




摘要
本周深入探讨了机器学习训练优化的关键策略。重点学习了自适应学习率技术(如Adagrad、RMSProp和Adam)的原理与应用,分析了训练停滞的原因与梯度震荡问题;同时研究了分类任务的本质,对比了回归与分类的差异,引入独热向量(one-hot vector)和Softmax函数处理多分类问题,并解释了交叉熵损失函数(Cross-entropy)相较于均方误差(MSE)在分类任务中的优势。
Abstract
This week delves into core strategies for optimizing machine learning training. Key focus includes: principles and applications of adaptive learning rate techniques (e.g., Adagrad, RMSProp, Adam); analysis of training stagnation and gradient oscillation issues; examination of classification task fundamentals, contrasting regression vs. classification; implementation of one-hot vectors and Softmax for multi-class problems; and the superior efficacy of cross-entropy loss over mean squared error (MSE) in classification tasks.
一.自适应学习率技术(Adaptive Learning Rate)
1.loss不再减小的原因不止于critical point
在上周的学习中我们了解了critical point是我们在训练network过程中的一个障碍,但是它并不 一定 是最大的一个障碍,而error surface(误差曲面)则一定是。那我们为什么这么说呢?
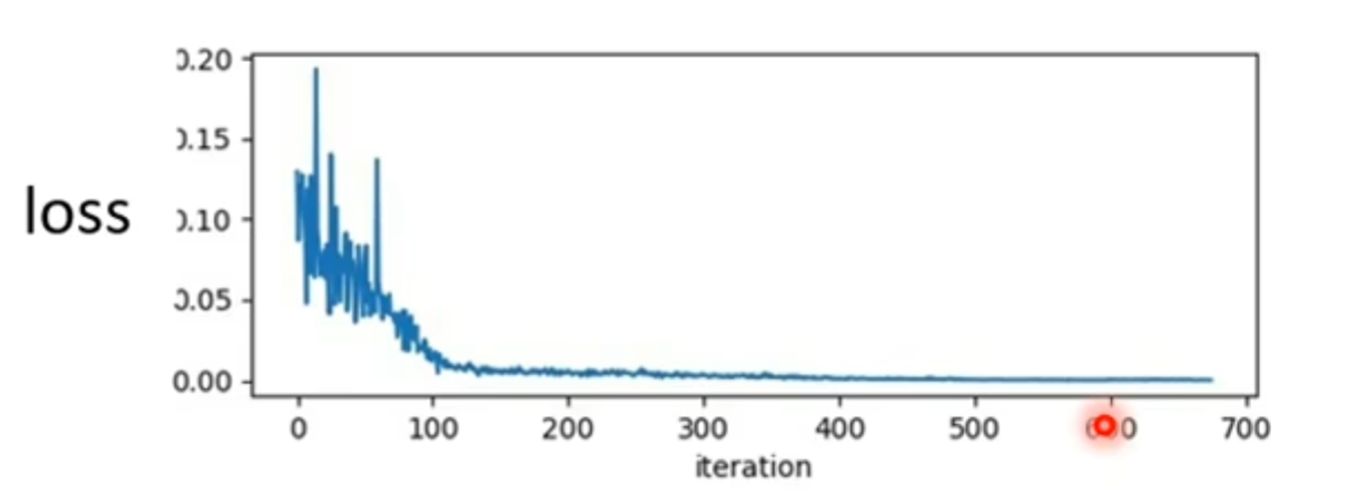
正常我们通过不断update,我们得到的loss会越来越小,最后loss不再减小,多数情况下我们会 认为是不是达到了critical point,因为gradient等于0的原因导致我们无法更新。但是我们要注意到当 我们的loss不在下降时,对应的gradient真的很小吗?

如上图,我们对比右边两个相对应的图像发现,当loss后面不再降低的时候gradient向量反而并 没有变得更小,而且还会突然的升高。而出现这种情况我们可能就是遇到了,左边图形error surface 的情况,我们的gradient在这个山谷谷壁间来回震荡。而这种情况我们并不是因为卡在critical point 这几个情况当中。
所以我们这并不是说critical point并不是一个问题,只是说当我们用gradient descent来optimization 时真正要注意的往往不是critica
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









