










文章目录
前言
👉软件安装包
| 软件包 | 版本 |
|---|---|
| Oracle JDK | 17 |
| Hadoop | 3.4.1 |
👉 系统
| 系统 | IP | 主机名 |
|---|---|---|
| Rocky Linux 9.x | 192.168.124.31 | hadoop01 |
| Rocky Linux 9.x | 192.168.124.32 | hadoop02 |
| Rocky Linux 9.x | 192.168.124.33 | hadoop03 |
👉 hadoop集群规划
NameNode和SecondaryNameNode不要安装在同一台服务器上
ResourceManager也很耗内存,不要和NameNode、SecondaryNameNode配置在同一台服务器上
| hadoop01 | hadoop02 | hadoop03 | |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | ResourceManager、NodeManager | NodeManager |
一、安装Oracle JDK 17
自我约定,软件都安装在:
/app/下
1.下载安装包
【官网】下载Oracle JDK17,注意,这个需要账号,这个自行注册解决。
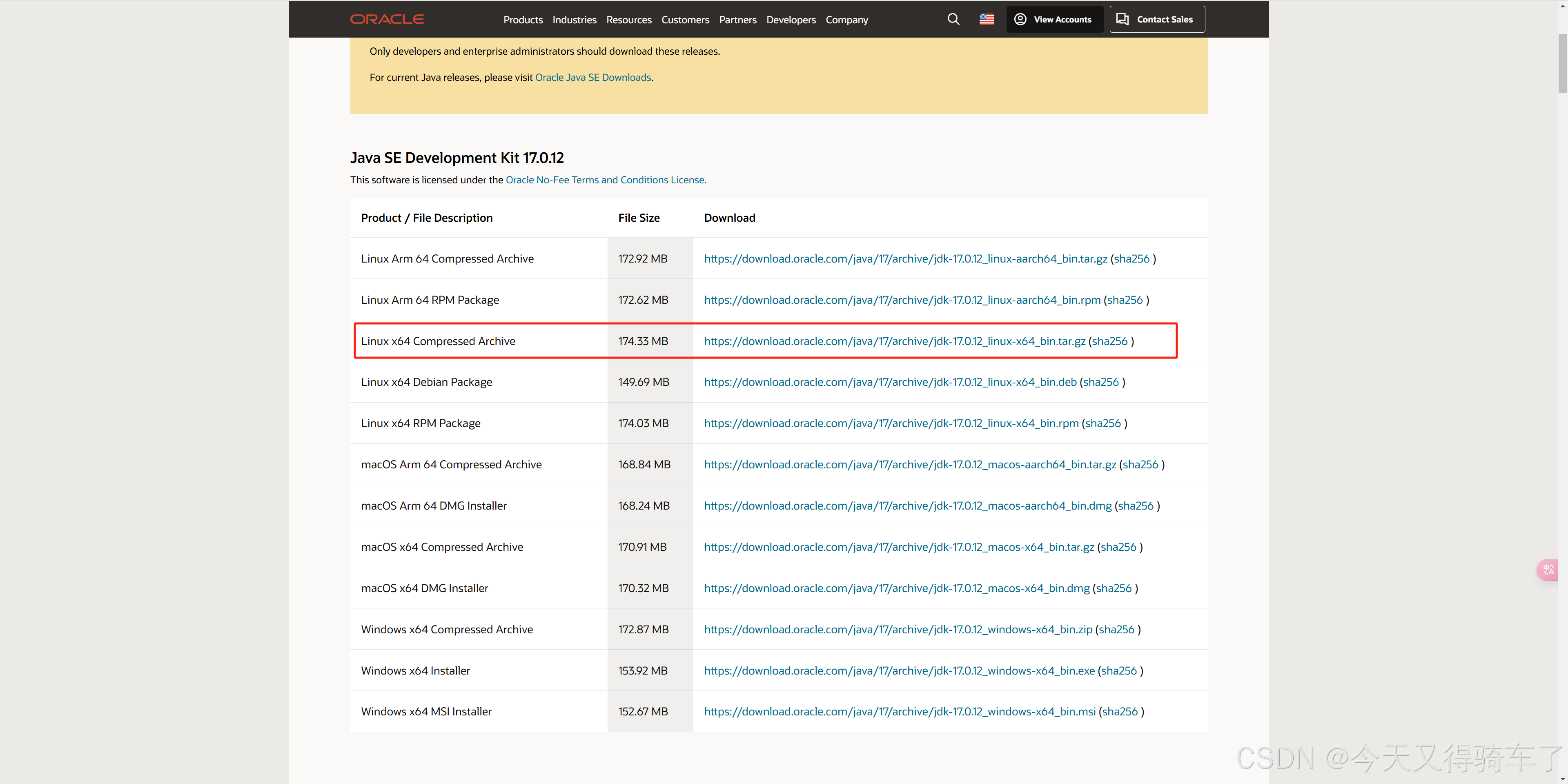
2.配置JDK17环境变量
# 创建JDK安装路径,并上传jdk-17.0.12_linux-x64_bin.tar.gz包到这个路径
mkdir -p /app/java
# 解压
cd /app/java
tar -zxvf jdk-17.0.12_linux-x64_bin.tar.gz
# 添加环境变量,在profile文件最末尾处追加
vim /etc/profile
彦祖,下面是可以直接复制粘贴的配置内容
# JDK17环境变量配置
export JAVA_HOME=/app/java/jdk-17.0.12
export PATH=$JAVA_HOME/bin:$PATH
之后:wq退出保存后,⚡️⚡️⚡️重新加载环境变量 ⚡️⚡️⚡️
source /etc/profile
最后,验证一下,是否配置成功。(这还用验证嘛,装了那么多次JDK,彦祖早就熟透了😆😆😆)
[root@localhost jdk-17.0.12]# java -version
java version "17.0.12" 2024-07-16 LTS
Java(TM) SE Runtime Environment (build 17.0.12+8-LTS-286)
Java HotSpot(TM) 64-Bit Server VM (build 17.0.12+8-LTS-286, mixed mode, sharing)
[root@localhost jdk-17.0.12]#
二、安装Hadoop3.4.1
1.下载Hadoop3.4.1安装包
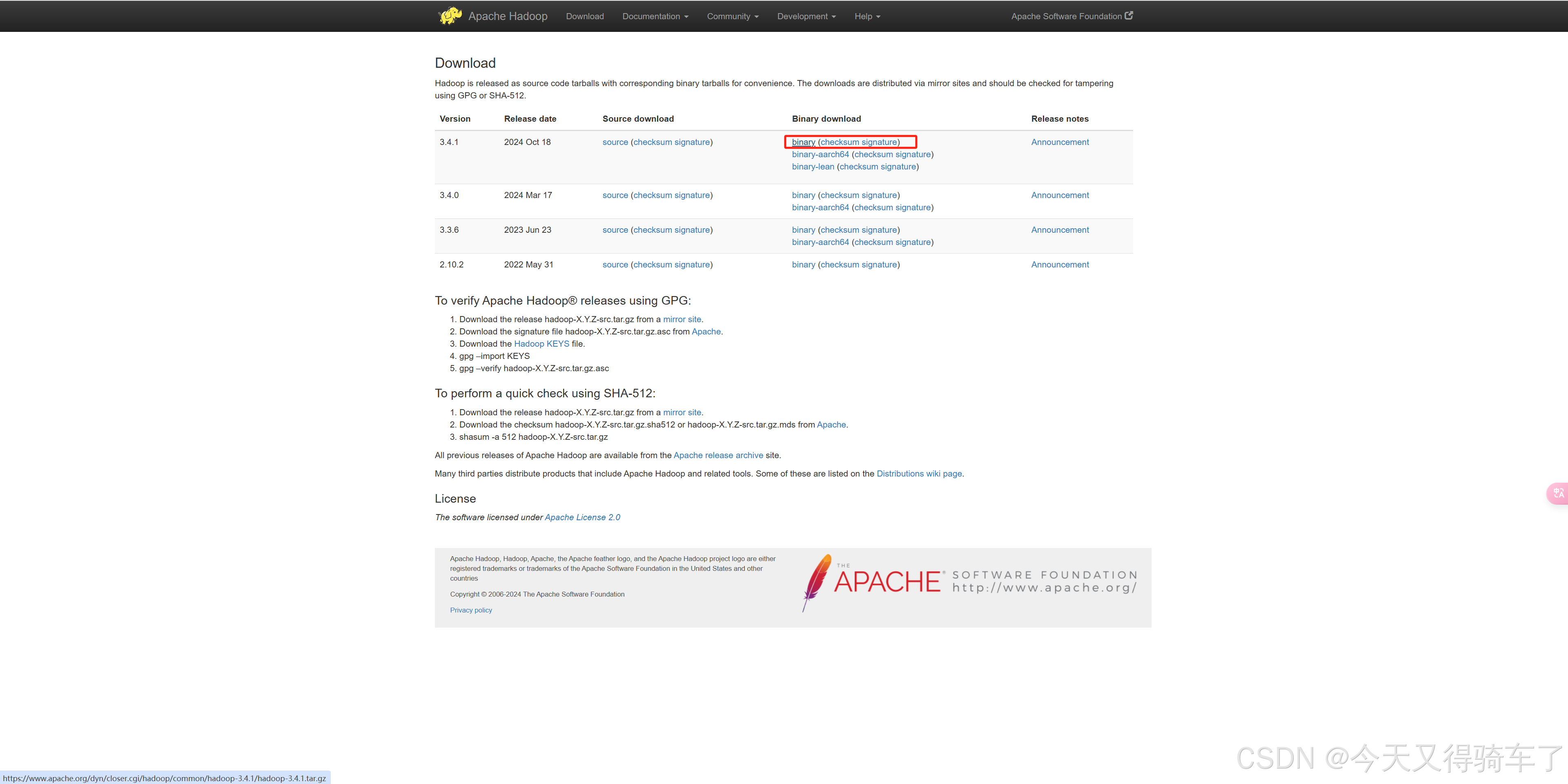
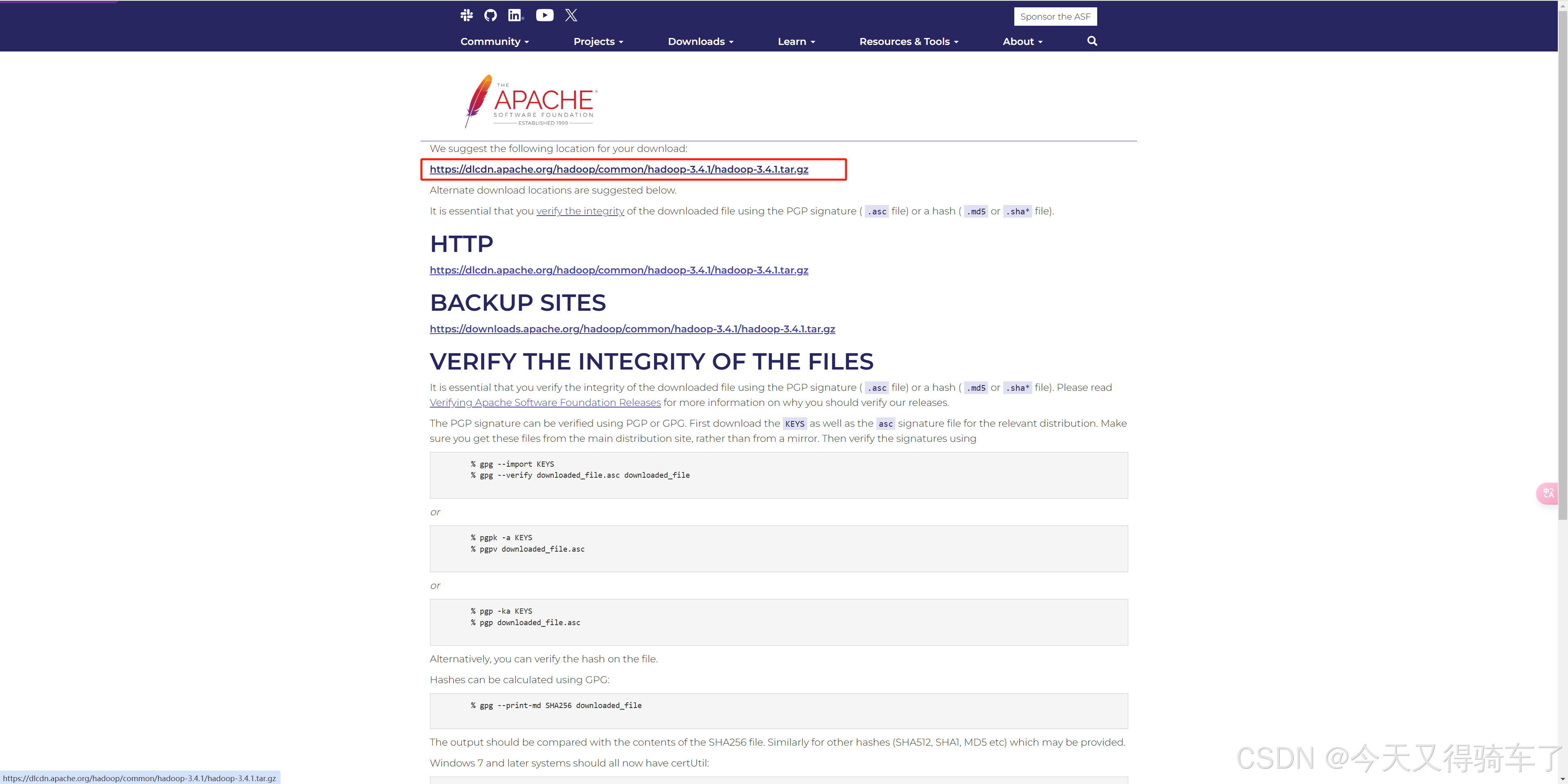
2.调整主机名和hosts
调整主机名,按下面这个表格进行调整
| 系统 | IP | 主机名 |
|---|---|---|
| Rocky Linux 9.x | 192.168.124.31 | hadoop01 |
| Rocky Linux 9.x | 192.168.124.32 | hadoop02 |
| Rocky Linux 9.x | 192.168.124.33 | hadoop03 |
# 调整主机名
vim /etc/hostname
# 设置hadoop,在hostname文件里,添加如下内容:
hadoop01
调整主机名称映射hosts,这里每台服务器,设置的都是一样的内容,内容如下:
vim /etc/hosts
添加如下内容
192.168.124.31 hadoop01
192.168.124.32 hadoop02
192.168.124.33 hadoop03
之后,重启服务器
reboot
3.开始安装Hadoop3.4.1
安装在
/app/hadoop下
使用的shh连接工具是:Tabby
3.1.上传安装包到应用服务器上
# 创建安装目录
mkdir -p /app/hadoop
三台服务器都上传hadoop-3.4.1.tar.gz包到/app/hadoop路径下
3.2.解压hadoop-3.4.1.tar.gz包
cd /app/hadoop
tar -zxvf hadoop-3.4.1.tar.gz
3.3.配置环境变量
vim /etc/profile
文件末尾追加
# Hadoop环境变量配置
export HADOOP_HOME=/app/hadoop/hadoop-3.4.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
配置文件生效
source /etc/profile
验证,又到了激动人心的验证时刻了,彦祖已经跃跃欲试
# 输入hadoop,会出现如下内容,就说明hadoop的环境变量已经配置好了
[root@hadoop01 sbin]# hadoop version
Hadoop 3.4.1
Source code repository https://github.com/apache/hadoop.git -r 4d7825309348956336b8f06a08322b78422849b1
Compiled by mthakur on 2024-10-09T14:57Z
Compiled on platform linux-x86_64
Compiled with protoc 3.23.4
From source with checksum 7292fe9dba5e2e44e3a9f763fce3e680
This command was run using /app/hadoop/hadoop-3.4.1/share/hadoop/common/hadoop-common-3.4.1.jar
3.4.常用目录下的命令
| 目录 | 命令 |
|---|---|
/app/hadoop/hadoop-3.4.1/bin | hadoop、mapred、yarn |
/app/hadoop/hadoop-3.4.1/etc/hadoop | workers、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml |
/app/hadoop/hadoop-3.4.1/etc/sbin | start-dfs.sh、start-yarn.sh、mr-jobhistory-daemon.sh |
上述的步骤,在hadoop01、hadoop02、hadoop03三台机器上,都需要操作。😃
如果,使用了3.5.配置内容分发步骤,在配置完一台后,可以使用同步的方式,直接同步到剩余节点机器。
3.5.配置内容分发
3.5.1.安装rsync
rsync 是一个常用的工具,用于在本地和远程主机之间同步文件和目录,支持增量同步、压缩、加密等功能。它非常适用于分布式环境中的文件同步任务,特别是在需要将文件分发到 Hadoop 集群等多个节点时。
# 在hadoop01、hadoop02、hadoop03三台机器上都安装
dnf install -y rsync
3.5.2.编写一个名为:xsync脚本
mkdir -p /app/hadoop/hadoop-3.4.1/myshell
vim /app/hadoop/hadoop-3.4.1/myshell/xsync
以下是xsync脚本里的内容:
#!/bin/bash
# 1、判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
# 2、遍历集群所有机器
for host in hadoop01 hadoop02 hadoop03
do
echo ===================== $host =====================
# 3、遍历所有目录,逐个发送
for file in $@
do
# 4、判断文件是否存在
if [ -e $file ]
then
# 5、获取父目录
pdir=$(cd -P $(dirname $file); pwd)
# 6、获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
赋权
chmod +x xsync
此时,我们已经在hadoop03上,新建了这个xsync脚本,我们现在就开始将这个脚本,同步到hadoop01、hadoop02机器上
# 输入如下命令
./xsync ../myshell/
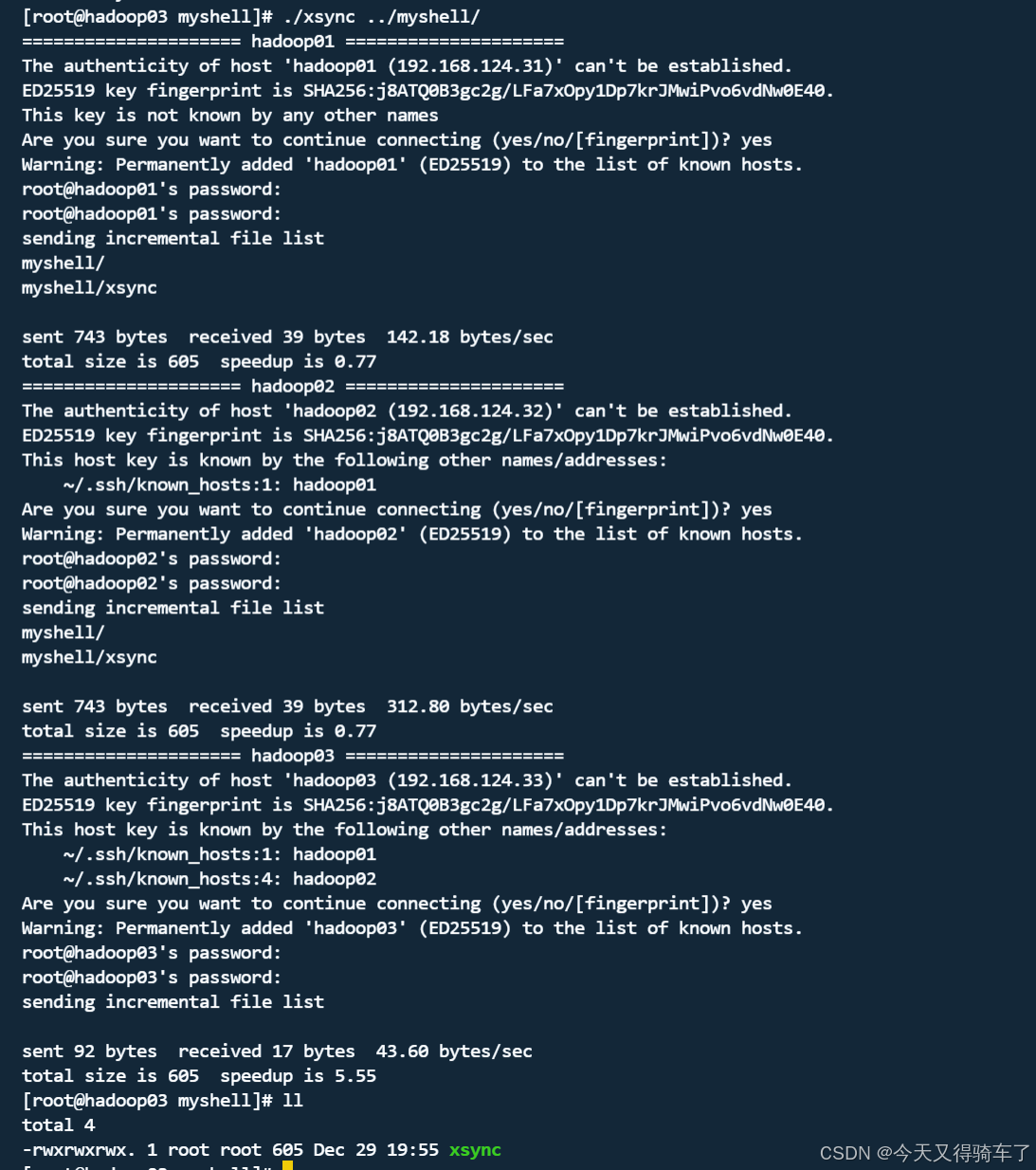
可以看到,在输入密码后,/app/hadoop/hadoop-3.4.1/myshell/xsync都成功同步给了hadoop01、hadoop02了
3.5.3.ssh免密登录配置
在3.5.2中,每次同步,都需要输入命令,机器少还可以,但是也很繁琐。
我们可以配置这些集群服务器之间,免密码登录,再此进行配置文件同步时,就不再需要繁琐的输入命令了。
(1)、配置hadoop01无秘钥登录hadoop02、hadoop03。
在hadoop01下,操作如下:
ssh-keygen -t rsa
然后三次回车
之后会生成公钥id_rsa.pub和私钥id_rsa
然后
# 本身的服务器,也配置免密设置,因为启动Hadoop服务时,能满足任意节点启动,需要这样配置,不然会报权限不足。
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
会出现如下内容:
[root@hadoop01 .ssh]# ssh-copy-id hadoop02
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop02's password: #在这里,会提示输入hadoop02机器的登录密码,输入即可
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop02'"
and check to make sure that only the key(s) you wanted were added.
最后,在hadoop01的机器上,验证是否可以直接通过免密的方式,进行登录
# 进行登录
ssh hadoop02
# 退出
exit
# 操作具体如下,注意看主机名改变了,说明免密登录已经配置完成。
[root@hadoop01 .ssh]# ssh hadoop02
Last login: Sun Dec 29 22:03:39 2024 from 192.168.124.20
[root@hadoop02 ~]# exit
logout
Connection to hadoop02 closed.
[root@hadoop01 .ssh]# ssh hadoop03
Last login: Sun Dec 29 22:03:37 2024 from 192.168.124.20
[root@hadoop03 ~]# exit
logout
Connection to hadoop03 closed.
[root@hadoop01 .ssh]#
至此,已经完成了hadoop01到hadoop02、hadoop03的免密配置访问。
剩下的:
(2)、hadoop02到hadoop01、hadoop03的免密配置
(3)、hadoop03到hadoop01、hadoop02的免密配置
也是一样的操作流程步骤。
从这里开始,需要认真的看每一步的操作,比较繁杂,希望彦祖可以跟得上。
3.6.集群配置
| hadoop01 | hadoop02 | hadoop03 | |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | ResourceManager、NodeManager | NodeManager |
😎配置文件说明:
Hadoop配置文件分为两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
3.6.1.默认配置文件
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| core-default.xml | /app/hadoop/hadoop-3.4.1/share/hadoop/common/hadoop-common-3.4.1.jar /core-default.xml |
| hdfs-default.xml | /app/hadoop/hadoop-3.4.1/share/hadoop/hdfs/hadoop-hdfs-3.4.1.jar/hdfs-default.xml |
| yarn-default.xml | /app/hadoop/hadoop-3.4.1/share/hadoop/yarn/hadoop-yarn-common-3.4.1.jar/yarn-default.xml |
| mapred-default.xml | /app/hadoop/hadoop-3.4.1/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.4.1.jar/mapred-default.xml |
3.6.2.自定义配置文件
当前,以hadoop01为例,在这台服务器上,进行更改这四个配置文件,更改完成后,使用xsync分发脚本进行内容同步到hadoop02、hadoop03机器上。
| 存放位置 | 文件名 |
|---|---|
| /app/hadoop/hadoop-3.4.1/etc/hadoop | hadoop-env.sh |
| /app/hadoop/hadoop-3.4.1/etc/hadoop | core-site.xml |
| /app/hadoop/hadoop-3.4.1/etc/hadoop | hdfs-site.xml |
| /app/hadoop/hadoop-3.4.1/etc/hadoop | yarn-site.xml |
| /app/hadoop/hadoop-3.4.1/etc/hadoop | mapred-site.xml |
下面进行逐个配置:
3.6.2.1.hadoop-env.sh 配置JDK的环境变量
vim hadoop-env.sh
# 在末尾追加
# JDK17环境变量配置
export JAVA_HOME=/app/java/jdk-17.0.12
# 解决遇到的 java.lang.reflect.InaccessibleObjectException 错误
# 由于 JDK 17 和 Java 模块系统的兼容性问题导致的。
# Java 9 及以上版本引入了 模块系统,需要显式地打开特定的模块才能允许访问某些类。
export HADOOP_OPTS="$HADOOP_OPTS --add-opens java.base/java.lang=ALL-UNNAMED"
export YARN_OPTS="$YARN_OPTS --add-opens java.base/java.lang=ALL-UNNAMED"
3.6.2.2.core-site.xml 配置文件
vim core-site.xml
以下是配置的完整内容
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<!-- 指定hadoop数据存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop/hadoop-3.4.1/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为admin -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>admin</value>
</property>
</configuration>
3.6.2.2.hdfs-site.xml 配置文件
vim hdfs-site.xml
以下是配置的完整内容
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- NameNode web访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop01:9870</value>
</property>
<!-- SecondaryNameNode web 端访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop03:9868</value>
</property>
</configuration>
3.6.2.3.yarn-site.xml 配置文件
vim yarn-site.xml
以下是配置的完整内容
<?xml version="1.0"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop02</value>
</property>
</configuration>
3.6.2.4.mapred-site.xml 配置文件
vim mapred-site.xml
以下是配置的完整内容
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce作业运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
🐮🐮🐮之后,配置workers
vim /app/hadoop/hadoop-3.4.1/etc/hadoop/workers
最后,进行内容分发或者拷贝到剩余的服务器上,当服务器多的时候,内容分发的脚本,就显得尤为重要了。
下面使用 3.5.配置内容分发 步骤的脚本xsync脚本进行操作,
🚴🚴🚴 开始同步🚴🚴🚴
/app/hadoop/hadoop-3.4.1/myshell/xsync /app/hadoop/hadoop-3.4.1/etc/hadoop/
4.启动集群
4.1.初始化
前期准备搞了那么久,终于可以启动集群看看情况了。
因为我们是第一次,第一次嘛,肯定要初始化,格式化NameNode。
注意:格式化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode的话,一定要先停止 NameNode 和 DataNode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式化。
cd /app/hadoop/hadoop-3.4.1/bin
hdfs namenode -format
初始化完毕后,会在/app/hadoop/hadoop-3.4.1 下,生成了一个data文件夹和logs文件夹
cd /app/hadoop/hadoop-3.4.1
ll -lrt
#
[root@hadoop01 hadoop-3.4.1]# ll -lrt
total 92
-rw-rw-r--. 1 1024 1024 175 Jul 16 03:54 README.txt
-rw-rw-r--. 1 1024 1024 1541 Jul 16 03:54 NOTICE.txt
-rw-rw-r--. 1 1024 1024 27165 Jul 16 03:54 NOTICE-binary
-rw-rw-r--. 1 1024 1024 15696 Jul 16 03:54 LICENSE.txt
-rw-rw-r--. 1 1024 1024 23759 Sep 17 04:47 LICENSE-binary
drwxr-xr-x. 3 1024 1024 4096 Oct 9 22:59 sbin
drwxr-xr-x. 3 1024 1024 20 Oct 9 22:59 etc
drwxr-xr-x. 2 1024 1024 4096 Oct 10 00:36 licenses-binary
drwxr-xr-x. 3 1024 1024 20 Oct 10 00:36 lib
drwxr-xr-x. 2 1024 1024 4096 Oct 10 00:36 bin
drwxr-xr-x. 2 1024 1024 106 Oct 10 00:36 include
drwxr-xr-x. 4 1024 1024 4096 Oct 10 00:36 libexec
drwxr-xr-x. 4 1024 1024 31 Oct 10 01:09 share
drwxr-xr-x. 2 root root 19 Dec 29 19:55 myshell
drwxr-xr-x. 2 root root 37 Dec 29 21:35 logs
drwxr-xr-x. 3 root root 17 Dec 29 21:35 data
4.2.集群的所有环境变量,验证是否存在如下内容(其实在3.3配置环境变量我们已经配置了)
vim /etc/profile
追加内容
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
使其生效
source /etc/profile
4.3.启动HDFS
启动HDFS在任意一个节点操作,都可以
cd /app/hadoop/hadoop-3.4.1/sbin
./start-dfs.sh
# 激动人心的时刻
[root@hadoop01 sbin]# ./start-dfs.sh
Starting namenodes on [hadoop01]
Starting datanodes
hadoop02: datanode is running as process 1943. Stop it first and ensure /tmp/hadoop-root-datanode.pid file is empty before retry.
hadoop03: datanode is running as process 1904. Stop it first and ensure /tmp/hadoop-root-datanode.pid file is empty before retry.
Starting secondary namenodes [hadoop03]
hadoop03: secondarynamenode is running as process 1960. Stop it first and ensure /tmp/hadoop-root-secondarynamenode.pid file is empty before retry.
4.4.启动YARN
启动YARN,必须在hadoop02上,注意,是❗️❗️❗️hadoop02❗️❗️❗️
帅气的彦祖可能会问,为什么在hadoop02上启动,为什么???
因为最初开始的时候,我们规划,是在hadoop02 上进行ResourceManager的配置的。
| hadoop01 | hadoop02 | hadoop03 | |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | ResourceManager、NodeManager | NodeManager |
cd /app/hadoop/hadoop-3.4.1/sbin
./start-yarn.sh
# 出现如下:
[root@hadoop02 sbin]# ./start-yarn.sh
WARNING: YARN_OPTS has been replaced by HADOOP_OPTS. Using value of YARN_OPTS.
Starting resourcemanager
WARNING: YARN_OPTS has been replaced by HADOOP_OPTS. Using value of YARN_OPTS.
Starting nodemanagers
WARNING: YARN_OPTS has been replaced by HADOOP_OPTS. Using value of YARN_OPTS.
hadoop03: WARNING: YARN_OPTS has been replaced by HADOOP_OPTS. Using value of YARN_OPTS.
hadoop02: WARNING: YARN_OPTS has been replaced by HADOOP_OPTS. Using value of YARN_OPTS.
hadoop01: WARNING: YARN_OPTS has been replaced by HADOOP_OPTS. Using value of YARN_OPTS.
4.5.验证所有服务
最后,我们来验证一下,启动的HDFS 是否和我们最初预规划的一致
| hadoop01 | hadoop02 | hadoop03 | 是否一致 | |
|---|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode | ✅ |
| YARN | NodeManager | ResourceManager、NodeManager | NodeManager | ✅ |
在hadoop01上
[root@hadoop01 sbin]# jps
5906 Jps
5159 NameNode
5722 NodeManager
5356 DataNode
在hadoop02上
[root@hadoop02 sbin]# jps
3313 DataNode
4178 Jps
3558 ResourceManager
3707 NodeManager
在hadoop03上
[root@hadoop03 sbin]# jps
4004 NodeManager
3803 SecondaryNameNode
3692 DataNode
4172 Jps
至此,彦祖你已经完成了Hadoop完全分布式集群的搭建。彦祖🐮🍺
三、访问一些web页面
| 节点 | 类型 | 地址 | 说明 |
|---|---|---|---|
| hadoop01 | HDFS | http://192.168.124.31:9870 | NameNode web访问地址 |
| hadoop03 | HDFS | http://192.168.124.33:9868 | SecondaryNameNode web 端访问地址 |
| hadoop02 | YARN | http://192.168.124.32:8088 | YARN web 端访问地址 |
注意
如果浏览器无法打开页面,可能是防火墙开启了,端口被限制,需要将防火墙关闭掉
# 关闭防火墙
systemctl stop firewalld
# 禁止开机启动
systemctl disable firewalld
NameNode web访问地址
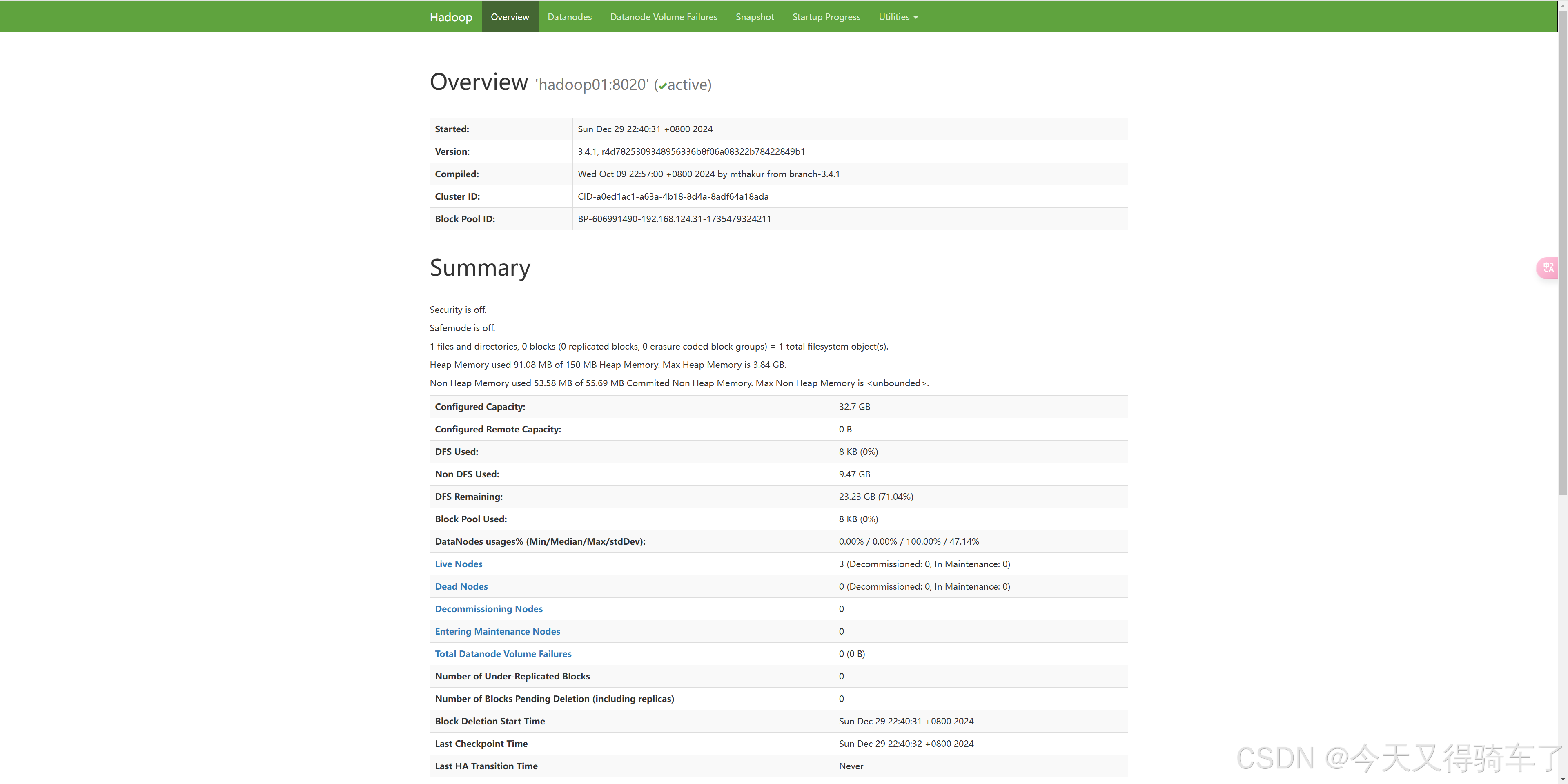
SecondaryNameNode web 端访问地址
YARN web 端访问地址
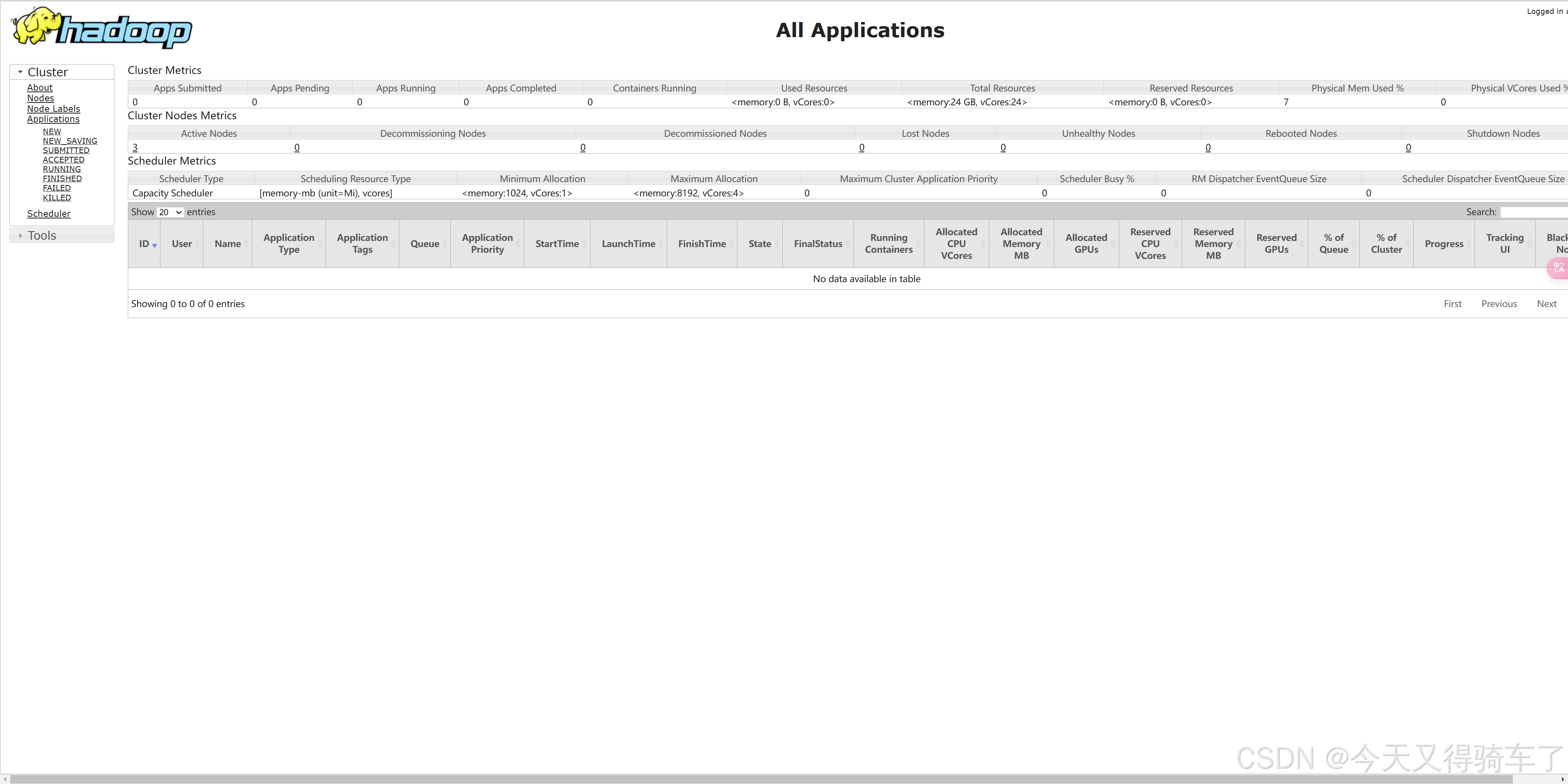
四、集群基本测试
1.上传文件到集群
在hadoop01机器上,将测试的文件都放在/app/testData下
1.1.小文件
mkdir -p /app/testData
cd /app/testData
touch test.txt
以下是test.txt的文件内容,彦祖你应该看得懂什么意思,憋说傲~
🐔🏀
ikun
amagi
kunkun
xiaoheizi
lizhi
lizhi
lizhi2.0
ikun
amagi
kunkun
jidan
chilaofan
🐔🏀
1.2.大文件
大文件上传JDK吧
cp /app/java/jdk-17.0.12_linux-x64_bin.tar.gz /app/testData
# 创建hadoop存放文件的目录
hadoop fs -mkdir /ikun
执行完命令后访问下面的地址,查询
| 节点 | 类型 | 地址 | 说明 |
|---|---|---|---|
| hadoop01 | HDFS | http://192.168.124.31:9870 | NameNode web访问地址 |
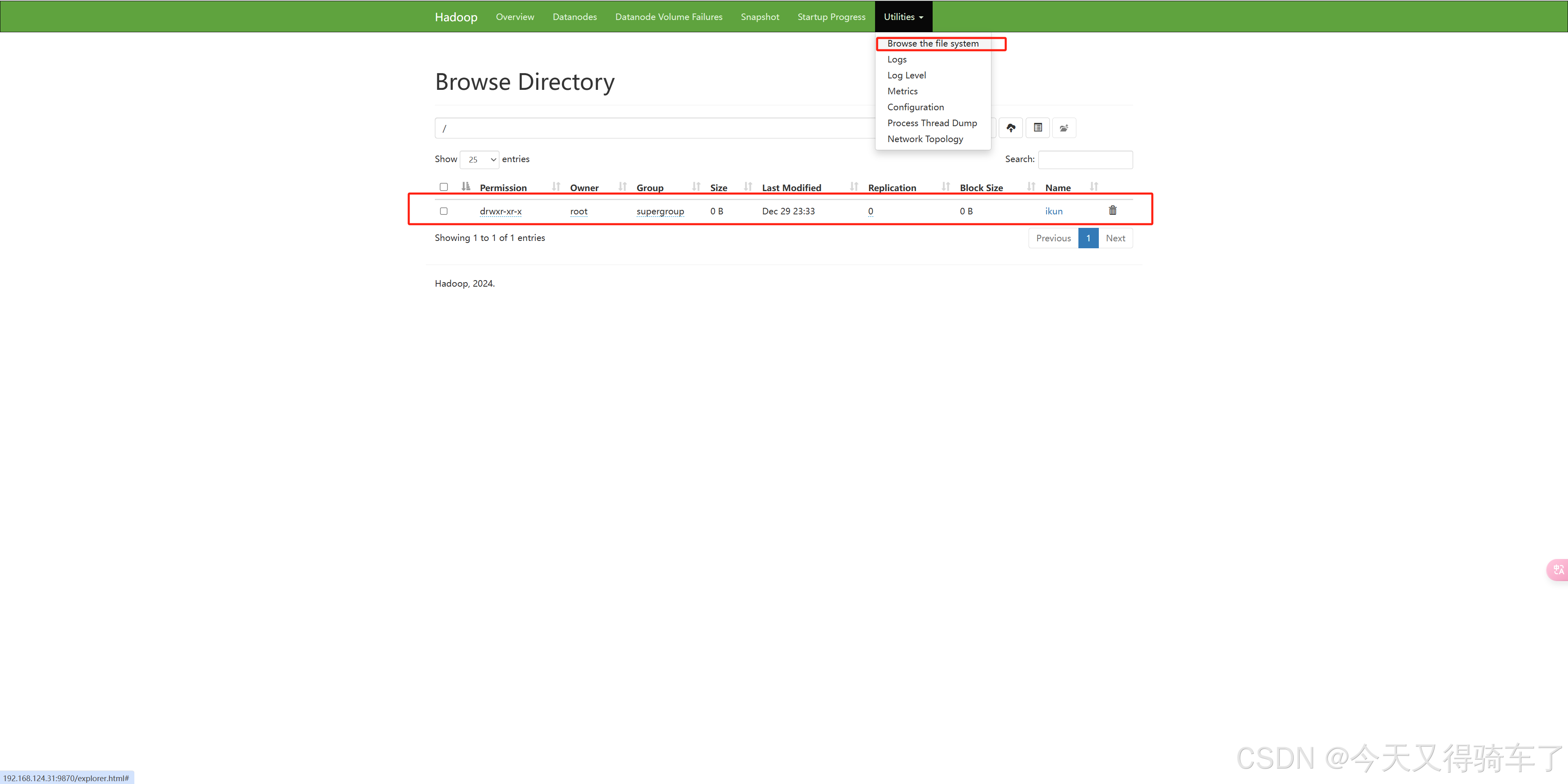
依次上传小文件,大文件
# 小文件
hadoop fs -put /app/testData/test.txt /ikun
# 大文件
hadoop fs -put /app/testData/jdk-17.0.12_linux-x64_bin.tar.gz /ikun
可以看到,此时两个文件已经上传完成
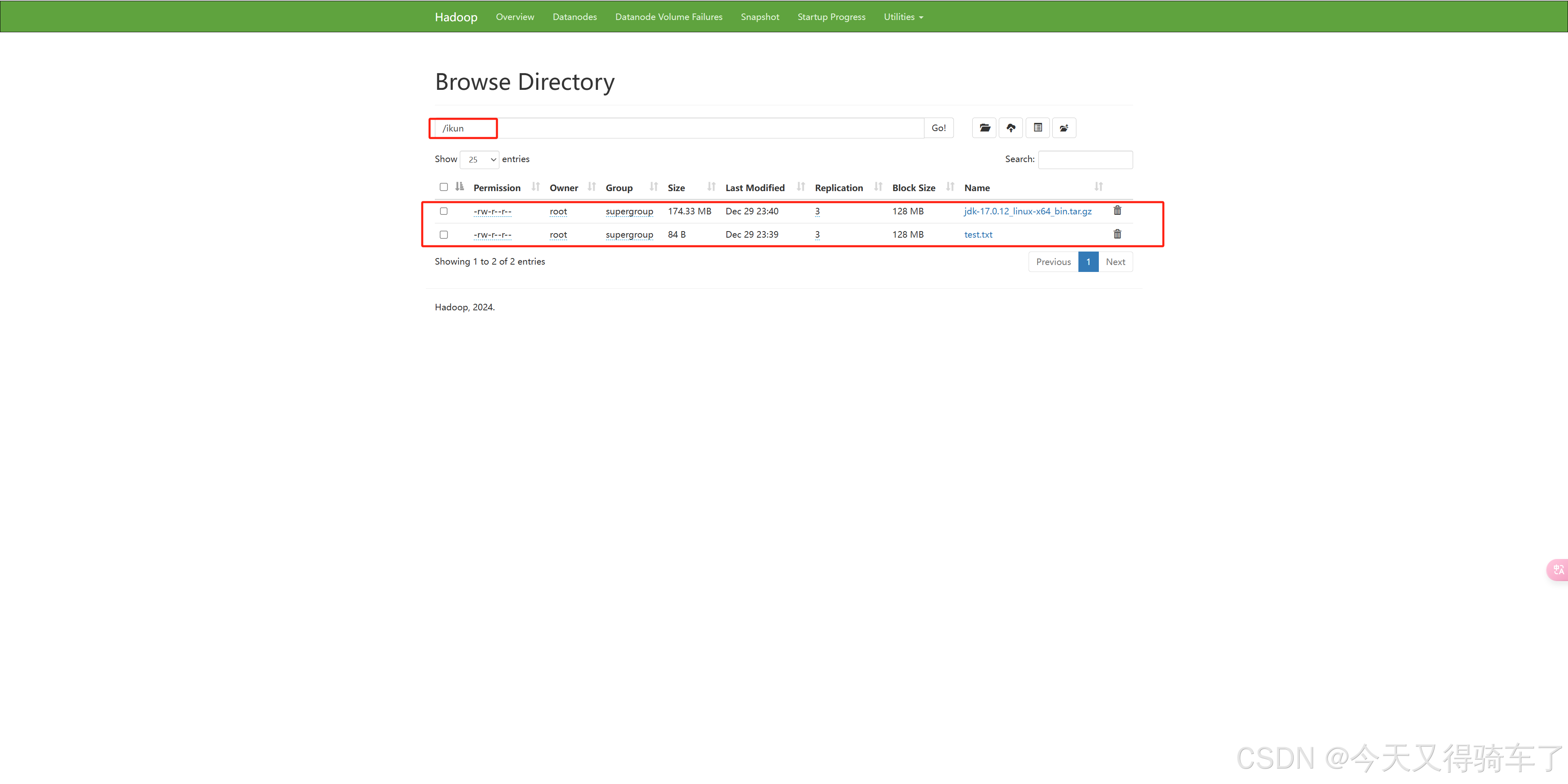
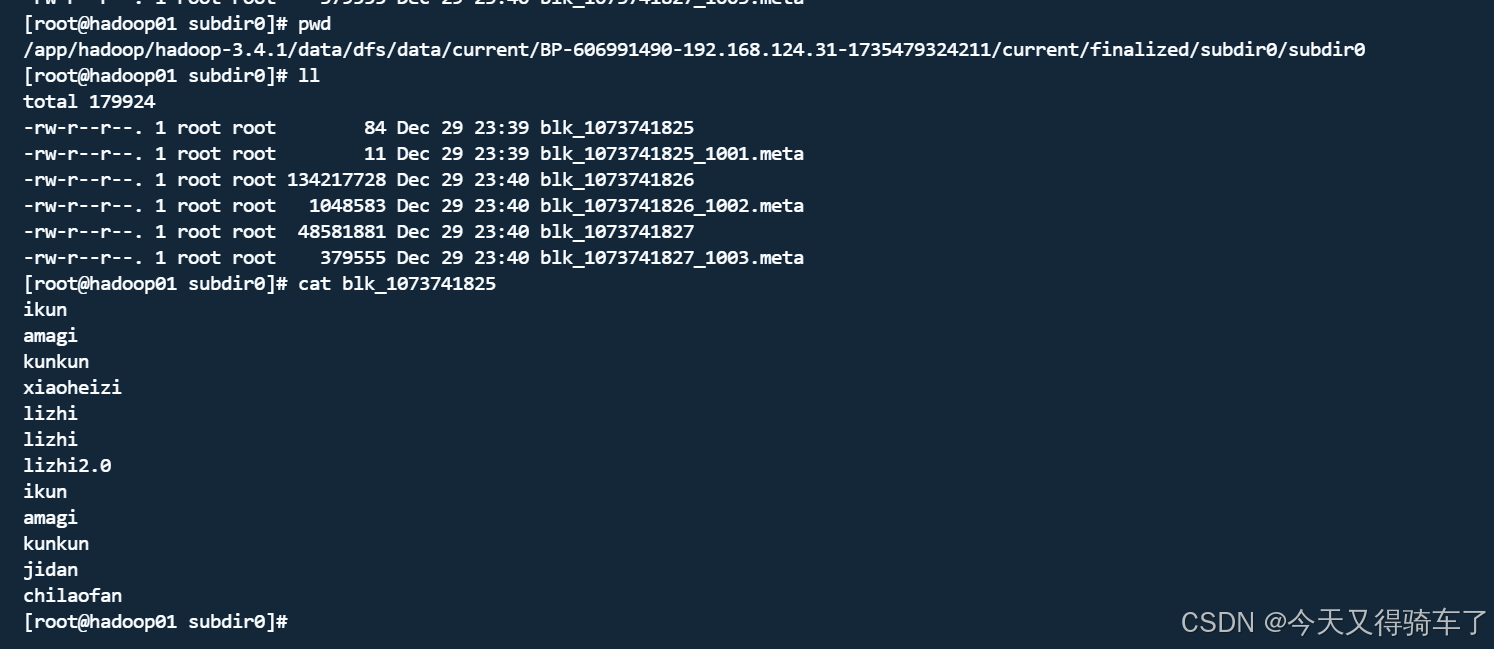
2.查看上传的文件存放位置
之前配置的core-site.xml文件,配置的存储的位置就是这里
cd /app/hadoop/hadoop-3.4.1/data
之后一路进来
是不是感觉很熟悉,这不就是我们刚刚上传的ikun文件吗?🐔🏀
3.验证任务
我们执行wordcount程序,都是集群上的路径
/ikun是集群下的,我们刚刚创建的
/ikun/xiaoheizi等会是生成wordcount结果的路径
这两个路径,都是集群上的路径。
在运行的时候,我们可以查看如下的页面
| 节点 | 类型 | 地址 | 说明 |
|---|---|---|---|
| hadoop02 | YARN | http://192.168.124.32:8088 | YARN web 端访问地址 |
运行之前
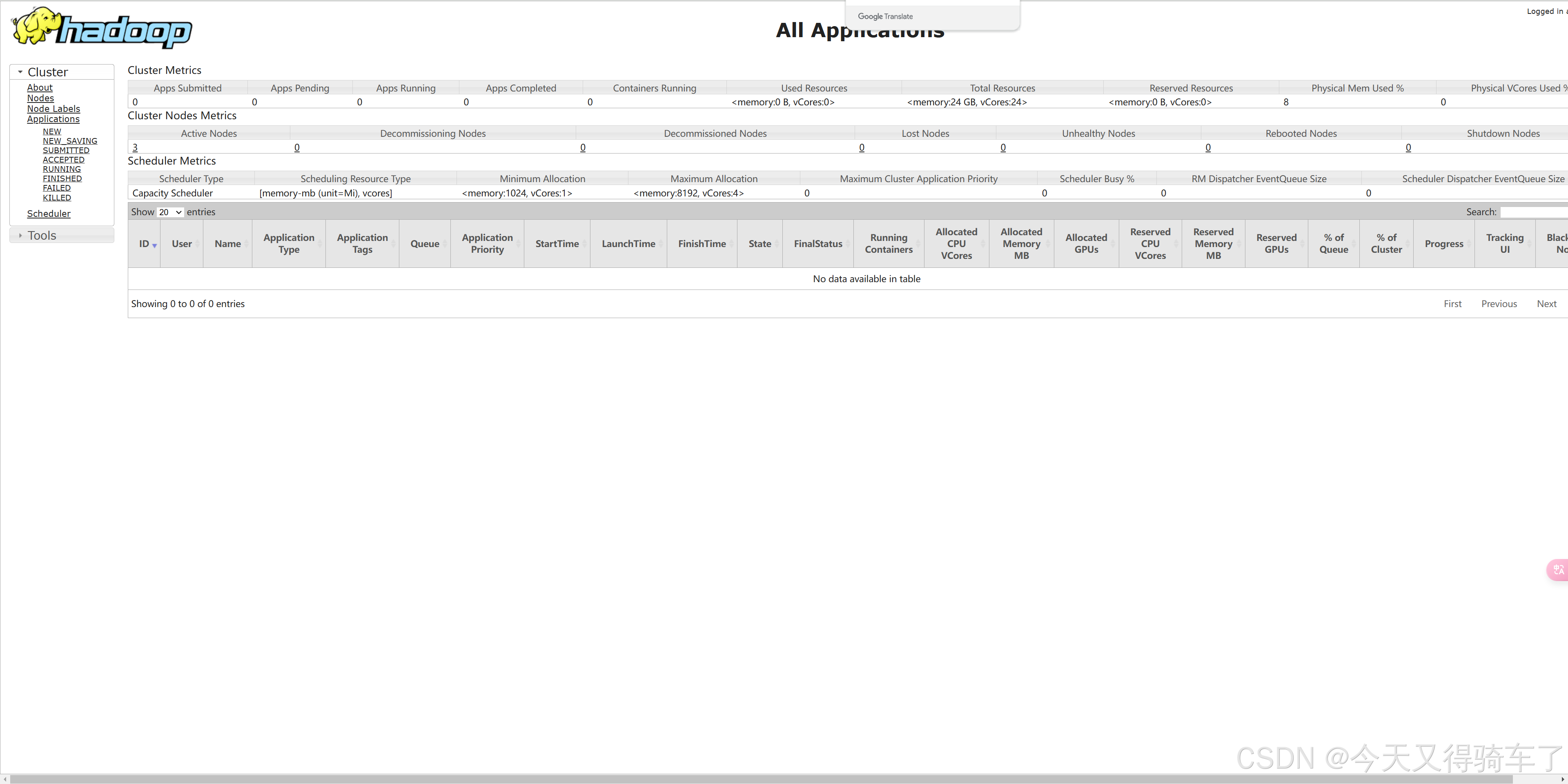
运行时
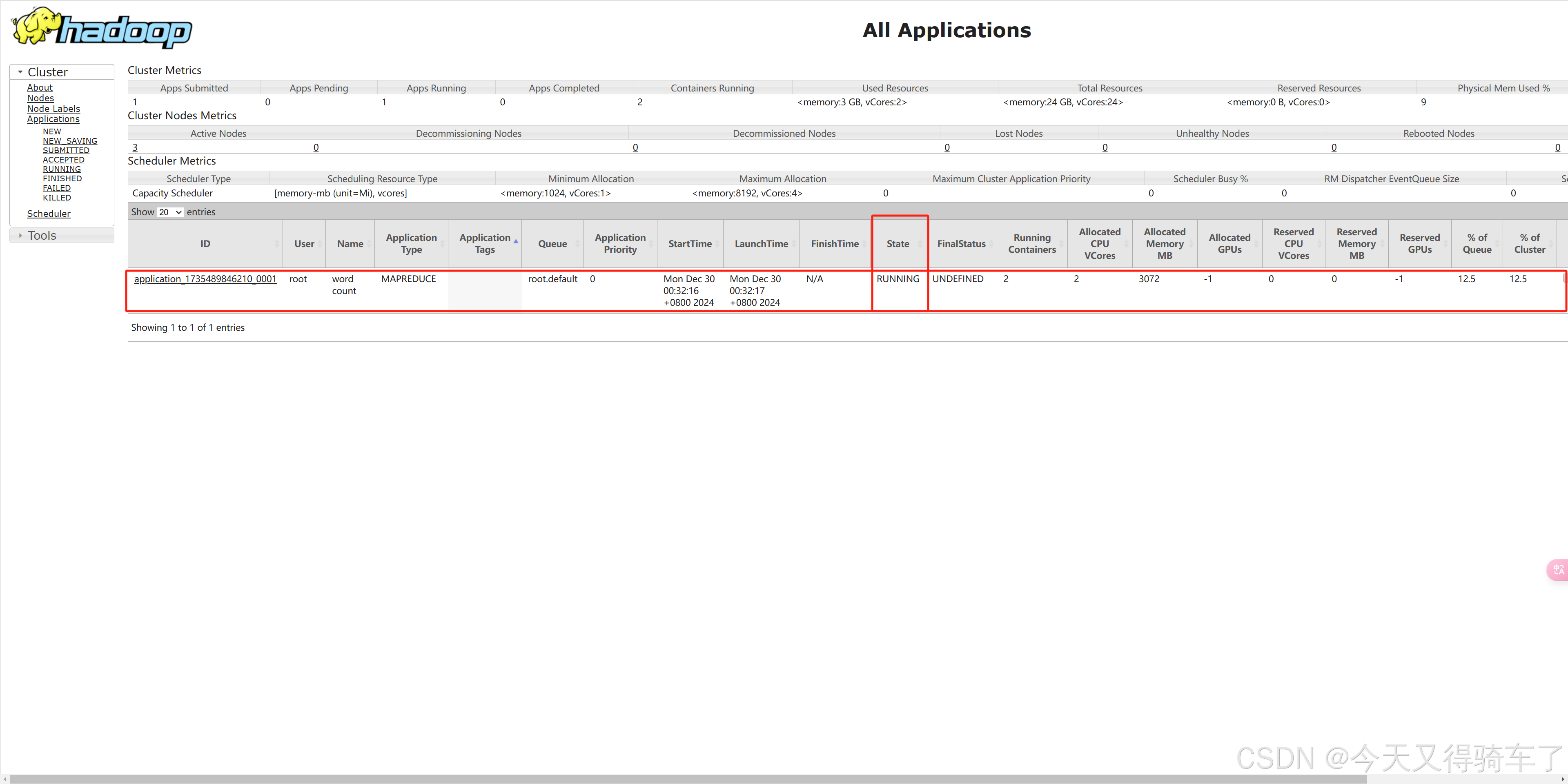
运行结束
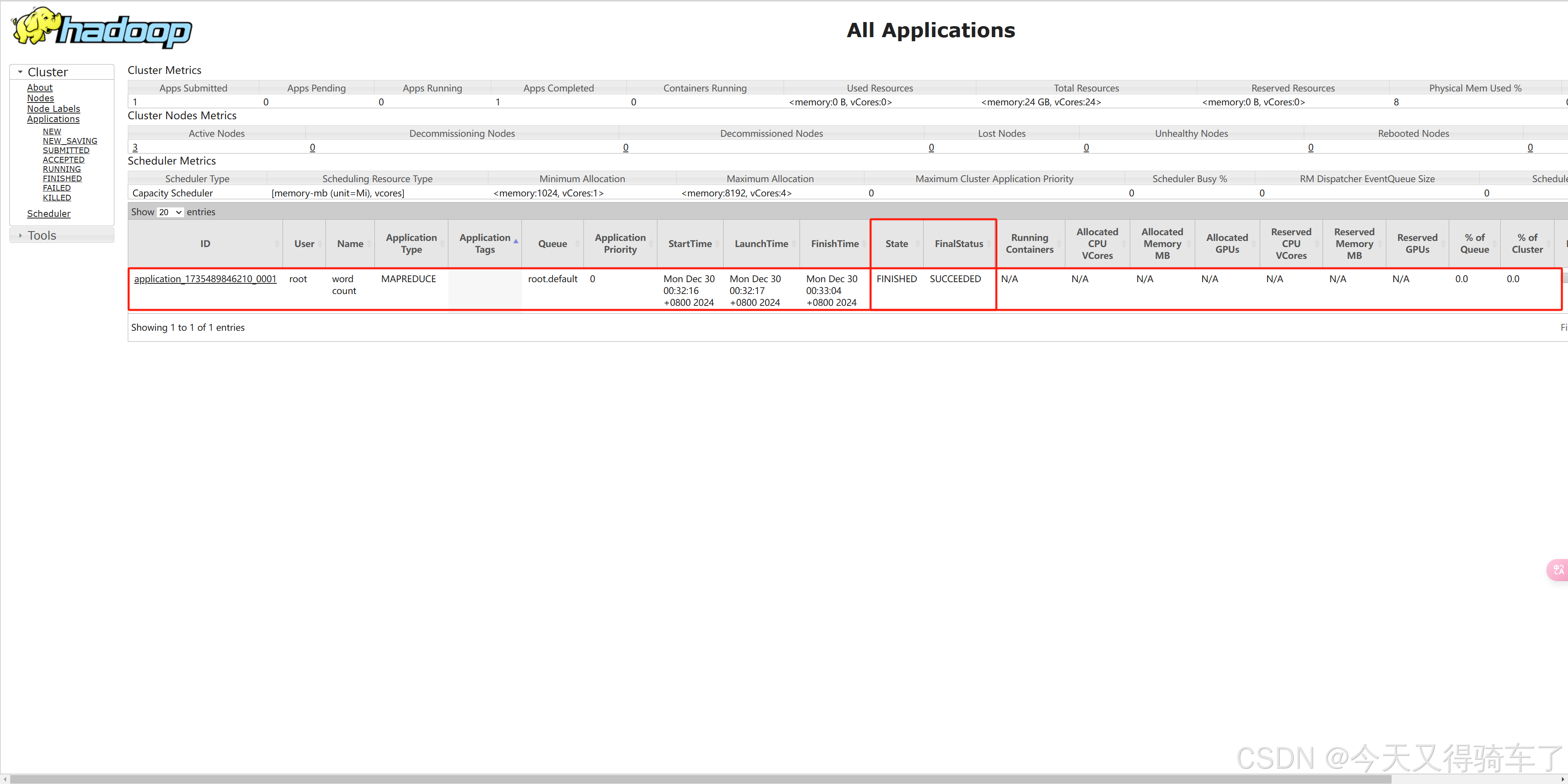
最终生成了
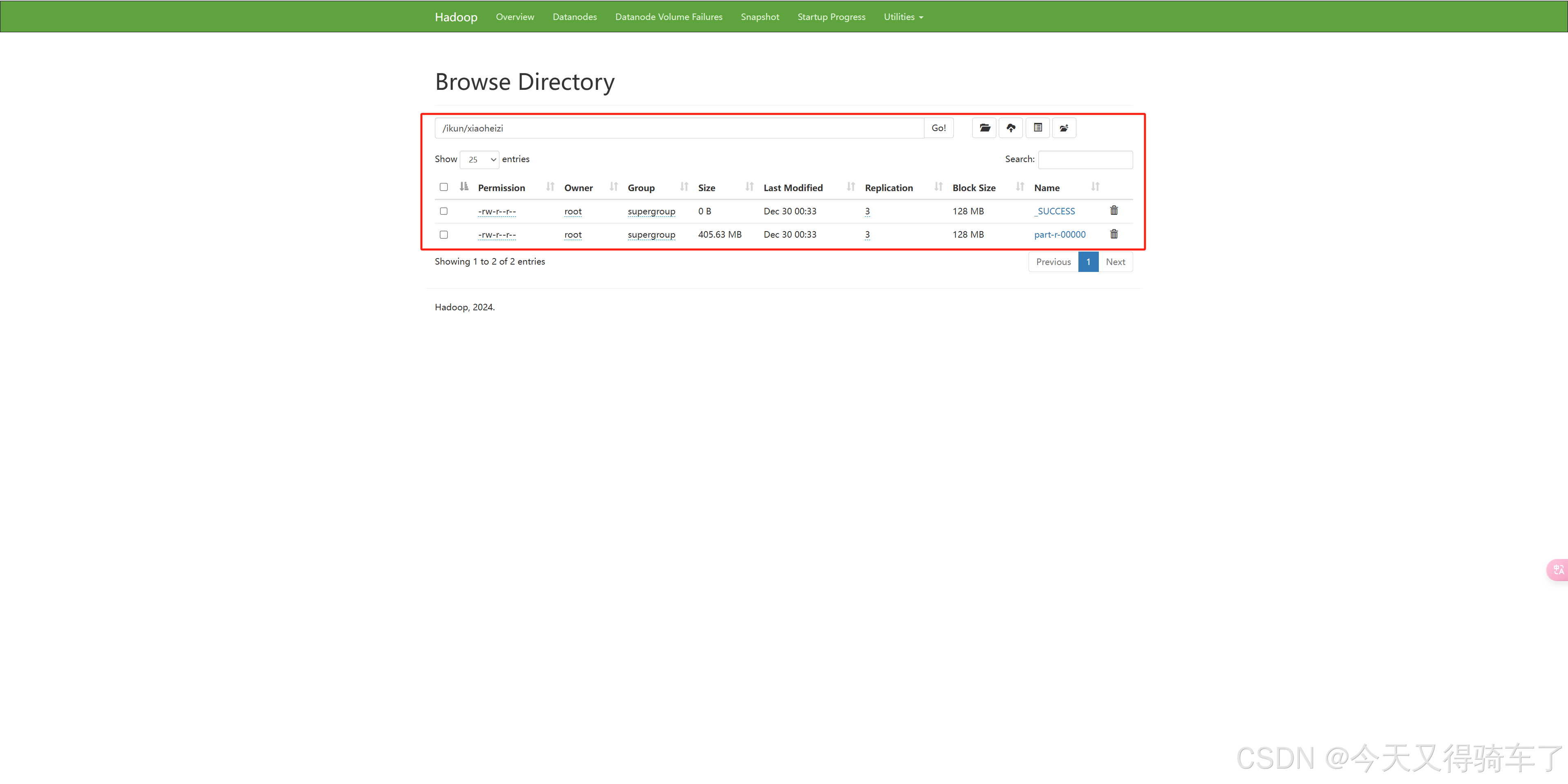
至此,我们的hadoop完全分布式集群,已经全部安装验证完成!
文章如若有误,请指正,谢谢!
总结
1、首先,我们先在服务器上,安装Oracle JDK17,并且配置好了JDK的环境变量。
2、登录Hadoop官网,下载Hadoop 3.4.1 版本
3、针对安装Hadoop之前,调整了主机名和hosts,并且编写了同步分发脚本xsync,设置集群之间免密登录,目的是为了让集群能够更方便的同步配置文件和管理服务的启停。
4、从3.6集群配置开始,操作上比较繁琐,但是针对配置文件,都可以直接复制粘贴,主要是一些操作上的问题。
5、启动Hadoop集群,启动HDFS服务,启动YARN服务
6、大小文件上传测试,并且执行wordcount程序,验证MapReduce。
学不完,根本学不完😭😭😭

















 1066
1066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









