






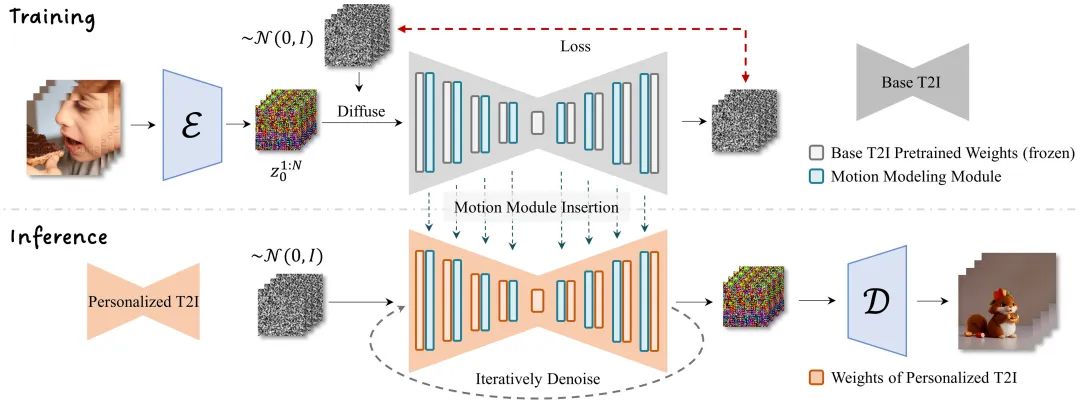
AnimateDiff采用控制模块来影响StableDiffusion模型,通过大量短[视频剪辑]的训练,使其能够调整图像生成过程,生成一系列与训练视频剪辑相似的图像。与传统的SD模型训练方式不同,AnimateDiff通过大量短视频的训练来提高图像之间的连续性,使得生成的每一张图像都能经过AnimateDiff微调,最终拼接成高质量短视频。
可以使用colab体验(https://colab.research.google.com/github/camenduru/AnimateDiff-
colab/blob/main/AnimateDiff_colab.ipynb )。也可以本地sd-webui安装使用。下面介绍sd-
webui安装方式。
AnimateDiff插件是一个可以让你在WebUI上方便地生成动画GIF的扩展,它支持多种运动模块(Motion
Module,MM),包括官方的v2版本,以及LoRA和ControlNet等创新的技术。AnimateDiff插件的主要功能和使用方法:
-
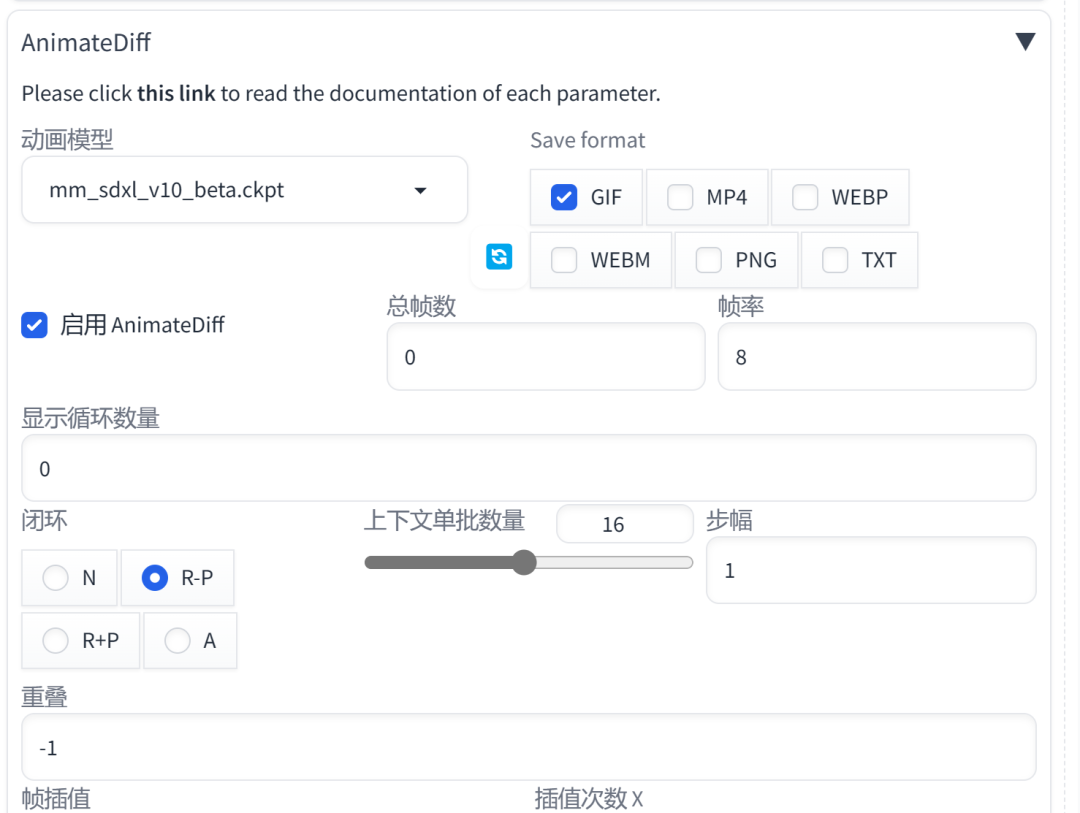
安装和准备 :要使用AnimateDiff插件,需要先更新WebUI到v1.6.0 ,然后通过链接安装sd-webui-animatediff(https://github.com/continue-revolution/sd-webui-animatediff)这个插件扩展。同时还需要下载模型的ckpt文件,并放在stable-diffusion-webui/extensions/sd-webui-animatediff/model/目录下。可以在huggingface代码库https://huggingface.co/guoyww/animatediff/tree/main中找到可用的ckpt模型和LoRA模块。注意:mm_sd_v15_v2.ckpt仅支持SD1.5模型,如果要使用SDXL需要下载mm_sdxl_v10_beta.ckpt模型。
-
生成动画GIF :在txt2img或img2img中使用AnimateDiff插件来生成动画GIF。选择一个SDM的检查点,写下绘图prompt,设置图片的宽度和高度等参数。如果想一次生成多个GIF,可以修改批次数量,而不是批次大小。然后需要启用AnimateDiff扩展,设置每个参数,然后点击Generate。就可以在输出画廊中看到输出的GIF了。也可以在stable-diffusion-webui/outputs/{txt2img或img2img}-images/AnimateDiff/{yy-mm-dd}中访问GIF输出。可以在stable-diffusion-webui/outputs/{txt2img或img2img}-images/{yy-mm-dd}中访问图片要在Settings/AnimateDiff中选择保存每次生成的帧到目录。相关web-ui参数设置:https://github.com/continue-revolution/sd-webui-animatediff?tab=readme-ov-file#webui-parameters
-
使用API :可以通过API来使用AnimateDiff插件。API会返回一个base64格式的视频。在format中,PNG表示只保存帧到本地文件系统,而不返回所有的帧。如果想让API返回所有的帧,请在format列表中添加Frame。关于API最新的参数:https://github.com/continue-revolution/sd-webui-animatediff?tab=readme-ov-file#api。
-
使用LoRA和ControlNet :AnimateDiff插件支持LoRA和ControlNet这两种创新的技术。LoRA是一种基于局部重建的运动模块,它可以生成更清晰和更连贯的动画。ControlNet是一种基于控制点的运动模块,它可以通过拖动控制点来改变图片的形状和方向。下载LoRA文件放置
stable-diffusion-webui/models/Lora目录,并在prompt 增加<lora:v2_lora_PanDown:0.8>。
在SD-Web-UI扩展安装 :
https://github.com/continue-revolution/sd-webui-animatediff.git
* 1
下载模型:
https://huggingface.co/guoyww/animatediff
* 1
-
注意:模型放置目录:stable-diffusion-webui/extensions/sd-webui-animatediff/model/。mm_sd_v15_v2.ckpt仅支持SD1.5模型,如果要使用SDXL需要下载mm_sdxl_v10_beta.ckpt模型。
-
下载LoRA文件放置目录stable-diffusion-webui/models/Lora
安装重启webui:
效果体验






关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1872
1872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









