




 本文深入探讨Python中的字符串数据类型,包括其基本概念、常见操作、格式化方法及性能优化技巧,适合初学者和进阶者阅读。
本文深入探讨Python中的字符串数据类型,包括其基本概念、常见操作、格式化方法及性能优化技巧,适合初学者和进阶者阅读。
字符串同样是 Python 中很常见的一种数据类型,比如日志的打印、程序中函数的注释、数据库的访问、变量的基本操作等等,都用到了字符串。
字符串基础
字符串是由独立字符组成的一个序列,通常包含在单引号(’’)双引号(" “)或者三引号之中(’’’ ‘’'或”"" “”",两者一样),Python 中单引号、双引号和三引号的字符串是一模一样的,没有区别,同时支持这三种表达方式很重要的一个原因就是,方便在字符串中内嵌带引号的字符串。另外,Python 的三引号字符串,主要应用于多行字符串的情境,比如函数的注释等等。
Python 也支持转义字符。所谓的转义字符,就是用反斜杠开头的字符串,来表示一些特定意义的字符。常见的的转义字符如下:
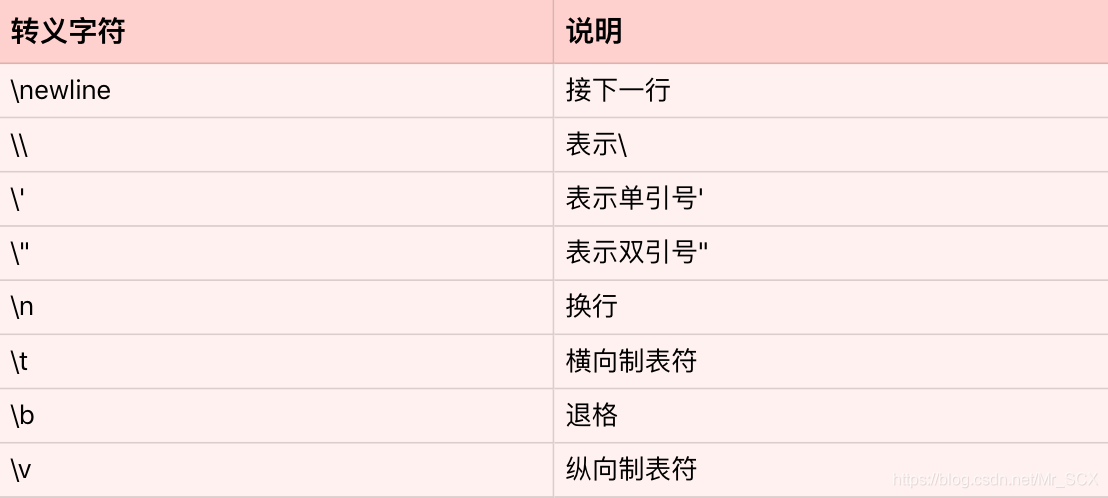
在转义字符的应用中,最常见的就是换行符 \n 的使用。比如文件读取,如果我们一行行地读取,那么每一行字符串的末尾,都会包含换行符 \n。而最后做数据处理时,我们往往会丢掉每一行的换行符。
字符串的常用操作
字符串可以想象成一个由单个字符组成的数组,所以,Python 的字符串同样支持索引,切片和遍历等等操作。如列表、元组一样,字符串的索引同样从 0 开始,[0 : index+1]则表示第 0 个元素到第 index 个元素组成的子字符串。而遍历字符串同样很简单,相当于遍历字符串中的每个字符。
要注意的是,Python 的字符串是不可变的(immutable)。因此,Python 中字符串的改变,通常只能通过创建新的字符串来完成。举个例子,如果要把 ‘hello’ 的第一个字符 ‘h’,改为大写的 ‘H’,可以采用以下做法:
- 第一种方法,直接用大写的 ‘H’,通过加号 ‘+’ 操作符,与原字符串切片操作的子字符串拼接而成新的字符串。
s = 'hello'
s = 'H' + s[1:]
s
'Hello'
- 第二种方法,直接扫描原字符串,把小写的 ‘h’ 替换成大写的 ‘H’,得到新的字符串。
s = 'hello'
s = s.replace('h', 'H')
s
'Hello'
因此,在Python 中,每次想要改变字符串,往往需要 O(n) 的时间复杂度,其中,n 为新字符串的长度。不过,随着版本的更新,Python 也越来越聪明,字符串操作的性能优化得越来越好了。比如,使用加等于操作符 ‘+=’ 的字符串拼接方法就是一个例外,打破了字符串不可变的特性。我们来分析一下下面这个例子的时间复杂度:
s = ''
for n in range(0, 100000):
s += str(n)
每次循环,由于要改变字符串 s,似乎都得创建一个新的字符串;而每次创建一个新的字符串,都需要 O(n) 的时间复杂度。因此,总的时间复杂度就为 O(1) + O(2) + … + O(n) = O(n2)。这样到底对不对呢?
乍一看,这样分析好像很有道理,但是必须说明一下,这个结论只适用于老版本的 Python 了。自从 Python2.5 开始,每次处理字符串的拼接操作时(str1 += str2),Python 首先会检测 str1 还有没有其他的引用。如果没有的话,就会尝试原地扩充字符串 buffer 的大小,而不是重新分配一块内存来创建新的字符串并拷贝。这样的话,上述例子中的时间复杂度就仅为 O(n) 了。
另外,对于字符串拼接问题,除了使用 ‘+=’ 操作符,我们还可以使用字符串内置的 join 函数。Python str.join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。这个字符串的操作类似列表中的 append 操作,时间复杂度是 O(1)。
s = "-";
seq = ("a", "b", "c"); # 字符串序列
s.join( seq )
'a-b-c'
# 上面的例子将 '+='操作符换成 str.join() 方法
l = []
for n in range(0, 100000):
l.append(str(n))
s = ''.join(l)
比较上述两种字符串拼接方式,如果字符串拼接的次数较少,比如range(100),那么方法一(使用 ‘+=’ 操作符)更优,因为时间复杂度精确的来说第一种是O(n),第二种是O(2n);但如果拼接的次数较多,比如range(1000000),方法二(使用字符串内置的 join 函数)稍快一些,虽然方法二会遍历两次,但是join的速度其实很快,列表append和join的总开销要比字符串 ‘+=’ 操作小一些。此外,这里再提一个更加高效的改进:
s = " ".join(map(str, range(0, 10000))) # 采用map()映射函数替换 for循环
此外,常见的函数还有:
- string.split(separator),表示把字符串按照 separator 分割成子字符串,并返回一个分割后子字符串组合的列表。它常常应用于对数据的解析处理。比如我们读取了某个文件的路径,想要调用数据库的 API,去读取对应的数据,通常会写成下面这样:
path = 'hive://ads/training_table'
namespace = path.split('//')[1].split('/')[0] # 返回'ads'
table = path.split('//')[1].split('/')[1] # 返回 'training_table'
- string.strip(str),表示去掉首尾的 str 字符串,比如很多时候,从文件读进来的字符串中,开头和结尾都含有空字符,我们需要去掉它们,就可以用 strip() 函数;
- string.lstrip(str),表示只去掉开头的 str 字符串;
- string.rstrip(str),表示只去掉尾部的 str 字符串。
- string.find(sub, start, end),表示从 start 到 end 查找字符串中指定范围内某个子字符串 sub 的位置,如果包含该子字符串,返回开始的索引值,否则返回-1。
字符串的格式化
通常,我们使用一个字符串作为模板,模板中会有格式符。这些格式符为后续真实值预留位置,以呈现出真实值应该呈现的格式。字符串的格式化,通常会用在程序的输出、logging 等场景。
举一个常见的例子。比如我们有一个任务,给定一个用户的 userid,要去数据库中查询该用户的一些信息,并返回。而如果数据库中没有此人的信息,我们通常会记录下来,这样有利于往后的日志分析,或者是线上 bug 的调试等等。通常会用下面的方法来打印输出:
print('no data available for person with id: {}, name: {}'.format(user_id, user_name))
这里的 string.format() 就是所谓的格式化函数,而大括号 {} 就是所谓的格式符,用来为后面的真实值——变量 name 预留位置。如果 user_id = ‘123’、user_name = ‘jason’,那么输出便是:
'no data available for person with id: 123, name: jason'
string.format() 是 Python 中最新的字符串格式函数与规范。在 Python 之前的版本中,字符串格式化通常是用 % 来表示,那么上述的例子也可以写成下面这样:
print('no data available for person with id: %s, name: %s' % (user_id, user_name))
# %s 表示字符串型,%d 表示整型,%f 表示浮点型
当然,现在写 python 程序时还是推荐使用 format 函数,毕竟这是最新规范,也是官方文档推荐的规范。此外,在很多情况下,字符串拼接也能满足格式化函数的需求。但是使用格式化函数,更加清晰、易读,并且更加规范,不易出错。
参考
《Python核心技术与实战》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









