




 本文深入解析注意力机制的概念,探讨其在神经网络中的应用,包括软注意力、硬注意力、键值对注意力、多头注意力等变体,以及在Transformer模型中的关键作用。
本文深入解析注意力机制的概念,探讨其在神经网络中的应用,包括软注意力、硬注意力、键值对注意力、多头注意力等变体,以及在Transformer模型中的关键作用。
Attention整理
来源多方面,课程记录以及各种博客。
除了摘录的定义,也会有个人理解
注意力机制的思想(为什么要?)
- 一方面:
人在观测物体、阅读文章时,肯定会有所侧重,不会同时注意到全部信息。如果带着任务,就会侧重于与任务相关的信息,如果没有,则可能会注意到醒目的,或者与个人知识背景有关的信息。
因此,对神经网络也是如此,比如在做阅读理解时,就需要把注意力集中在与问题相关的段落上。
但是比如RNN、LSTM这样的方法,虽然使得网络具有记忆能力,隐藏层能够存储之前的信息。但还是存在长程记忆的问题;对于长句,LSTM也是无法很好地解决。
RNN这样的网络,还面临着模型容量问题,内容保存越多,需要的容量就要越大 - 另一方面:
虽然说有通用近似定理作为支撑,神经网络能够近似任意非线性函数。
但由于优化算法、计算能力的限制,一般很难达到理想的效果。
因此,提升网络能力十分重要:局部连接、权重共享、汇聚操作
注意力机制也是一种提升网络能力的办法,映射到人的思想:大面积覆盖,小范围关注
定义
在计算能力有限的情况下, 注意力机制也可称为注意力模型.注意力机制(Attention
Mechanism)作为一种资源分配方案,将有限的计算资源用来处理更重要的信息,是解决信息超载问题的主要手段.
注意力机制的计算可以分为两步:一是在所有输入信息上计算注意力分布,二是根据注意力分布来计算输入信息的加权平均.
要计算注意力分布,一般而言需要一个查询向量,比如阅读理解任务中的问题(encoder后),当然这个query有时也作为可学习的参数,有时也是信息本身的一部分(self attention)。这很好理解,同样的信息,对于不同的任务我们需要关注的重点是不一样的,所以这个查询向量可以理解为与任务相关的表示。
给定信息X
∈
R
d
∗
N
\in\mathbb R^{d*N}
∈Rd∗N,查询向量q,注意力分布从数学上表达:
α
n
=
p
(
z
=
n
∣
X
,
q
)
=
s
o
f
t
m
a
x
(
s
(
x
n
,
q
)
)
=
exp
(
s
(
x
n
,
q
)
)
∑
j
=
1
N
exp
(
s
(
x
j
,
q
)
)
\alpha_n = p(z = n|X,q) =softmax(s(x_n,q)) = \frac{\exp(s(x_n,q))}{\sum_{j=1}^{N}\exp(s(x_j,q))}
αn=p(z=n∣X,q)=softmax(s(xn,q))=∑j=1Nexp(s(xj,q))exp(s(xn,q))
-
这里给出的例子是soft attention的计算方法。
如果是hard attention,就是随机采样,或者最大采样(类似于max pooling操作)。
但hard attention的问题在于其不可导(损失函数与注意力分布之间的函数关系)。因此通常需要强化学习的方法进行训练。 -
s ( x n , q ) s(x_n,q) s(xn,q)是注意力打分函数,有多种形式:
加性模型:𝑠(𝒙, 𝒒) = 𝒗T tanh(𝑾𝒙 + 𝑼𝒒)
点积模型:𝑠(𝒙, 𝒒) = 𝒙T𝒒
缩放点积模型:𝑠(𝒙, 𝒒) =𝒙T𝒒\√𝐷
双线性模型:𝑠(𝒙, 𝒒) = 𝒙T𝑾𝒒加性模型就可以简单理解为一个线性层+tanh的激活函数
但点积模型在实现上可以利用矩阵计算,效率更高
缩放点积模型考虑到维数高方差大进而导致梯度小(注意函数的曲线)的问题
双线性模型则引入非对称性,W是可学习的参数。
注意力机制的变体
硬注意力
soft attention选择的信息是所有输入向量在注意力分布下的期望,hard attention只关注某一个输入向量的信息,比如最大或者随机。
问题正如上述:最终的损失函数与注意力分布之间的函数关系不可导,无法使用反向传播算法进行训练。
键值对注意力
a
t
t
(
(
K
,
V
)
,
q
)
=
∑
i
=
1
N
α
n
v
n
=
∑
i
=
1
N
exp
(
s
(
k
n
,
q
)
)
∑
j
=
1
N
exp
(
s
(
k
j
,
q
)
)
v
n
att((K,V),q) = \sum_{i=1}^N\alpha_nv_n = \sum_{i=1}^N\frac{\exp(s(k_n,q))}{\sum_{j=1}^{N}\exp(s(k_j,q))} v_n
att((K,V),q)=i=1∑Nαnvn=i=1∑N∑j=1Nexp(s(kj,q))exp(s(kn,q))vn
当K=V时,就是普通的soft attention。
多头注意力
利用多个查询向量来并行的从输入信息中心选取多组信息,进行拼接。意义在于每个注意力来关注输入信息中的不同部分。
层次注意力
当输入信息是扁平结构时,注意力机制实际是去找所有输入信息上的多项分布。当输入信息不是平坦的,有层次结构时,可以引入层次化的注意力来进行更好地信息选择。
在关系抽取中,《Hierarchical Relation Extraction with Coarse-to-Fine Grained Attention》这篇就是利用数据集中关系的层次化结构来运用层次化的注意力机制。
指针网络
如果只使用注意力机制的第一步,即计算出注意力分布,可将其作为一个软性指针,指出相关位置的信息。
自注意力机制
在NLP中,我们通常面对的输入是变长的向量序列,用CNN或者RNN进行编码。CNN,可以理解为一个词窗,对于局部的信息进行编码整合;RNN,虽然理论上说可以处理长距离依赖,比如LSTM、GRU的提出,但是,由于模型的容量以及依然存在的梯度消失问题,实际上还是对于短距离的依赖关系进行编码。
注意力机制\自注意力机制对于变长序列,是可以生成注意力分布,覆盖到全局,分布其实就是连接的权重,然后根据权重,确定需要关注的部分。
自注意力机制就是K、Q、V的向量由自己产生。
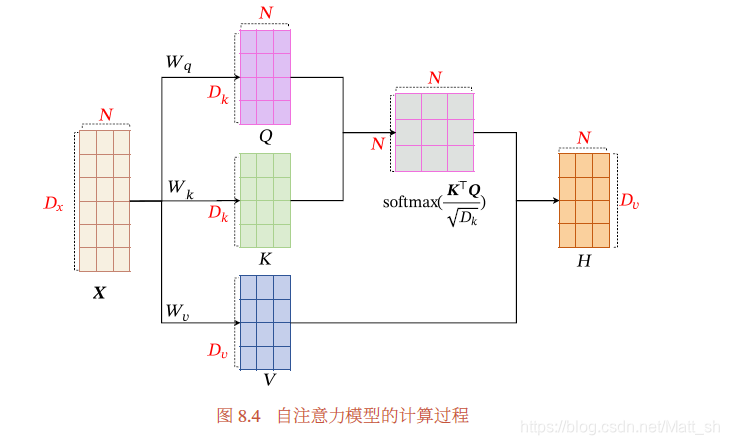
在自注意力机制中,对于一个自注意力模型,查询向量就是Q = [q1,q2,…qN],也就是自身的一个矩阵乘法。之前有些任务,比如阅读理解,查询向量q,是特定的问题;翻译中,查询向量是解码部分的隐藏层。
具体过程:
- 首先生成三个向量序列
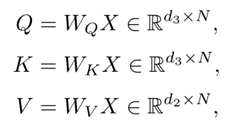
- 计算
h
n
h_n
hn:
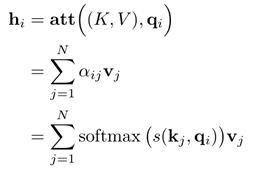
自注意模型输出的人仍是同样长度的序列(维度会变)但与全连接网络还是不一样的。
体现在:
- 全连接网络是定长的,而自注意力模型是变长的,取决于每次输入序列的实际长度(因为有结束标志)
- 全连接网络权重wij是要学习的参数,最后是固定的。而自注意力模型要学习的参数不是权重本身,而是产生权重的这些矩阵Wq,Wk,Wv。因此训练完,对于每个新的输入,其注意力分布也是会有所差异的。可以理解为自注意力模型的权重是动态生成的。
Transfomer
说到自注意力机制,就必须提到Transfomer这个介绍十分的详细。
Transfomer中需要关注的点:
- 自注意力机制(多头注意力)
- 位置编码
- 层归一化
- 逐位的FNN
- 直连边
多头自注意力
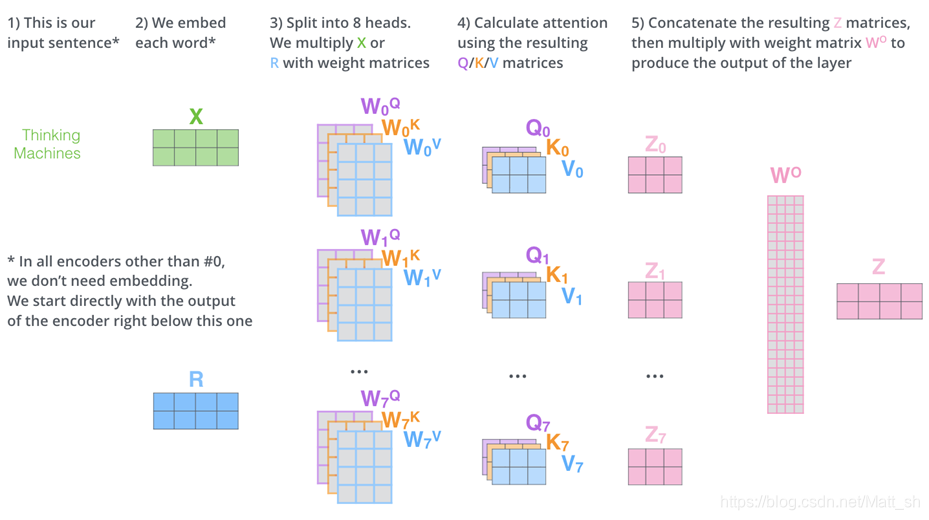
多头注意力,就是设置多组(Q,K,V)进行计算,然后将结果(Z1,Z2,Z3…)拼接成最终的Z。
这样做的好处是什么?
摘抄自上述文章:
It expands the model’s ability to focus on different positions. Yes, in the example above, z1 contains a little bit of every other encoding, but it could be dominated by the the actual word itself. It would be useful if we’re translating a sentence like “The animal didn’t cross the street because it was too tired”, we would want to know which word “it” refers to.
It gives the attention layer multiple “representation subspaces”. As we’ll see next, with multi-headed attention we have not only one, but multiple sets of Query/Key/Value weight matrices (the Transformer uses eight attention heads, so we end up with eight sets for each encoder/decoder). Each of these sets is randomly initialized. Then, after training, each set is used to project the input embeddings (or vectors from lower encoders/decoders) into a different representation subspace.
好处肯定是增强了模型的能力。体现在什么?attention就是能关注不同的部分,多个自注意力就能更好地关注到需要关注的部分,同时,多个注意力机制相当于多个表示的子空间,即模型对于语义信息的表示能力也增强。
【个人看法:这些都是直观的阐述与理解,证明就是效果确实好。没有很严密的理论推导证明,正是现在深度学习的特点之一。】

















 9147
9147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









