







论文介绍
题目:
OMNI-SCALE CNNS: A SIMPLE AND EFFECTIVE KER
NEL SIZE CONFIGURATION FOR TIME SERIES CLASSIFI
CATION
论文地址:
链接: https://arxiv.org/pdf/2002.10061
创新点
1. 提出 Omni-Scale Block (OS-block)
- 背景问题:在时间序列分类任务中,一维卷积神经网络(1D-CNN)的接收场(Receptive Field, RF)大小对性能有重要影响。然而,不同的数据集需要不同的最佳接收场大小,且目前没有通用的最佳接收场大小。因此,寻找合适的接收场大小通常需要大量的搜索工作,这既耗时又计算成本高昂。
- 创新点:文章提出了一种名为 Omni-Scale Block(OS-block)的新型 1D-CNN 模块。该模块通过一种简单且通用的规则自动选择核大小,能够高效地覆盖不同数据集的最佳接收场大小,从而避免了复杂的搜索过程。
2. 基于素数的核大小设计
- 设计灵感:OS-block 的设计灵感来源于哥德巴赫猜想,即任何正偶数都可以表示为两个素数之和。因此,OS-block 使用一组素数作为核大小,通过不同组合的素数核大小来覆盖所有可能的接收场大小。
- 具体实现:OS-block 包含三层多核结构,前两层使用素数大小的卷积核(如 1, 2, 3, 5, 7 等),最后一层使用大小为 1 和 2 的核。这种设计能够覆盖所有整数范围内的接收场大小,同时保持模型的高效性。
3. 高效覆盖所有接收场大小
- 性能优势:实验表明,OS-block 能够在多个时间序列分类基准数据集上实现与最优接收场大小相当的性能,且无需进行复杂的搜索。此外,由于其基于素数的设计,OS-block 在模型大小和计算效率方面优于其他方法(如使用偶数或奇数核大小的设计)。
- 理论优势:从模型复杂度角度看,使用素数核大小的 OS-block 的模型大小复杂度为 O(r²/log®),而其他方法(如偶数或奇数对)的复杂度为 O(r²),这使得 OS-block 在处理长序列数据时更具优势。
4. 广泛的实验验证
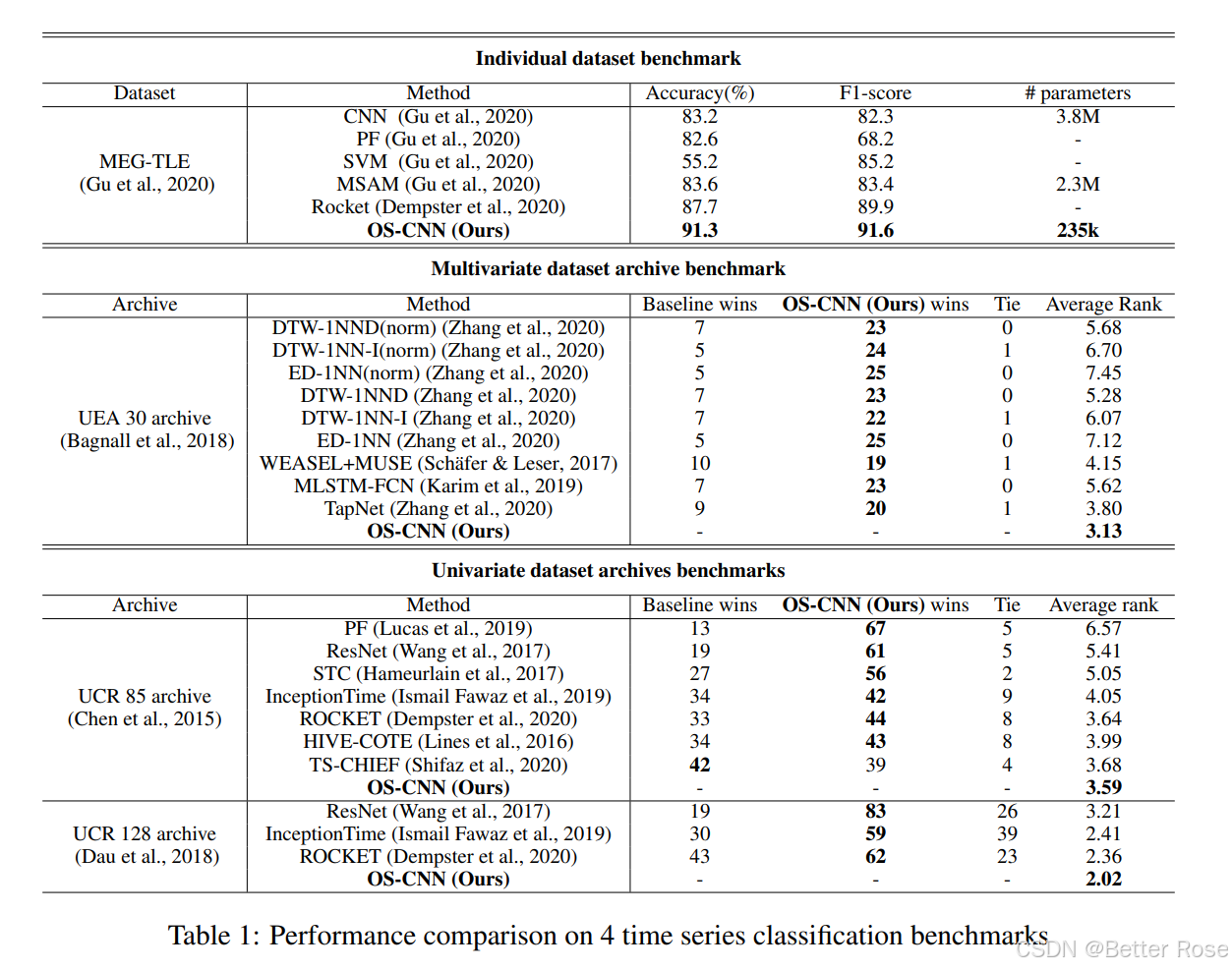
- 基准测试:文章在四个时间序列分类基准(包括 MEG-TLE 数据集、UEA 30 多变量数据集、UCR 85 数据集和 UCR 128 数据集)上验证了 OS-block 的性能。这些数据集涵盖了医疗、活动识别、语音识别等多个领域,结果表明 OS-block 在所有基准测试中均达到了最先进的性能。
- 鲁棒性:OS-block 在不同数据集上表现一致,即使在动态模式变化较大的数据集上也能保持高性能。此外,文章还通过对比实验验证了 OS-block 在捕捉最佳时间尺度方面的能力。
5. 灵活性和扩展性
- 结构扩展:OS-block 的多核层可以与现有的复杂结构(如残差连接、注意力机制、Transformer 等)结合,进一步提升性能。文章还展示了如何将 OS-block 应用于多变量时间序列数据的分类任务,以及如何通过集成学习进一步提升性能。
通用性:OS-block 的设计不仅适用于时间序列分类任务,还可以扩展到其他需要处理时间尺度问题的领域,如视频分类等。
方法
模型总体架构
这篇论文提出的模型是 OS-CNN,核心组件为 OS-block,通过多层基于素数设计的卷积核,高效覆盖所有可能的感受野大小,从而提取多尺度特征。模型整体结构包括输入层、多个 OS-block、全局平均池化层和全连接层,用于降维和分类。此外,OS-block 可以与其他深度学习结构(如残差连接、Transformer 等)结合,具有很强的灵活性和扩展性,在时间序列分类任务中表现出卓越性能。
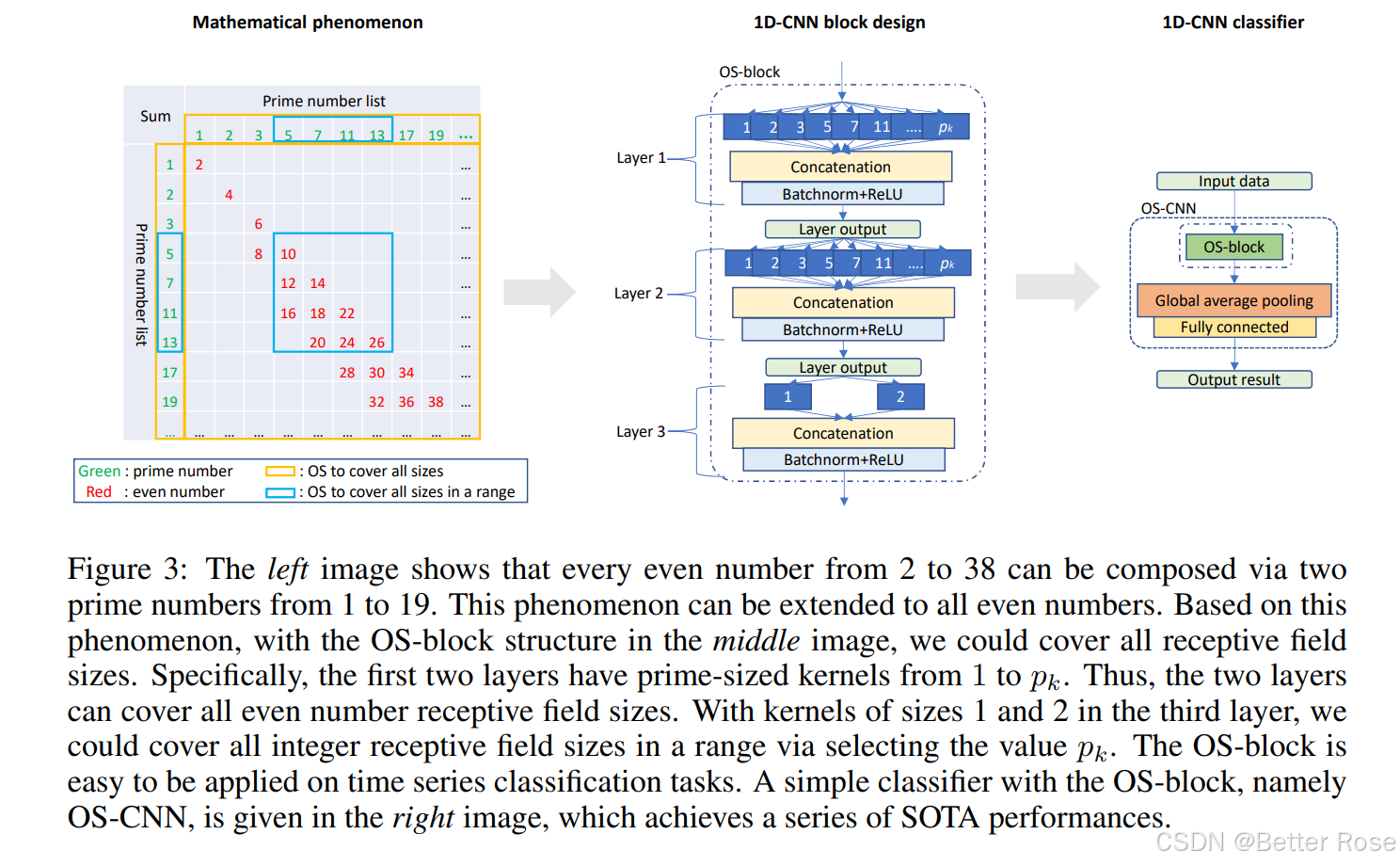
核心模块
1. Omni-Scale Block (OS-block)
OS-block 是 OS-CNN 的核心模块,其设计灵感来源于 哥德巴赫猜想,即任何正偶数都可以表示为两个素数之和。OS-block 使用一组素数作为卷积核大小,通过不同组合的素数核来覆盖所有可能的接收场大小。
结构设计:
- 三层多核结构:OS-block 包含三层卷积层,每层使用多个不同大小的卷积核。
- 第一层和第二层:使用素数大小的卷积核(如 1, 2, 3, 5, 7 等)。
- 第三层:使用大小为 1 和 2 的卷积核。
- 输出:每层的卷积结果通过 Concatenation(拼接)合并,然后经过 Batch
- Normalization + ReLU 激活。
接收场覆盖:
- 通过前两层的素数核组合,可以覆盖所有偶数大小的接收场。
- 第三层的核大小 1 和 2 用于覆盖所有奇数大小的接收场。
- 因此,OS-block 能够覆盖从 1 到时间序列长度的所有整数接收场大小。
2. OS-CNN 架构
OS-CNN 是基于 OS-block 的完整时间序列分类模型,其结构如下:
- 输入层:
- 接收时间序列数据,支持单变量和多变量时间序列。
- 输入通道数根据时间序列的变量数调整。
- OS-block:
- 包含一个或多个 OS-block,用于提取多尺度特征。
- 每个 OS-block 的输出通过 Concatenation 合并。
- 全局平均池化层:
- 用于降维,将特征图压缩为固定大小的特征向量。
- 全连接层:
- 用于分类,输出类别概率。
- 输出层:
- 输出分类结果。
模型迁移
OS-block 具有很强的扩展性,可以与其他深度学习结构结合,例如:
- 残差连接:增强模型的训练稳定性。
- 集成学习:通过多个 OS-block 的投票提升性能。
- 多通道架构:针对多变量时间序列数据,为每个变量分别应用 OS-block。
消融实验
在多个基准数据集上的性能对比,包括 MEG-TLE、UEA 30、UCR 85 和 UCR 128 数据集。
- OS-CNN 在多个数据集中表现优于其他方法,并且模型参数量显著减少。
- 结果表明,OS-block 的设计不仅提高了分类准确率,还降低了模型复杂度。
核心代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import numpy as np
def calculate_mask_index(kernel_length_now, largest_kernel_lenght):
right_zero_mast_length = math.ceil((largest_kernel_lenght - 1) / 2) - math.ceil((kernel_length_now - 1) / 2)
left_zero_mask_length = largest_kernel_lenght - kernel_length_now - right_zero_mast_length
return left_zero_mask_length, left_zero_mask_length + kernel_length_now
def creat_mask(number_of_input_channel, number_of_output_channel, kernel_length_now, largest_kernel_lenght):
ind_left, ind_right = calculate_mask_index(kernel_length_now, largest_kernel_lenght)
mask = np.ones((number_of_input_channel, number_of_output_channel, largest_kernel_lenght))
mask[:, :, 0:ind_left] = 0
mask[:, :, ind_right:] = 0
return mask
def creak_layer_mask(layer_parameter_list):
largest_kernel_lenght = layer_parameter_list[-1][-1]
mask_list = []
init_weight_list = []
bias_list = []
for i in layer_parameter_list:
conv = torch.nn.Conv1d(in_channels=i[0], out_channels=i[1], kernel_size=i[2])
ind_l, ind_r = calculate_mask_index(i[2], largest_kernel_lenght)
big_weight = np.zeros((i[1], i[0], largest_kernel_lenght))
big_weight[:, :, ind_l:ind_r] = conv.weight.detach().numpy()
bias_list.append(conv.bias.detach().numpy())
init_weight_list.append(big_weight)
mask = creat_mask(i[1], i[0], i[2], largest_kernel_lenght)
mask_list.append(mask)
mask = np.concatenate(mask_list, axis=0)
init_weight = np.concatenate(init_weight_list, axis=0)
init_bias = np.concatenate(bias_list, axis=0)
return mask.astype(np.float32), init_weight.astype(np.float32), init_bias.astype(np.float32)
class build_layer_with_layer_parameter(nn.Module):
def __init__(self, layer_parameters, relu_or_not_at_last_layer=True):
super(build_layer_with_layer_parameter, self).__init__()
self.relu_or_not_at_last_layer = relu_or_not_at_last_layer
os_mask, init_weight, init_bias = creak_layer_mask(layer_parameters)
in_channels = os_mask.shape[1]
out_channels = os_mask.shape[0]
max_kernel_size = os_mask.shape[-1]
self.weight_mask = nn.Parameter(torch.from_numpy(os_mask), requires_grad=False)
self.padding = nn.ConstantPad1d((int((max_kernel_size - 1) / 2), int(max_kernel_size / 2)), 0)
self.conv1d = torch.nn.Conv1d(in_channels=in_channels, out_channels=out_channels, kernel_size=max_kernel_size)
self.conv1d.weight = nn.Parameter(torch.from_numpy(init_weight), requires_grad=True)
self.conv1d.bias = nn.Parameter(torch.from_numpy(init_bias), requires_grad=True)
self.bn = nn.BatchNorm1d(num_features=out_channels)
def forward(self, X):
self.conv1d.weight.data = self.conv1d.weight * self.weight_mask
# self.conv1d.weight.data.mul_(self.weight_mask)
result_1 = self.padding(X)
result_2 = self.conv1d(result_1)
result_3 = self.bn(result_2)
if self.relu_or_not_at_last_layer:
result = F.relu(result_3)
return result
else:
return result_3
class OS_block(nn.Module):
def __init__(self, layer_parameter_list, relu_or_not_at_last_layer=True):
super(OS_block, self).__init__()
self.layer_parameter_list = layer_parameter_list
self.layer_list = []
self.relu_or_not_at_last_layer = relu_or_not_at_last_layer
for i in range(len(layer_parameter_list)):
if i != len(layer_parameter_list) - 1:
using_relu = True
else:
using_relu = self.relu_or_not_at_last_layer
layer = build_layer_with_layer_parameter(layer_parameter_list[i], using_relu)
self.layer_list.append(layer)
self.net = nn.Sequential(*self.layer_list)
def forward(self, X):
X = self.net(X)
return X
if __name__ == '__main__':
layer_parameter_list = [
[(16, 32, 3)],
[(32, 16, 5)],
[(16, 16, 7)]
]
input = torch.rand(10, 16, 100)
block = OS_block(layer_parameter_list=layer_parameter_list, relu_or_not_at_last_layer=True)
output = block(input)
print(input.size()) print(output.size())

















 717
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









