







 本文深入探讨了数据库索引的优化,从二叉树、红黑树到B-Tree和B+Tree的演变。二叉树在范围查询上的不足,导致了对红黑树的需求,但其高度问题又催生了B-Tree。B-Tree通过在一个节点存储多个索引来提升效率,而B+Tree进一步优化,非叶子节点仅存储索引,叶子节点包含所有数据,且具有顺序访问指针,特别适合范围查询。通过B+Tree,可以显著提高数据库的查询性能。
本文深入探讨了数据库索引的优化,从二叉树、红黑树到B-Tree和B+Tree的演变。二叉树在范围查询上的不足,导致了对红黑树的需求,但其高度问题又催生了B-Tree。B-Tree通过在一个节点存储多个索引来提升效率,而B+Tree进一步优化,非叶子节点仅存储索引,叶子节点包含所有数据,且具有顺序访问指针,特别适合范围查询。通过B+Tree,可以显著提高数据库的查询性能。
索引的本质:
索引是帮助Mysql高效获取数据的排好序的数据结构
索引数据结构:
1.二叉树
2.红黑树
3.Hash表
4.B-Tree
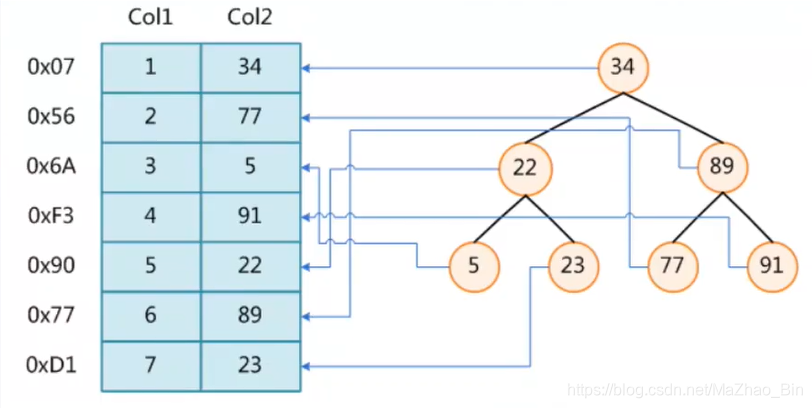 上面的例题是通过二叉树来索引来实现优化
上面的例题是通过二叉树来索引来实现优化
例:Select * Form t1 Where Col2 = 22
首先二叉树的基本知识左边子节点要小于根节点右边要大于根节点 同理把要查的22元素对比二叉树就需要两步查到结果
Mysql的索引存储并不是用二叉树数据结构来存储的 其实是用的B-Tree的数据结构来存储的,刚才示例二叉树使用起来还是有些弊端(最后Mysql官方工程师没有选择二叉树数据结构来作为索引的存储)
弊端:
列:Select * Form t1 Where Col1 = 6
通过二叉树来查询索引为6的也就会逐行往下查询,为什么呢,因为他通过Col1来查询就会形成一个链表式查询图如下:
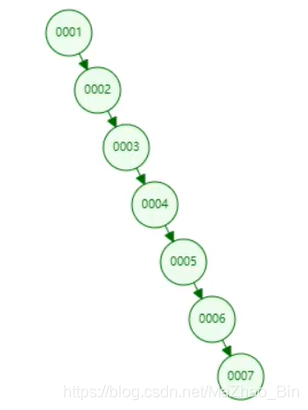 这样查询的话和不用使用二叉树数据结构没什么区别。
这样查询的话和不用使用二叉树数据结构没什么区别。
那好我们来看下什么样的数据结果会满足我们各种需求呢
红黑树
实际上红黑树他本身就是一个二叉树只不过全名(平衡二叉树)他有一个置旋平衡的一个过程
1.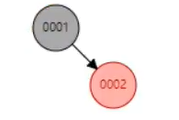 2.
2.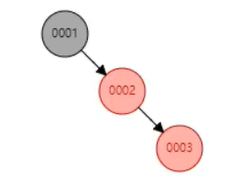 3.
3.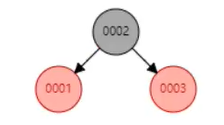
2到3这个过程就是置旋平衡的一个过程
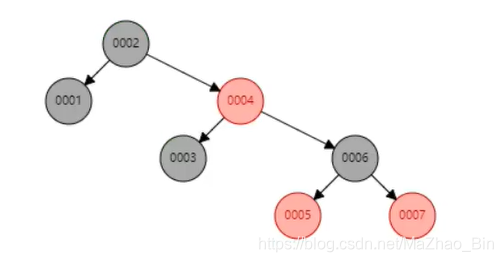
相比二叉树单面增长通过红黑树查找行索引6就需要3步比二叉树单面查找速度减少了一半,那就是红黑树优于二叉树数据结构的一个优点,虽然这麽说但是Mysal官方工程师并没有选择红黑树数据结构,红黑树在一些方便也存在一些弊端,存在哪些弊端呢最大的弊端就是高度,现在测试的数据还好就几条数据,那如果存储这100万行数据那我们索引对应的是不是100万个索引
Hash表
Hash表相对比二叉树和红黑树优化较大那它是怎样实现的呢,还是拿上面的举例where Col1 = 5 他会把这个条件作为一个hash(5)做运算就是数据存储的数据磁盘地址指针有个一一映射关系,我不管你sql语句怎样写我只管where后面的条件做hash运算,换句话说M05加密运算CRcib/32算法都是hash算法,不管数据库有多少条数据只要做完运算就能算出要查索引所对应磁盘地址只经历一次磁盘ao就能查找到我们这一行的数据
那这样使用起来性能非常高,为什么最后mysql官方工程师没有选择这个,很少有业务去用这个呢,道理也很简单就是如果把条件 = 换成 > 这样就出问题了,范围性查找这是我们都会遇到的场景吧。相对来说mysql官方给Hash提供了场景二叉树和红黑树这两个性能差太多了就没有。
下面就让我们了解下B-Tree数据结构了
B-Trre
叶子节点具有相同高度
叶子节点的指针为空
节点中的数据索引从左向右递增排序
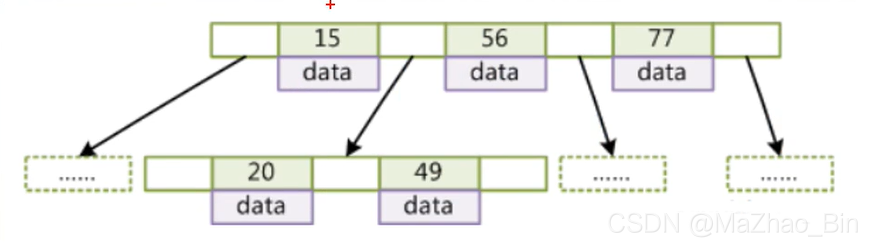
会不会有的老铁想把所以的索引全放一个节点上,首先这中是不可取的也是极大的消耗内存,也相当耗费时间,如果数据不是很大全放在一个节点上全部加载内存当中也对内存空间有一定浪费的。如果一次性弄那么大的数据一次磁盘ao是读取不到的,一次磁盘ao和内存的交互基本单位只有4k,一次的磁盘ao弄到4k的基本也就差不多了。
上面的问题mysql官方也想到了,所以就给这个节点设置一个限制也比较折中的一个值就是16k。
B-Trre除了可以一个节点可以存储多个索引还有一个特性,他也满足二叉树的一个特性,仔细发现第一行节点从左往右他是一个逐渐递增的一个排序
虽然B-Trre解决了红黑树的缺点但是还是没有解决范围性问题,如果都要实现就需要使用B+Trre,看到这里是不有点想说优美的中国话了,先别着急往下接着看
B+Trre结构 (B-Trre变种)
非叶子节点不存储data,只存储索引,可以放更多的索引
叶子节点不存储指针
顺序访问指针,提高区间访问的性能
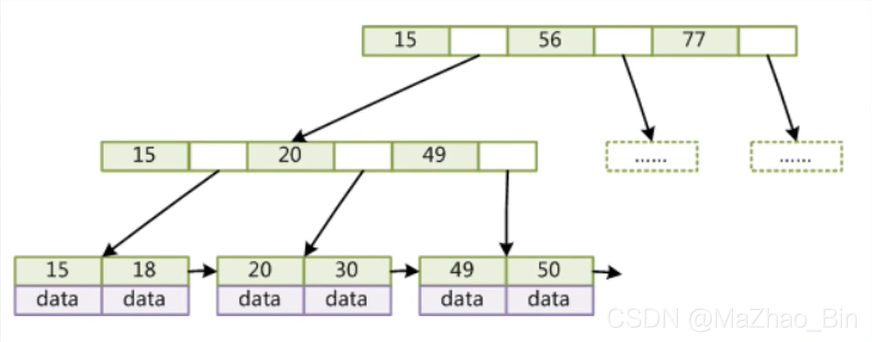
关键来了 B+Trre根节点下面的子节点都会冗余一个子节点,上面B-Trre的data在根节点都有而B+Trre则把data移到了第三层,之所以移到最下面就是节省掉data的空间可以存储多个索引,只有分支有更多的索引就会衍生出更多的索引值,那抹他是怎么查找的呢就是上图15所占的空间是8B后面空的空间值是6B加起来就是14B。最大可以到1170个,当我们这个树被盛满之后会存储多少个索引元素,高度3=h,第一行的叶子节点是1170个第二行相同也是1170到第三行的15占8B字节下面的data也有可能是索引磁盘文件指针,也有可能就是这一行所有的data全放在一个里面了,初步就先大约下这个data的大小为1kb那也就是这个 也是16k,这个大小可以存储16个索引元素 如果存满了就是(1170*1170*16)=21,902,400个,
也是16k,这个大小可以存储16个索引元素 如果存满了就是(1170*1170*16)=21,902,400个,
如何做到查询效率很高呢比如说查询30这个从第一行开始大于15小于56就查询第一个分支节点再往下大于20小于49就查询20后面空的分支节点到第三行就找到要查询的索引,总共查询的速度就三次,实际上就执行了2次的磁盘ao就能在B+Trre中找到我们的索引然后再根据索引中的data元素找到我们的值
B-Trre他是不能实现范围性查找的,而注意观察B+Trre他是有联系的其实中间是双向指针
那就显而易见了 如果查询 > 20 的元素。先定位到20然后在顺藤摸瓜获取到后面的元素,可以发现左边的元素永远在小于右边的元素


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









