



2024.11.05 周二
周二上午睡觉+上课 下午在玩原子之心+炒股(bushi) 晚上浅浅学习了一会…
还留了点时间去补作业(要加快学习进度啦,不然有种来不及找实习的感觉)
八股
浅拷贝与深拷贝
深拷贝和浅拷贝的区别?
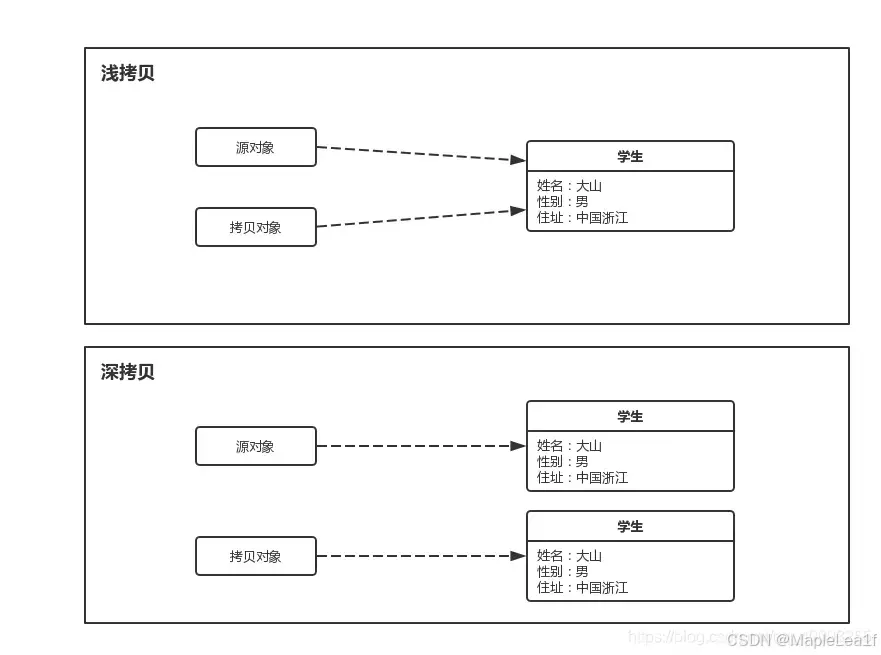
- 浅拷贝
- 浅拷贝是指只复制对象本身和其内部的值类型字段,但不会复制对象内部的引用类型字段。换句话说,浅拷贝只是创建一个新的对象,然后将原对象的字段值复制到新对象中,但如果原对象内部有引用类型的字段,只是将引用复制到新对象中,两个对象指向的是同一个引用对象。
- 深拷贝
- 深拷贝是指在复制对象的同时,将对象内部的所有引用类型字段的内容也复制一份,而不是共享引用。换句话说,深拷贝会递归复制对象内部所有引用类型的字段,生成一个全新的对象以及其内部的所有对象。
实现深拷贝的三种方法是什么?
实现 Cloneable 接口并重写 clone() 方法
// 定义MyClass类实现java.lang中的Cloneable接口
class MyClass implements Cloneable {
private String field1;
private NestedClass nestedObject;
// protected表示该方法可以被MyClass类及其子类访问
// 若对象不支持克隆,抛出该异常:CloneNotSupportedException
@Override
protected Object clone() throws CloneNotSupportedException {
// super.clone()指调用其父类Object类中定义的clone()方法,该方法执行的是浅复制
// 并将返回的对象强转成MyClass类型并赋值给cloned变量
MyClass cloned = (MyClass) super.clone();
// 调用NestedClass类的clone()方法,将返回的对象强转成NestedClass类并赋值给cloned内部的私有变量nestedObject中
cloned.nestedObject = (NestedClass) nestedObject.clone(); // 深拷贝内部的引用对象
return cloned;
}
}
class NestedClass implements Cloneable {
private int nestedField;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
使用序列化和反序列化
// 导入java.io包中的所有类
import java.io.*;
//定义MyClass类实现Serializable接口(该接口告诉JVM该类的对象可以被序列化)
class MyClass implements Serializable {
private String field1;
private NestedClass nestedObject;
public MyClass deepCopy() {
try {
// 创建一个ByteArrayOutputStream对象,它是一个字节数组输出流,用于存储序列化后的对象
ByteArrayOutputStream bos = new ByteArrayOutputStream();
// 创建一个ObjectOutputStream对象,它用于将对象写入ByteArrayOutputStream
ObjectOutputStream oos = new ObjectOutputStream(bos);
// 将当前MyClass对象(通过this引用)写入ObjectOutputStream,从而序列化该对象
oos.writeObject(this);
// 刷新ObjectOutputStream,确保所有缓冲的数据都被写入ByteArrayOutputStream中
oos.flush();
// 关闭ObjectOutputStream,释放与之相关的资源
oos.close();
// 创建一个ByteArrayInputStream对象,它是一个字节数组输入流,用于从ByteArrayOutputStream中读取序列化的对象数据
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
// 创建一个ObjectInputStream对象,用于从ByteArrayInputStream中读取对象
ObjectInputStream ois = new ObjectInputStream(bis);
// 从ObjectInputStream中调用readObject方法,将返回的Object对象强转成MyClass类并返回,到此深拷贝完成
return (MyClass) ois.readObject();
// 捕获序列化或反序列化时可能发生的IO异常和ClassNotFound异常
} catch (IOException | ClassNotFoundException e) {
// 打印异常的堆栈跟踪信息,以便于调试
e.printStackTrace();
// 若发生异常返回null
return null;
}
}
}
// 将NestedClass也实现Serializable接口,便于深拷贝时将其序列化的操作
class NestedClass implements Serializable {
private int nestedField;
}
手动递归复制
class MyClass {
private String field1;
private NestedClass nestedObject;
public MyClass deepCopy() {
MyClass copy = new MyClass();
copy.setField1(this.field1);
// copy中的nestedObject通过当前类中的nestedObject的deepcopy()赋值
copy.setNestedObject(this.nestedObject.deepCopy());
return copy;
}
}
class NestedClass {
private int nestedField;
// 当前被引用类中的deepCopy方法新建一个NestedClass类,手动完成赋值
public NestedClass deepCopy() {
NestedClass copy = new NestedClass();
copy.setNestedField(this.nestedField);
return copy;
}
}
抽象类和接口的区别是什么?
两者的特点:
- 抽象类用于描述类的共同特性和行为,可以有成员变量、构造方法和具体方法。适用于有明显继承关系的场景。
- 接口用于定义行为规范,可以多实现,只能有常量和抽象方法(Java 8 以后可以有默认方法和静态方法)。适用于定义类的能力或功能。
两者的区别:
- 实现方式:实现接口的关键字为
implements,继承抽象类的关键字为extends。一个类可以实现多个接口,但一个类只能继承一个抽象类。所以,使用接口可以间接地实现多重继承。 - 方法方式:接口只有定义,不能有方法的实现,java 1.8中可以定义
default方法体,而抽象类可以有定义与实现,方法可在抽象类中实现。
/**
default方法是在Java 8中引入的
它的目的是为了在不破坏现有代码的情况下,向接口中添加新方法。
在Java 8之前,接口中的方法都是抽象的,必须由实现类提供具体的实现。
引入default方法后,接口可以在不改变现有实现类的情况下添加新方法。
*/
public interface MyInterface {
// 抽象方法
void abstractMethod();
// 默认方法
default void defaultMethod() {
// 默认实现
System.out.println("这是默认方法的实现");
}
}
- 访问修饰符:接口成员变量默认为
public static final,必须赋初值,不能被修改;其所有的成员方法都是public、abstract的。抽象类中成员变量默认default,可在子类中被重新定义,也可被重新赋值;抽象方法被abstract修饰,不能被private、static、synchronized和native等修饰,必须以分号结尾,不带花括号。 - 变量:抽象类可以包含实例变量和静态变量,而接口只能包含常量(即静态常量)。
Cookie & Session & Token
Cookie和Session有什么区别?
Cookie和Session都是Web开发中用于跟踪用户状态的技术,但它们在存储位置、数据容量、安全性以及生命周期等方面存在显著差异:
- 存储位置:
Cookie的数据存储在客户端(通常是浏览器)。当浏览器向服务器发送请求时,会自动附带Cookie中的数据。Session的数据存储在服务器端。服务器为每个用户分配一个唯一的Session ID,这个ID通常通过Cookie或URL重写的方式发送给客户端,客户端后续的请求会带上这个Session ID,服务器根据ID查找对应的Session数据。
Cookie: ASP.NET_SessionId=ndwbt1jmspswjsnuosbmldlv
- 数据容量:单个Cookie的大小限制通常在4KB左右,而且大多数浏览器对每个域名的总Cookie数量也有限制。由于Session存储在服务器上,理论上不受数据大小的限制,主要受限于服务器的内存大小。
- 安全性:Cookie相对不安全,因为数据存储在客户端,容易受到XSS(跨站脚本攻击)的威胁。不过,可以通过设置
HttpOnly属性来防止JavaScript访问,减少跨站脚本(XSS)攻击的风险,但仍然可能受到CSRF(跨站请求伪造)的攻击。Session通常认为比Cookie更安全,因为敏感数据存储在服务器端。但仍然需要防范Session劫持(通过获取他人的Session ID)和会话固定攻击。
Set-Cookie: session_token=abc123; HttpOnly
- 生命周期:Cookie可以设置过期时间,过期后自动删除。也可以设置为会话Cookie,即浏览器关闭时自动删除。Session在默认情况下,当用户关闭浏览器时,Session结束。但服务器也可以设置Session的超时时间,超过这个时间未活动,Session也会失效。
- 性能:使用Cookie时,因为数据随每个请求发送到服务器,可能会影响网络传输效率,尤其是在Cookie数据较大时。使用Session时,因为数据存储在服务器端,每次请求都需要查询服务器上的Session数据,这可能会增加服务器的负载,特别是在高并发场景下。
token,session,cookie的关系
- session存储于服务器,可以理解为一个状态列表,拥有一个唯一识别符号sessionId,通常存放于cookie中。
服务器收到cookie后解析出sessionId,再去session列表中查找,才能找到相应session,依赖cookie。 - cookie类似一个令牌,
装有sessionId,存储在客户端,浏览器通常会自动添加。 - token也类似一个令牌,无状态,
用户信息都被加密到token中,服务器收到token后解密就可知道是哪个用户,需要开发者手动添加。
客户端禁用Cookie,如何绕过Session无法正常使用的问题?
默认情况下禁用 Cookie 后,Session 是无法正常使用的,因为大多数 Web 服务器都是依赖于 Cookie 来传递 Session 的会话 ID 的。
客户端浏览器禁用 Cookie 时,服务器将无法把会话 ID 发送给客户端,客户端也无法在后续请求中携带会话 ID 返回给服务器,从而导致服务器无法识别用户会话。
- URL重写:每当服务器响应需要保持状态的请求时,将Session ID附加到URL中作为参数。例如,原本的链接
http://example.com/page变为http://example.com/page;jsessionid=XXXXXX,服务器端需要相应地解析 URL 来获取 Session ID,并维护用户的会话状态。这种方式的缺点是URL变得不那么整洁,且如果用户通过电子邮件或其他方式分享了这样的链接,可能导致Session ID的意外泄露。 - 隐藏表单字段:在每个需要Session信息的HTML表单中包含一个隐藏字段,用来存储Session ID。当表单提交时,Session ID随表单数据一起发送回服务器,服务器通过解析表单数据中的 Session ID 来获取用户的会话状态。这种方法仅适用于通过表单提交的交互模式,不适合链接点击或Ajax请求。
<div class="aspNetHidden">
<input type="hidden" name="__VIEWSTATEGENERATOR" id="__VIEWSTATEGENERATOR" value="A3C0820E" />
<input type="hidden" name="__EVENTVALIDATION" id="__EVENTVALIDATION" value="/wEdAAQzAciB/QDW6zkymZaSNIWsHZ4wi8ny7Ddjn7Rp4o1bKeH0Iu/9fZc467JXyMTUE04rU8x5SglfzmEU2KqYFKCXUPtFZlhnqU6SzCMo4bcRBiEMcQ00d/JzNIc16qX0s38=" />
</div>
什么是LocalStorage?Cookie和Storage的区别是什么?
浏览器的 localStorage 是一种 Web Storage API,它允许网页在用户的浏览器中保存键值对,并在同一域名下的所有页面之间共享这些数据。localStorage 的数据是持久化的,即使浏览器关闭后,数据仍然会被保留,直到被显式删除。
- 存储容量: Cookie 的存储容量通常较小,每个 Cookie 的大小限制在几 KB 左右。
而 LocalStorage 的存储容量通常较大,一般限制在几 MB 左右。因此,如果需要存储大量数据,LocalStorage 通常更适合; - 数据发送:
Cookie 在每次 HTTP 请求中都会自动发送到服务器,这使得 Cookie 适合用于在客户端和服务器之间传递数据。而 localStorage 的数据不会自动发送到服务器,它仅在浏览器端存储数据,因此 LocalStorage 适合用于在同一域名下的不同页面之间共享数据;
// 保存数据到 localStorage
localStorage.setItem('key', 'value');
// 从 localStorage 获取数据
var value = localStorage.getItem('key');
- 生命周期:Cookie 可以设置一个过期时间,使得数据在指定时间后自动过期。
而 LocalStorage 的数据将永久存储在浏览器中,除非通过 JavaScript 代码手动删除; - 安全性:Cookie 的安全性较低,因为 Cookie 在每次 HTTP 请求中都会自动发送到服务器,存在被窃取或篡改的风险。
而 LocalStorage 的数据仅在浏览器端存储,不会自动发送到服务器,相对而言更安全一些;
因此 Cookie 适合用于在客户端和服务器之间传递数据、跨域访问和设置过期时间,而 LocalStorage 适合用于在同一域名下的不同页面之间****共享数据、存储大量数据和永久存储数据。
算法
102.二叉树的层序遍历(队列+单变量控制长度)
215.数组中的第k个最大元素(堆排序)
// 队列的实现方法通常是Queue(队列)下的LinkedList
Queue<TreeNode> queue = new LinkedList<TreeNode>();
// 队列的实现方法通常是Deque(双端队列)下的LinkedList
Deque<TreeNode> stack = new LinkedList<TreeNode>();
堆是什么?
堆是一颗完全二叉树,这样实现的堆也被称为二叉堆。堆中节点的值都大于等于(或小于等于)其子节点的值,堆中如果节点的值都大于等于其子节点的值,我们把它称为大顶堆,如果都小于等于其子节点的值,我们将其称为小顶堆。
完全二叉树是一种特殊的二叉树,它具有以下性质:
- 除了最后一层外,每一层的节点数都是满的。
- 最后一层的节点从左到右紧密排列,没有空缺。
下图中,1,2 是大顶堆,3 是小顶堆, 4 不是堆(不是完全二叉树)
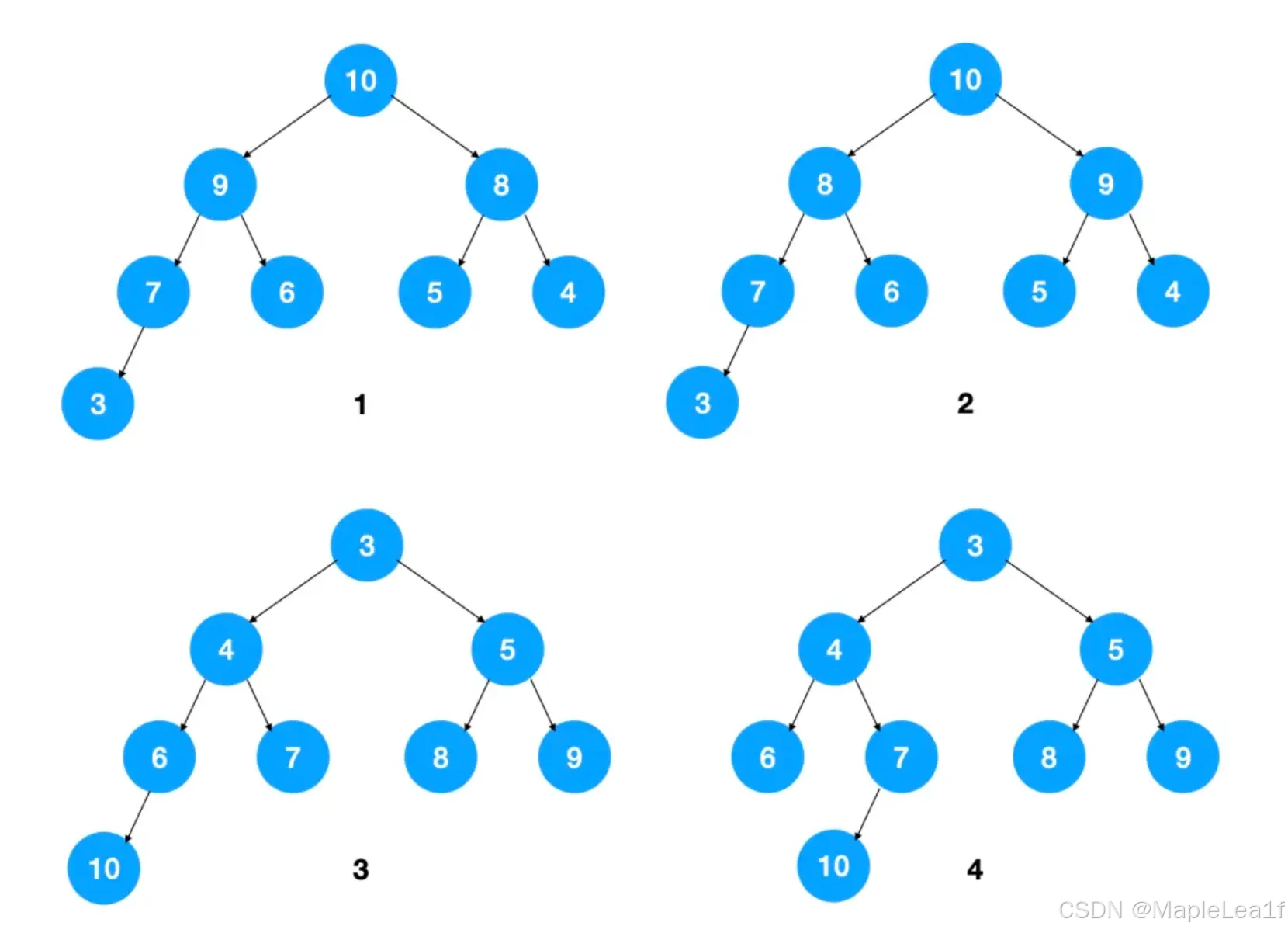
堆排序
(以 215.数组中的第k个最大元素为例)
class Solution {
public int findKthLargest(int[] nums, int k) {
int heapSize = nums.length;
// 将数组转换成一个最大堆
buildMaxHeap(nums, heapSize);
/**
从数组的末尾开始,将最大的元素(堆顶元素)与当前索引的元素交换
然后减少堆的大小,并对新的堆顶元素进行maxHeapify操作
直到找到第k大的元素
*/
for (int i = nums.length - 1; i >= nums.length - k + 1; --i){
swap(nums, 0, i);
--heapSize;
maxHeapify(nums, 0, heapSize);
}
// 返回堆顶元素
return nums[0];
}
public void buildMaxHeap(int[] a, int heapSize){
/**
自底向上建堆法
从最后一个非叶子节点开始,向前遍历到根节点
对每个节点调用maxHeapify方法,确保每个子树都是一个最大堆
*/
for (int i = heapSize / 2 - 1; i >= 0; --i){
maxHeapify(a, i, heapSize);
}
}
public void maxHeapify(int[] a, int i, int heapSize){
/**
根据二叉堆层序遍历的性质,当前节点编号(索引)为i(编号从0开始)
则左子节点为2i + 1,其右子节点为2i + 2
*/
int l = i * 2 + 1, r = i * 2 + 2, largest = i;
// 当其左子节点仍在数组中 且 左子节点的值大于当前值时,将largest指向左子节点
if (l < heapSize && a[l] > a[largest]){
largest = l;
}
// 同左子节点
if (r < heapSize && a[r] > a[largest]){
largest = r;
}
/**
当前节点不是目前最大的节点时,将该节点和目前最大的节点交换位置
且将交换后的最大节点作为下一次建堆过程的当前节点
*/
if (largest != i){
swap(a, i, largest);
maxHeapify(a, largest, heapSize);
}
}
/**
交换两个节点的值
*/
public void swap(int[] a, int i, int j){
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
项目
前端发送的请求,是如何请求到后端服务的?
- 1). nginx反向代理
- nginx 反向代理,就是将前端发送的动态请求由 nginx 转发到后端服务器
'''
监听80端口号
当我们访问 http://localhost:80/api/../..这样的接口的时候
它会通过 location /api/ {} 这样的形式
反向代理到 http://localhost:8080/admin/上来。
'''
server{
listen 80; #监听80端口号
server_name localhost;
location /api/{
proxy_pass http://localhost:8080/admin/; #反向代理(设置代理服务器的地址)
}
}
- 2). nginx 负载均衡
- 当如果服务以集群的方式进行部署时,那nginx在转发请求到服务器时就需要做相应的负载均衡。其实,负载均衡从本质上来说也是基于反向代理来实现的,最终都是转发请求。
'''
监听80端口号
当我们访问 http://localhost:80/api/../..这样的接口的时候
它会通过 location /api/ {} 这样的形式
反向代理到 http://webservers/admin
根据webservers名称找到一组服务器
根据设置的负载均衡策略(默认是轮询)转发到具体的服务器
'''
// 使用upstream指令配置后端服务器组
upstream webservers{
server 192.168.100.128:8080;
server 192.168.100.129:8080;
}
server{
listen 80;
server_name localhost;
location /api/{
proxy_pass http://webservers/admin;#负载均衡
}
}
负载均衡有哪些策略 / 算法?
| 名称 | 说明 |
|---|---|
| 轮询 | 默认方式 |
| weight | 权重方式,默认为1,权重越高,被分配的客户端请求就越多 |
| ip_hash | 依据ip分配方式,这样每个访客可以固定访问一个后端服务 |
| least_conn | 依据最少连接方式,把请求优先分配给连接数少的后端服务 |
| url_hash | 依据url分配方式,这样相同的url会被分配到同一个后端服务 |
| fair | 依据响应时间方式,响应时间短的服务将会被优先分配 |
- 简单轮询(默认方式):将请求按顺序分发给后端服务器上,不关心服务器当前的状态,比如后端服务器的性能、当前的负载。
- 加权轮询(
weight):根据服务器自身的性能给服务器设置不同的权重,将请求按顺序和权重分发给后端服务器,可以让性能高的机器处理更多的请求 - 简单随机(
random):将请求随机分发给后端服务器上,请求越多,各个服务器接收到的请求越平均 - 加权随机(
weight+random):根据服务器自身的性能给服务器设置不同的权重,将请求按各个服务器的权重随机分发给后端服务器,在后面添加random指定负载均衡算法 - 一致性哈希(
ip_hash<=>hash &request_uri):根据请求的客户端 ip、或请求参数通过哈希算法得到一个数值,利用该数值取模映射出对应的后端服务器,这样能保证同一个客户端或相同参数的请求每次都使用同一台服务器 - 最小活跃数(
least_conn):统计每台服务器上当前正在处理的请求数,也就是请求活跃数,将请求分发给活跃数最少的后台服务器
# 轮询
upstream webservers{
server 192.168.100.128:8080;
server 192.168.100.129:8080;
}
# weight
upstream webservers{
server 192.168.100.128:8080 weight=90;
server 192.168.100.129:8080 weight=10;
}
# ip_hash
upstream webservers{
ip_hash;
server 192.168.100.128:8080;
server 192.168.100.129:8080;
}
# least_conn
upstream webservers{
least_conn;
server 192.168.100.128:8080;
server 192.168.100.129:8080;
}
# url_hash
upstream webservers{
hash &request_uri;
server 192.168.100.128:8080;
server 192.168.100.129:8080;
}
# fair
upstream webservers{
server 192.168.100.128:8080;
server 192.168.100.129:8080;
fair;
}

















 2651
2651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









