




声明:本公众号所有文章均仅限个人学习或技术研究使用,不可用作任何违法获利或任何不良诱导宣传。如有类似事情发生,与本频道无关。
一、背景知识介绍
1、什么是OWL?
借用官方团队的话来说,OWL 是一个前沿的多智能体协作框架,推动任务自动化的边界,构建在CAMEL-AI Framework(Github官方链接https://github.com/camel-ai/camel,该框架使多智能体系统能够通过生成数据和与环境交互来不断发展,具有强可扩展性,支持具有数百万代理的系统,确保大规模的有效协调,通信和资源管理。)。团队的愿景是彻底变革 AI 智能体协作解决现实任务的方式。通过利用动态智能体交互,OWL 实现了跨多领域更自然、高效且稳健的任务自动化。
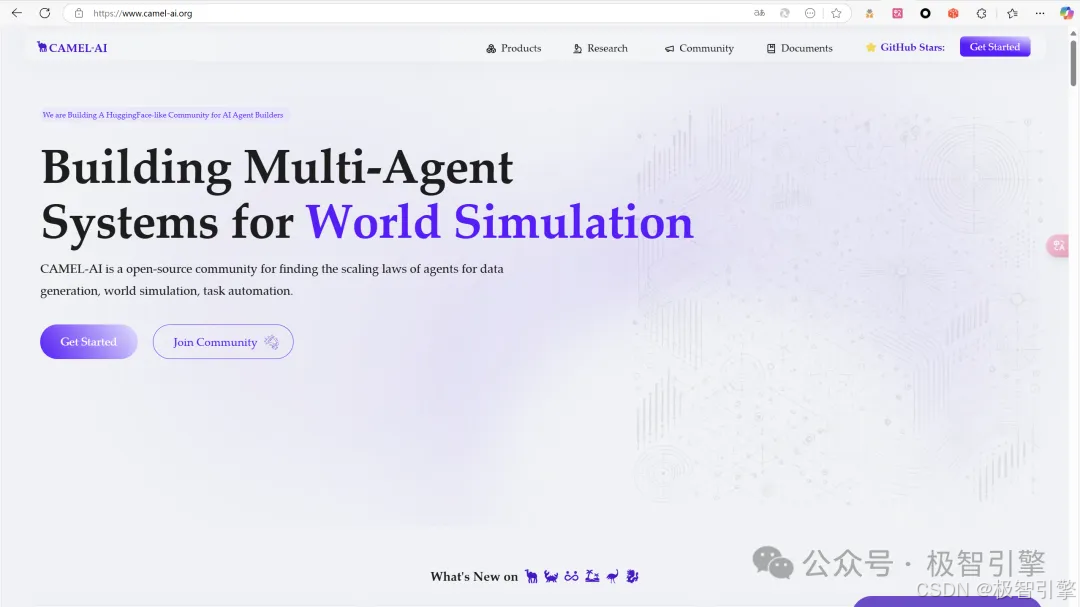
2、OWL的核心功能
如下图所示,OWL结合多AI大模型协作以及各类工具包调用来解决真实世界的各种问题。参考官方文档,OWL的核心功能如下:
在线搜索:支持多种搜索引擎(包括维基百科、Google、DuckDuckGo、百度、博查等),实现实时信息检索与知识获取
多模态处理:支持互联网或本地视频、图片、语音
处理浏览器操作:借助Playwright框架开发浏览器模拟交互,支持页面滚动、点击、输入、下载、历史回退等功能
文件解析:word、excel、PDF、PowerPoint信息提取,内容转文本/Markdown
代码执行:编写python代码,并使用解释器运行
丰富工具包:提供丰富的工具包,包括ArxivToolkit(学术论文检索)、AudioAnalysisToolkit(音频分析)、CodeExecutionToolkit(代码执行)、DalleToolkit(图像生成)、DataCommonsToolkit(数据共享)、ExcelToolkit(Excel处理)、GitHubToolkit(GitHub交互)、GoogleMapsToolkit(地图服务)、GoogleScholarToolkit(学术搜索)、ImageAnalysisToolkit(图像分析)、MathToolkit(数学计算)、NetworkXToolkit(图形分析)、NotionToolkit(Notion交互)、OpenAPIToolkit(API操作)、RedditToolkit(Reddit交互)、SearchToolkit(搜索服务)、SemanticScholarToolkit(语义学术搜索)、SymPyToolkit(符号计算)、VideoAnalysisToolkit(视频分析)、WeatherToolkit(天气查询)、BrowserToolkit(网页交互)等多种专业工具,满足各类特定任务需求。
3、什么是playwright?
playwright-python(常被称作playwright)是微软开源的跨浏览器自动化测试工具,OWL有用到该工具来调用浏览器进行自动化工作,以下是关键信息:
核心功能
多浏览器支持:Chromium/Firefox/WebKit
自动化操作:页面导航、点击、表单填写、截图等
无头模式:可在无界面环境下运行
网络拦截:模拟API响应、处理请求
移动端模拟:支持设备型号模拟(如iPhone 13)
二、OWL环境搭建
OWL官方提供了多种方式的环境部署安装,包括uv、venv、conda、Docker等,上节【OpenManus部署】Manus平替OpenManus真的好用吗?手把手带你部署并运行OpenManus(不需要魔法)我们在部署OpenManus的时候python虚拟环境创建工具使用的是conda,这次我们沿用上次的方法来部署,不知道怎么安装conda的大家可以参考上节内容。
1、Python Conda环境创建
在自己想要部署OWL的目录,按照上节【OpenManus部署】Manus平替OpenManus真的好用吗?手把手带你部署并运行OpenManus(不需要魔法)文章中介绍的方法安装miniconda后,在PowerShell中运行如下命令创建并启动owl的python Conda环境
conda create -n owl python=3.10
conda activate owl
创建conda环境
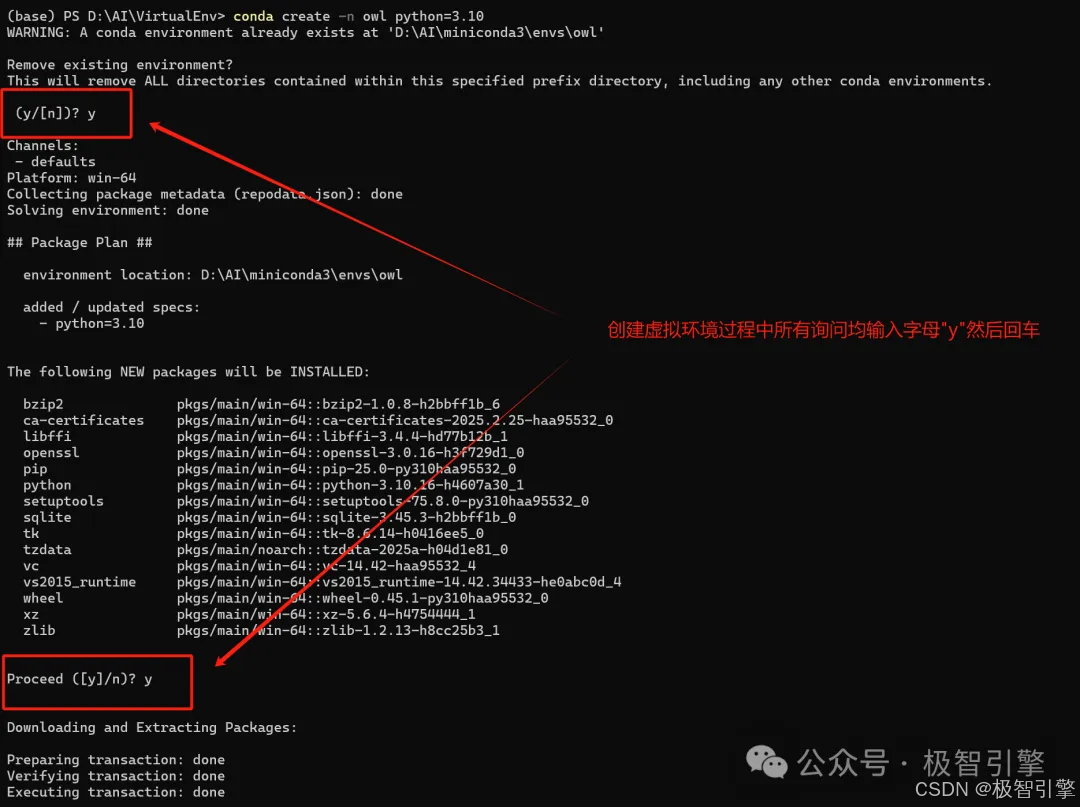
激活conda环境

2、克隆OWL代码(听核心工程师说昨晚有更新哦,新版更稳定)
git clone https://github.com/camel-ai/owl.git
PowerShell切换到你要部署OWL的文件目录,运行如上代码后,等待代码下载完成,如下图所示:
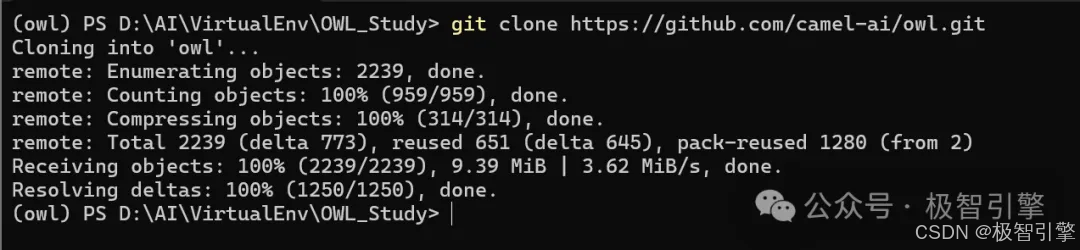
然后运行如下命令,进入owl目录
#Windows CMD
cd .\owl
#Linux/Mac/Windows Powershell
cd ./owl
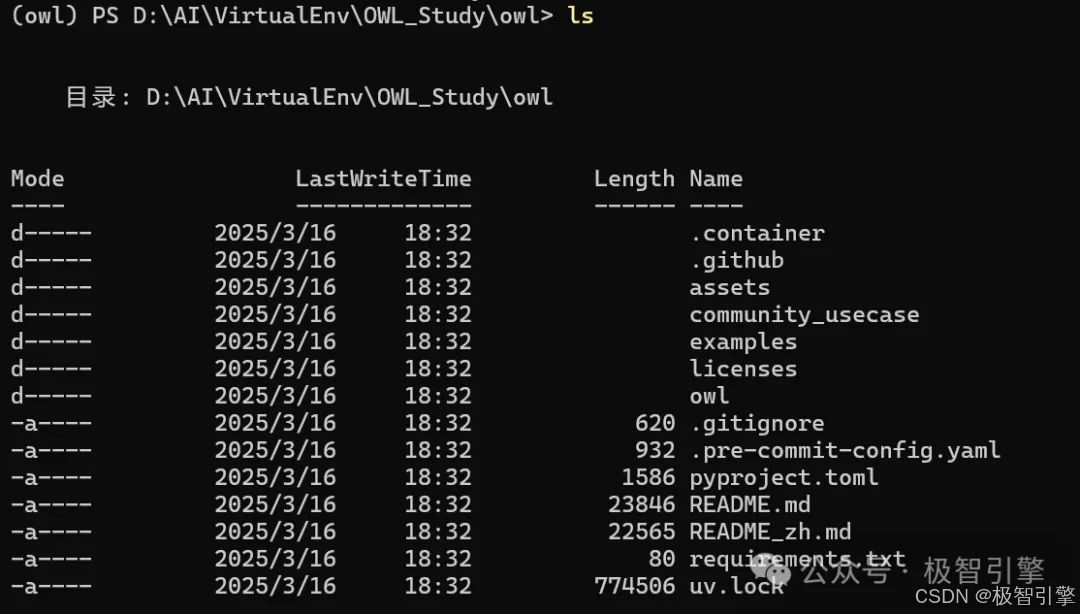
如下图所示为切换目录后在Powershell中执行ls命令后看到的代码目录结构:
3、依赖安装
官方推荐作为包安装,那我们就运行如下命令安装依赖包(时间大约5分钟,下载速度取决于网速,我这里指定了国内阿里源):
pip install -e . -i https://mirrors.aliyun.com/pypi/simple
安装完成后如下图所示:
4、大模型接口及API配置(硅基流动、QWEN)
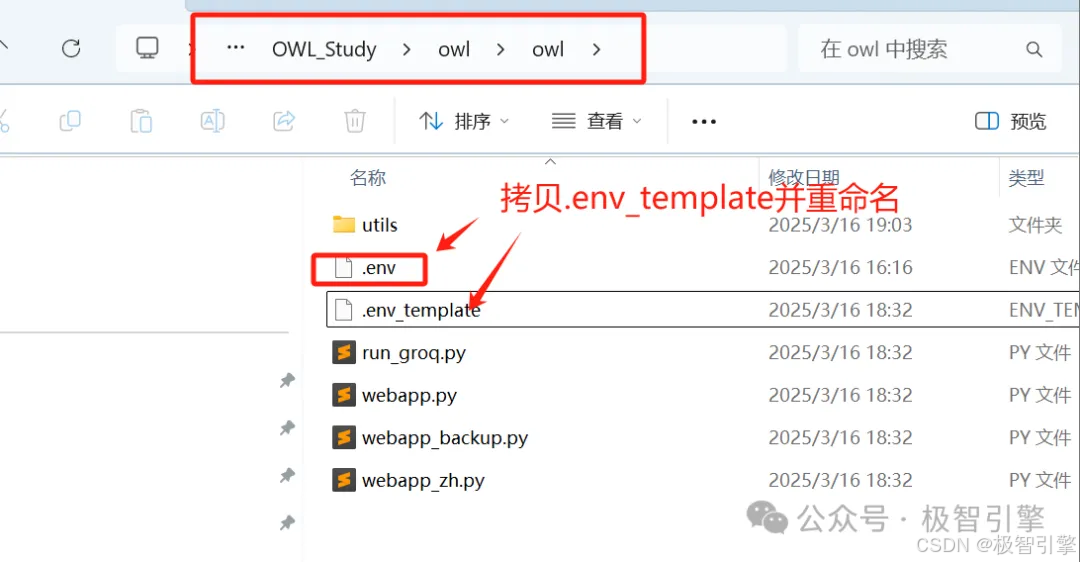
大模型接口及API配置文件是一个叫.env的文件,大家可以在项目owl\owl目录下将.env_template复制一份,重命名为.env,如下图所示:
(1)硅基流动自定义接口配置:
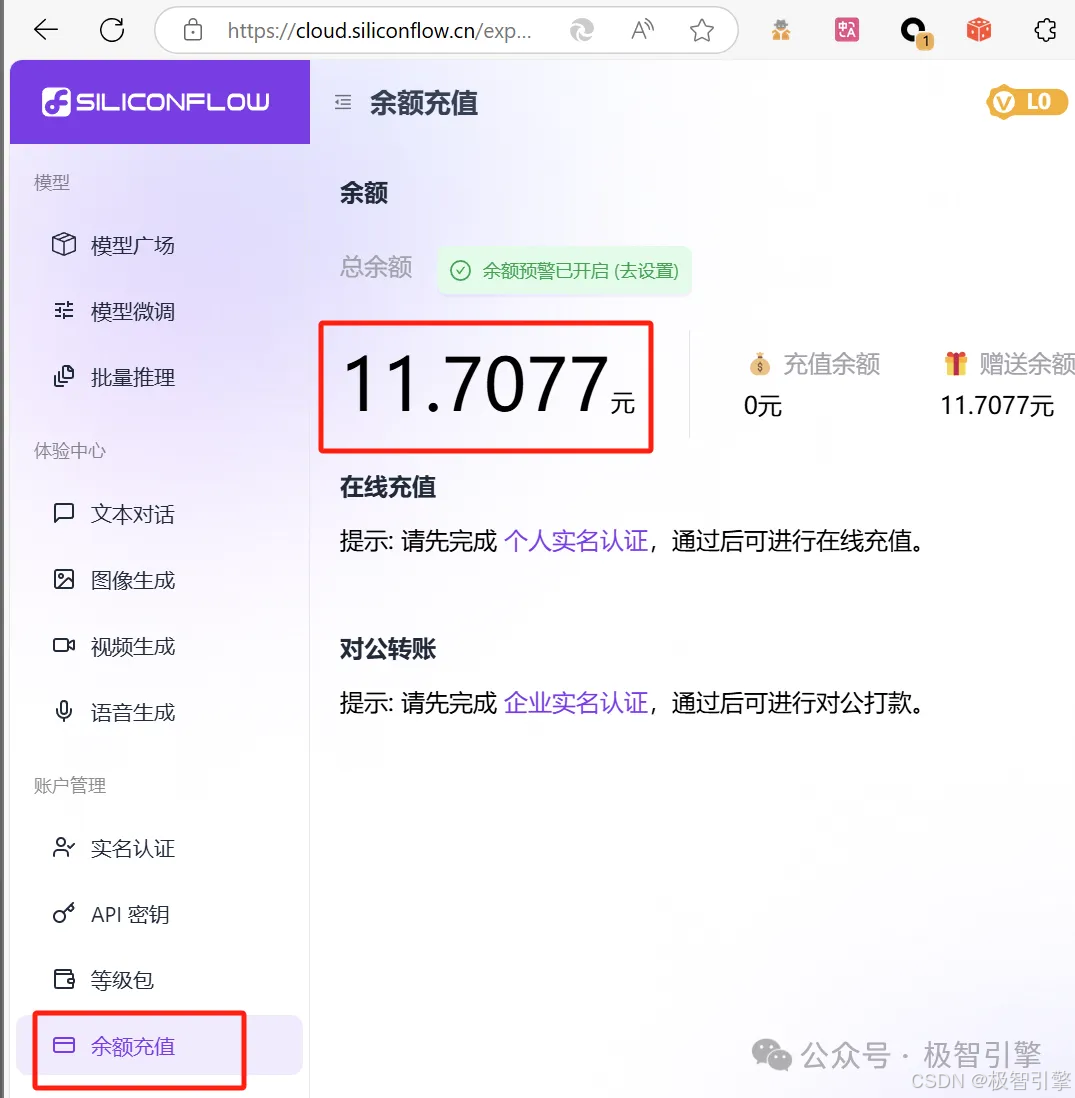
“极智引擎”公众号在上期OpenManus部署过程中已经讲解过硅基流动及其接口的配置,不了解的同学可以访问:https://mp.weixin.qq.com/s?__biz=Mzk3NTUyNDUxOQ==&mid=2247483764&idx=1&sn=2c779b8573ae5a4c15b40940cda6b9c6&scene=21#wechat_redirect查看,调用硅基流动接口需要支付一定的费用,但官方给新注册的用户赠送了一部分金额,足够做几次小研究使用了,大家随时关注自己账户余额即可。
打开前文所述的.env文件,添加如下自定义配置后保存:
# SILICONFLOW
SILICONFLOW_API_KEY='这里需要替换成你自己硅基流动的Key'
SILICONFLOW_API_URL='https://api.siliconflow.cn/v1'
然后切换到项目的examples文件夹,这里创建一个自定义的支持硅基流动的脚本文件,我这里命名是run_SiliconFlow.py,文件内容大家可以直接复制我这里调整好的代码直接用。硅基流动我这里配置的语义模型为“Qwen/QwQ-32B”,图形识别模型为“Qwen/Qwen2-VL-72B-Instruct”,这里大家根据自己喜好修改即可。
# ========= Copyright 2023-2024 @ CAMEL-AI.org. All Rights Reserved. =========
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ========= Copyright 2023-2024 @ CAMEL-AI.org. All Rights Reserved. =========
# To run this file, you need to configure the Qwen API key
# You can obtain your API key from Bailian platform: bailian.console.aliyun.com
# Set it as QWEN_API_KEY="your-api-key" in your .env file or add it to your environment variables
from dotenv import load_dotenv
from camel.models import ModelFactory
from camel.configs import SiliconFlowConfig
from camel.toolkits import (
CodeExecutionToolkit,
ExcelToolkit,
ImageAnalysisToolkit,
SearchToolkit,
VideoAnalysisToolkit,
BrowserToolkit,
FileWriteToolkit,
)
from camel.types import ModelPlatformType, ModelType
from camel.societies import RolePlaying
from owl.utils import run_society, DocumentProcessingToolkit
from camel.logger import set_log_level
import pathlib, sys
base_dir = pathlib.Path(__file__).parent.parent
env_path = base_dir / "owl" / ".env"
load_dotenv(dotenv_path=str(env_path))
set_log_level(level="DEBUG")
def construct_society(question: str) -> RolePlaying:
"""
Construct a society of agents based on the given question.
Args:
question (str): The task or question to be addressed by the society.
Returns:
RolePlaying: A configured society of agents ready to address the question.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









