




目录
6.2.2远端仓库设置(推荐用gitee,github太容易卡了)
1. Linux 软件包管理器 yum
ps:本文章用的镜像是centos7.6,ubuntu的安装包管理器是apt什么的。原理基本都是一样的
1.1 软件包
在Linux下安装软件, 一个通常的办法是下载到程序的源代码, 并进行编译(容易出问题,不同环境编译要处理的问题很多), 得到可执行程序。
太麻烦了, 于是有些人把一些常用的软件提前编译好, 做成软件包(可以理解成windows上的安装程序),然后通过拷贝包的方式安装对应的程序/指令/工具,但是还是太麻烦了(要自己到处找包),于是有些人把软件包放在一个服务器上, 通过包管理器可以很方便的获取到这个编译好的软件包, 直接进行安装.
软件包和软件包管理器, 就好比 "App" 和 "应用商店" 这样的关系.
yum(Yellow dog Updater, Modified)是Linux下非常常用的一种包管理器. 主要应用在Fedora, RedHat,Centos等发行版上。yum本身只是linux预装的一个指令,可以搜索、下载、安装对应软件。
1.2 查看软件包
通过 yum list 命令可以罗列出当前一共有哪些软件包. 由于包的数目可能非常之多, 这里我们需要使用 grep 命令只筛选出我们关注的包. 例如
yum list | grep lrzsz
软件包名称: 主版本号.次版本号.源程序发行号-软件包的发行号.主机平台.cpu架构.
"x86_64" 后缀表示64位系统的安装包, "i686" 后缀表示32位系统安装包. 选择包时要和系统匹配。这个是系统的环境,另外windows和linux的安装包也是不能互通的。
"el7" 表示操作系统发行版的版本. "el7" 表示的是 centos7/redhat7. "el6" 表示 centos6/redhat6.
最后一列, os 表示的是 "软件源" 的名称, 类似于 "小米应用商店", "华为应用商店" 这样的概念

1.3 如何安装软件
通过 yum, 我们可以通过很简单的一条命令完成 lrzsz的安装
非root sudo yum install lrzsz root yum install lrzszyum 会自动找到都有哪些软件包需要下载, 这时候敲 "y" 确认安装.
出现 "complete" 字样, 说明安装完成
安装软件时由于需要向系统目录中写入内容, 一般需要 sudo 或者切到 root 账户下才能完成.
yum安装软件只能一个装完了再装另一个. 正在yum安装一个软件的过程中, 如果再尝试用yum安装另外一个软件, yum会报错.
如果 yum 报错, 请自行百度
1.4 如何卸载软件
sudo yum remove lrzsz yum remove lrzsz
关于 yum 的所有操作必须保证主机(虚拟机)网络畅通!!!
可以通过 ping 指令验证
ping www.baidu.com-------------------
不管是安装还是卸载,都会询问你y/n之类的
如果不想回回打y,可以给yum加个参数 -y。
yum -y remove lrzsz yum -y install lrzsz-------------------
好玩的软件:
yum install sl
如果不能安装,一要提权,二要先安装个epel-release
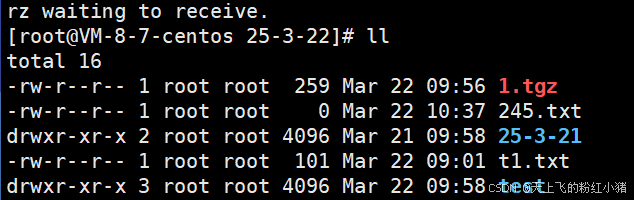
1.5 关于rzsz
yum install -y lrzsz
传入linux直接拖
传给windows,就sz 文件名
如果是linux互传,则scp 压缩包\文件 对面机器用户名@该机器公网ip。
然后输对应用户密码,即可。
有时候想在本地写程序,弄个centos虚拟机什么的,然后写完把程序打包压缩上传到云服务器,就是上传部署。
1.6 yum的生态
yum本身相当于应用商城,我们云服务器上的linux中的yum是没有额外软件的,当我们用yum进行下载软件的过程,本质是yum通过网络向远端的linux服务器寻求访问并下载软件。在这个过程中,联网是几乎必须的,像云服务器的linux不联网甚至我们自己都无法访问,本地的虚拟机中的linux也得联网才能用yum下载软件,虽然有些极少数情况是可以不联网下载安装软件的,但这里不多提。
这样又会延伸出新的问题,yum是怎么得知这个远端的存有软件的服务器的地址和相应下载链接呢。以及谁提供这些远端服务器和这些免费软件呢(注意,linux的开源导致了其生态基本都遵循开源,只有一些特殊情况才会进行收费)
linux的开源,意味着更多人的人愿意使用(安全等等),使用的人多意味着可以暴露更多的问题,(这些使用的人很多都是各个企业公司的开发者,他们依赖这个系统获得了收益,就更加愿意维护这个系统)有更多的人可以去解决问题,不断有人解决bug越说明这个系统好。而且人多,意味着官方文档更加合理丰富,社区的活跃度高,不断地有人开发软件。
其次,就是linux下的不同版本,像ubuntu、kali、centos都有不同的侧重点,这些系统内核都是linux只是使用给的内核版本可能不一样罢了。之所以不同系统有不同的人用,就是因为这些系统选择了不同的侧重点,吸引了不同群体使用,像centos可能有很多企业的人使用,kali有很多涉及网络安全的人使用,Ubuntu会吸引很多学生群体。不同的群体,让社区的氛围不一样,产生的技术文档趋向性和开发的软件也不一样(像centos的社区中就会有很多跟企业相关的软件,kali会有很多涉及网络安全的软件)。
1.6.1 谁提供了这些远端服务器和免费软件
根据上述其实就能理解,谁提供了这些远端服务器,那就是这些用户群体中的一部分人,这些人不缺钱,但他们希望这个生态更加好,所以捐赠等形式提供这些服务器。
同理,为什么有人免费开发软件,因为这也是一种维护生态,让生态更好的方式。
上述可以形象的理解,用户群体的增多,既得利益者为了维护生态、让生态更好,会以各种形式进行支持,包括但不限于提供远端服务器、开发软件、修复bug等等。
1.6.2 linux下载软件的过程
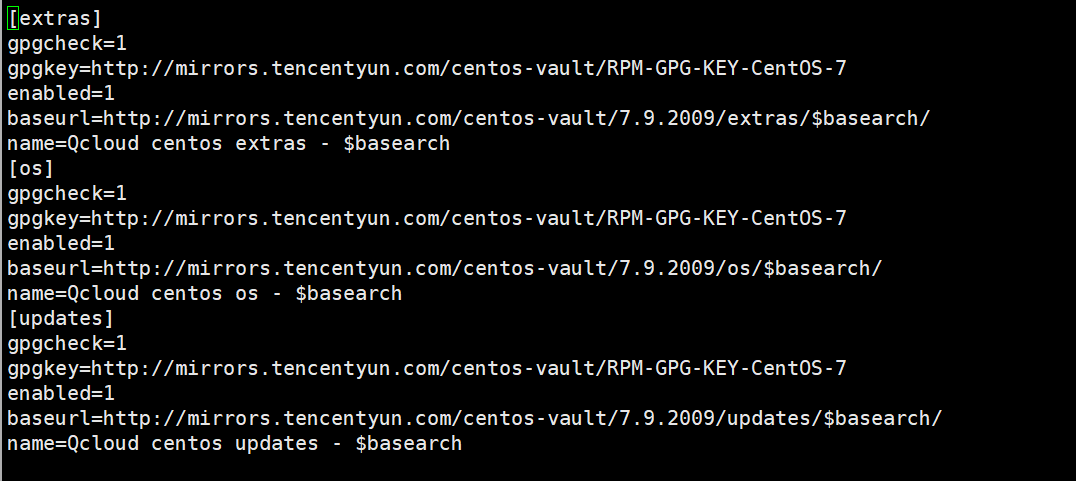
yum中存储着一些安装源
这里的base和epel都是源,前者是标准源,后者是扩展源,可以理解为配置文件,这些源里就有相应的一些镜像源的路径。base就是基础源,可以理解为c/c++的标准库,而epel就是扩展源,可以理解为c/c++的Boost库,基础源里面放的都是相对稳定,使用时间足够久的软件,扩展源里放的都是相对新颖,但没有足够的使用历史,稳定性不能保证的软件。
如果没有epel,可以yum install -y epel-release
如图,是我在腾讯云服务器下centos7.6中的yum的base源里的内容。
从路径名就能看出,很明显是腾讯自己的软件源路径。
-----------------------------------------------------------------------------------
这个base配置文件是可以改的,基本上云服务器的不用担心,因为都是会配置对应的国内镜像源,只有虚拟机需要自己改下(虚拟机用的系统镜像如果是纯净的,那么访问的链接基本都是国外的相应官网,访问会很慢),改变的具体方法可以去搜,这里只是罗列下可能用到的命令。
yum工具在每次安装指定软件包的时候,都会检测源服务器上的软件包信息,为了便捷不用每次都去搜索软件包信息,因此使用 yum makecache将软件包信息缓存到本地,使用 yum clean all 清理老旧的缓存信息。
yum search 用于在搜索包含有指定关键字的软件包
yum -y update:升级所有包同时,也升级软件和系统内核;
yum -y upgrade:只升级所有包,不升级软件和系统内核,软件和内核保持原样。
-------------------------------------------------------------------------------------
国内有很多源,大多都是把国外的源下载到国内,方便国内的人访问,有很多,像是阿里云的、腾讯的、清华大学等等,可以直接搜索。
-----------------------------------------------------------------------------------------
yum下载软件的过程,就是通过访问这些链接,然后通过关键字搜索拼凑出一个访问路径,从而下载对应的软件。

2.编辑器vim
我们学过编程语言,要写代码(编辑器),编译代码(编译器),调试代码,等等
,我们平时在windows系统环境下,使用过很多开发软件,像是vs,vscode等等。vs是一个典型的集成式开发环境,里面集成了编辑器、编译器等等。
而linux下虽然也有图形化或集成式的开发环境,但我们先介绍指令层面的开发工具。
2.1 基本概念
首先vi/vim都是多模式编辑器,vim是vi的升级版本,兼容vi所有指令,额外增加新的特性,比如语法加亮,可视化操作可以在终端和x window,mac os,windows等上运行。
其次,vim一共有12种模式,但我这里只会讲3种常规一点的模式,其他可以自行百度(实在不行AI也不是不可以),6种basic模式,6种additional模式
简单介绍下3个模式(命令、插入、底行)
命令(也可以说正常、普通)模式,主要是控制屏幕光标的移动,字符,字或行的删除,移动复制某区段及 进入插入模式(insert mode)或者进入底行模式(last line mode)
插入模式,只有在insert mode下,才可以做文字输入,按 esc 键可回到命令行模式,这个模式也是使用最频繁的模式。
底行(也可以翻译是末行模式),主要是进行文件保存或退出,也可以进行文件替换,找字符串,列出行号等操作。在命令模式下 'shift' + ';' 即可进入该模式。注意,其实是:,只是我们键盘不加shift只会输出 ; ,所以才要shift+ ; 。如果要回到命令模式,还是esc。
插入和底行之间,一般是不能切换的,必须先经过命令模式。
如果要查看所有模式,打开vim,进入底边模式,直接输入 help vim-modes
2.2 vim基本操作
vim 文件名,即可进入vim编辑页面
默认刚进入vim编辑页面时,是处于命令模式的
注意,插入模式下,只能输入文字,但是可以键盘左右上下挪动光标,默认不能用鼠标(早期鼠标不普及),现在可以通过配置改
光标的位置取决于上一次退出的位置,如果是新文件,就默认最开始。
但也可以通过 vim filename +num 的形式一打开光标就定在num行开头
如vim test.c +11

2.2.1 命令模式
切换模式
可以通过 a/i/o进入插入模式,不同按键效果不同。
a:从目前光标所在位置的下一个位置开始输入文字。
o:插入新的一行,从行首开始输入文字。
i:从光标当前位置开始输入文字
还有别的,但这里只罗列常用的
-------------------------------------------------------------------------
按 esc 键可以从插入模式回到命令模式
-------------------------------------------------------------------------
移动光标
vim是可以在命令模式下直接用键盘的上下左右键移动光标的,但正规的vim是用小写英文字母 h j k l,分别控制光标 左、下、上、右移一格。(早期键盘没有上下左右键,只能用这4个字母)
除此之外,还有别的按键
G :移动到文章的最后。
$ :移动到光标所在行的 行尾。
^ :移动到光标所在行的“行首”
w:光标跳到下个字的开头 字可以理解为单词等等
e:光标跳到下个字的字尾
b:光标回到上个字的开头
#l:光标移到该⾏的第#个位置,如:5l,56l
gg:进入到文本开始
shift+g:进入文本末端
ctrl+b:屏幕往“后”移动一页
ctrl+f:屏幕往“前”移动一页
ctrl+u:屏幕往“后”移动半页
ctrl+d:屏幕往“前”移动半页------------------------------------------------------------------------------------、
删除文字
「x」:每按⼀次,删除光标所在位置的⼀个字符
「#x」:例如,「6x」表⽰删除光标所在位置的“后面(包含自己在内)”6个字符
「X」:大写的X,每按⼀次,删除光标所在位置的“前面”⼀个字符(不包含自己)
「#X」:例如,「20X」表示删除光标所在位置的“前面”20个字符(不包含自己)「dd」:删除光标所在行
「#dd」:从光标所在行开始删除#行--------------------------------------------------------------------------------------
复制剪切
「yw」:将光标所在之处到字尾的字符复制到缓冲区中。
「#yw」:复制#个字到缓冲区
「yy」:复制光标所在行到缓冲区。
「#yy」:例如,「6yy」表⽰拷贝从光标所在的该行“往下数”6行⽂字。
「p」:将缓冲区内的字符贴到光标所在位置。注意:所有与“y”有关的复制命令都必须
与“p”配合才能完成复制与粘贴功能。「#p」:复制#次
dd在不p的时候,可以就理解为删除,但是dd之后再p,就可以实现剪切(可以多行剪切)。
--------------------------------------------------------------------------------------
替换(替换模式)
「r」:替换光标所在处的字符。先 r一次,再输入要替换成的字符
「#r」:替换光标所在处开始往后#个字符。注意这样#个字符都会是替换成功后的字符
「R」:进入了替换模式,替换光标所到之处的字符,esc回到命令模式。--------------------------------------------------------------------------------------
撤销上⼀次操作
「u」:如果您误执行⼀个命令,可以马上按下「u」,回到上⼀个操作。按多次“u”可以执行
多次回复。
「ctrl + r」: 撤销的恢复注意,只要没有退出当前vim编辑界面,就算用w保存了文件,依旧可以进行撤销和恢复撤销,只有退出了之后重进,才会重置。
--------------------------------------------------------------------------------------
更改
「cw」:更改光标所在处的字到字尾处
「c#w」:例如,「c3w」表⽰更改3个字--------------------------------------------------------------------------------------
跳至指定的行
「ctrl」+「g」列出光标所在行的行号。
「#G」:例如,「15G」,表示移动光标至文章的第15行行首。
--------------------------------------------------------------------------------------
大小写转换
「shift」+「`」即「~」可以实现大小写转换。
每转换一次光标就会向右移动一次,一直到当前行结束。
--------------------------------------------------------------------------------------
高亮查找
「shift」+「3」即「#」,可以实现高亮当前的词/字,按n或者「#」查找。
常用于函数名等的查找。取消可以底行模式输入nohl
--------------------------------------------------------------------------------------
保存退出vim
「shift」+「zz」即「ZZ」,就是wq,即底行模式下的wq,但是,因为命令模式的命令我们是看不到究竟输了什么,很容易出奇怪的问题,建议保存退出还是在底行模式下wq
2.2.2底行模式
列出行号
「set nu」: 输入「set nu」后,会在文件中的每一行前面列出行号。
「set nonu」: 输入「set nonu」后,会取消在文件中的每一行前面列出行号。
--------------------------------------------------------------------------------------
跳到文件中的某一行
「#」:「#」号表示⼀个数字,在冒号后输入一个数字,再按回车键就会跳到该行了,如输入数字15,再回车,就会跳到文章的第15行。
--------------------------------------------------------------------------------------
查找字符
「/关键字」: 先按「/」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以⼀直按「n」会往后寻找到您要的关键字为止。
「?关键字」:先按「?」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按「n」会往前寻找到您要的关键字为止。--------------------------------------------------------------------------------------
保存文件
「w」: 在冒号输入字母「w」就可以将文件保存起来
--------------------------------------------------------------------------------------
替换
:s 表示substitute,也就是替换, 格式为以下
:[range]s[ubstitute]/{pattern}/{string}/[flags] [count]
range 表示区间;「%」 用于表示全文, 「2,3」 表示从第2行开始到第3行
{pattern} 表示字符串匹配规则,要匹配什么样的字符串 , 比如^a 表示以a字符起始的字符串
{string} 表示要将匹配到的字符串替换为的新的string字符串
[flags] s_flags中,g比较常用,通常使用g表示全部替换,默认如果不给的话,表示只替换一次
[count] 表示在一行中匹配多少次,很少会用到....
如果想要将文件中所有 nihao 替换为 hello 则命令为: %s/nihao/hello/g
--------------------------------------------------------------------------------------
打印
:p 用于打印指定区间的行
:[range]p[rint] [flags]
--------------------------------------------------------------------------------------
指定行添加文本
:i 在指定行上方添加文本
:{range}i[nsert][!]
--------------------------------------------------------------------------------------
离开vim
「q」:按「q」就是退出,如果无法离开vim,可以在「q」后跟一个「!」强制离开vim。
「wq」:一般建议离开时,搭配「w」⼀起使用,这样在退出的时候还可以保存文件。!就是强制执行,有时候遇到权限不符合(root强行对无权限的文件更改),或者说文件同时有多个人在编辑,会不让用w或q,这时候不管是普通用户还是root用户,都是加「!」。
----------------------------------------------------------------------------------------
特殊
「!」后面跟命令,可以直接执行shell的命令,比如!man printf,可以直接在手册里寻找printf的用法,退出时按q,回到shell页面,再输入任意键,即可回到vim编辑界面。
像是编译,运行的命令,也可以这样。
另外, 补充下gcc编译c文件的时候,会告诉报错位置,给出调整方案(基础问题可以解决)
-----------------------------------------------------------------------------------------
vs
在底行模式中,输入vs 文件名,比如vs pit.c
可以这样打开文件。可以打开多个文件
注意,这时候底边模式的命令行只有一个,是跟着我们的光标走的。可以用「ctrl」+「ww」来切换光标所在文件
注意,如果文件是未创建的文件,且我们直接用底边模式退出,那么外面同级目录下也不会出现这个文件,如果我们选择保存,那么就会在同级目录下出现这个文件。

2.2.3 视图模式
批量化注释
命令模式下 按ctrl +v 即可进入视图模式
视图模式下,移动光标
让光标囊括需要注释的行
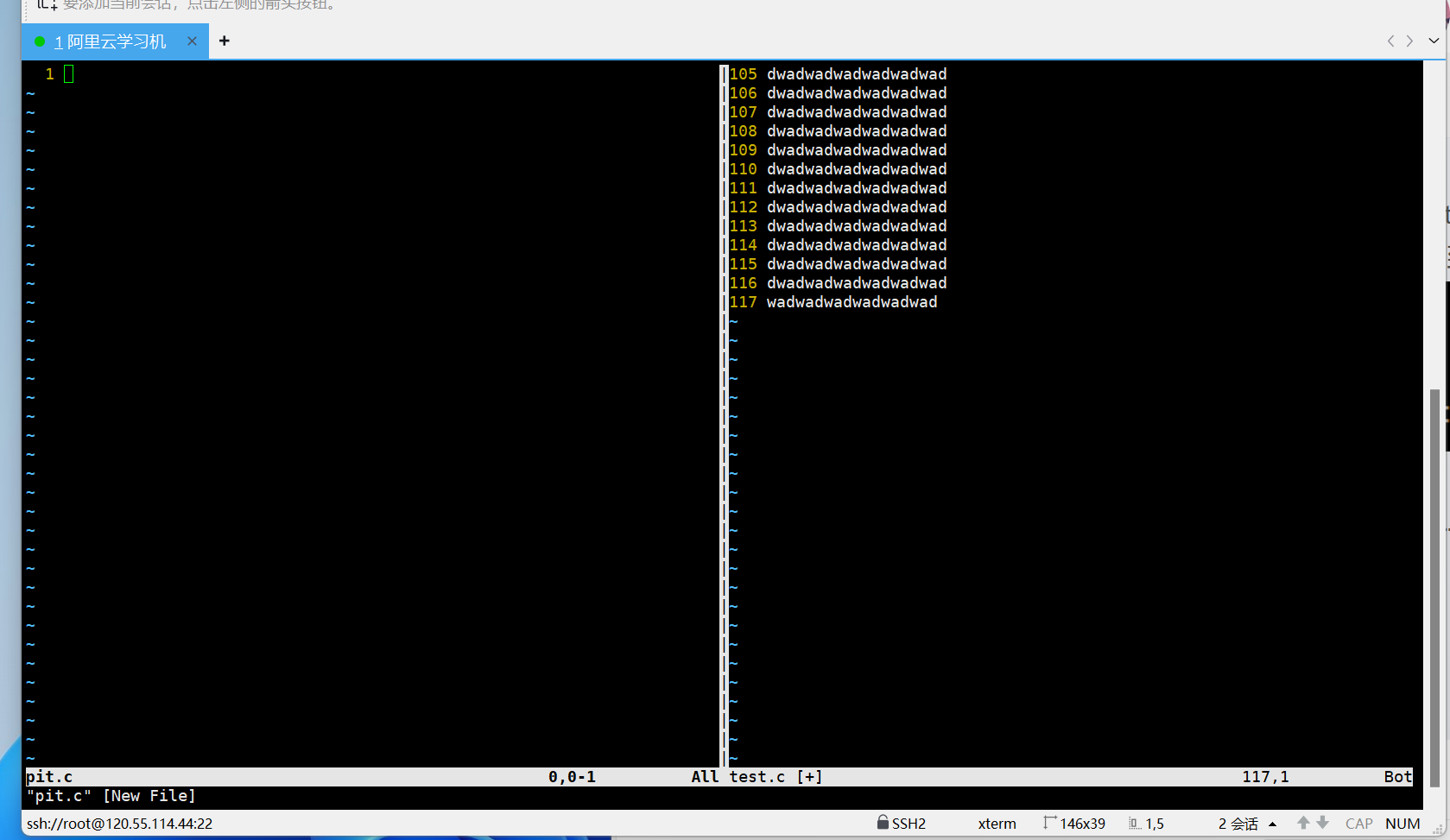
然后按 shift + i 即I,即可马上进入插入模式,这时候光标会自动跳到起始行,直接打//,然后按esc,结果如下。
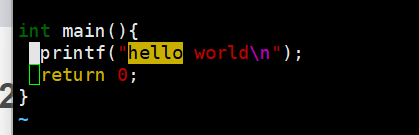
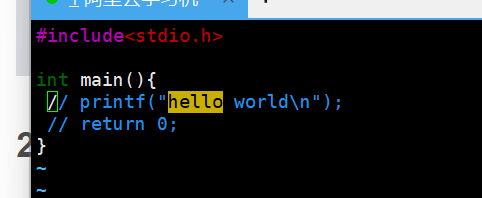
批量化取消注释
进入视图模式,移动光标,涵盖要取消注释的所有注释符号,按d即可
2.2.4 特殊情况
如果我们在进入vim编辑页面的情况下,没有正常 保存 退出,而是因为 服务器断开连接,输入奇怪的组合键被迫强行关闭终端等等。
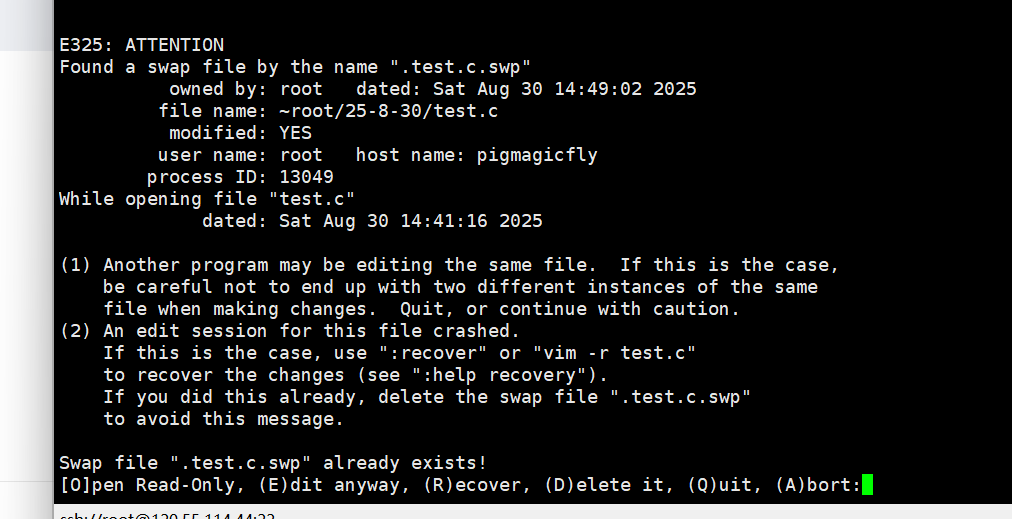
当我们再次以vim形式进入这个文件的时候会这样
vim对于这种情况会将我们为保存的内容,以同名+.swp的隐藏文件形式额外保存在同级目录下,这里我们可以输入R加回车,就可以把为保存的内容显示出来,但下次进入还是这个界面,因为这个swp文件还是存在,所以我们可以输入D。
注意,不能一开始就是D,这样的话,未保存的内容就直接没了,只能回到上一个保存的版本。如果未保存的内容是需要的,可以先R,再D。
当然,如果未保存的内容是不需要的,也可以直接删除这个.swp文件。
注意,这个特殊情况,是针对文件内容被修改了,但未保存直接强行退出了才会有的,如果未对文件进行内容修改,是不会出现这个情况的。
2.3配置文件
在目录/etc/下面,有个名为vimrc的文件,这是系统中公共的vim配置文件,这是系统中公共的vim配置文件,对所有用户都有效。
而在每个用户的家目录下,都可以建立私有的配置文件,命名为:".vimrc" 。例如,/root目录下,通常已经存在一个.vimrc文件,如果不存在就手动创建。
如果要打开这个文件,可以用vim打开。vim .vimrc
如果不确定自己的配置对不对,可以在.vimrc文件里加入这几个:
语法高亮 syntax on
显示行号 set nu
设置缩进的空格数为4 set shiftwidth=4
类似的配置选项有很多,可以自行百度搜索,也可以用插件。
但这里还是推荐自动化配置,快速,而且不麻烦。
3.编译器gcc/g++
最简单的用法,就是编写一个.c的c语言文件,比如test.c。然后输入gcc test.c,会默认生成一个可执行程序,a.out。然后直接执行./a.out即可。
如果想要指定这个可执行程序的名称gcc test.c -o filename 即可。但注意,-o选项只对后面的一个名字起反应,所以可以这样gcc -o filename test.c
而g++是对c++的文件进行编译,但是我们要知道,c++是兼容c的,所以你用g++编译器也是可以编译c语言文件的。但gcc不能编译.cpp文件
gcc和g++的选项都是一样的。
注意,有些云服务器可能没有g++,只有gcc,可以手动安装,centos可以sudo yum install gcc-c++


语言分机器语言、汇编语言、高级语言
语言和编译器之间是有一个自举的过程。比如c语言不存在的时候,这时候只有汇编语言和汇编语言写的编译器。这时有人发明c语言,但没有编译器可以把c语言翻译成汇编再翻译成机器语言,所以这时候先用汇编语言写了一个把c语言翻译成汇编语言的编译器。
然后再用c语言写了一个编译器,这个编译器是用于把c语言编译成汇编语言,这个编译器本事是c语言写的,再把这个c语言的编译器交给汇编语言写的编译c语言的编译器形成软件。
之后,c语言写的程序就只需要丢给这个c语言的编译器即可。
形象的理解就是:已经有成熟的汇编转机器语言形成软件的过程了——发明了c语言——用汇编语言写一个c转汇编 的编译器——能用c语言写软件了——用c语言写一个c转汇编的编译器——这个编译器交给前面用汇编语言的写的c转汇编的编译器——c语言写的c转汇编的编译器正式成为软件。
之后编译器的优化,也是自举的过程,先对v1版本优化,新的编译器用v1编译,形成v2。
总结一下,语言肯定是比相应语言写的编译器早出现,相应语言的编译器是需要相应的自举过程的,自举过程,自举的过程是可以套在汇编跟机器语言,高级语言跟汇编语言之间的。
这样一看语言的发展其实就是在前人基础上做加法,比如c语言的编译器,不需要考虑怎么把汇编语言变成机器语言,c语言的编译器只要考虑怎么把c语言翻译成汇编语言即可,之后只要把汇编语言丢给 已经成熟的 用汇编语言写的 用于汇编语言转机器语言的编译器 即可
可以理解为阶梯式递进。
3.1 gcc/g++编译选项
gcc和g++除了适用范围不一样外,几乎一模一样,就不分开说了。
关于编译过程的详细内容,可以参考我的关于预处理-优快云博客和C/C++编译与运行环境详解:从源码到可执行程序-优快云博客,当然自行百度也行
这里只进行补充说明。
编译过程为 扫描程序-->语法分析-->语义分析-->源代码优化-->代码生成器-->目标代码优化;
扫描程序进行词法分析,从左向右,从上往下扫描源程序字符,识别出各个单词,确定单词类型
语法分析是根据语法规则,将输入的语句构建出分析树,或者语法树,也就是分析树parse tree或者语法树syntax tree
语义分析是根据上下文分析函数返回值类型是否对应这种语义检测,可以理解语法分析就是描述一个句子主宾谓是否符合规则,而语义用于检测句子的意思是否是正确的
目标代码生成指的是,把中间代码变换成为特定机器上的低级语言代码。
3.1.1预处理(进行宏替换)
预处理功能主要包括宏替换,头文件展开,条件编译,去注释等。
条件编译主要是对程序进行动态裁剪,比如软件的专业版和社区版,维护一份代码即可,通过条件编译对这份代码进行裁剪,形成专业版和社区版
预处理指令是以#号开头的代码行。
预处理阶段编译选项例子:
gcc -E test.c -o hello.i
选项“-E”,该选项的作用是让 gcc 在预处理结束后停止编译过程。
选项“-o”是指目标文件,“.i”文件为已经过预处理的C原始程序。
3.1.2编译(生成汇编)
在这个阶段中,gcc 首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,gcc 把代码翻译成汇编语言。
可以使用“-S”选项来进行查看,该选项只进行编译而不进行汇编,生成汇编代码。
例子:gcc -S test.i -o test.s
3.1.3汇编(生成机器可识别代码)
汇编阶段是把编译阶段生成的“.s”文件转成目标文件
在此可使用选项“-c”就可看到汇编代码已转化为“.o”的二进制目标代码(全名 可重定位目标二进制文件)了。linux下后缀是.o,win下是.obj注意,这个二进制目标文件是不能执行的。
例子:gcc -c test.s -o test.o
3.1.4链接(生成可执行文件或库文件)
成功编译之后,就进入链接阶段
例子:
gcc test.o -o hello
3.2动静态链接和库
我们的C程序中,并没有定义“printf”的函数实现,且在预编译中包含的“stdio.h”中也只有该函数的声明,而没有定义函数的实现,那么,是在哪里实现“printf”函数的呢?
最后的答案是:系统把这些函数实现都被做到名为 libc.so.6 的库文件中去了,在没有特别指定
时,gcc 会到系统默认的搜索路径“/usr/lib”下进行查找,也就是链接到 libc.so.6 库文件中去,这样就能实现函数“printf”了,而这也就是链接的作用。不过我上面的真正的路径其实是在/usr/lib64下的库文件里。库的最重要的作用,是加快开发效率,因为库里面的函数都是已经提前写好的,不需要重新写,后来人会用就好
----------------------------------------------------------------------
一般云服务器里没有静态库,可以手动yum安装一下
yum install glibc-static libstdc++-static -y
glibc-static是c的静态库,libstdc++-static是c++的静态库
如果没有静态库,强行gcc静态链接,会反馈
/usr/bin/ld: cannot find -lc
ld是链接器,-l是gcc的一个选项
意思是缺少c的库。
安装完后,在/lib64目录下会多出libc.a,是c的静态库
----------------------------------------------------------------------本文章不会讲完动静态,后续在基础IO中继续补充。
3.2.1静态库和动态库
静态库是指编译链接时,把库文件的代码全部加入到可执行文件中。其后缀名一般为“.a”
动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库。动态库一般后缀名为“.so”,如前面所述的
libc.so.6 就是动态库。gcc 在编译时默认使用动态库。完成了链接之后,gcc 就可以生成可执行文件,gcc test.o -o 1.exe--------------------------------------------------------
gcc默认生成的二进制程序,是动态链接的,这点可以通过file命令验证。
其中executable表示可执行程序,dynamically linked表示是动态链接,uses shared libs是共享库也称动态库
--------------------------------------------------------
静态库是这样的
ldd告诉我们,这个可执行程序不依赖动态库
file告诉我们,这个可执行程序是依靠静态库的。
-------------------------------------
linux下,动态库 *.so,静态库 *.a
win下,动态库*.dll , 静态库 *.lib
-------------------------------------
要注意,其实库文件的后缀看起来很奇怪,但其实只是表象,像写一个程序时的声明和定义分离,比如有个test.h和test.c,所谓的库文件,就是先把test.c编译成test.o文件,再把.o文件打包,变成库文件,所谓的链接,其实就是把多个.o文件相连


3.2.2动静态链接
粗略的理解,链接动态库的过程,就是动态链接,链接静态库就是静态链接
静态链接
在我们的实际开发中,不可能将所有代码放在一个源文件中,所以会出现多个源文件,而且多个源文件之间不是独立的,而会存在多种依赖关系,如一个源文件可能要调用另一个源文件中定义的函数,但是每个源文件都是独立编译的,即每个*.c文件会形成⼀个*.o文件,为了满足前面说的依赖关系,则需要将这些源文件产生的目标文件链接,从而形成一个可以执行的程序。这个链接的过程就是静态链接。
静态链接更加形象的理解,那就是,程序在编译时,把静态库中需要的库文件的代码拷贝一份放入了程序中,这样当可执行程序想调用某个函数的时候,可以直接调用。
动态链接
动态链接的基本思想是把程序按照模块拆分成各个相对独立部分,在程序运行时才将它们链接在一起形成一个完整的程序,而不是像静态链接一样把所有程序模块都链接成一个单独的可执行文件。
动态链接其实远比静态链接要常用得多。比如我们查看下这个可执行程序依赖的动态库,会发现它就用到了一个c动态链接库:
ldd是用于打印程序或者库文件所依赖的共享库列表。
动态链接,更加形象的理解,就是可执行程序本身不包含库文件里的代码,只是在编译器编译的时候,将要调用哪些动态库,哪些函数记录在了可执行程序中,可执行程序运行时,操作系统的加载器会去系统中找相应的动态库,将动态库加载到内存,根据动态库中的函数实际地址,修正程序中的调用点,当可执行程序中的某个代码要调用函数的时候,cpu会直接跳到相应的地址上去执行函数,执行完毕再返回。

静态库/链接的优点:
在运行时不依赖库,同类型平台都可以直接运行使用。
在可执行程序中已经具备了所有执行程序所需要的任何东西,在执行的时候运行速度快。静态库/链接的缺点很明显:
浪费空间:因为每个可执行程序中对所有需要的目标文件都要有一份副本,所以如果多个程序对同一个目标文件都有依赖,如多个程序中都调用了printf()函数,则这多个程序中都含有
printf.o,那么当执行可执行程序,程序加载到内存里,同一个目标文件都在内存存在多个副本;文件内容较大:生成的文件比较大。
上面两种都会造成资源的浪费,比如磁盘、内存、网络等。
其中1.exe是动态链接,2.exe是静态链接。可以看到,1.exe只占8480B,2.exe占861288B。占用空间大,意味着下载时间长、对网络要求高,占磁盘空间,加载到内存时占内存空间。
更新比较困难:因为每当库函数的代码修改了,这个时候就需要重新进行编译链接形成可执行程序。

动态库/链接的出现解决了静态链接中提到问题。
动态库/链接的优点:
不把库文件的代码都拷贝进入可执行程序,这样可以节省系统的开销(包括磁盘、内存、网络),不会出现太多重复代码(调用的函数永远都是那一个,而且不用拷贝到可执行程序里,而是放在动态库里)。
动态库/链接的缺点:
对动态库的依赖很强,一旦动态库丢失,所有使用这个库的程序都无法运行(可以参考运行游戏的时候,有些报错信息中提示的某.dll文件缺失)。
另外,由于每次都要去动态库里找,肯定会有额外的开销,所以运行速度相较于静态链接,肯定是慢一点,但也是慢一点,相比其优点可以忽略不计。
补充
怎么认识一个库,最基本的就是靠库文件名字,像上面的libc.so.6,把lib这个前缀去掉(linux下所有库文件基本都会带lib前缀),把so.6也去掉(代表动态库),剩下的c,代表的,这个库文件就是c语言的标准库。
---------------------------------------
注意,就算一个.c文件里面没有内容,只要用gcc编译,那么也会链接到相应的库。
---------------------------------------
为什么我们的linux一开始就能写c语言代码,就是因为linux自带了很多的c语言头文件以及其他的常见的一些语言头文件(像是c++和python)。可以在/usr/include下找到他们
像前面说的,除了头文件还需要相应的库,在/lib64/lib下就有很多自带的库,像是c的库等等。
为什么一开始就会有这些内容呢,因为linux的内核很多都是c语言写的,像是指令什么的,还有些内容可能是其他语言写的,比如python,因此就需要提前有这些头文件和库文件
-------------------------------------
题外话,这也是为啥在win下要进行开发,ide需要下载一些内容,其中很大部分就是这些头文件和库文件,比如vs2022。注意不同ide写同一个语言,可能会重复安装,这是因为这些ide进行编译运行的时候会去找自己下的这些头文件和库文件,每个ide装的位置可能都不一样,他们只知道自己下的头文件和库文件。不过vscode会好点,你可以选择手动配置路径,避免重复利用。
3.3gcc常用选项
-E 只激活预处理,不生成文件,需要把它重定向到一个输出文件里面,用例看上面。生成.i文件
-S 编译到汇编语言不进行汇编和链接 .s文件
-c 编译到目标代码 .o文件--------上面三个可以用键盘上的esc键记忆,唯一注意的是S要大写,文件后缀可以用镜头文件iso记忆
-o 文件输出到文件
-static 此选项对生成的文件采用静态链接
-g 生成调试信息。GNU 调试器可利用该信息。
-shared 此选项将尽量使用动态库,所以生成文件比较小,但是需要系统有动态库.
-std=c99 可以改变语言标准,默认的c90在某些地方,比如for循环里面定义变量是不支持的。---------------------------------------------------------------------------------------------------------------------
3.3.1编译器优化
-O0、-O1、-O2、-O3 :编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高
死代码删除是编译最优化技术,指的是移除根本执行不到的代码,或者对程序运行结果没有影响的代码,而并不是删除被注释的代码
内联函数,也叫编译时期展开函数, 指的是建议编译器将内联函数体插入并取代每一处调用函数的地方,从而节省函数调用带来的成本,使用方式类似于宏,但是与宏不同的是内联函数拥有参数类型的校验,以及调试信息,而宏只是文本替换而已。
for循环的循环控制变量,通常被cpu访问频繁,因此如果调度到寄存器中进行访问则不用每次从内存中取出数据,可以提高访问效率
强度削弱是指执行时间较短的指令等价的替代执行时间较长的指令,比如 num % 128 与 num & 127 相较,则明显&127更加轻量-----------------------------------------------------------------------------------------------------------------------
-w 不生成任何警告信息。
-Wall 生成所有警告信息。
4.自动化构建-make/Makefile
4.1介绍
⼀个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作
makefile带来的好处就是⸺“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
make是⼀个命令工具,是⼀个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了⼀种在工程方面的编译方法。
make是一条命令(系统本身就已经提供了),makefile是一个文件,两个搭配使用,完成项目自动化构建。makefile文件中,保存了编译器和链接器的参数选项,并且描述了所有源文件之间的关系。make程序会读取makefile文件中的数据,然后根据规则调用编译器,汇编器,链接器产生最后的输出。
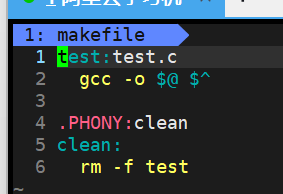
Makefile里主要包含了五个东西:显式规则、隐晦规则、变量定义、文件指示和注释
显式规则说明了,如何生成一个或多个目标文件。
make有自动推导的功能,所以隐晦的规则可以让我们比较粗糙地简略地书写makefile,比如源文件与目标文件之间的时间关系判断之类
在makefile中可以定义变量,当makefile被执行时,其中的变量都会被扩展到相应的引用位置上,通常使用 $(var) 表示引用变量
文件指示。包含在一个makefile中引用另一个makefile,类似C语言中的include;
注释,makefile中可以使用 # 在行首表示行注释
默认的情况下,make命令会在当前目录下按顺序找寻文件名为“GNUmakefile”、“makefile”、“Makefile”的文件
4.2基本用法
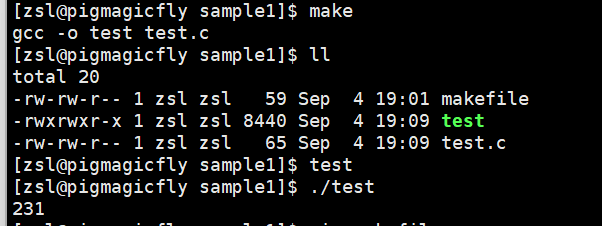
我们可以随便写一份代码
#include<stdio.h> int main(){ printf("hello\n"); return 0; }其次,创建一个名为Makefile/makefile的文件
效果如下
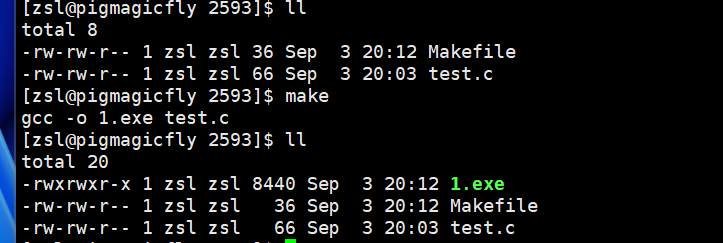
注意,如果重复使用make且不修改test.c,则会提示你1.exe已经是最新的了
问题来了,make和makefile怎么知道是最新的。
答案是通过对比时间比出来的,只要可执行程序的最近修改时间比所有源文件的最近修改时间新,说明它就是最新的。在一般而言,两者的最近修改时间是不可能相同的。这个修改的时间是modify,具体看下面。
在vs中,如果是多个源文件形成一个可执行程序,且我们只修改了其中一两个源文件,这时我们重新再编译,是旧的未修改的源文件形成的.obj文件(这个obj可能不会重新生成,而是直接用旧的)和新修改的源文件生成的obj文件一起链接到库,然后形成一个可执行程序。
vs中,有时候我们修改了一处bug,但发现运行后还是错的,很可能是vs没有识别好时间,导致用的还是旧的obj文件,这时候把项目的临时文件(包含了obj等文件)清理一下就行
4.2.1依赖关系
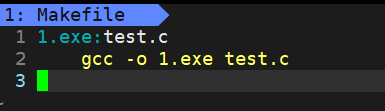
1.exe文件,是依赖于test.c文件生成的。
:左侧是目标文件,右侧是依赖文件列表(一个可执行程序可能由多个源文件生成,这些文件之间用空格隔开)
4.2.2依赖方法
gcc -o 1.exe test.c就是依赖的方法。
依赖关系说明了2个文件之间存在的某种关系,这个关系是为什么要执行依赖方法的依据,而依赖方法,则是具体的2个文件之间出现了什么操作。
注意,建议依赖方法跟依赖关系连着写,不要中间空一行。
另外,方法前面是一个tab,不是几个空格。
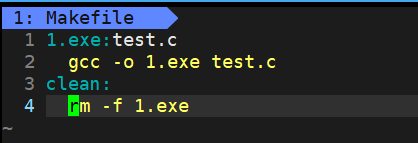
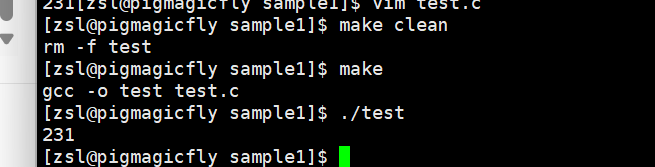
4.2.3项目的清理
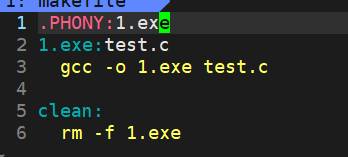
像是我们生成的可执行程序,我们很多时候不需要保留,比如调试的时候,所以项目里面是需要清理的,我们可以这样
我们在这里又定义了一个依赖关系和其方法,关系中没有依赖文件,而方法就是执行删除文件的操作。
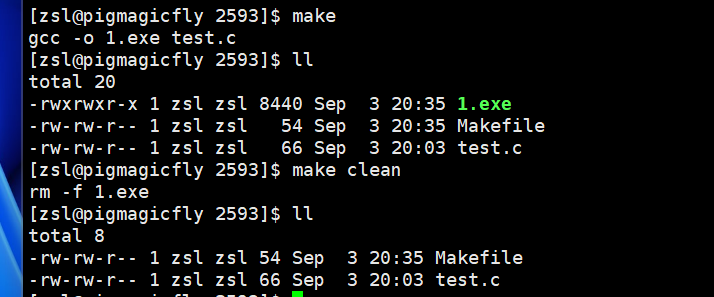
如图可以看到,我们是通过make clean执行的依赖。但是我们要执行1.exe依赖的时候,是不需要make 1.exe的。原因是,单单的make默认会执行makefile中第一个依赖。当我们要显示调用某个依赖的时候,就在make后面加对应目标文件。即make和makefile形成目标文件的时候,默认是从上到下扫描makefile文件,默认形成的是第一个目标文件
文件的时间属性
文件 = 内容 + 属性
Modify: 内容变更,时间更新Change:属性变更,时间更新
Access:常指的是文件最近一次被访问的时间。
-------------------------------------------------------------------------------------------
其中的属性,
就是这里罗列的内容。
注意的是,我们平时对文件内容修改,很有可能是modify和change一起变,modify不用解释,change会一起改变的原因,就是文件的大小可能会有变化,所以change也会一起变。
-------------------------------------------------------------------------------------------
Access并不一定每次访问都会更新时间,在Linux的早期版本中,每当文件被访问时,其时间都会更新,而平时相比修改内容和属性,访问文件才是最频繁的操作,而access本身也是一种属性,频繁更新意味着系统要对文件进行操作,文件数量少还好,文件数量多,就容易影响操作系统的效率,所以后面更改了更新的策略,具体不多说,有兴趣可以自行百度。
-------------------------------------------------------------------------------------------
时间属性也是可以我们手动强制刷新的,即使我们没有修改内容和属性。用touch filename的形式,因为文件已经存在,所以只会强行更改3个时间属性为最新。
这样遇到不让make的时候,就可以这样快速达到修改时间的效果。
---------------------------------------------------------------------------------------------

但其实,我们还可以依赖一个叫伪目标的东西,可以让make忽略源文件和可执行目标文件的Modify时间对比。做到总是被执行。具体可以看下面的语法补充。
不过建议把clean设置成伪目标,因为当需要clean的时候,说明一定是要删的。但生成可执行程序还是建议遵循make的提示(因为当文件多了之后,如果每次都重新编译,会非常浪费时间)。
4.3工作过程
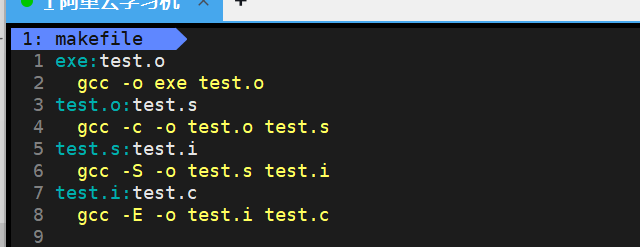
make的工作过程是先去当前目录中找Makefile或makefile的文件,找到后,进入其中,假如内部是这样的。
根据我们之前make时的命令,选择最终要生成的目标文件,比如我们是直接make,那么默认就是第一个目标文件,即exe。
如果目标文件的依赖文件列表为空则直接形成目标文件。
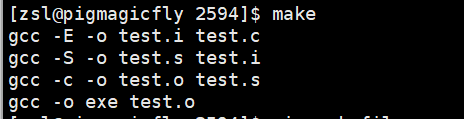
如果不为空,则在当前目录找依赖文件是否存在,不存在,就在整个makefile文件里面找这个依赖文件的是否有依赖关系,如上的test.o依赖文件,在里面也有个test.o:test.s的依赖关系,然后看test.s是否存在,不存在,继续找依赖关系,直到最后,test.c是存在的,然后开始执行依赖方法,递归回test.s的依赖方法,一直到最终的exe。
在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错,而对于所定义的命令的错误,或是编译不成功,make根本不理。
如图,是执行make后的效果,可以看到方法是递归执行,直到最终的。
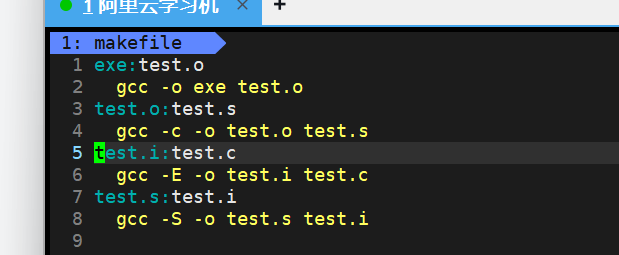
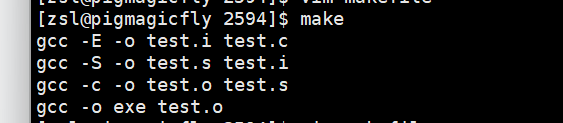
要注意,文件里的依赖关系顺序可以打乱,make是在整个文件里面找,比如这样
但效果依然是
如上只是个例子,实际不需要这么麻烦的依赖关系,之前那样一步到位即可。
4.4语法补充
1.让make忽略源文件和可执行目标文件的Modify时间对比
.PHONY
用法:
作用是修饰目标文件,使其成为伪目标,当伪目标被make形成的时候,伪目标的依赖方法一定被执行
2.注释
3.其他语法
$@代表目标文件,$^代表依赖文件列表
可以定义变量,$(变量名)就可以使用变量了。
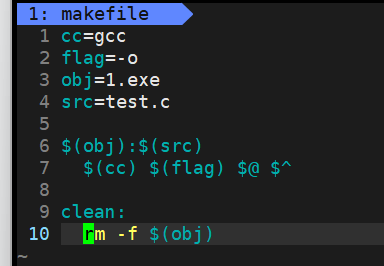
更加完整一点的
BIN=proc.exe # 定义变量 CC=gcc #SRC=$(shell ls *.c) # 采⽤shell命令⾏⽅式,获取当前所有.c⽂件名 SRC=$(wildcard *.c) # 或者使⽤ wildcard 函数,获取当前所有.c⽂件名 OBJ=$(SRC:.c=.o) # 将SRC的所有同名.c 替换 成为.o 形成⽬标⽂件列表 LFLAGS=-o # 链接选项 FLAGS=-c # 编译选项 RM=rm -f # 引⼊命令 $(BIN):$(OBJ) @$(CC) $(LFLAGS) $@ $^ # $@:代表⽬标⽂件名。 $^: 代表依赖⽂件列表 @echo "linking ... $^ to $@" %.o:%.c # %.c 展开当前⽬录下所有的.c。 %.o: 同时展开同名.o @$(CC) $(FLAGS) $< # %<: 对展开的依赖.c⽂件,⼀个⼀个的交给gcc。 @echo "compling ... $< to $@" # @:不回显命令 .PHONY:clean clean: $(RM) $(OBJ) $(BIN) # $(RM): 替换,⽤变量内容替换它 .PHONY:test test: @echo $(SRC) @echo $(OBJ)
5.简单小程序
5.1小知识
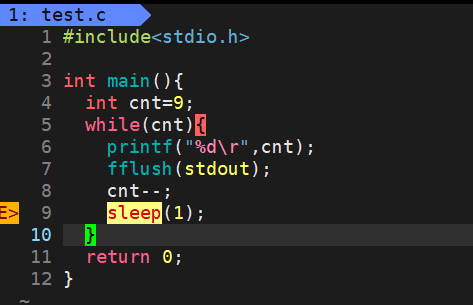
5.1.1缓冲区
可以看到,是一个非常简单的输出程序。效果如下
但我们稍微修改下。
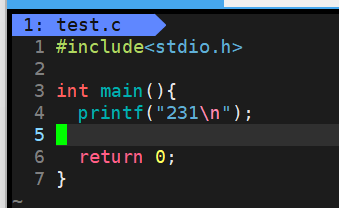
去掉换行符,在printf下面加上sleep(3)
结果如下
光看这张图还看不出来,其实在231输出前,是经过了3秒的休眠,按理来说,应该是231输出后,再等3秒休眠,程序结束。
这时候我们再加上换行符\n
效果如下
又正常了。
----------------------------------------------------------------------------------------------
上面的现象,就是缓冲区造成的。c对io函数有提供缓冲区,缓冲区是在内存中的,printf输出的内容会先存放在缓冲区里。而\n换行符可以做到刷新缓冲区,让缓冲区的内容输出到屏幕上。第二次改的时候为什么最后还是会输出呢,因为虽然sleep不会刷新缓冲区,但return的时候,即程序结束的时候会刷新缓冲区,这才让231显示在屏幕上。
----------------------------------------------------------------------------------------------
fflush函数是c语言的函数,可以做到刷新流,或者暂时可以理解为刷新缓冲区。
而c语言在程序启动后,会默认启动stdin,stdout,stdeer三个流。而其中stdout就是输出流,负责输出内容,刷新stdout意味着让缓冲区马上刷新。
-------------------
以上只是稍微补充内容,更详细的可以等我把基础io的写了。
5.1.2回车和换行
我们以网格举例,光标只会移动在网格内。
换行就是光标纵坐标向下,回车是光标横坐标跑到到最左边。
而我们c语言里的\n其实是先换行,再加上回车。
我们键盘上的enter键,效果等同于\n。
\r是单独的回车。
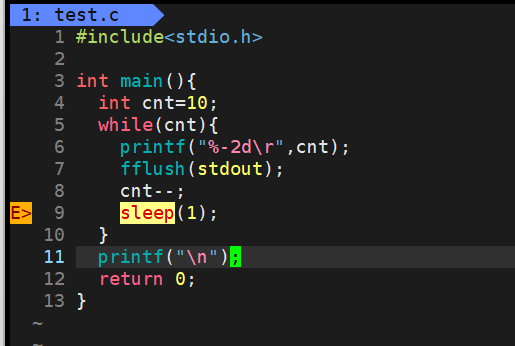
5.2练手-倒计时
原理很简单,利用回车覆盖前面的内容。
每次把数字+回车,放入缓冲区,然后刷新流,让这时候就会出现数字,然后光标移到数字上,因为光标每次都会挪到行首,也就是数字上,下一次输出数字的时候会把原先的数字覆盖,这样就实现了倒计时的程序。
要注意的是,这样写的话,最后的数字是不会保留的,当程序执行完,接下来屏幕就会输出一行这个
因为光标是停留在数字上,所以这一行内容会覆盖数字。
想保留数字就在程序结束前加个换行即可。
----------------------------------------------------------------------------------------------
但这个程序还有问题,想想,如果我们要从10开始倒计时。
这时候,程序不会如我们所想的变化
因为计算机不认识10,输出10,也只是输出1和0两个字符罢了,而我们从9开始,只会覆盖一个字符,所以就出现这个情况了。
我们可以这样改,printf("%2d",cnt);
但还是有个问题,2d的意思是,输出的时候预留2个字符的位置,当输出单个字符的时候,默认是右对齐,也就是左边空了一格,如图
我们每次虽然可以做到覆盖,但是数字一直放在第二个字符处,这就是右对齐。printf("%-2d",cnt);就可以左对齐
最后就是这个样子。





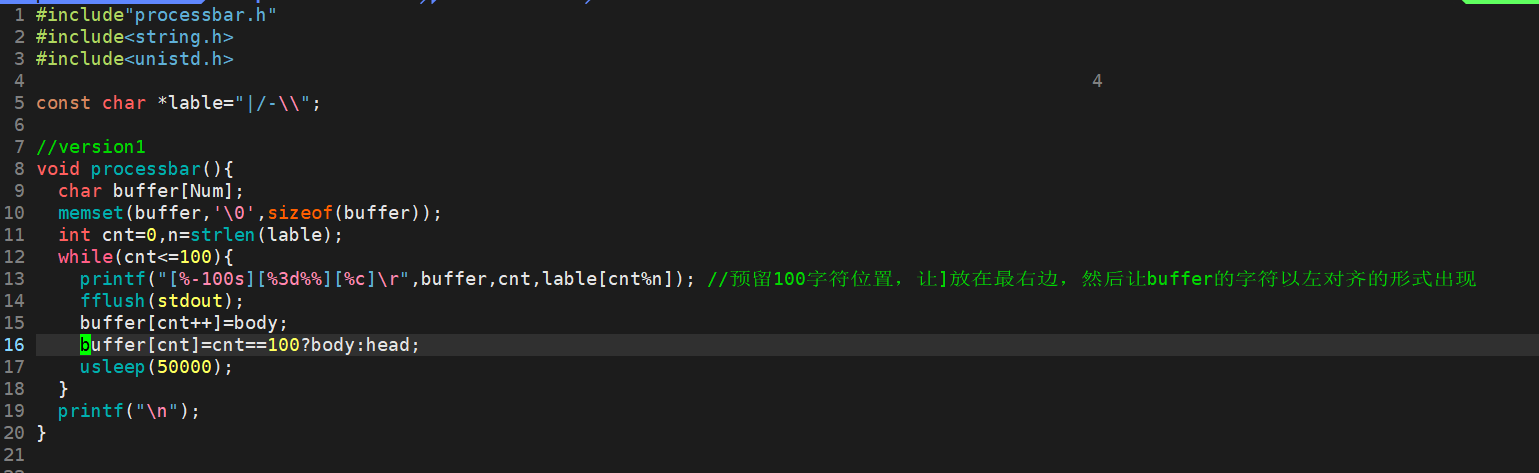
5.3进度条
原理依旧是利用回车,只是这次是每次比上一次多输出一个字符,实现进度条增长的效果。
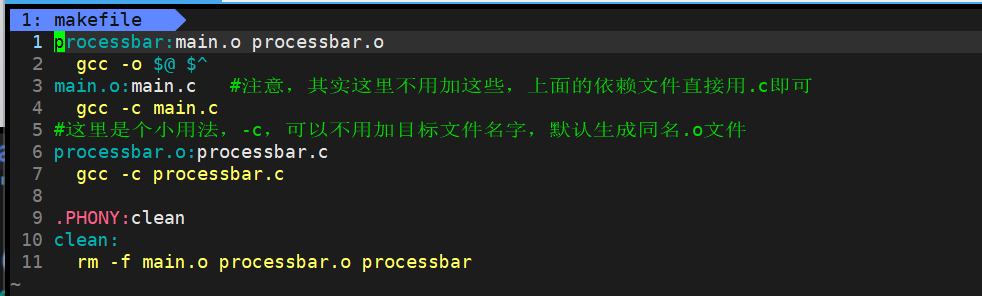
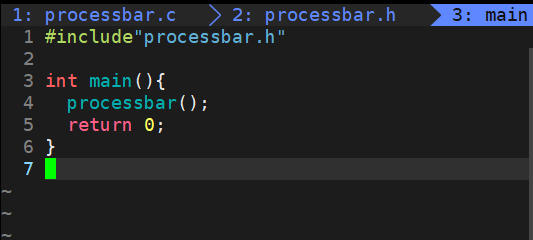
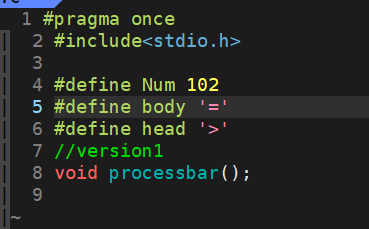
简易版
makefile
main.c
processbar.h
processbar.c
usleep微秒单位
效果如图:

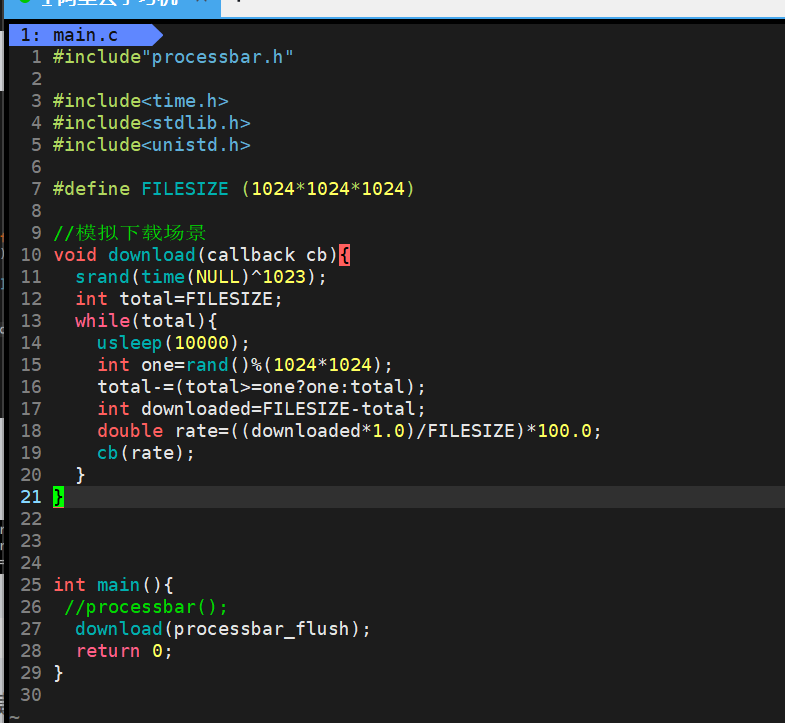
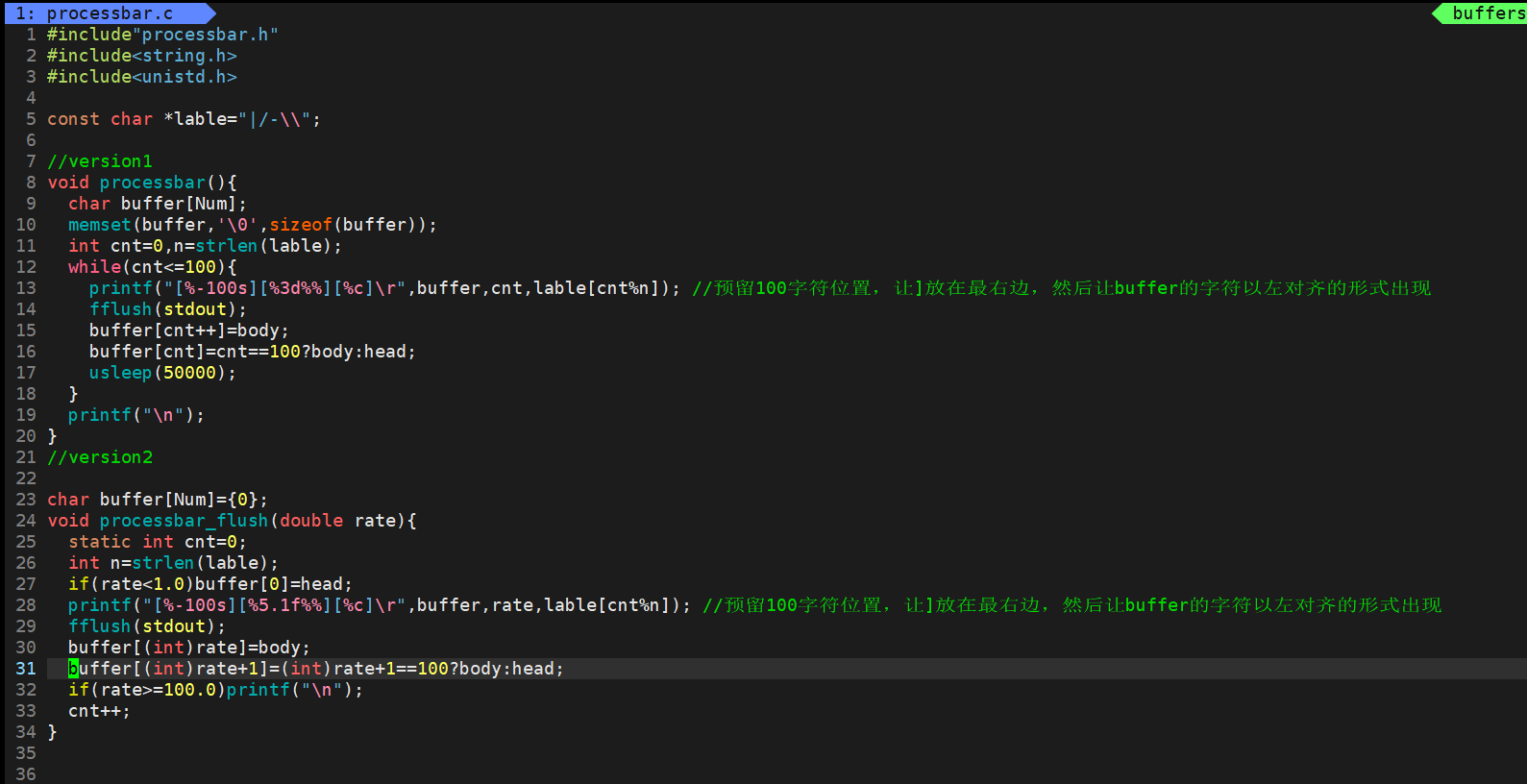
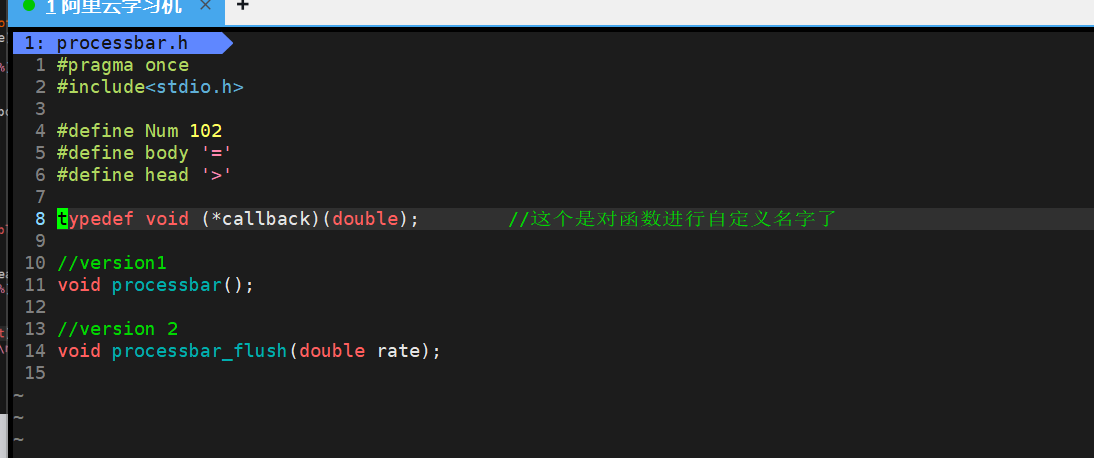
升级版,搭配某个模拟下载场景
makefile不变。
main.c
processbar.c
processbar.h
效果如图

输出时加入彩色。
processbar.c修改一下。


6.Git基础
后面有空我会再写一篇详细一点的,这里只是基础介绍加使用。
6.1简单介绍
git本身只是一个开源工具,用于管理资源(代码、图片等等)。
用git在自己的电脑上创建本地仓库(文件夹),在里面可以放需要被管理的文件,这些文件的每一次修改都会被仓库记录,形成不同的版本,我们需要的时候可以利用这个恢复到曾经的某个版本。
另外,有本地仓库就有远端仓库,远端仓库可以理解为云盘,云端存储,方便在不同地方下载使用文件。远端仓库本身是放在一个云服务器上,这个云服务器目前大家都是用别人提供的(自己弄这个很麻烦),这些云服务器做了相应的设计,基于git工具,有网站有手机、电脑客户端,通过这个可以直接访问,而不是通过命令行或者某些图形化界面来访问。这些云服务器比较出名的就是github(国外的,访问时好时坏),gitee(国内,访问速度快)。
git仓库还有分支,主要是对仓库内的内容做分类,形成一层层管理,比如默认的master分支。
git仓库不建议放太多太大的文件,因为免费版的用户仓库其实很小,就几百MB,建议只放源文件+头文件+配置文件。
6.2使用
6.2.1安装(linux)
centos7.6下
sudo yum install -y git
6.2.2远端仓库设置(推荐用gitee,github太容易卡了)
在gitee里面选择创建仓库,把仓库名字,介绍,选择初始化仓库,根据你平时主要写哪些语言选择语言(主要是后面gitee会有一些百分比,语法高亮等等东西,是根据你选择的语言的)。
gitignore,看名字就知道,这是一个配置文件,配置的是本地仓库的哪些文件类型不会被上传。这里根据语言选就行,主要是省麻烦。
gitigonre是对本地仓库的add进行过滤的,并且是立即生效,甚至在你把gitigonre文件重新提交到本地仓库前,新的gitigonre就已经生效了,效果如图,我加了过滤txt的规则。这就导致了这个文件里的后缀对应的文件,无法被本地仓库和远端仓库管理。
然后就是开源许可,看你需求,建议最少要选一个。
下面模板,就是比如使用说明等等,选readme即可。
然后分支,这里先不说了,直接不选就行,默认单分支就好。有兴趣可以等我后面·写git的文章。或者自行百度。
然后就是把远程仓库克隆到本地,成为自己的本地仓库。
仓库里有克隆下载,里面有教怎么弄,我就不多说了。
注意,设置本地邮箱的时候建议跟gitee账号邮箱一致,不然没有绿点更新。
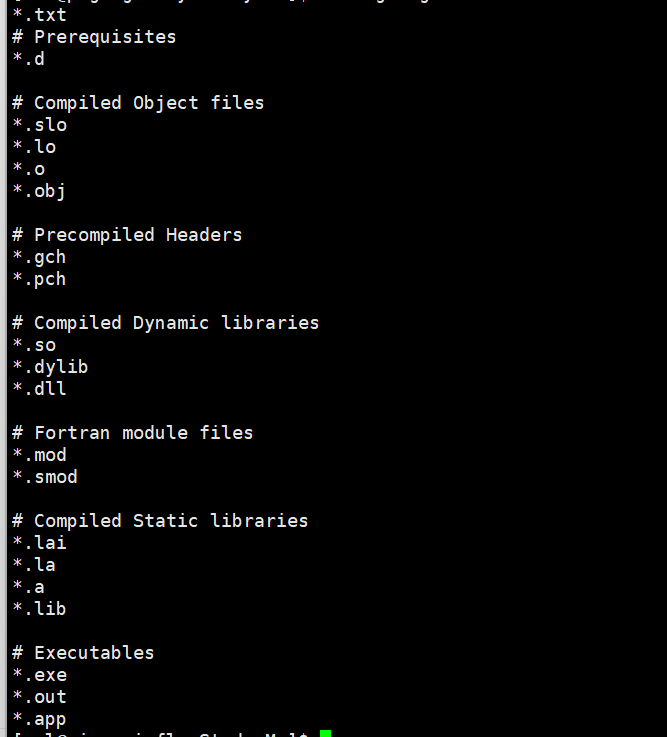

6.2.3指令
可以看到克隆指令时的目录下多了个跟仓库名相同的文件夹,这个文件夹就是克隆的下来的东西。
.git是本地仓库,其他的都可以视作工作区。
git add 文件名 可以把指定文件添加到本地仓库的暂存区。也可以直接.,就直接把当前工作区里没有被加到暂存区的文件都添加到暂存区。
git commit -m "XXXX" 把暂存区的所有内容真正提交到本地仓库,成为某一次的版本。xxx是提交时的日志,很重要,以后用的时候要说明这次提交是提交了什么,或者做了什么修改。
git push 把本地仓库与远端仓库进行同步。
输完之后要输用户名密码(是你gitee账号的用户名和密码)。
下面是配置免密提交。
git本地免密码和账号pull、push_没有git账号怎么拉代码-优快云博客
---------------------------------------------------------------------------------------------------------
git log查看修改日志
git status 查看工作区与本地仓库的差别,会告诉你哪些文件做了修改或者有新的文件出现,但是没有添加到暂存区或提交到本地仓库或跟远端仓库同步。
git rm 文件名 可以删除文件,注意虽然直接rm也行,但还是推荐加个git。删除也是一种修改,也是可以add、commit、push的。
---------------------------------------------------------------------------------------------------------
注意,本地仓库跟远端仓库同步的前提是,本地仓库比远端仓库新,如果远端仓库内容比本地仓库新(比如其他人修改了内容同步了仓库),那么,要想同步仓库的前提是,先用git pull拉取仓库到本地,然后才能修改push。
7调试器- gdb
程序的发布方式有2种,debug模式和release模式,linux gcc/g++出来的二进制程序,默认是release模式。debug是开发者用的,附带有调试信息可以被调试器识别。release是没有调试信息,可以理解为给用户用的,测试也是测试的release版本。debug版本程序比release版本大。
要使用gdb调试,必须在源代码生成二进制程序的时候,加上-g选项,如果没有添加,程序无法被编译。
可执行程序的格式是ELF。里面封装了表头、段等等,具体不多说,有兴趣自行百度。
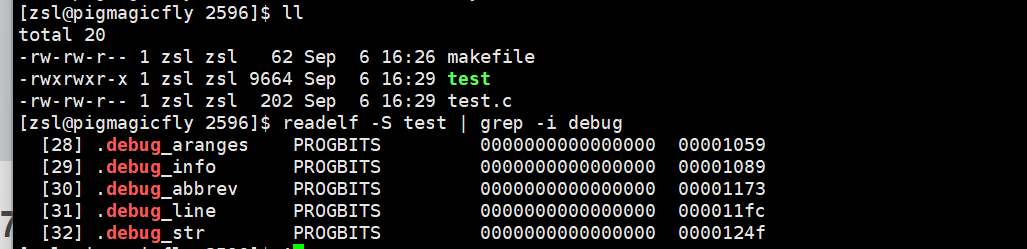
如果想看可执行程序中的调试信息,可以这样
--------------------------------------------------
调试的第一步是找到问题,第二步是查找问题(范围查找,局部逐行查找)
断点是用来范围查找,逐行逐语句是为了看上下文变量
-----------------------------------------------
7.1常见使用
安装:sudo yum -y install gdb
注意后面run的时候会发现,有可能会提示你缺失debuginfo 巴拉巴拉。
参考下面的内容。镜像可以不去官网(centos7.6已经停止维护,建议去阿里云,腾讯云那边找)
CentOS7:gdb出现没有调试信息:Missing Separate debuginfos - 立体风 - 博客园
开始: gdb binfile
退出: ctrl+d 或quit调试命令
gdb会记录最近一条指令,按上可以找,也可以直接按回车,自动执行上一个指令
Enb就是表示这个断点是否启用。

命令 作用 用例 list/l 显示源代码,从上次位置开始,每次列出10行 list/l list/l N 从当前文件的第N行开始列出10行 list/l 1 list/l 函数名 列出指定函数的源代码 list/l main list/l 文件名:行号 列出指定文件的源代码 list/l mycmd.c:1 r/run 从程序开始连续执行 run n/next 单步执行,不进入函数内部, 逐过程 F10 next s/step 单步执行,进入函数内部, 逐语句 F11 step break/b 文件名:行号 在指定行号设置断点 break 10
break test.c:10
break/b 函数名 在函数开头设置断点 break main info break/b 查看当前所有断点的信息 info break
i b
finish 执行到当前函数返回,然后停止。范围查找 finish print/p 表达式 打印表达式的值 print start+end p 变量 打印指定变量的值 p x set var 变量=值 修改变量的值(不用改代码,多分支测试) set var i=10 continue/c 从当前位置开始连续执行程序。范围查找 continue delete/d
breakpoints
删除所有断点 delete breakpoints
d
delete/d
breakpoints n
删除序号为n的断点 delete breakpoints 1
d 1
disable breakpoints 禁用所有断点 disable breakpoints
disable b
disable N 禁用编号N的断点 disable 2 enable breakpoints 启用所有断点 enable breakpoints
enable b
enable N 启用编号N的断点 enable 2 info/i breakpoints 查看当前设置的断点列表 info breakpoints display 变量名 跟踪显示指定变量的值(每次停止时) display x undisplay 编号 取消对指定编号的变量的跟踪显示 undisplay 1 until x行号 执行到指定行号。范围查找 until 20 backtrace/bt 查看当前执行栈的各级函数调用及参数 backtrace info/i locals 查看当前栈帧的局部变量值 info locals quit 退出GDB调试器 quit watchpoint 变量 监视变量的变化,一旦有变化,就会暂停 watchpoint answer b 行号/文件名:行号/函数名 if 条件
新增条件断点 b 3 if i==3
b test.c:4 if c==5
b Sum if x==true
condition 断点编号 条件 把现有断点变成条件断点 condition 2 i==3
7.2补充Cgbd
Cgbd 分屏操作 ESC 进入代码屏, i 回到 gdb 屏
Ubuntu: sudo apt-get install -y cgdbCentos: sudo yum install -y cgdb
cgdb 程序名

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









