




爬虫作业记录:航班数据爬取与可视化分析全流程解析
一、提示
本文所有数据均为网站公开数据,本文仅用于学术讨论和技术研究。
二、网站介绍
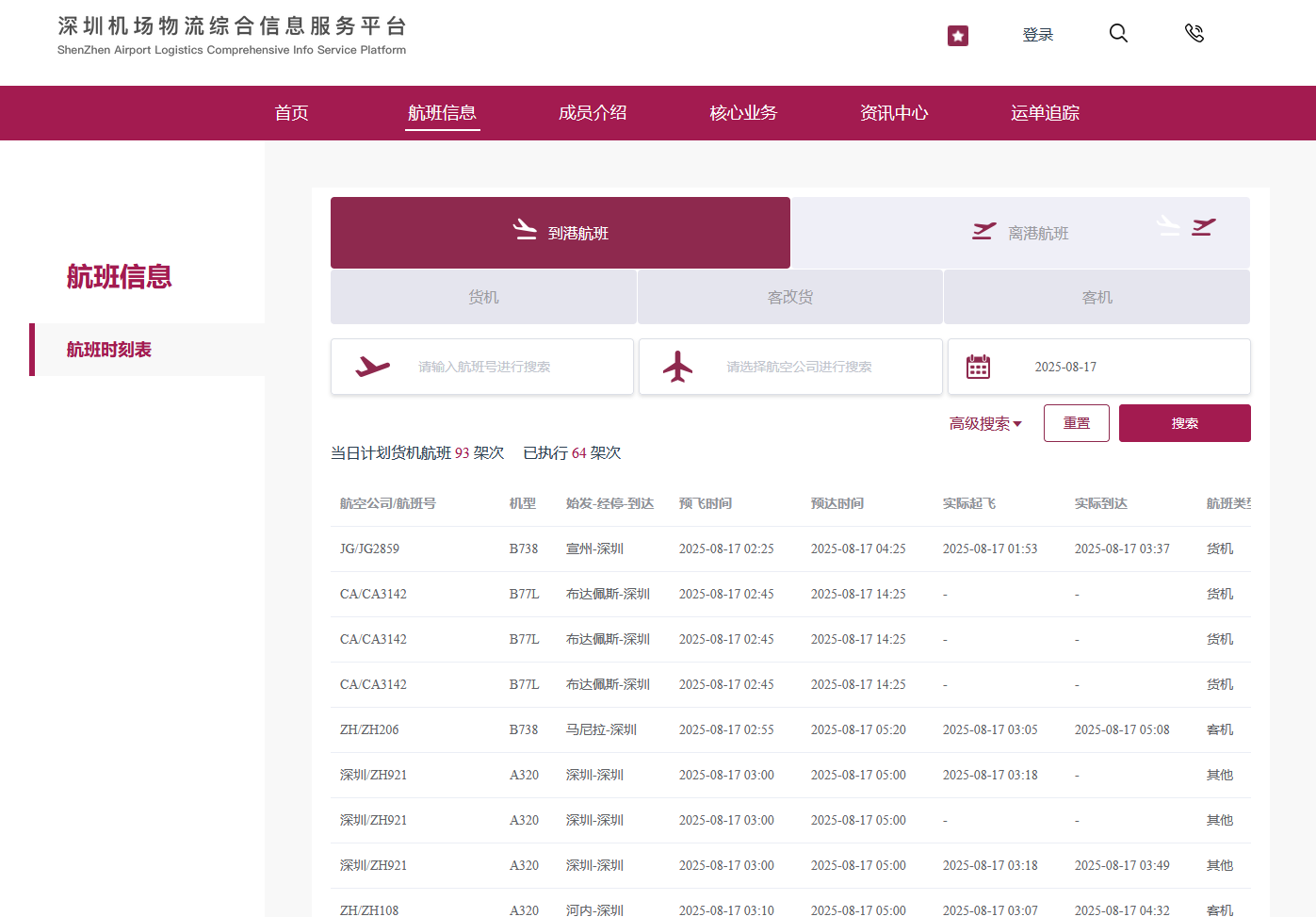
深圳机场航空物流网站:
https://logistics.szairport.com/#/air-route-network/FlightSchedule
公开展示了深圳机场的航空物流数据:
三、数据爬取模块
数据爬取是整个分析流程的基础,我们需要从目标网站获取结构化的航班信息。
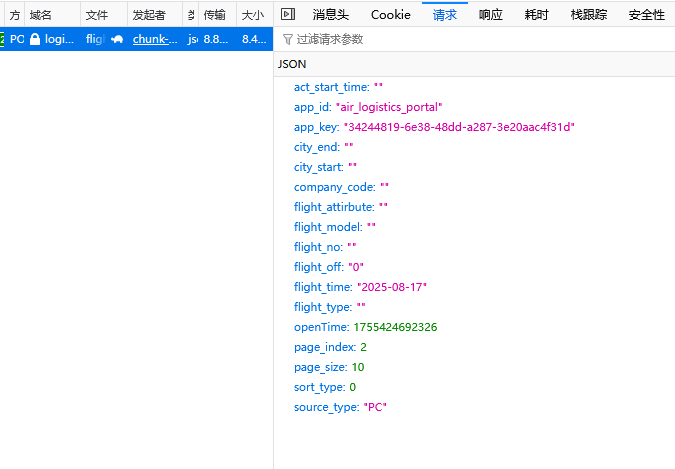
首先通过浏览器分析接口,很容易可以找到接口为
https://logistics.szairport.com/air/logistics/api/v1/multiple/flight_query
发送的请求体:
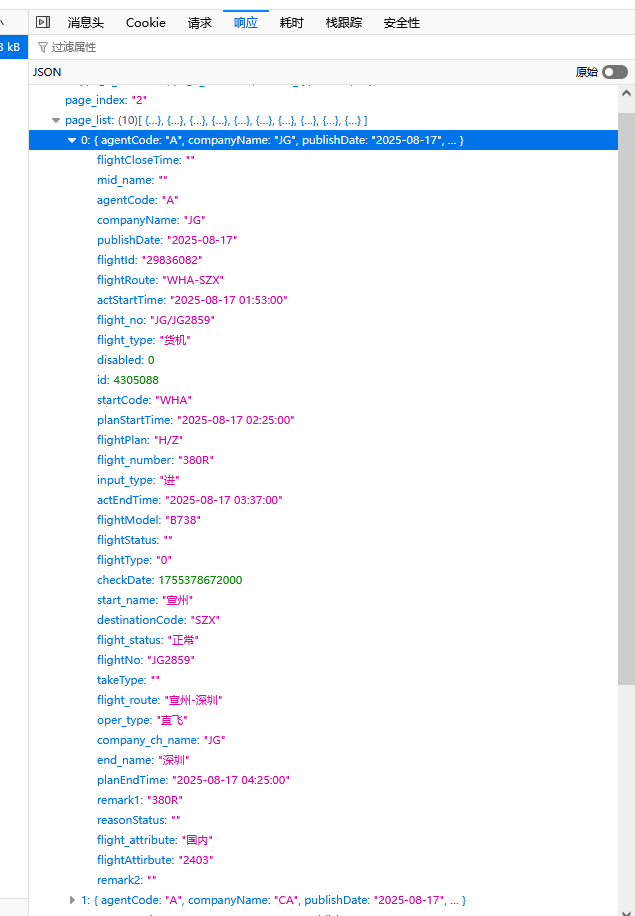
返回的数据也是标准的json格式,很容易解析:
3.1 导入必要库
import requests
import json,time,datetime
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
requests:用于发送 HTTP 请求,获取网页数据json:处理 JSON 格式数据time和datetime:处理时间相关操作,实现按日期爬取pandas:数据处理与分析的核心库warnings:忽略不必要的警告信息,使输出更简洁
3.2 初始化数据存储结构
df = pd.DataFrame(columns=['航空公司/航班号','机型机型','计划起飞','实际起飞','出发地','计划到达','实际到达','经停地','到达地','状态','机位'])
创建一个空的 DataFrame,定义了将要爬取的所有字段,包括航班基本信息、时间信息、地点信息和状态信息等。
3.3 设置请求头和目标 URL
根据浏览器的请求构建headers
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:104.0) Gecko/20100101 Firefox/104.0",
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Content-Type": "application/json;charset=utf-8",
"device": "pc",
"Origin": "https://logistics.szairport.com",
"Connection": "keep-alive",
"Referer": "https://logistics.szairport.com/",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"Pragma": "no-cache",
"Cache-Control": "no-cache"
}
# 航运数据接口
url = "https://logistics.szairport.com/air/logistics/api/v1/multiple/flight_query"
headers:模拟浏览器请求头信息,包含浏览器类型、支持的数据类型、编码方式等url:目标数据接口,这是一个 POST 请求接口,用于获取航班数据
3.4 设置爬取日期范围
start_day = '2025-05-01'
end_day = '2025-05-10'
end_day = datetime.datetime.strptime(end_day,'%Y-%m-%d')
tmp_day= datetime.datetime.strptime(start_day,'%Y-%m-%d')
- 将字符串格式的日期转换为 datetime 对象,便于进行日期计算和循环
- 设置了从 2025-05-01 到 2025-05-10 的爬取日期范围
3.5 核心爬取逻辑
while (end_day-tmp_day).days>-1:#构建循环
print(tmp_day)
for page in range(999):
data = {
"flight_type": "0",
"flight_no": "",
"city_start": "",
"city_end": "",
"flight_time": f"{tmp_day.year}-{tmp_day.month}-{tmp_day.day}",
"page_index": page,
"page_size": 10,
}
data = json.dumps(data)
response = requests.post(url, headers=headers, data=data)
dedejson = response.json()
for tmp_data in dedejson['data']['page_list']:
print({'航空公司/航班号':tmp_data['flight_no'],'机型':tmp_data['flightModel'],'计划起飞':tmp_data['planStartTime'],'实际起飞':tmp_data['actStartTime'],
'出发地':tmp_data['start_name'],'计划到达':tmp_data['planEndTime'],'实际到达':tmp_data['actEndTime'],'经停地':tmp_data['mid_name'],
'到达地':tmp_data['end_name'],'状态':tmp_data['flight_status'],'机位':tmp_data['remark1']})
df = df._append({'航空公司/航班号':tmp_data['flight_no'],'机型':tmp_data['flightModel'],'计划起飞':tmp_data['planStartTime'],'实际起飞':tmp_data['actStartTime'],
'出发地':tmp_data['start_name'],'计划到达':tmp_data['planEndTime'],'实际到达':tmp_data['actEndTime'],'经停地':tmp_data['mid_name'],
'到达地':tmp_data['end_name'],'状态':tmp_data['flight_status'],'机位':tmp_data['remark1']},ignore_index=True)
# time.sleep(5)
if len(dedejson['data']['page_list'])<10: #如果条数小于十条就爬下一天的
tmp_day = (tmp_day + datetime.timedelta(days=+1))
break
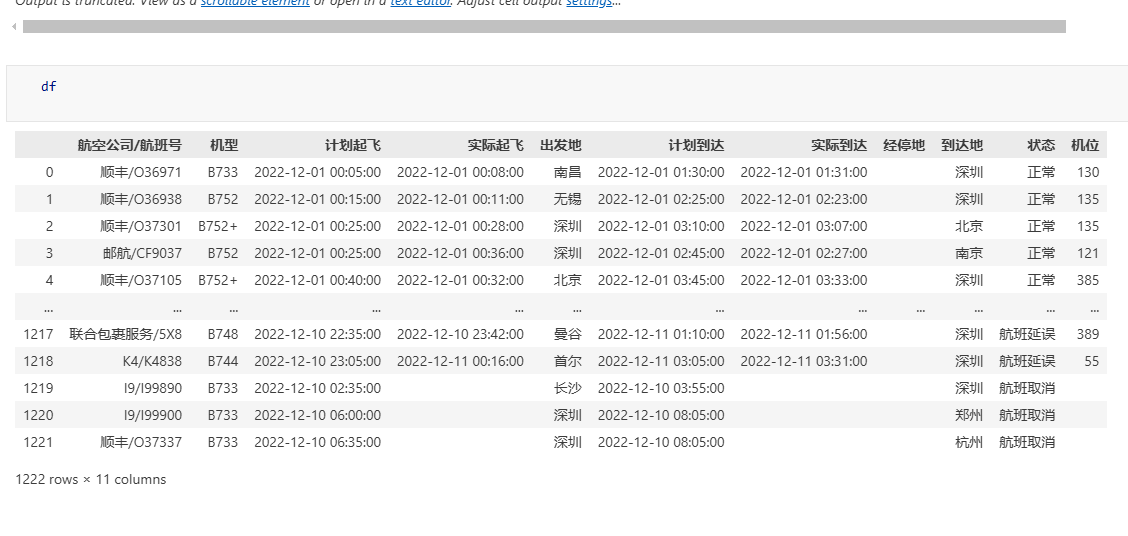
这段代码实现了多日期、多页的航班数据爬取:
- 外层
while循环:按日期遍历,从 start_day 到 end_day - 内层
for循环:按页码遍历,最多 999 页(实际会提前结束) data字典:构造 POST 请求参数,包括航班类型、日期、页码等json.dumps(data):将参数转换为 JSON 字符串格式requests.post():发送 POST 请求获取数据- 解析 JSON 响应,提取航班列表数据
- 遍历每条航班数据,将其添加到 DataFrame 中
- 终止条件:当某页返回的航班数小于 10 条(分页大小),说明当前日期数据已爬取完毕,切换到下一天
运行结果如下:

四、数据存储到 MongoDB
爬取到数据后,我们需要将其持久化存储,以便后续分析使用。这里选择 MongoDB 作为存储数据库。
4.1 导入 MongoDB 客户端库
from pymongo import MongoClient
pymongo 是 Python 操作 MongoDB 的官方驱动库。
4.2 连接数据库并创建集合
client = MongoClient('mongodb://localhost:27017/') # 连接本地MongoDB服务
db = client['flight'] # 创建或使用名为'flight'的数据库
collection = db['flight'] # 创建或使用名为'flight'的集合
- MongoDB 是文档型数据库,数据以 JSON 类似的文档形式存储
- 这里假设 MongoDB 服务运行在本地,端口为默认的 27017
4.3 插入数据到 MongoDB
# 将DataFrame转换为字典列表
data = df.to_dict(orient='records')
# 插入数据到MongoDB中
collection.insert_many(data)
print("数据已成功插入到MongoDB中")
df.to_dict(orient='records'):将 DataFrame 转换为字典列表,每个字典代表一条航班记录insert_many(data):批量插入多条记录,比单条插入效率更高
五、数据可视化分析
数据可视化是探索数据、发现规律的重要手段。下面将通过多种图表展示航班数据的不同维度。
5.1 航空公司航班准点率对比柱状图
import pandas as pd
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题
# 计算总航班数
airline_ontime = df.groupby('航空公司/航班号').size().reset_index(name='总航班数')
# 计算准点航班数
on_time_flights = df[df['状态'] == '正常'].groupby('航空公司/航班号').size().reset_index(name='准点航班数')
# 使用左连接合并数据
airline_ontime = pd.merge(airline_ontime, on_time_flights, on='航空公司/航班号', how='left')
# 处理没有准点航班的情况
airline_ontime['准点航班数'] = airline_ontime['准点航班数'].fillna(0)
# 计算准点率
airline_ontime['准点率'] = (airline_ontime['准点航班数'] / airline_ontime['总航班数']) * 100
# 提取航空公司名称
df['航空公司'] = df['航空公司/航班号'].apply(lambda x: x.split('/')[0])
# 按航空公司汇总准点率
airline_data = airline_ontime.copy()
airline_data['航空公司'] = airline_data['航空公司/航班号'].apply(lambda x: x.split('/')[0])
airline_summary = airline_data.groupby('航空公司').agg({
'总航班数': 'sum',
'准点航班数': 'sum'
}).reset_index()
airline_summary['准点率'] = (airline_summary['准点航班数'] / airline_summary['总航班数']) * 100
# 绘制柱状图
plt.figure(figsize=(8, 5))
plt.bar(airline_summary['航空公司'], airline_summary['准点率'],
color=['#1f77b4', '#ff7f0e'], width=0.6)
plt.ylabel('准点率 (%)', fontsize=12)
plt.title('航空公司航班准点率对比', fontsize=14, fontweight='bold')
# 添加数值标签
for i, rate in enumerate(airline_summary['准点率']):
plt.text(i, rate, f'{rate:.1f}%', ha='center', va='bottom')
plt.xticks(rotation=45, ha='right', fontsize=10)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.tight_layout()
plt.show()
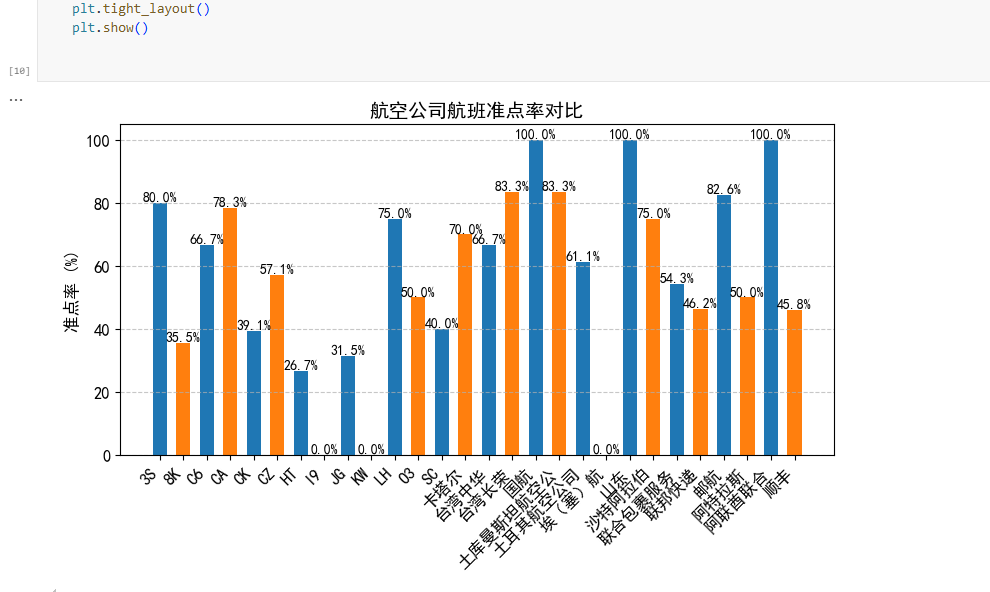
这段代码实现了航空公司准点率的计算和可视化:
-
数据处理阶段:
- 按航班号分组计算总航班数
- 筛选状态为"正常"的航班,计算准点航班数
- 合并总航班数和准点航班数数据
- 处理缺失值(没有准点航班的情况)
- 计算准点率(准点航班数/总航班数×100%)
- 从"航空公司/航班号"字段中提取航空公司名称
- 按航空公司汇总数据,计算各航空公司的总体准点率
-
可视化阶段:
- 创建柱状图,X轴为航空公司,Y轴为准点率
- 添加数值标签显示具体准点率
- 设置坐标轴标签、标题和网格线
- 调整X轴标签角度,避免重叠
- 优化布局,确保所有元素清晰显示
运行结果如下:
5.2 机型分布饼图
import matplotlib.pyplot as plt
# 统计各机型数量
aircraft_counts = df['机型'].value_counts()
# 绘制饼图
plt.figure(figsize=(8, 6))
wedges, texts, autotexts = plt.pie(
aircraft_counts.values,
labels=aircraft_counts.index,
autopct='%1.1f%%', # 显示百分比
colors=['#1f77b4', '#ff7f0e', '#2ca02c'],
textprops={'fontsize': 12},
)
plt.title('机型分布占比', fontsize=14, fontweight='bold')
plt.axis('equal') # 保证饼图为正圆形
plt.legend(wedges, aircraft_counts.index, loc='best', fontsize=12)
plt.tight_layout()
plt.show()
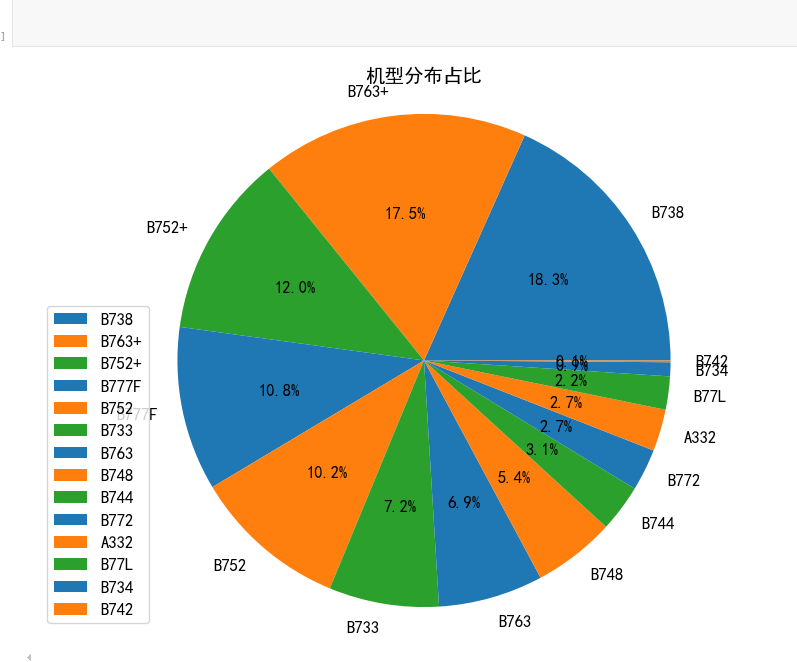
这段代码展示了不同机型的分布情况:
df['机型'].value_counts():统计每种机型出现的次数plt.pie():绘制饼图,包含以下关键参数:autopct='%1.1f%%':显示百分比,保留一位小数colors:指定饼图各部分的颜色textprops:设置文本属性
plt.axis('equal'):确保饼图是正圆形而非椭圆形- 添加图例和标题,使图表更易理解
运行结果如下:
5.3 起飞时间分布折线图
import plotly.express as px
# 将计划起飞时间和实际起飞时间转换为 datetime 类型
df['计划起飞时间'] = pd.to_datetime(df['计划起飞'])
df['实际起飞时间'] = pd.to_datetime(df['实际起飞'])
# 方案一:使用向量化操作(推荐)
df['计划时间间隔'] = df['计划起飞时间'].dt.hour * 60 + df['计划起飞时间'].dt.minute // 15 * 15
df['实际时间间隔'] = df['实际起飞时间'].dt.hour * 60 + df['实际起飞时间'].dt.minute // 15 * 15
# 统计各时间间隔的航班数量
planned_counts = df['计划时间间隔'].value_counts().sort_index()
actual_counts = df['实际时间间隔'].value_counts().sort_index()
# 合并计划和实际数据
time_intervals = pd.concat([planned_counts, actual_counts], axis=1).fillna(0)
time_intervals.columns = ['计划起飞数', '实际起飞数']
# 将时间间隔转换为 HH:MM 格式
time_intervals.index = time_intervals.index.map(lambda x: f'{int(x//60)}:{int(x%60):02d}')
# 绘制折线图
fig = px.line(
time_intervals,
x=time_intervals.index,
y=['计划起飞数', '实际起飞数'],
title='起飞时间分布对比',
labels={'value': '航班数量', 'variable': '类型'},
markers=True,
color_discrete_map={'计划起飞数': '#1f77b4', '实际起飞数': '#ff7f0e'}
)
# 设置x轴标签倾斜
fig.update_layout(
xaxis=dict(tickangle=45),
font=dict(size=12),
title_font=dict(size=14, weight='bold')
)
fig.show()
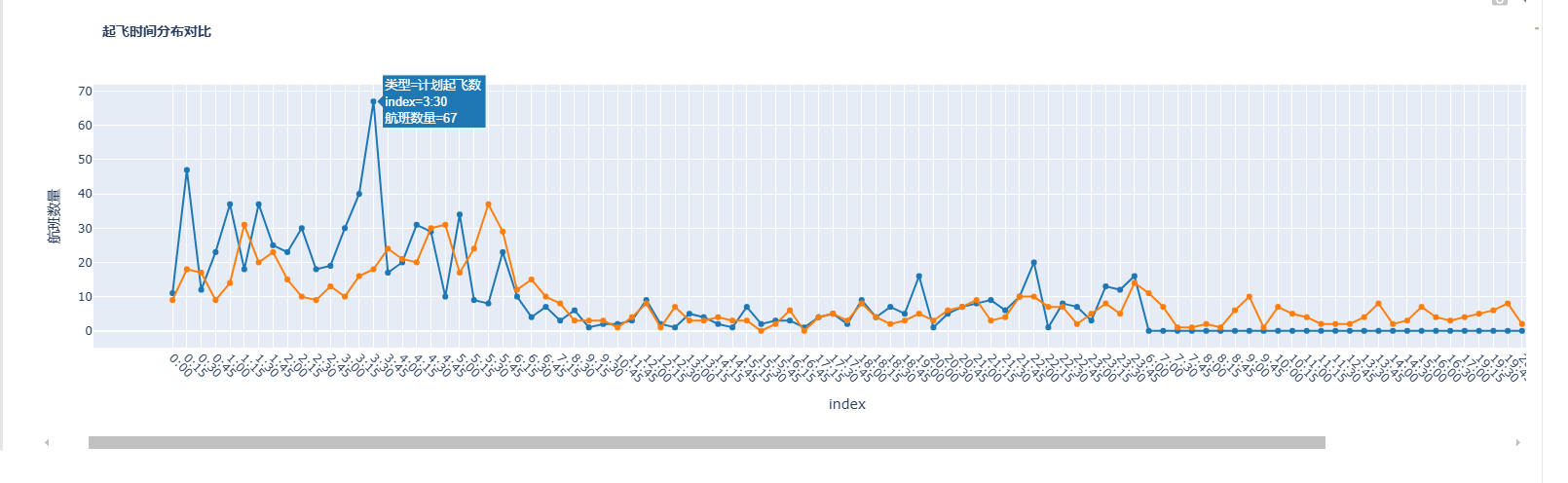
这段代码使用 Plotly 绘制了计划起飞时间与实际起飞时间的分布对比:
-
数据预处理:
- 将字符串类型的时间转换为 datetime 类型
- 将时间按 15 分钟间隔分组(如 0:00-0:15、0:15-0:30 等)
- 统计每个时间间隔内的计划起飞和实际起飞航班数量
- 将分钟数格式转换为 HH:MM 格式,便于阅读
-
可视化:
- 使用 Plotly Express 绘制折线图,对比计划与实际起飞分布
- 添加标记点(markers=True)使数据点更清晰
- 自定义颜色区分不同数据系列
- 设置标题、标签和字体样式
- 调整X轴标签角度,避免重叠
Plotly 生成的图表是交互式的,用户可以放大、缩小、悬停查看具体数值,增强了数据探索能力。
运行结果如下:
5.4 出发地-到达地流向图
import plotly.graph_objects as go
# 统计出发地到到达地的航班数量
flow_data = df.groupby(['出发地', '到达地']).size().reset_index(name='航班数')
# 构建节点和链接数据
nodes = list(set(flow_data['出发地'].tolist() + flow_data['到达地'].tolist()))
node_indices = {node: i for i, node in enumerate(nodes)}
links = []
for _, row in flow_data.iterrows():
source = node_indices[row['出发地']]
target = node_indices[row['到达地']]
value = row['航班数']
links.append({'source': source, 'target': target, 'value': value})
# 绘制桑基图
fig = go.Figure(data=[go.Sankey(
node=dict(
pad=15,
thickness=20,
line=dict(color='black', width=0.5),
label=nodes,
color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728']
),
link=dict(
source=[link['source'] for link in links],
target=[link['target'] for link in links],
value=[link['value'] for link in links],
color=['rgba(31, 119, 180, 0.5)', 'rgba(255, 127, 14, 0.5)', 'rgba(44, 160, 36, 0.5)']
)
)])
fig.update_layout(
title='航班出发地-到达地流向图',
title_font=dict(size=14, weight='bold'),
font=dict(size=12)
)
# 保存为图片和 HTML
fig.write_image("flight_sankey.png") # 保存为 PNG
fig.write_html("flight_sankey.html") # 保存为交互式 HTML
这段代码使用桑基图(Sankey diagram)展示了航班的流向分布:
-
数据处理:
- 按出发地和到达地分组,统计航班数量
- 提取所有独特的城市作为节点
- 为每个城市分配一个索引,用于构建链接关系
- 创建链接列表,包含源节点、目标节点和流量值
-
桑基图绘制:
node参数:定义节点样式,包括间距、厚度、边框、标签和颜色link参数:定义链接样式,包括源、目标、流量值和颜色- 设置图表标题和字体样式
- 保存图表为静态图片和交互式 HTML 文件
桑基图特别适合展示流量分布,能直观地反映不同城市之间的航班流量大小,帮助我们识别主要航线。
运行结果如下:

六、总结
本文详细解析了一个完整的航班数据爬取与可视化分析流程,涵盖了从数据获取到存储再到多维度可视化的全过程。通过这段代码,我们可以:
- 自动爬取指定日期范围内的航班数据
- 将数据持久化存储到 MongoDB 数据库
- 通过多种可视化方式分析航班准点率、机型分布、起飞时间分布和航线流向
这个流程不仅适用于航班数据,也可以作为其他类型数据爬取与分析的参考框架。在实际应用中,你可以根据需要调整爬取参数、优化数据处理逻辑或增加更多的可视化维度,以获取更深入的 insights。
需要注意的是,在进行网络爬虫时,应遵守目标网站的 robots 协议,合理控制爬取频率,避免给服务器带来过大负担,确保数据获取的合法性和道德性。
七、获取完整代码
关注微信公众号:
公众号名称:数海船长
公众号ID:SeaDataCap
输入关键词“机场爬虫”即可获取完整代码下载链接


















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









