
pb1=pb1;
idf1=idf1;
end
end
end
always @(*)
begin
bb2=0;
pb2=0;
idf2=0;
for(k=0;k<32;k=k+1)
begin
if(bb2==0&&Predictor[k][31:0]==PCA4)
begin
bb2=1;
pb2=Predictor[k][33];
idf2=k;
end
else
begin
bb2=b 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7893
7893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









