



1. 什么是大模型
参数规模大达到数十亿甚至万亿量级、结构复杂的深度学习模型,它的参数规模可达千亿级别(例如GPT-3)这也决定了模型的表达能力和泛化能力,它的训练数据量依赖海量多模态数据。因此个人认为`大`是指参与训练的数据量大,参数规模大,训练数据类型多样。
大模型包括了专注于文本处理的大语言模型、专注于处理不同数据类型的多模态模型、专注于图像处理的视觉模型等。
2. 大模型的缺陷
1.偏见与深度理解不足
大模型依赖于大量数据进行训练但是这些数据具有偏向性,LLM在生成内容时可能会延续这些偏见,例如性别或种族刻板印象。此外,尽管模型能够生成流畅的文本,但它并不具备真正的深度理解能力,仅基于统计模式进行生成,缺乏逻辑推理和概念理解。
2. 特定领域知识的局限性
在医学、法律等专业领域,LLM的知识准确性有限,可能无法提供可靠的建议。此外,由于训练数据的时效性,模型对新知识或技术的掌握往往滞后,难以满足快速发展的领域需求。
3. 高资源需求与可解释性差
LLM的训练和推理需要大量的计算资源和存储空间,导致成本较高。同时,其内部机制复杂,难以解释生成结果的原因,这在某些需要透明性的场景中可能成为障碍。尽管存在这些缺点,LLM仍然是一个强大的工具,但在使用时需要结合人类的判断力和专业知识,以弥补其不足并最大化其优势。
4. LLM无法处理模糊和复杂的任务
LLM的强项在于它可以处理明确、结构化的问题,但当问题变得模糊或者涉及复杂的推理时,它的表现就会大打折扣。
5. 事实准确性与一致性问题
LLM容易生成与事实不符的信息,出现所谓的“幻觉问题”。在回答问题或生成内容时,可能会编造不存在的事件或数据。此外,在处理长文本或多轮对话时,模型难以保持上下文一致性,可能导致前后矛盾的回答。例如有时你给LLM一个看似简单的问题,它却能给出一个完全错误的答案。比如,你问它:“世界上最高的山是什么?”它可能会回答“马尔科姆山”,这个名字根本不存在,但由于模型根据某些错误的训练数据生成了这个答案。
6. 推理与规划能力不足
LLM在因果推理和多步规划方面表现较弱。它们难以理解事件之间的因果关系,例如无法准确推断“如果不下雨,地面就不会湿”。此外,在处理复杂任务时,模型难以合理分解步骤并进行有效排序,导致规划结果不够实用。
7. 数值处理与计算能力有限
由于LLM的token化方式,对数值的理解和计算容易出错。例如,在比较数字或执行算术运算时,可能会因错误的处理方式得出不准确的结果。此外,模型缺乏真正的数值概念,无法像人类一样分析数量或比例问题。
8. 无状态性
模型本身不记得之前的对话或交互。
总结:大模型的缺陷主要在于它训练时的数据与现在需要的数据不全、不实时的问题;大模型没有记忆以及大模型生成回答的不可解释性、复杂问题的理解能力不足和幻觉(大模型胡言乱语即生成问题与事实不符)的问题。
3. RAG
3.1 什么是RAG,它解决了什么问题
为了解决LLM缺陷中的幻觉问题、数据的实时性问题、特定领域知识的局限性、偏见问题,给大模型装载一个“外挂”知识库,只是库中存放的定制化的数据,当向大模型回答时会根据情况判断是否需要调用本地的知识,并把结果和问题进行处理后喂给大模型进行输出。这个过程就是rag的基本过程。
3.2 RAG的组件概况
文档解析器:对不同的文档进行解析并转为想要的格式。例如,把PDF格式的文档转为mardown格式便于后续进行拆分处理。现在市面上有很多开源文档解析器,例如:Miner U、Docling 、Marker等。
向量数据库:文档转为数据进行存储。与mysql等数据库类似都是用于存储数据的。
嵌入模型:文档转为数据(向量)时所采用的模型就是嵌入模型。转为向量的目的在于能够进行保留语义信息并能够通过余弦相似度进行计算查找比较匹配的内容。
重排模型:根据从向量数据库中检索到的数据进行基于问题和向量数据库的打分,最后输出根据相关度排序的序列。
LLM: 大模型,包括语言大模型、多模态大模型,负责基于上下文输出结果。
3.3 RAG的基本流程
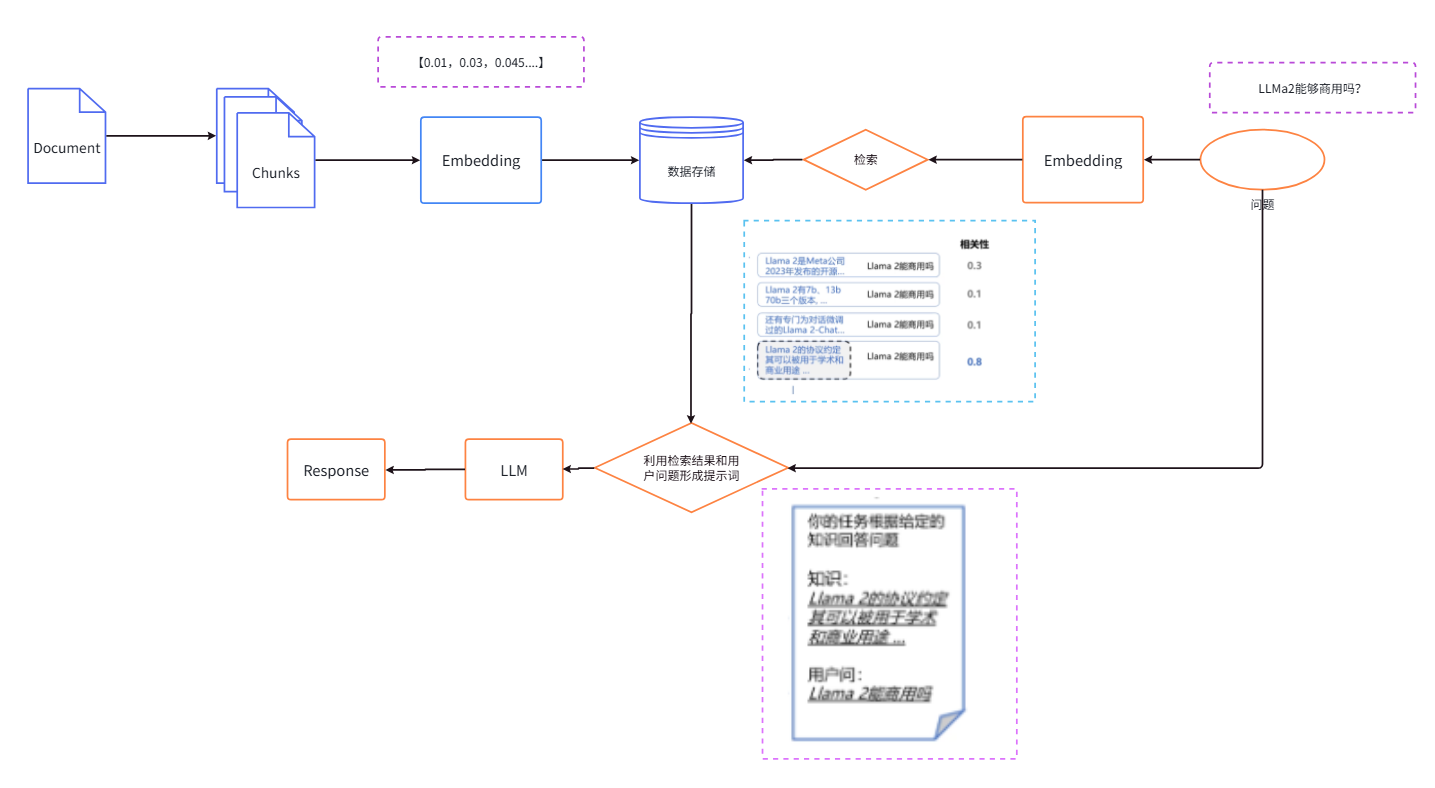
以上是最基本的RAG流程,其中 ![]() 表示该步骤的输出,蓝色部分表示建立索引的过程:文档解析——生成document——文档拆分(Chunks)——文档嵌入(Embedding)——存入数据库中;
表示该步骤的输出,蓝色部分表示建立索引的过程:文档解析——生成document——文档拆分(Chunks)——文档嵌入(Embedding)——存入数据库中;
黄色部分表示检索生成的过程:输入问题——问题嵌入(Emedding)——从向量数据库中搜索——合并检索结果和问题——调用大模型——生成回答。
3.3.1 文档的解析
3.3.1 文档的解析的定义及原因
文档解析是利用计算机算法和人工智能技术,对文档中的文字、图像、表格等内容进行自动识别、提取、理解和结构化的过程。文档解析是为了解析文档的布局、内容、上下文关系,将非结构化数据或这半结构化的数据转为结构化的、计算机可以处理的消息格式,如XML、JSON、Markdown等。
内容包括:文字段落、表格、公式、标题层级、手写字符、图片分类、页眉页脚。
在这一步骤的输入和输出为:
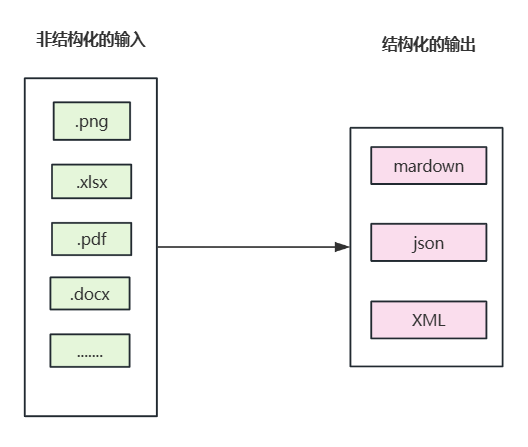
3.3.2 文档解析的痛点
主要是版式识别、表格识别与解析、公式识别与解析、阅读顺序恢复。
1. 版式识别:复杂的版式(跨页表格、混合图文)的识别;页脚、脚注的定位易出错。
2. 表格识别与解析:表格的形式多样,比如有线框的、没线框、少线框的这就导致单元格之间的边界模糊,不易准确检测与合并;对于跨行、跨列、跨页的单元格识别后恢复到原来格式逻辑复杂;为识别输出格式如MarkDown、CSV等,容易导致数据信息与样式的丢失,导致在最后输出引用时格式变化重点与含义变化。
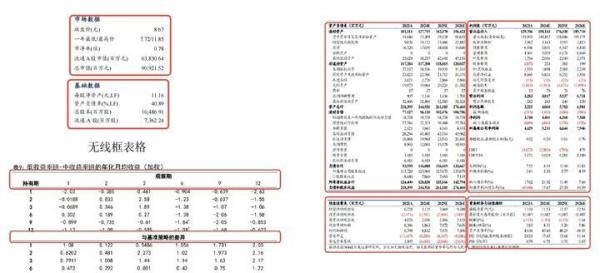
3.公式识别与解析:数学公式结构复杂、字符形近、特殊字符多因此公式还原的结构、字符容易出错。

4.阅读顺序的恢复:对于多栏、嵌套表格、或其他‘花式’布局还原困难。

5. 另外还有手写体的识别、多层级还原、非正文元素的检测与去除。
3.3.3 文档解析的相关方法
根据阅读文献综述,目前流程的文档解析有两种办法:模块化pipeline以及基于大型视觉-语言模型的端到端处理方法。
模块化Pipeline大致为:layout模型识别图文表的位置——OCR分类处理(公式:先进行检测在进行识别,可以通过大模型输出为laTex格式;表格:单独识别;图表:先得到内容,再与对应的位置信息结合)——最后在语义、上下文关系不变的前提下合并在同一个文档中,可以是MarDown等格式。这个方式的主要难点在于,版面的还原。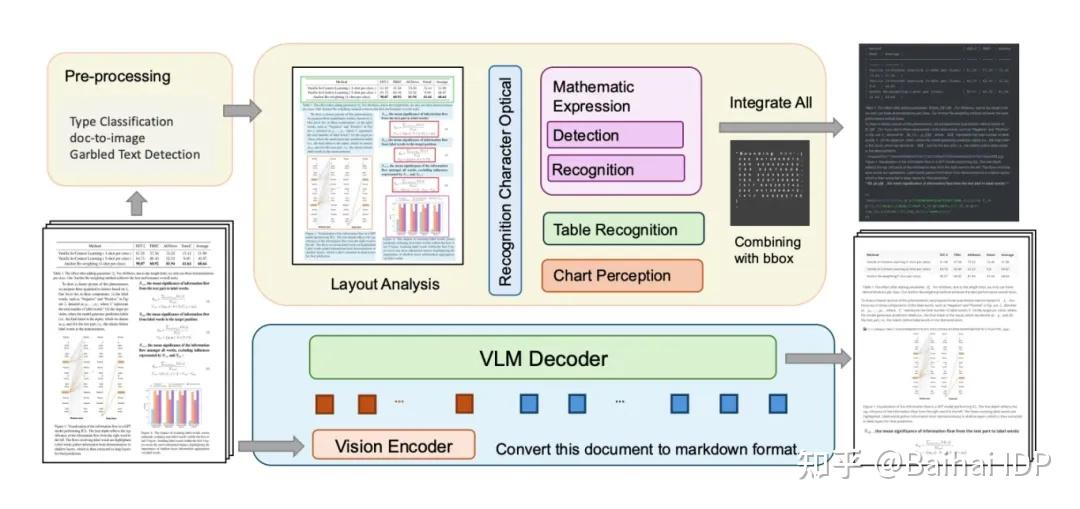
端到端的方法,就是使用大模型直接进行转换。
3.3.4 文档解析的开源工具有哪些以及优缺点
| 维度 | MinerU | Marker | docling | Unstructured |
|---|---|---|---|---|
| 优势 | 复杂的中文版面 | 公式最友好,英文比MinerU友好 | 对表格的友好度超过MInerU | |
| 缺点 | 环境复杂,显存占用大,如果不用GPU速度较慢 | 表结构经常出错 | 他的OCR对中文支持不够 | 精度上限低,需要更换底层模型 |
| OCR技术 | PaddleOCR (魔改版) | Surya (自研) 专门针对多语言优化的 OCR 和版面模型。 | EasyOCR / Tesseract (可配置) 但核心强项在于结构理解而非字形识别 | Tesseract / Paddle / unstructured-inference (取决于配置) |
| 公式技术 |
UniMERNet / P2T | Texify / Nougat 变种 | 基础支持 | 弱,通常作为普通文本处理 |
| 表格技术 | SLANet / LORE 变种 采用视觉分割表格结构,准确率高。 | 通过大模型理解表格,复杂表格容易“幻觉”或错位。 | IBM 专有的表格结构大模型,表格还原能力 SOTA 级别。 | 依赖外部工具,通常较弱。 |
| 支持的输出格式 | Markdown, JSON | Markdown | Markdown,HTML 和无损 JSON | Markdown, JSON, XML, HTML |
| 原理 | pipeline:layout-切片-ocr-规则拼接 | DOM:视作序列预测任务,类似 GPT,输入图片,直接预测 Markdown 文本流 | 端到端:基于 GLM/Layout 模型将文档解析为层级树状结构,再导出 | 策略路由模式,底层调用 Tesseract, Paddle, YOLOX 等外部工具。 |
注意:我曾使用过MinerU进行解析他在表格处理部分确实有不足的地方,特别是在表格跨行合并时,因为MarkDown没有页码,因此我使用的时JSON格式输出,他的图片和图注也有问题。因此我认为需要先知道他的更具体的逻辑在进行一个复用或调整。在表格部分看能不能使用docling的。
3.3.5 最简单的pipeline
3.3.6 miner u调用
我是直接调用miner u上的demo.py代码,修改其中的配置进行修改,详见代码 3.语义搜索中miner u demo.py以及药品知识库中.py部分配置信息如下:
def do_parse(
output_dir, # Output directory for storing parsing results
pdf_file_names: list[str], # List of PDF file names to be parsed
pdf_bytes_list: list[bytes], # List of PDF bytes to be parsed
p_lang_list: list[str], # List of languages for each PDF, default is 'ch' (Chinese)
backend="pipeline", # The backend for parsing PDF, default is 'pipeline'
parse_method="auto", # The method for parsing PDF, default is 'auto'
formula_enable=True, # Enable formula parsing
table_enable=True, # Enable table parsing
server_url=None, # Server URL for vlm-sglang-client backend
f_draw_layout_bbox=True, # Whether to draw layout bounding boxes
f_draw_span_bbox=True, # Whether to draw span bounding boxes
f_dump_md=True, # Whether to dump markdown files
f_dump_middle_json=True, # Whether to dump middle JSON files
f_dump_model_output=True, # Whether to dump model output files
f_dump_orig_pdf=False, # Whether to dump original PDF files
f_dump_content_list=True, # Whether to dump content list files
f_make_md_mode=MakeMode.MM_MD, # The mode for making markdown content, default is MM_MD
start_page_id=0, # Start page ID for parsing, default is 0
end_page_id=None, # End page ID for parsing, default is None (parse all pages until the end of the document)
):
3.4 文档的切片
3.4.1 文档切片的原因
如果不进行切片,当一个文档很大时,如果直接传给模型,存在的问题如下
- 首先就是在嵌入时,一个向量不能表示所有的语义;
- 相似度被稀释了,检索不准;
- 会检索出大量无关的信息影响回答质量;
- 算力成本增加了,因为内容很多,那么就需要大向量,因此计算缓慢,成本大;
- 如果检索结果不进行处理,可能会超出模型上下文。
例如一本《西游记》,直接一本给嵌入后存入向量库,你的问题是”三打白骨精的地点在哪里?“他会把整个西游记进行输出,最后结果就是,超出模型上下文,模型理解缓慢,回答不正确。
因此切片的目的在于克服窗口的限制、减少成本、提高回答的质量、提高检索的精度。
请注意:过细的拆分会导致上下文确实,例如原句为:”患者近 3 天持续发热,伴有咳嗽、乏力,考虑上呼吸道感染。“ 拆分结果为”患者近 3 天持续发热,伴有咳嗽“,”乏力,考虑上呼吸道感染。“ ,会导致实际上是患者的综合情况,但是只能检索出其中一个,而医生的诊断依赖全貌,因此不符合需求。
3.4.2 文档切片的方法和优缺点
1. 固定块
定义:按照固定的大小chunk_size,并设置一个重叠的大小chunk_overlap,从文本开头的取chunk_size个大小的字符,第二个chunk从第一个chunk的最后减去chunk_overlap开始取chunk_size,依次类推。计算方式以种是token一种是字符。
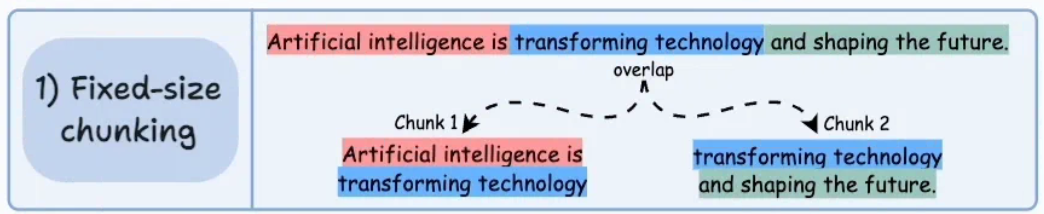
优点:实现简单,计算开销小,处理快。
缺点:很容易破环语义完整性,语义从中间断开。第二个就是忽略了文本结构。
适用:适用于文本结构简单;需要快速切分;一般作为复杂策略的最后手段;对上下文要求不高的检索任务中。
案例:
def fixed_size_chunking(text, chunk_size, chunk_overlap):
chunks = []
start_index = 0
while start_index < len(text):
end_index = start_index + chunk_size
chunks.append(text[start_index:end_index])
start_index += chunk_size - chunk_overlap
if start_index >= len(text): # 避免因 overlap 超出
break
return chunks
text = ''
with open(file_path,'r',encoding='utf-8') as f:
for line in f:
if line != '\n':
text += line
# 假设 text 是你的长文本
chunks = fixed_size_chunking(text, 50, 10)
pprint(chunks[0])#'【药品名称】\n通用名称:非奈利酮片商品名称:可申达(Kerendia)英文名称:Finerenone'
pprint(chunks[1])#'Finerenone Tablets汉语拼音:Feinailitong Pian\n【成份】\n主要成份'
2. 基于句子
定义:先根据语言规则(?。!)拆分成一句一句的话,按照设定的大小,进行句子的合并直到满足大小设定
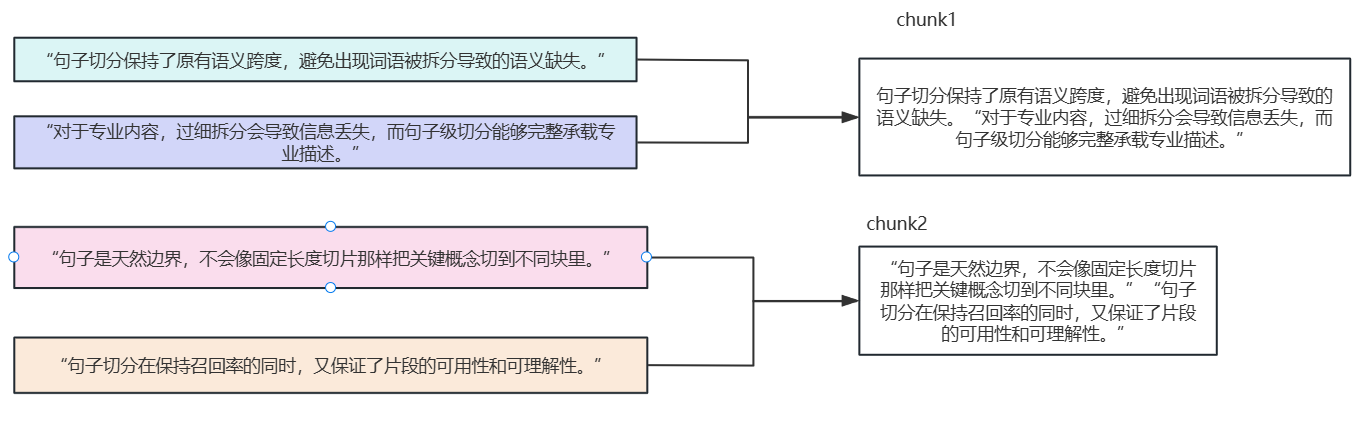
优点:因为是按照句子进行合并的能够较好的保留语义完整性
缺点:由于句子长度差异大,导致chunk的大小不均匀,可能会影响检索的稳定性,跨句子的复杂语义也有可能会被切断,造成回答不准确。
适用场景:结构良好,以完整句子为主的文本,或者说句子层面语义保留良好的,比如新闻文章,以及句子层面的语义完整比较重要的。
3. 递归字符
4. 文档结构
5. 混合分块
6. 语义分块
7. 分层分块
8. small to big
9. 命题分块
3.4.3 最优chunk
分块的核心挑战在于检索的精度和上下文完整性之间的权衡
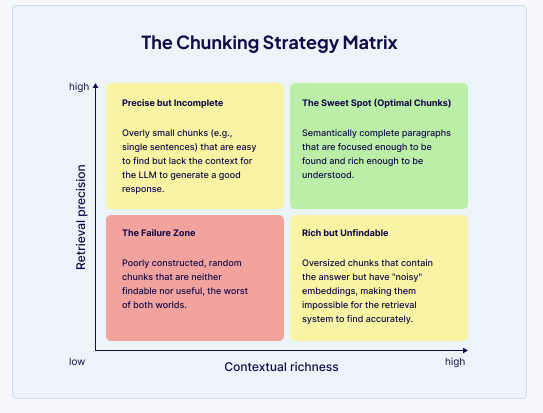
3.4.4 切片方法的抉择
3.5 文档的嵌入
3.5.1 进行文档嵌入的原因
3.5.2 文档嵌入的方法
3.5.3 常用模型对比
3.5.4 调用方法对比
3.6 向量数据库
什么是向量数据库以及向量数据库的作用
数据库的对比指标
流行的向量数据库以及对比
Milvus
milvus介绍
milvus简单调用
milvus索引
milvus性能
milvus完整案例
3.7 大模型调用知识库进行回答
3.8 RAG应用的评估
评估的指标
评估的框架
框架的原理
3.9 RAG应用的重难点以及应对策略
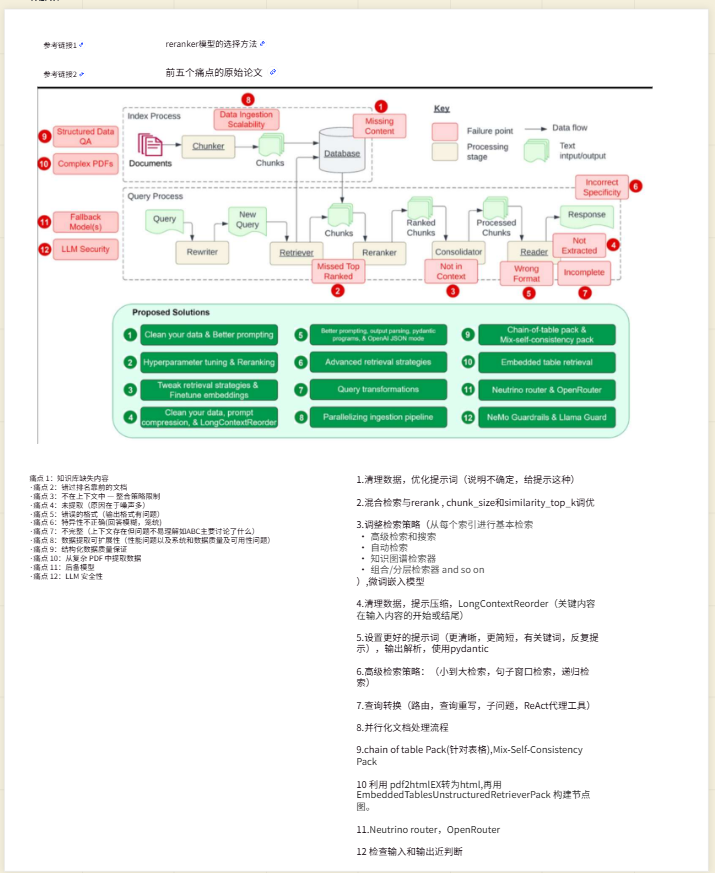
3.10 RAG发展历程
naive rag
advanced rag
module rag
graph rag
agentic rag
3. 11 优化策略总结

















 666
666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









