



💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
在当今数字化与智能化飞速发展的时代背景下,基础论文聚焦于极具前沿性与挑战性的智能人机交互系统领域。智能人机交互系统旨在打破人与机器之间的隔阂,实现两者之间高效、自然且精准的沟通与协作,其应用场景广泛涵盖智能家居、智能驾驶、工业自动化控制以及医疗康复辅助等众多关键领域,对于提升人类生活质量、推动各行业技术革新具有举足轻重的意义。
在深入探究智能人机交互系统的过程中,一个核心问题浮现出来,即如何精准地寻找模型的最佳参数。传统的参数寻优方法往往需要耗费大量的人力、物力以及时间成本,研究人员需要反复进行手动调整与试验,并且难以确保所得到的参数组合能够实现系统的最优性能。为了攻克这一难题,研究者创新性地将寻找模型最佳参数的问题巧妙转化为线性二次型调节器(LQR)问题。LQR 作为一种经典的最优控制理论方法,基于系统的状态方程和性能指标函数,通过求解一组线性代数方程,能够实现对系统的精准控制,使得系统在满足一定约束条件下,最大限度地减少人力的投入,同时有效地优化闭环行为,提升系统的整体稳定性、响应速度以及精准度。
然而,智能人机交互系统中的人体模型具有极高的复杂性与不确定性。人体的运动、姿态、意图以及生理状态等诸多因素相互交织且动态变化,这使得准确估计人体模型成为一项艰巨的任务。面对这一困境,本文另辟蹊径,引入强化学习这一前沿技术来解决 LQR 问题。强化学习借鉴了生物学习的基本原理,通过让智能体在环境中不断地进行试验与探索,依据环境反馈的奖励信号来学习最优策略。在本研究中,智能体代表着智能人机交互系统,环境则包含了人体模型以及与之相关的外部条件。智能体通过采取不同的行动(对应不同的参数设置),接收来自环境的奖励(如系统性能的提升、人机交互的流畅度等),从而逐步学习到解决 LQR 问题的最优参数,实现对人体模型不确定性的有效应对。
围绕着利用强化学习解决 LQR 问题这一核心,该项目精心规划了两项关键任务。
第一部分着重于积分强化学习的应用。积分强化学习是强化学习领域中的一个重要分支,它相较于传统的强化学习方法,具有独特的优势。传统强化学习有时可能会陷入局部最优解,而积分强化学习通过引入积分项,能够综合考虑系统的长期累积效果,更加注重系统的全局最优性能。在智能人机交互系统中,积分强化学习可以充分利用系统在过去一段时间内的交互信息,对不同时刻的奖励进行累积与整合,使得智能体在探索过程中能够更全面地权衡利弊,避免因短期利益而忽视长期发展,进而引导智能体找到更优的人机交互策略,提升系统的稳定性与适应性。
第二部分致力于使用神经网络找到 LQR 的最佳解决方案。神经网络作为一种强大的机器学习工具,具有出色的非线性映射能力和自学习能力。在面对复杂的 LQR 问题时,神经网络能够通过构建多层神经元结构,对大量的数据进行学习与训练,自动捕捉系统中隐藏的复杂规律和关系。通过将神经网络与 LQR 相结合,一方面可以利用神经网络对人体模型以及系统的动态特性进行高效建模,克服传统建模方法的局限性;另一方面,神经网络能够快速地为 LQR 提供所需的最优参数估计,大大提高了求解 LQR 问题的效率和准确性,为智能人机交互系统的优化提供了强有力的技术支撑。 综上所述,本基础论文通过将模型参数寻优转化为 LQR 问题,并借助强化学习以及相关的前沿技术手段,致力于攻克智能人机交互系统中的关键难题,为该领域的进一步发展开辟了新的道路,有望在未来的实际应用中带来诸多变革与突破。
📚2 运行结果
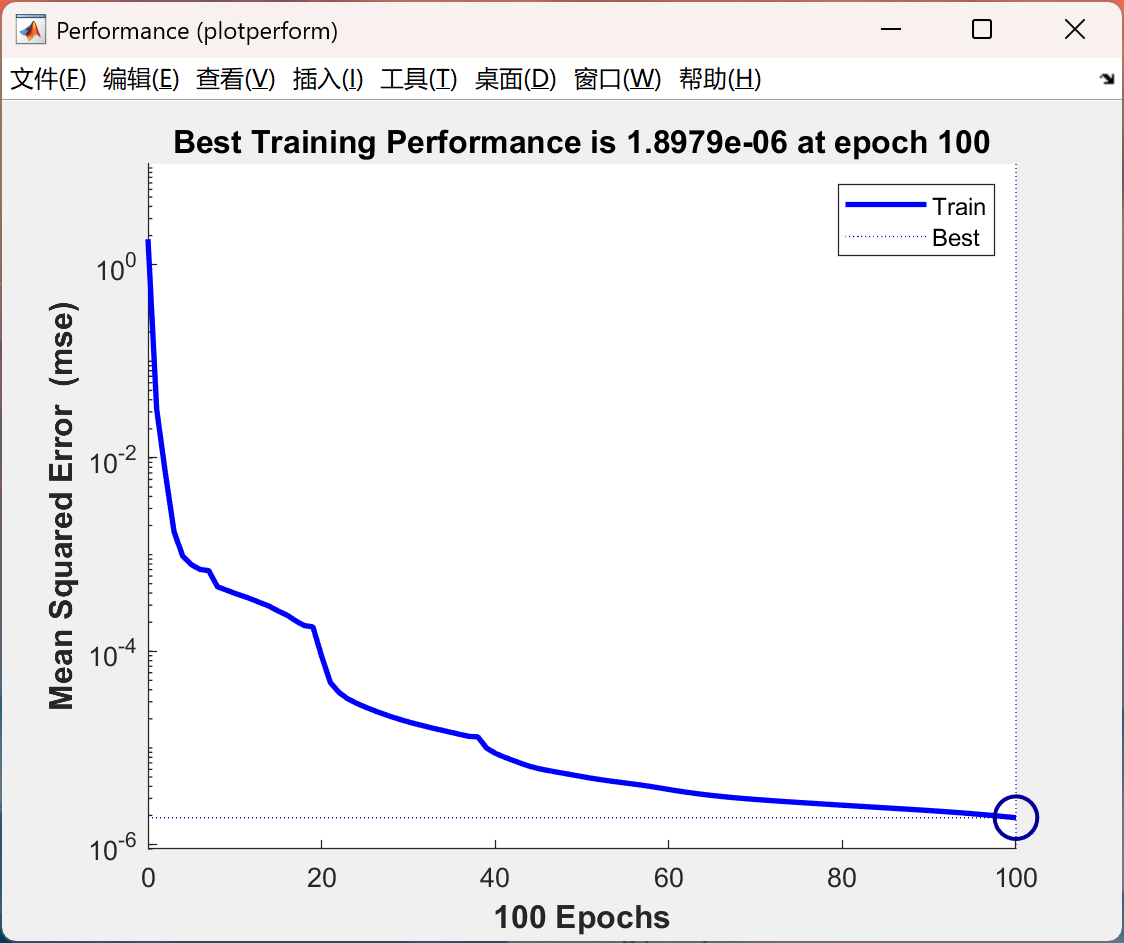
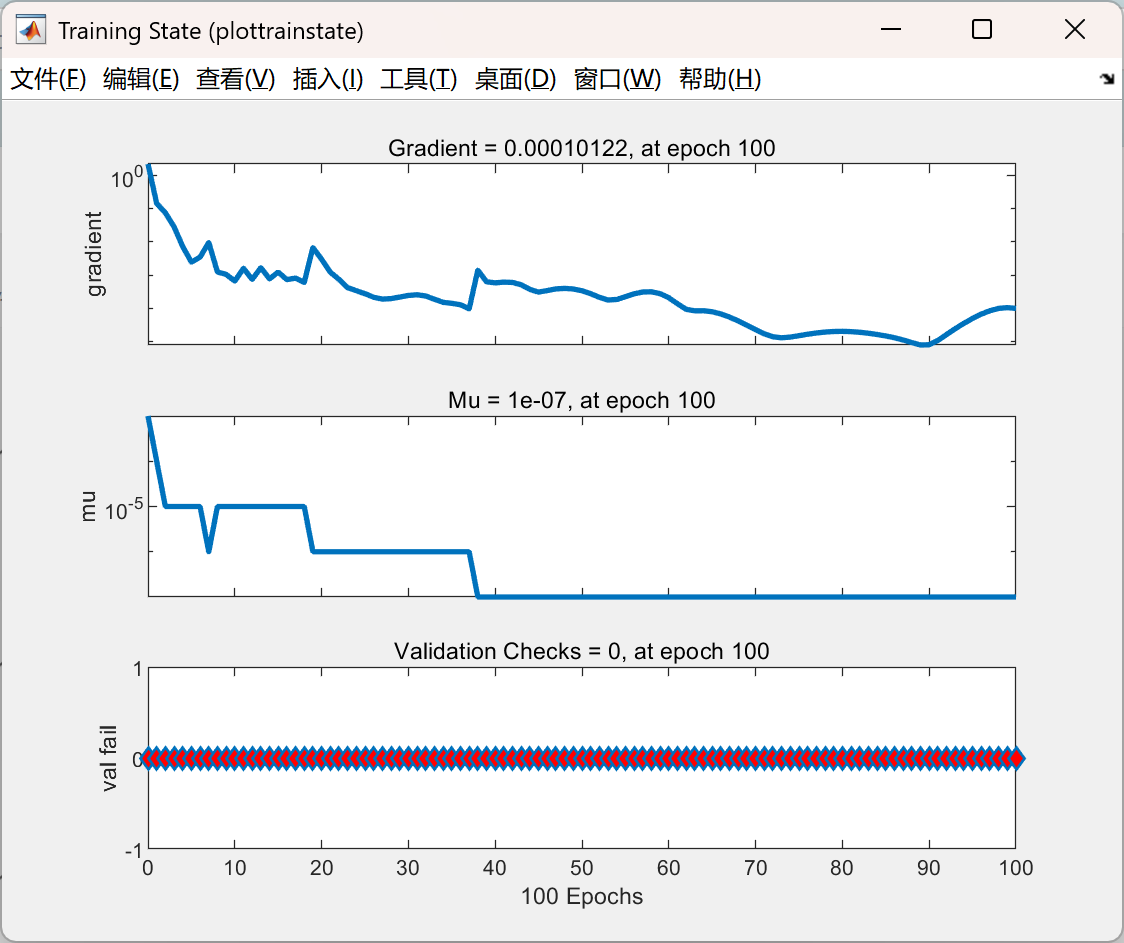
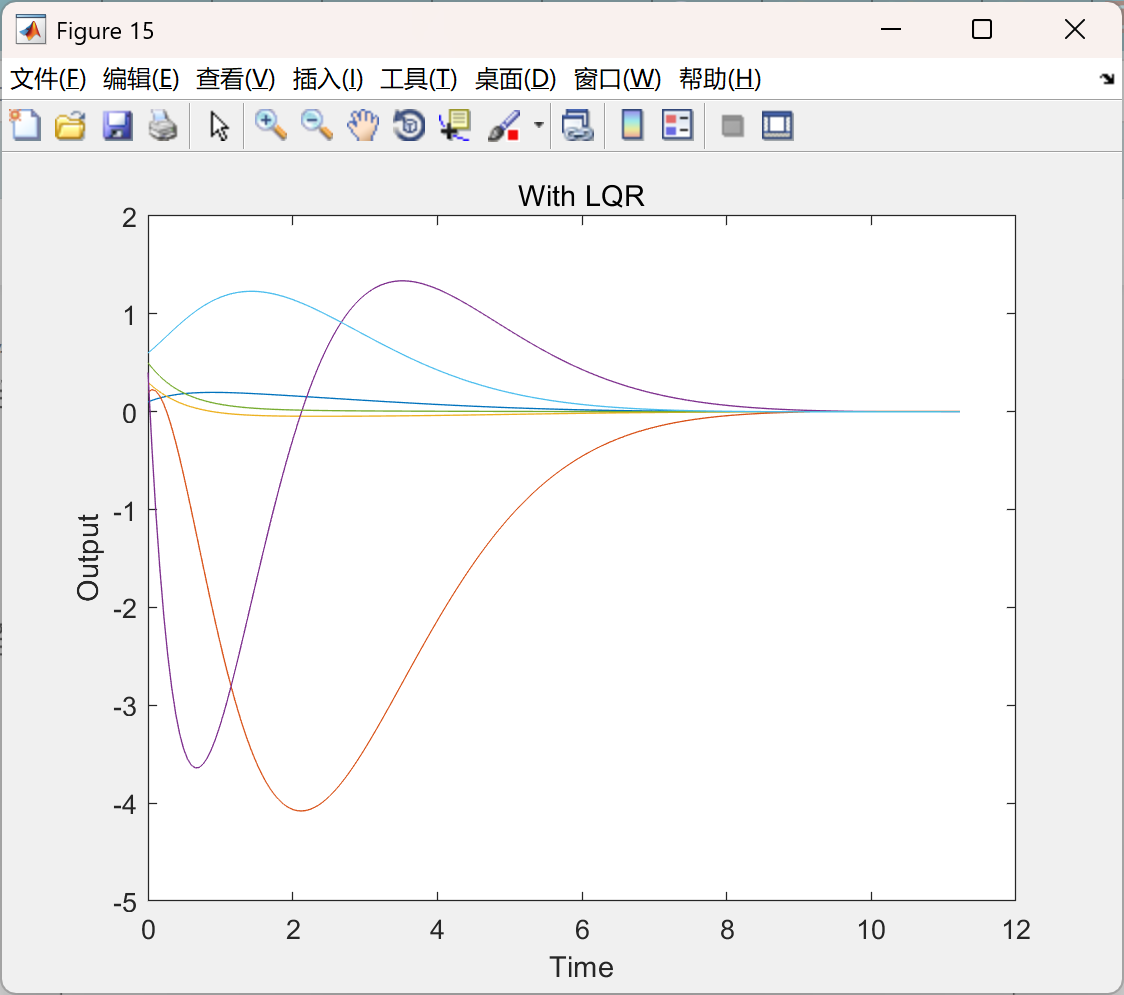
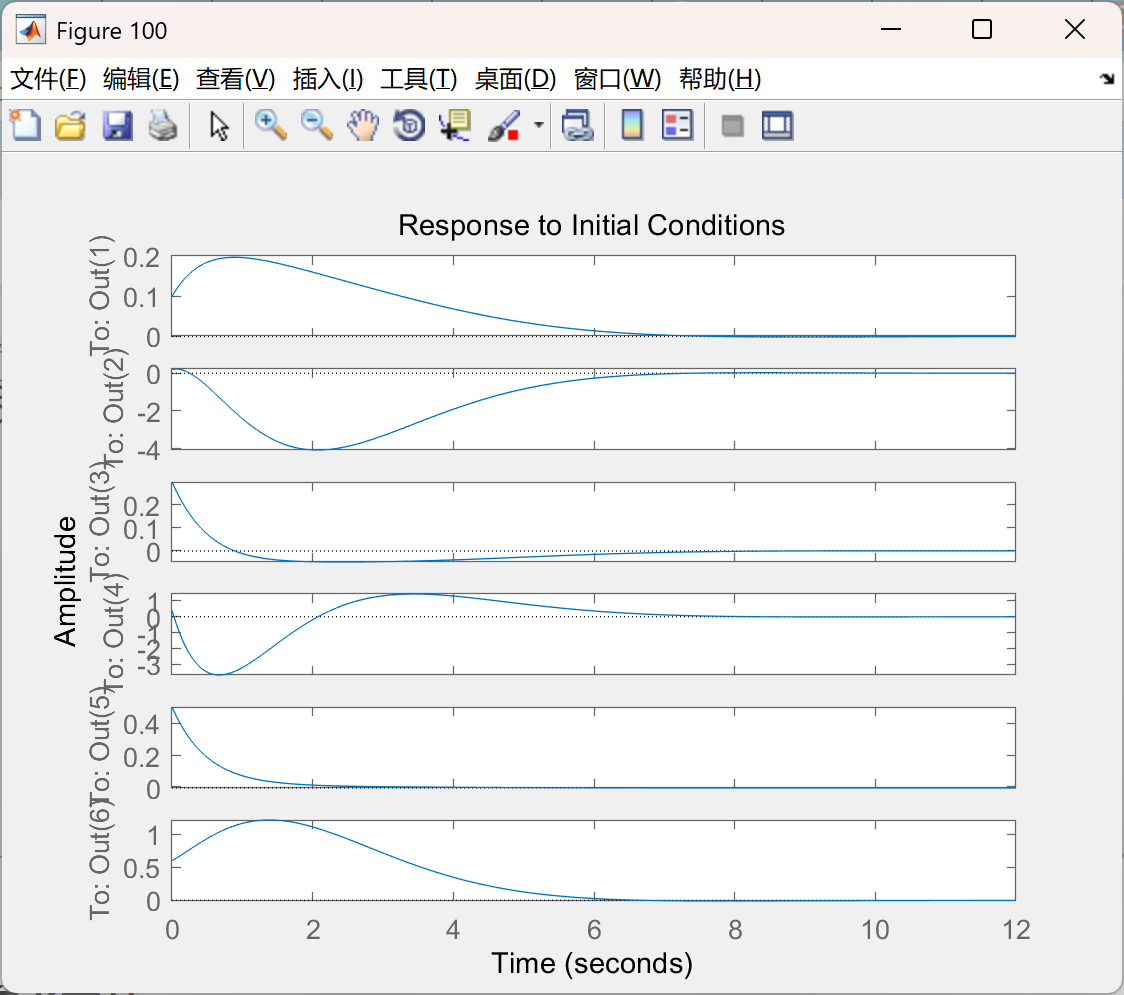
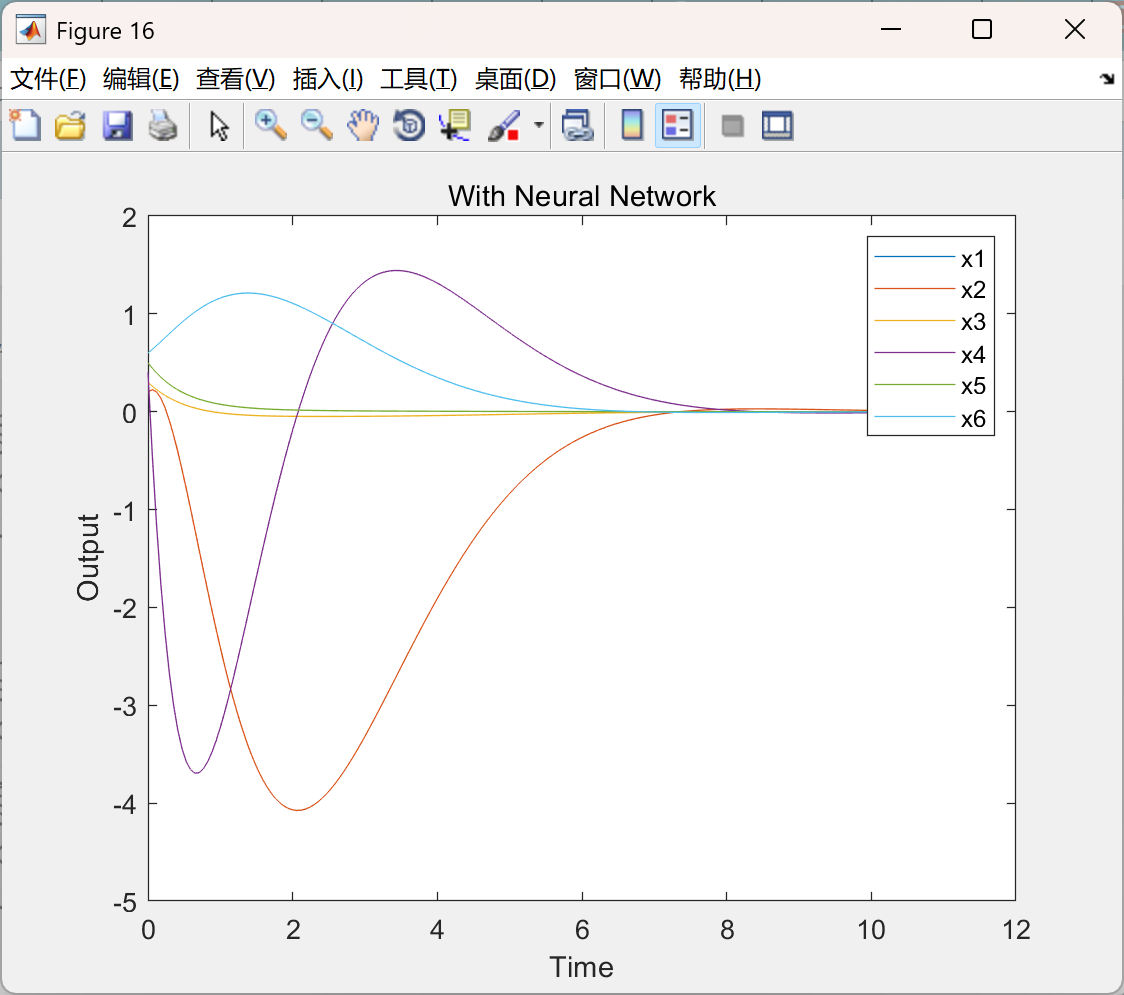
部分代码:
clear all
training = 1;
with_noise = 1;
% pendulum parameters
M = .5;
m = 0.2;
b = 0.1;
I = 0.006;
g = 9.8;
l = 0.3;
a2_max = 100;
a1_max = 4;
if training == 0,
load net_lqr.mat
open('sfoc_lqr_ann.slx');
disp('Simulating...');
set_param('sfoc_lqr_ann','SimulationCommand','start');
return
end
k = 1;
disp('LQR: calculating gain matrices K for different slips at different mass for pendulum and cart');
for a1 = 1:1:100,
for a2 = 1:0.5:20,
p = I*(a1+a2)+a1*a2*l^2; %denominator for the A and B matrices
A = [0 1 0 0;
0 -(I+a2*l^2)*b/p (a2^2*g*l^2)/p 0;
0 0 0 1;
0 -(a2*l*b)/p a2*g*l*(a1+a2)/p 0];
B = [ 0;
(I+a2*l^2)/p;
0;
a2*l/p];
% [AT,BT,CT,DT] = ssdata(rss(6,1,2));
Q = eye(4);
R = eye(1);
if rank(ctrb(A,B)) ~= 4
continue;
end
[Klqr,S,E] = lqr(A,B,Q,R);
%inputANN(:,k) = [A(1,:)';A(2,:)';A(3,:)';A(4,:)';A(5,:)';A(6,:)';BT(1,:)';BT(2,:)';BT(3,:)';BT(4,:)';BT(5,:)';BT(6,:)'];
inputANN(:,k) = [a1;a2];
outputANN(:,k) = [Klqr(1,:)'];
k = k+1;
end
end
norm_input = max(abs(inputANN'))';
norm_inputANN = repmat(norm_input',max(size(inputANN)),1)';
norm_output = max(abs(outputANN'))';
norm_outputANN = repmat(norm_output',max(size(outputANN)),1)';
P = inputANN./norm_inputANN;
T = outputANN./norm_outputANN;
s1 = 12;
s2 = 20;
[s3,pom] = size(T);
net = feedforwardnet([s1,s2]);
net.layers{1}.transferFcn = 'tansig';
net.layers{2}.transferFcn = 'tansig';
net.layers{3}.transferFcn = 'purelin';
net.divideFcn='dividetrain';
net.trainParam.show = 5;
net.trainParam.epochs = 50;
disp('Training');
[net,tr] = train(net,P,T);
figure(13)
plotperform(tr)
figure(14)
plottrainstate(tr)
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
[1]赵为光,安佰杰,杨莹,等.基于稳定性约束深度强化学习的含源配电网分散式无功功率电压控制策略[J/OL].南方电网技术,1-11[2025-03-23].http://kns.cnki.net/kcms/detail/44.1643.TK.20250320.2253.006.html.
[2]王政,王华,崔可可,等.局部引导强化学习的舰载机自主调运方法[J/OL].航空学报,1-13[2025-03-23].http://kns.cnki.net/kcms/detail/11.1929.v.20250320.1420.004.html.
🌈4 Matlab代码实现


















 1118
1118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









