




Google的MapReduce,展示了一个简单通用和自动容错的批处理计算模型。但是对于其他类型的计算,比如交互式计算和流式计算,他不适合。
统一大数据处理框架Spark,提出了RDD概念(一种新的抽象的弹性数据集),某种程度是MapReduce的一种拓展。
MapReduce缺乏一种特性:即在并行计算的各个阶段进行有效的数据共享,这就是RDD的本质。
容错方式:
MapReduce是将计算构建成为一个有向无环图的任务集。这只能允许他们有效的重新计算部分DAG。在单独计算之间(比如迭代),除了复制文件,这些模型没有提供其他的存储抽象,这就显著的增加了在网络之间复制文件的代价。
而RDD能够适应当前大部分的数据并行计算和编程模型。
大数据处理分为三种:复杂的批量数据处理、基于历史数据的交互式查询、基于实时数据流的数据处理
Spark生态:
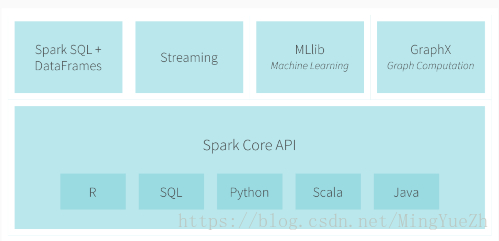
Spark Core:基于RDD提供了丰富的操作接口,利用DAG进行统一的任务规划,更加灵活的处理类似MapReduce的批处理作业。
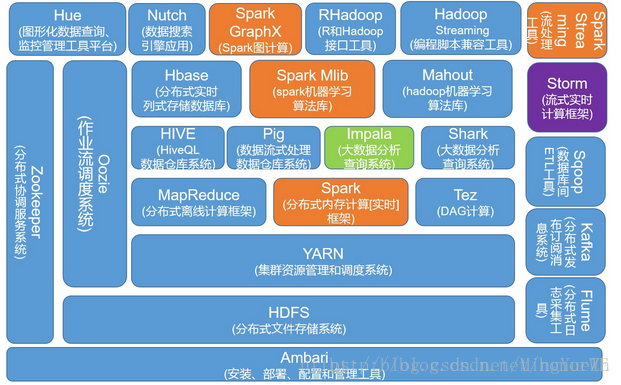
Spark生态系统兼容了Hadoop生态系统。完美兼容了HDFS和YARN等其他组件

















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









