




 本文介绍了一种使用Python爬取英雄联盟(LOL)英雄皮肤信息的方法。通过访问特定URL,如剑魔(编号266)的皮肤列表页面,利用requests和json库解析数据,提取并打印所有皮肤的名称和详情链接。此教程适用于初学者实践网络爬虫技能。
本文介绍了一种使用Python爬取英雄联盟(LOL)英雄皮肤信息的方法。通过访问特定URL,如剑魔(编号266)的皮肤列表页面,利用requests和json库解析数据,提取并打印所有皮肤的名称和详情链接。此教程适用于初学者实践网络爬虫技能。
代码
- 爬虫链接 https://blog.youkuaiyun.com/MarkAdc/article/details/99710763
- 以剑魔为例,剑魔编号id是266,那么就访问https://game.gtimg.cn/images/lol/act/img/js/hero/266.js
https://game.gtimg.cn/images/lol/act/img/js/hero/266.js
import requests
import json
def first_step(url):
response = requests.get(url)
json_dict = json.loads(response.text)
skin_list = json_dict["skins"]
for skin in skin_list:
name = skin["name"]
detail_url = skin["mainImg"]
print(name, detail_url)
if __name__ == '__main__':
url = "https://game.gtimg.cn/images/lol/act/img/js/hero/266.js"
first_step(url)
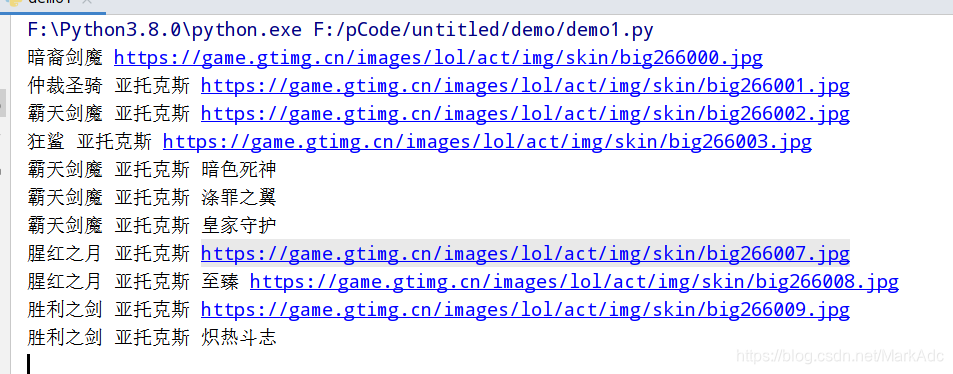
运行结果

















 2084
2084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









