



 该论文提出了Self-Supervised MultiModal Versatile Networks,利用自我监督对比学习,从多模态数据(视觉、音频、文本)中学习通用表示。通过设计模态嵌入图,它在细粒度和粗粒度空间中比较不同模态,尤其适用于未标记视频。这种方法无需手动注释,且在多种下游任务中表现出色。
该论文提出了Self-Supervised MultiModal Versatile Networks,利用自我监督对比学习,从多模态数据(视觉、音频、文本)中学习通用表示。通过设计模态嵌入图,它在细粒度和粗粒度空间中比较不同模态,尤其适用于未标记视频。这种方法无需手动注释,且在多种下游任务中表现出色。
【论文笔记】Self-Supervised MultiModal Versatile Networks
论文详细信息
题目:Self-Supervised MultiModal Versatile Networks
作者:Jean-Baptiste Alayrac, Adrià Recasens, Rosalia Schneider, Relja Arandjelovic, Jason Ramapuram, Jeffrey De Fauw, Lucas Smaira, Sander Dieleman, & Andrew Zisserman.
期刊/会议:NIPS’20: Proceedings of the 34th International Conference on Neural Information Processing Systems
时间:2020
领域: Multimedia
关键词: Multimodal interaction
What?
切入点是什么?
我们对世界的体验是多模态的。早在婴儿床上,我们就通过多个感官系统进行感知,例如,我们观看火焰在火场上跳舞,我们听到木头劈啪作响的声音,以及感觉热量的释放。通过这种多模态同步感知,我们学会了在模态之间建立有用的联系,从而使我们能够形成对世界的良好表征。后来,出现了一种语言,允许我们使用更高层次的抽象概念来交流这种细粒度的多模态体验。我们的目标是以自我监督的方式从这种多模态体验中学习表征,而无需诉诸任何特定的手动注释。
思路是什么?
作者选择了一种将每个模态嵌入向量空间的设计,这样模态之间的相似性通过简单的点积获得。每个模态都由一个适合信号性质的主干网络进行处理,并构造模态嵌入图,使得视觉和音频嵌入是细粒度的,而文本嵌入是语义粗粒度的。这种策略是基于这样一种观察:视觉和音频空间是细粒度的(有许多视觉或吉他声音可能彼此确实不同),而文本域则更粗糙,因为它的目标是抽象掉细节(例如,一个“吉他”单词)。然后,通过对大量未标记视频的自我监督对比学习,从零开始训练网络。
解决方案的关键是什么?
学习了两个嵌入空间,在细粒度空间中比较视觉和音频,而在低维粗粒度空间中比较文本、音频和视觉。关键的是Sva中的向量可以通过简单的从细到粗的投影Gva嵌入到Svat
How?
论文的具体贡献
(a)研究了MMV的不同模态嵌入图,并提出了一种简单而有效的音频、视频和语言流多模态表示的自监督训练策略;
(b)引入了一种压缩方法,使得MMV视频网络能够有效地接收静态图像;
(c)展示了学习到的表征在多个图像、视频、音频和视频文本下游任务中的优越性。
具体模型和算法
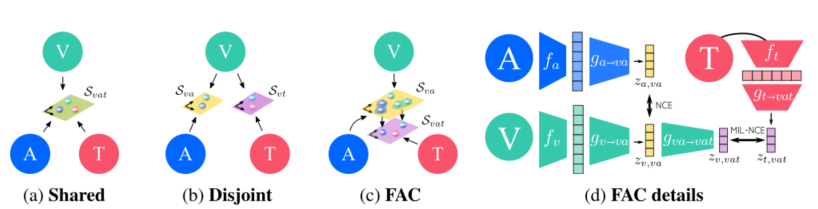
图中©为作者提出的符合四条原则的嵌入方式
(i) it should be able to take as input any of the three modalities;
(ii) it should respect the specificity of modalities, in particular the fact that the audio and visual modalities are much more fine-grained than language;
(iii) it should enable the different modalities to be easily compared even when they are never seen together during training;
(iv) it should be efficiently applicable to visual data coming in the form of dynamic videos or static images.
实验结果
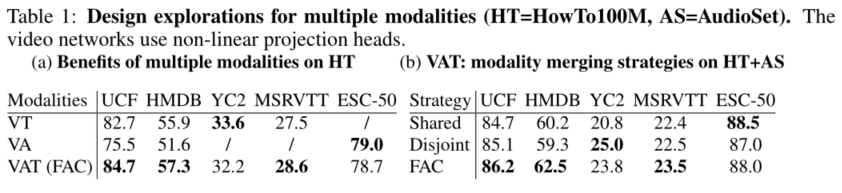
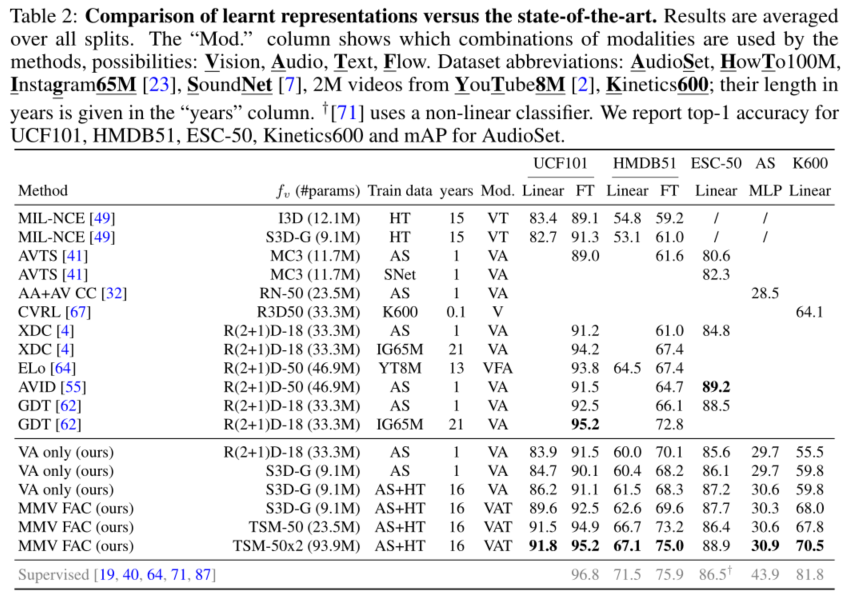
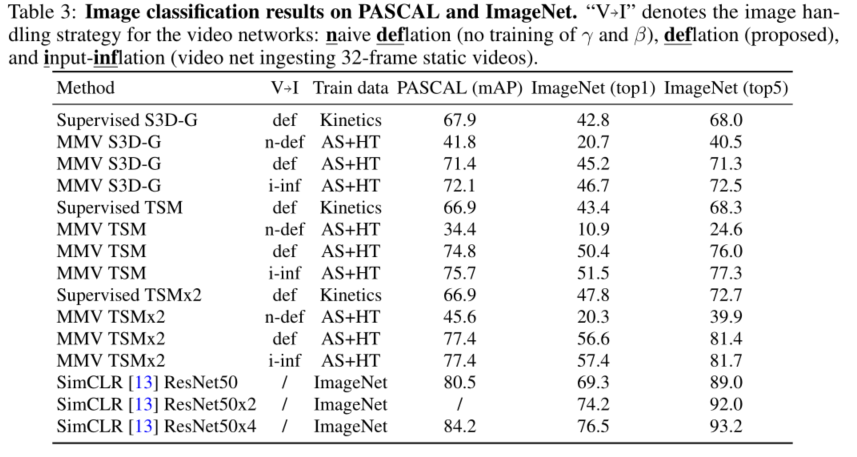
提供了哪些思路?
为多模态的嵌入网络提供了一种思路和遵循的原则

















 1219
1219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









