







 Redis Cluster采用虚拟槽分区,通过CRC16算法映射数据到16384个槽位,实现节点间数据均衡。节点间通信使用Gossip协议进行信息交换和故障检测。当节点被标记为主观下线后,通过多数节点确认变为客观下线,进而触发故障转移,从节点晋升为新的主节点。数据倾斜问题可能源于节点分配不均、槽数据量差异、大key或内存配置不一致,需要进行排查和调整。
Redis Cluster采用虚拟槽分区,通过CRC16算法映射数据到16384个槽位,实现节点间数据均衡。节点间通信使用Gossip协议进行信息交换和故障检测。当节点被标记为主观下线后,通过多数节点确认变为客观下线,进而触发故障转移,从节点晋升为新的主节点。数据倾斜问题可能源于节点分配不均、槽数据量差异、大key或内存配置不一致,需要进行排查和调整。
目录
前言
集群的作用和为什么要使用集群在上一篇文章里已经介绍过了。链接:
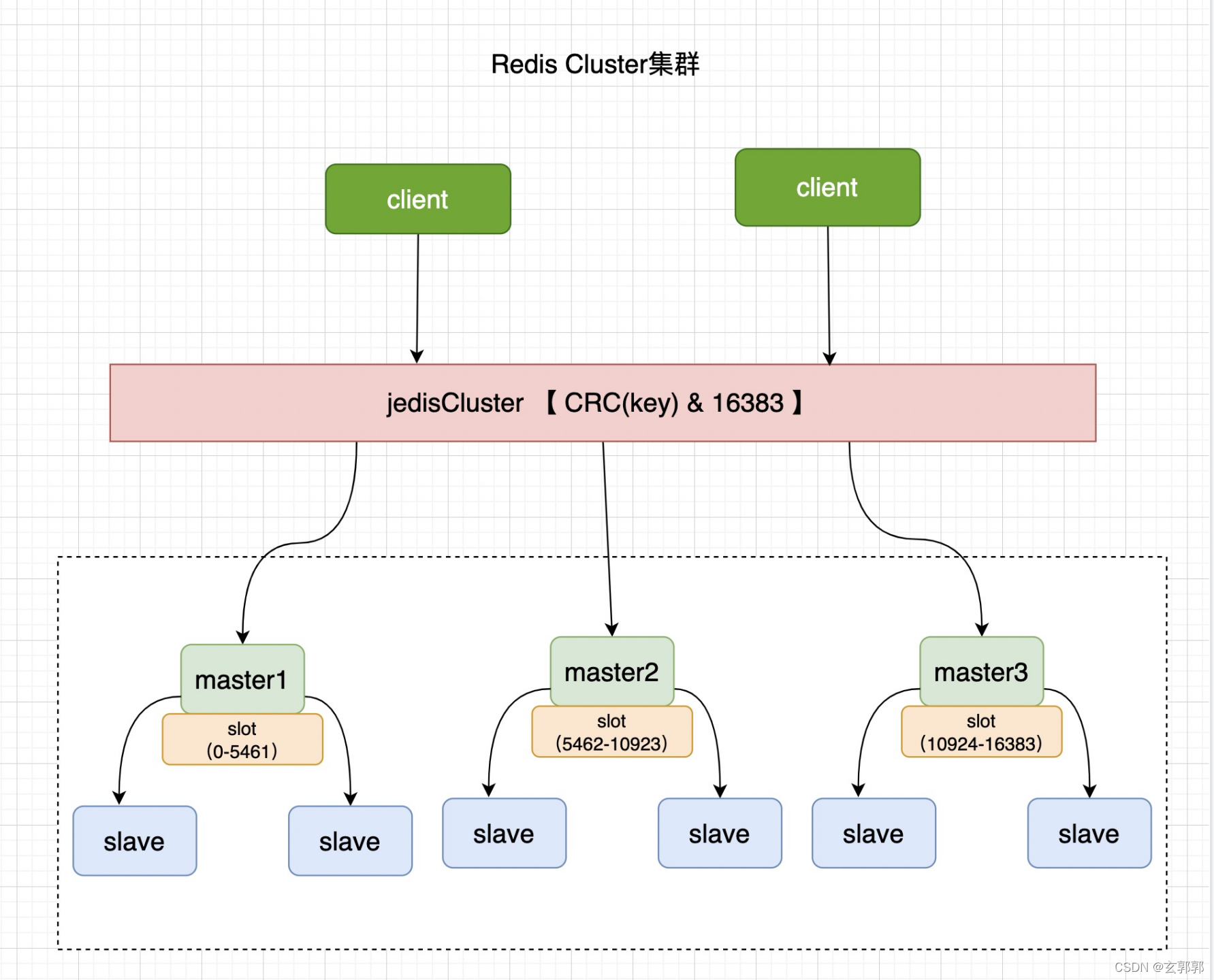
Redis Cluster集群是多个主从节点组成的分布式解决方案。
做到了去中心化,高可用。也不需要哨兵来监控各个节点。
下面来逐步了解一下Redis Cluster集群
数据分区
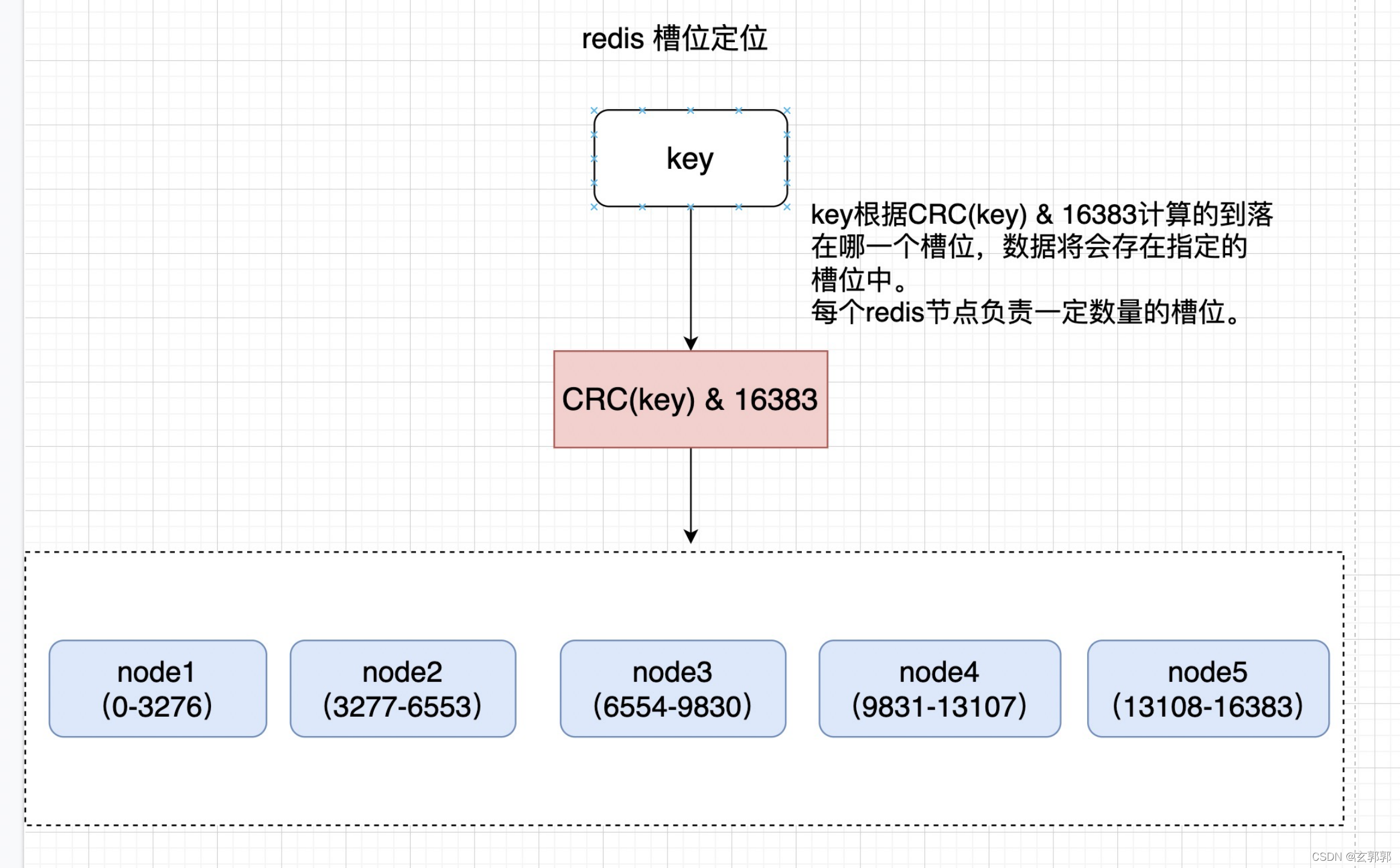
Redis Cluster采用的是虚拟槽分区的方式,将数据进行分区。
虚拟槽分区是利用了哈希空间,通过哈希函数将数据分别映射值一个固定范围的整数集合中,每个整数就相当于一个槽,redis cluster的槽范围就0至16383,一共16384个槽位。槽是集群内数据的基本单位。对数据的迁移等操作,都是按照这个基本单位进行操作的。
Redis Custer中的每一个节点就会负责一定数量的槽。
比如集群有5个节点,那么每个节点负责的大概就是 16384/ 5 = 3276 这么多个槽位的数据。
那么数据是放到哪个槽位中的呢?
是通过这个计算公式得出来的:slot = CRC16(key) & 16383
Redis cluster为什么要使用虚拟槽来进行分区?
1、解耦数据与节点之间的关系
2、节点自身维护槽的映射关系
3、简化了节点的扩容与收缩
集群搭建
参考此篇文章:Linux下Redis安装及集群搭建_玄郭郭的博客-优快云博客_linux安装redis集群
节点通信
因为大多数使用到redis cluster模式的,redis集群的节点会很多,那么节点之间是如何通信的呢?
redis集群采用的是Gossip (流言)协议,工作原理就是节点之间不断的通信交换信息,一段时间后所有的节点都会知道集群的完整的信息。
通信过程:
1、集群中每个节点都会开辟一个单独的TCP通道,用于节点之间通信,通信的端口号是在基础端口号上加10000
2、每个节点会在固定的时间内选择几个节点发送ping消息
3、接收到ping消息的节点会通过pong消息响应。
每个节点都会跟一定数量的节点进行通信,只要每个节点间能够正常通信,经过消息的传播,经过一段时间后所有的节点的信息都会同步完成。
Gossip消息
主要是用来交换信息的。
可分为ping消息、pong消息、meet消息、fail消息。
1、ping消息:集群中交换最频繁的消息。用于检测节点是否在线并交换信息状态的。ping消息会发送自身节点的状态和部分其他节点的状态。
2、meet消息:通知有新节点加入。
3、pong消息:响应消息。当接受到有ping和meet消息时,封装自身状态信息响应给发送消息的节点。
4、fail消息:当某个节点判断集群中的另一个节点下线后,会广播fail消息给其他节点。当其他节点接收到fail消息后,会将该节点状态更新为下线状态。
故障转移
主观下线:某个节点A认为另一个节点B不可用时,会将B标注为下线状态,但这个B节点的下线状态并不是最终的状态。
客观下线:当集群内多个节点都认为某一个C节点不可用时,则C节点是客观下线。如果是持有槽的master节点客观下线了,则需要进行故障转移。
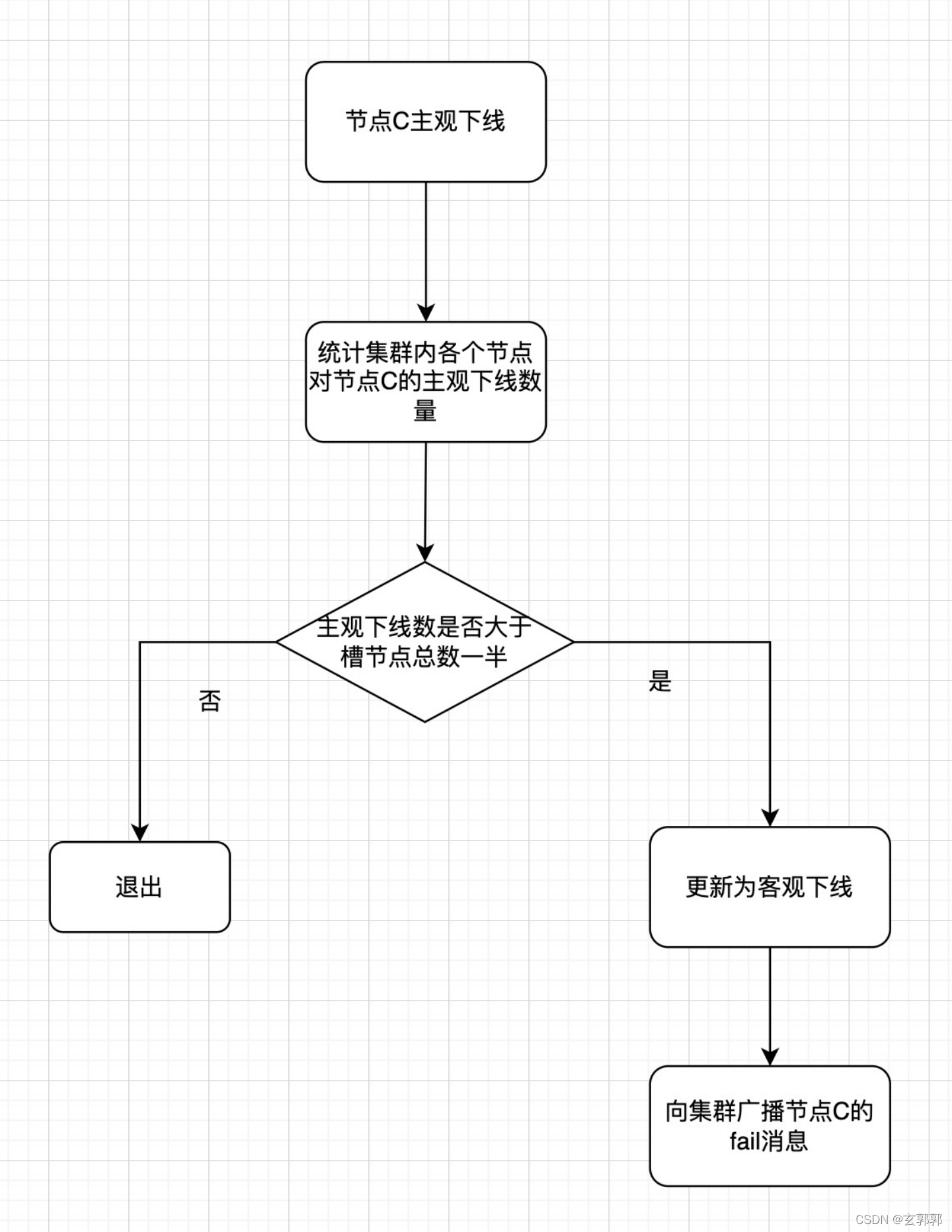
当节点被客观下线后,如果下线的是master节点,则会在他的从节点中选择一个节点来作为新的master节点。大致流程如下:
1、资格检查:检查各个子节点,看谁有成为主节点的资格。
2、准备选举时间:当找到可以成为新的主节点的节点后,会更新触发故障选举的时间,只有到达这个时间后才能执行后续流程
3、发起选举:当从节点的定时任务检查到故障选举时间到了后,则进行开始选举。会向其他的节点发送广播选举消息。
4、选举投票:只有主节点才可以处理收到的广播选举消息的权利,他会同意第一个发送消息的节点作为新的主节点。当有一个从节点收到了整个集群master节点数量一半加1的投票后,则会将该从节点升级为新的master节点,并通知其他节点这个信息。
5、更新主节点:当从节点有足够的票数后,会将自己升级为新的主节点。
数据倾斜问题
日常开发过程中遇到数据问题,可以按照下面几个方向进行排查
1、节点和槽分配不均匀
2、不同的槽对应的数据量差异过大
3、有大key存在
4、内存相关配置不一致


















 1834
1834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









