



近期内容总结
3.16 动量法
- 动量法的简单例子:通过结合前一步的更新方向和当前梯度的方向来更新参数,有助于克服局部最小值或鞍点,使模型能够继续优化。
- 图示:红色表示负梯度方向,蓝色虚线表示前一步的方向,蓝色实线表示真实的移动量。动量法通过结合两者,即使梯度方向改变,仍可能继续向正确方向移动。
3.3 自适应学习率
- 临界点问题:训练过程中,虽然梯度很小,但损失可能不再下降,不一定是卡在局部最小值或鞍点,而是梯度在山谷两侧来回震荡。
- 图示:
- 图3.18:训练网络时损失变化,显示损失最终停止下降。
- 图3.19:训练网络时梯度范数变化,即使损失不再下降,梯度范数仍然很大。
- 图3.20:梯度在山谷两侧来回震荡的误差表面。
- 分析:指出一般梯度下降难以直接走到临界点,多数情况在损失不再明显下降时停止训练。
3.6.3 分类损失
- softmax函数:用于多分类问题,将输出转换为概率分布,并放大类别间的差异。
- 损失函数:
- 均方误差:计算预测值与真实值之间的平方差和。
- 交叉熵:更常用于分类问题,因为它在损失大时梯度也较大,有助于优化过程。
- 图示:
- 图3.33:softmax示例,显示三个类别的概率分布。
- 图3.34:分类损失计算示意图。
- 图3.35:softmax在分类中的好处。
- 图3.36:均方误差与交叉熵在优化过程中的对比,显示交叉熵在损失大时梯度更大,优化更容易。
3.7 批量归一化(Batch Normalization, BN)
- 目的:改善误差表面的地貌,使其更平滑,易于训练。
- 方法:在训练过程中,对每个小批量数据进行归一化处理,使得数据的均值接近0,方差接近1。
- 效果:有助于加速训练过程,提高模型性能,并减少对初始化参数的敏感度。
通过动量法、自适应学习率、合适的损失函数(如交叉熵)以及批量归一化等技术,可以更有效地训练神经网络,提高模型的性能和稳定性。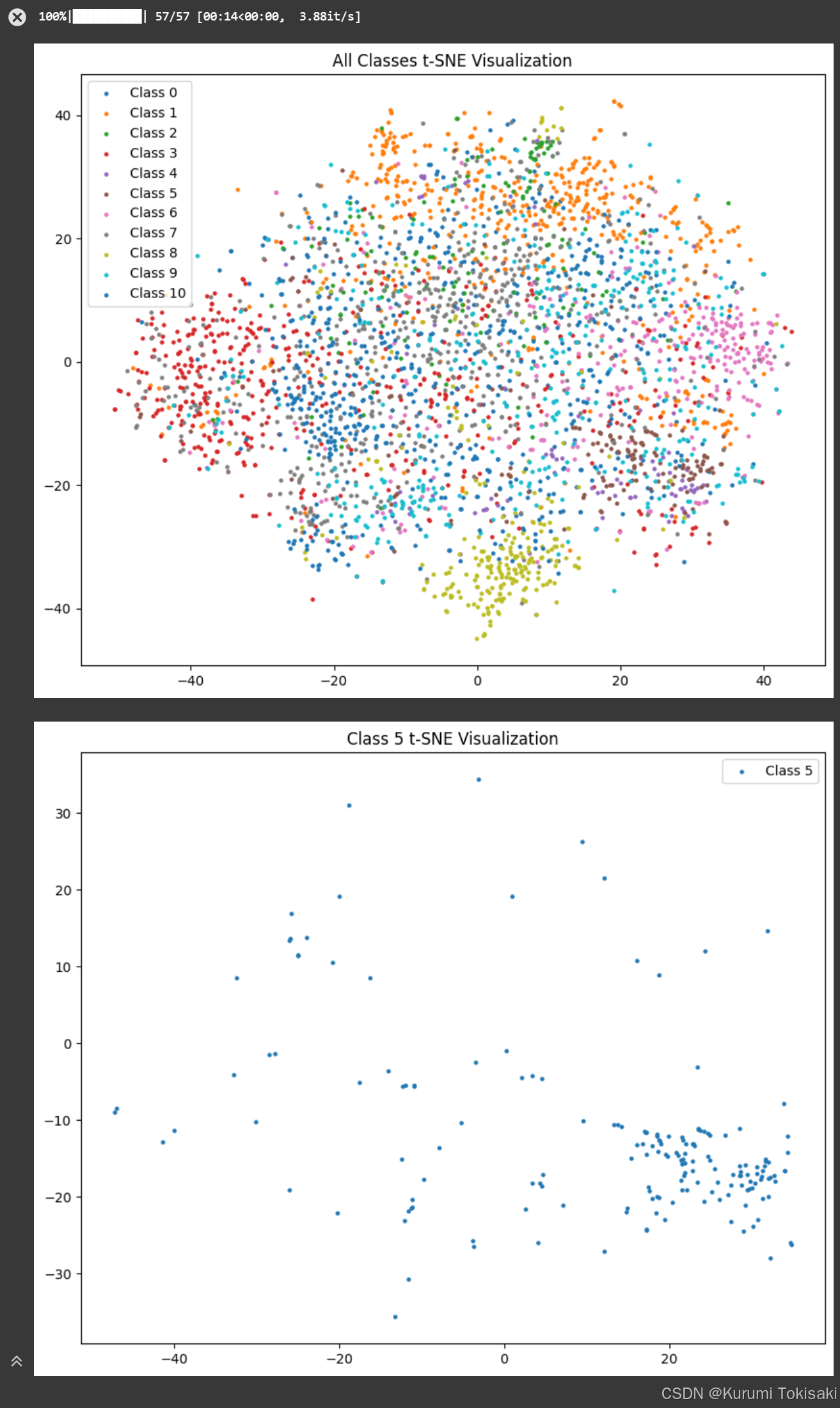
要完成一个深度神经网络训练模型的代码,通常遵循一个标准的流程,这个流程不仅适用于图像分类任务,也广泛适用于各种深度学习任务,如自然语言处理、语音识别等。以下是该流程的大致概述:
1. 导入所需要的库/工具包
首先,你需要导入完成深度学习任务所必需的库和工具包。这些通常包括用于构建和训练模型的深度学习框架(如TensorFlow、PyTorch等),以及用于数据处理和可视化的库(如NumPy、Pandas、Matplotlib等)。
python复制代码
import numpy as np | |
import pandas as pd | |
import torch | |
import torch.nn as nn | |
import torch.optim as optim | |
from torchvision import datasets, transforms | |
from torch.utils.data import DataLoader | |
import matplotlib.pyplot as plt |
2. 数据准备与预处理
接下来,你需要准备并预处理你的数据。这通常包括加载数据、划分训练集和测试集(或验证集)、数据标准化/归一化、以及可能的增强(如图像旋转、裁剪等)以改善模型的泛化能力。
python复制代码
# 假设使用PyTorch的torchvision来加载CIFAR-10数据集 | |
transform = transforms.Compose([ | |
transforms.ToTensor(), | |
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) | |
]) | |
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) | |
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) | |
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) | |
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False) |
3. 定义模型
然后,你需要定义一个模型。这通常涉及到选择或设计网络架构,如卷积神经网络(CNN)对于图像任务,或循环神经网络(RNN)及其变体对于序列任务。
python复制代码
class SimpleCNN(nn.Module): | |
def __init__(self): | |
super(SimpleCNN, self).__init__() | |
self.conv1 = nn.Conv2d(3, 16, 5) | |
self.pool = nn.MaxPool2d(2, 2) | |
self.conv2 = nn.Conv2d(16, 32, 5) | |
self.fc1 = nn.Linear(32 * 5 * 5, 120) | |
self.fc2 = nn.Linear(120, 84) | |
self.fc3 = nn.Linear(84, 10) | |
def forward(self, x): | |
x = self.pool(torch.relu(self.conv1(x))) | |
x = self.pool(torch.relu(self.conv2(x))) | |
x = torch.flatten(x, 1) # flatten all dimensions except batch | |
x = torch.relu(self.fc1(x)) | |
x = torch.relu(self.fc2(x)) | |
x = self.fc3(x) | |
return x | |
model = SimpleCNN() |
4. 定义损失函数和优化器等其他配置
你需要选择一个适合你的任务的损失函数(如交叉熵损失对于分类任务),并选择一个优化器(如SGD、Adam等)来更新模型的权重。
python复制代码
criterion = nn.CrossEntropyLoss() | |
optimizer = optim.Adam(model.parameters(), lr=0.001) |
5. 训练模型
在训练过程中,你需要迭代地通过训练数据,使用优化器来更新模型的权重,以最小化损失函数。
python复制代码
for epoch in range(num_epochs): | |
for inputs, labels in train_loader: | |
optimizer.zero_grad() | |
outputs = model(inputs) | |
loss = criterion(outputs, labels) | |
loss.backward() | |
optimizer.step() |
6. 评估模型
在训练完成后,使用测试集(或验证集)来评估模型的性能。
python复制代码
correct = 0 | |
total = 0 | |
with torch.no_grad(): | |
for data in test_loader: | |
images, labels = data | |
outputs = model(images) | |
_, predicted = torch.max(outputs.data, 1) | |
total += labels.size(0) | |
correct += (predicted == labels).sum().item() | |
print(f'Accuracy of the network on the 10000 test images: {100 * correct / total} %') |
7. 进行预测
最后,你可以使用训练好的模型来进行预测。
python复制代码
# 假设有一些新的图像数据 | |
new_images = ... # 加载或生成新图像数据 | |
with torch.no_grad(): | |
outputs = model(new_images) | |
_, predicted = torch.max(outputs, 1) | |
# 使用predicted进行后续处理或展示 |
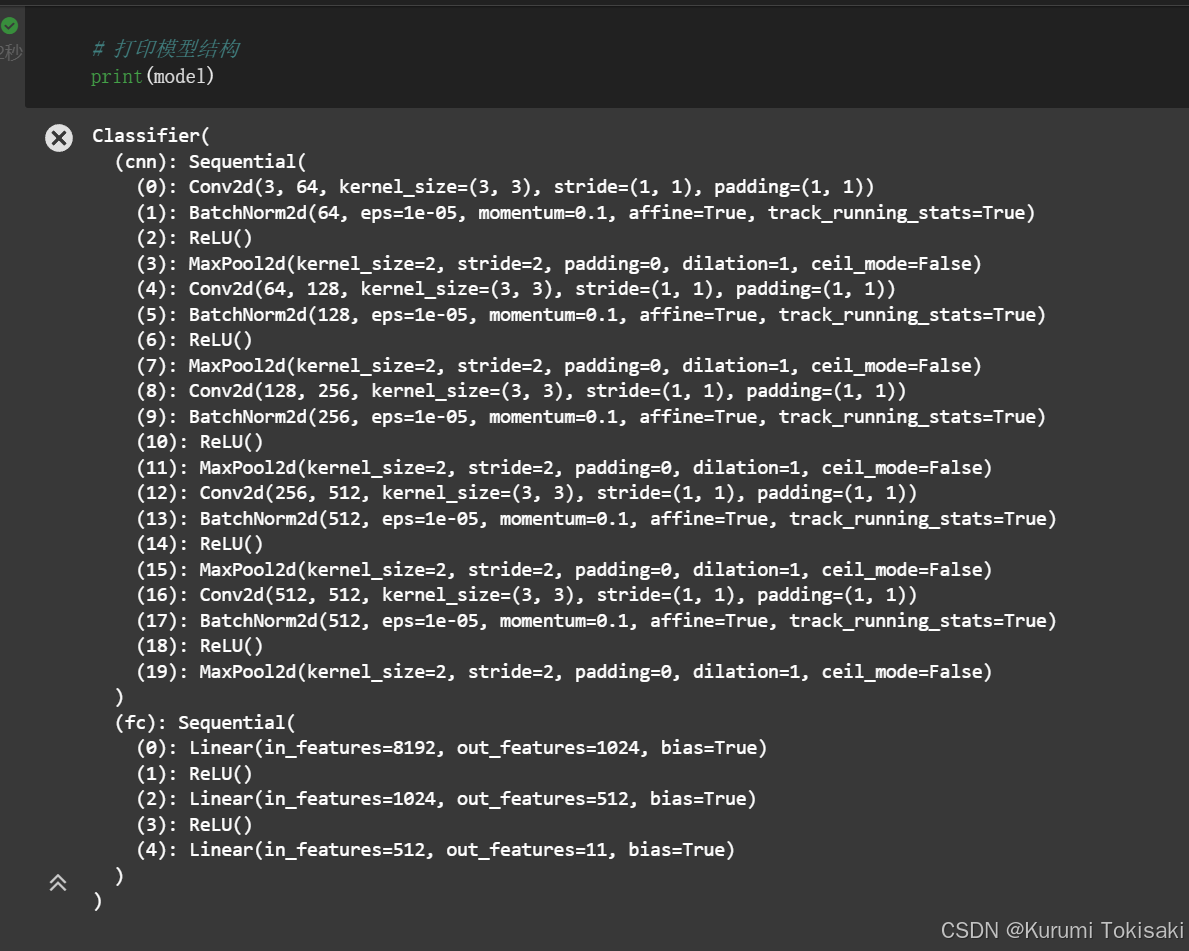
这个流程是深度学习任务中的一个典型范式,可以根据具体任务和数据集进行调整和优化,如上图所示。


















 2027
2027



 到【灌水乐园】发言
到【灌水乐园】发言








