




http://zookeeper.apache.org/
常见名词
数据模型
zookeeper 的视图结构和标准的文件系统非常类似,每一个节点称之为 ZNode,是 zookeeper 的最小单元。每个 znode 上都可以保存数据以及挂载子节点。构成一个层次化的树形结构
- 持久节点(PERSISTENT) 创建后会一直存在 zookeeper 服务器上,直到主动删除
- 持久有序节点(PERSISTENT_SEQUENTIAL) 每个节点都会为它的一级子节点维护一个顺序
- 临时节点(EPHEMERAL) 临时节点的生命周期和客户端的会话绑定在一起,当客户端会话 失效该节点自动清理
- 临时有序节点(EPHEMERAL) 在临时节点的基础上多了一个顺序性
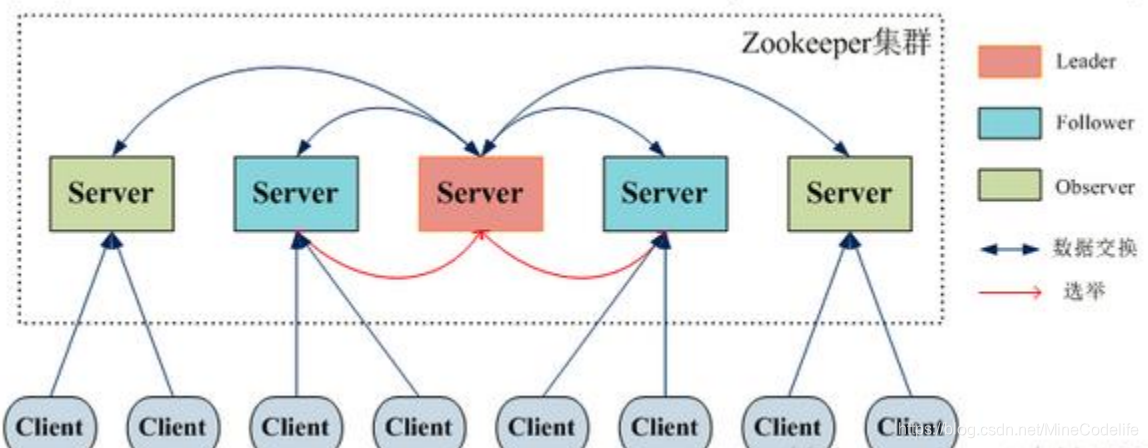
集群角色
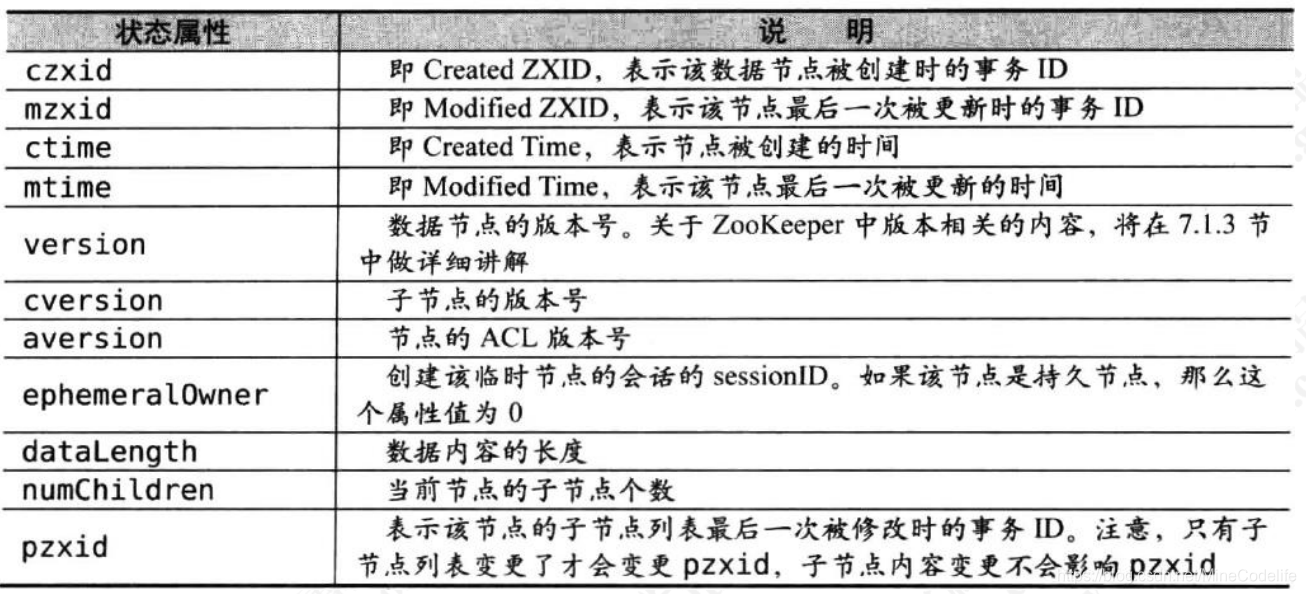
Stat 状态信息
版本-保证分布式数据原子性

Watcher
zookeeper 提供了分布式数据的发布/订阅功能,zookeeper 允许客户端向服务端注册一个 watcher 监听,当服务端的一 些指定事件触发了 watcher,那么服务端就会向客户端发送 一个事件通知。 值得注意的是,Watcher 通知是一次性的,即一旦触发一次 通知后,该 Watcher 就失效了,因此客户端需要反复注册 Watcher
分布式锁
利用有序节点来实现分布式锁
每个客户端都往 指定的节点下注册一个临时有序节点,越早创建的节点, 节点的顺序编号就越小,那么我们可以判断子节点中最小 的节点设置为获得锁。如果自己的节点不是所有子节点中 最小的,意味着还没有获得锁。这个的实现和前面单节点 实现的差异性在于,每个节点只需要监听比自己小的节点, 当比自己小的节点删除以后,客户端会收到 watcher 事件, 此时再次判断自己的节点是不是所有子节点中最小的,如 果是则获得锁,否则就不断重复这个过程,这样就不会导 致羊群效应,因为每个客户端只需要监控一个节点
curator 分布式锁的基本使用
Zookeeper 实现 leader 选举
zab 协议介绍
(Zookeeper Atomic Broadcast) 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议
ZAB 协议包含两种基本模式,分别是 1. 崩溃恢复 2. 原子广播
消息广播模式
崩溃恢复
崩溃恢复状态下 zab 协议需要做两件事 1. 选举出新的 leader 2. 数据同步
leader 选举算法:能够确保已经被 leader 提交的事务 Proposal 能够提交、同时丢弃已经被跳过的事务 Proposal。
根据上述要求,新选举出来的leader不能包含未提交的proposal,即新选举的leader必须都是已经提交了的proposal的follower服务器节点。同时,新选举的leader节点中含有最高的ZXID。这样做的好处就是可以避免了leader服务器检查proposal的提交和丢弃工作
leader 选举的原理
- 服务器 ID(myid)
- zxid 事务 id
- 逻辑时钟(epoch – logicalclock)
- 选举状态
- LOOKING,竞选状态。
- FOLLOWING,随从状态,同步 leader 状态,参与投票。
- OBSERVING,观察状态,同步 leader 状态,不参与投票
- LEADING,领导者状态
服务器启动时的 leader 选举
每个节点启动的时候状态都是 LOOKING,处于观望状态,接下来就开始进行选主流程
(1) 每个 Server 发出一个投票。由于是初始情况,Server1 和 Server2 都 会将自己作为 Leader 服务器来进行投票,每次投票会包含所推举的 服务器的 myid 和 ZXID、epoch,
使用(myid, ZXID,epoch)来表示, 此时 Server1 的投票为(1, 0),Server2 的投票为(2, 0),然后各自将这 个投票发给集群中其他机器。
(2) 接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判 断该投票的有效性,如检查是否是本轮投票(epoch)、是否来自 LOOKING 状态的服务器。
(3) 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投 票进行 PK,PK 规则如下
i. 优先比较 epoch ii. 其次检查 ZXID。ZXID 比较大的服务器优先作为 Leader iii. 如果 ZXID 相同,那么就比较 myid。myid 较大的服务器作为 Leader 服务器
(4) 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有 过半机器接受到相同的投票信息,对于 Server1、Server2 而言,都 统计出集群中已经有两台机器接受了(2, 0)的投票 信息,此时便认为 已经选出了 Leader。
(5) 改变服务器状态。一旦确定了 Leader,每个服务器就会更新自己的 状态,如果是 Follower,那么就变更为 FOLLOWING,如果是 Leader, 就变更为 LEADING。
运行过程中的 leader 选举
(1) 变更状态。Leader 挂后,余下的非 Observer 服务器都会将自己的服 务器状态变更为 LOOKING,然后开始进入 Leader 选举过程。
(2) 每个 Server 会发出一个投票。在运行期间,每个服务器上的 ZXID 可 能不同,此时假定 Server1 的 ZXID 为 123,Server3 的 ZXID 为 122; 在第一轮投票中,Server1 和 Server3 都会 投自己,产生投票(1, 123), (3, 122),然后各自将投票发送给集群中所有机器。接收来自各个服 务器的投票。与启动时过程相同。
(3) 处理投票。与启动时过程相同,此时,Server1 将会成为 Leader。
(4) 统计投票。与启动时过程相同。
(5) 改变服务器的状态。与启动时过程相同
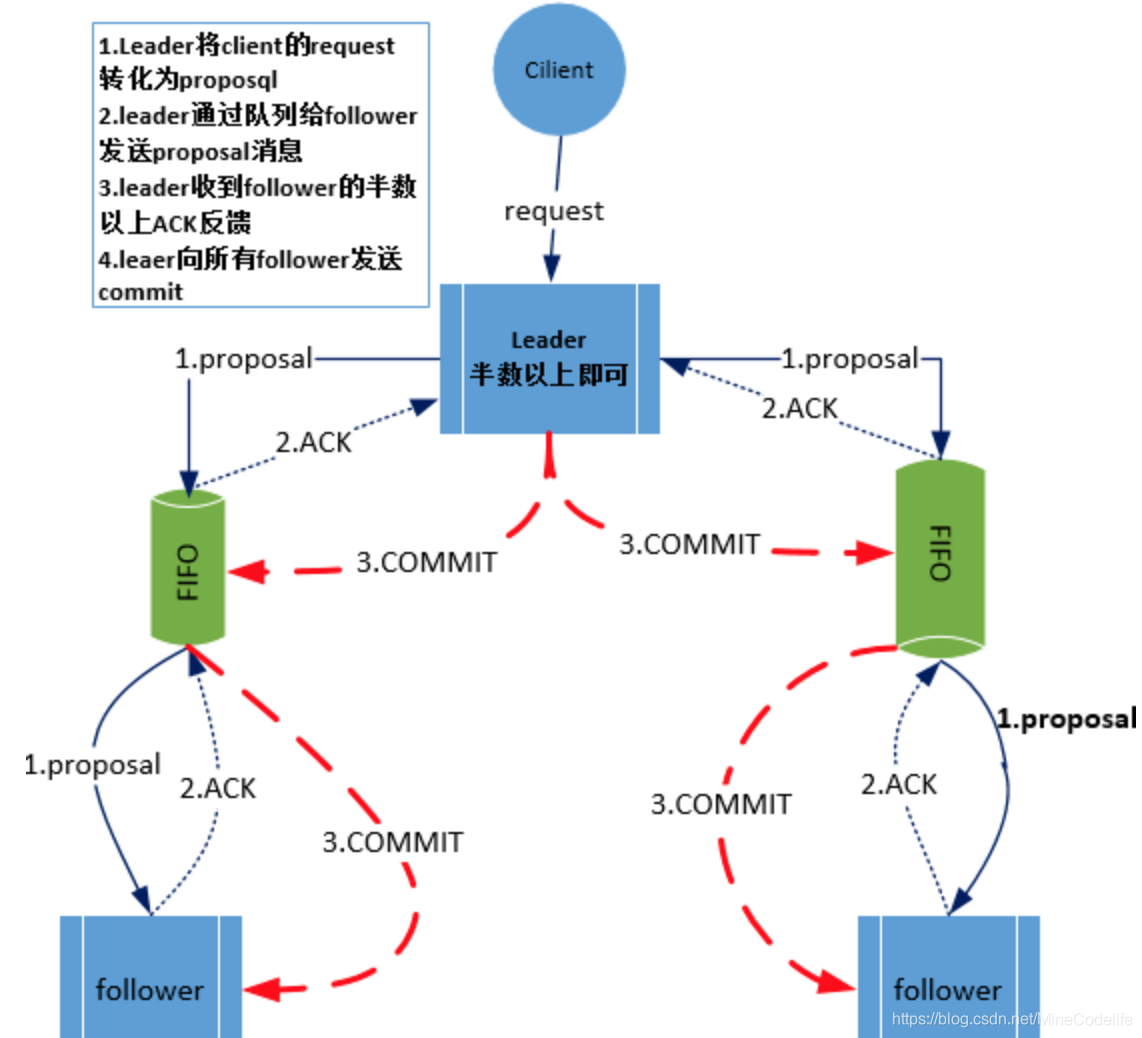
Zookeeper 的一致性
zab 协议的同步流程,在 zookeeper 集群内部的数据副本同步,是基于过半提交的策略,意味着它是最终一致性。并不满足强一致的要求
zookeeper 是一个顺序一致性模型 ( http://zookeeper.apache.org/doc/r3.5.5/zookeeperProgrammers.ht ml#ch_zkGuarantees )顺序一致性是针对单个操作,单个数据对象。属于 CAP 中 C 这个范畴。一个数据被更新后,能够立马被后续的读操作读到。
zookeeper 不保证在每个实例中,两个不同的客户端具有相同的 zookeeper 数据视图,由于网络延迟等因素,一个客户端可能会在另外一 个客户端收到更改通知之前执行更新
如果客户端 A 和 B 要读取必须要读取到 相同的值,那么 client B 在读取操作之前执行 sync 方法
除此之外,zookeeper 基于 zxid 以及阻塞队列的方式来实现请求的顺序一致性。如果一个 client 连接到一个最新的 follower 上,那么它 read 读取到了最新的数据。client 会记录自己已经读取到的最大的 zxid,如果 client 重连到 server 发 现 client 的 zxid 比自己大。连接会失败
源码入口
去看启动脚本 zkServer.sh 中的运行命令
ZOOMAIN 就是 QuorumPeerMain

ZooKeeper 的 Watcher 机制
客户端注册 watcher 有 3 种方式,getData、exists、getChildren

















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









