




 本文介绍了 Teradata 数据库的基础概念,包括并行处理、线性扩展性和四种主要的索引类型:唯一主索引 (UPI)、非唯一主索引 (NUPI)、多列主索引以及无主索引表。同时探讨了这些索引如何影响数据分布及查询效率。
本文介绍了 Teradata 数据库的基础概念,包括并行处理、线性扩展性和四种主要的索引类型:唯一主索引 (UPI)、非唯一主索引 (NUPI)、多列主索引以及无主索引表。同时探讨了这些索引如何影响数据分布及查询效率。
TeraData Basics
持续更新中。。
插图画得很辛苦
1. Basic concept
1.1 Parallel Processing
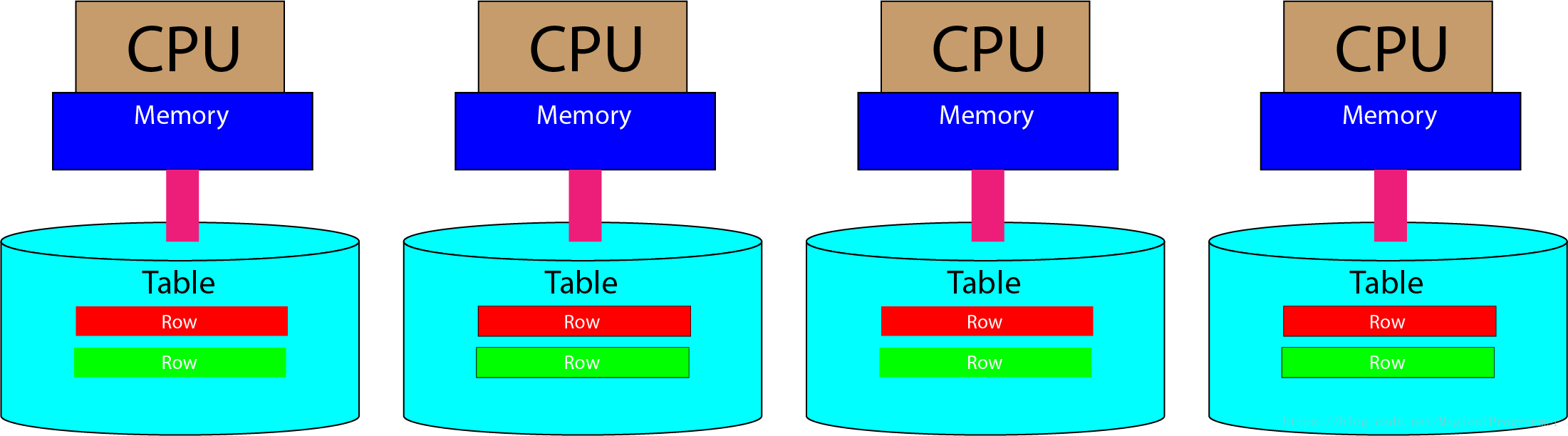
AMP(Access Module Processor)
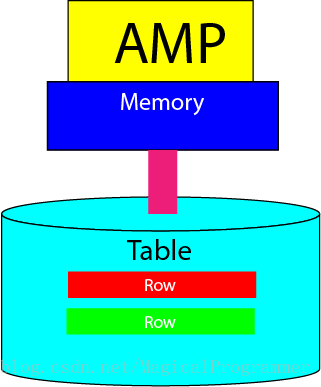
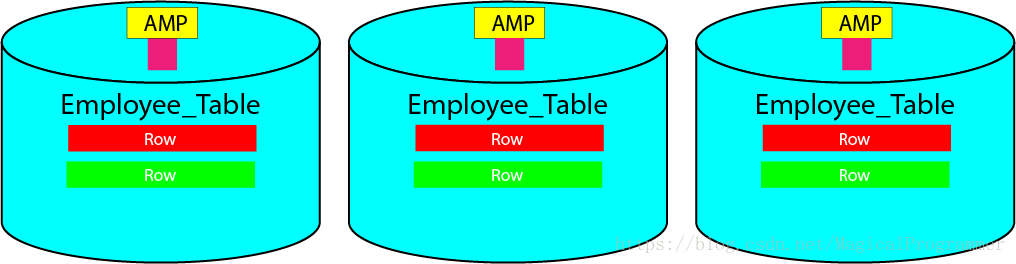
1.2 Linear Scalability
All Teradata tables are spread across ALL AMPs
3. Four Different Primary Indexes
3.1 UPI
CREATE TABLE Employee_Table
( Employee_No INTEGER
,Last_Name CHAR(20)
,Mgr_No VARCHAR(12)
,Salary Decimal(10,2)
) UNIQUE PRIMARY INDEX(Employee_No)Teradata hashes UPI to distribute the date to all the AMPs evenly
3.2 NUPI
CREATE TABLE Employee_Intl
( Employee_No INTEGER
,Dept_No INTEGER
,Last_Name CHAR(20)
,Salary Decimal(10,2)
) PRIMARY INDEX(Dept_No)Teradata distributes same NUPI into one AMPs, normally unevenly
3.3 Multi-Column Primary Index
Apply to both UPI & NUPI
CREATE TABLE Employee_Intl
( Employee_No INTEGER
,Dept_No INTEGER
,First_Name CHAR(10)
,Last_Name CHAR(20)
,Salary Decimal(10,2)
) PRIMARY INDEX(First_Name,Last_Name)Where write query, you need to combine the multi-column primary index, in order to get single AMP retrieving.
SELECT FROM Employee_Intl WHERE First_Name = '' AND Last_Name = '';3.4 No Primary Index Tables
Random distribution, which is always even.
CREATE TABLE Employee_Intl
( Employee_No INTEGER
,Dept_No INTEGER
,First_Name CHAR(10)
,Last_Name CHAR(20)
,Salary Decimal(10,2)
) PRIMARY INDEX(First_Name,Last_Name)When execute the query, it will do a full table scan, usually for staging, which makes loading data faster.
Or use it for Columnar design
CREATE TABLE Employee_Columnar
( Employee_No INTEGER
,Dept_No INTEGER
,First_Name CHAR(10)
,Last_Name CHAR(20)
,Salary Decimal(10,2)
) No Primary Index
Partition By Column- must be a NoPI table
- COLUMN keyword
4. Nodes
4.1 SMP Node
AMPs and Parsing Engines live inside SMP (Symmetric Multi-Processing) Nodes
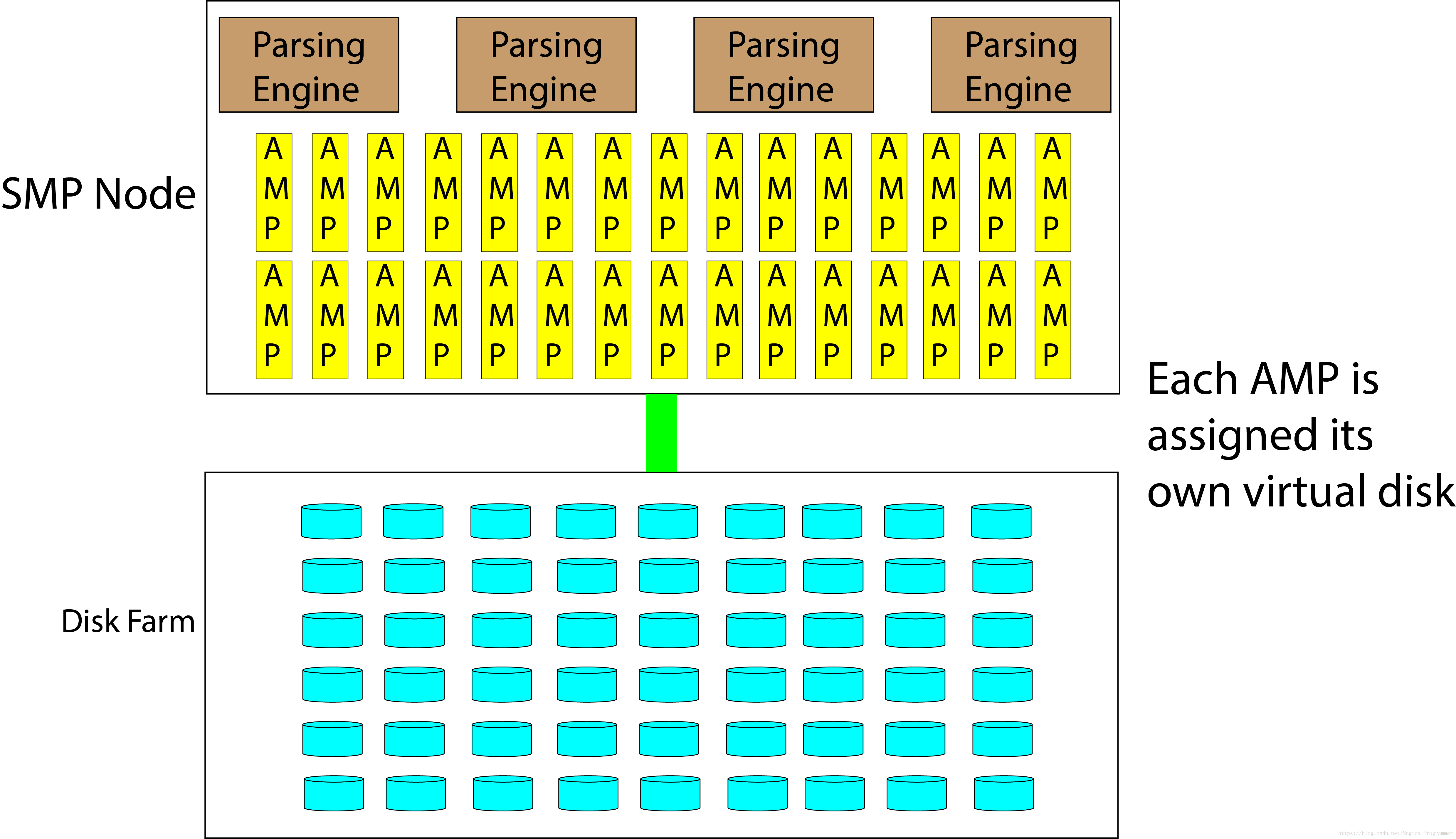
AMPs share nothing, each of them has its own disk, memory, CPU
4.2 MPP
Two SMP nodes connected become one MPP (Massive Parallel Processing) system
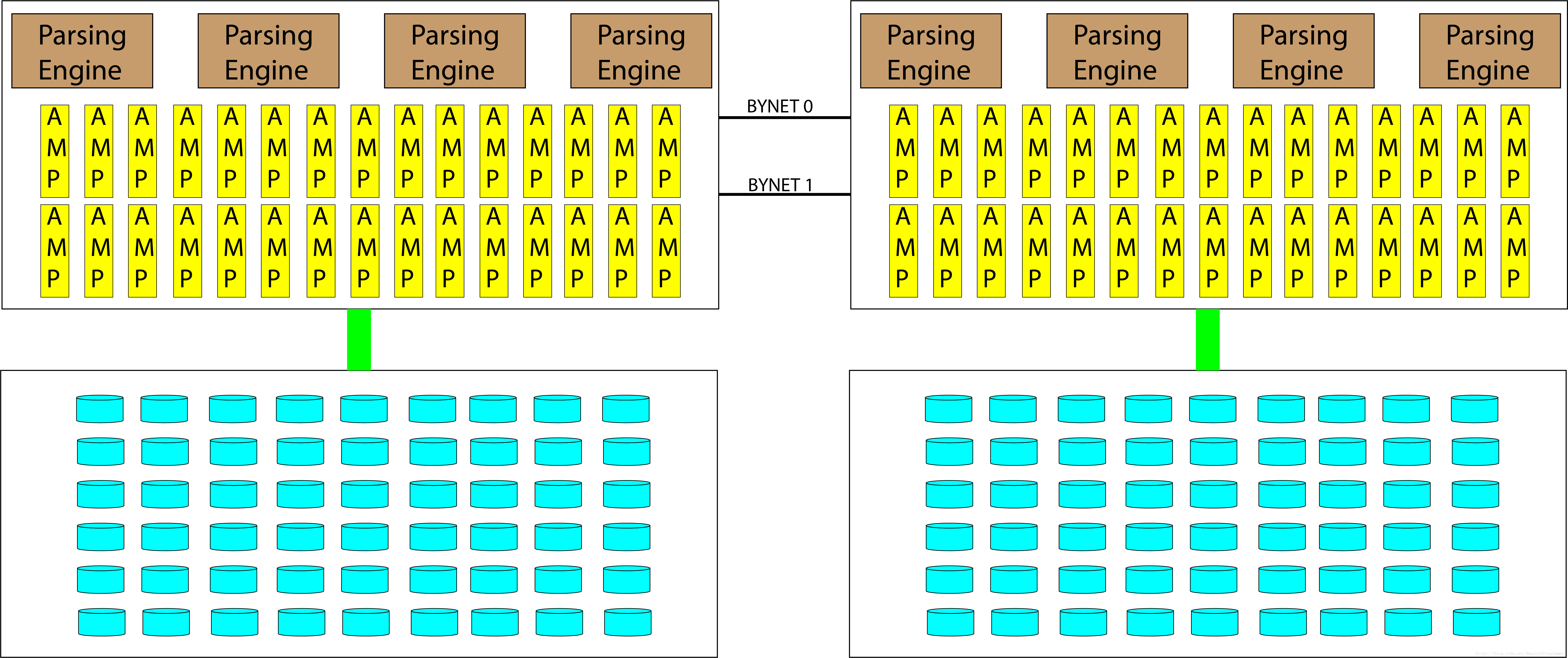
4.3 Teradata Cabinet

4.4 Inside a Node
PDE - Parallel Database Extensions, which controls the BYNET
PE - Parsing Engines
Vproc - Virtual Processes
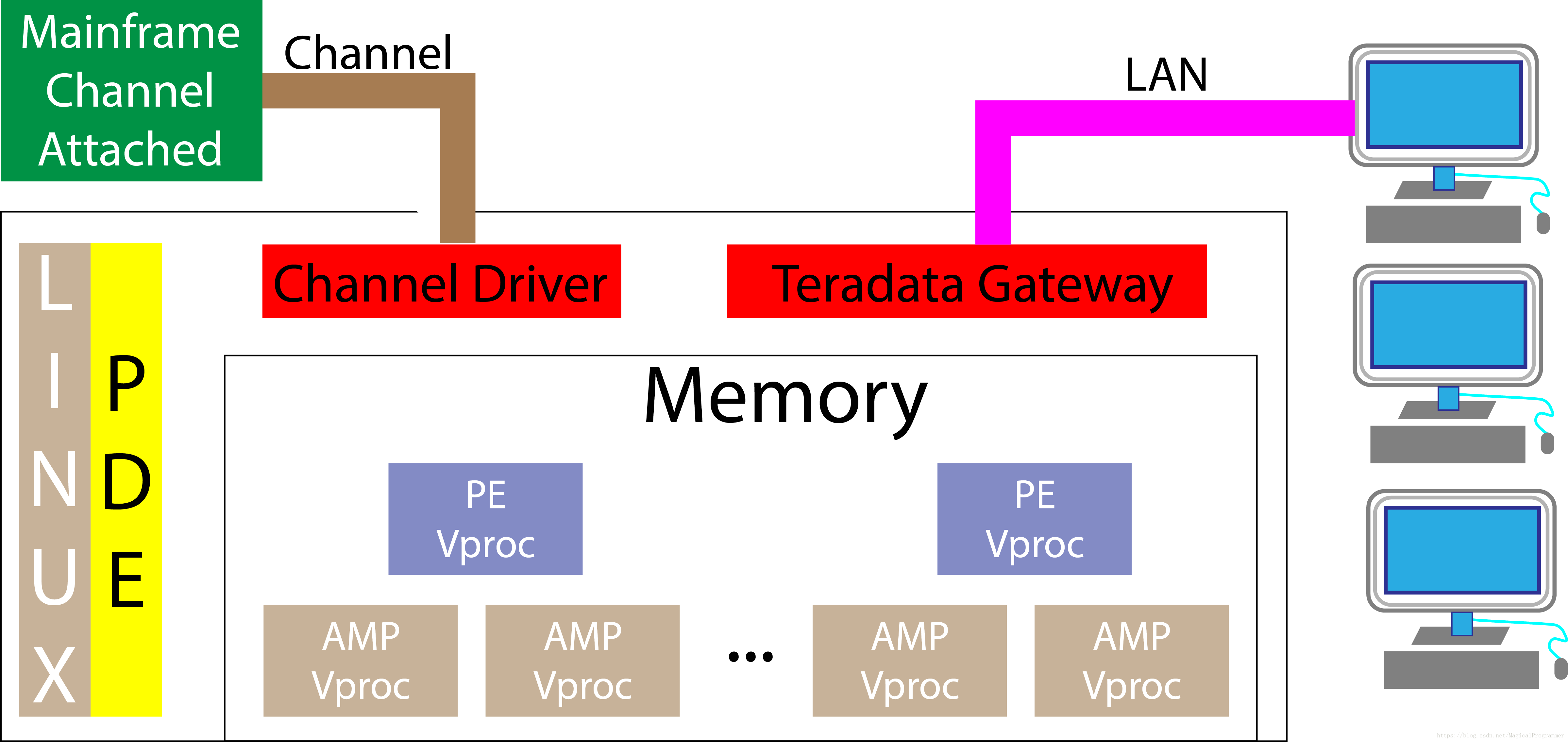
4.5 Boardless BYNET and Physical BYNET
Each PE controls every AMP, but why multiple PEs instead of one? Because each PE handles 120 sessions (users), which makes Teradata available for many users at the same time.


















 191
191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









