










我们在使用BeautiflSoup 的时候会获取节点,可以获取到节点下的其他的节点。
例如:
title=html2.find('div',{'class':'xq-head'}).find("h2").text
BeautiflSoup 的优势是结构比较清晰,可以很方便得通过一层层地查找,可以快速找到节点信息。
而selenium的优势是可以实现自动化交互,例如可以点击网页元素,可以模拟鼠标移动等等,这些是BeautiflSoup 所没有的。但是BeautiflSoup 在获取节点信息上则更为方便。
但是其实,在selenium里,也可以用find_element 里,也可以使用通过元素的下一个节点去获取元素。

在Selenium中,如果你想通过一个元素的下一个节点去获取该元素,可以使用以下几种方法:
1. 多层递进式:
可以点找到一个一级元素,然后往它的下级再继续查找。
例如下面的写法,可以找到CLASS_NAME节点下,第一个 a 节点并点击它。
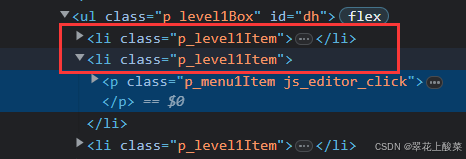
代码:
driver.find_element(By.CLASS_NAME, 'p_level1Box').find_element(By.TAG_NAME, 'a').click()
如果想要点击下一个元素,可以这样写:
driver.find_element(By.CLASS_NAME, 'p_level1Box').find_elements(By.TAG_NAME, 'li')[1].click()
这里适用于,用xpath 或者css_selector去点击某个元素执行不了,或者它来解析多层次节点的内容,例如获取href 或者text,可以不用额外使用BeautiflSoup ,就能办到了!
2. 节点式:
-
XPath轴:
-
使用
following-sibling轴来选取当前节点之后的所有同级节点。
例如,如果你想获取某个节点之后的第一个同级节点,可以使用如下XPath表达式:driver.find_element_by_xpath("//div[@id='s-top-left']/following-sibling::*[1]")这里的
[1]表示选择第一个同级后续节点。
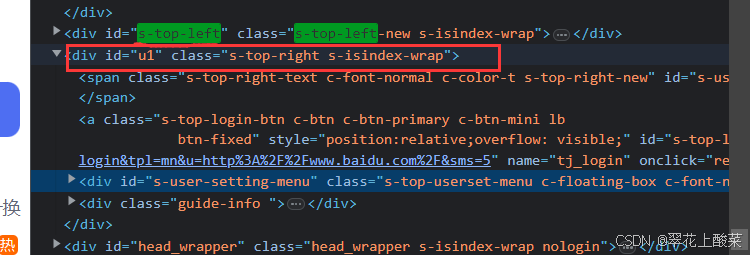
例如上面是获取绿色框节点下,并列的节点的文字。
-
-
CSS选择器:
- 使用
+选择器来选取当前节点紧随其后的同级节点,或者使用~选择器来选取当前节点之后的所有同级节点。例如:
或者driver.find_element_by_css_selector("div#s-top-left + div")driver.find_element_by_css_selector("div#s-top-left ~ div")+选择器会选取紧随其后的同级节点,而~选择器会选取所有后续的同级节点。
- 使用
效果跟xpath同在
- XPath其他位置:
- 你也可以使用XPath的位置函数来选取特定的后续节点。例如,如果你想选取某个节点之后的第二个同级节点,可以使用:
这里的driver.find_element_by_xpath("//div[@id='s-top-left']/following-sibling::div[2]")[2]表示选择第二个同级后续节点。
- 你也可以使用XPath的位置函数来选取特定的后续节点。例如,如果你想选取某个节点之后的第二个同级节点,可以使用:
这些方法可以帮助你根据一个元素的下一个节点去定位和获取该元素。
在实际使用中,你可以根据具体情况选择最适合的方法。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









