




 本文深入探讨多任务学习在推荐系统中的挑战,如负转移和跷跷板现象,并介绍解决方案,如Grad Norm、DADNN、Star Topology和PLE模型。PLE模型通过定制化门控和分层提取提高多任务信息共享效率,减少任务间的负面影响。同时,文章提及了位置偏置问题及其在CTR预测中的处理方法。
本文深入探讨多任务学习在推荐系统中的挑战,如负转移和跷跷板现象,并介绍解决方案,如Grad Norm、DADNN、Star Topology和PLE模型。PLE模型通过定制化门控和分层提取提高多任务信息共享效率,减少任务间的负面影响。同时,文章提及了位置偏置问题及其在CTR预测中的处理方法。
综述
Grad Norm
梯度归一化
https://mp.weixin.qq.com/s/RIxxtMqdb6yJKLorg_WjrA
https://www.cnblogs.com/douzujun/p/14633524.html
多任务学习的多个权重改如何调节
梯度修剪,保证每个任务的梯度在同一个数量级
https://blog.youkuaiyun.com/Leon_winter/article/details/105014677
多场景论文
DADNN: Multi-Scene CTR Prediction via Domain-Aware Deep Neural Network
One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction
https://zhuanlan.zhihu.com/p/361113529
摘要
ple
https://zhuanlan.zhihu.com/p/291406172
代码
摘要

多任务学习在推荐系统中很常用,然而,多任务模型经常因为现实场景中任务之间的复杂联系,而效果不好。此外,我们观察到一个现象,一个任务的效果提高了,另外一个任务的效果反而会下降。为了解决这些问题,他们提出了ple这个模型:一个创新的共享层结构。ple把共享层分开,采用了一个创新性的机制去提取分开的语意信息,提高了联合训练的效率和不同任务之间信息共享的效率。
ple应用在了复杂的关系中,和简单的关系中,包含2个关系的和多个关系的。例如,腾讯视频,

跷跷板现象:
https://zhuanlan.zhihu.com/p/348294790
多任务学习相对于多个单任务学习的模型,往往能够提升一部分任务的效果,同时牺牲另外部分任务的效果。
(不同的任务用不同的特征?好像mmoe论文里也提到过)
1.绪论

同时满足用户满意度和参与度,例如点击,观看完,分享的概率。


negative transfer:任务相关性不强或者冲突导致性能下降。
seesaw phenomenon:多任务学习相对于多个单任务学习的模型,往往能够提升一部分任务的效果,同时牺牲另外部分任务的效果。
mmoe用门单元去关联不同的任务权重,但是忽略了不同的expert之间的差异性和关联性,这种不同expert之间的差异性和关联性往往会导致跷跷板现象。
(补充mmoe的demo实现)

2.related work
2.1 多任务学习模型
2.2 推荐系统中的多任务学习
3.跷跷板现象
https://zhuanlan.zhihu.com/p/359494543
3.1
在文中场景下,他们用多目标去给用户行为建模,例如点击,分享,和评论。在离线训练过程中,他们基于用户行为日志提取数据去训练模型。当有请求发生时,模型给每个任务输出一个预测结果,然后得到预测结果的加权值。
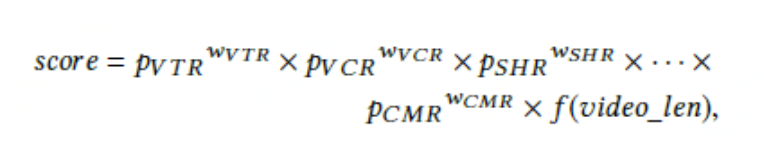
w是每个任务的重要程度;f vedio-len是一个针对视频播放长度的非线性变换。
在诸多的目标中,完播率和点击率/vcr(view completion ratio)和vtr(view through rate)是两个比较重要的指标。vcr是一个回归任务,用mse,预测播放长度。vtr是一个分类任务用交叉熵loss,预测一个视频被观看的概率,一个有效的观看是指播放长度超过了一定的阈值。vcr和vtr相互关系十分复杂,首先vtr的label是play action和vcr的耦合因素,因为只有超过了播放阈值的play action才被任务是有效的观看。
4.Progressive Layered Extraction
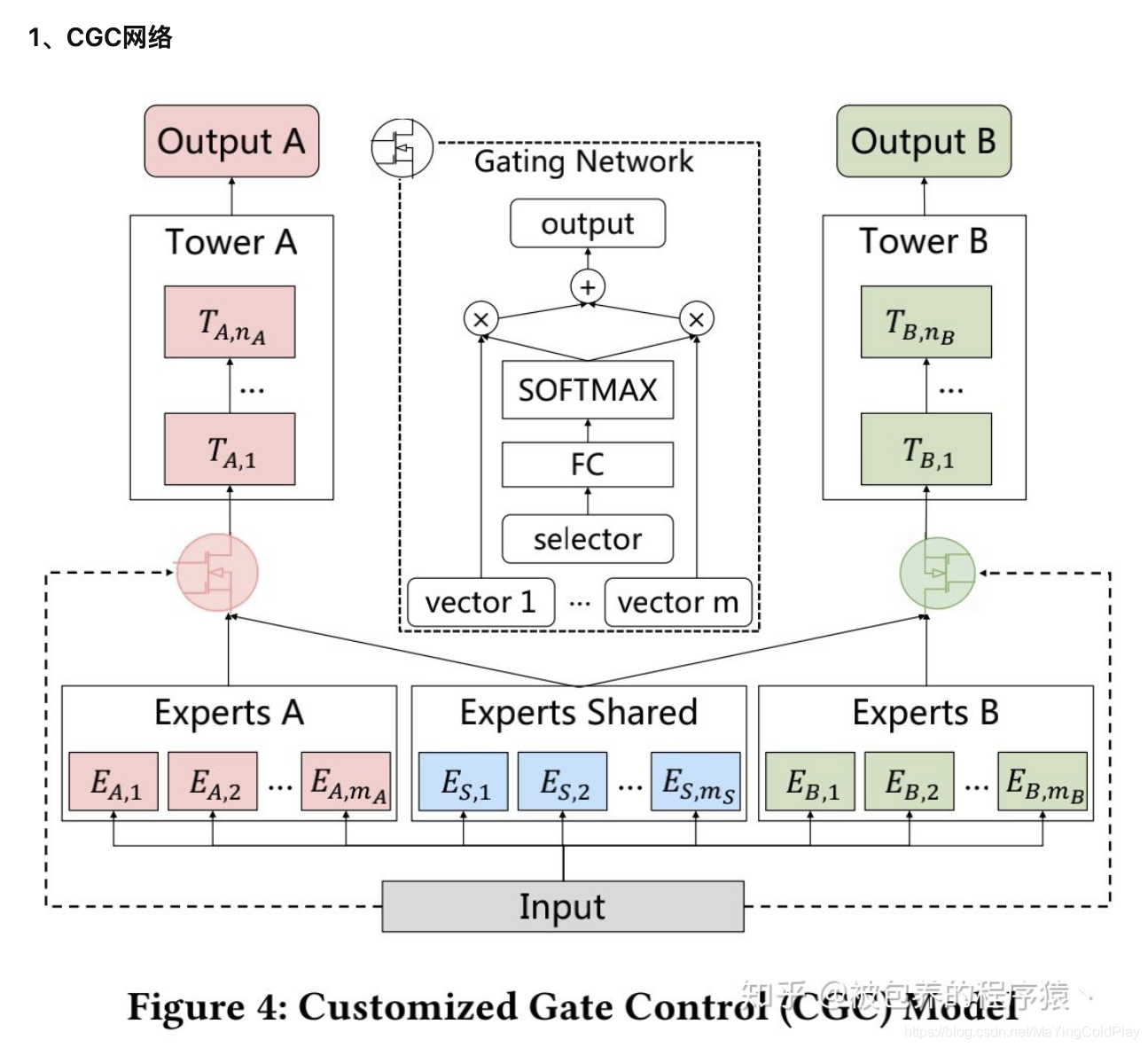
4.1 Customized Gate Control(特定的门单元)
https://zhuanlan.zhihu.com/p/272708728
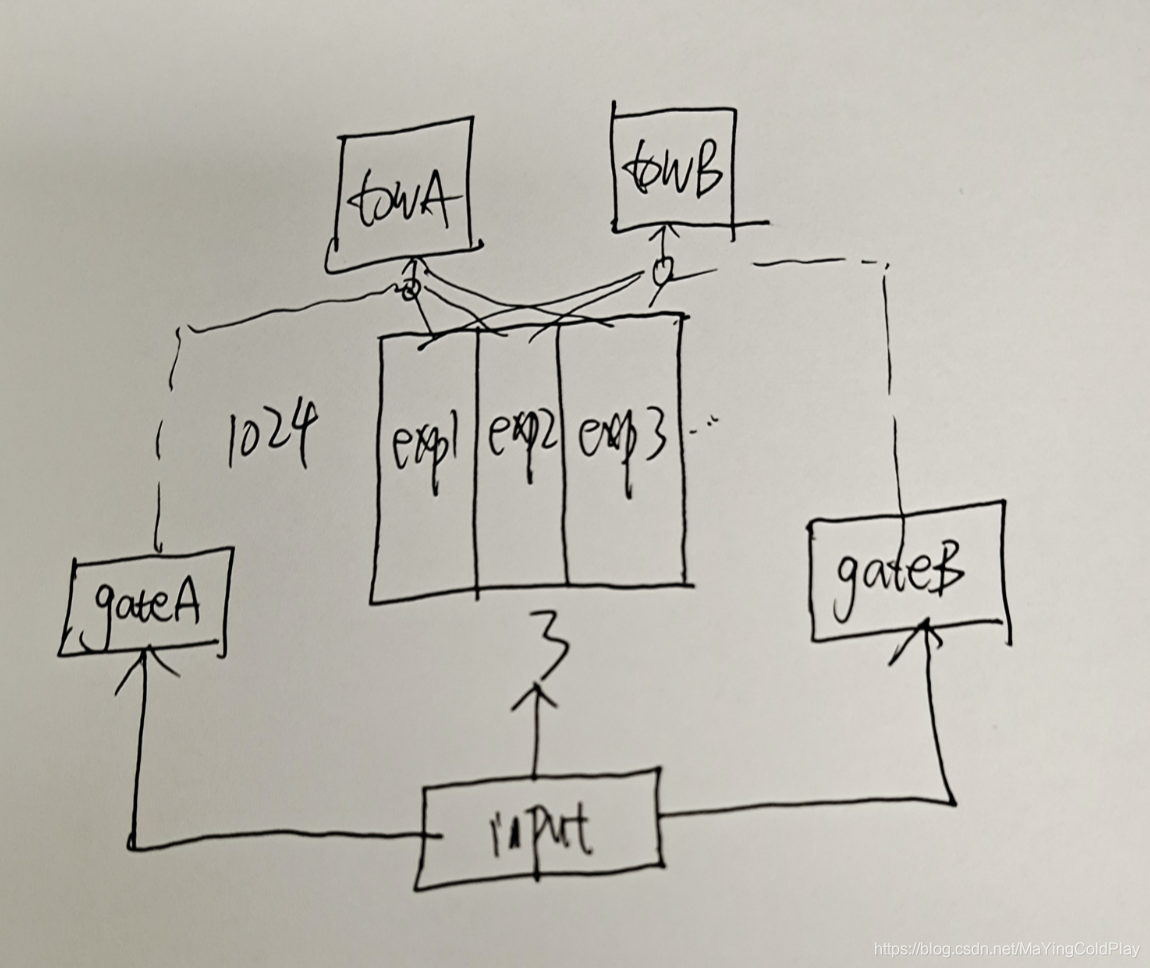
为了解决seesaw phenomenon和negative transfer效应,文章提出了PLE网络结构,而PLE结构可以看做是CGC网络结构的进一步扩展(CGC是single-level的,PLE是multi-level的)。整个CGC网络结构如上图所示。从图中的网络结构可以看出,CGC的底层网络主要包括shared experts和task-specific expert构成,每一个expert module都由多个子网络组成,子网络的个数和网络结构(维数)都是超参数;上层由多任务网络构成,每一个多任务网络(towerA和towerB)的输入都是由gating网络进行加权控制,每一个子任务的gating网络的输入包括两部分,其中一部分是本任务下的task-specific部分的experts和shared部分的experts组成(即gating network网络结构中的vector1……vector m),输入input作为gating network的selector。而gating网络的结构也是比较简单的,只是一个单层的前向FC,利用输入作为筛选器(selector)从而获得不同子网络所占的权重大小,从而得到不同任务下gating网络的加权和。也就是说CGC网络结构保证了,每个子任务会根据输入来对task-specific和shared两部分的expert vector进行加权求和,从而每个子任务网络得到一个embedding,再经过每个子任务的tower就得到了对应子任务的输出。
CGC网络的好处是即包含了task-specific网络独有的个性化信息,也包含了shared网络具有的更加泛化的信息,文章指出虽然MMoE模型在理论上可以得到同样的解,但是在实际训练过程中很难收敛到这种情况。

任务k的门单元实际上是一个权重,是expert的权重,维度是expert的维度。Gate其实就是一个权重矩阵。
w是经过softmax的权重矩阵。
https://zhuanlan.zhihu.com/p/355391933
(找个demo)
mmoe门单元的公式

与mmoe相比,cgc消除了单任务塔网络,和共享层之间的互相影响。
4.2 ple结构
4.3 loss
https://zhuanlan.zhihu.com/p/359494543
多任务学习的loss
https://mp.weixin.qq.com/s/RIxxtMqdb6yJKLorg_WjrA

http://www.360doc.com/content/20/1001/10/7673502_938402394.shtml

ple相关博客
https://www.zhihu.com/question/425243050/answer/1520453566
文章通过构建一个解耦的MMOE网络,加上loss权重的动态变化,成功的让多任务模型可以在每个任务上都有最优表现。非常不错的做法,比帕累托这种action非常繁琐的做法好了不少。比较接地气,容易action。确实是一篇佳作。

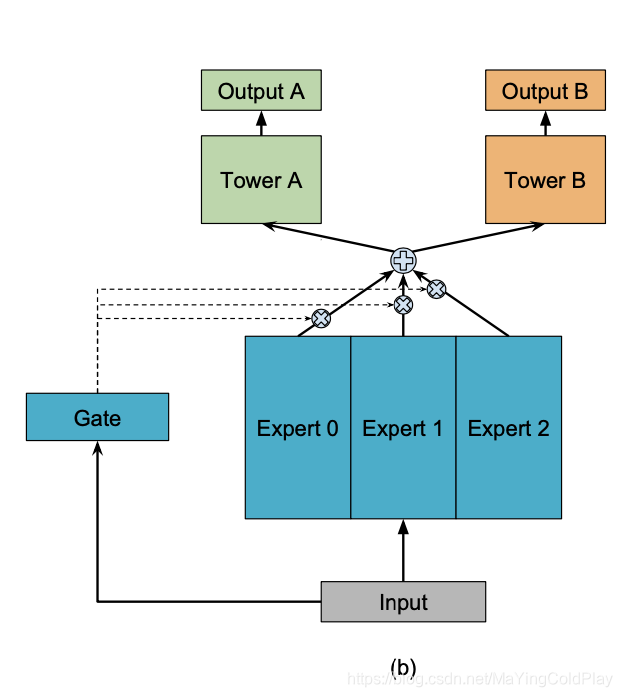
mmoe
moe

One-gate MoE model,门单元是一个向量,表示每个专家网络的权重。
mmoe
Multi-gate Mixture-of-Experts

w是n行d列的权重矩阵,n是expert的数量,d是feature数。这指的是有一条数据的时候。
例如,当https://github.com/SnowColdplay/FMmodels/blob/master/mmoe_new.ipynb这个例子时,experts nums是8,





mmoe的应用文章
https://zhuanlan.zhihu.com/p/125507748
Recommending What Video to Watch Next: A Multitask Ranking System
位置偏置
详情页的场景大多都面临着各种bias问题。包括position bias,user bias,trigger bias等。position bias指的是不同坑位天然的xx率指标都不同;user bias表示着不同用户天然的xx率不同,有的用户爱点,有的用户不爱点;trigger bias表示这个内容出现在不同的详情页下,xx率也并不相同。
Youtube这篇论文解决的是position bias的问题,下图以点击率为例,可以看出youtube的详情页场景的点击率面临着严重的position bias问题。
Recommending What Video to Watch Next: A Multitask Ranking System
解决方案分为几种:
1、一种是将做特征,训练的时候设置,预测的时候特征置固定值。
2、通过特征预测bias,然后加入的得分中。参考MMOE。
3、构建网络。参考华为工作。PAL: A Position-bias Aware Learning Framework for CTR Prediction in Live Recommender Systems

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









