



 本文详细探讨了Python中的字典数据结构,包括其广泛应用、Python对字典的优化以及散列表在字典和集合中的核心作用。还介绍了Mapping和MutableMapping抽象基类,以及字典的构造方法、映射方法和可散列类型的要求。
本文详细探讨了Python中的字典数据结构,包括其广泛应用、Python对字典的优化以及散列表在字典和集合中的核心作用。还介绍了Mapping和MutableMapping抽象基类,以及字典的构造方法、映射方法和可散列类型的要求。
字典这个数据结构活跃在所有 Python 程序的背后,即便你的源码里并没有直接用到它。
dict 类型不但在各种程序里广泛使用,它也是 Python 语言的基石。模块的命名空间、实例的属性和函数的关键字参数中都可以看到字典的身影。跟它有关的内置函数都在__builtins__.__dict__ 模块中。
正是因为字典至关重要,Python 对它的实现做了高度优化,而散列表则是字典类型性能出众的根本原因。
集合(set)的实现其实也依赖于散列表。反过来说,想要进一步理解集合和字典,就得先理解散列表的原理。
- 泛映射类型
collections.abc模块中有Mapping 和 MutableMapping这两个抽象基类,它们的作用是为dict和其他类似的类型定义形式接口(在Python 2.6到Python 3.2的版本中,这些类还不属于collections.abc模块,而是隶属于collections模块)
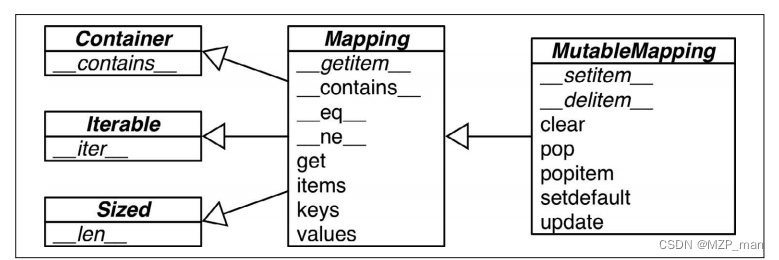
然而,非抽象映射类型一般不会直接继承这些抽象基类,它们会直接对dict或是collections.User.Dict进行扩展。这些抽象基类的主要作用是作为形式化的文档,它们定义了构建一个映射类型所需要的最基本的接口。然后它们还可以跟isinstance一起被用来
判定某个数据是不是广义上的映射类型。
from collections import abc
print(isinstance({}, abc.Mapping))
# True
这里用 isinstance 而不是 type 来检查某个参数是否为 dict 类型,因为这个参数有可能不是 dict,而是一个比较另类的映射类型。
标准库里的所有映射类型都是利用 dict 来实现的,因此它们有个共同的限制,即只有可散列的数据类型才能用作这些映射里的键(只有键有这个要求,值并不需要是可散列的数据类型)
- 什么是可散列的数据类型
在 Python 词汇表(https://docs.python.org/3/glossary.html#term-hashable)中,关于可散列类型的定义有这样一段话:
如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不变的,而且这个对象需要实现__hash__()方法。另外可散列对象还要有__qe__()方法,这样才能跟其他键做比较。如果两个可散列对象是相等的,那么它们的散列值一定是一样的……
原子不可变数据类型(str、bytes和数值类型)都是可散列类型,frozenset也是可散列的,因为根据其定义,frozenset里只能容纳可散列类型。元组的话,只有当一个元组包含的所有元素都是可散列类型的情况下,它才是可散列的。来看下面的元组 tt、
tl 和 tf:
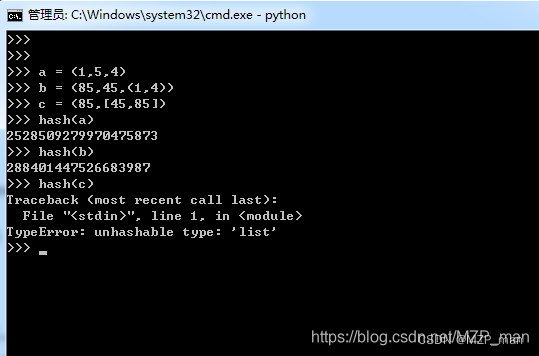
Python词汇表(https://docs.python.org/3/glossary.html#term-hashable)里还在说“Python里所有的不可变类
型都是可散列的”。这个说法其实是不准确的,比如虽然元组本身是不可变序列,它里面的元素可能是其他可变类型的引用
根据这些定义,字典提供了很多种构造方法“Built-in Types”(https://docs.python.org/3/library/stdtypes.html#mapping-types-dict)示例说明
a = dict(one=1, two=2, three=3)
b = {'one': 1, 'two': 2, 'three': 3}
c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
d = dict([('two', 2), ('one', 1), ('three', 3)])
e = dict({'three': 3, 'one': 1, 'two': 2})
print(a == b == c == d == e)
# True
除了这些字面句法和灵活的构造方法之外,字典推导(dict comprehension)也可以用来建造新 dict
- 常见的映射方法
映射类型的方法其实很丰富。下表为我们展示了dict、defaultdict和OrderedDict的常见方法,后面两个数据类型是dict的变种,位于collections模块内。
dict、collections.defaultdict和collections.OrderedDict这三种映射类型的方法列表(依然省略了继承自object的常见方法);可选参数以[…]表示
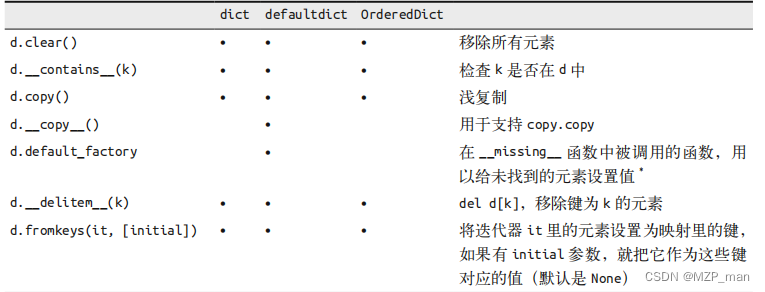

default_factory并不是一个方法,而是一个可调用对象(callable),它的值在defaultdict初始化的时候由用户设定。
OrderedDict.popitem()会移除字典里最先插入的元素(先进先出);同时这个方法还有一个可选的last参数,若为真,则会移除最后插入的元素(后进先出)。
上面的表格中,update 方法处理参数 m 的方式,是典型的“鸭子类型”。函数首先检查 m是否有 keys 方法,如果有,那么 update 函数就把它当作映射对象来处理。否则,函数会退一步,转而把 m 当作包含了键值对 (key, value) 元素的迭代器。Python 里大多数映射类型的构造方法都采用了类似的逻辑,因此你既可以用一个映射对象来新建一个映射对象,也可以用包含 (key, value) 元素的可迭代对象来初始化一个映射对象。

















 2082
2082



 到【灌水乐园】发言
到【灌水乐园】发言








