代码
import requests
from lxml import etree
import re
import csv
import threading
class Spider:
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
def get_response(self, url):
try:
response = requests.get(url, headers=self.headers)
response.encoding = 'utf-8'
assert response.status_code == 200
return response
except:
return None
def run(self, url):
html = etree.HTML(self.get_response(url).text)
detail_url = html.xpath('//p[@class="name"]/a/@href')
for url in detail_url:
url = "https://maoyan.com" + url
self.parse_detail(url)
def parse_detail(self, url):
html = etree.HTML(self.get_response(url).text)
item = {}
item["电影名称"] = ''.join(html.xpath('//div[@class="movie-brief-container"]/h3/text()'))
item["类型"] = ''.join(html.xpath('//div[@class="movie-brief-container"]/ul/li[1]/text()'))
item["上映地点"] = ''.join(html.xpath('//div[@class="movie-brief-container"]/ul/li[2]/text()'))
item["上映地点"] = re.sub(' |\n', '', item['上映地点'])
item["上映日期"] = ''.join(html.xpath('//div[@class="movie-brief-container"]/ul/li[3]/text()'))
print(item)
w.writerow(item)
if __name__ == '__main__':
url = "https://maoyan.com/board/4?offset={}"
spider = Spider()
with open('./猫眼.csv', 'w') as f:
w = csv.DictWriter(f, fieldnames=["电影名称", "上映地点", "上映日期", "类型"])
w.writeheader()
thread_l = []
for x in range(10):
t = threading.Thread(target=spider.run, args=(url.format(x * 10),))
t.start()
thread_l.append(t)
for t in thread_l:
t.join()
数据展示
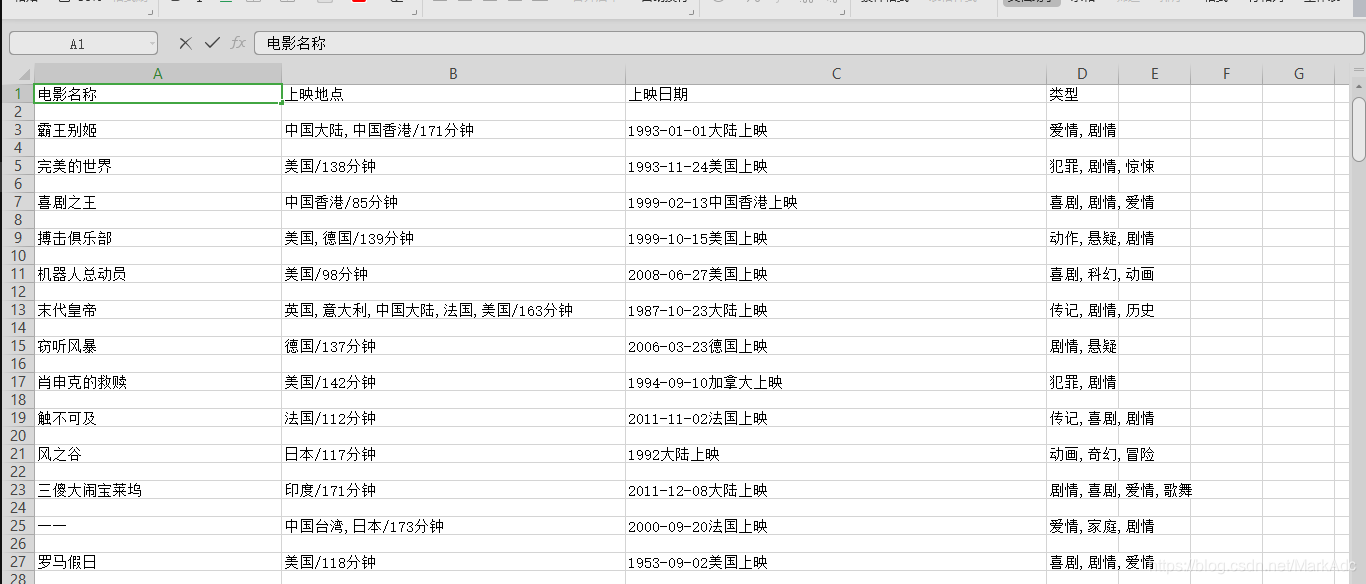





 博客主要包含代码和数据展示两部分内容,聚焦信息技术领域中代码编写及数据呈现相关内容。
博客主要包含代码和数据展示两部分内容,聚焦信息技术领域中代码编写及数据呈现相关内容。

















 1485
1485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









