



 该博客内容涉及对视频场景和人物信息的处理,以生成供前端使用的csv文件。通过检查是否存在场景照片来决定是否填充1,确保字典结构统一。如果有人脸信息且场景齐全,则不补充;否则,为空场景或人物添加1。最终,根据不同的信息组合,进行'与'操作生成所需的字典文件。
该博客内容涉及对视频场景和人物信息的处理,以生成供前端使用的csv文件。通过检查是否存在场景照片来决定是否填充1,确保字典结构统一。如果有人脸信息且场景齐全,则不补充;否则,为空场景或人物添加1。最终,根据不同的信息组合,进行'与'操作生成所需的字典文件。
2021SC@SDUSC
最终需要返回给前端同学一个csv文件保存的字典,用来反映视频的场景人物信息。为了方便前端同学处理,这里针对不同组合情况进行归一化处理,生成最后一份字典文件。
处理情况:
-场景-人物1-人物2
-场景-人物1
-人物1-人物2
-人物1
最终字典结构如下:
视频名 -人物1 -人物2-场景
前端同学只需要将上面的情况依据选择进行“与”操作,空缺部分后端提前填入1,不受影响。
如果存在场景要求,判断人脸信息是否齐全,齐全则不用补充,否则空缺部分补1
try:
print("有场景照片")
t=CalculateDistance('/opt/data/private/xuyunyang/EasyCut/'+id+'/'+id_video_name+'/Resources/ScenePhoto')
df1 = pd.read_csv(
'/opt/data/private/xuyunyang/EasyCut/' + id + '/' + id_video_name + '/Resources/result/' + id_video_name + "_" + 'gif_count.csv')
df2 = pd.DataFrame({'scene': t})
l = len(list(df1.keys()))
if l == 4:
pass
else:
if l == 3:
df1.columns = ['videoPath', 'face1', 'face2']
df2.columns = ['scene']
dataframe = df1.join(df2)
dataframe.to_csv(
'/opt/data/private/xuyunyang/EasyCut/' + id + '/' + id_video_name + '/Resources/result/' + id_video_name + "_" + 'gif_count.csv',
index=False, mode='w', sep=',')
else:
df1.columns = ['videoPath', 'face1']
df2.columns = ['scene']
a = len(df1['videoPath'])
d = []
for i in range(a):
d.append(1)
df3 = pd.DataFrame({'face2': d})
dataframe = df1.join(df3)
dataframe = dataframe.join(df2)
dataframe.to_csv(
'/opt/data/private/xuyunyang/EasyCut/' + id + '/' + id_video_name + '/Resources/result/' + id_video_name + "_" + 'gif_count.csv',
index=False, mode='w', sep=',')
如果没有场景要求,则会把场景部分补1
except:
print("没有场景照片")
#场景照片补1
df1 = pd.read_csv(
'/opt/data/private/xuyunyang/EasyCut/' + id + '/' + id_video_name + '/Resources/result/' + id_video_name + "_" + 'gif_count.csv')
if l == 3:
df1.columns = ['videoPath', 'face1', 'face2']
a = len(df1['videoPath'])
d = []
for i in range(a):
d.append(1)
df3 = pd.DataFrame({'scene': d})
dataframe = df1.join(df3)
dataframe.to_csv(
'/opt/data/private/xuyunyang/EasyCut/' + id + '/' + id_video_name + '/Resources/result/' + id_video_name + "_" + 'gif_count.csv',
index=False, mode='w', sep=',')
else:
df1.columns = ['videoPath', 'face1']
a = len(df1['videoPath'])
d = []
for i in range(a):
d.append(1)
df3 = pd.DataFrame({'face2': d})
dataframe = df1.join(df3)
a = len(df1['videoPath'])
d = []
for i in range(a):
d.append(1)
df3 = pd.DataFrame({'face2': d})
dataframe = dataframe .join(df3)
实现
运行命令测试:
python scene_gennerate.py --ID 5 --ID_VideoName 5_5_1654526936103
出错记录:

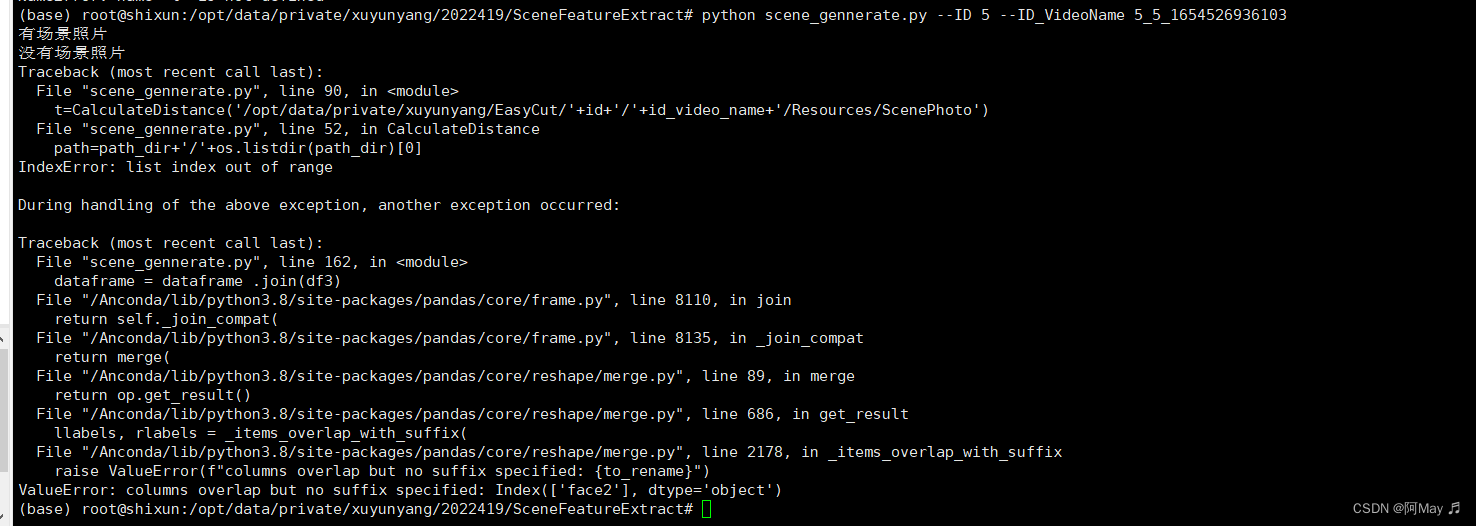
最后调试成功,在服务器顺利生成:

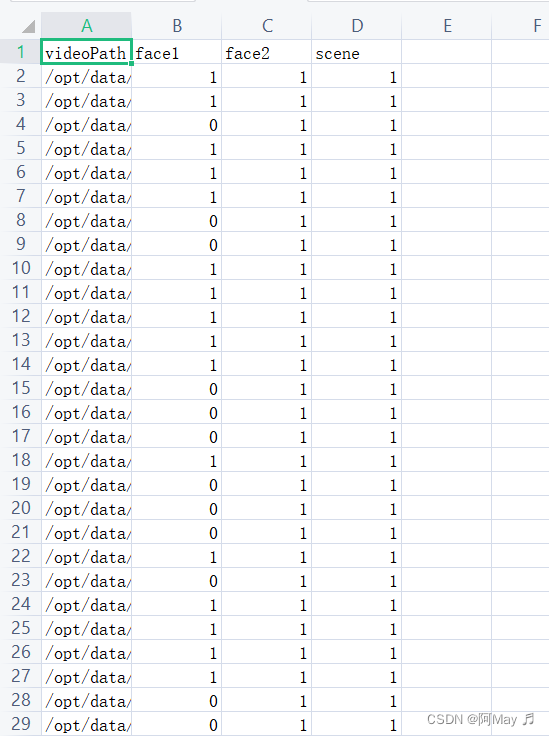
效果:
这里测试是使用一个人脸无场景进行的:

















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









