




一、Prometheus 概述:
为什么要用zabbix/prometheus监控
Prometheus 是一个开源的服务监控系统和时序数据库,其提供了通用的数据模型和快捷数据采集、存储和查询接口。它的核心组件 Prometheus server 会定期从静态配置的监控目标或者基于服务发现自动配置的目标中进行拉取数据,新拉取到的数据会持久化到存储设备当中。
zabbix 以;只适合传统设备,;只分了服务端和客户端,架构简单
prometheus使用http来收集数据,主动拉取数据;专门用于监控容器化的服务;将各种监控内容,进行解耦,所以架构很复杂;
每个被监控的主机都可以通过专用的 exporter 程序提供输出监控数据的接口,它会在目标处收集监控数据,并暴露出一个 HTTP 接口供 Prometheus server 查询,Prometheus 通过基于 HTTP 的 pull 的方式来周期性的采集数据。
如果存在告警规则,则抓取到数据之后会根据规则进行计算,满足告警条件则会生成告警,并发送到 Alertmanager 完成告警的汇总和分发。
当被监控的目标有主动推送数据的需求时,可以以 Pushgateway 组件进行接收并临时存储数据,然后等待 Prometheus server 完成数据的采集。
zabbix 是push;客户端主动上传数据到服务端
prometheus 是pull; 主动去客户端拉取数据
因为是为了监控k8s并且是近几年出来的,所以原生不支持(兼容)nginx、tomcat
任何被监控的目标都需要事先纳入到监控系统中才能进行时序数据采集、存储、告警和展示;监控目标可以通过配置信息以静态形式指定,也可以让 Prometheus 通过服务发现的机制进行动态管理。
Prometheus 能够直接把 API Server 作为服务发现系统使用,进而动态发现和监控集群中的所有可被监控的对象。
Prometheus 官网地址:https://prometheus.io
Prometheus github 地址:https://github.com/prometheus
Prometheus 的存储引擎——TSDB
●存储的数据量级十分庞大
●大部分时间都是写入操作
●写入操作几乎是顺序添加,大多数时候数据都以时间排序
●很少更新数据,大多数情况在数据被采集到数秒或者数分钟后就会被写入数据库
●删除操作一般为区块删除,选定开始的历史时间并指定后续的区块。很少单独删除某个时间或者分开的随机时间的数据
●基本数据大,一般超过内存大小。一般选取的只是其一小部分且没有规律,缓存几乎不起任何作用
●读操作是十分典型的升序或者降序的顺序读
●高并发的读操作十分常见
Prometheus 的特点
●多维数据模型:由度量名称和键值对标识的时间序列数据
时间序列数据:按照时间顺序记录系统、设备状态变化的数据,每个数据称为一个样本;
服务器指标数据、应用程序性能监控数据、网络数据等都是时序数据
●内置时间序列(Time Series)数据库:Prometheus ;外置的远端存储通常会用:InfluxDB、OpenTSDB 等
●promQL 一种灵活的查询语言,可以利用多维数据完成复杂查询
●基于 HTTP 的 pull(拉取)方式采集时间序列数据
●同时支持 PushGateway 组件收集数据
●通过静态配置或服务发现发现目标
●支持作为数据源接入 Grafana
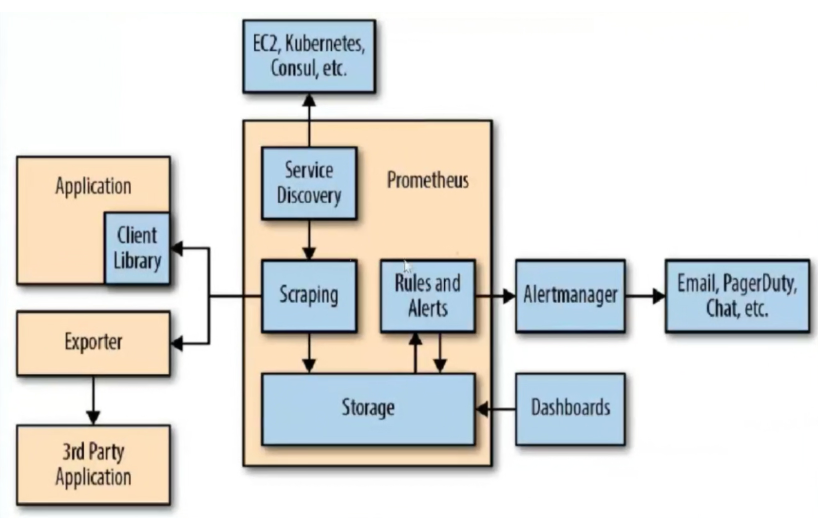
二、Prometheus 的生态组件
Prometheus 负责时序型指标数据的采集及存储,但数据的分析、聚合及直观展示以及告警等功能并非由 Prometheus Server 所负责。
Prometheus 生态圈中包含了多个组件,其中部分组件可选:
(1)Prometheus server:服务核心组件,采用 pull 方式采集监控数据,通过 http 协议传输;存储时间序列数据;基于“告警规则”生成告警通知。
Prometheus server 由三个部分组成:
Retrieval,Storage,PromQL
●Retrieval:负责在活跃的 target 主机上抓取监控指标数据。
●Storage:存储,主要是把采集到的数据存储到磁盘中。默认为 15 天。
●PromQL:是 Prometheus 提供的查询语言模块。
(2)Client Library: 客户端库,目的在于为那些期望原生提供 Instrumentation 功能的应用程序提供便捷的开发途径,用于基于应用程序内建的测量系统。
(3)Exporters:指标暴露器,负责收集不支持内建 Instrumentation 的应用程序或服务的性能指标数据,并通过 HTTP 接口供 Prometheus Server 获取。
换句话说,Exporter 负责从目标应用程序上采集和聚合原始格式的数据,并转换或聚合为 Prometheus 格式的指标向外暴露。
常用的 Exporters:
●Node-Exporter:用于收集服务器节点的物理指标状态数据,如平均负载、CPU、内存、磁盘、网络等资源信息的指标数据,需要部署到所有运算节点。
指标详细介绍:https://github.com/prometheus/node_exporter
●mysqld-exporter/nginx-exporter
●Kube-State-Metrics:为 Prometheus 采集 K8S 资源数据的 exporter,通过监听 APIServer 收集 kubernetes 集群内资源对象的状态指标数据,例如 pod、deployment、service 等等。同时它也提供自己的数据,主要是资源采集个数和采集发生的异常次数统计。
需要注意的是 kube-state-metrics 只是简单的提供一个 metrics 数据,并不会存储这些指标数据,所以可以使用 Prometheus 来抓取这些数据然后存储, 主要关注的是业务相关的一些元数据,比如 Deployment、Pod、副本状态等;调度了多少个 replicas ?现在可用的有几个?多少个 Pod 是 running/stopped/terminated 状态?Pod 重启了多少次?有多少 job 在运行中。
●cAdvisor:用来监控容器内部使用资源的信息,比如 CPU、内存、网络I/O、磁盘I/O 。
●blackbox-exporter:监控业务容器存活性。
(4)Service Discovery:服务发现,用于动态发现待监控的 Target,Prometheus 支持多种服务发现机制:文件、DNS、Consul、Kubernetes 等等。 服务发现可通过第三方提供的接口,Prometheus 查询到需要监控的 Target 列表,然后轮询这些 Target 获取监控数据。该组件目前由 Prometheus Server 内建支持
(5)Alertmanager:是一个独立的告警模块,从 Prometheus server 端接收到 “告警通知” 后,会进行去重、分组,并路由到相应的接收方,发出报警, 常见的接收方式有:电子邮件、钉钉、企业微信等。
Prometheus Server 仅负责生成告警指示,具体的告警行为由另一个独立的应用程序 AlertManager 负责;告警指示由 Prometheus Server 基于用户提供的告警规则周期性计算生成,Alertmanager 接收到 Prometheus Server 发来的告警指示后,基于用户定义的告警路由向告警接收人发送告警信息。
(6)Pushgateway:类似一个中转站,Prometheus 的 server 端只会使用 pull 方式拉取数据,但是某些节点因为某些原因只能使用 push 方式推送数据, 那么它就是用来接收 push 而来的数据并暴露给 Prometheus 的 server 拉取的中转站。
可以理解成目标主机可以上报短期任务的数据到 Pushgateway,然后 Prometheus server 统一从 Pushgateway 拉取数据。
(7)Grafana:是一个跨平台的开源的度量分析和可视化工具,可以将采集的数据可视化的展示,并及时通知给告警接收方。其官方库中具有丰富的仪表盘插件。
exporter 暴露器;每种服务对应一种暴露器
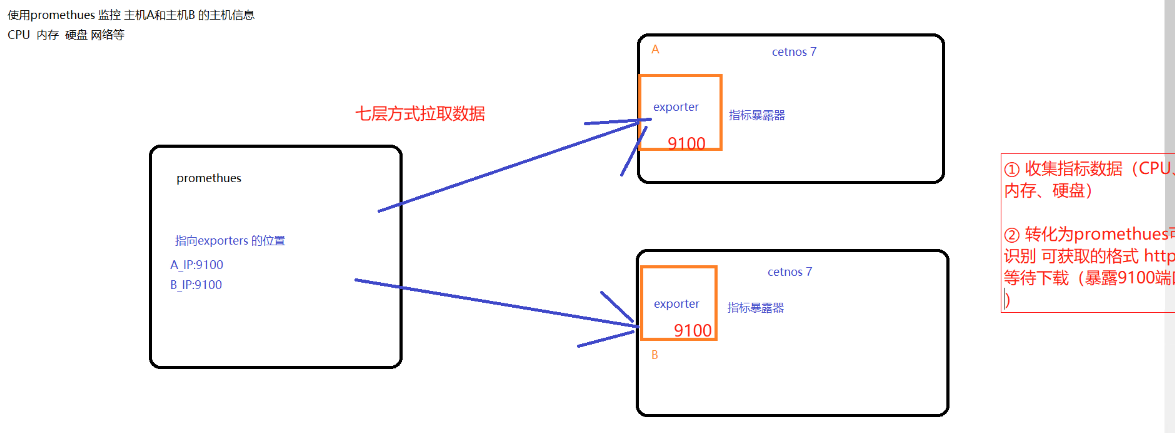
使用prometheus 监控主机A和主机B 的主机信息:cpu,内存,硬盘,网络等
收集指标数据(cpu、内存、磁盘)
转化为prometheus可以识别和获取的格式,通过http等待下载(暴露9100端口)
下载
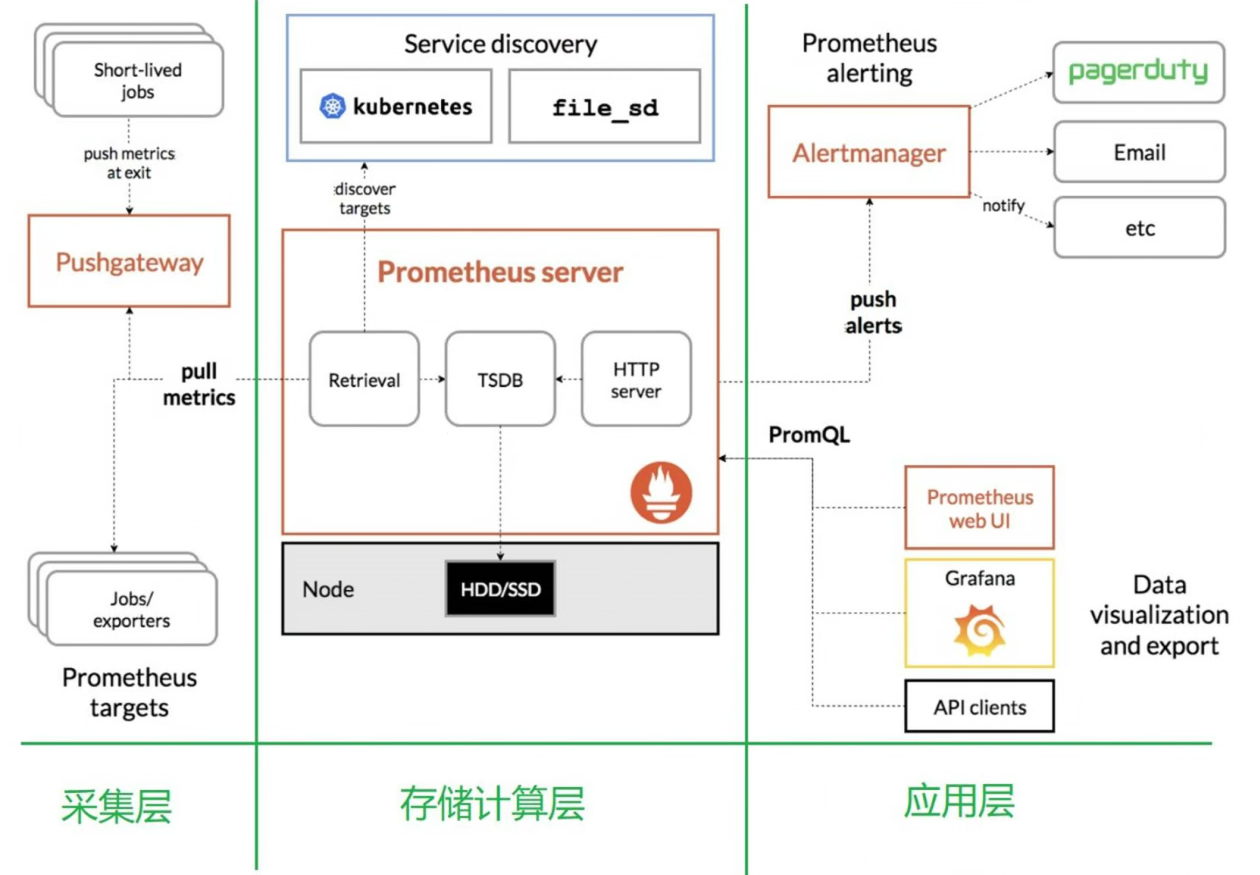
工作模式
●Prometheus Server 基于服务发现(Service Discovery)机制或静态配置获取要监视的目标(Target),并通过每个目标上的指标 exporter 来采集(Scrape)指标数据;
●Prometheus Server 内置了一个基于文件的时间序列存储来持久存储指标数据,用户可使用 PromQL 接口来检索数据,也能够按需将告警需求发往 Alertmanager 完成告警内容发送;
●一些短期运行的作业的生命周期过短,难以有效地将必要的指标数据供给到 Server 端,它们一般会采用推送(Push)方式输出指标数据, Prometheus 借助于 Pushgateway 接收这些推送的数据,进而由 Server 端进行抓取
Prometheus的工作流程
1)Server 为核心,负责收集和存储时间序列数据;通过pull 拉取指标数据,客户端push的数据也会先存储在pushgateway中,然后等待server通过pull拉取
2)server将采集到的监控指标数据,按时间序列,通过TSDB存储到本地的HDD/SDD中
3)server通过配置报警规则,把触发的告警通知,生成并传给Alertmanager,再通过Alertmanager 以各种形式发送给接收方
4)使用 PromQL 查询语言 可以在 Prometheus 的UI界面查询监控数据
5)通过Grafana 将监控数据图形化展示出来
原生支持:scraping 收集clientLibrary 的数据,存储到storage
原生不支持:主动push上传的数据,Exporter 会先将数据转换成pro能识别的数据;再通过http拉取数据到scraping,并存储到storage
局限性
●Prometheus 是一款指标监控系统,不适合存储事件及日志等;它更多地展示的是趋势性的监控,而非精准数据;
●Prometheus 认为只有最近的监控数据才有查询的需要,其本地存储的设计初衷只是保存短期(例如一个月)数据,因而不支持针对大量的历史数据进行存储;
若需要存储长期的历史数据,建议基于远端存储机制将数据保存于 InfluxDB 或 OpenTSDB 等系统中;
●Prometheus 的集群机制成熟度不高,可基于 Thanos 实现 Prometheus 集群的高可用及联邦集群。
日志监控
三、部署prometheus
Prometheust Server 端安装和相关配置
关闭防火墙
#关闭防火墙
systemctl stop firewalld.service
setenforce 0
1)上传 prometheus-2.35.0.linux-amd64.tar.gz 到 /opt 目录中,并解压
cd /opt/
#添加 prometheus-2.35.0.linux-amd64.tar.gz 到 /opt 目录中#解压
tar xf prometheus-2.35.0.linux-amd64.tar.gz
#移动到 /usr/local/ 目录下,并改名为prometheus
mv prometheus-2.35.0.linux-amd64 /usr/local/prometheus
#查看
ls /usr/local/prometheus/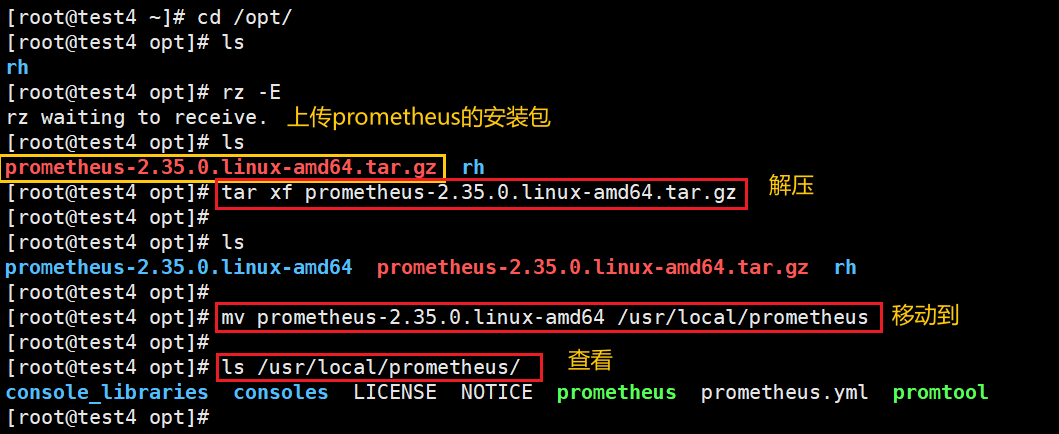
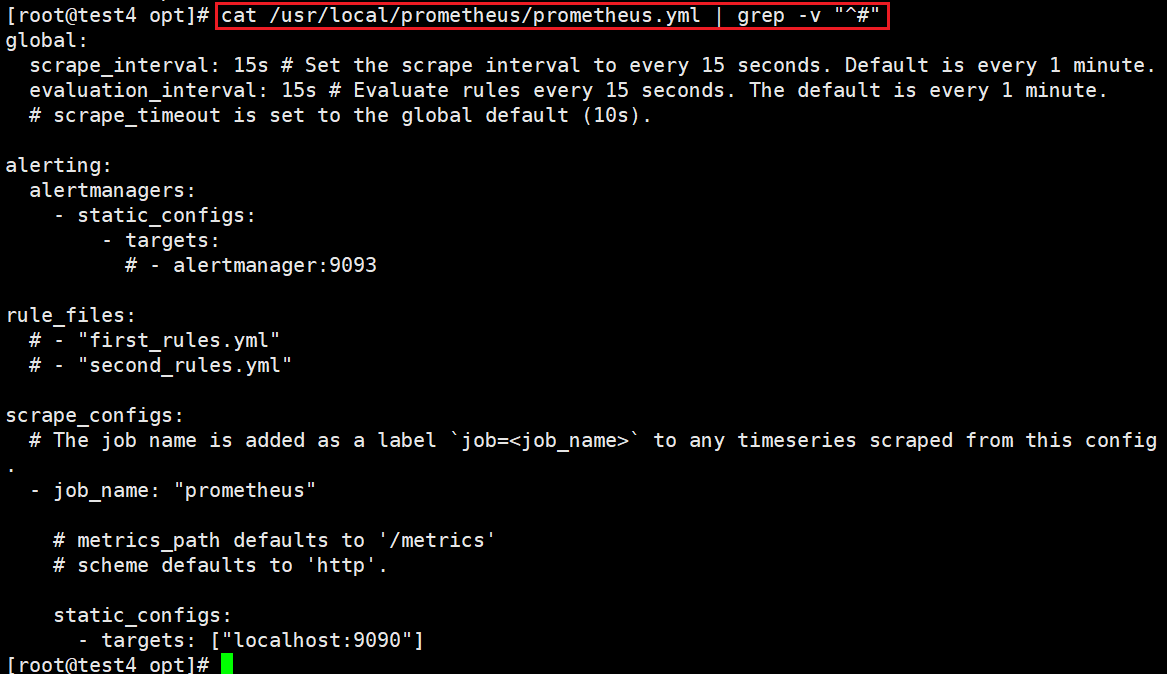
查看prometheus.yml 文件中的内容
#过滤查看prometheus.yml 文件中不以#开头的行
cat /usr/local/prometheus/prometheus.yml | grep -v "^#"global: #用于prometheus的全局配置,比如采集间隔,抓取超时时间等
scrape_interval: 15s #采集目标主机监控数据的时间间隔,默认为1m
evaluation_interval: 15s #触发告警生成alert的时间间隔,默认是1m
# scrape_timeout is set to the global default (10s).
scrape_timeout: 10s #数据采集超时时间,默认10s
alerting: #用于alertmanager实例的配置,支持静态配置和动态服务发现的机制
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
rule_files: #用于加载告警规则相关的文件路径的配置,可以使用文件名通配机制
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs: #用于采集时序数据源的配置
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus" #每个被监控实例的集合用job_name命名,支持静态配置(static_configs)和动态服务发现的机制(*_sd_configs)
# metrics_path defaults to '/metrics'
metrics_path: '/metrics' #指标数据采集路径,默认为 /metrics
# scheme defaults to 'http'.
static_configs: #静态目标配置,固定从某个target拉取数据
- targets: ["localhost:9090"]
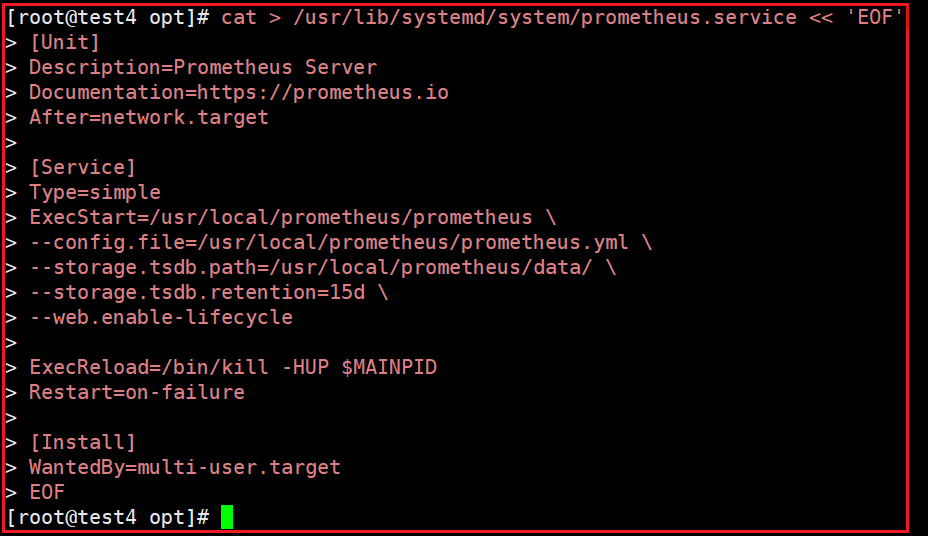
2)配置系统启动文件,启动 Prometheust
cat > /usr/lib/systemd/system/prometheus.service <<'EOF'
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/prometheus/prometheus \
--config.file=/usr/local/prometheus/prometheus.yml \
--storage.tsdb.path=/usr/local/prometheus/data/ \
--storage.tsdb.retention=15d \
--web.enable-lifecycle
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
3)启动
#启动 prometheus
systemctl start prometheus.service
#查看状态
systemctl status prometheus.service
#过滤查看9090端口
netstat -natp | grep :9090

4)浏览器访问
http://192.168.67.14:9090
访问到 Prometheus 的 Web UI 界面
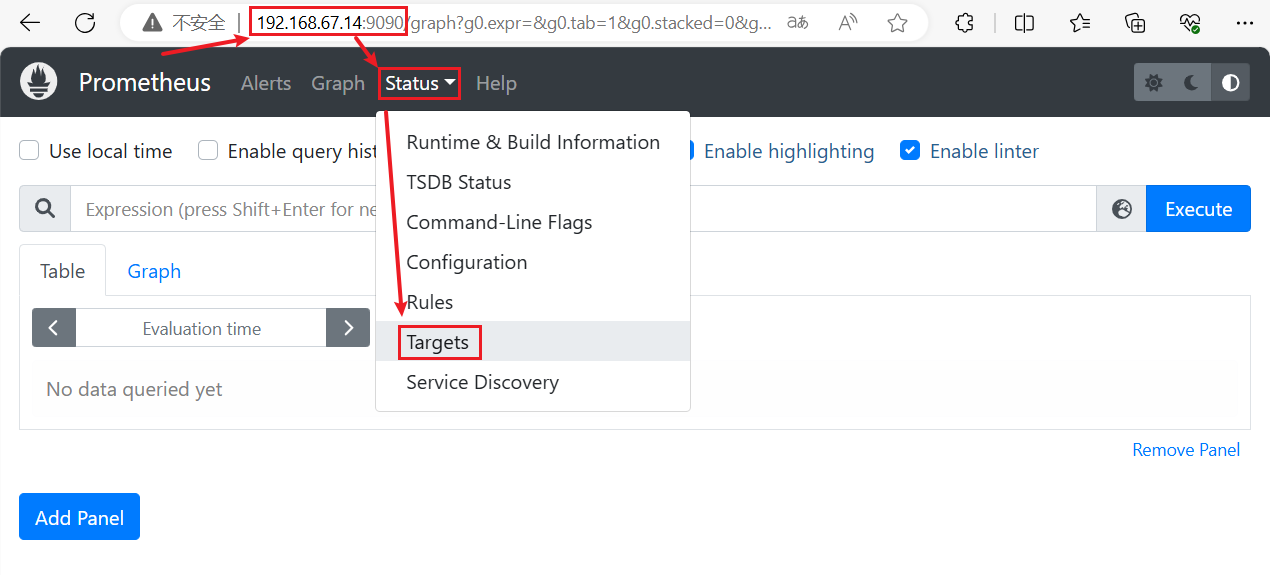
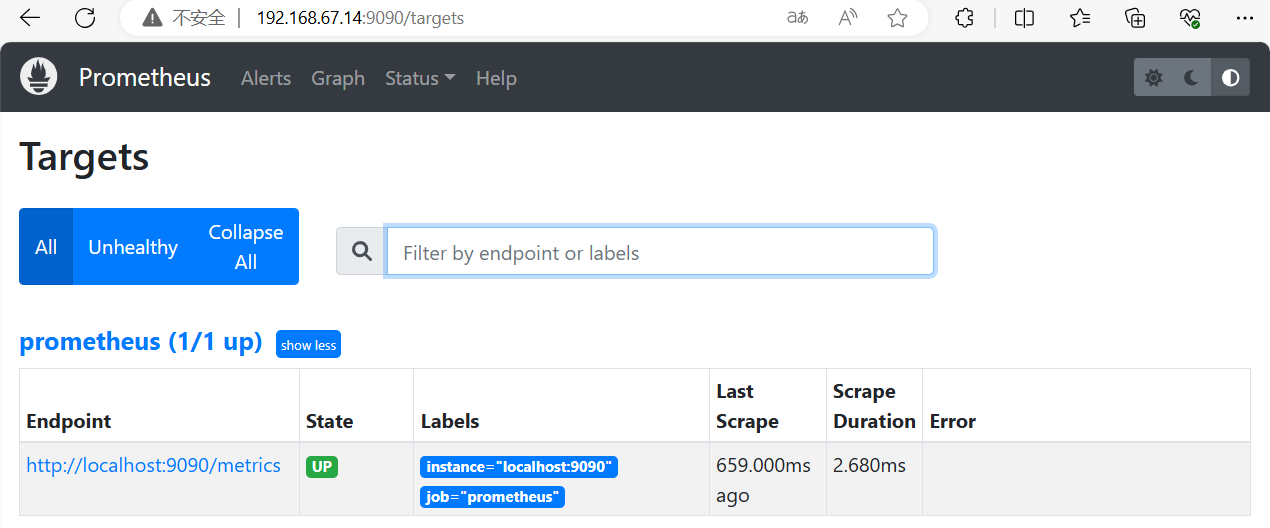
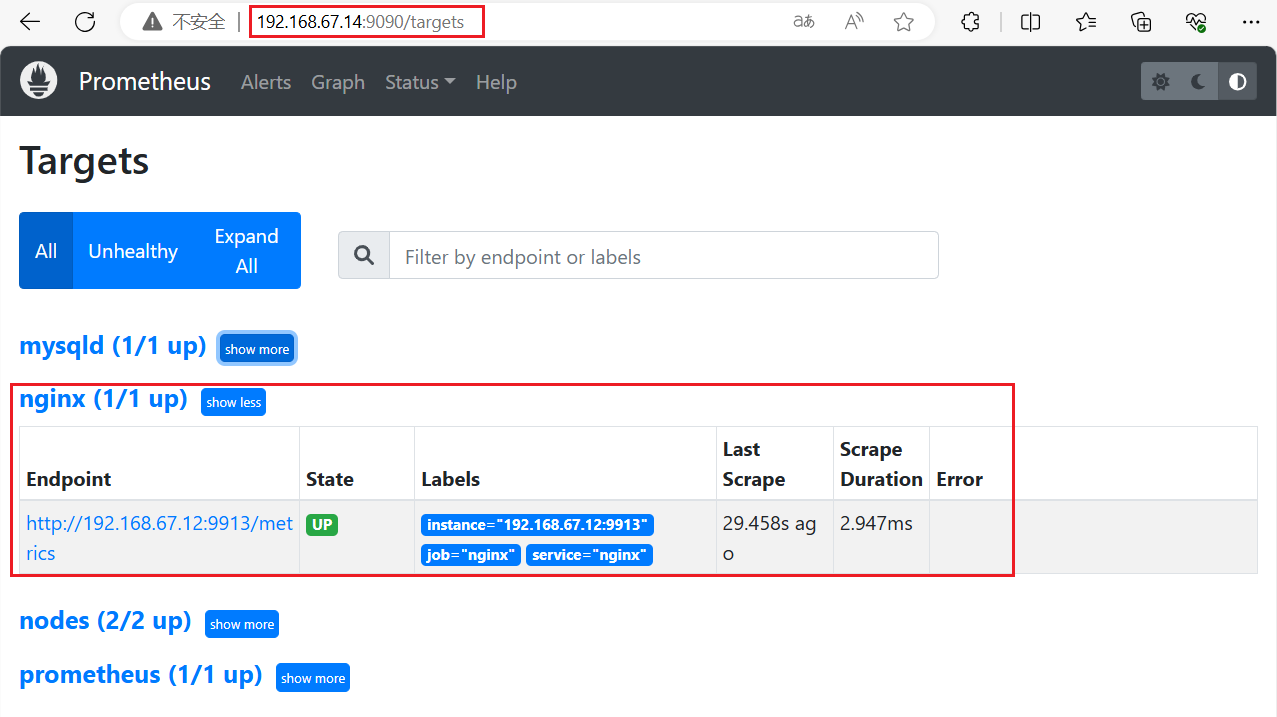
点击页面的 【Status】 ——>【Targets】,如看到 Target 状态都为 UP,说明 Prometheus 能正常采集到数据在prometheus上部署exporter后可以监控到自己
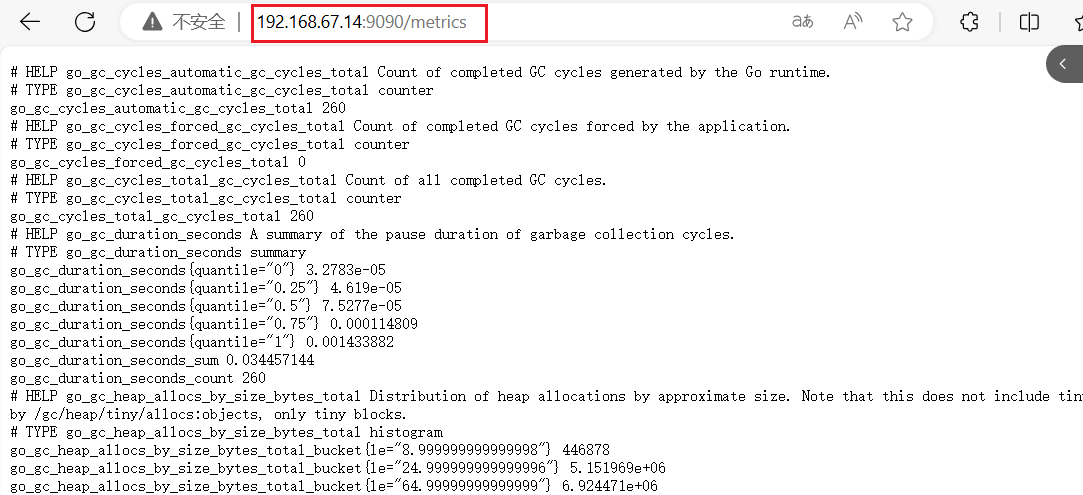
http://192.168.67.14:9090/metrics可以看到 Prometheus 采集到自己的指标数据;其中 Help 字段用于解释当前指标的含义,Type 字段用于说明数据的类型
四、部署 Exporters
将node_exporters 部署在要被监控的 k8s 节点上;这里演示部署在k8s集群中的node01节点上
部署 Node Exporter 监控系统级指标
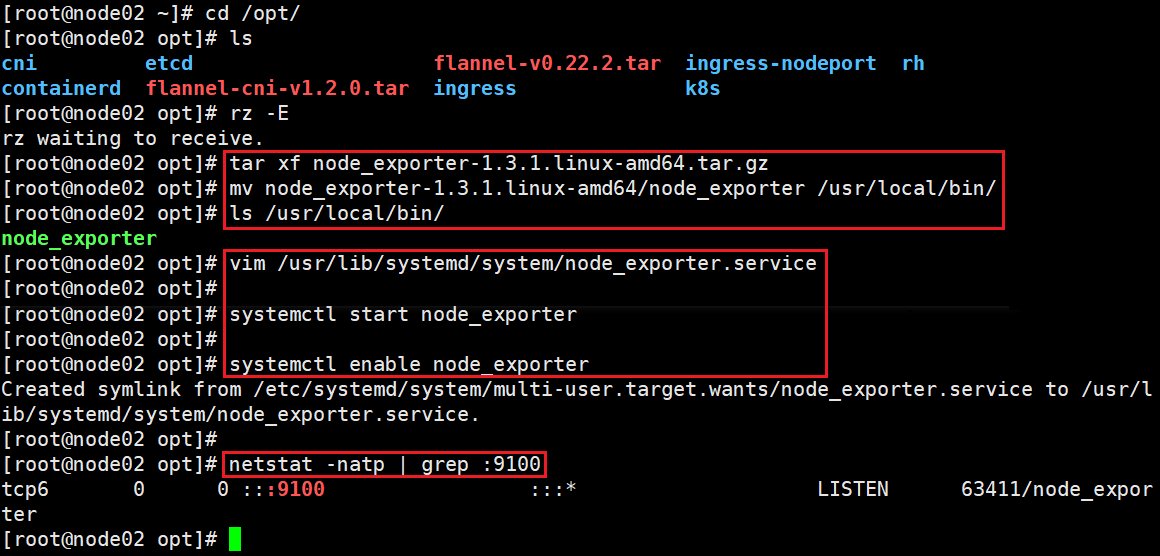
1)上传 node_exporter-1.3.1.linux-amd64.tar.gz 到 /opt 目录中,并解压
cd /opt/
#上传 node_exporter-1.3.1.linux-amd64.tar.gz 到 /opt 目录#解压
tar xf node_exporter-1.3.1.linux-amd64.tar.gz
#移动
mv node_exporter-1.3.1.linux-amd64/node_exporter /usr/local/bin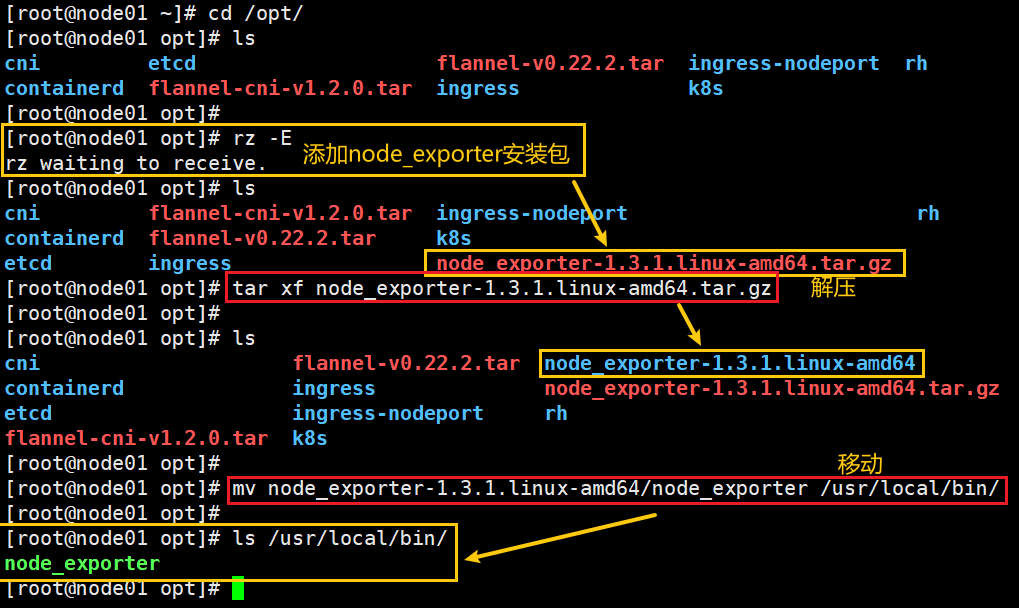
2)配置启动文件
cat > /usr/lib/systemd/system/node_exporter.service <<'EOF'
[Unit]
Description=node_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/bin/node_exporter \
--collector.ntp \
--collector.mountstats \
--collector.systemd \
--collector.tcpstat
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF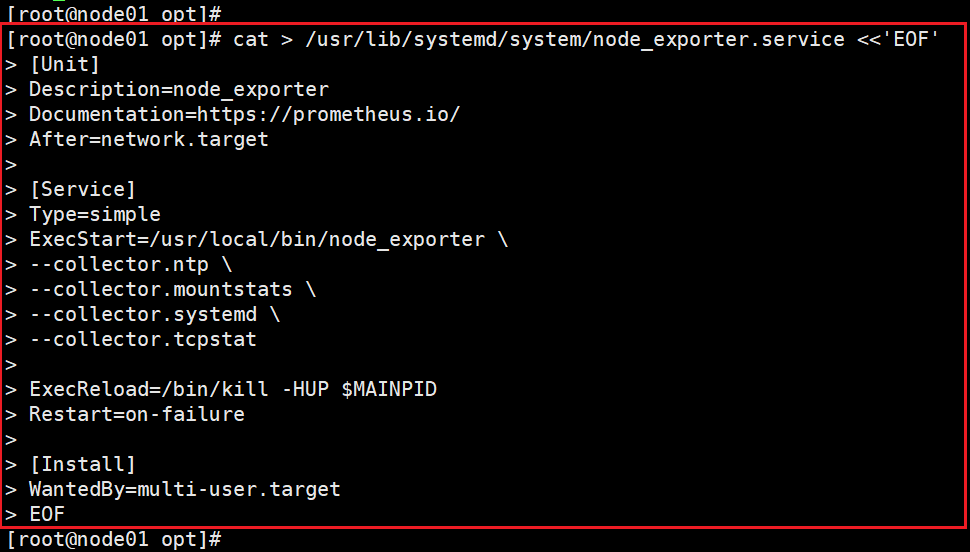
3)启动
#重新加载 systemd 管理的服务单元文件
#systemctl daemon-reload
#启动
systemctl start node_exporter
#设置开机自启
systemctl enable node_exporter
#过滤查看9100 端口
netstat -natp | grep 9100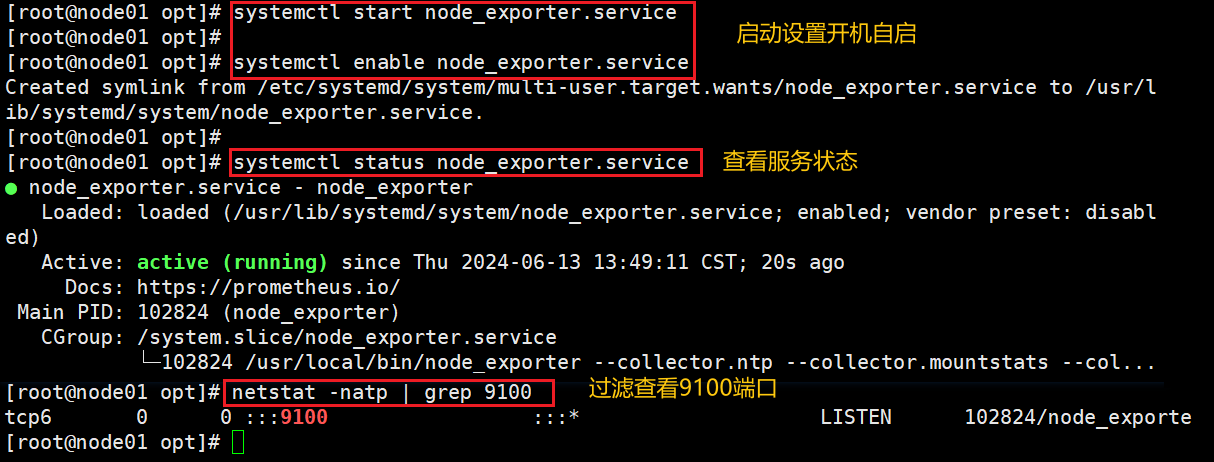
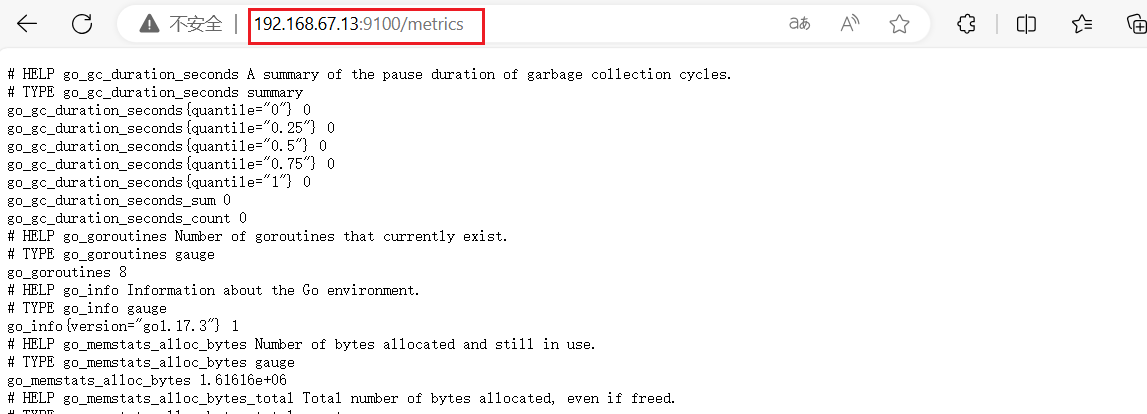
4)浏览器访问
#node01节点的IP地址
http://192.168.67.12:9100/metrics
可以看到 Node Exporter 采集到的指标数据
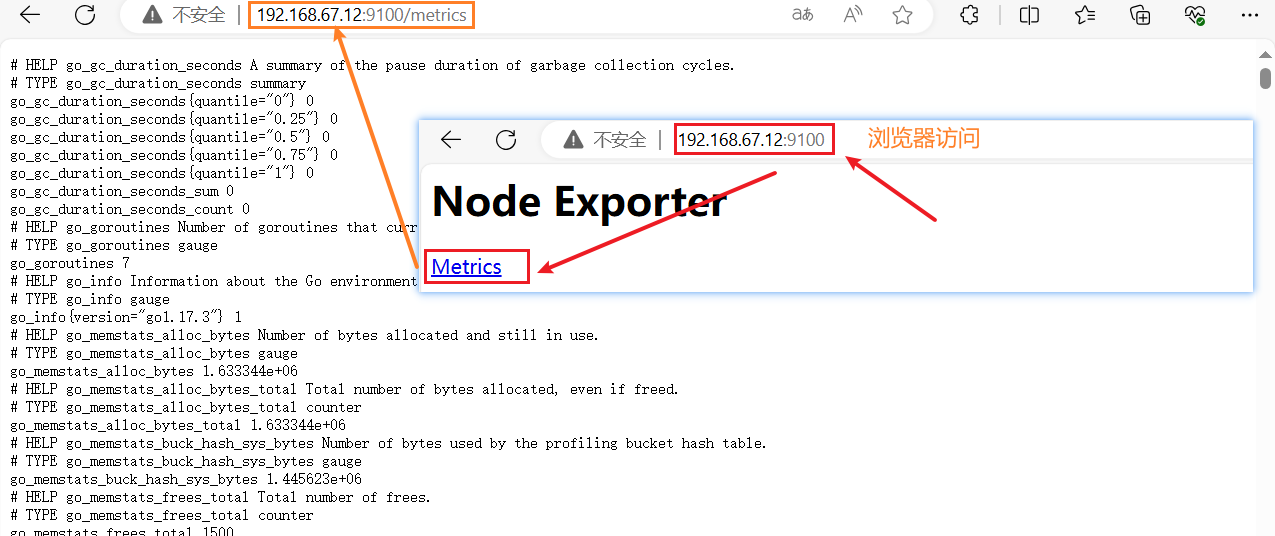
node02 上也部署一下部署 Exporters
5)修改 prometheus 配置文件,加入到 prometheus 监控中
修改前可以先对文件进行备份
vim /usr/local/prometheus/prometheus.yml
#在末尾增加如下内容
- job_name: nodes
metrics_path: "/metrics"
static_configs:
- targets:
- 192.168.67.12:9100
- 192.168.67.13:9100
labels:
service: kubernetes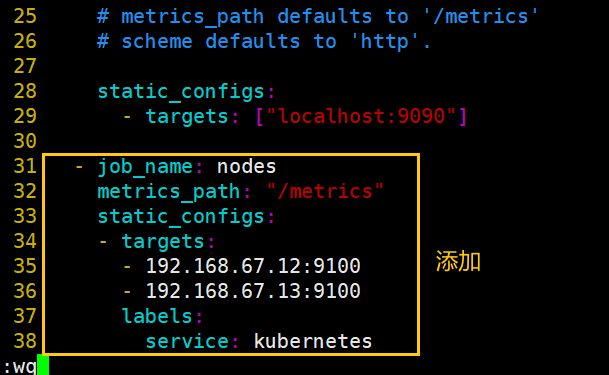
6)重新载入配置
curl -X POST http://192.168.67.14:9090/-/reload
#或
systemctl reload prometheus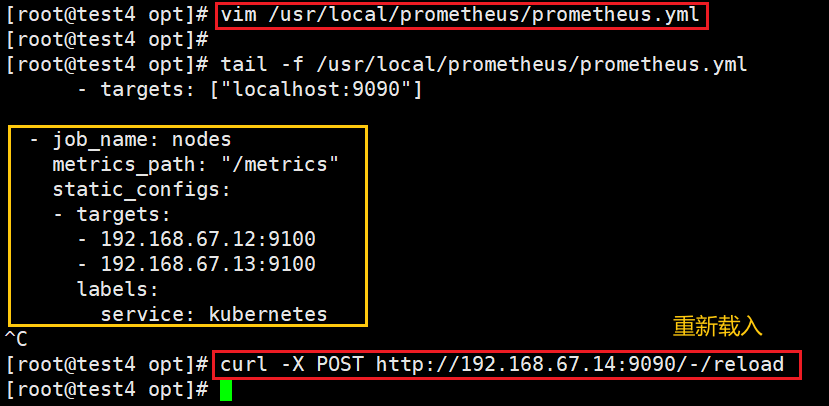
7)浏览器访问
浏览器查看 Prometheus 页面的 【Status】 ——> 【Targets】
刷新页面,可以看到监控到了两个node节点的指标
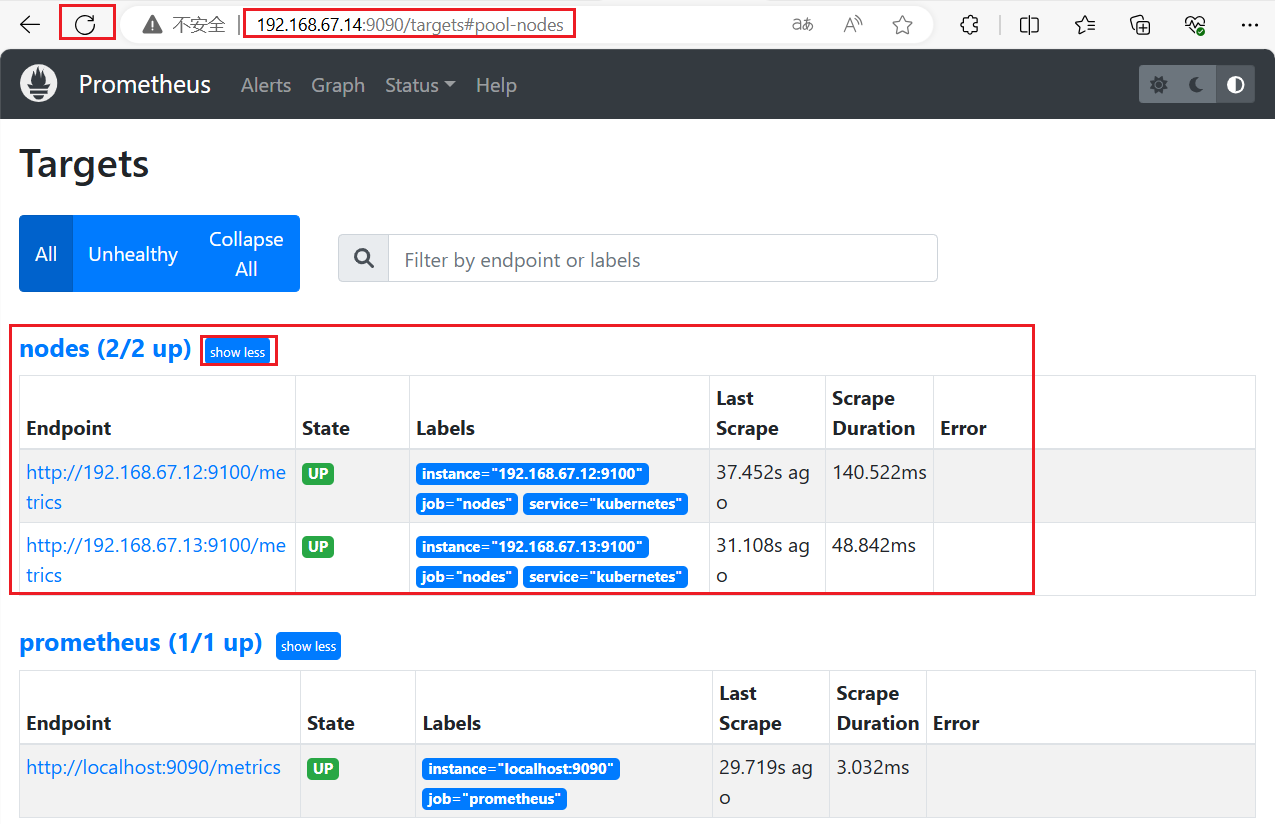
查看客户端(被监控端)的指标信息
通过搜索 up 可以查看客户端状态
可以使用指标命令搜索,来查看客户端的指标状态
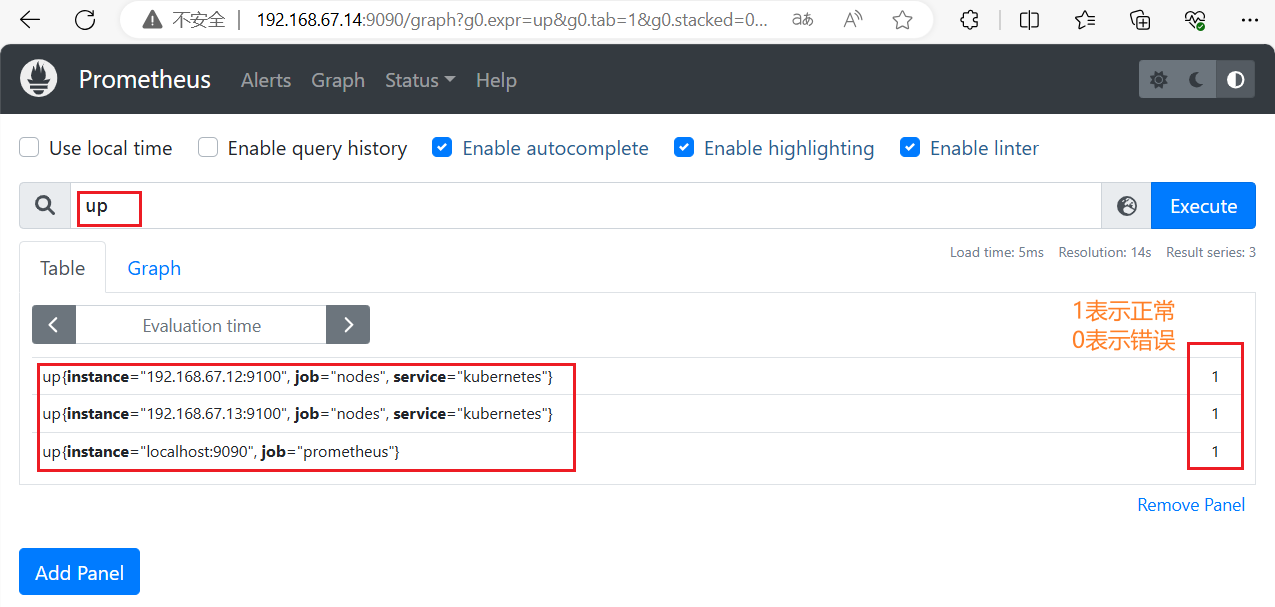
常用的各种指标
●node_cpu_seconds_total #监控 CPU 使用情况的指标
●node_memory_MemTotal_bytes #监控系统的总内存大小
●node_filesystem_size_bytes{mount_point=PATH} #监控特定挂载点的文件系统大小
●node_system_unit_state{name=} #监控系统单元的状态,如服务、套接字
●node_vmstat_pswpin #系统每秒从磁盘读到内存的字节数
●node_vmstat_pswpout #系统每秒钟从内存写到磁盘的字节数
更多指标介绍:https://github.com/prometheus/node_exporter
五、监控 MySQL 配置示例
在 MySQL 服务器上操作 ,将mysql_exporter 部署在MySQL服务器上
1)上传MySQL安装包
上传 mysqld_exporter-0.14.0.linux-amd64.tar.gz 到 /opt 目录中,并解压
cd /opt/
#上传 mysqld_exporter-0.14.0.linux-amd64.tar.gz 到 /opt 目录#解压并移动
tar xf mysqld_exporter-0.14.0.linux-amd64.tar.gz
mv mysqld_exporter-0.14.0.linux-amd64/mysqld_exporter /usr/local/bin/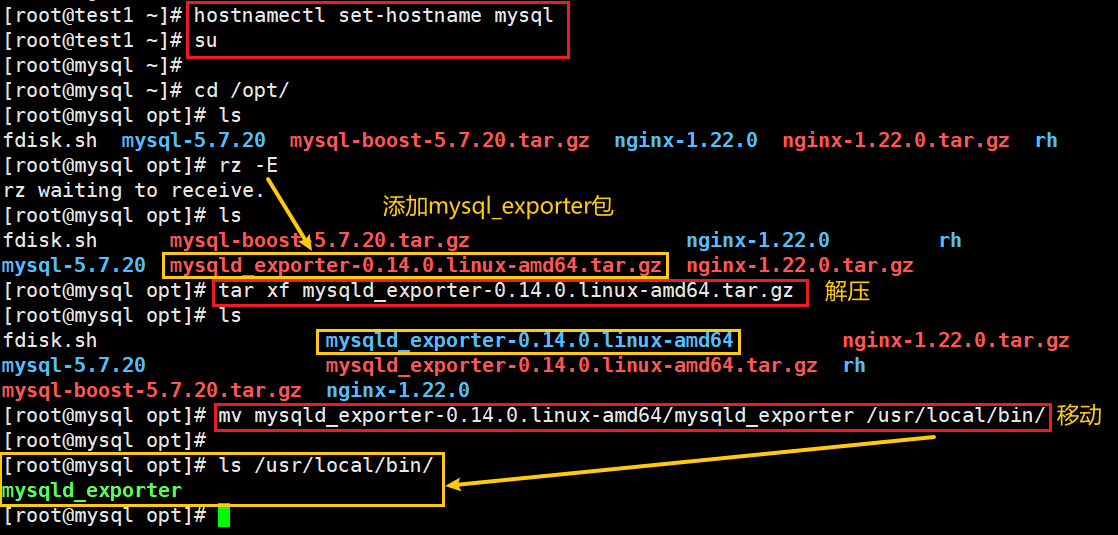
2)配置启动文件
cat > /usr/lib/systemd/system/mysqld_exporter.service <<'EOF'
[Unit]
Description=mysqld_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/bin/mysqld_exporter --config.my-cnf=/etc/my.cnf
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF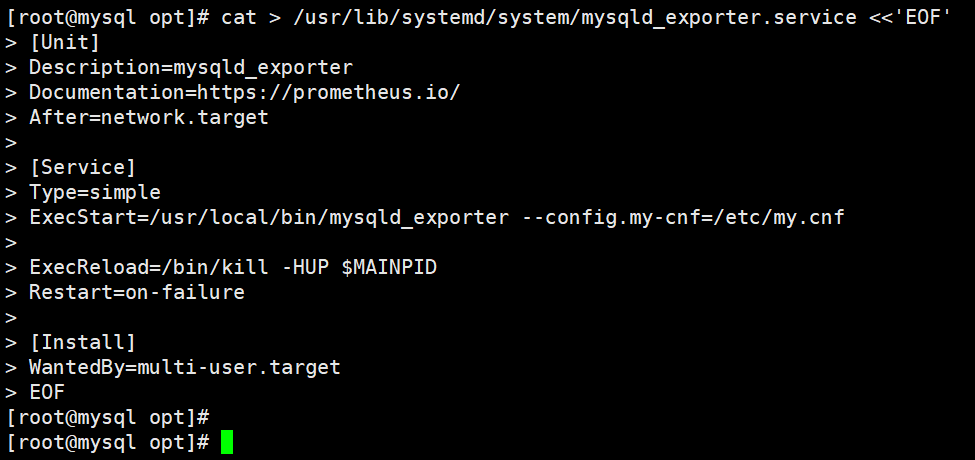
3)修改 MySQL 配置文件
vim /etc/my.cnf
[client]
......
host=localhost
user=exporter
password=abc123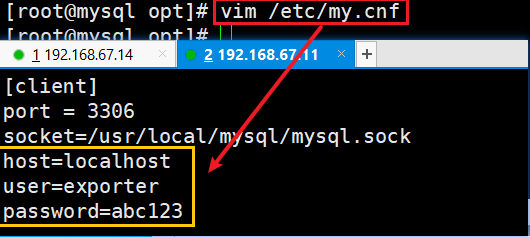
4)授权 exporter 用户
#登录数据库
mysql -uroot -p123456
#授权
grant process,replication client,select on *.* to 'exporter'@'localhost' identified by 'abc123';
#刷新
flush privileges;
#退出
exit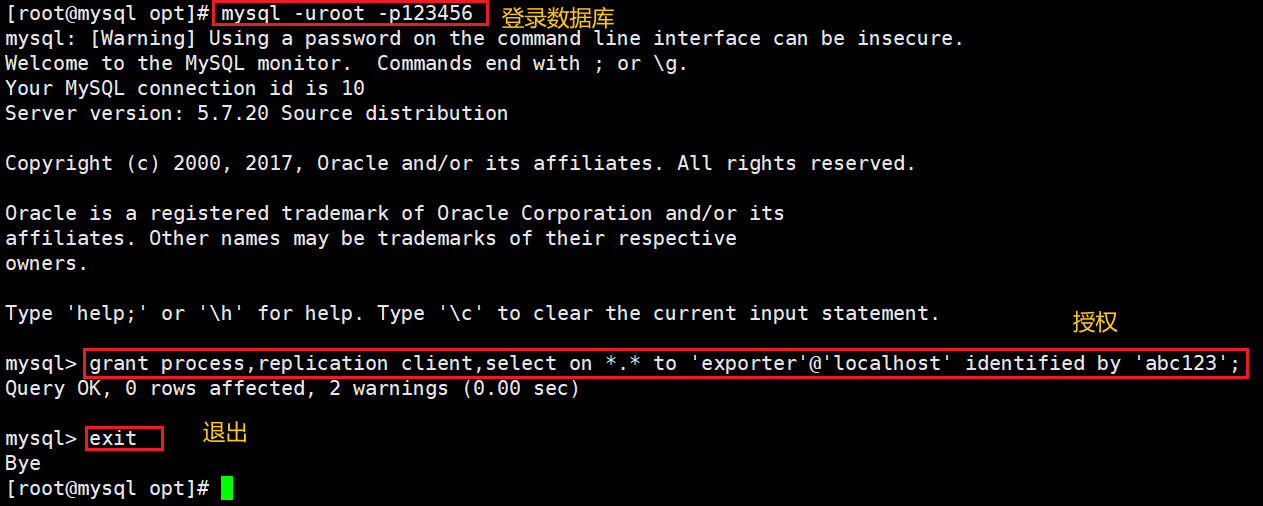
5)重启服务
#启动 mysqld
systemctl restart mysqld
#启动mysqld_exporter并设置开机自启
systemctl start mysqld_exporter
systemctl enable mysqld_exporter
#过滤查看9104端口
lsof -i:9104
#或
netstat -natp | grep :9104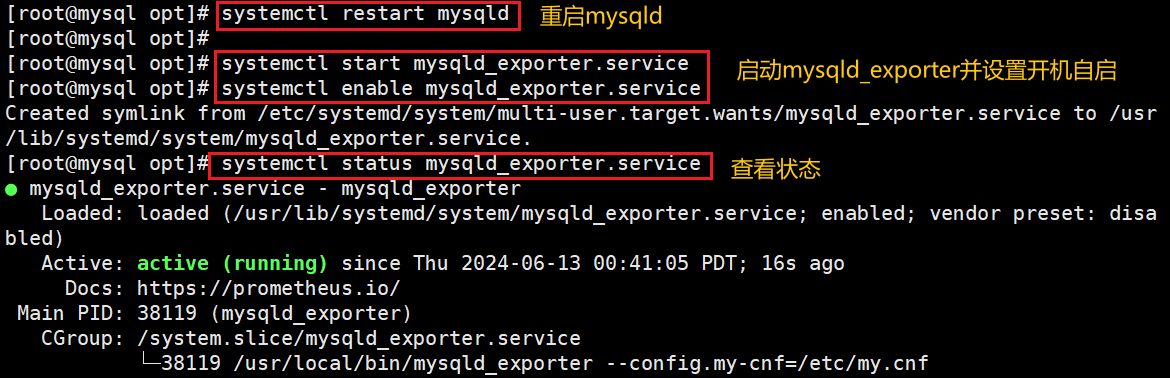

在 Prometheus 服务器上操作
配置prometheus-server服务端,让server服务端可以监控到客户端的数据指标
1)修改 prometheus 配置文件,加入到 prometheus 监控中
vim /usr/local/prometheus/prometheus.yml
#在尾部增加如下内容
- job_name: mysqld
metrics_path: "/metrics"
static_configs:
- targets:
- 192.168.67.11:9104
labels:
service: mysqld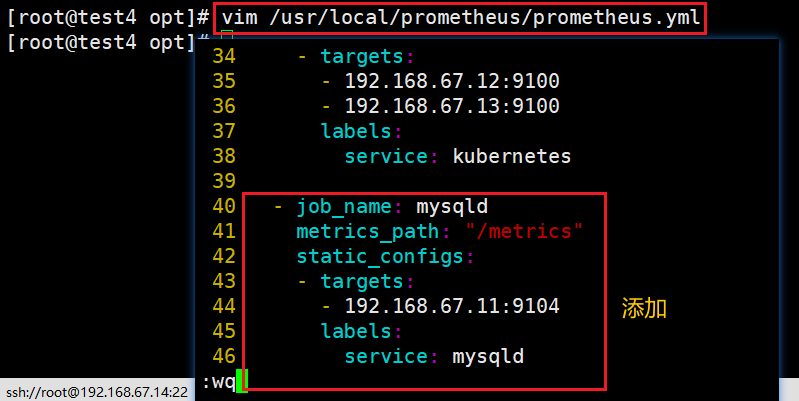
2)重新载入配置
curl -X POST http://192.168.10.80:9090/-/reload
#或
systemctl reload prometheus

浏览器查看 Prometheus 页面的 【Status】 ——> 【Targets】
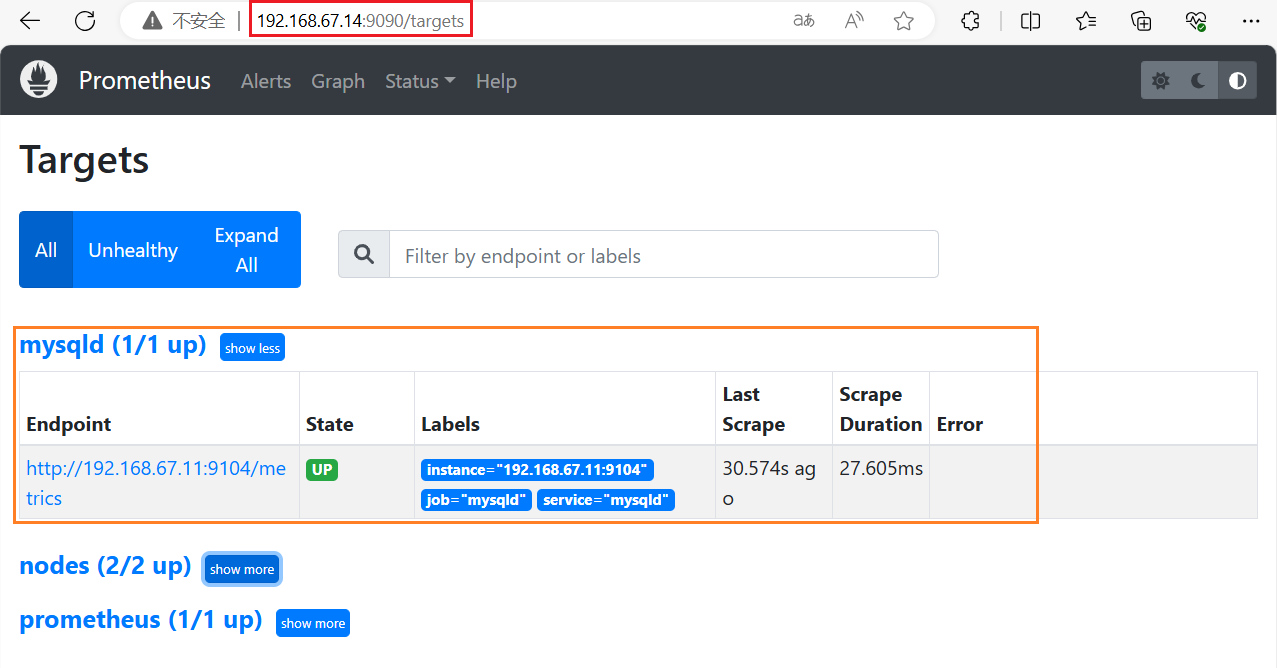
六、监控 Nginx 配置示例
#在 Nginx 服务器上操作;
找一台服务器部署nginx服务;这里我借用 k8s 集群中的 node01 节点来做nginx服务器,并不是在k8s的pod里面部署nginx;此时把node01当作一个部署nginx服务的普通服务器即可
下载 nginx-exporter 地址:https://github.com/hnlq715/nginx-vts-exporter/releases/download/v0.10.3/nginx-vts-exporter-0.10.3.linux-amd64.tar.gz
下载 nginx 地址:http://nginx.org/download/
下载 nginx 插件地址:https://github.com/vozlt/nginx-module-vts/tags
(1)解压 nginx 插件
cd /opt
#添加nginx-module-vts安装包#解压
tar xf nginx-module-vts-0.1.18.tar.gz
#移动
mv nginx-module-vts-0.1.18 /usr/local/nginx-module-vts
#查看
ls /usr/local/nginx-module-vts/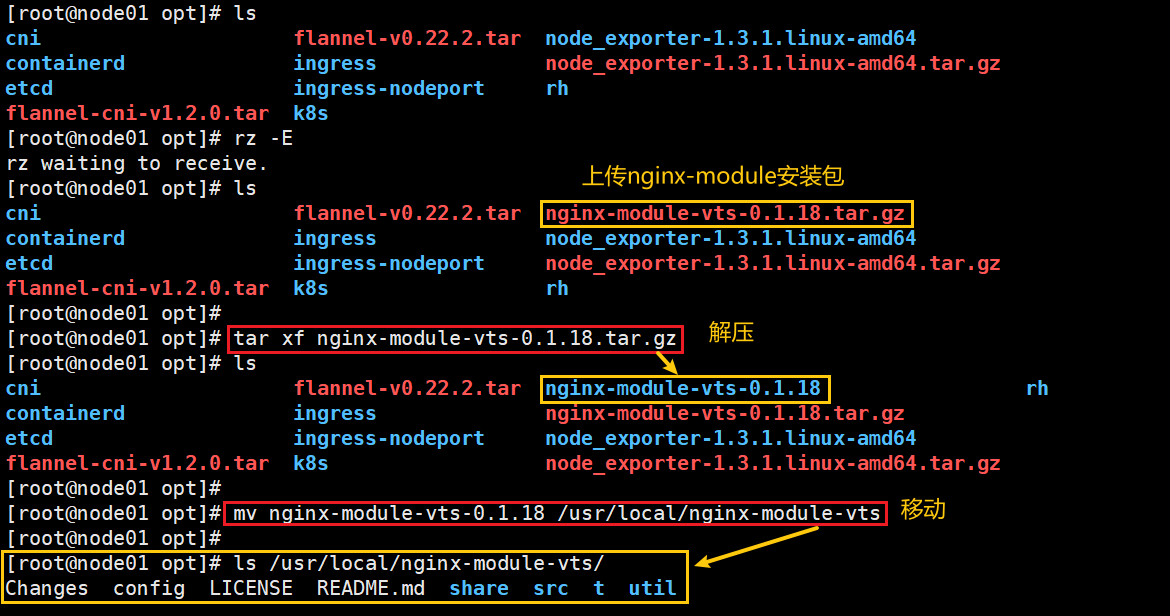
(2)安装 Nginx
通过程序用户,不能登录系统
cd /opt/
#添加 nginx 和 nginx-module-vts 安装包#环境
yum -y install pcre-devel zlib-devel openssl-devel gcc gcc-c++ make
#添加程序用户
useradd -M -s /sbin/nologin nginx#解包
cd /opt
tar xf nginx-1.18.0.tar.gz
#编译安装
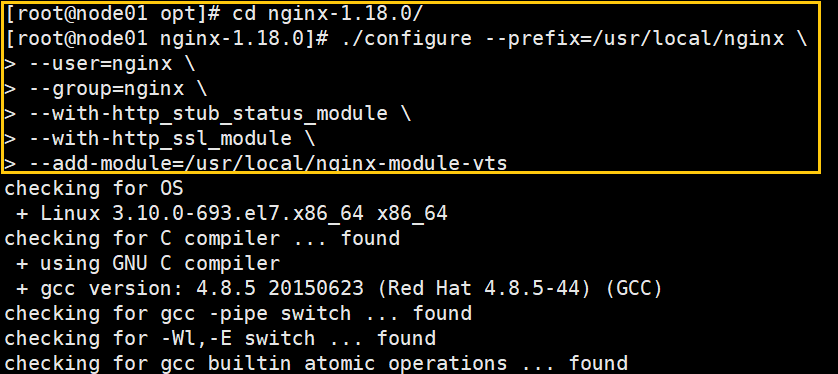
cd nginx-1.18.0/
./configure --prefix=/usr/local/nginx \
--user=nginx \
--group=nginx \
--with-http_stub_status_module \
--with-http_ssl_module \
--add-module=/usr/local/nginx-module-vts
make & make install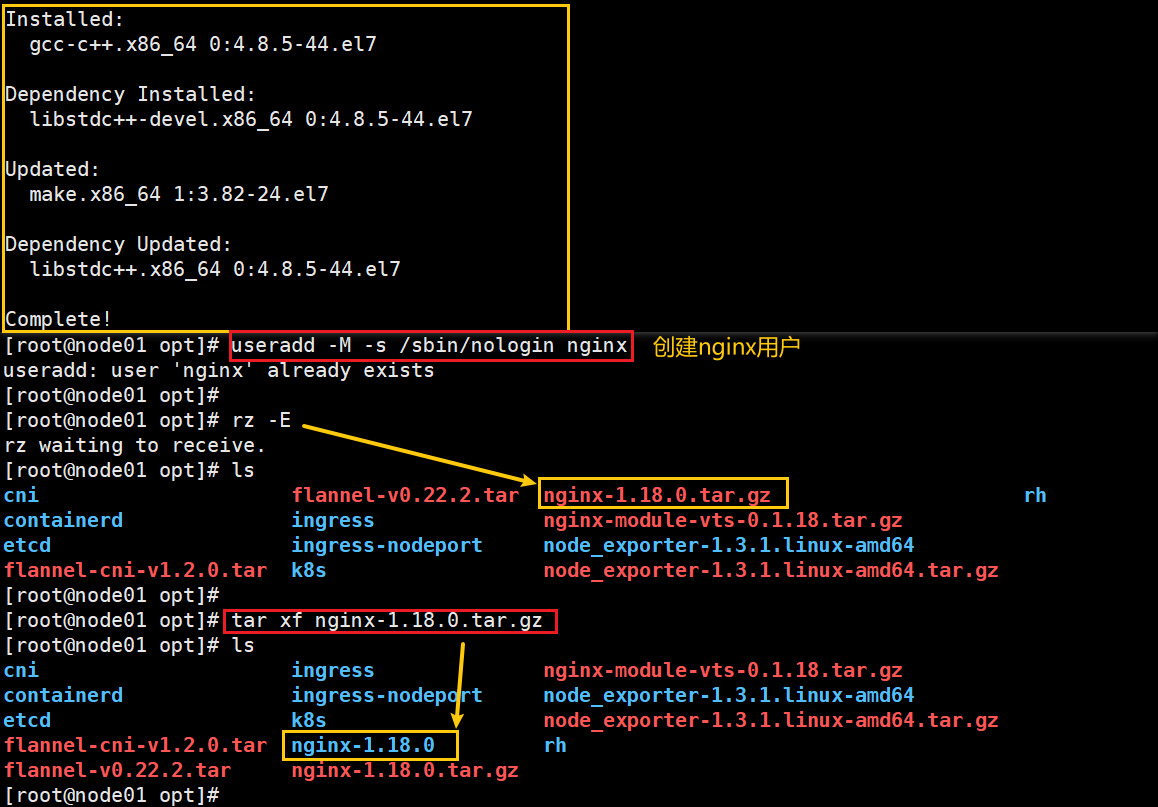

(3)修改 nginx 配置文件,启动 nginx
#备份
cd /usr/local/nginx/conf/
cp nginx.conf nginx.conf.bak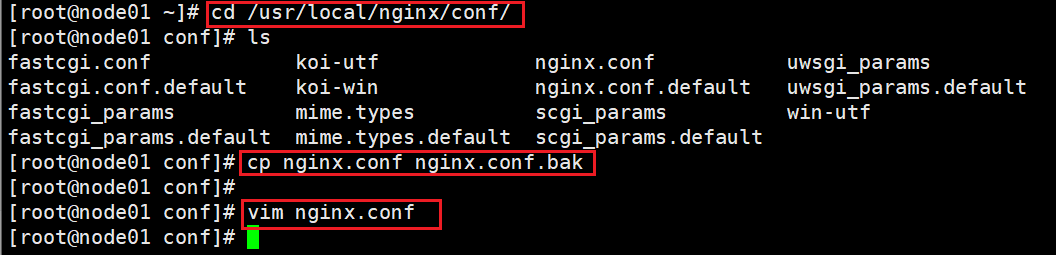
vim /usr/local/nginx/conf/nginx.conf
http {
#添加
vhost_traffic_status_zone;
#添加,开启此功能,在 Nginx 配置有多个 server_name 的情况下,会根据不同的 server_name 进行流量的统计,否则默认会把流量全部计算到第一个 server_name 上
vhost_traffic_status_filter_by_host on;
......
server {
......
}
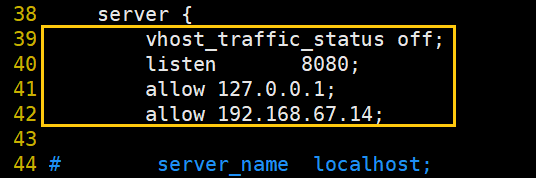
server {
#在不想统计流量的 server 区域,可禁用 vhost_traffic_status
vhost_traffic_status off;
listen 8080;
#允许指定地址,相当于做白名单
allow 127.0.0.1;
#设置为 prometheus 的 ip 地址
allow 192.168.67.14;
#禁止所有,只允许上面的IP通过
deny all;
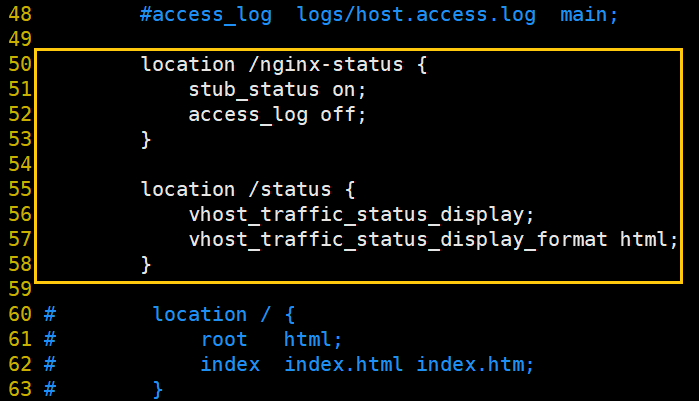
location /nginx-status {
stub_status on;
access_log off;
}
location /status {
vhost_traffic_status_display;
vhost_traffic_status_display_format html;
}
}
}#假如 nginx 没有规范配置 server_name 或者无需进行监控的 server 上,那么建议在此 vhost 上禁用统计监控功能。否则会出现 127.0.0.1、hostname 等的域名监控信息。

添加软连接,检查nginx.conf
#做软连接并检查nginx配置文件
ln -s /usr/local/nginx/sbin/nginx /usr/local/sbin/
nginx -t
添加启动配置文件
cat > /lib/systemd/system/nginx.service <<'EOF'
[Unit]
Description=nginx
After=network.target
[Service]
Type=forking
PIDFile=/usr/local/nginx/logs/nginx.pid
ExecStart=/usr/local/nginx/sbin/nginx
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
PrivateTmp=true
[Install]
WantedBy=multi-user.target
EOF启动nginx并设置开机自启
systemctl start nginx
systemctl enable nginx
systemctl status nginx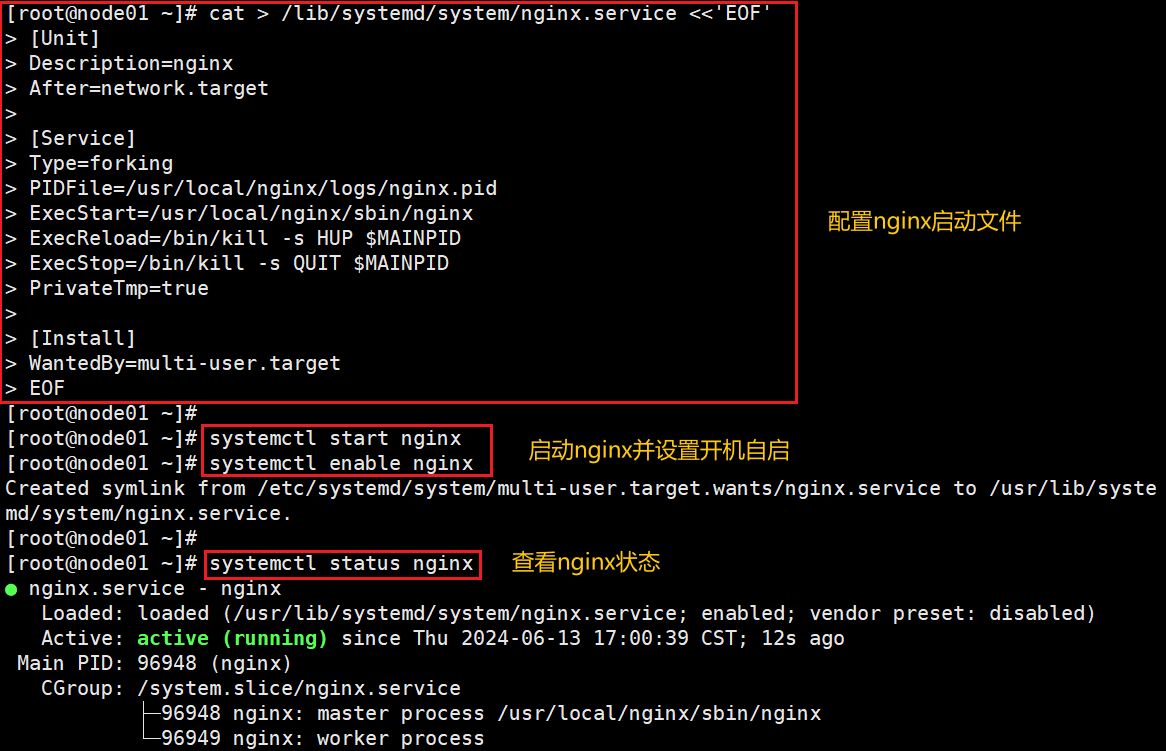
浏览器访问
浏览器访问:node01 的IP
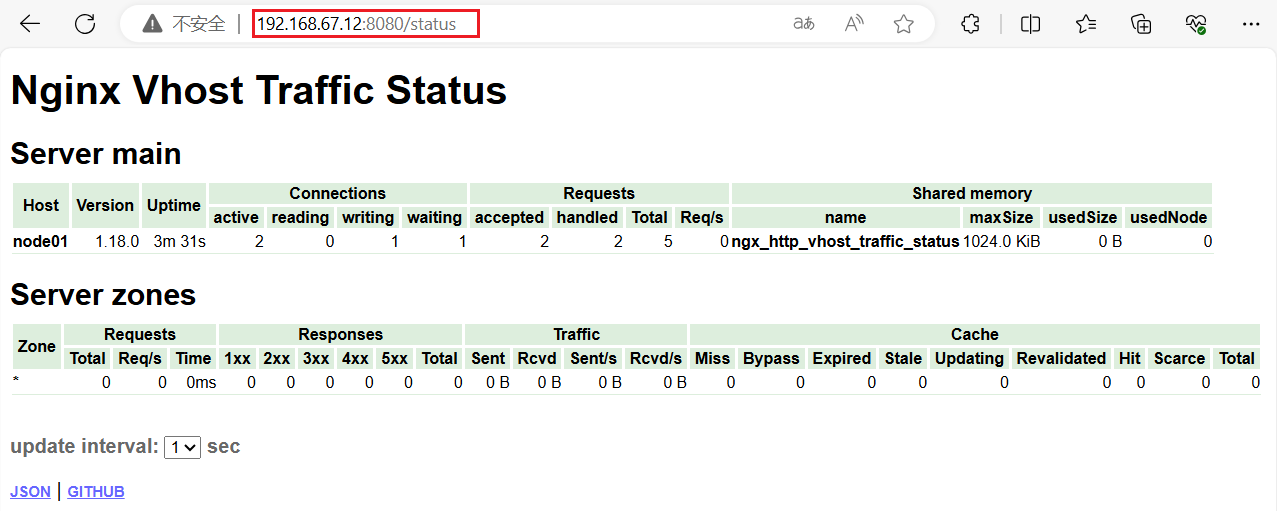
http://192.168.67.12:8080/status
可以看到 Nginx Vhost Traffic Status 的页面信息;
用于监控 Nginx 服务器上每个虚拟主机的流量情况
(4)解压 nginx-exporter,启动 nginx-exporter
配置nginx的prometheus监控端口
cd /opt/
#添加nginx-vts-exporter包#解压、移动、查看
tar -zxvf nginx-vts-exporter-0.10.3.linux-amd64.tar.gz
mv nginx-vts-exporter-0.10.3.linux-amd64/nginx-vts-exporter /usr/local/bin/
ls /usr/local/bin/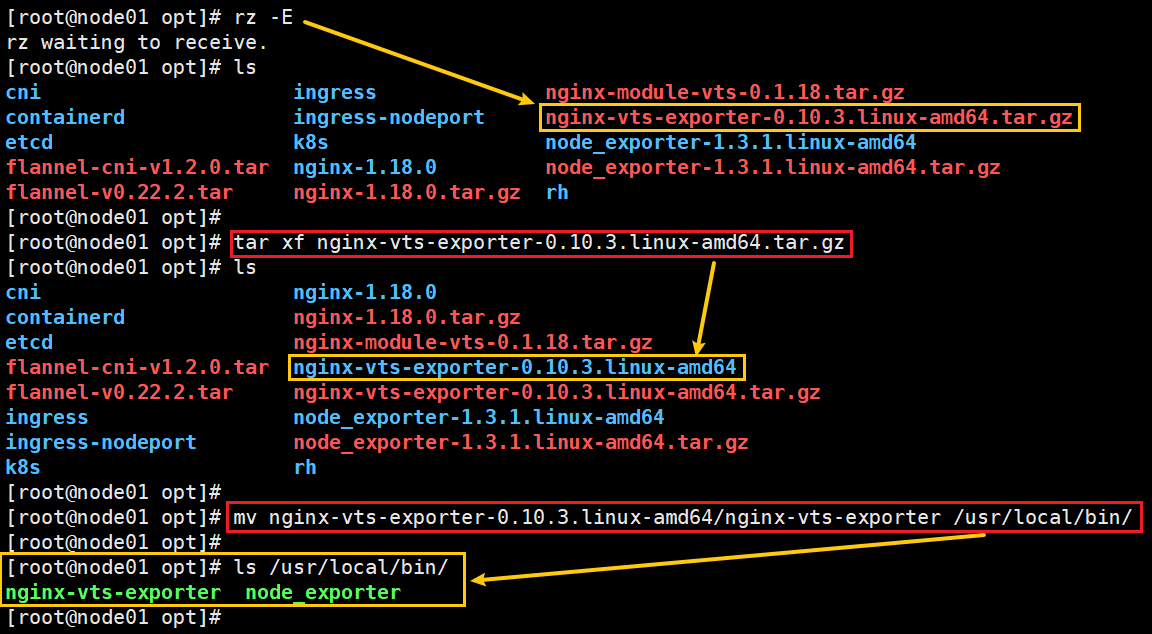
添加启动配置文件
cat > /usr/lib/systemd/system/nginx-exporter.service <<'EOF'
[Unit]
Description=nginx-exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/bin/nginx-vts-exporter -nginx.scrape_uri=http://localhost:8080/status/format/json
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF启动nginx-exporter并设置开机自启
#启动nginx-exporter并设置开机自启
systemctl start nginx-exporter
systemctl enable nginx-exporter
#查看9913端口
netstat -natp | grep :9913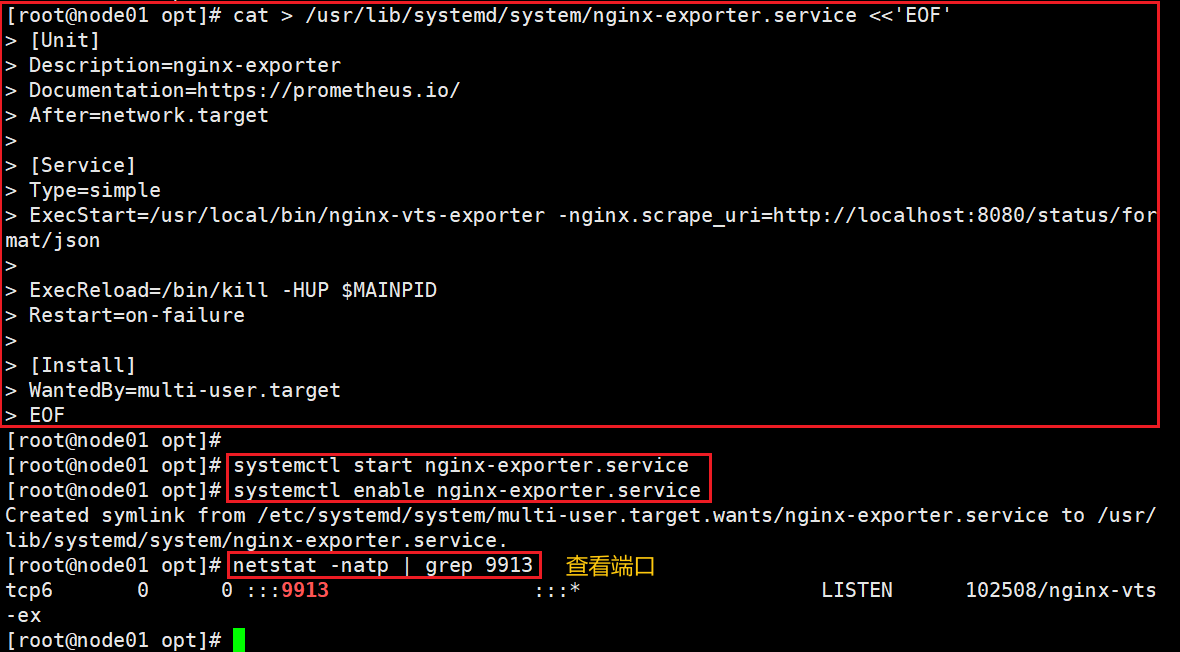
在 Prometheus 服务器上操作
(1)修改 prometheus 配置文件,加入到 prometheus 监控中
vim /usr/local/prometheus/prometheus.yml
#在尾部增加如下内容
- job_name: nginx
metrics_path: "/metrics"
static_configs:
- targets:
# nginx服务器的IP地址
- 192.168.67.12:9913
labels:
service: nginx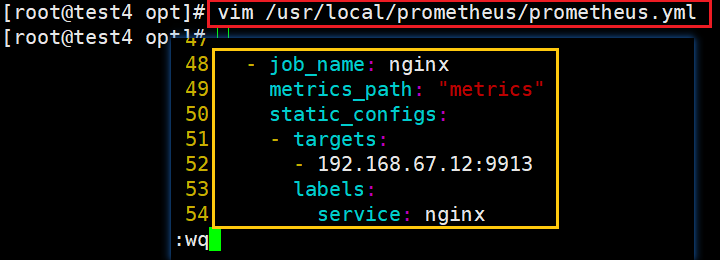
(2)重新载入配置
curl -X POST http://192.168.10.80:9090/-/reload
#或
systemctl reload prometheus
浏览器查看 Prometheus 页面的 Status -> Targets
七、部署 Grafana 进行展示

Grafana是一个开源的度量分析和可视化工具,可以通过将采集的数据分析,查询,然后进行可视化的展示,并能实现报警
(1)下载和安装
下载地址:https://grafana.com/grafana/download
https://mirrors.bfsu.edu.cn/grafana/yum/rpm/
这里我安装的 grafana-enterprise-8.5.9-1.x86_64.rpm 包
cd /opt
#添加 grafana-enterprise-8.5.9-1.x86_64.rpm 包yum install -y grafana-7.4.0-1.x86_64.rpm
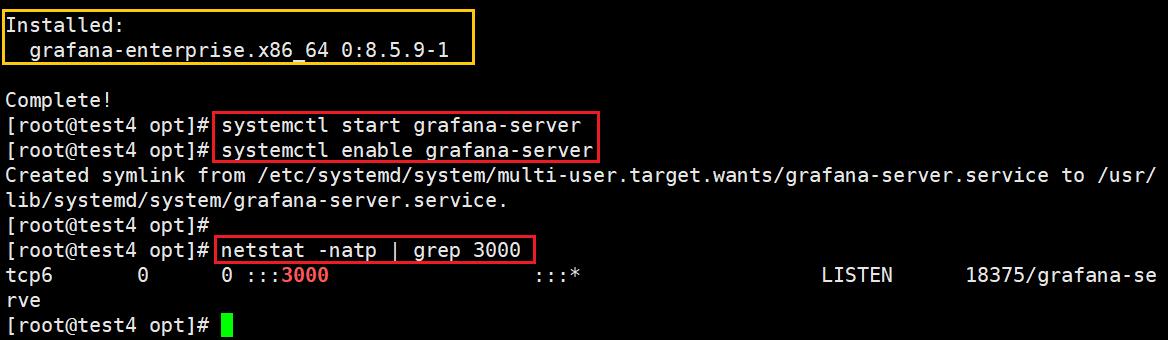
#启动grafana并设置开机自启
systemctl start grafana-server
systemctl enable grafana-server
#查看3000端口
netstat -natp | grep :3000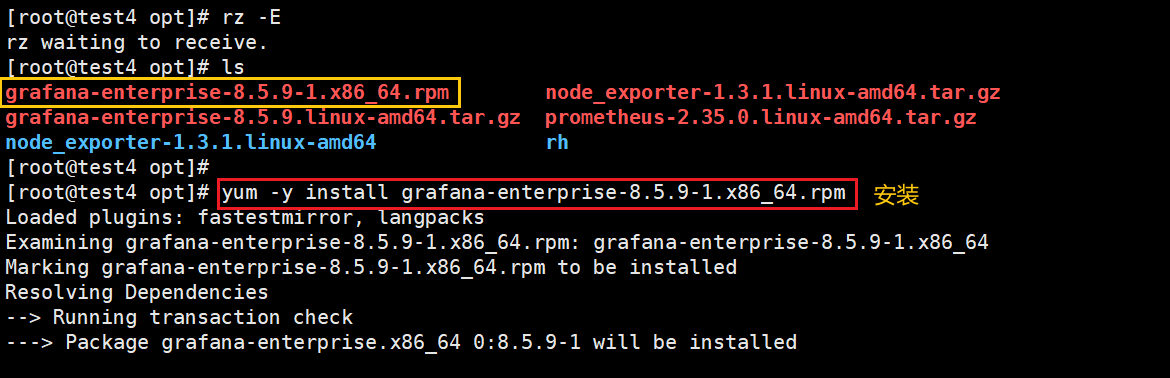
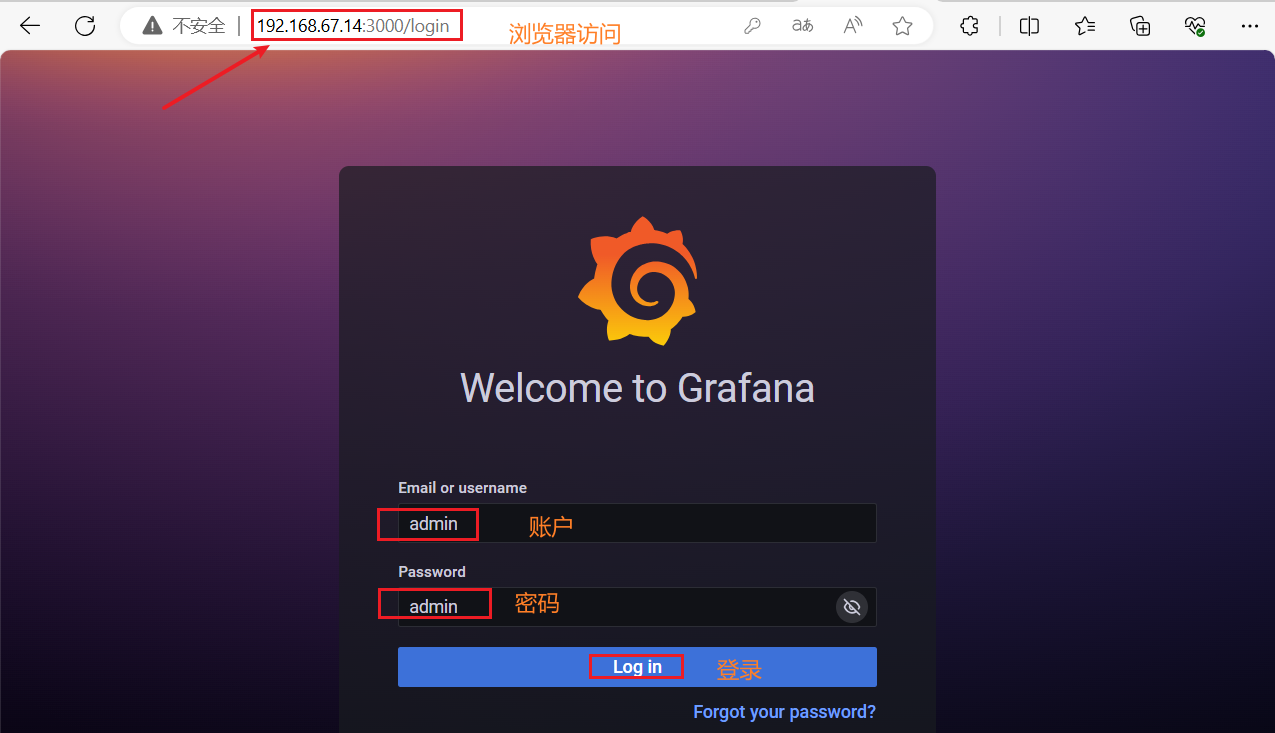
(2)浏览器访问
浏览器访问:Prometheus的IP地址
http://192.168.67.14:3000
默认账号和密码为 admin/admin
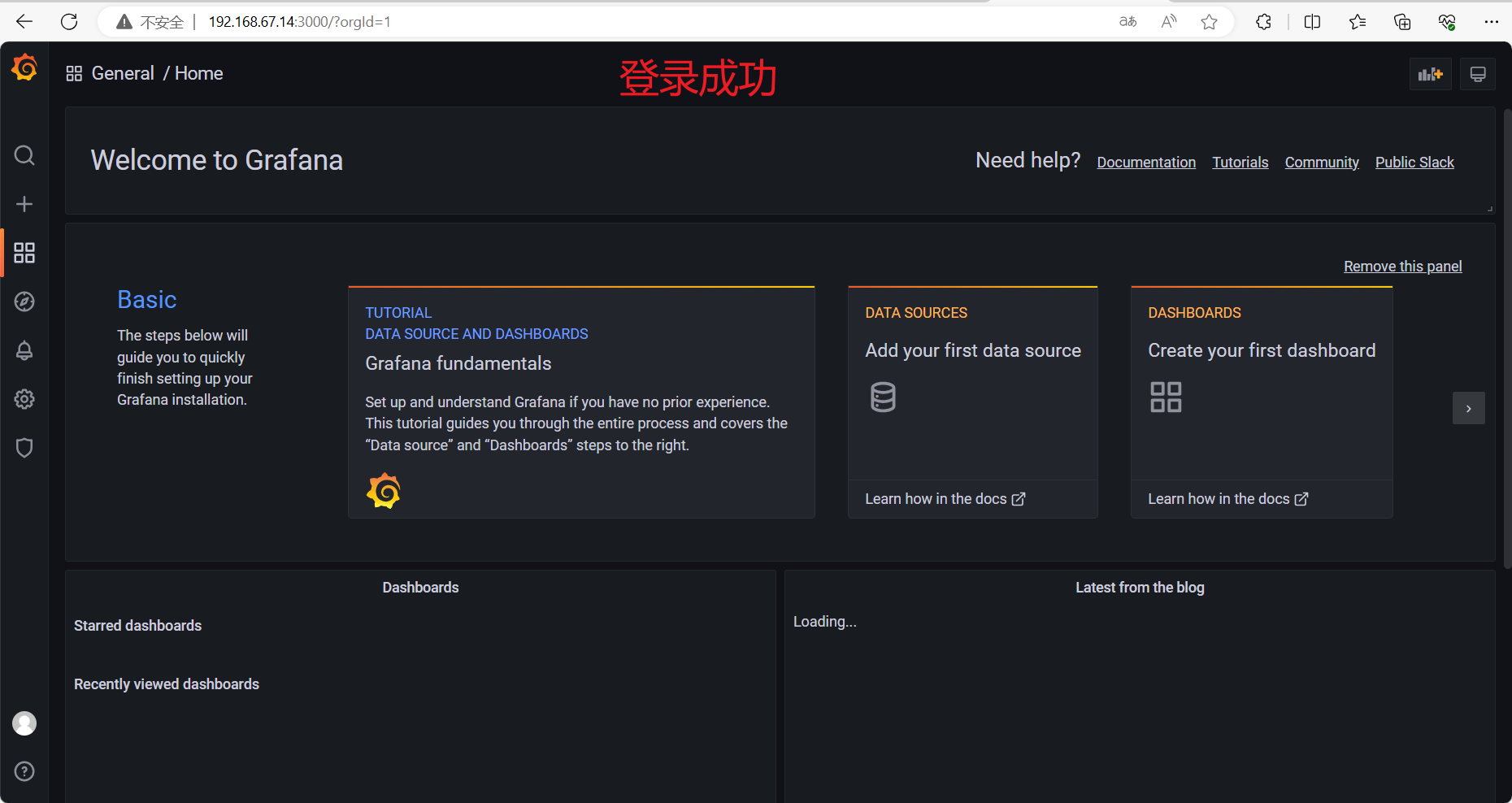
登录后会提示你修改密码,不想修改的话点击【Skip】跳过

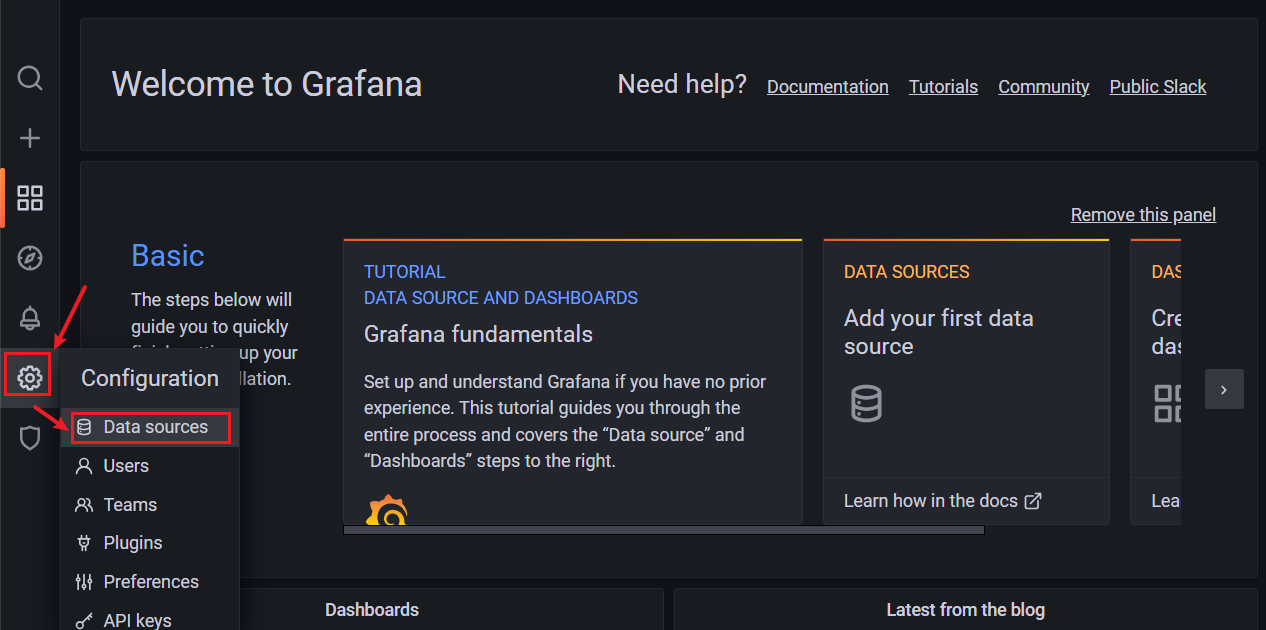
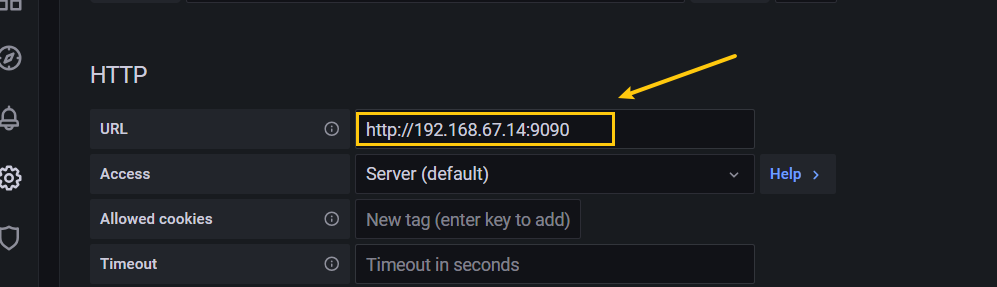
(3)配置数据源
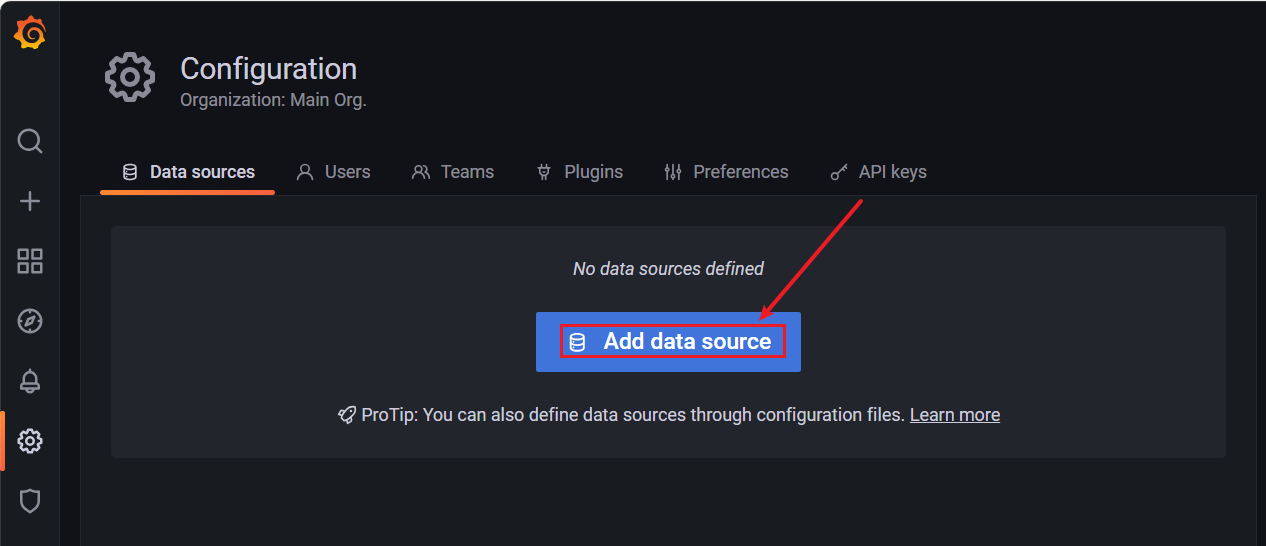
【Configuration】 ——> 【Data Sources】
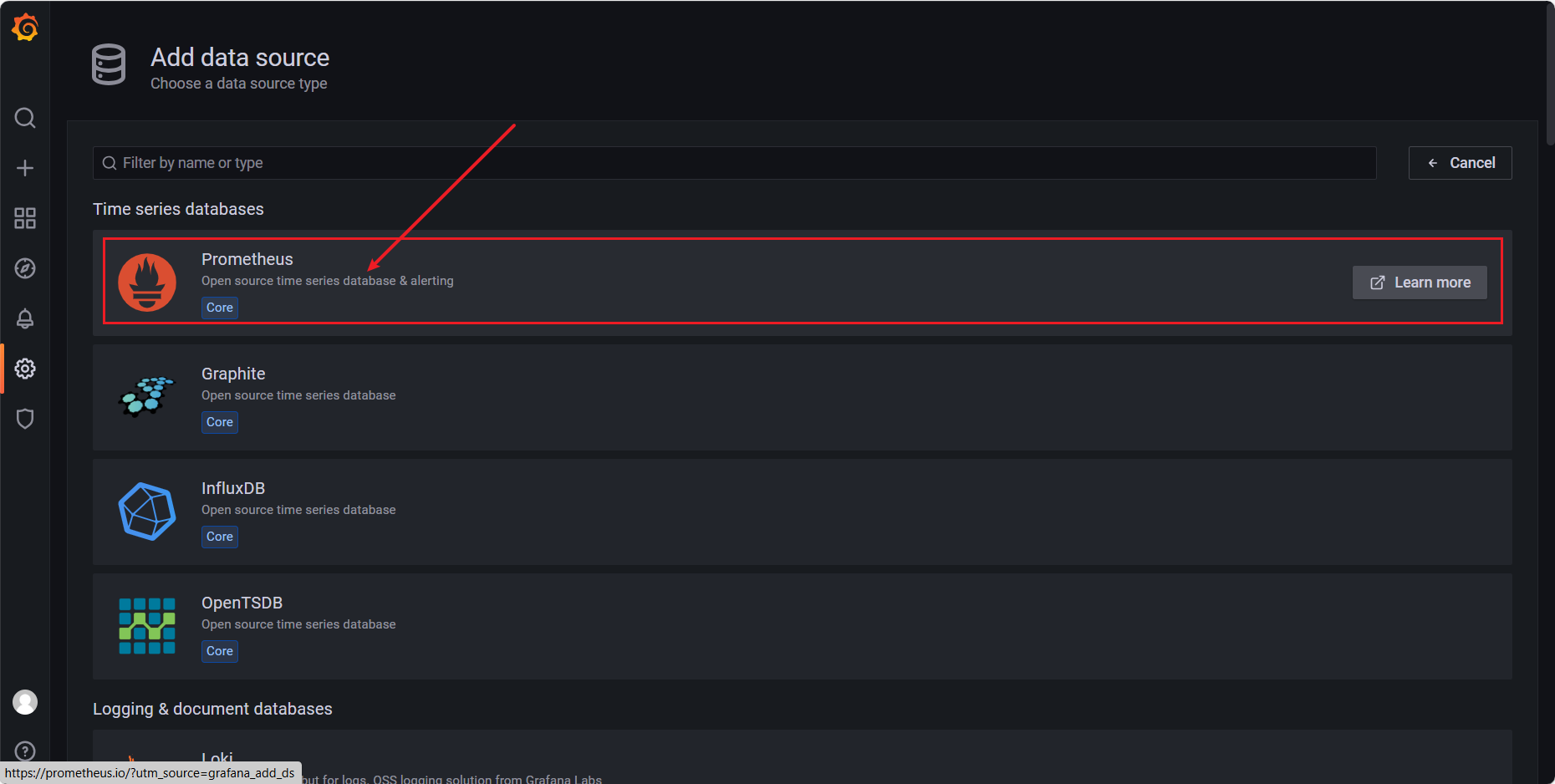
【Add data source】 ——> 选择 【Prometheus】
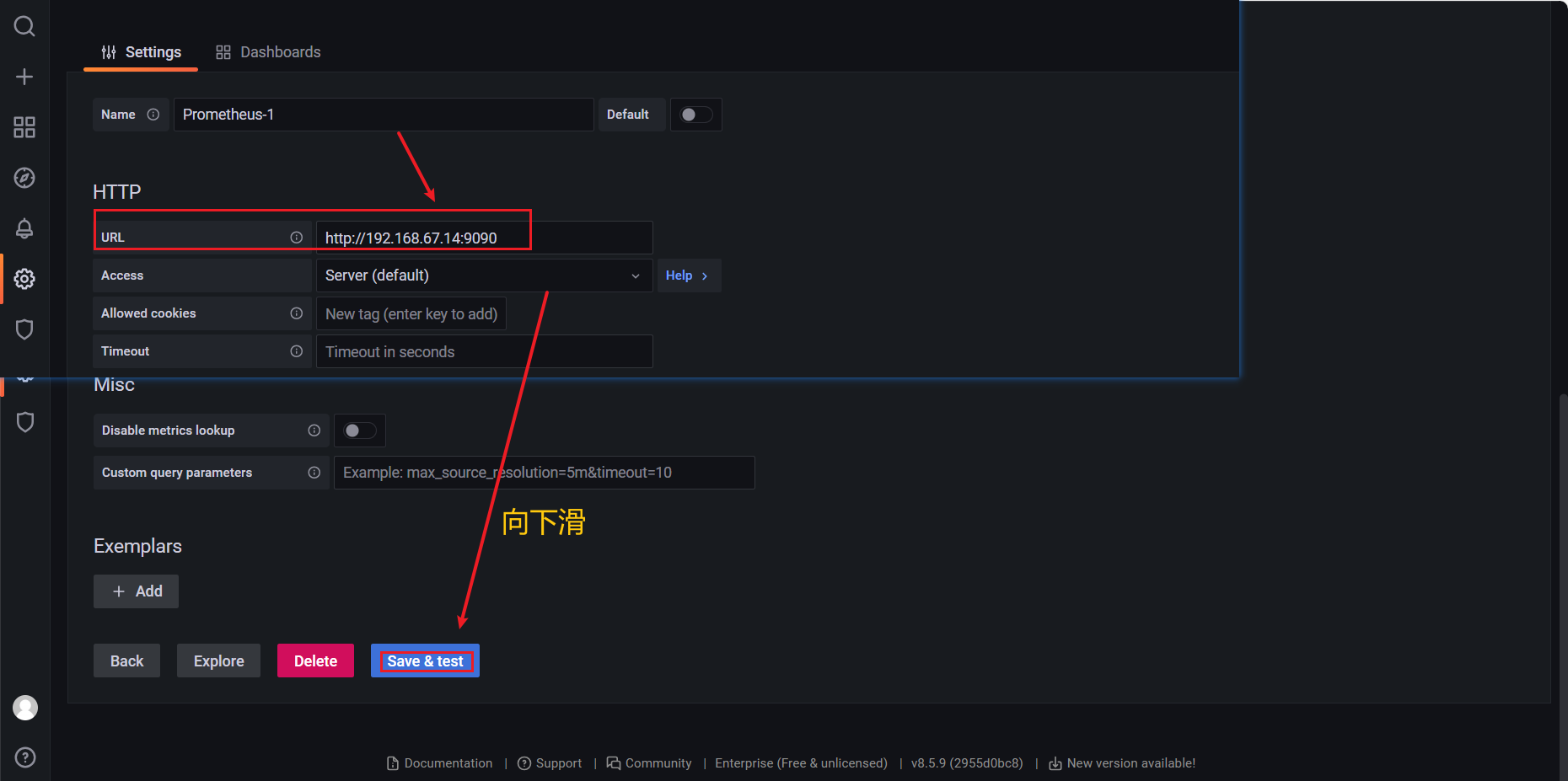
【HTTP】 ——> 【URL】 输入 http://192.168.67.14:9090
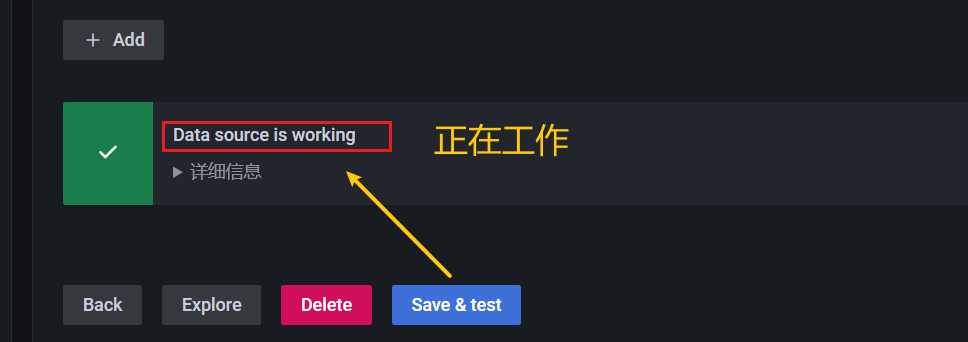
点击 【Save & Test】
点击 上方菜单 【Dashboards】,【Import】 所有默认模板
Dashboards -> Manage ,选择 Prometheus 2.0 Stats 或 Prometheus Stats 即可看到 Prometheus job 实例的监控图像
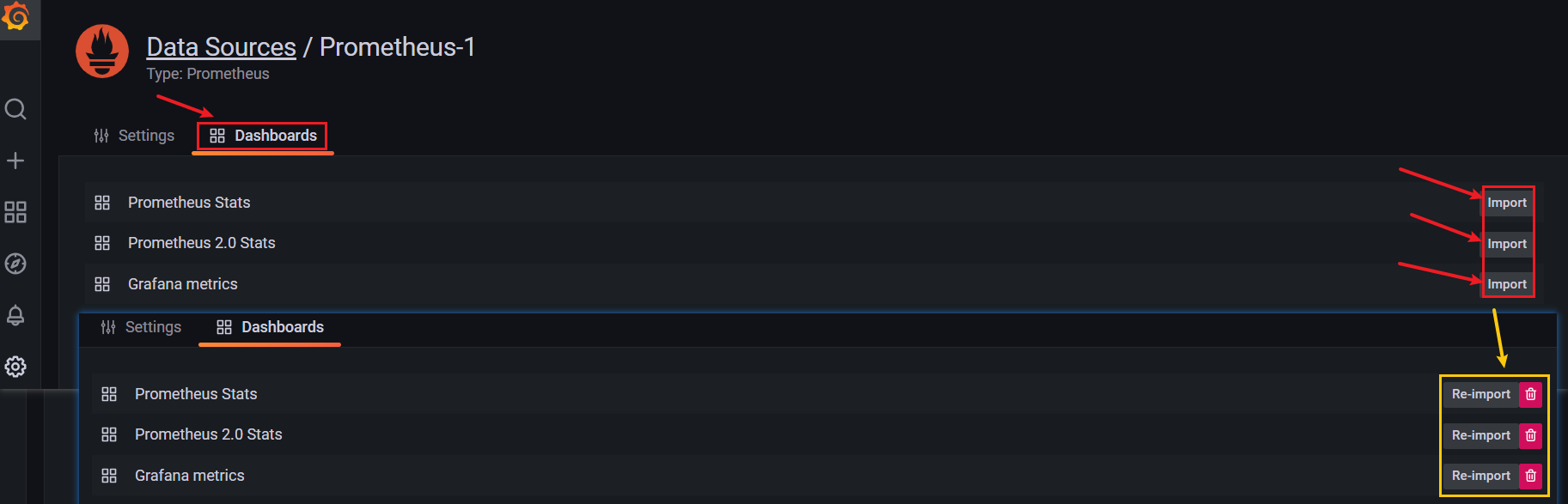
(4)导入 grafana 监控面板
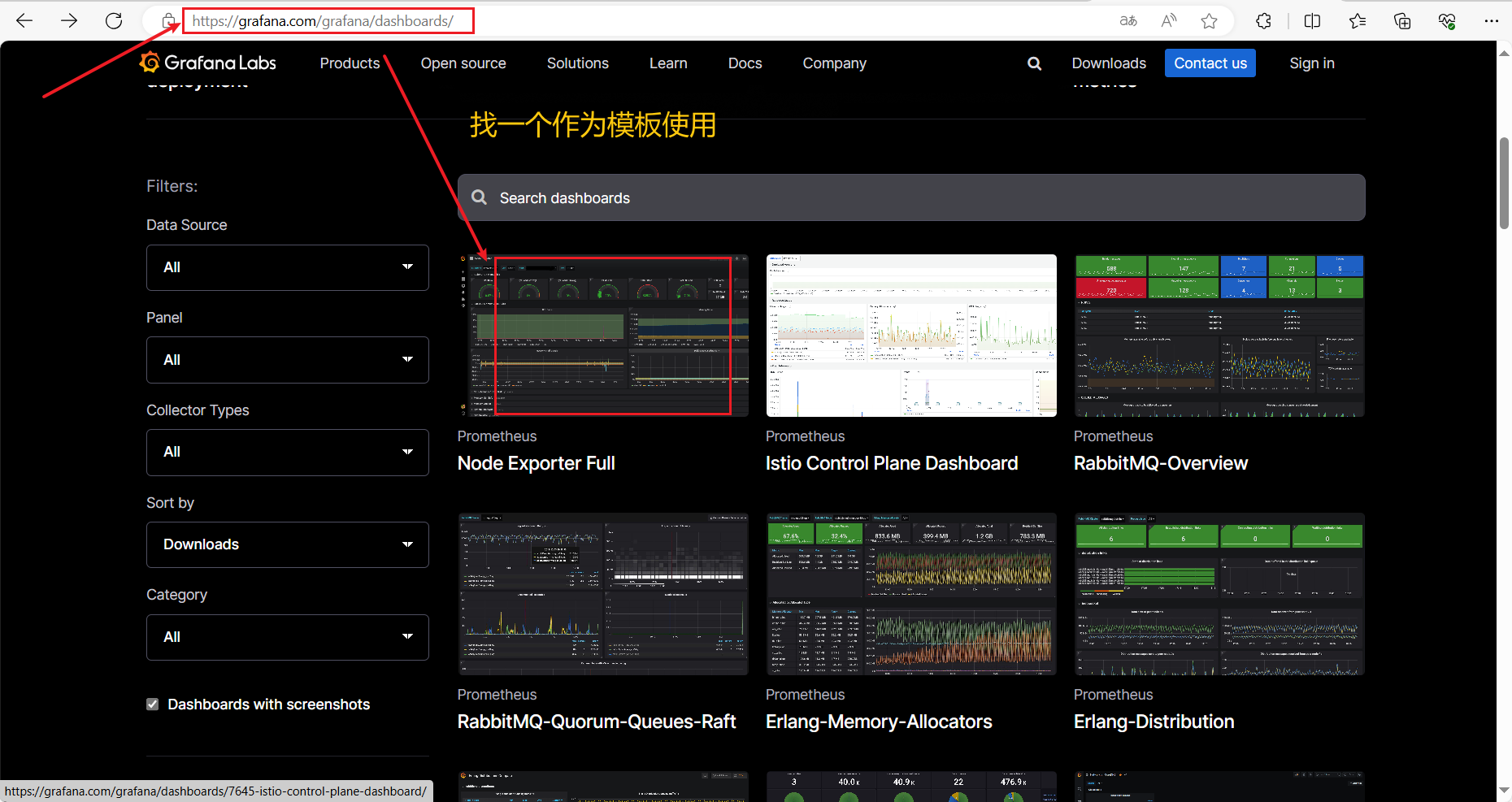
浏览器访问:
https://grafana.com/grafana/dashboards/
在页面中搜索 【node exporter】 ,选择适合的面板;
点击 【Copy ID】 或者 【Download JSON】
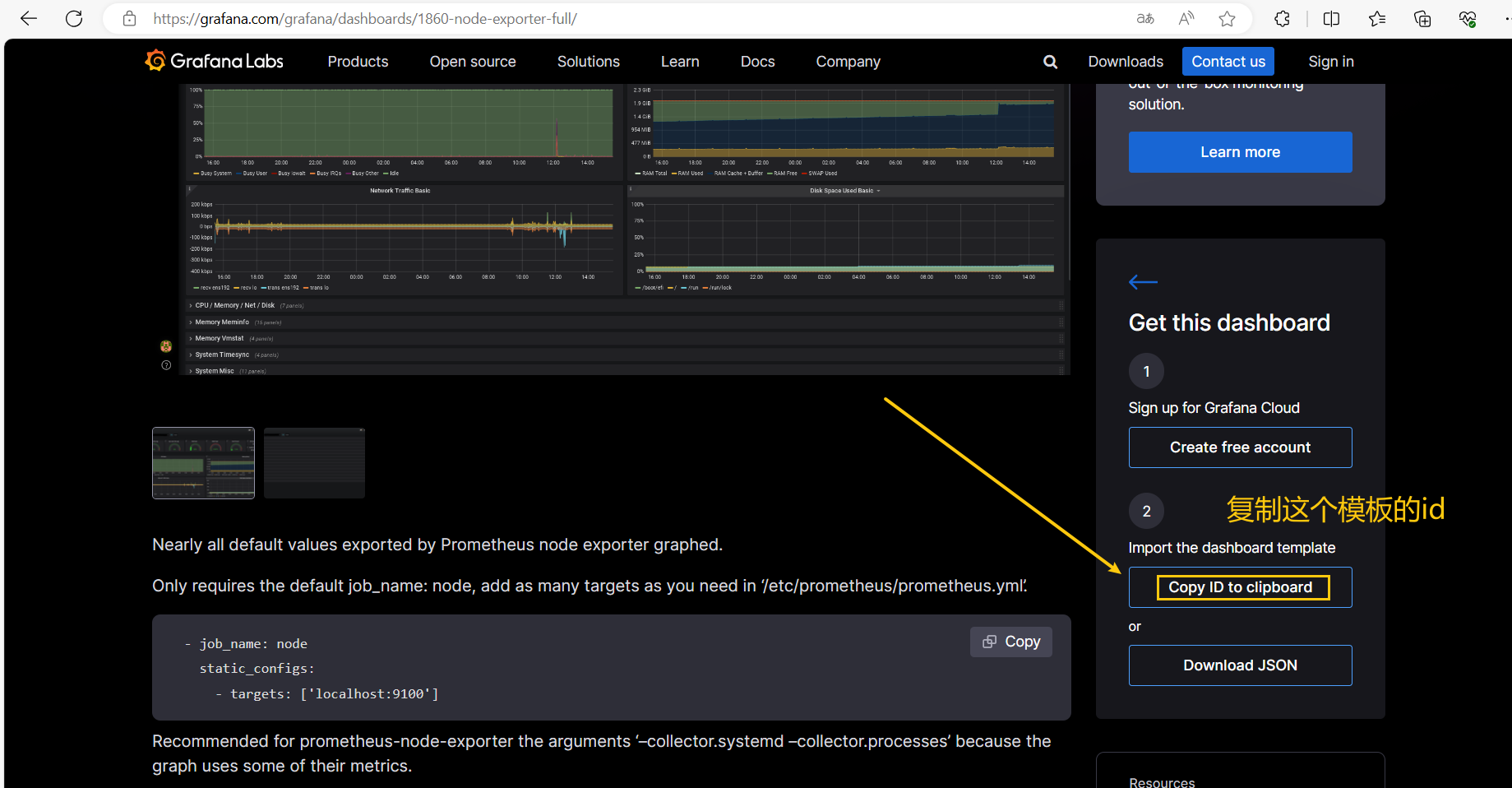
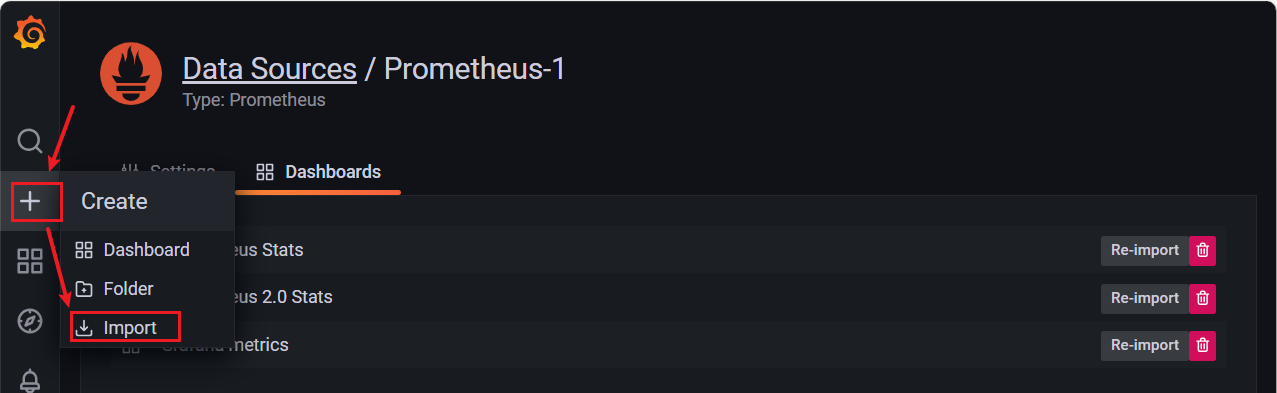
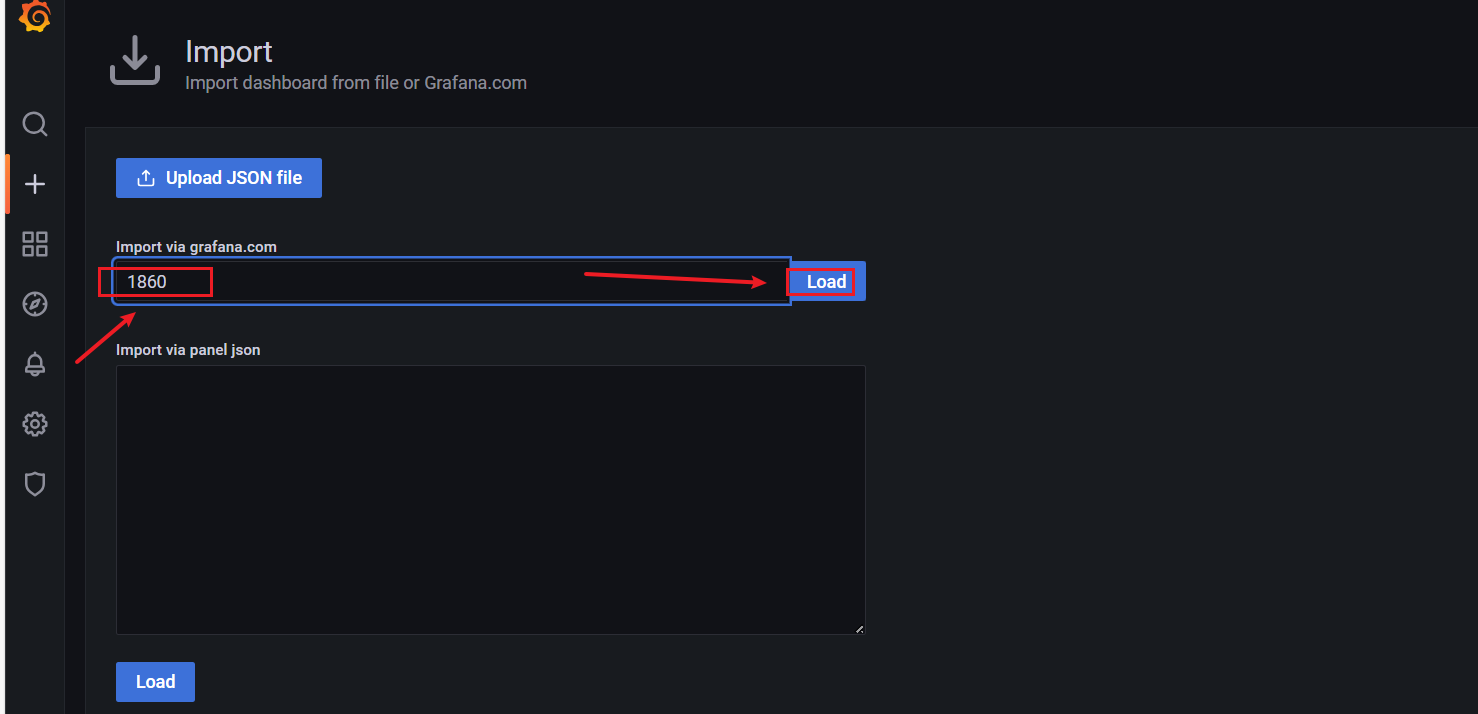
在 grafana 页面中,【+ Create】 ——> 【Import】;
输入【面板 ID 号】,点击右侧的 【Load】,即可导入监控面板
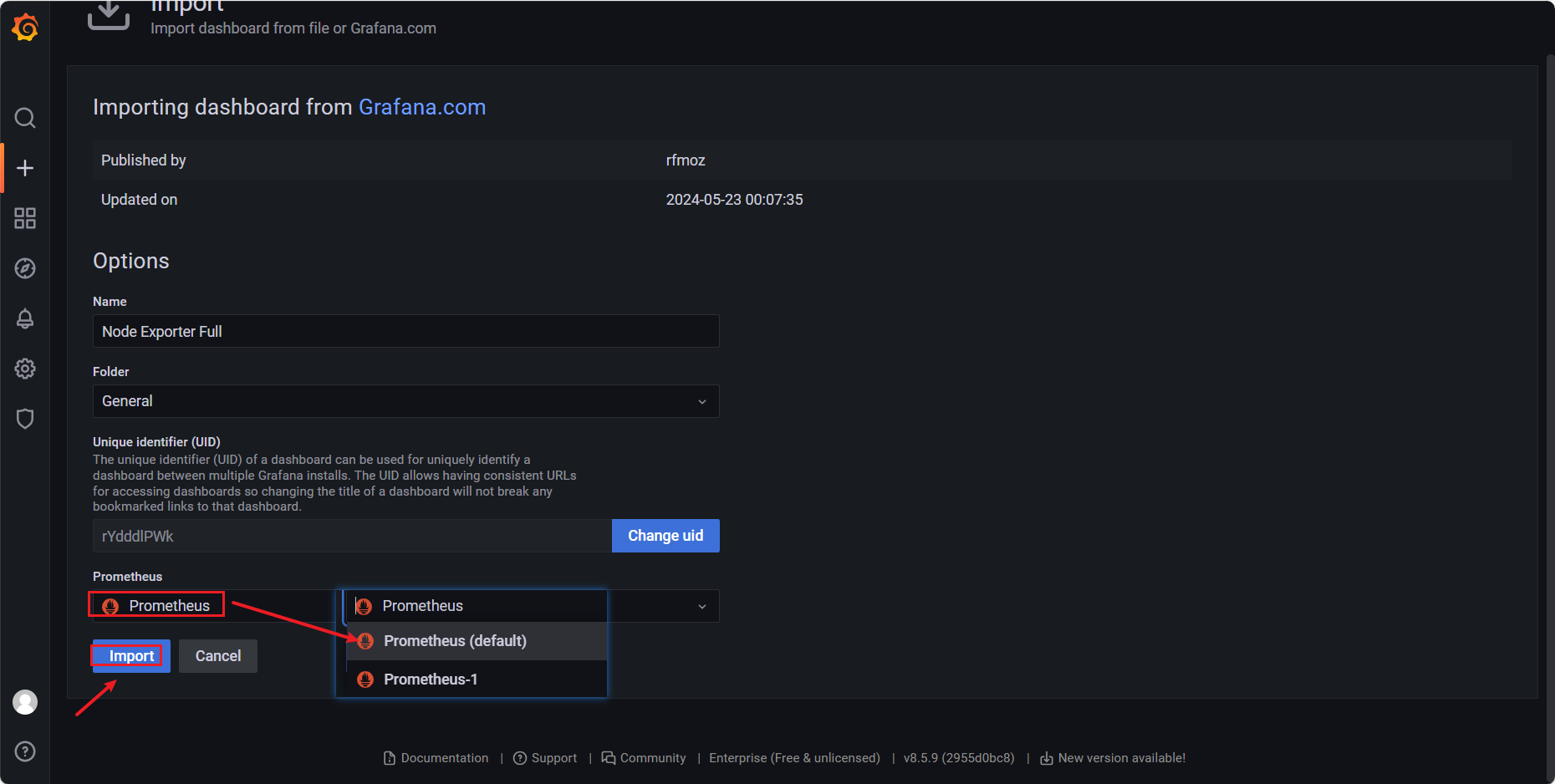
#或者上传 【JSON 文件】,点击下面的 【Load】
下拉,选择【Prometheus(default)】,点击【Import】
报错:提示更新数据源代理时出现问题
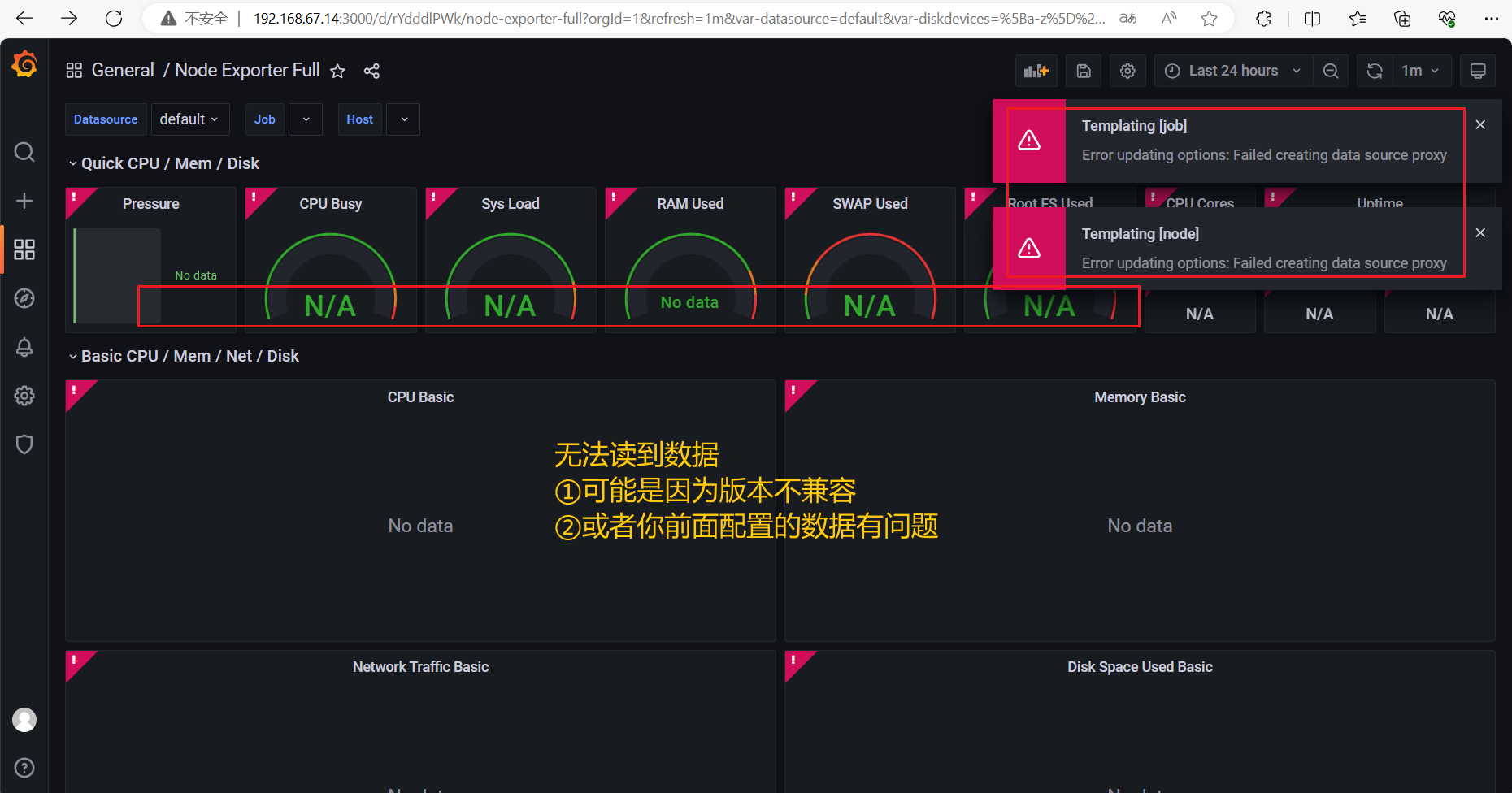
原因:前面配置数据源时,没配置上
解决:重新配置了一下 Prometheus 的数据源
八、部署 Prometheus 服务发现
基于文件的服务发现
基于文件的服务发现是仅仅略优于静态配置的服务发现方式,它不依赖于任何平台或第三方服务,因而也是最为简单和通用的实现方式。
Prometheus Server 会定期从文件中加载 Target 信息,文件可使用 YAML 和 JSON 格式,它含有定义的 Target 列表,以及可选的标签信息。
(1)创建用于服务发现的文件,在文件中配置所需的 target
#创建target 目录
cd /usr/local/prometheus
mkdir targets#创建用于服务发现的文件,在文件中配置所需的 target
vim targets/node-exporter.yaml
- targets:
- 192.168.67.12:9100
- 192.168.67.13:9100
labels:
app: node-exporter
job: nodesvim targets/mysqld-exporter.yaml
- targets:
- 192.168.67.11:9104
labels:
app: mysqld-exporter
job: mysqldvim targets/nginx-exporter.yaml
- targets:
- 192.168.67.12:9913
labels:
app: nginx-exporter
job: nginx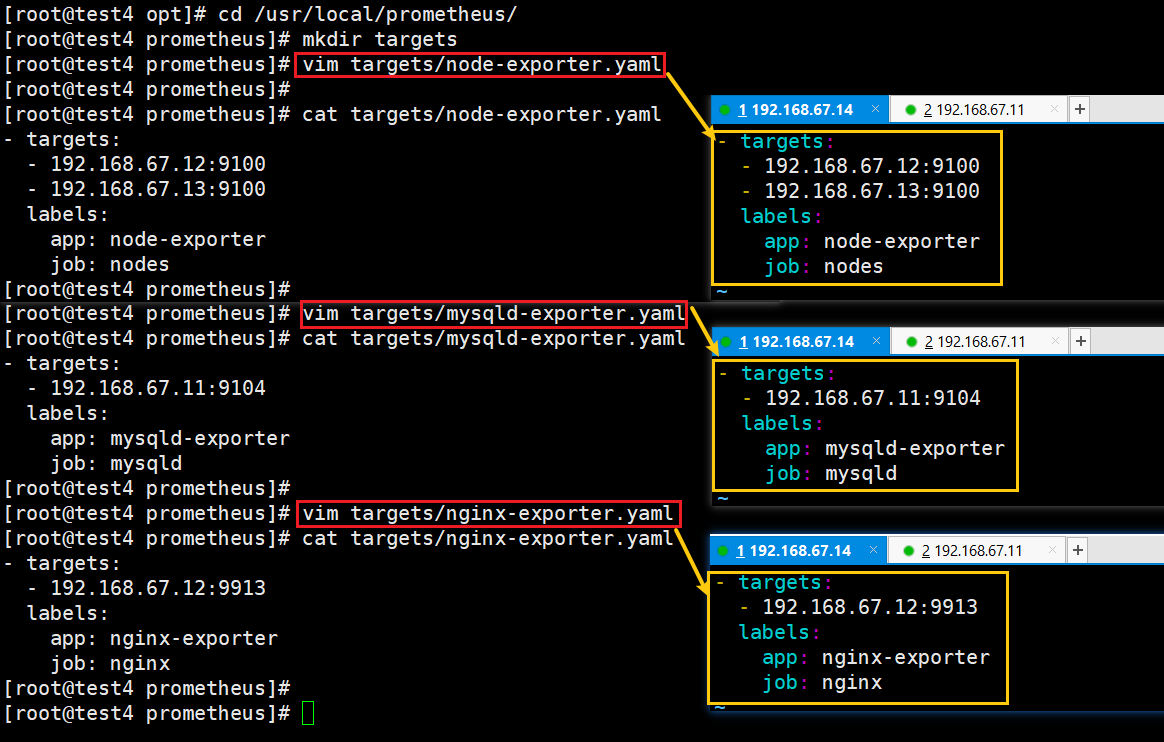
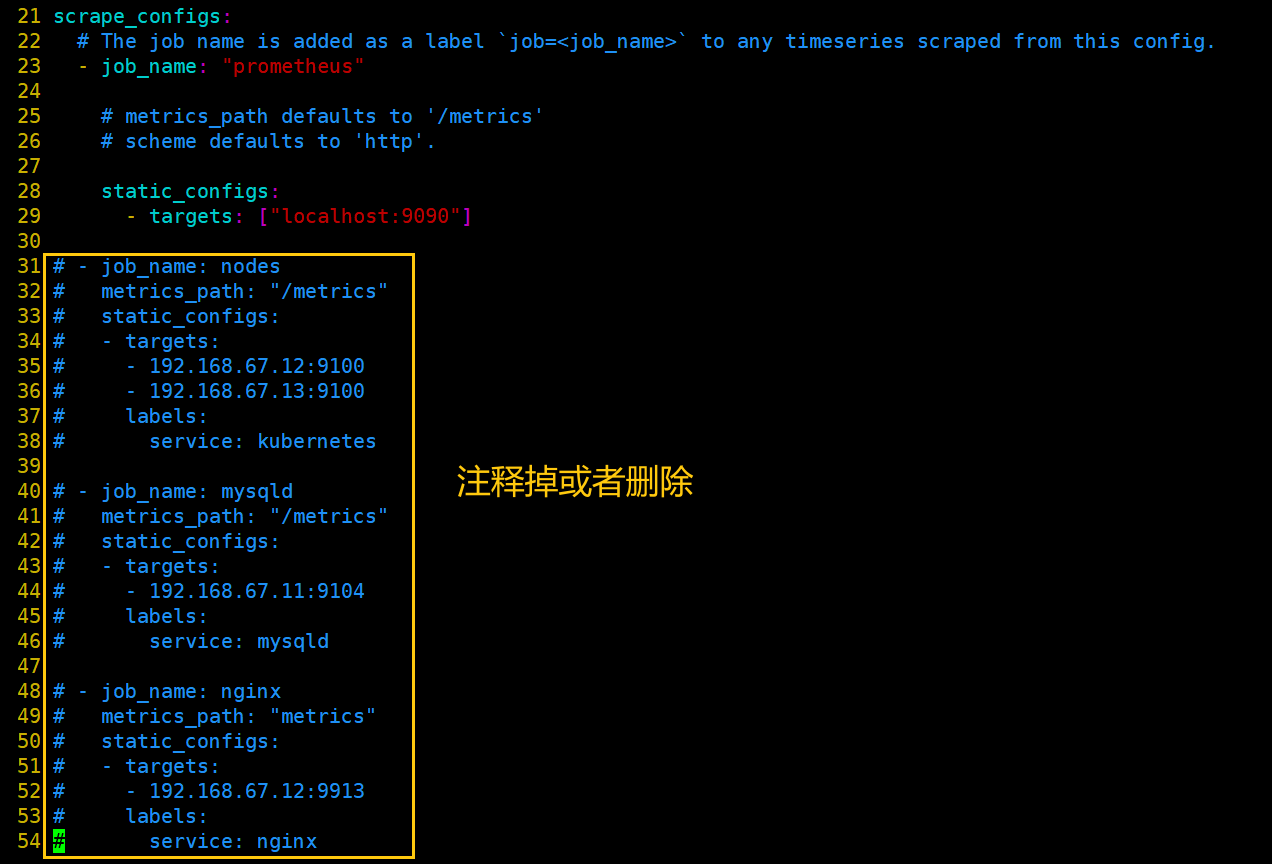
(2)发现 target 的配置
vim /usr/local/prometheus/prometheus.yml视图模式 ctrl+v;然后使用上下方向键选中;点r ,点#
#重新载入配置文件并访问
systemctl reload prometheus.service#浏览器访问
http://192.168.67.14:9090/targets

#修改 prometheus 配置文件,发现 target 的配置,定义在配置文件的 job 之中
vim /usr/local/prometheus/prometheus.yml
......
scrape_configs:
- job_name: nodes
file_sd_configs: #指定使用文件服务发现
- files: #指定要加载的文件列表
- targets/node*.yaml #文件加载支持通配符
refresh_interval: 2m #每隔 2 分钟重新加载一次文件中定义的 Targets,默认为 5m
- job_name: mysqld
file_sd_configs:
- files:
- targets/mysqld*.yaml
refresh_interval: 2m
- job_name: nginx
file_sd_configs:
- files:
- targets/nginx*.yaml
refresh_interval: 2m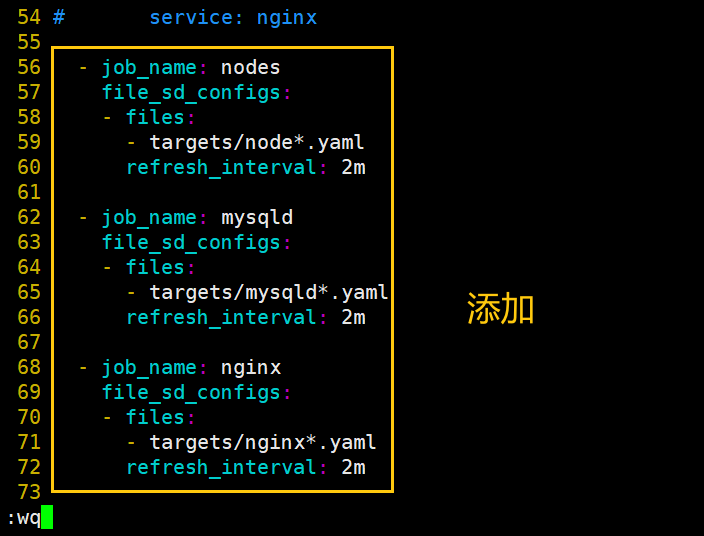
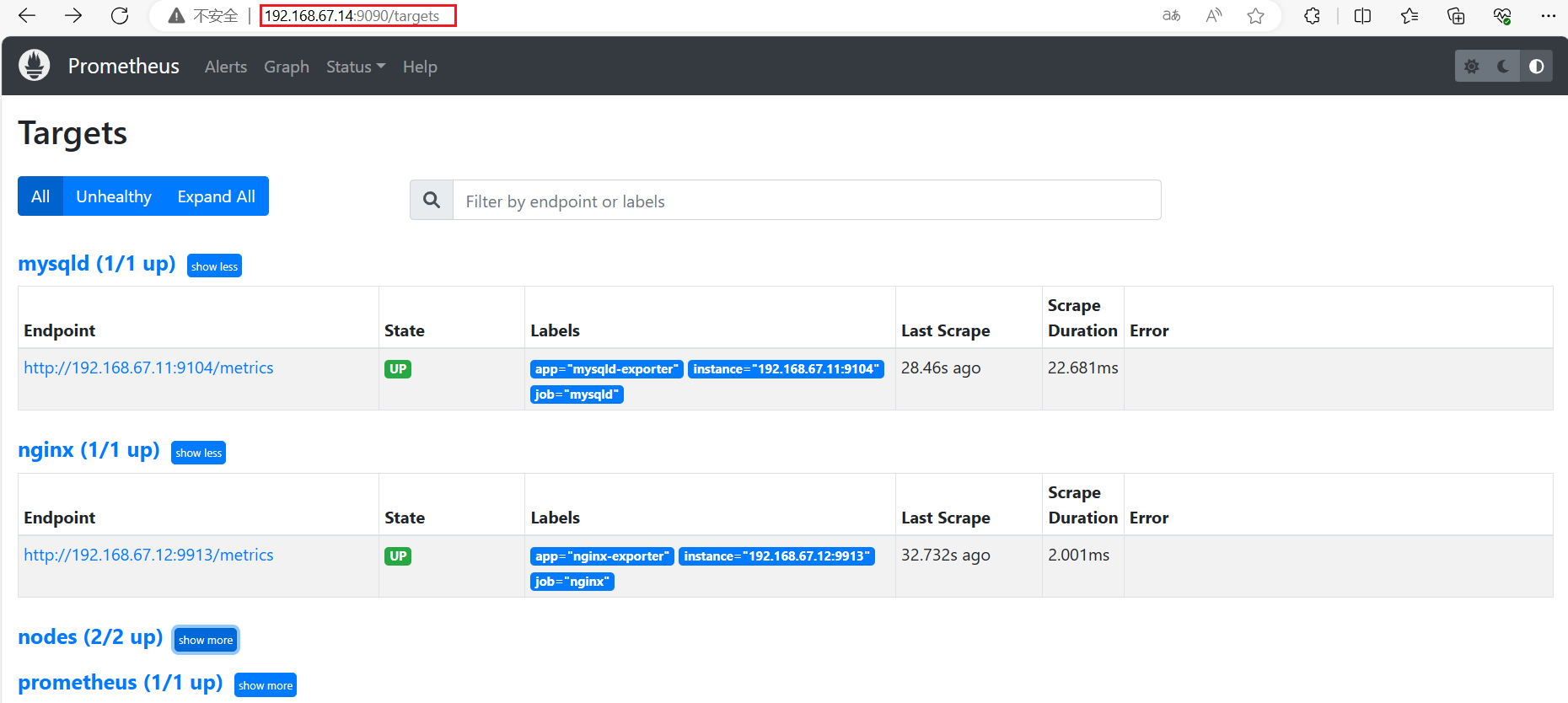
(3)重新加载并访问
#重新加载 prometheus 配置文件
systemctl reload prometheus浏览器查看 Prometheus 页面的 【Status】 ——> 【Targets】
九、基于 Consul 的服务发现
Consul 是一款基于 golang 开发的开源工具,主要面向分布式,服务化的系统提供服务注册、服务发现和配置管理的功能。
提供服务注册/发现、健康检查、Key/Value存储、多数据中心和分布式一致性保证等功能。
下载地址:https://www.consul.io/downloads/
(1)部署 Consul 服务
cd /opt/
#添加 consul 安装包#解压、移动
unzip consul_1.9.2_linux_amd64.zip
mv consul /usr/local/bin/#创建 Consul 服务的数据目录和配置目录
mkdir /var/lib/consul-data
mkdir /etc/consul/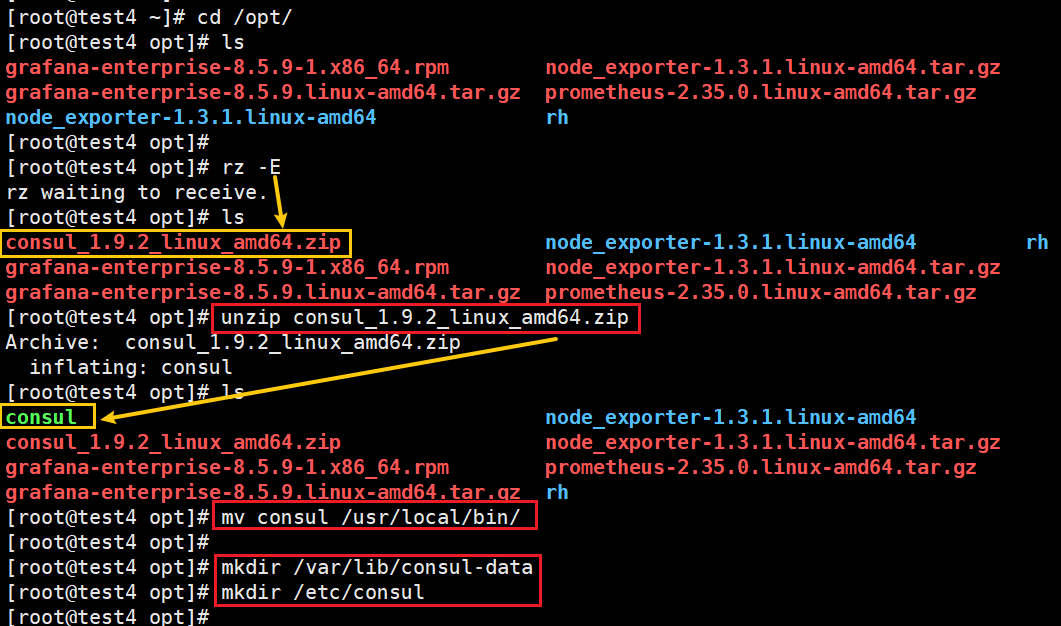
#使用 server 模式启动 Consul 服务
consul agent \
-server \
-bootstrap \
-ui \
-data-dir=/var/lib/consul-data \
-config-dir=/etc/consul/ \
-bind=192.168.67.14 \
-client=0.0.0.0 \
-node=consul-server01 &> /var/log/consul.log &这是一个启动 Consul 代理的命令。根据提供的命令,Consul 代理将以服务器模式启动,并作为引导节点(bootstrap)来初始化集群。它还启用了 Consul 的用户界面(UI),并指定了数据目录和配置目录的路径
#查看 consul 集群成员
consul members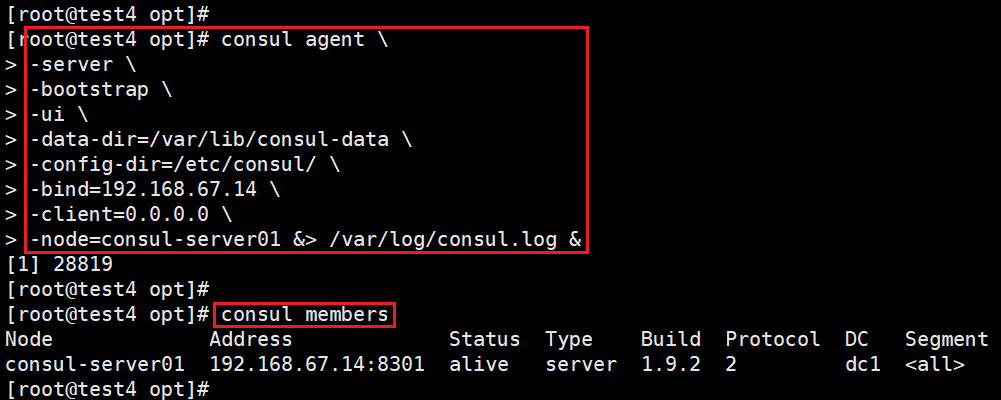
(2)在 Consul 上注册 Services
#在配置目录中添加文件
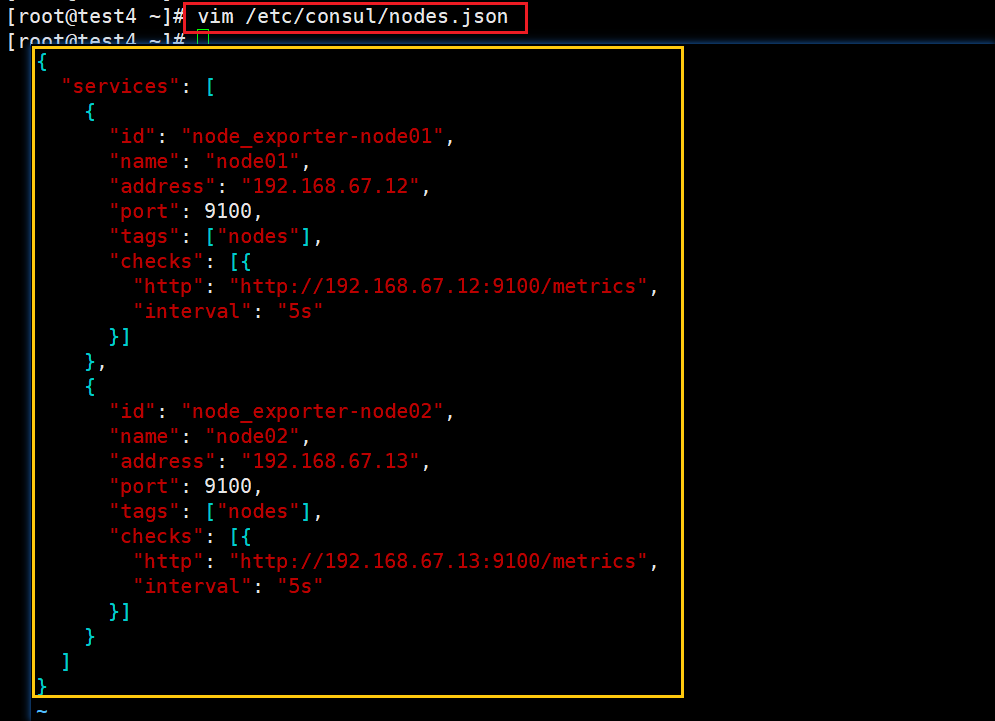
vim /etc/consul/nodes.json
{
# k8s-node01
"services": [
{
"id": "node_exporter-node01",
"name": "node01",
"address": "192.168.67.12",
"port": 9100,
"tags": ["nodes"],
"checks": [{
"http": "http://192.168.67.12:9100/metrics",
"interval": "5s"
}]
},
# k8s-node02
{
"id": "node_exporter-node02",
"name": "node02",
"address": "192.168.67.13",
"port": 9100,
"tags": ["nodes"],
"checks": [{
"http": "http://192.168.67.13:9100/metrics",
"interval": "5s"
}]
}
]
}
#让 consul 重新加载配置信息
consul reload
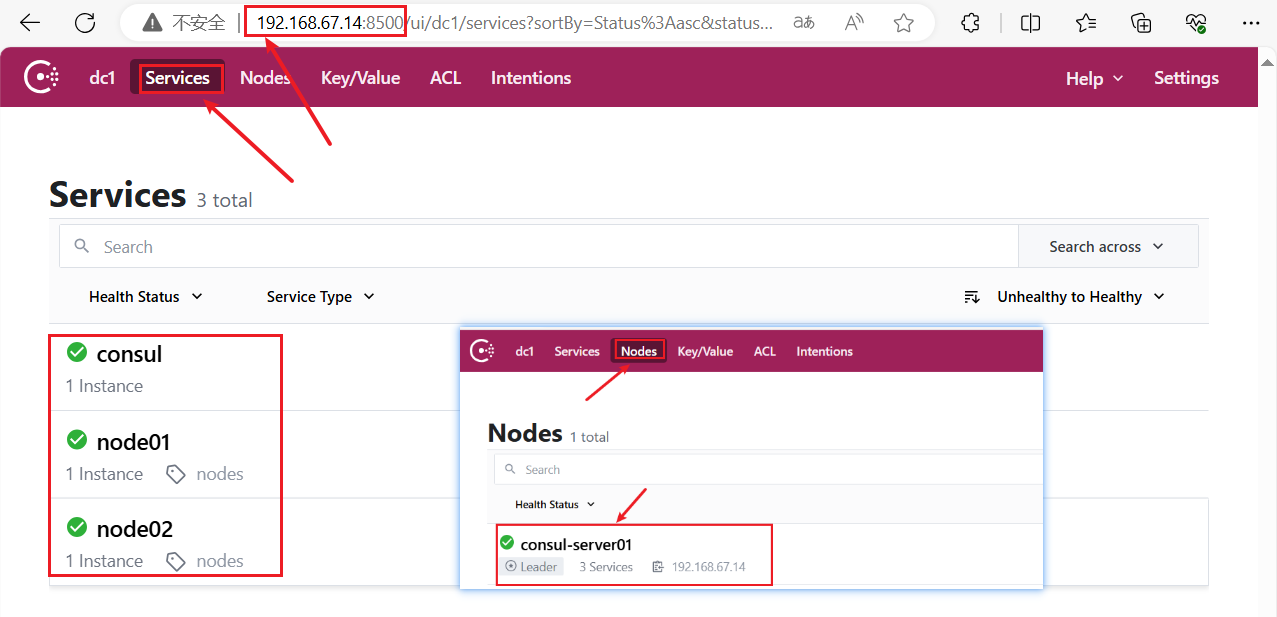
#浏览器访问
浏览器访问:
http://192.168.67.14:8500
(3)修改 prometheus 配置文件
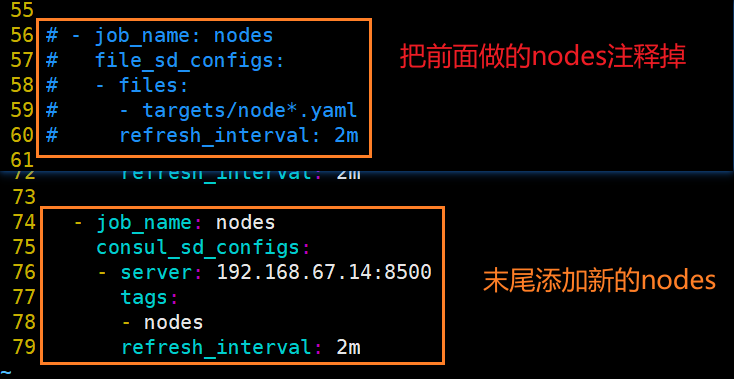
#把前面做的nodes注释掉
vim /usr/local/prometheus/prometheus.yml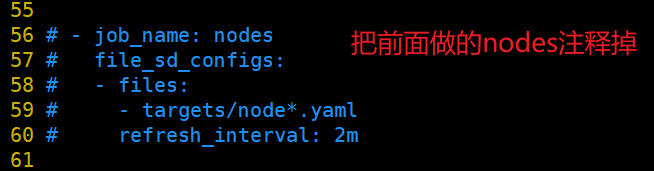
#重载并访问,确认失效
systemctl reload prometheus.servicehttp://192.168.67.14:9090/targets
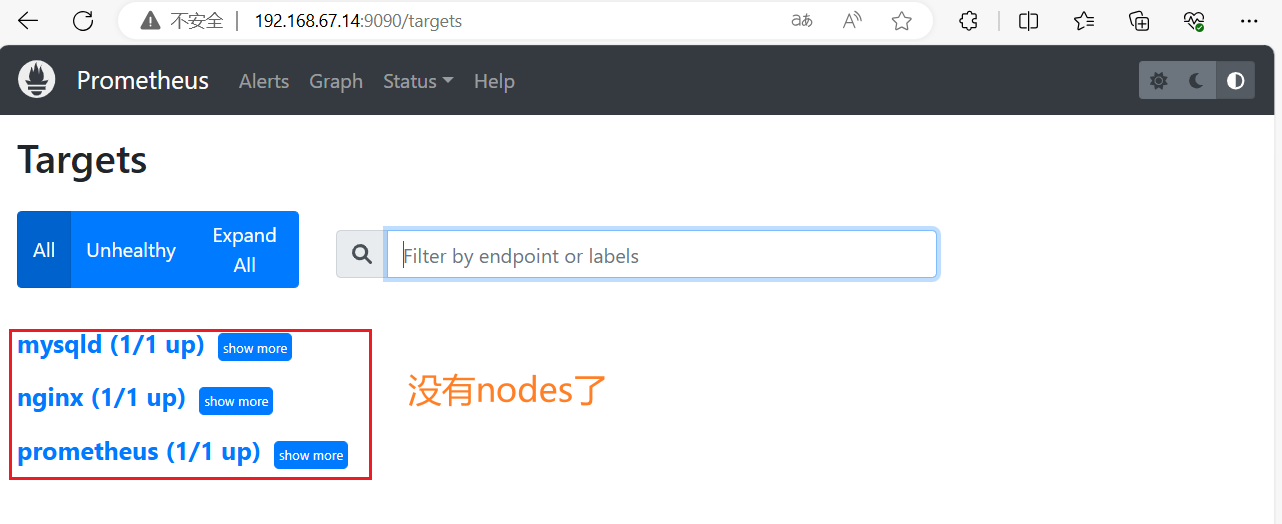
添加新的nodes指向
vim /usr/local/prometheus/prometheus.yml
......
- job_name: nodes
consul_sd_configs: #指定使用 consul 服务发现
- server: 192.168.67.14:8500 #指定 consul 服务的端点列表
tags: #指定 consul 服务发现的 services 中哪些 service 能够加入到 prometheus 监控的标签
- nodes
refresh_interval: 2m
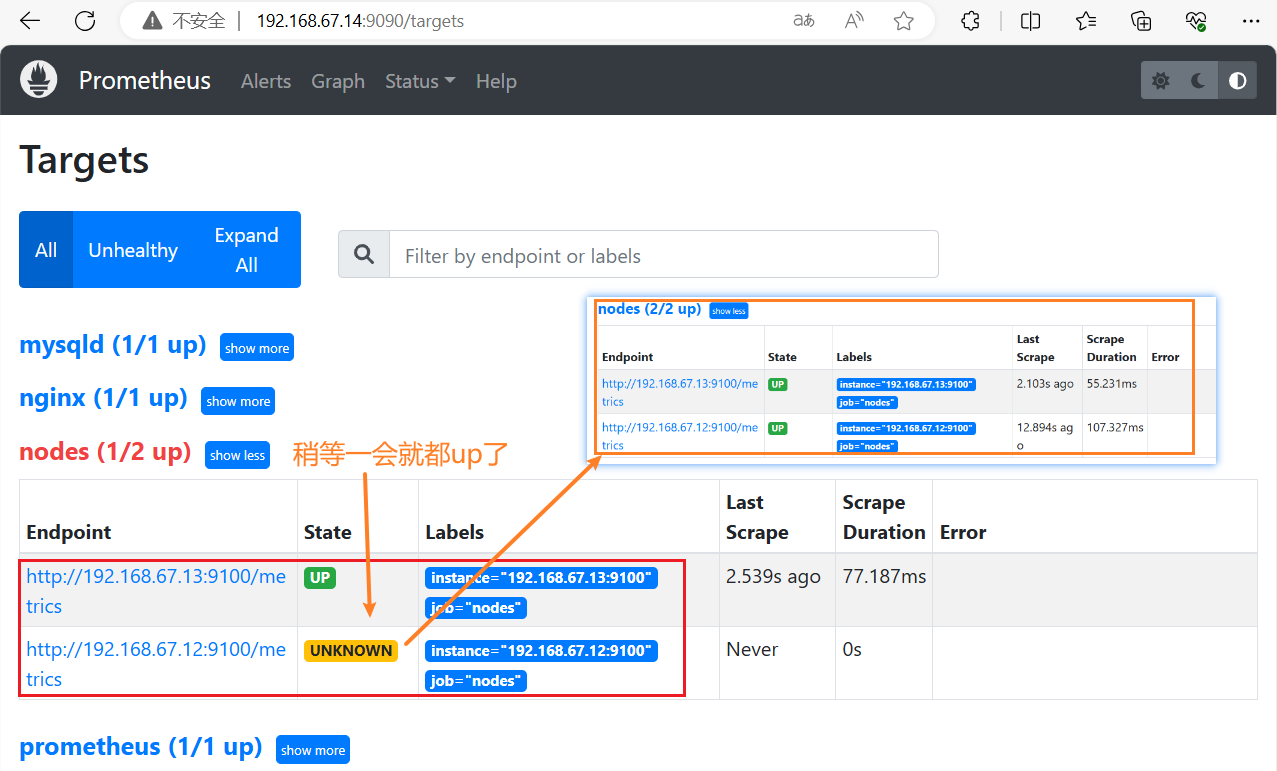
浏览器访问
#重新加载配置
systemctl reload prometheus浏览器查看 Prometheus 页面的 【Status】 ——> 【Targets】

#让 consul 注销 Service
#注销node02
consul services deregister -id="node_exporter-node02"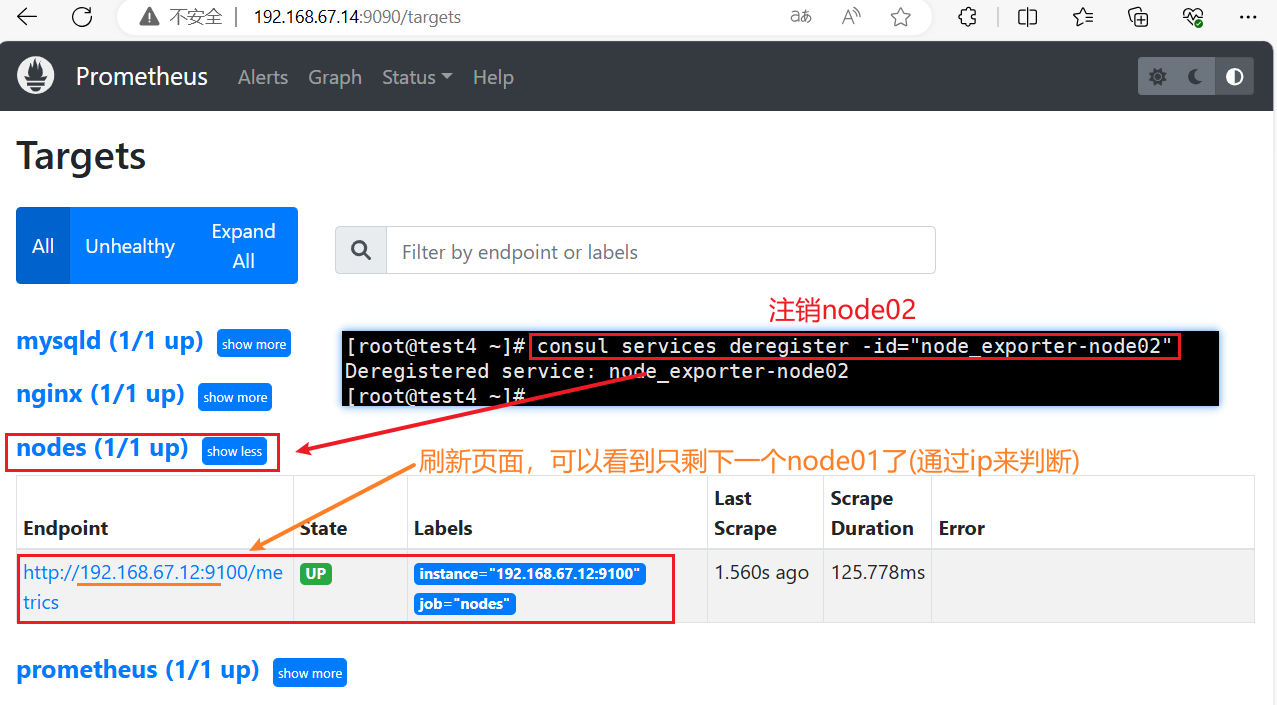
#重新注册
consul services register /etc/consul/nodes.json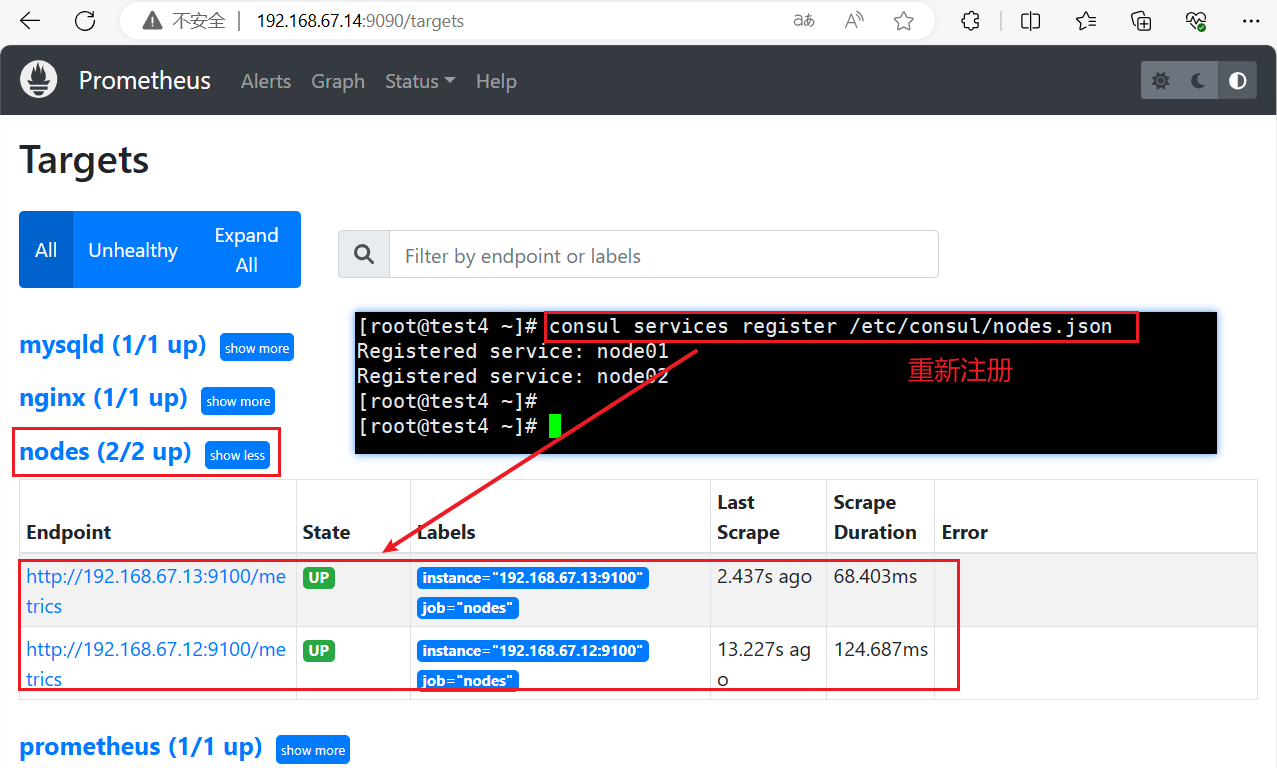
十、基于 Kubernetes API 的服务发现
官网:https://prometheus.io/docs/prometheus/2.42/configuration/configuration/
基于 Kubernetes API 的服务发现机制,支持将API Server 中 Node、Service、Endpoint、Pod 和 Ingress 等资源类型下相应的各资源对象视作 target, 并持续监视相关资源的变动
●Node、Service、Endpoint、Pod 和 Ingress 资源分别由各自的发现机制进行定义
●负责发现每种类型资源对象的组件,在 Prometheus 中称为一个 role
●支持在集群上基于 DaemonSet 控制器部署 node-exporter 后发现各 Node 节点,也可以通过 kubelet 来作为 Prometheus 发现各 Node 节点的入口
#基于 Kubernetes 发现机制的部分配置参数
# The API server addresses. If left empty, Prometheus is assumed to run inside
# of the cluster and will discover API servers automatically
and use the pod's
# CA certificate and bearer token file at /var/run/secrets/kubernetes.io/serviceaccount/.
[ api_server: <host> ]
# The Kubernetes role of entities that should be discovered. One of endpoints, service, pod, node, or ingress.
role: <string>
# Optional authentication information used to authenticate to the API server.
# Note that 'basic_auth', 'bearer_token'和'bearer_token_file' 等认证方式互斥;
[ bearer_token: <secret> ]
[ bearer_token_file: <filename> ]
# TLS configuration.
tls_config:
# CA certificate to validate API server certificate with.
[ ca_file: <filename> ]
# Certificate and key files for client cert authentication to the server.
[ cert_file: <filename> ]
[ key_file: <filename> ]
# ServerName extension to indicate the name of the server.
[ server_name: <string> ]
# Optional namespace discovery. If omitted, all namespaces are used.
namespaces:
names:
[ - <string> ]总结——Prometheus
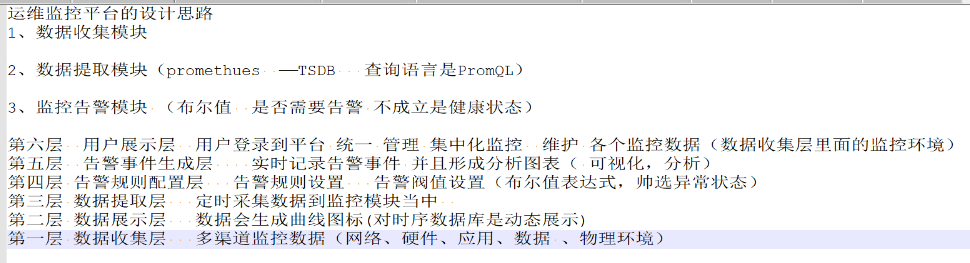
运维监控平台的设计思路:
1.数据收集模块:容器,网络,应用等的数据
2.数据提取模块:定时采集数据库;prometheus使用TSDB 数据库,使用PromQL语言
3.监控告警模块:(布尔值,是否需要告警,true则报警,不成立则为健康状态)
第一层:数据收集层;从多方面(多渠道)来监控数据(网路、硬件、应用、数据、物理环境等)
第二层:数据展示层;数据会生成曲线图标,时序数据库是动态展示
第三层:数据提取层;定时采集需要/相应的数据到监控模块中
第四层:告警规则配置层;设置告警规则和阈值(布尔值表达式,筛选异常状态并罗列)
第五层:告警事件生成层;实时记录告警事件,并形成分析图表(根据可视化进行告警分析)
第六层:用户展示层;用户登录到平台统一管理集中化监控,以及维护各个平台的监控数据(数据收集层里面的监控环境)
Prometheus 监控系统的时序数据库,
prometheus 生态组件
prometheus server 是核心,以http 通过pull 拉取方式进行数据采集,TSDB的数据存储,altermanager 告警生成
client-libray 客户端库,使用服务原生,支持 prometheus 监控的系统和应用的数据采集
expother 暴露器,对应指标,用于收集原生不支持Prometheus 监控系统和应用的数据暴露给 prometheus
altermanger 接受prometheus生成的告警信息,并转发给接收方
pushgetway 接收客户端push推送的短期任务,进行临时存储,再由prometheus server统一进行拉取
Grafana 外置的监控数据展示平台;使用promQL 查询prometheus 的数据源

Prometheus的工作流程
1)Server 为核心,负责收集和存储时间序列数据;通过pull 拉取指标数据,客户端push的数据也会先存储在pushgateway中,然后等待server通过pull拉取
2)server将采集到的监控指标数据,按时间序列,通过TSDB存储到本地的HDD/SDD中
3)server通过配置报警规则,把触发的告警通知,生成并传给Alertmanager,再通过Alertmanager 以各种形式发送给接收方
4)使用 PromQL 查询语言 可以在 Prometheus 的UI界面查询监控数据
5)通过Grafana 将监控数据图形化展示出来
prometheus 远程外置的存储;influxDB openTSDB
prometheus 高可用/联邦集群;thanos

pull 拉取/监控数据的端口
prometheus server 端口为9090
node exporter 端口为9100
#非原生服务是通过exporter暴露的端口,暴露后通过pull来拉取数据
mysqld 端口为9104
nginx-exporter 端口为9913
grafana 端口为3000
服务发现、基于文件、基于静态static
监控目标 target static
job_name 定义监控作业的名称
static_configs 定义静态配置的端点
- targets:
file consul、kubernetes_sd_config
- file:
-servers:
tags:
- role:

Prometheus 的数据采集配置(scrape_configs)
scrape_sonfig:
- job_name: #定义监控的服务的名称
metrics_path: #指定获取监控指标的数据的路径,通常是/metrics
static_path: #定义静态的监控配置
- targets:
- IP1:PORT
- IP2:PORT
file consul
- files:
- 文件路径
refresh_intercal: #指定服务发现刷新时间间隔
- server
tags: #指定加入Prometheus监控的服务标签
- xxx
refresh_interval
- role: #指定需要监控的 k8s 资源对象时间同步
#时间同步为北京时间
timedatectl set-timezone Asia/Shanghai
#安装同步插件
yum install ntpdate -y
ntpdate time.windows.com

















 5033
5033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









