




菜品作为到店餐饮各相关业务的基石,提供了更细粒度的视角理解餐饮供给,为到餐精细化运营提供了抓手。美团到店研发平台/数据智能平台部与天津大学刘安安教授团队展开了“基于多模态信息抽取的菜品知识图谱构建”的科研合作,利用多模态检索实现图文食材的识别,扩展了多模态菜品食材识别的范围,提升了食材识别的准确性。
1. 背景
中国有句古话:“民以食为天”。对食物的分析和理解,特别是识别菜肴的食材,在健康管理、卡路里计算、烹饪艺术、食物搜索等领域具有重要意义。但是,算法技术尽管在目标检测[1]-[3]、通用场景理解[4][5]和跨模态检索[6]-[8]方面取得了很大进展,却没有在食物相关的场景中取得好的表现,尤其是对烹饪菜肴的相关场景。其核心原因是缺乏细粒度食材的基准,这已经成为该领域发展的瓶颈。
以往的研究主要集中在食物层面的表征学习,如Food2K上的食物识别[9]-[12],UNIMIB2016上的食物检测[13]-[15]。然而,这些方法忽视了菜肴中的食材组成,也不理解食材之间的上下文关系。相比之下,一系列的方法[16]-[18]运用Recipe1M的“食谱-图像”对,实现了跨模态的食谱检索[16]。
然而,由于缺乏食材边界框的标注,这种类型的研究只能通过三元组建模出整个食物图像和食谱文本之间的关联[16],[19],[20]。这种限制导致图像区域与食物的一系列食材之间存在模糊的匹配关系,产生虚假相关性[21]。综上,目前迫切需要一个细粒度的食材级基准,促进复杂的食品场景理解算法的发展,并支持细粒度的任务,如食材检测和跨模态食材检索。
在本研究中提出对于中餐进行理解这一新任务,旨在捕捉中餐图像中食材之间的语义关系,并建立了有关中国菜品理解的新基准。我们大致设定了中餐理解的两个任务:食材检测和食材检索。对于食材检测,目标是确定图像中特定食材的存在并提供精确的定位。对于食材检索,目标是探索不同食材组合与食品图像之间的细粒度对应关系。对中餐的理解扩展了食品相关任务的范围,在食品领域开辟了更广泛的应用。同时,食材的多样外观和它们错综复杂的语境关系,对中餐的理解提出了一个更大的难题。
为了进行中餐理解这一新任务,我们需要构建一个包含食材粒度标注的数据集。然而,由于中餐种类繁多、风格独特,因此在食材标注上面临着巨大的挑战。构建含中餐食材的细粒度跨模态数据集主要有三个难点。
- 首先,相同的食材有不同的名称。图1.1(a)说明了这种情况:“圣女果”和“小番茄”都是广泛使用的食材名称,它们是同一食材的不同名称,这样的情况使得我们需要花费更多的精力来清除数据集中的模糊标签以及其他噪声。
- 其次,同一植物类食材之间的图像存在细微差异,如“青菜”和“油菜”,“香菇”和“冬菇”,如图1.1(b)所示。这些情况对标注人员来说是相当具有挑战性的,他们需要从文本部分获得一些提示。此外,对于下游任务来说,基于视觉特征来区分它们也是相当具有挑战性的。
- 第三,由于烹饪方法的原因,中国菜肴的食材通常分散在图像中。如图1.1©所示,碎片化食材通常缺乏清晰的轮廓边界。此外,从图1.1(d)中可以看出,食品图像中的主要食材往往占据显著区域,这不可避免地削弱了辅助食材的语义信息。这使得在提取食材特征的同时,对辅助食材之间的上下文关系进行建模成为一个关键问题。
为了应对上述挑战并促进对中餐理解的研究,我们开发了一个名为CMIngre (Cross-Modal Ingredient-level Dataset) 的跨模态食材级数据集。该数据集旨在通过提供对食材及其关系的有价值的见解来增强对中国烹饪的理解。该数据集由来自三个不同来源的8,001张图像组成,即菜肴,食谱和用户生成内容(UGC)。该数据集包含429种不同的中国食材和95,290种食材边界框。
为了对广泛的食材进行全面的语义分类,我们根据中华人民共和国健康行业标准对食品食材数据表达的规定[23],将其划分为更高级的层次。这些层次关系也可以作为先验信息,以促进在后续研究中探索不同食材之间的上下文关系。此外,我们评估了传统的基于CNN的检测算法和基于Transformer的预训练模型在CMIngre上食材检测任务的性能。我们还提出了食材检索任务的基线方法,该方法捕获单个食材的语义信息以及各种食材组合之间的关系,并进一步采用pooling策略来研究跨模态图像-食材之间的匹配关系。在CMIngre数据集上进行的深入实验评估证实了我们提出的方法在提高食材检测和检索性能方面的有效性。
本文的贡献可以概括为以下几点:
- 本文提出了一种新的基于“图像-文本”对的中餐理解任务,该任务扩展了细粒度对象检测和检索的范围,对中餐烹饪领域的理解提供进一步的帮助。
- 为了支持对中餐理解的研究,我们建立了一个名为CMIngre的跨模态食材级别的数据集,该数据集由来自三个不同来源的8,001组图像食材组成,涵盖了429种不同的中国食材和95,290个边界框。
- 我们评估了不同的目标检测算法在CMIngre数据集上的性能,并提出了跨模态食材检索任务的基线方法。
- 我们在CMIngre上对两个食材级的食品理解任务进行了广泛的实验,以评估我们提出的方法的有效性。

2. 数据集
在本节中,我们将讨论如何构造CMIngre数据集。我们将在第一部分中介绍我们如何收集和标注数据。在第二部分中,我们对数据进行了后处理,提升原始数据的质量。在第三部分中进行了CMIngre数据集的统计和分析。
2.1 数据收集和标注
数据收集:为了收集全面的食物图像,我们探索了三种类型的图像-文本对:
- 菜肴图片:如图2.1第二行所示,这一类别包括与其名称配对的菜肴图像。与其他类型相比,这种类型的文本提供了最简洁的描述。
- 菜谱图片:如图2.1第三行所示,这些数据由菜谱图像和详细的食谱文本组成。这些图像的质量更高,并且比其他两个类别的图像描述的信息更丰富。
- 用户UGC图片:如图2.1的最后一行所示,这种类型数据主要包含用户拍摄的图像及其附带的评论。由于用户生成的内容缺乏约束限制,图像和文本描述经常包含与食物无关的元素,例如餐厅氛围或餐具。为了将该数据集细化为专注于食物,我们使用菜肴名称识别算法[45]来识别带有菜肴名称的文本。具体来说,我们会选择评论中包含三个以上菜名的照片,减少与食物无关的内容。
这三种类型的数据在线上平台很流行,并且提供了食品相关数据的多样化表示。我们总共收集了11,300个图像-文本对用于标注。

数据标注:这里将详细介绍收集到的“图像-文本”对的标注过程。我们首先雇佣了8名母语为中文的工作人员,分别对文字描述和图片进行标注。然后,使用另外两名工作人员进行双重检查过程。
- 文字描述标注:标注人员的任务是识别文本描述中提到的所有食材。该标注的结果如图2.1第三列所示。
- 图片标注:如图2.1最后一列所示,图像标注遵循两个关键原则:1)要求标注人员标注文本中提到的和图像中可见的食材。2)文本中没有提及但在图像中可以识别的食材也需要标注。在这个过程中,标注人员遇到了几个挑战:1)一个图像包含相同食材的多个实例。在这种情况下,标注人员需要用多个边界框标注所有实例。但是,如果同一食材的多个实例紧密聚集在一起,则可以将它们分组在一个边界框中。2)多种食材被其他食材覆盖。在这种情况下,标注人员需要标注出所有可识别的部分。本质上,食材中任何可以被辨别和识别的部分都应该被标注。
经过标注过程后,最终的数据集包含11,300个图像-文本对,用4,492个不同的食材标签和199,853个边界框进行了标注。
2.2 标注数据后处理
由于缺乏对标注人员关于每个图像的边界框的大小和数量的限制,最终的标注结果中存在边界框大小的显著变化和相当多的冗余边界框。为了解决这个问题,我们分别对图像和文本进行了进一步的后处理。
- 图像标注清洗:为了提高数据集中边界框的质量,我们基于两个关键策略实现了清理过程:1)边界框融合:我们通过将相同标签(重叠,相互包含或临近)合并到单个边界框中来解决冗余边界框的问题。具体来说,融合是基于边界框的面积,计算每个边界框内的像素数。如果融合前后的面积比大于一个特定的阈值,我们将这些边界框整合成一个新的边界框。这个阈值的设置是一个关键问题。我们注意到,过高的阈值将使融合策略无效,而过低的阈值将导致可能包含多种食材的过大的边界框。因此,我们根据经验将其设置为0.6作为平衡。2)较小边界框移除:我们通过两个过程来移除数据集中的小边界框。首先,为了去除只有小框的图像,我们去除所有框的总面积小于整个图像面积3%的图像-文本对。其次,如果图像中有超过三个相同类别的边界框,我们只保留面积至少为该类别中最大边界框面积0.8倍的边界框。在这些清理步骤之后,我们的精细化数据集包含8,001个图像-文本对,共有95,290个边界框。
- 文本标注清洗:为了改进数据集中的食材标注,我们实现了两个步骤:1)为了保留足够的数据用于训练和测试,我们删除出现在少于五张图像中的食材。由于原始数据集中存在显著的长尾问题,这一步使得食材标签总数减少到510。2)在这510种食材中,我们发现了不同名称指代同一种食材的情况,例如“松花蛋-皮蛋”。为了解决这个问题,我们利用中华人民共和国健康行业标准[23]中的食物成分数据表达规范,对目前510种食材进行比较和组合。具体而言,两个标注人员最初将510个食材中的每一个分类到分层本体的适当叶节点中。随后,另一个标注人员在同一父节点下审查并合并具有相同语义的食材。合并操作进一步将食材标签减少到429个。
综上所述,清理后的数据集包括8,001张图像,95,290个边界框和429个食材标签。
2.3 数据统计和分析
在CMIngre中,有1,719对来自菜肴的图像-文本,2,330对来自食谱,3,952对来自UGC。如2.1所述,UGC的图像质量比菜肴和食谱的图像质量差,这给我们在接下来的食物理解任务中处理低质量数据带来了更多的工作量,因为UGC覆盖了近一半的数据集。
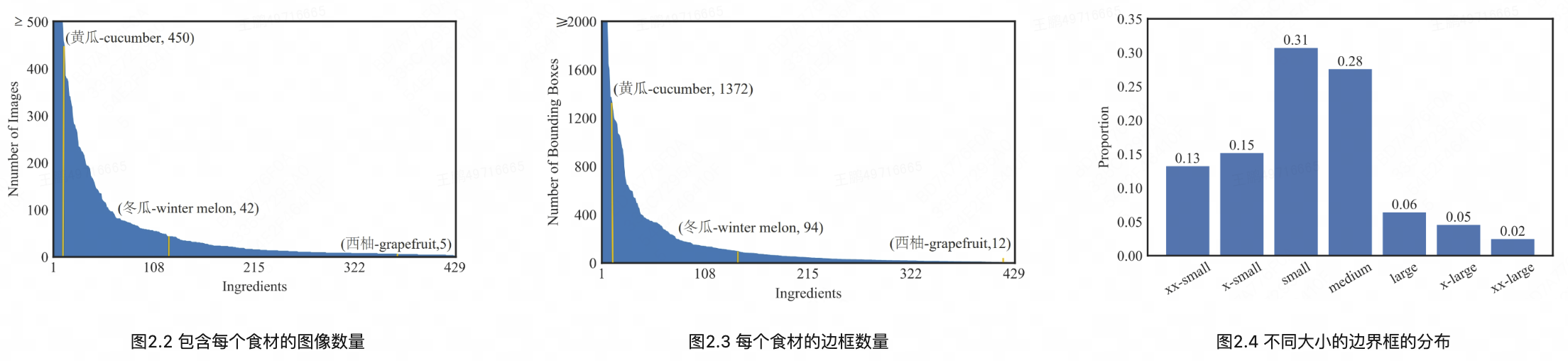
数据集中每个食材上的图像数量如图2.2所示,少量食材在我们的数据集中出现了很多次。例如,“葱–scallion”在1,961张图片中出现次数最多,约占图片总数的24.51%。此外,有138种食材出现在不到10张图片中。例如,只有5张图片包含“西柚–grapefruit”,8张图片包含“桃–Peach”。图2.3显示了我们数据集中每个食材的边界框数量。如图2.3所示,每种食材对应的边界框数量分布与图2.2中包含该食材的图像数量分布大致相似,均为长尾。为了说明边界框尺寸的差异,图2.4给出了不同尺寸边界框的比例。我们观察到小尺寸的边界框(面积比在0.0025 ~ 0.01之间)的比例最大。同时,有超过50%的边界框的面积比小于0.01,说明数据集中有很多小物体。
表2.1显示了与食品相关数据集的统计比较。我们可以看到,现有的食品相关数据集主要集中在食品识别任务上,其目的是识别图像内的食品类别。很少有数据集为食物边界框提供标注,这是由于它们的目标是定位整个菜肴,而不是各种类型的食材。相比之下,Recipe 1M为每个食物图像提供食材标注。然而,由于缺乏对这些细粒度食材的位置标注,它们只能隐式地建模整个食物图像与相应食材之间的关联,从而限制了模型的性能。因此,我们引入了CMIngre,旨在通过食材检测和检索任务增强对中餐的理解。

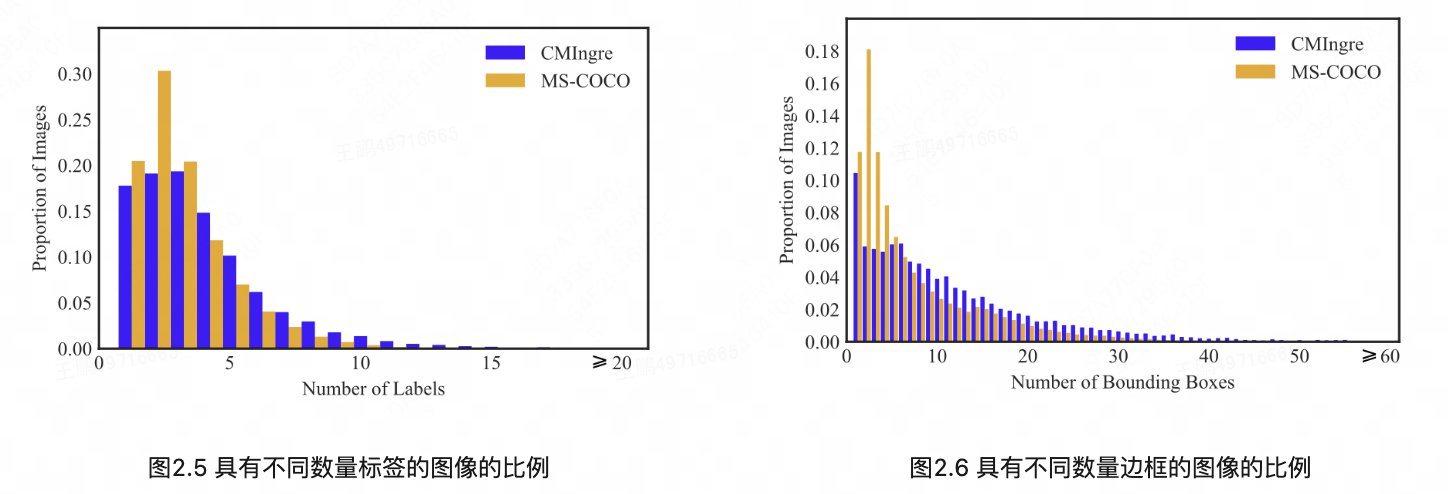
最后,我们将CMIngre数据集与广泛使用的目标检测数据集COCO进行了比较分析。在图2.5中,横轴表示每张图像中标签种类的数量(在CMIngre中标签为食材,在COCO中标签为物体)纵轴表示每种图像的比例。很明显,CMIngre图像通常包含更多的对象(在我们的例子中是食材)。具体来说,CMIngre中包含三个以上标签的图像的占比高于MS COCO数据集。这一趋势在边界框的数量上也很明显。如图2.6所示,与MS COCO相比,我们的数据集中超过5个边界框的图像比例更大。综上所述,CMIngre中的图像比其他现有数据集具有更丰富的语义和更密集的边界框,这对图像理解提出了更艰巨的挑战。
3. 方法
在本研究中,我们引入了两项从食材层面理解中国菜食材的任务,即食材检测(任务1)和跨模态食材检索(任务2)。任务1的重点是识别食材并在图像中标注准确的位置信息,任务2旨在研究图像与食材组成之间的复杂关系。对于任务1,我们使用现有目标检测模型在CMIngre数据集上进行微调,构建有关中国菜品理解的新基准;对于
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 477
477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









