



 本文介绍了如何用C语言实现链式队列的创建、插入、删除和显示功能,以及二叉树的中序遍历和后序遍历。包括`create_link_from`、`Enter_from`等函数和`create_tree`、`pri_show`等二叉树操作函数。
本文介绍了如何用C语言实现链式队列的创建、插入、删除和显示功能,以及二叉树的中序遍历和后序遍历。包括`create_link_from`、`Enter_from`等函数和`create_tree`、`pri_show`等二叉树操作函数。
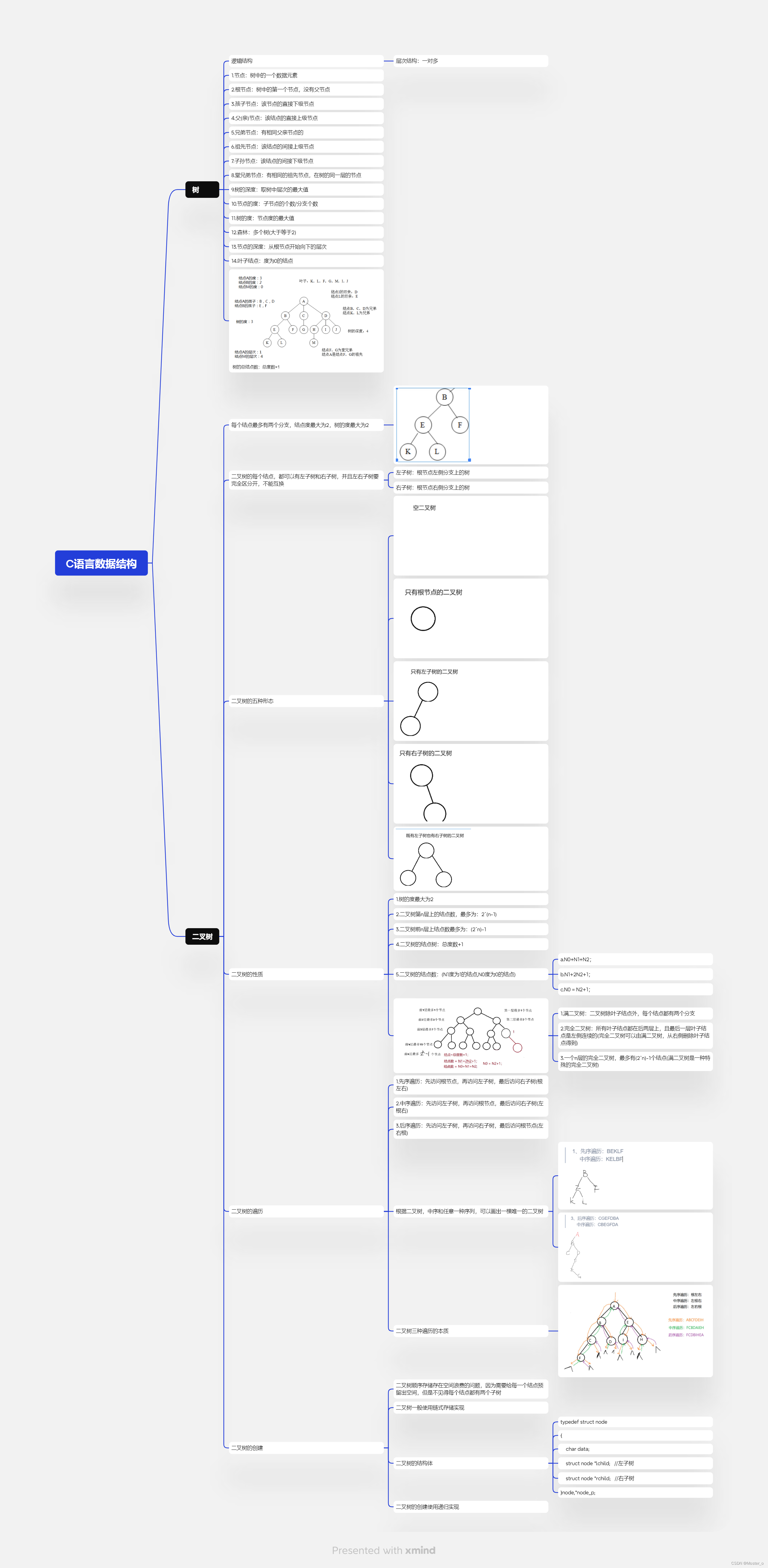
1.思维导图
2.链式队列代码
main.c
#include "link_from.h"
int main(){
point_p P=create_link_from(10);
Enter_from(P,11);
Enter_from(P,12);
Enter_from(P,13);
Enter_from(P,14);
Enter_from(P,15);
Enter_from(P,16);
show_from(P);
Pop_from(P);
Pop_from(P);
Pop_from(P);
show_from(P);
return 0;
}
link_from.c
#include "link_from.h"
point_p create_link_from(datatype data){
point_p P=(point_p)malloc(sizeof(point));
if(P==NULL){
printf("空间申请失败\n");
return NULL;
}
node_p F=(node_p)malloc(sizeof(node));
if(F==NULL){
printf("空间申请失败\n");
return NULL;
}
P->front=F;
P->rear=F;
F->data=data;
F->next=NULL;
return P;
}
void Enter_from(point_p P,datatype data){
if(P==NULL){
printf("空间申请失败\n");
return;
}
node_p new=NULL;
new=(node_p)malloc(sizeof(node));
P->rear->next=new;
P->rear=new;
new->data=data;
new->next=NULL;
}
int empty_from(point_p P){
if(P==NULL){
printf("入参为空\n");
return -1;
}
return P->front==P->rear?1:0;
}
void show_from(point_p P){
if(P==NULL){
printf("入参为空\n");
return;
}
node_p p=P->front;
while(p!=P->rear){
printf("%-4d",p->data);
p=p->next;
}
printf("%-4d",p->data);
putchar(10);
}
void Pop_from(point_p P){
if(P==NULL){
printf("空间申请失败\n");
return;
}
if(empty_from(P)){
printf("队列为空,无法输出\n");
return;
}
node_p del=P->front;
P->front=P->front->next;
free(del);
/*node_p p=P->front;
while(p->next!=P->rear){
p=p->next;
}
node_p del=P->rear;
P->rear=p;
p->next=NULL;
free(del);*/
}
link_from.h
#ifndef __LINK_FROM_H__
#define __LINK_FROM_H__
#include <stdio.h>
#include <stdlib.h>
typedef int datatype;
typedef struct node{
datatype data;
struct node* next;
}node,*node_p;
typedef struct point{
struct node* front;
struct node* rear;
}point,*point_p;
point_p create_link_from(datatype data);
void Enter_from(point_p P,datatype data);
void Pop_from(point_p P);
void show_from(point_p P);
#endif
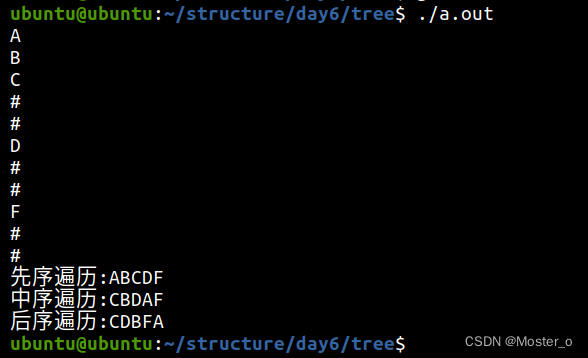
运行演示:

3.二叉树中序遍历&后序遍历
3.1中序遍历
void med_show(node_p T){
if(T==NULL){
return;
}
med_show(T->lchild);
printf("%c",T->data);
med_show(T->rchild);
}
3.2后序遍历
void rig_show(node_p T){
if(T==NULL){
return;
}
rig_show(T->lchild);
rig_show(T->rchild);
printf("%c",T->data);
}
3.3代码总结
tree.c
#include "tree.h"
node_p create_tree(){
char input='\0';
scanf(" %c",&input);
if(input=='#'){
return NULL;
}
node_p new=create_node(input);
new->lchild=create_tree();
new->rchild=create_tree();
return new;
}
node_p create_node(datatype input){
node_p new=(node_p)malloc(sizeof(node));
if(new==NULL){
printf("空间申请失败\n");
return NULL;
}
new->data=input;
return new;
}
void pri_show(node_p T){
if(T==NULL){
return;
}
printf("%c",T->data);
pri_show(T->lchild);
pri_show(T->rchild);
}
void med_show(node_p T){
if(T==NULL){
return;
}
med_show(T->lchild);
printf("%c",T->data);
med_show(T->rchild);
}
void rig_show(node_p T){
if(T==NULL){
return;
}
rig_show(T->lchild);
rig_show(T->rchild);
printf("%c",T->data);
}
tree.h
#ifndef __TREE_H__
#define __TREE_H__
#include <stdio.h>
#include <stdlib.h>
typedef char datatype;
typedef struct node{
char data;
struct node* lchild;
struct node* rchild;
}node,*node_p;
node_p create_tree();
node_p create_node(datatype input);
void pri_show(node_p T);
void rig_show(node_p T);
void med_show(node_p T);
#endif
运行演示:
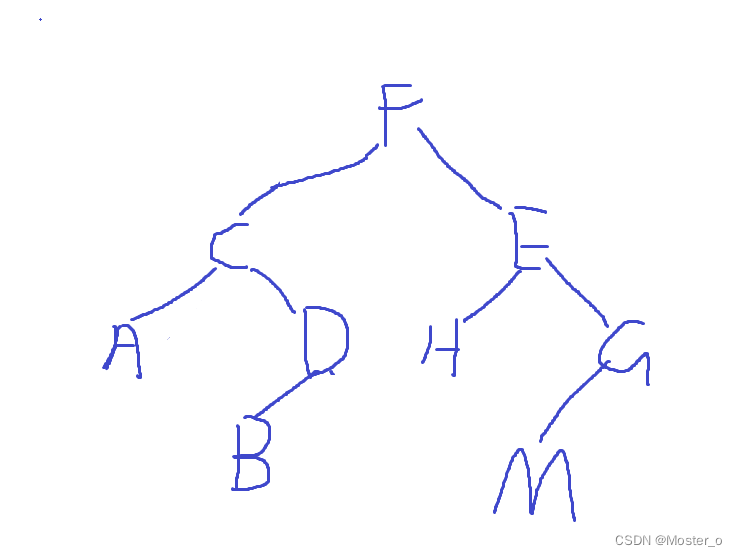
4.画二叉树:先序:FCADBEHGM & 中序:ACBDFHEMG

















 3399
3399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









