



 本文介绍了OpenMP,一种用于共享内存并行系统的多线程编程方案,适用于C、C++和Fortran。文章详细讲解了如何使用OpenMP的pragma指令,包括获取线程数、并行处理for循环、解决线程竞争问题以及数据环境类导语,旨在简化多核CPU上的并行编程,提高程序执行效率。
本文介绍了OpenMP,一种用于共享内存并行系统的多线程编程方案,适用于C、C++和Fortran。文章详细讲解了如何使用OpenMP的pragma指令,包括获取线程数、并行处理for循环、解决线程竞争问题以及数据环境类导语,旨在简化多核CPU上的并行编程,提高程序执行效率。
一、什么是OpenMP
OpenMP是⼀种⽤于共享内存并⾏系统的多线程程序设计⽅案,⽀持的编程语⾔包括C、C++和Fortran。OpenMP提供了对并⾏算法的⾼层抽象描述,特别适合在多核CPU机器上的并⾏程序设计。编译器根据程序中添加的pragma指令,⾃动将程序并⾏处理,使⽤OpenMP降低了并⾏编程的难度和复杂度。当编译器不⽀持OpenMP时,程序会退化成普通(串⾏)程序。程序中已有的OpenMP指令不会影响程序的正常编译运⾏。
二、OpenMP的使用
1、获取本机的线程数
代码
#include<omp.h>
#include<iostream>
int main()
{
std::cout << "parallel begin:\n";
#pragma omp parallel
{
std::cout << omp_get_thread_num() << std::endl;
}
std::cout << "\n parallel end.\n";
std::cin.get();
return 0;
}
结果:

说明本机是16线程
2、基本的编译导语
#pragma omp parallel
omp中使用parallel制导指令标识代码中的并行段
如上个例子中的指令#pragma omp parallel,因此打印输出并行执行。
#pragma omp parallel
{
//线程并行执行的代码
}
parallel表示其后语句将被多个线程并行执行,“#pragma omp parallel”后面的语句(或者,语句块)被称为parallel region。多个线程的执行顺序是不能保证的。
#pragma omp parallel for
对for循环进行并行处理,每个核之间是并行执行,各线程顺序不能保证
- 不加openmp指令运行,耗时1.97s
#include <iostream>
#include <time.h>
void test()
{
int a = 0;
for (int i=0;i<100000000;i++)
a++;
}
int main()
{
clock_t t1 = clock();
for (int i=0;i<8;i++)
test();
clock_t t2 = clock();
std::cout<<"time: "<<t2-t1<<std::endl;
}
- 加openmp指令
#include <iostream>
#include <time.h>
void test()
{
int a = 0;
for (int i=0;i<100000000;i++)
a++;
}
int main()
{
clock_t t1 = clock();
#pragma omp parallel for
for (int i=0;i<8;i++)
test();
clock_t t2 = clock();
std::cout<<"time: "<<t2-t1<<std::endl;
}
#pragma omp parallel for num_threads(4)
指定使用线程数为4
3、解决线程竞争引入的编译导语
当多个线程并行执行时,有可能多个线程同时对某变量进行了读写操作,从而导致不可预知的结果。比如下面的例子,对于包含10个整形元素的数组a,我们用for循环求它各个元素之和,并将结果保存在变量sum里。
#include <iostream>
int main()
{
int sum = 0;
int a[10] = {1,2,3,4,5,6,7,8,9,10};
#pragma omp parallel for
for (int i=0;i<10;i++)
sum = sum + a[i];
std::cout<<"sum: "<<sum<<std::endl;
return 0;
}
如果我们注释掉#pragma omp parallel for,让程序先按照传统串行的方式执行,很明显,sum=55。但按照并行方式执行后,sum则会变成其他值,比如在某次运行过程中,sum=49。其原因是,当某线程A执行sum = sum + a[i]的同时,另一线程B正好在更新sum,而此时A还在用旧的sum做累加,于是出现了错误。
基本解决方案
生成一个数组sumArray,其长度为并行执行的线程的个数(默认情况下,该个数等于CPU的核数),在for循环里,让各个线程更新自己线程对应的sumArray里的元素累加到sum里
代码
#include <iostream>
#include <omp.h>
int main(){
int sum = 0;
int a[10] = {1,2,3,4,5,6,7,8,9,10};
int coreNum = omp_get_num_procs();//获得处理器个数
int* sumArray = new int[coreNum];//对应处理器个数,先生成一个数组
for (int i=0;i<coreNum;i++)//将数组各元素初始化为0
sumArray[i] = 0;
#pragma omp parallel for
for (int i=0;i<10;i++)
{
int k = omp_get_thread_num();//获得每个线程的ID
sumArray[k] = sumArray[k]+a[i];
}
for (int i = 0;i<coreNum;i++)
sum = sum + sumArray[i];
std::cout<<"sum: "<<sum<<std::endl;
return 0;
}
用omp_get_num_procs()函数来获取处理器个数,用omp_get_thread_num()函数来获得每个线程的ID,为了使用这两个函数,我们需要include<omp.h>
存在的问题:
上面的代码虽然达到了目的,但是它产生了较多的额外操作。OpenMP提供了以下的方法解决线程竞争冒险。
#pragma omp parallel for reduction(+:sum)
在#pragma omp parallel for后面加上了reduction(+:sum),它的意思是告诉编译器:下面的for循环你要分成多个线程跑,但每个线程都要保存变量sum的拷贝,循环结束后,所有线程把自己的sum累加起来作为最后的输出。
#include <iostream>
int main(){
int sum = 0;
int a[10] = {1,2,3,4,5,6,7,8,9,10};
#pragma omp parallel for reduction(+:sum)
for (int i=0;i<10;i++)
sum = sum + a[i];
std::cout<<"sum: "<<sum<<std::endl;
return 0;
}
存在的问题:
reduction虽然很方便,但它只支持一些基本操作,比如+,-,*,&,|,&&,||等。
#pragma omp critical
实例:求数组a的最大值,将结果保存在max里。
for循环还是被自动分成N份来并行执行,用#pragma omp critical将if(temp > max) max = temp 括了起来,它的意思是:各个线程还是并行执行for里面的语句,但当你们执行到critical里面时,要注意有没有其他线程正在里面执行,如果有的话,要等其他线程执行完再进去执行。这样就避免了race condition问题,但显而易见,它的执行速度会变低,因为可能存在线程等待情况。
#include <iostream>
int main(){
int max = 0;
int a[10] = {11,2,33,49,113,20,321,250,689,16};
#pragma omp parallel for
for (int i=0;i<10;i++)
{
int temp = a[i];
#pragma omp critical
{
if (temp > max)
max = temp;
}
}
std::cout<<"max: "<<max<<std::endl;
return 0;
}
#pragma omp atomic
与critical类似,但比critical效率高
只支持x++ , x–, --x, ++x
x ( + - * / & | << >> ) = expr
#include <iostream>
#include <omp.h> // OpenMP编程需要包含的头文件
int main()
{
int sum = 0;
std::cout << "Before: " << sum << std::endl;
#pragma omp parallel for
for (int i = 0; i < 20000; ++i)
{
#pragma omp atomic
sum++;
}
std::cout << "After: " << sum << std::endl;
return 0;
}
pragma omp single
用在一段只被单个线程执行的代码段之前,表示后面的代码段将被单线程执行。
代码
 结果
结果
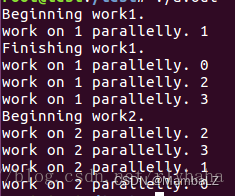
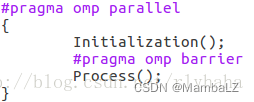
#pragma omp barrier
事件同步,各线程执行顺序是不同的,在并行结束的位置加barrier,可以在此位置让各线程同步
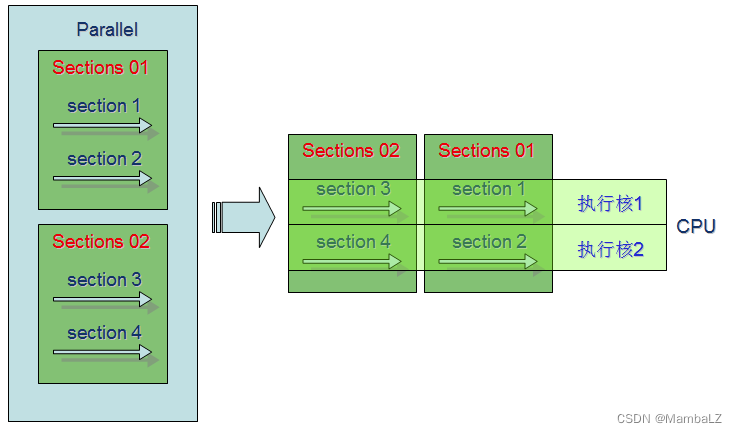
#pragma omp section
采用section定义的每段程序都将只执行一次,sections中的每段section将并行执行。一个程序中可以定义多个sections,每个sections中又可以定义多个section。同一个sections中section之间处于并行状态。sections与其他sections之间处于串行状态。
#include<omp.h>
#include<iostream>
using namespace std;
void SectionsTest()
{
int i;
#pragma omp parallel num_threads(4)
{
#pragma omp sections //第1个sections
{
#pragma omp section
{
cout<<"section 1 线程ID:"<<omp_get_thread_num()<<"\n";
}
#pragma omp section
{
cout<<"section 2 线程ID:"<<omp_get_thread_num()<<"\n";
}
}
#pragma omp sections //第2个sections
{
#pragma omp section
{
cout<<"section 3 线程ID:"<<omp_get_thread_num()<<"\n";
}
#pragma omp section
{
cout<<"section 4 线程ID:"<<omp_get_thread_num()<<"\n";
}
}
}
}
运行程序,其结果有:
section 1 线程ID:0
section 2 线程ID:1
section 3 线程ID:3
section 4 线程ID:1
section1 与section2并行, section3与section4并行
这两个section又串行
task
参考:https://blog.youkuaiyun.com/gengshenghong/article/details/7004594
task主要适用于不规则的循环迭代和递归的函数调用。都是无法使用for来完成的情况。
#include <omp.h>
void task(int p)
{
printf("task, Thread ID: %d, task: %d\n", omp_get_thread_num(), p);
}
#define N 50
void init(int*a)
{
for(int i = 0;i < N;i++)
a[i] = i + 1;
}
int main(int argc, _TCHAR* argv[])
{
int a[N];
init(a);
#pragma omp parallel num_threads(2)
{
#pragma omp single
{
for(int i = 0;i < N; i=i+a[i]) //i递增没有规律
{
#pragma omp task
task(a[i]);
}
}
}
return 0;
}
用single表示只有一个线程会执行下面的代码,表示一开始程序单线程执行,遇到task之后动态的派发线程。OpenMP遇到了task之后,就会使用当前的线程或者延迟一会后接下来的线程来执行task定义的任务。task的作用,就是定义了一个显式的任务。
task和前面的for和sections的区别在于:
for/section 静态 task 动态
task是“动态”定义任务的,在运行过程中,只需要使用task就会定义一个任务,任务就会在一个线程上去执行,那么其它的任务就可以并行的执行。可能某一个任务执行了一半的时候,或者甚至要执行完的时候,程序可以去创建第二个任务,任务在一个线程上去执行,一个动态的过程,不像sections和for那样,在运行之前,已经可以判断出可以如何去分配任务。而且,task是可以进行嵌套定义的,可以用于递归的情况等等。
4、数据环境类导语
OpenMP的数据处理子句包括private、firstprivate、lastprivate、shared、default、reduction copyin和copyprivate。它与编译制导指令parallel,for和sections相结合,用来控制变量的作用范围。
share
没有采取保护会有数据竞争
shared子句声明的变量将在所有线程之间共享,所有线程都可以对同一个内存位置进行读写操作,程序员需确保多个线程正确地访问共享变量(通过critical等指令)

没有保护,因此两次运行结果不一样
private
private(list)每个线程都有它自己的私有变量副本,从申明的并行区域开始,为每个线程声明一个相同类型的新对象,对原始对象的所有引用都将替换为对新对象的引用,对于每个线程,声明为私有的变量未初始化
int i = 0;
float a = 512.3;
#pragma omp parallel private(i,a)
{
i = i + 1;
printf("thread %d i = %d a= %f\n", omp_get_thread_num(), i, a);
}
printf("out of parallel i = %d", i);
}
运行结果如下,每个线程都有一个独立的i变量,互不影响,同时也不影响原始的i。
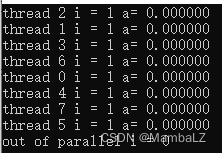
firstprivate
firstprivate子句指定的变量不仅是private作用范围,同时在进入并行区域构造前根据其原始对象的值初始化
示例代码如下
int i = 1;
float a = 512.3;
#pragma omp parallel firstprivate(i) private(a)
{
i = i + 1;
printf("thread %d i = %d a= %f\n", omp_get_thread_num(), i, a);
}
printf("out of parallel i = %d", i);
运行结果如下,每个线程都有一个独立的i变量,且进入并行区域时每个线程的i都被初始化原始值1。
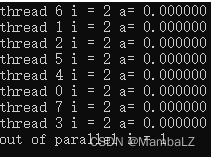
lastprivate
lastprivate子句指定的变量不仅是private作用范围,同时会将最后一次迭代或最后一个section执行的值复制回原来的变量
int i = 0;
float a = 512.3;
#pragma omp parallel
{
#pragma omp sections lastprivate(i) private(a)
{
#pragma omp section
{
i = i + omp_get_thread_num();
printf("thread %d i = %d a= %f\n", omp_get_thread_num(), i, a);
}
#pragma omp section
{
i = i + omp_get_thread_num();
printf("thread %d i = %d a= %f\n", omp_get_thread_num(), i, a);
}
}
}
printf("out of parallel i = %d", i);
运行结果如下,每个线程都有一个独立的i变量,且退出并行区域时原始的i变量被设置成其中一个section线程的相应变量值。
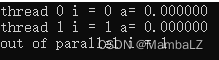
参考:
https://blog.youkuaiyun.com/laobai1015/article/details/79020128?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162843230216780265414989%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=162843230216780265414989&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-1-79020128.first_rank_v2_pc_rank_v29&utm_term=openMP%E9%85%8D%E7%BD%AE&spm=1018.2226.3001.4187
https://zhuanlan.zhihu.com/p/61857547
https://blog.youkuaiyun.com/augusdi/article/details/8808158#
https://blog.youkuaiyun.com/u014357799/article/details/79387357
https://blog.youkuaiyun.com/rlyhaha/article/details/79420233

















 6042
6042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









