




目录
数据控制语言(DCL:Data Control Language):
其他系统内置函数: (3)显示主机名 (4)元数据函数 (5)安全函数 (6)配置函数 (7)排名函数
ROLLBACK TRANSACTION --回滚事务,撤销交易
使用Create Trigger 命令创建DDL (建表库约束)触发器的语法:
(3)通过全局变量@@FETCH_STATUS 和 WHILE 循环配合,实现对游标结果集的遍历
T-SQL可以看作是sql语言的升级版,包含了更多的功能。
让应用程序与sql server沟通的主要语言。
起到的翻译作用,将程序的指令翻译成sql能看懂的指令,让sql执行相应代码。
微软的sql-server支持:T-SQL
Oracle:PL-SQL
实际的数据库管理系统之间的sql是不能完全相互通用
T-SQL是SQL语言的一种版本,且只能在微软MS SQL-Server以及Sybase Adaptive Server系列数据库(最早的T-SQL数据库)上使用。
T-SQL 把 SQL 从“数据查询语言”升级成了“数据库编程语言”,可以写逻辑、处理异常、封装功能,支持复杂系统开发,例如可以写函数,使用内置的函数。
1.基本语法(简单描述)
T-sql包含了标准sql的所有命令。
数据定义语言:对数据库和数据库的各种对象进行创建、删除、修改(字段、结构)
数据库对象有很多:表、缺省约束、规则、视图、触发器、存储过程。
create(创建数据库或数据库对象),不同对象,语法形式不一样。
还有数据操纵语言、查询语言。
新增语法
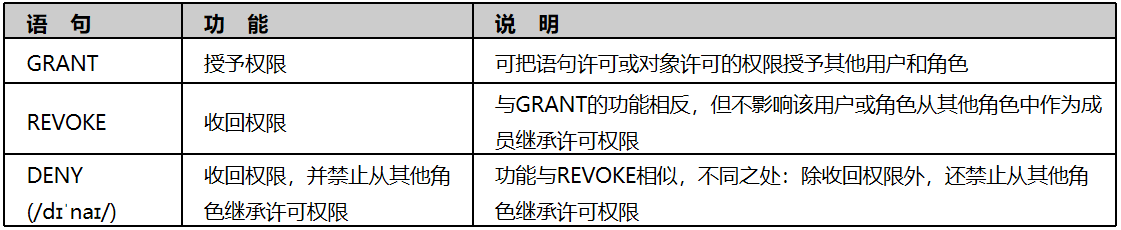
数据控制语言(DCL:Data Control Language):
DCL用于安全管理,确定哪些用户可以查看或修改数据库中的数据。DCL包括的主要语句及功能如表所示。
“REVOKE 是‘取消允许’,但别的角色还可以给你权限;DENY 是‘永远禁止’,就算别的角色给你权限,也无效。”
附加的语言元素:
包括变量、运算符、函数、注释和流程控制语句等
语法约定
在T-SQL中不区分大写和小写
续行:一般情况下,T-SQL语句都会写得很长,可以将一条长语句进行多行编写。 T-SQL会忽略空格和行尾的换行符号。
注释:
--(双减号):创建单行文本注释语句
/*…*/:块注释语句。在注释文本得起始处输入”/*”,在注释语句的结束处输入”*/”,就可以使两个符号间的所有字符成为注释。
批处理:批处理是由一条或多条T-SQL语句构成的。SQL Server从批处理中读取所有语句,编译成可执行单元,一次性执行。这里使用GO关键字结束批处理(可写可不写)。
和sql server语法约定一样

数据类型
基础的数据类型,我在前面sqlserver文章里有写,这里不多说,只是讲下新的东西。
常量
1、字符串常量的编码方式—定义字符串之后
按照编码方式分可分为ASCII字符串常量和Unicode。
字符串常量 ASCII每个字符用一个字节存储,Unicode 每个字符用两个字节存储。
ASCII字符串常量—对应不带N的,Unicode字符串常量—对应带N的。
支持ASCII字符集(0-255),主要包括英文字母、数字和常用符号。
支持Unicode字符集,能够表示世界上几乎所有语言的字符,包括中日韩文、阿拉伯文、希伯来文等。
2、整型常量—定义完数值常量之后
分为二进制、十六进制、十进制整型常量
十六进制整型常量的表示:前辍 0x 后跟十六进制数字串
正常的:0xEBF
0x 是空十六进制常量
二进制整型常量的表示:即数字 0 或1,并且不使用引号
十进制整型常量即不带小数点的十进制数:
1894
+145345234
3、实数常量
有定点表示和浮点表示两种方式
定点表示 :
2.0
+145345234.2234
-2147483648.10
浮点表示:
101.5E5
0.5E-2
-12E5
aE±b,其中a是定点数,b是指数,表示10的b次方。 例如,101.5E5表示101.5 × 10^5。
4、货币常量
以”$”作为前缀
5、日期时间常量
6、uniqueidentifier 唯一标识常量
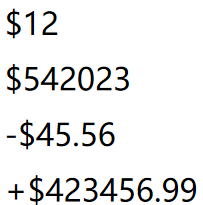


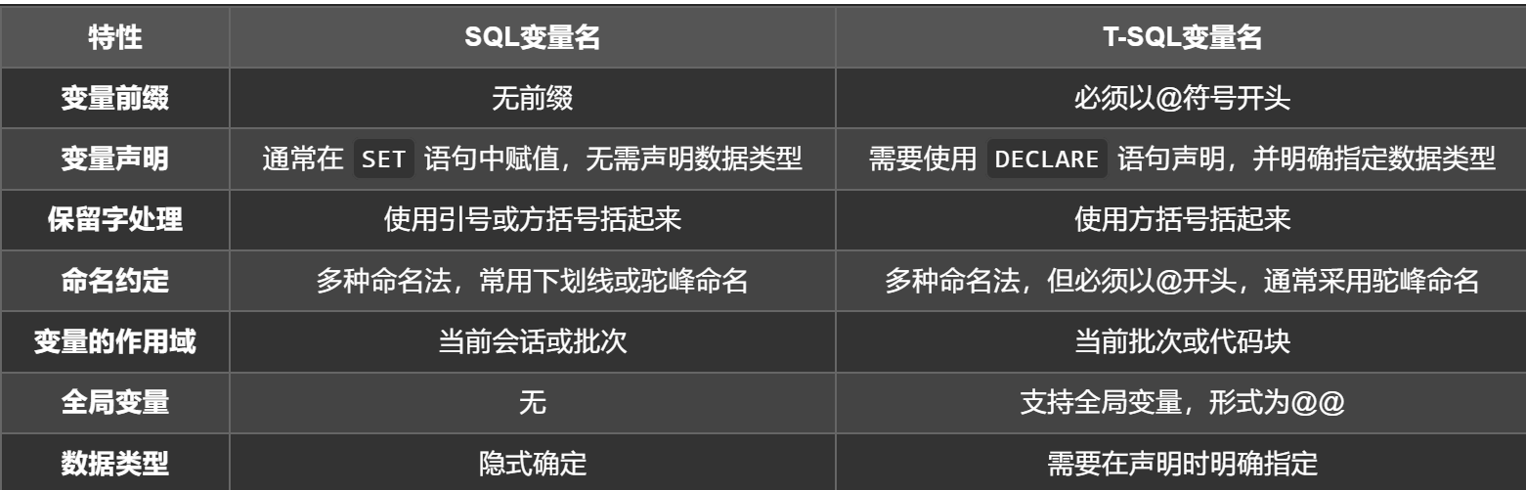
变量
1、变量名
变量名必须是一个合法的标识符,在讲解变量名之前,先讲解合法标识符—可以是表名、列名、变量名…
常规标识符:
以ASCII字母、Unicode字母、下划线 (_)、@或#开头,后续可跟一个或若干个ASCII字符、Unicode字符、下划线 (_)、美元符号($)、@或#.
但不能全为下划线(_)、@或#
标识符不允许是T-SQL保留字(关键字),如select 标识符内不允许有空格和特殊字符 长度小于128
补充:驼峰命名法 通过大小写变化来分隔不同的单词,而不使用任何分隔符。 UserName、GetUserID
界定标识符:
对于不符合标识符规则的标识符,则要使用界定符方括号([])或双引号(“”)将标识符括起来。 如标识符[My Table]、“select”内分别使用了空格和保留字select
2、变量分类
全局变量
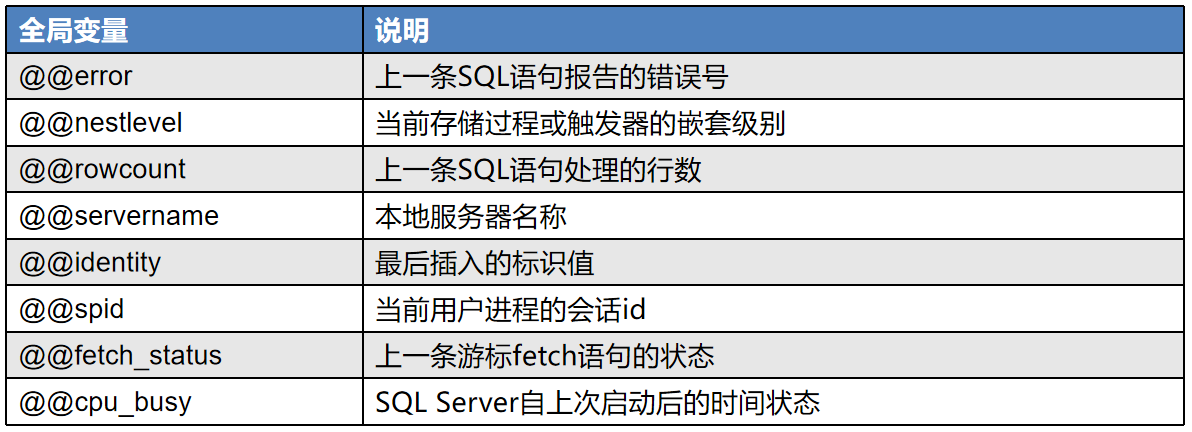
全局变量由SQL Server系统定义,通常用来跟踪服务器范围和特定会话期间的信息,不能被用户定义和赋值。可以通过访问全局变量来了解系统目前的一些状态信息。(如错误处理、行计数等) 全局变量名以@@开头
局部变量
局部变量由用户定义,其作用范围仅在程序内部
局部变量的声明:局部变量必须先声明,后使用
声明:
DECLARE @变量1 [as] datatype,@变量2 [as] datatype,...局部变量名称必须以@开始开头
as可以省略
赋初值NULL(自动赋值)
单对于变量名来说,在合法标识符的前提下:

局部变量的赋值
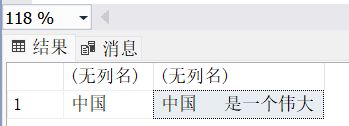
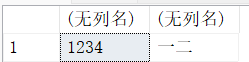
【例1】创建局部变量@var1、@var2,并赋值,然后输出变量的值。 DECLARE @Var1 NCHAR(5),@Var2 NCHAR(10); SET @Var1='中国'; --set一次只能给一个变量赋值 SET @Var2=@Var1+'是一个伟大的国家' --sql server会把中文字符串(unicode)转化为ASCII --但是可能会出现数据的丢失,可以在‘是一个伟大的国家’ 前加一个N SELECT @Var1,@Var2 GO 比较,理解nvarchar和nchar DECLARE @var1 NVARCHAR(5),@var2 NVARCHAR(10); SET @Var1='中国'; --set一次只能给一个变量赋值 SET @Var2=@Var1+'是一个伟大的国家' --sql server会把中文字符串(unicode)转化为ASCII --但是可能会出现数据的丢失 SELECT @Var1,@Var2 GO /*注意变量的类型;1个英文要1个字节存储,1个中文需要2个字节存储*/ DECLARE @Var1 CHAR(4),@Var2 CHAR(4); SET @var1='1234'; --set一次只能给一个变量赋值 SET @var2='一二三四' --sql server会把中文字符串(unicode)转化为ASCII --但是可能会出现数据的丢失 SELECT @var1,@var2 GO
在 SQL Server 中,添加注释的快捷键是 Ctrl+K, Ctrl+C,而取消注释的快捷键是 Ctrl+K, Ctrl+U。
【例2】直接赋值,创建一个名为学号的局部变量,并在 SELECT 语句中使用该局部变量查找StuCou表中该学生所选课程的课程号和志愿号。以StuXK学生选课数据库为例。 --第一种 USE StuXK; GO --每个GO命令之后,当前的执行环境(如变量、临时表等)会被清空。 --优化执行:通过分批次执行,可以优化资源使用和错误处理。 DECLARE @StuNo CHAR(8)='00000001'; SELECT CouNo,WillOrder FROM StuCou WHERE StuNo = @StuNo; GO --第二种 USE StuXK; GO DECLARE @StuNo CHAR(8); SET @StuNo='00000001'; SELECT CouNo,WillOrder FROM StuCou WHERE StuNo = @StuNo; GO --第三种 USE StuXK; GO DECLARE @StuNo CHAR(8); SELECT @StuNo='00000001'; SELECT CouNo,WillOrder FROM StuCou WHERE StuNo = @StuNo; GO当利用SELECT查询语句给局部变量赋值时的语法格式
在变量赋值时,子查询必须返回一个单一的标量值。
在T-SQL中,当使用DECLARE或SET为变量赋值时,右边的表达式必须是一个标量值。SELECT语句通常返回一个结果集,而不是标量值,因此需要使用小括号将其包裹起来,以指示这是一个子查询,并将其结果作为一个标量值处理。
【例3】使用子查询给变量赋值。创建一个@StuName的局部变量, 找到学生学号是00000001的学生的姓名并赋值给@StuName。 --方法一: GO DECLARE @StuName NVARCHAR(30) = (SELECT StuName FROM Student WHERE StuNo='00000001’); PRINT @StuName; --方法二: GO DECLARE @StuName NVARCHAR(30); SET @StuName = (SELECT StuName FROM Student WHERE StuNo='00000001') PRINT @StuName; --方法三: GO DECLARE @StuName NVARCHAR(20); SELECT @StuName=(SELECT StuName FROM Student WHERE StuNo='00000001') PRINT @StuName --方法四: GO DECLARE @StuName NVARCHAR(20); SELECT @StuName=StuName FROM Student WHERE StuNo='00000001' PRINT @StuName
(1)如果表达式是列名(查询赋值),当返回多个值的时候会选择最后一个值赋给变量 /*对比*/但是,当表中有约束时,结果可能不是最后一个,所以一定要确保返回值是一个 DECLARE @Stuname nvarchar(30) SELECT @Stuname = ‘刘丰’ --先赋一个初始值 SELECT @Stuname = Stuname FROM Student --没有加条件,直接选取最后一个值赋给变量 SELECT @Stuname '姓名' GO 比较:如果表达式是子查询,作为子查询的部分,返回值只能有一个值,否则会报错 DECLARE @StuName NVARCHAR(30); SELECT @StuName = '刘丰' SELECT @StuName = (SELECT StuName From Student); SELECT @StuName '姓名'; GO
(2)表达式是列名,如果select语句没有返回行(不存在),变量保留当前值 【例4】在Student表中不存在学号的姓名字段,因此对该表的查询不返回结果,变量@Stuname将保留原值。 DECLARE @StuName NVARCHAR(30); SELECT @StuName = '刘丰' SELECT @StuName = StuName FROM Student WHERE StuNo = '00000099'; SELECT @StuName '姓名'; GO(3) 如果表达式是不返回值的标量子查询,则把变量设置为null 【例5】子查询用于给 @Stuname赋值。在Student表中Stuno字段值不存在,因此子查询不返回值并将变量@Stuname设为 NULL。 DECLARE @StuName NVARCHAR(30); SELECT @StuName = '刘丰' SELECT @StuName = (SELECT StuName FROM Student WHERE StuNo = '00000099'); SELECT @StuName '姓名'; GO(4)一个select语句可以初始化多个局部变量 【例6】将学生学号为00000027的学生姓名和密码用局部变量保存。 DECLARE @StuName NVARCHAR(20),@Pwd CHAR(8); SELECT @StuName = StuName,@Pwd = Pwd FROM Student WHERE StuNo = '00000027'; SELECT @StuName '姓名',@Pwd '密码'; GO





SQL和T-SQL的变量名命名规则对比
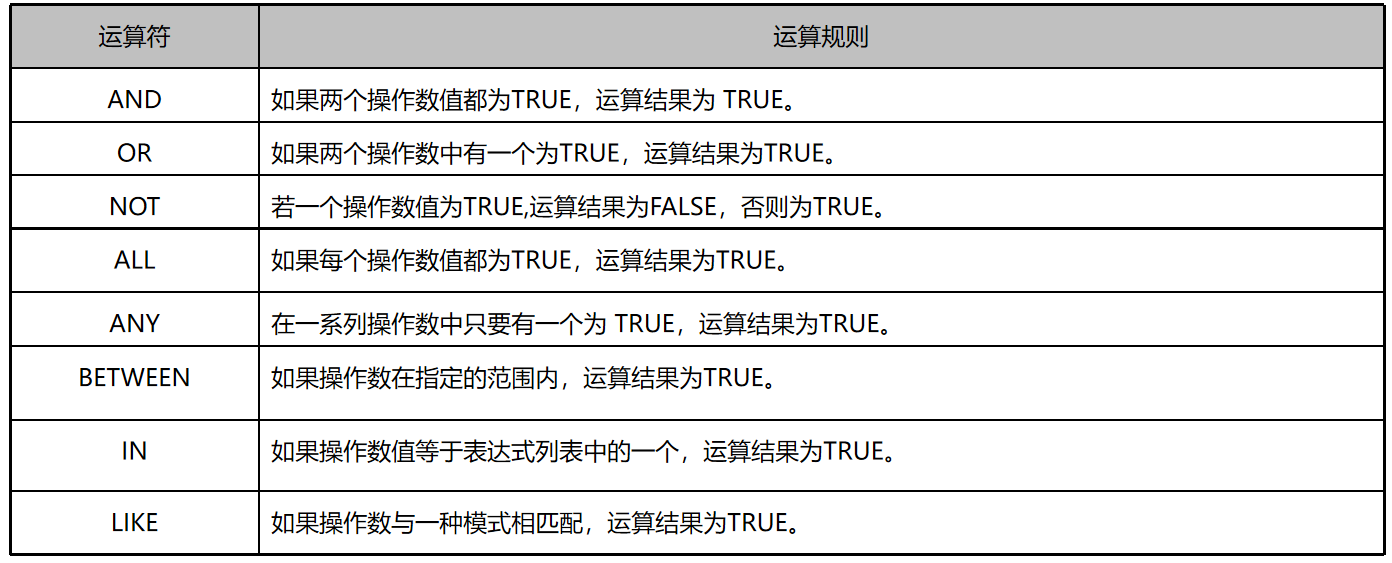
运算符与表达式
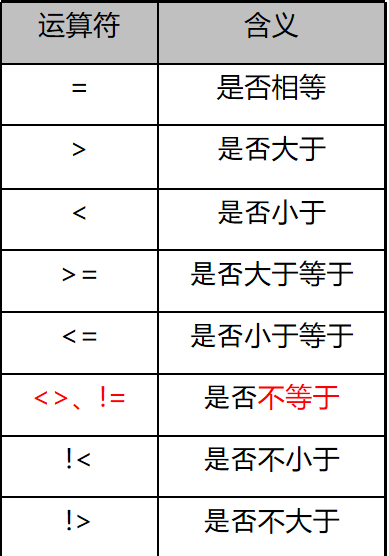
算术运算符:+、-、*、/、%(求余) 按位运算符:&(位与)、|(位或)、^(按位异或) 比较运算符:=、>、>=、<、<=、<>、!>、!< 逻辑运算符:NOT、AND、OR、ALL、ANY、BETWEEN...AND、EXISTS、IN、LIKE 字符串连接运算符:+ 赋值运算符:=
算术运算符
算术运算符有:+(加)、-(减)、*(乘)、/(除,取除数)和%(求模(求余数))五种运算。
+ (加) 和–(减)运算符也可用于对 datetime 进行算术运算
如果两个数都是整数(如 int),SQL Server 会执行整数除法,直接舍去小数部分!
SELECT 7/3,7%3 --只能得到除数 SELECT 7.0/3 --得到完整结果 【例7】求2000年10月10日出生学生的年龄。 DECLARE @DateTime DATETIME; SET @DateTime = GETDATE(); SELECT YEAR(@DateTime) - YEAR ('2000-10-10') "年龄"; GO 补充:GETDATE()得到目前的时间,YEAR(date) 返回当前日期的年份
位运算符
【例8】 在master数据库中,建立表bitop,并插入一行, 然后将a字段和 b字段列上值进行按位运算。 USE master; CREATE TABLE bitop ( a int NOT NULL, b int NOT NULL ) INSERT bitop VALUES(168,73) SELECT a & b,a | b,a ^ b FROM bitop GO位操作会自动把数值转化为二进制,再进行运算

比较运算符
用于测试两个表达式的值是否相同,运算结果为逻辑值,可以为三种之一:TRUE、FALSE 及 UNKNOWN。
【例9】查询指定学号的学生在Student表中的信息。学号‘00000027’。 USE StuXk; DECLARE @StuNo CHAR(8); SET @StuNo = '00000027'; SELECT * FROM Student WHERE StuNo = @StuNo; GO
逻辑运算符
用于对若干个条件表达式进行测试,结果为 TRUE 或FALSE。
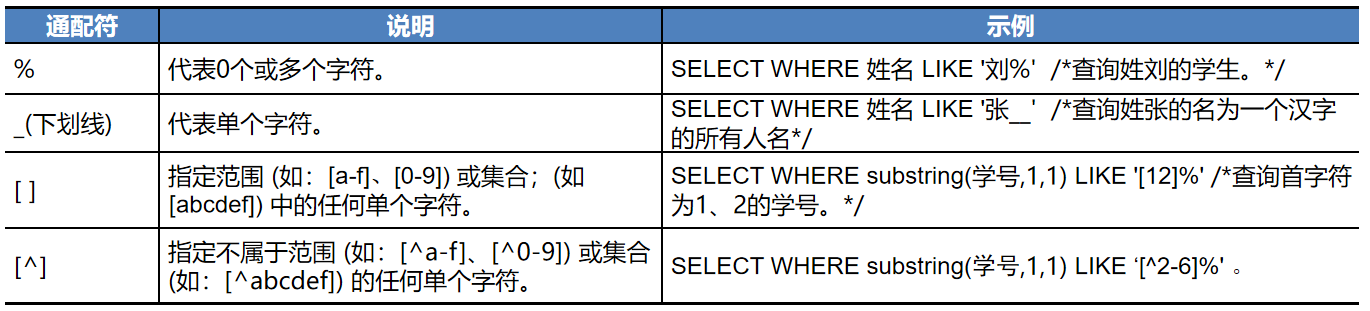
模糊查询:like的使用
【例10】查询姓名以张或王开头的姓名的学生的情况。 SELECT * FROM Student WHERE StuName LIKE '[张王]%'; GO 补充:SUBSTRING(字符串, 起始位置, 长度) 截取字符串指定位置,指定长度的字符
字符串连接运算符
通过运算符“+”实现两个字符串的联接运算
【例11】多个字符串的联接。从 Student 表中找出所有学号最后两位是 '08' 的学生, 并将“学号 + 逗号 + 空格 + 姓名”拼接在一起显示出来,列名为“学号及姓名”。 SELECT stuno + ',' + SPACE(1) + Stuname AS "学号及姓名" FROM Student WHERE RIGHT(stuno,2) = '08'; GO 补充:RIGHT ( 要处理的字符串表达式, 从右数要提取的字符个数) SPACE(n) --n 是一个整数,表示你想要多少个空格字符
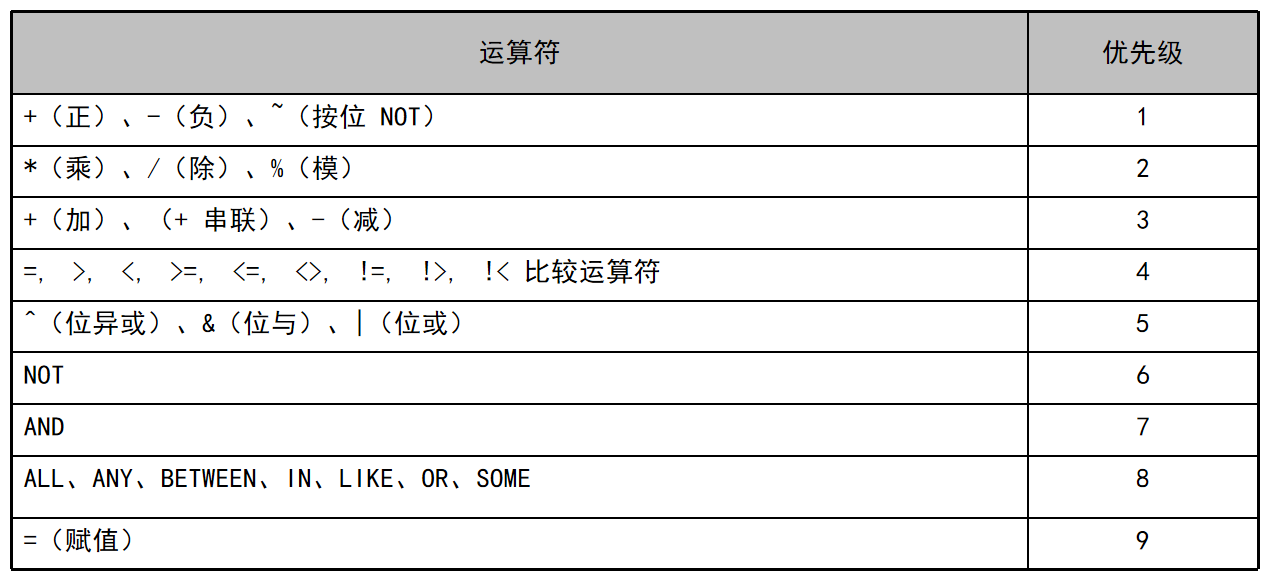
运算符的优先顺序
系统内置函数
T-SQL提供了三种函数,系统内置函数也可分为:
行集函数:行集函数返回的结果是一个表,常用于跨系统或外部数据源访问。
聚合函数:聚合函数用于对一组值执行计算并返回一个单一的值。
标量函数:标量函数用于对传递给它的一个或者多个参数值进行处理和计算,并返回一个单一的值。
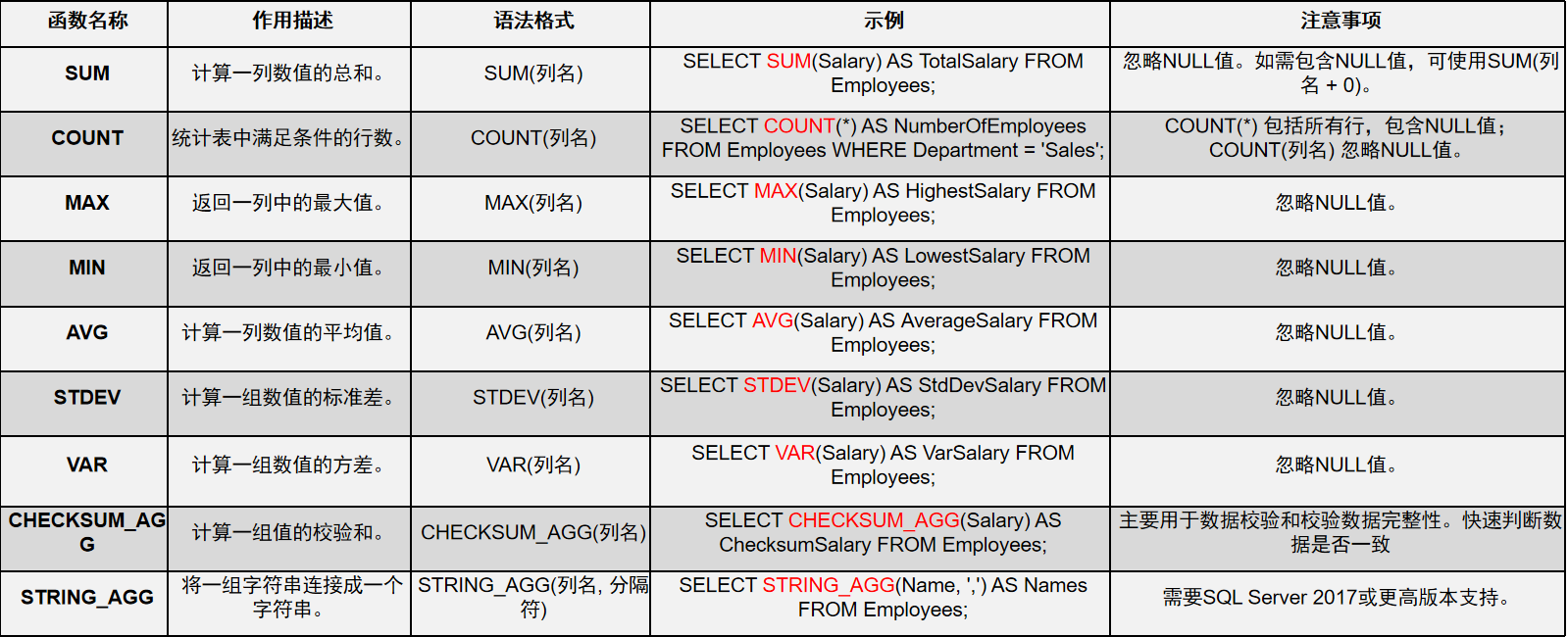
聚合函数
聚合函数:对一组值操作,返回单一的汇总值
平均值AVG、标准偏差STDEV、方差VAR、最大值MAX、最小值MIN、求和SUM、次数COUNT、极差值MAX-MIN,都是针对一组数据得到的单个数值。
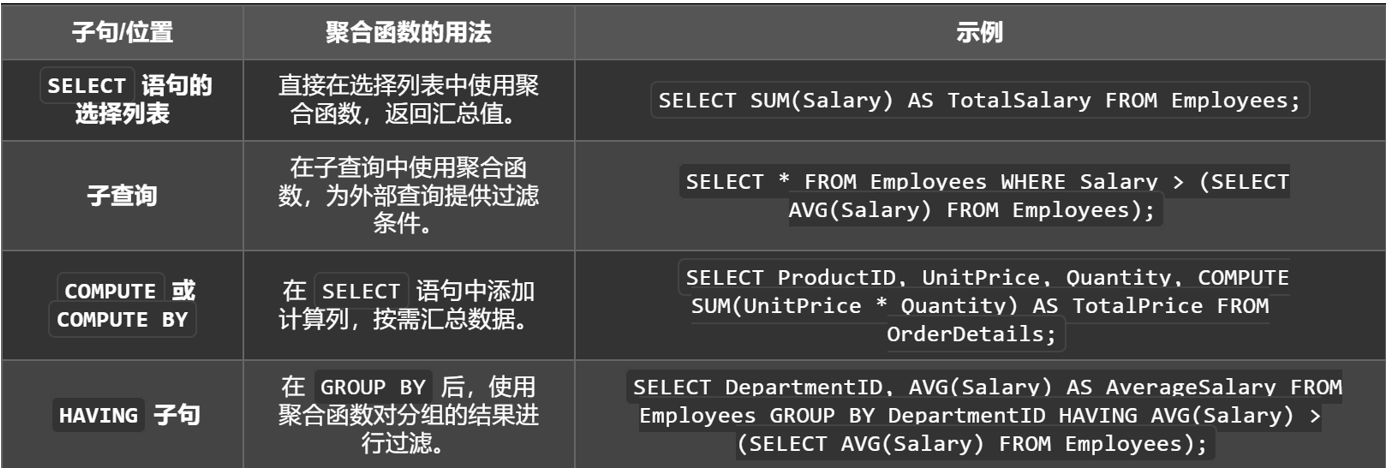
聚合函数在如下情况下,允许作为表达式使用:
SELECT 语句的选择列表(子查询或外部查询)
COMPUTE 或 COMPUTE BY 子句
HAVING 子句
补充:COMPUTE在结果集的最后一行添加总和行。
按部门分组,计算每个部门的平均工资;只保留那些“部门平均工资”高于“全公司平均工资”的部门;HAVING 起到的是对“聚合后结果”的筛选作用。
标量函数
标量函数:输入参数的类型为基本类型,返回值也为基本类型
配置函数 系统函数 系统统计函数 数学函数 字符串函数
日期和时间函数 游标函数 文本和图像函数 元数据函数 安全函数
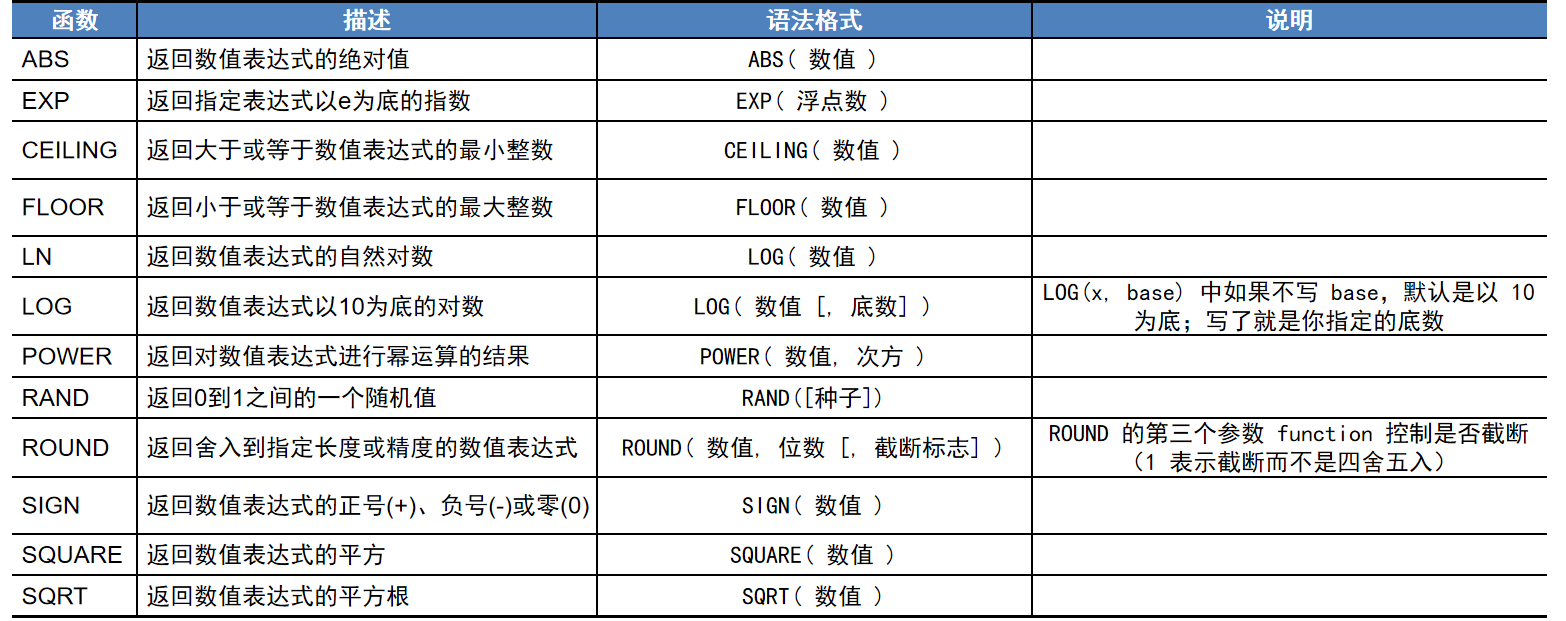
1、数学函数
数学函数可对 SQL Server提供的数字数据(decimal、integer、float、real、money、smallmoney、smallint 和 tinyint)进行数学运算并返回运算结果。
【例12】显示绝对值ABS函数对三个不同数字的效果。 SELECT ABS(-5.0), ABS(0.0), ABS(8.0) GO 【例13】如下程序通过 RAND 函数生成随机值。 DECLARE @count int SET @count = 8 SELECT RAND(@count) 'Rand_Num' GO

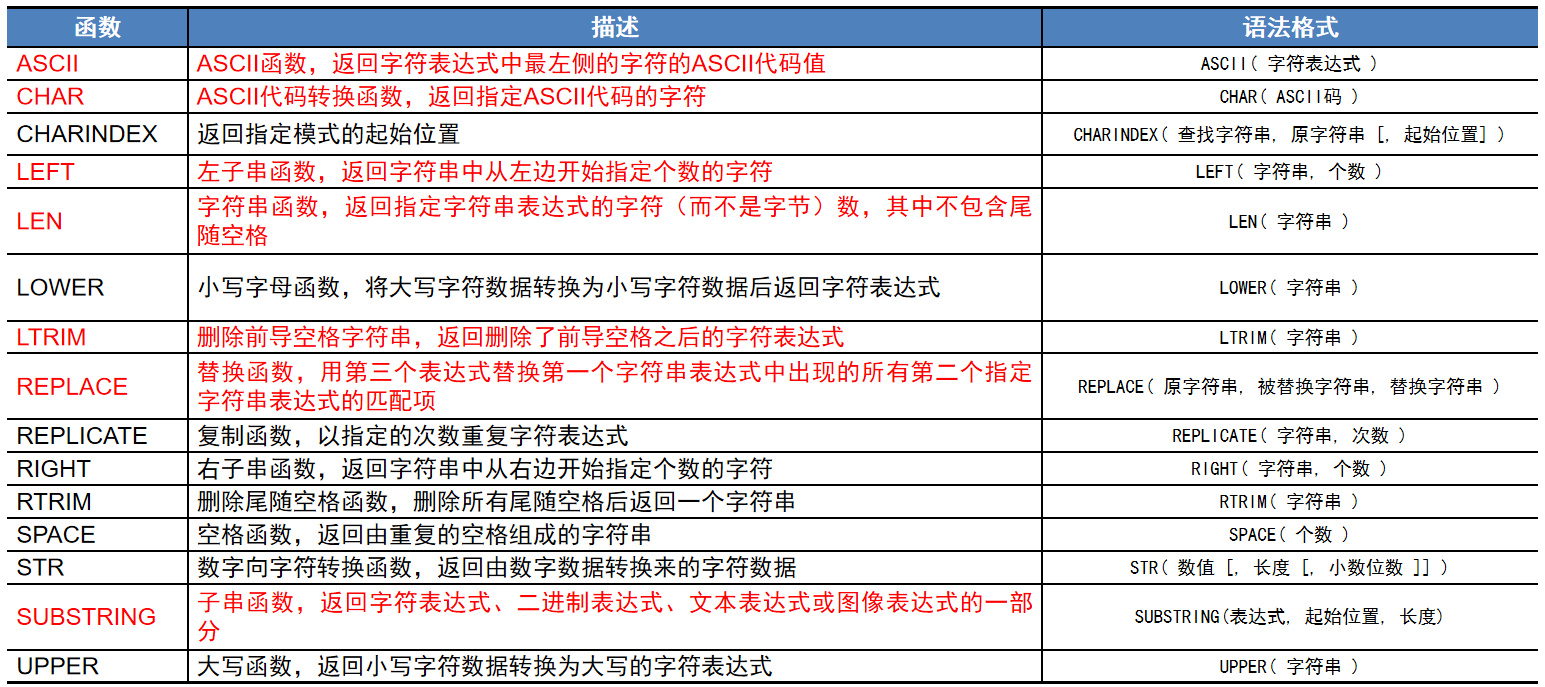
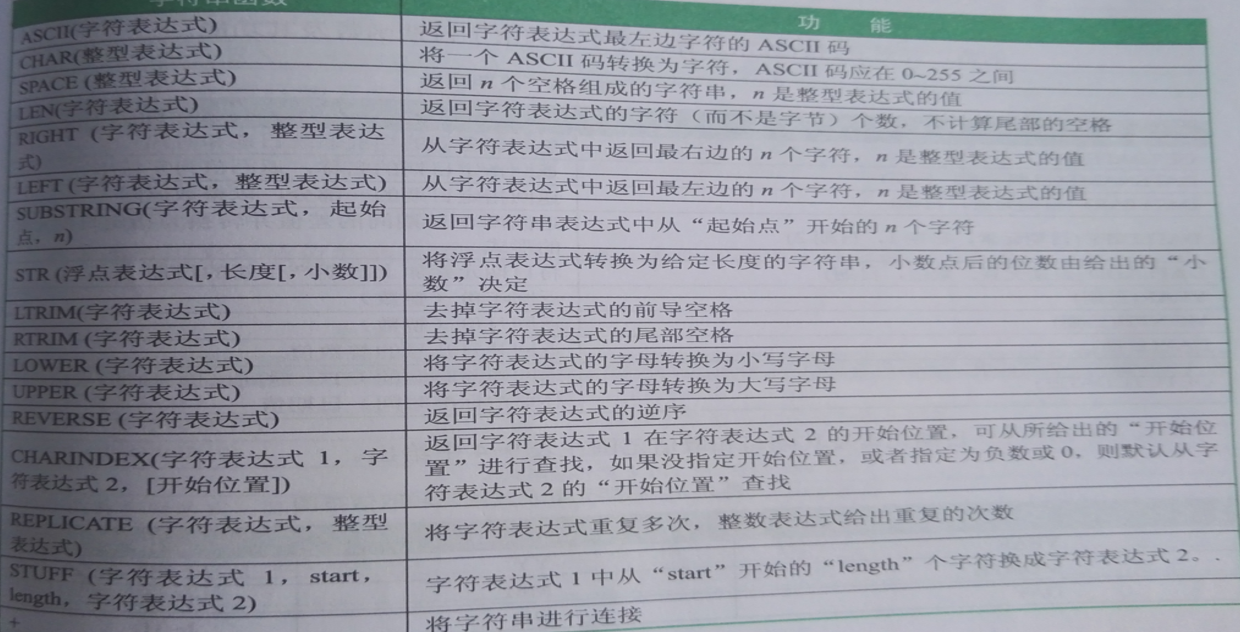
2、字符串函数
ASCII:
DECLARE @String CHAR; SET @String='ABC'; SELECT ASCII(@String);CHAR:
DECLARE @Char INT; SET @Char=65; SELECT CHAR(@Char);
LEFT:【例14】返回StuXk数据库中课程名最左边的 4个字符,并按课程名进行升序排序。 USE StuXk; SELECT LEFT(CouName,4) FROM Course ORDER BY CouName GOLTRIM:
【例15】删除字符变量' 中国,一个古老而伟大的国家'中的起始空格。 DECLARE @String NVARCHAR(40); SET @String=' 中国,一个古老而伟大的国家'; SELECT LTRIM(@String); GOREPLACE:
【例16】将字符变量' 中国,一个古老而伟大的国家'中“国家”替换成“民族”。 DECLARE @String NVARCHAR(40); SET @String=' 中国,一个古老而伟大的国家'; SELECT REPLACE(@String,'国家','民族'); GOSUBSTRING:
【例17】取子字符串:从字符串'中国,一个古老而伟大的国家'的 第3个字符开始取2个字符。 SELECT SUBSTRING('中国,一个古老而伟大的国家',3,2); GOLen:
【例18】如下程序在一列中返回Student表中的姓氏, 在另一列中返回表中学生的名,并按姓名排序。 SELECT SUBSTRING(StuName,1,1) "姓氏",SUBSTRING(StuName,2,LEN(StuName)-1) "名字" FROM Student ORDER BY StuName; GO
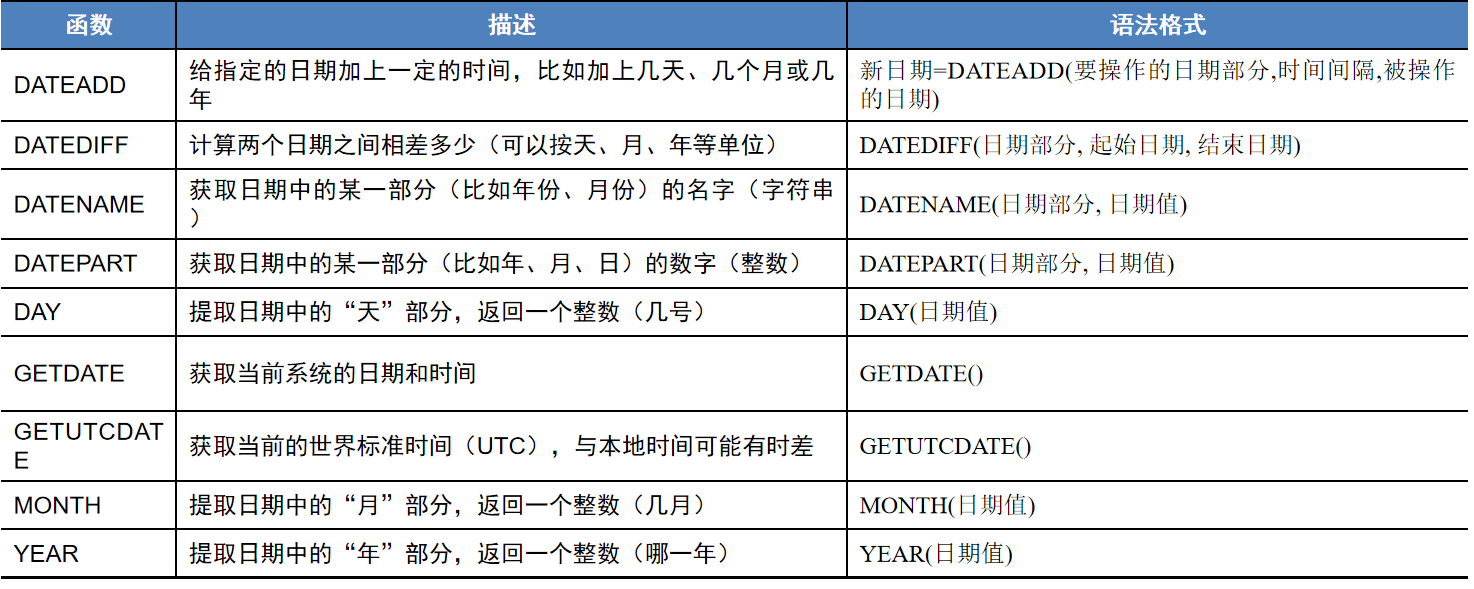
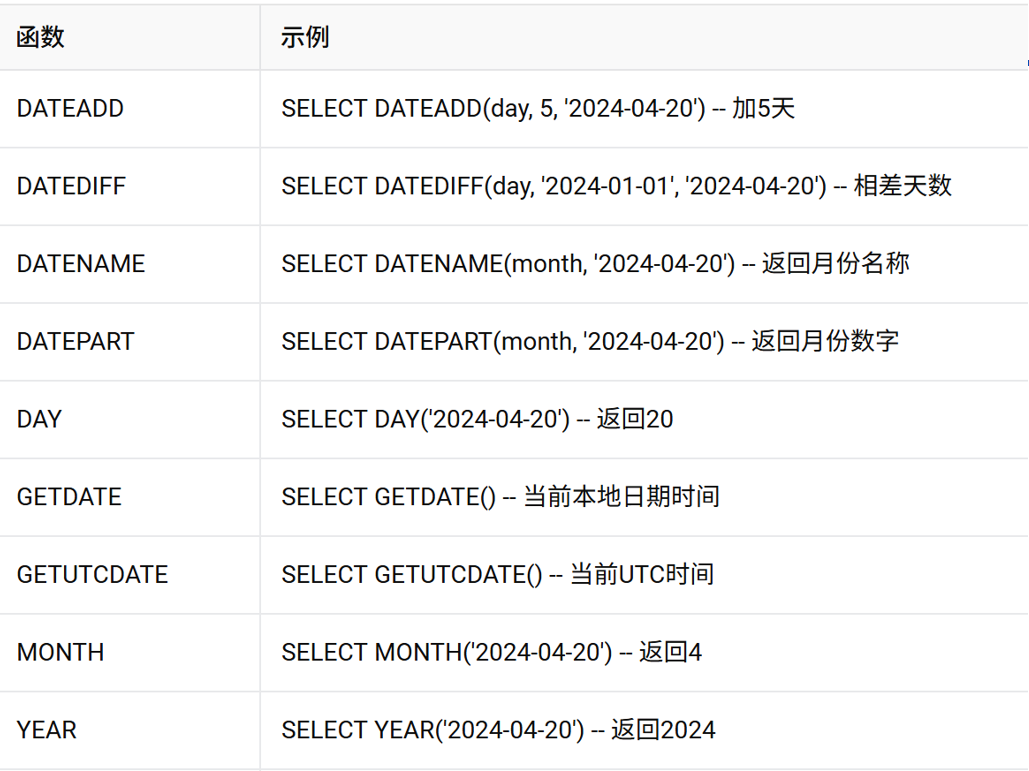
3、 时间日期函数
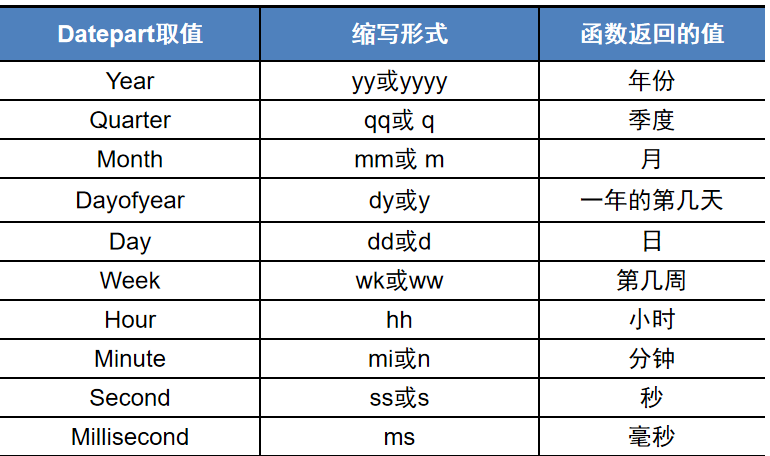
为了让 SQL Server 明确知道你要提取的部分,它使用了一套统一的、简洁的缩写代码(也叫 datepart 参数)来表示这些单位。
DATEDIFF(日期部分, 起始日期, 结束日期) DATEPART(日期部分, 日期值) DATENAME(日期部分, 日期值) DATEADD(要操作的日期部分,时间间隔,被操作的日期)这两列都可以
dw星期
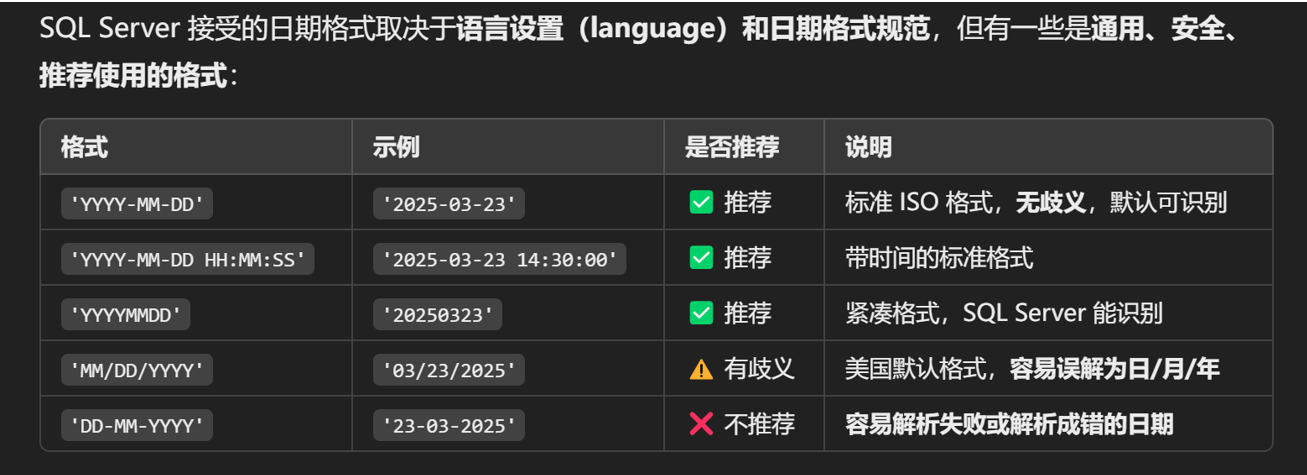
日期格式
举例:【例19】求2021年4月1日前后100天的日期。 DECLARE @Curtime DATETIME,@Fortime DATETIME,@Aftertime DATETIME; SET @Curtime='2021-04-01'; SET @Fortime = DATEADD(dd,100,@Curtime); SET @Aftertime = DATEADD(dd,-100,@Curtime); SELECT @Fortime,@Aftertime GO 【例20】根据自己的出生时间计算年龄,出生在周几,年龄对应的总天数和总的星期数。 SELECT DATEDIFF(yy,'2000-03-14',GETDATE()) "年龄", DATENAME(dw,'2000-03-14') "星期", DATEDIFF(dd,'2000-03-14',GETDATE()) "天数", DATEDIFF(ww,'2000-03-14',GETDATE()) "周数"; 该语句通过GETDATE函数获取当前系统日期和时间,采用DATEDIFF函数由出生时间计算年龄、天数和周数。

特殊内置函数
isnull,判断是否为null
第一个参数被判断的值,第二个参数,为空时返回什么值。
4、系统函数
(1)case函数
简单case函数 : case 输入表达式 when 条件值1 then 结果1 when 条件值2 then 结果2 …… else 默认值 end输入表达式:就是拿来和每个 WHEN 后面的值进行比较的对象,常常是一个字段名、变量、函数等。
【例20】根据学分范围显示相应结果。 SELECT CouName,Credit= CASE Credit WHEN 1 THEN '1个学分’ WHEN 2 THEN '2个学分’ WHEN 3 THEN '3个学分’ WHEN 4 THEN '4个学分’ ELSE '5个学分’ END FROM CourseSELECT 既能用于 查询结果输出(列别名),也能用于 变量赋值(@变量名)。
关键就在于:变量有 @,列名没有 @,这就是你判断它“是不是变量”的关键。case搜索函数: case when 表达式1 then 结果1 when 表达式2 then 结果2 …… else 默认值 end 这里把表达式写在了WHEN的后面 【例21】如果要求学分在3.0以下,显示'小于3个学分', 学分是3.0,则显示'3个学分',否则显示'大于3个学分‘ SELECT CouName, Credit= CASE WHEN Credit>3 THEN '大于3个学分’ WHEN Credit<3 THEN '小于3个学分’ ELSE '3个学分’ END FROM Course GO需要缩进的关键字:
(2)CAST 和 CONVERT
日期型-》字符型 字符型-》日期型 数值型-》字符型 语法格式: CAST ( 表达式 AS 数据类型 ) CONVERT (待转化为的数据类型(长度), 表达式) 【例22】 检索3学分的课程,并将学分字段转化为字符char(20)。 分别用cast和convert实现 -- 使用CAST实现 SELECT *,CAST(Credit AS CHAR(20)) "CreditStr" FROM Course WHERE Credit=3 -- 使用CONVERT实现 SELECT *,CONVERT(CHAR(20),Credit) "CreditStr" FROM Course WHERE Credit=3其他系统内置函数: (3)显示主机名 (4)元数据函数 (5)安全函数 (6)配置函数 (7)排名函数
显示主机名 SELECT HOST_NAME() Go 元数据函数:查看数据库和数据库对象的信息 --返回Student表的ID值 SELECT OBJECT_ID('Student') --通过OBJECT_ID('Student')得到Table_id SELECT COL_NAME(OBJECT_ID('Student'),1) --显示Xk数据库的标识 SELECT DB_ID(‘StuXK') 安全函数: --显示目前用户在数据库中的用户名 SELECT USER GO --检查用户是否可以访问StuXk数据库 SELECT HAS_DBACCESS(‘StuXK') GO 配置函数: --显示允许用户同时连接的最大数 SELECT @@Max_Connections --显示所使用的SQL SERVER 软件版本信息 SELECT @@Version --显示所使用的SQL SERVER 软件版本语言 Select @@Language GO
流程控制语句
T-SQL语言与其他高级语言一样,提供了可以控制程序执行流程的语句,可以更好地组织和控制程序的流程
语句块:begin…end --代表一个语句块的开始和结束 条件语句:if…else 循环语句:while,break,continue 返回语句:return 等待语句:wait for 转移语句:goto
BEGIN……END语句块
BEGIN --语句块开始 语句 1 语句 2 END --语句块结束 BEGIN和END必须成对出现 可以将多条T-SQL语句封装起来,构成一个独立的语句块 应用场景:常用于存储过程、函数、触发器等,用于执行多个SQL语句。

IF……ELSE语句块
语法格式 IF 条件 /*条件表达式*/ 语句 1 /*条件表达式为真时执行*/ ELSE 语句 2 /*条件表达式为假时执行*/else部分可选,可以单单if
【例1】如果“数据库原理课程”的平均成绩高于75分, 则显示“平均成绩高于75分”,否则显示‘平均成绩不高于75分’。 USE PXSCJ BEGIN IF (SELECT AVG(CJ) FROM KCB,CJB WHERE KCB.KCH=CJB.KCH AND KCM='数据库原理’) > 75 SELECT '平均成绩高于75分' ELSE SELECT ‘平均成绩不高于75分' END GO KCB.KCH = CJB.KCH 是连接条件,将两个表连接为一个表,再指定课程名就可以了
WHILE、BREAK和CONTINUE语句块
WHILE 布尔表达式 /*条件表达式*/ 循环体 /*T-SQL语句序列构成的循环体*/表达式为真执行循环体,否则跳过while
【例2】 将学号为081101的学生的总学分使用循环修改到大于等于60, 每次只加2,并判断循环了多少次。 DECLARE @Num INT,@Zxf INT; SET @Num=0; SET @Zxf=(SELECT ZXF FROM XSB WHERE XH=‘081101’); WHILE @Zxf<60 BEGIN SET @Zxf=@Zxf+2; SET @Num=@Num+1; END UPDATE XSB SET Zxf=@Zxf WHERE XH='081101’ SELECT @Num '循环次数’break就是跳出循坏,continue就是跳过本次循坏,进入下次循坏
RETURN语句块
RETURN 返回值 如果没有返回值,则退出程序并返回一个空值。 说明: (1)除非特别指明,所有系统存储过程返回0值表示成功,返回非零值则表示失败。 (2)当用于存储过程(后面的内容)时,RETURN不能返回空值。【例3】 判断是否存在学号为081128的学生,如果存在则返回(提前终止程序), 不存在则插入081128的学生信息,姓名是张可。 IF EXISTS(SELECT XH FROM XSB WHERE XH='081128’) RETURN ELSE INSERT INTO XSB(xh,xm) VALUES('081128','张可’) 通过 “判断学生是否存在,存在则返回” 的逻辑, 展示 RETURN 语句在流程控制中的提前终止作用。 说明:当学号为081128的学生存在时,RETURN会立即终止当前批处理或存储过程的执行, 后续的INSERT语句不会执行。这体现了 RETURN 在条件判断中 “阻断后续操作” 的功能, 常用于避免重复操作或错误执行。
WAITFOR语句块
WAITFOR { DELAY 'time_to_wait' |TIME 'target_time' } 指定触发语句块、存储过程或事务执行的时刻、或需等待的时间间隔 1. DELAY 'time_to_wait' 含义:DELAY 关键字用于指定等待的时间段。 'time_to_wait' 是一个表示时间间隔的字符串, 格式为 hh:mm:ss(小时:分钟:秒),最长可以指定 24 小时。 2. TIME 'target_time' 含义:TIME 关键字用于指定等待到某个特定的时间点。 'target_time' 是一个表示具体时间的字符串, 格式为 hh:mm:ss(小时:分钟:秒),这里的时间是 24 小时制。 【例26】如下语句设定 WAITFOR DELAY '00:00:05'; PRINT '延迟5秒后执行这条语句’; WAITFOR TIME '14:30:00'; PRINT '现在是14:30';
用户定义函数
在使用SQL server的时候,除了我们上节课提到的系统内置函数之外,还允许用户根据需要自己定义函数
标量函数:返回一个确定类型的标量值,其返回值类型为 除TEXT、NTEXT、IMAGE、CURSOR、TIMESTAMP和TABLE类型外的其它数据类型。 内联表值函数:返回的是一个表。该表是由一个 位于renturn子句中的select命令从数据库中筛选出来。 相当于一个参数化的视图(后面会讲)。 多语句表值函数:返回一个表。可以看做是标量函数和内联表值函数的结合体。 他返回的是一个表,但返回值的表中的数据 是由函数体中的语句插入的(可以对数据进行运算修改)。
标量函数
返回一个确定类型的标量值
(1)定义标量函数
函数体语句定义在Begin-End语句内 在函数体中,最后一条语句必须为Return语句 在Returns子句中(注意是Returns关键字),定义返回值的数据类型 语法格式如下: CREATE FUNCTION 函数名 /*函数名部分*/ (@形式参数1 [AS] 数据类型 [ = 默认值 ] ,...n) /*形参定义部分*/ RETURNS 返回值类型 /*返回参数的类型*/ AS BEGIN 功能代码 /*函数体部分*/ RETURN 返回值或表达式 /*必须有Return子句*/ END 【例5】计算全体学生某门功课(课程号)的平均成绩。 CREATE FUNCTION CouAvg_1(@CouNum VARCHAR(20)) --飘红的话前面加GO RETURNS FLOAT AS BEGIN DECLARE @Cou_avg FLOAT SELECT @Cou_avg=(SELECT AVG(CJ) FROM CJB WHERE KCH=@CouNum) RETURN @Cou_avg END;(2)调用标量函数
可以在 T-SQL 语句中允许使用标量表达式的任何位置调用返回标量值 (与标量表达式的数据类型相同)的函数。 使用由两部分组成名称的函数来调用标量值函数, 即架构名.函数名,如dbo.Max(12,34)。在select语句中调用:Select[架构名.]函数名(实参1,…,实参n) 用Exec语句执行: Exec[架构名.]函数名 实参1,…,实参n 或 Exec[架构名.]函数名 形参1=实参1,…,形参n=实参n 备注:三种调用方法的数据库所有者名均可省略,但是不建议 省略【例6】如下程序对上例定义的函数调用。 DECLARE @Cou_1 VARCHAR(20); DECLARE @Couavg_1 FLOAT; SET @Cou_1='101'; SELECT @Couavg_1= dbo.CouAvg_1(@Cou_1); SELECT @Couavg_1 '课程平均成绩' 【例7】调用上述计算平均成绩的函数。 DECLARE @Cou_1 VARCHAR(20) DECLARE @Couavg FLOAT SET @Cou_1='101' SELECT @CouAvg= DBO.CouAvg_1(@Cou_1); SELECT @Couavg '课程平均成绩';1、函数以计算列的形式嵌入到表结构中:列名 AS (计算表达式)
2、若需创建到特定数据库(如 CJB),需在表名前添加数据库名和架构名,格式为:数据库名.架构名.表名计算列是指:列的值不是手动输入的,而是通过表达式自动计算出来的,它的值通常来自同一行的其他列、常量或函数调用的结果,类似于excel表的函数。
【例8】在PXSCJ中建立一个course表,并将一个字段定义为计算列。 CREATE TABLE PXSCJ.DBO.Course( Kch char(3), /*课程号*/ Kcm varchar(20), /*课程名*/ credit int, /*学分*/ avg AS (DBO.CouAvg_1(Kch)) ); GO
内嵌表值函数
返回的是一个表
(1)定义内嵌表值函数
内联表值型函数没有由BEGIN-END 语句括起来的函数体。 其返回的是由一个位于 RETURN 子句中的 SELECT 命令从数据库中筛选出来的表。 内联表值型函数功能相当于一个参数化的视图。 语法格式如下: CREATE FUNCTION 函数名 (@参数名 数据类型, ...) RETURNS TABLE AS RETURN ( 查询语句 );
注意!!!创建表值函数时,查询结果如果出现无列名的列,一定要给该列添加列标题
【例9】为了让学生每学期查询其各科成绩及学分, 可以利用xsb、kcb、cjb三个表,创建视图。 定义内嵌表值函数: CREATE FUNCTION StuCJ(@StuXh CHAR(8)) RETURNS TABLE AS RETURN (SELECT * FROM XSB WHERE XH=@StuXh) GO(2)调用内嵌表值函数
调用时不需指定数据库所有者名,只能通过select语句调用,格式为: select * from 函数名(实参1)
【例10】调用函数,查询学号为“081101”学生的各科成绩及学分。 SELECT * FROM StuCJ('081101')【例9】为了让学生每学期查询其各科成绩及学分, 可以利用xsb、kcb、cjb三个表,创建视图。 CREATE VIEW XsView AS SELECT XSB.XH,XM,CJB.KCH,KCM,CJ,XF FROM XSB,KCB,CJB --当该字段在多个表里都存在时需要加上表名.,否则不用加 WHERE CJB.XH=XSB.XH AND KCB.KCH=CJB.KCH GO 调用视图:SELECT * FROM 视图名; SELECT * FROM XsView


多语句表值函数
(1)定义多语句表值函数
它的返回值是一个表,但它和标量型函数一样有一个用 BEGIN-END 语句括起来的函数体, 返回值的表中的数据是由函数体中的语句写入的。 由此可见,它可以在函数体内,对数据进行筛选与写入,再返回表CREATE FUNCTION 函数名 (@参数1 类型, @参数2 类型, ...) RETURNS @返回表变量名 TABLE ( 列名1 数据类型, 列名2 数据类型, ... ) AS BEGIN -- 可以包含多条语句 INSERT INTO @返回表变量名 SELECT ... FROM 表 WHERE 条件; RETURN; END;为什么单表值内嵌函数不需要创建一个表名? 因为内嵌表值函数直接返回的是一个 SELECT 查询,而多语句表值函数返回的是一个“自己构建的表变量”,所以必须命名它,需要对表格进行修改。
【例10】创建返回table的函数,通过以学号作为实参,调用该函数, 可显示该学生各门功课的成绩和学分。 CREATE FUNCTION StuCjTable(@XsbXh CHAR(8)) RETURNS @StuCj TABLE( XSB_ID CHAR(8),XSB_XM CHAR(8),KCB_KCM CHAR(16),CJB_FS INT,CJB_XF INT ) AS BEGIN INSERT @StuCj SELECT XSB.XH,XSB.XM,KCB.KCM,CJB.CJ,KCB.XF FROM XSB,KCB,CJB WHERE XSB.XH=CJB.XH AND KCB.KCH=CJB.KCH AND XSB.XH=@XsbXh RETURN END(2)调用多语句表值函数
和内联表值函数一样,调用时不需指定数据库所有者名,只能通过select语句调用,格式为: select * from function(实参1)
【例34】如下语句查询学号为”081101”学生的各科成绩和学分。 SELECT * FROM StuCjTable('081101') GO内嵌表值函数和多语句表值函数的区别
两者返回的都是表 不同之处在于:内嵌表值函数没有函数主体,返回的表是单个SELECT语句的结果集, 相当于一个参数化的视图; 多语句表值函数在 BEGIN...END 块中定义的函数主体, 可生成行并将行插入至表中,最后返回表。1、利用企业管理器创建、删除用户定义函数 数据库——可编程性——函数
2、删除函数的语法格式: DROP FUNCTION 函数名
DROP FUNCTION StuCjTable

创建和管理存储过程
函数局限性: 若需求升级,如除了返回选课信息,还需记录查询操作(如写入日志表)、根据选课情况返回不同格式的结果,甚至需要输出参数与调用者交互,函数无法满足,函数的功能相对单一(主要用于返回数据),对复杂业务逻辑(如多操作组合、流程控制、多形式结果输出)的支持不足。
存储过程的优势: 存储过程可以解决这些问题。它不仅能封装查询逻辑,还支持编写复杂的 SQL 语句组合、使用 IF WHILE 等流程控制,甚至能通过输入输出参数与应用交互。例如,用存储过程实现选课查询时,可同时完成数据查询、日志记录,还能根据选课结果返回不同提示。
存储过程的概念
是一组用于完成特定功能的T-SQL语句和流控语句的集合,经编译存储在数据库中;但是存储过程是独立存在于数据表之外的数据库对象(和函数、视图一样)
使用存储过程,可以将一些反复使用、固定的操作集中起来交给SQL Server服务器,以完成某个任务,在一定程度上能改善系统性能。
注意:存储过程保存在服务器端(不是自己的电脑),这样可以提高性能、减轻网络传输压力。
存储过程和函数的区别: 函数可以返回“表类型的结果”,这个表是临时生成的、只存在于查询中,类似虚拟表,但不是实际的物理表或数据库视图,对原始表格只可读取,不可修改。 存储过程可以读取可以修改原始表格数据。
存储过程的优点
模块化编程:创建的存储过程保存在数据库中,可被其他程序反复使用。
快速执行:存储过程第一次被执行后就驻留在内存中。以后执行就省去了重新分析、优化、编译的过程。
减少网络通信量:有了存储过程后,在网络上只需要传送一条语句就能执行存储过程。
安全机制:通过隔离和加密的方法提高了数据库的安全性,通过授权可以让用户只能执行存储过程而不能直接访问数据库对象;另外,存储过程的定义可以被加密。
存储过程分类:
系统存储过程(SP_开头)
用户自定义存储过程(建议P_开头)
用户自定义存储过程
无参数的存储过程
简单的无参数存储过程
CREATE PROCEDURE proc_name [WITH ENCRYPTION] --加密 [WITH RECOMPILE] --重新编译 AS Sql_statements执行存储过程
EXEC proc_name【例1】使用StuXk数据库,创建一个名为p_Student的存储过程:查询学号为00000002的学生是否选课,如果有选课则返回该学生的全部选课信息;否则,返回“该学生还没有选课,请提醒其选课!”
CREATE PROCEDURE p_Student AS IF EXISTS(SELECT State FROM StuCou WHERE StuNo='00000002’) SELECT * FROM StuCou WHERE StuNo='00000002' ELSE SELECT '请及时选课' EXEC p_Student GO【例2】使用Management Studio查看p_Student存储过程的属性。
StuXK——可编程性——存储过程——右击p_Student——修改(可查看也可修改)。
【例3】使用StuXk数据库,修改p_Student的存储过程:查询学号为00000002的学生是否选课,如果有选课则返回该学生的全部选课信息;否则,返回“该学生还没有选课,请提醒其选课!” 请修改该存储过程并加密。
ALTER PROCEDURE p_Student WITH ENCRYPTION AS If exists(Select * from StuCou where stuno='00000002') Select * From StuCou Where stuno='00000002' Else Select '该学生还没有选课,请提醒其选课!' GO在创建存储过程的时候也可以对该存储过程进行加密。此时的存储过程将不能进行查看或修改!!
如果学生学号不固定,是否可以根据给定的学号查询相应的选课信息?
创建带输入参数的存储过程
带输入参数的存储过程
带输入参数的存储过程
CREATE PROCEDURE proc_name @para_name datatype [=default], … --参数实际是一个变量 [WITH ENCRYPTION] --加密 [WITH RECOMPILE] --重新编译 AS Sql_statements执行存储过程
EXEC proc_name value,… --直接用实参 EXEC proc_name @para_name = value, … --先将实参赋给形参
【例4】使用StuXk数据库,创建名为p_SeleStucou的存储过程:根据给定学生学号查询该学生是否选课,如果有选课则返回该学生的全部选课信息;否则,返回“该学生还没有选课,请提醒其选课!”。 并调用该存储过程,分别查看学号为'00000002'和‘00000005'的同学的选课情况
CREATE PROCEDURE p_Student @StuNo VARCHAR(8) AS IF EXISTS(SELECT State FROM StuCou WHERE StuNo=@StuNo) SELECT * FROM StuCou WHERE StuNo=@StuNo ELSE SELECT '请及时选课' GO--执行存储过程方法1 EXEC p_Student '00000002' GO EXEC p_Student '00000005' GO --执行存储过程方法2 指定参数名 EXEC p_Student @StuNo='00000002' GO EXEC p_Student @StuNo='00000005' GO根据给定学生学号,统计该学生选课门数,并将选课门数通过输出变量返回
创建带输出参数的存储过程
带输出参数的存储过程
需要 OUTPUT 的情况:若希望在存储过程外部(如应用程序、其他 SQL 语句)对存储过程内部的某个变量值进行二次操作(如计算、判断、赋值给其他变量等),需通过 OUTPUT 参数将值 “传出” 。例如,存储过程计算学生平均分,调用方需用该平均分进行等级判定,此时必须用 OUTPUT 传递平均分(类似于有返回值) 。
无需 OUTPUT 的情况:若仅需返回结果集(如查询选课信息)或提示信息,通过 SELECT 直接输出即可,调用方接收结果展示即可,无需进一步操作内部变量,此时不需要 OUTPUT。
CREATE PROCEDURE proc_name @para_name datatype [=default], …, @para_name1 datatype output,@para_name2 datatype output [WITH ENCRYPTION] --加密 [WITH RECOMPILE] --重新编译 AS Sql_statements GO定义格式同上,同时指明OUTPUT关键字
【例5】使用StuXk数据库,创建名为p_SeleStucou的存储过程:根据给定学生学号,统计该学生选课门数,并将选课门数通过输出变量返回
CREATE PROCEDURE P_CountStucou @StuNo CHAR(8) AS SELECT COUNT(*) FROM StuCou WHERE StuNo=@StuNo GO Create Procedure p_SeleStucou @Stuno char(8),@Countnum INT OUTPUT AS select @Countnum=count(*) from StuCou where stuno=@Stuno GO【例6】执行带输入与输出参数的存储过程,查询学号为'00000002'的学生选课门数。
--调用方法1: DECLARE @StuNo1 CHAR(8),@CouNum1 INT; --定义输入变量和输出变量 SET @StuNo1='00000002'; --给输入变量赋值 EXEC P_CountStucou @StuNo1,@CouNum1 OUTPUT --调用函数,传入输入参数和盛放输出参数的变量 SELECT @CouNum1 '选课门数'; GO --方法2:(推荐此方法测试) --具体的执行过程是怎么样的? DECLARE @CouNum1 INT; --定义输出变量 EXEC P_CountStucou '00000002',@CouNum1 OUTPUT --调用函数,传入输入参数和输出参数变量盛放输出参数的变量 SELECT @CouNum1 '选课门数'; GO
【练习1】创建存储过程P_ClassNum,要求能根据用户给定的班级代码,统计该班的人数。执行该带输入与输出参数的存储过程,查询班级代码为’20000001’的学生人数
管理存储过程
查看存储过程
EXEC sp_helptext proc_name修改存储过程
ALTER PROCEDURE proc_name @para_name datatype [=default], … [WITH ENCRYPTION] AS Sql_statements重命名存储过程
SP_RENAME --旧名,新名删除存储过程
DROP PROCEDURE proc_name
存储过程和视图、函数的比较
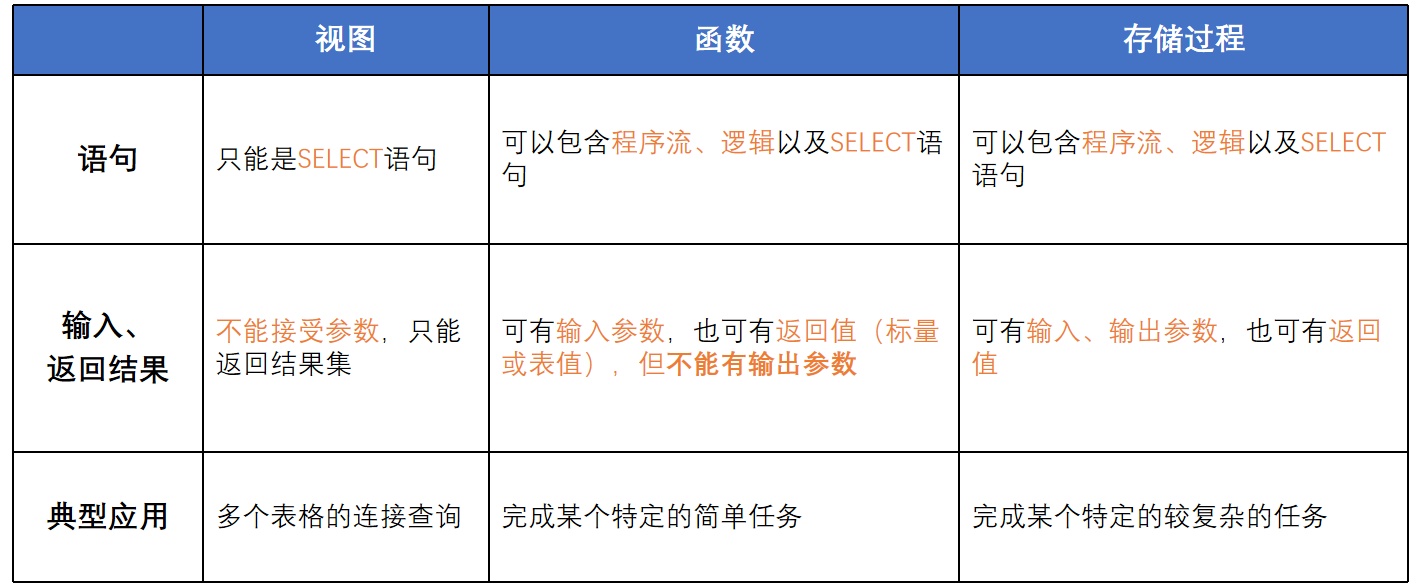
系统存储过程
系统存储过程是系统创建的存储过程,以“sp_”开头
小结
存储过程的作用和优势:模块化编程、快速执行、减少网络通信量、提升安全性
创建、执行简单的存储过程
创建、执行带参数(输入)的存储过程(重点)
创建、执行带参数(输入、输出)的存储过程(理解)
重点:存储过程的创建和执行,特别是带有参数的存储过程
创建和管理触发器
触发器的概念
触发器是在对表进行写入、更新或删除操作时自动执行的存储过程 触发器通常用于强制业务规则 触发器是一种高级约束,可以定义比用CHECK约束更为复杂的约束 可执行复杂的SQL语句(if/while/case) 可引用其它表中的列 触发器定义在特定的表上,与表相关 自动触发执行 不能直接调用,自动触发触发器是一种特殊类型的存储过程。存储过程是通过存储过程名被调用和执行的, 而触发器主要是通过事件触发而被执行的。 SQL SERVER主要提供了两种机制来强制执行业务规则和数据完整性:约束和触发器。 触发器在指定的表中数据发生变化时被调用以响应INSERT、UPDATE或DELETE事件。 触发器可查询其他表,并可以包含复杂的T-SQL语句。 如检测到严重错误时,则整个事务自动回滚,恢复到原来的状态。 触发器的作用:强制执行业务规则和数据完整性DML触发器--Data Manipulation Language(数据操纵语言)
当数据库中发生数据操纵语言事件时调用DML触发器。 包括Insert、Update、Delete等事件 对表或视图的insert、update、delete操作做出响应,保证数据一致性 作用:专门盯着数据层面的变化,比如学生选课写入新记录时, 它自动更新课程报名人数,保证相关数据一致。DDL触发器--Data Definition Language(数据定义语言)
当数据库中发生数据定义语言事件时调用DDL触发器。 包括Create、Alter、Drop或相似的语句 对服务器或数据库事件做出响应,可用于管理任务 作用:主要管理数据库的 “架构变动”,比如记录谁修改了表结构, 防止随意删改数据库对象,更关注数据库整体结构的变化。
DML触发器
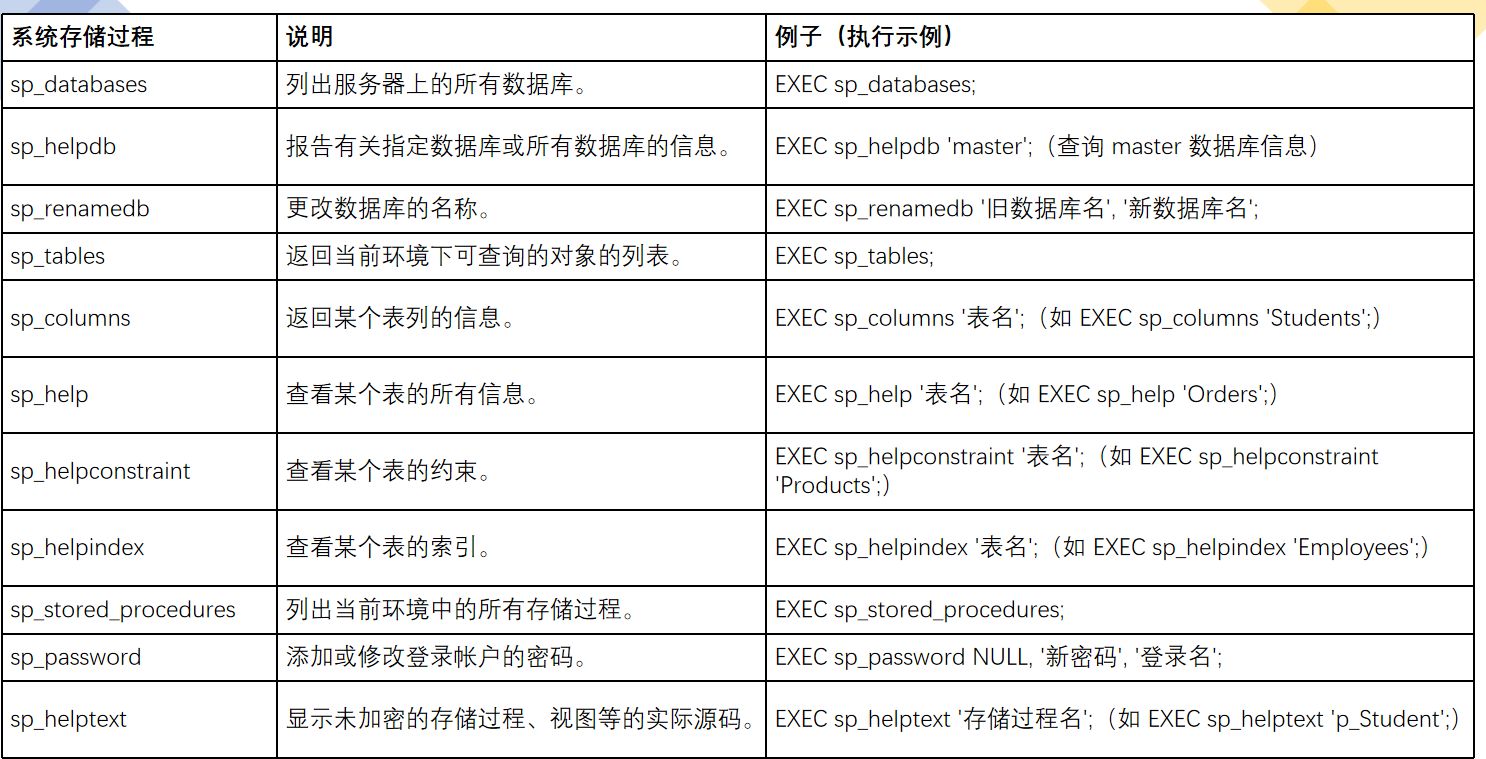
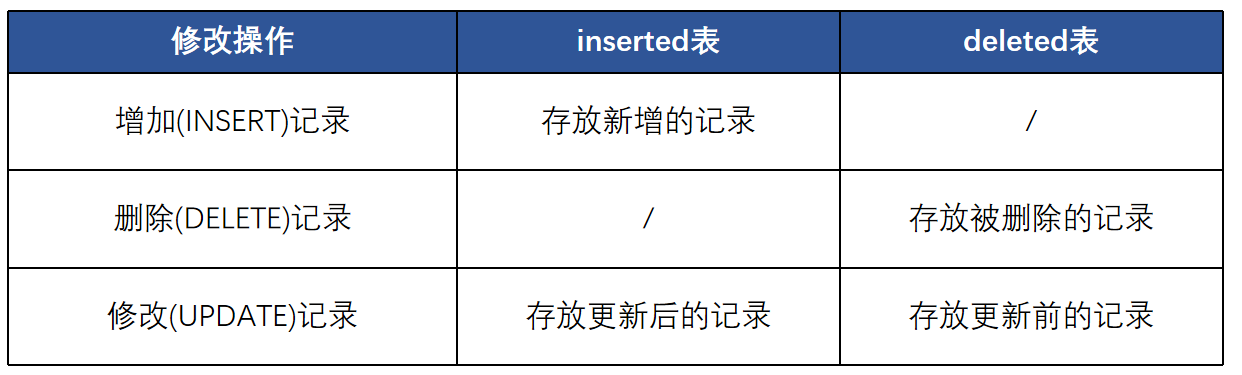
1、Inserted表和Deleted表
触发器触发时
系统自动在内存中创建deleted表或inserted表 只读,不允许修改;触发器执行完成后,自动删除--工具人,任务结束就 “下班”。inserted表(添加或修改)
比如往表里加一条新学生记录,这条新记录会先放进 inserted表; 如果是修改数据(更新),改完后的新数据也会放这里。就像 “新数据的临时存放点”。 可以从这个表里看看新数据符不符合规则。 比如规定学号必须 8 位,结果写入了 10 位,就从这里发现问题。 如果数据有问题,就告诉用户 “搞错啦”,然后把刚才写入或更新的操作取消(回滚)。deleted表(删除或修改)
如果删了一条学生记录,被删掉的这条数据会先存到 deleted表; 如果是修改(更新)数据,更新前的旧数据也会放这里。相当于 “旧数据的备份区”。 从这个表里看看被删掉的数据或旧数据是否该删。 比如误删重要学生记录,就能通过这里发现。 如果发现删错了,就告诉用户 “删错啦”,然后把删除操作取消(回滚), 就像后悔删掉文件,赶紧撤回删除一样。
2、创建DML触发器
CREATE TRIGGER 触发器名称 ON 表名 -- 触发器所作用的表(检测哪个表) [WITH ENCRYPTION] FOR|AFTER|INSTEAD OF [删除操作(DELETE), 添加操作(INSERT), 修改操作(UPDATE)] AS T-SQL 语句 GO[WITH ENCRYPTION]:这是一个可选的子句。WITH ENCRYPTION 用于对触发器的定义进行加密,加密后其他人无法使用 sp_helptext 等系统存储过程查看触发器的源代码,从而提高安全性。
FOR|AFTER|INSTEAD OF:必须从 FOR、AFTER、INSTEAD OF 中选择一个关键字来指定触发时机。
[删除操作(DELETE), 写入操作(INSERT), 更新操作(UPDATE)]:可以选择多个 DELETE、INSERT、UPDATE 操作,以实现对多种数据操作的触发响应。
FOR 和 AFTER
作用:二者功能相同,表明触发器会在指定的数据操作(DELETE、INSERT、UPDATE)成功执行之后触发。也就是说,只有当相应的数据操作在数据库中真正完成后,触发器里的代码才会执行。比如说你往一个学生信息表里写入了一条新的学生记录(数据操作),等这条记录成功写入到数据库之后,数据库就会触发一个触发器,这个触发器可能会去更新另一个统计学生数量的表(StudentCount),把学生总数加1。
INSTEAD OF
作用:表示在执行指定的数据操作之前,先执行触发器中的逻辑,而原数据操作会被替代(以上三种操作将可能不被执行,或换一种操作执行)。比如你有一个视图(可以理解成是一个虚拟的表,从其他表取数据展示出来),你想往这个视图里写入一条数据。但是视图本身可能不能直接写入数据,或者有一些特殊的规则。这时候 INSTEAD OF 触发器就会被触发,然后按照触发器里写好的逻辑,把数据写入到真正能存数据的表里面去,而不是直接对视图进行写入操作,对视图进行修改的将不会被执行。
3、创建INSERT触发器
insert触发器的工作原理:
执行insert写入语句,在表中写入数据行;
触发insert触发器,向系统临时表inserted表中写入新行的备份(副本)
触发器检查inserted表中写入的新行数据,确定是否需要回滚或执行其他操作。例: 当执行INSERT语句往表(如transInfo)写入数据后,触发器会检查inserted表的新数据。 如果数据不符合规则(比如transMoney是负数, 不符合“存入/支取金额必须为正” 的业务要求),触发器就会触发回滚。 回滚会撤销刚才的写入操作,让表回到还没写入这条数据的状态, 确保数据库里的数据始终符合业务规则。问题: 当向交易信息表(transInfo)中写入一条交易信息时,我们应自动更新对应帐户的余额。 在交易信息表上创建INSERT触发器 从inserted临时表中获取写入的数据行 根据交易类型(transType)字段的值是存入/支取,增加/减少对应帐户的余额。CREATE TRIGGER trig_transInfo ON transInfo FOR INSERT AS DECLARE @transType char(4),@transMoney MONEY, @cardID char(10) SELECT @transType =transType,@transMoney =transMoney,@cardID =cardID FROM inserted IF (@transtype='支取') UPDATE bankcustomer SET currentMoney=currentMoney-@outMoney WHERE cardID=@cardID ELSE UPDATE bankcustomer SET currentMoney=currentMoney+@outMoney WHERE cardID=@cardID GO1. 向 transInfo 表插入数据
你得先通过INSERT语句往transInfo表插入新的交易记录。INSERT INTO transInfo (transDate,transType, transMoney, cardID) VALUES (GETDATE(),'支取', 500, '1001 0001');
2. 触发器触发
由于trig_transInfo触发器是基于transInfo表的INSERT操作来触发的(FOR INSERT),所以在transInfo表插入新记录后,触发器就会被自动触发。
3. 触发器执行逻辑更新bankcustomer表
获取插入数据:触发器执行时,数据库会自动创建一个名为inserted的临时表,里面存放着刚刚插入到 transInfo表的新记录。触发器通过SELECT语句从inserted表中获取交易类型、交易金额和银行卡ID并赋值给相应变量。
更新bankcustomer表:根据获取到的交易类型,触发器会执行相应的UPDATE语句来更新bankcustomer表中对应客户的当前余额。如果是“支取”操作,就把余额减去支取金额;如果是其他操作(可理解为 “存入”),就把余额加上存入金额。
注意,如果是多条的话,得这样写CREATE TRIGGER trig_transInfo ON transInfo AFTER INSERT AS BEGIN -- 支取操作:减少余额 UPDATE b SET b.currentMoney = b.currentMoney - i.transMoney FROM bankcustomer b INNER JOIN inserted i ON b.cardID = i.cardID WHERE i.transType = '支取'; -- 存入操作:增加余额 UPDATE b SET b.currentMoney = b.currentMoney + i.transMoney FROM bankcustomer b INNER JOIN inserted i ON b.cardID = i.cardID WHERE i.transType <> '支取'; -- 或其他明确条件如 '存入' END GO把表关联起来,形成只包含新增记录的表,然后对这个表进行操作。
4、创建DELETE触发器
delete触发器的工作原理:
执行delete删除语句,删除表中的数据行;
触发delete删除触发器,向系统临时表的deleted表中写入被删除的副本
触发器检查deleted表中被删除的数据,确定是否需要回滚或执行其他操作。
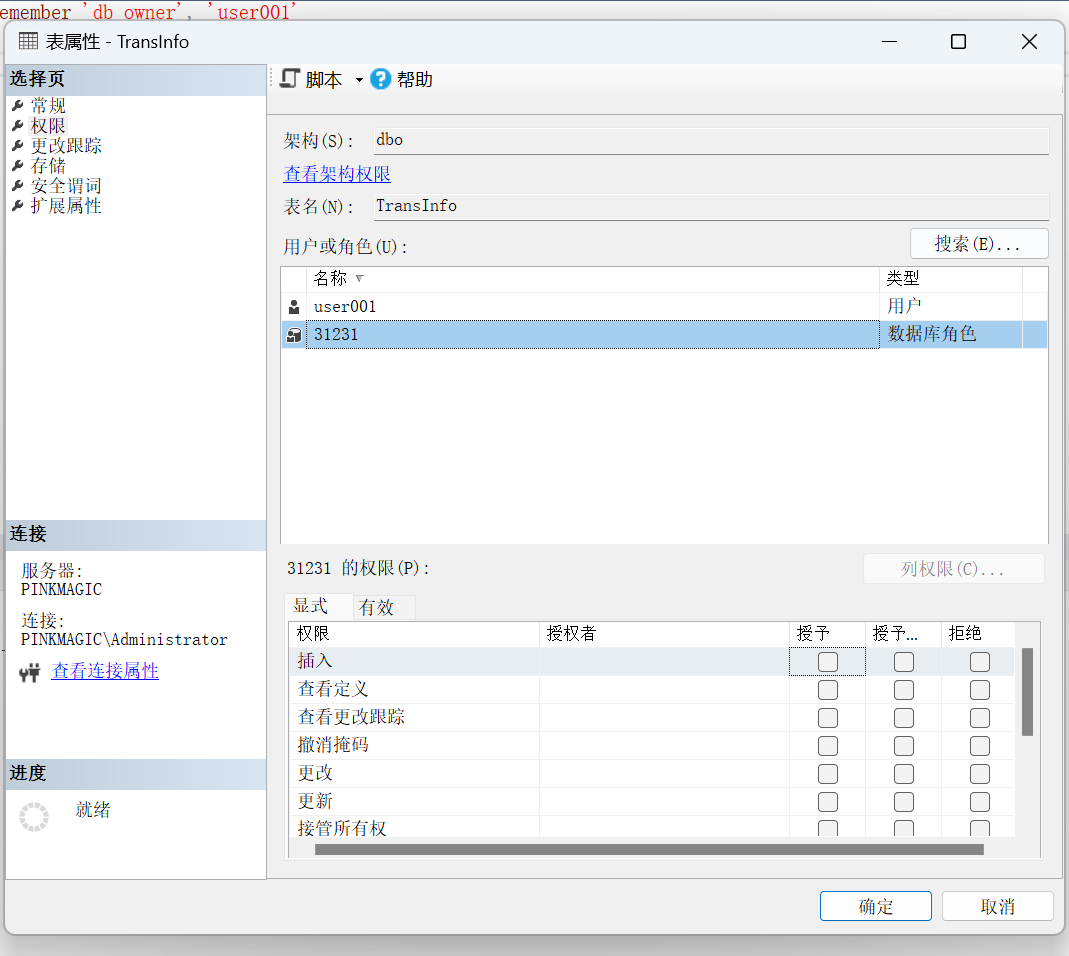
问题: 当删除交易信息表时(只删除记录),要求自动备份被删除的数据到表backupTable中 在交易信息表上创建DELETE触发器 被删除的数据可以从DELETED表中获取CREATE TRIGGER trig_delete_transInfo ON transInfo FOR DELETE AS print '开始备份数据,请稍后......' IF NOT EXISTS(SELECT * FROM sys.tables WHERE name='backupTable') SELECT * INTO backupTable FROM deleted ELSE INSERT INTO backupTable SELECT * FROM deleted print '备份数据成功,备份表中的数据为:' SELECT * FROM backupTable GO DELETE FROM transInfo WHERE transDate='2020-03-22 18:06:00';1、sys.tables:是 SQL Server 的系统表,存储数据库中所有对象的元数据(如表、视图、存储过程等)。
2、SELECT * INTO backupTable FROM deleted
新建backupTable表,并把deleted表里的数据全都放入backupTable里。
3、INSERT INTO backupTable SELECT * FROM deleted
把deleted表的数据插入已有的表backupTable表里。
5、创建UPDATE触发器
执行更新操作,例如把李四的余额改为20001元: 删除李四原有的数据:李四 1000 0002 1,将数据备份到deleted表中。 再写入新行:李四 1000 0002 20001,将数据备份到inserted表中。 最后看起来就是把余额从1元修改为20001元了。 所以:如果我们希望查看修改前的原始数据,可以查看表deleted 。 如果我们希望查看修改后的数据,可以查看表inserted 。
RAISERROR
RAISERROR ('每笔交易不能超过2万元,交易失败',16,1)
第一个参数是错误消息,第二个参数 16 表示错误的严重级别,第三个参数 1 表示错误的状态码。
第二个参数:严重级别
表示错误的严重级别,是一个介于 0 到 25 之间的整数。
不同的严重级别有不同的含义,常见的情况如下:
0 - 10:表示信息性消息,不会导致事务回滚。
11 - 16:表示一般错误,客户端可以处理这些错误。在 RAISERROR ('每笔交易不能超过2万元,交易失败', 16, 1) 中,严重级别为 16,属于一般错误,客户端可以捕获并处理这个错误。
17 - 25:表示严重错误,可能会导致数据库服务器停止响应或者事务回滚。
第三个参数:错误的状态码
这个值可以帮助开发人员区分不同情况下抛出的同一错误消息。
ROLLBACK TRANSACTION --回滚事务,撤销交易
举例
即使满足前面插入和删除的要求(已确定可以进行插入和删除的操作),在对bankcustomer表进行更新时,也需要考虑交易金额是否满足规定。
问题: 跟踪用户的交易,交易金额超过20000元,则取消交易,并给出错误提示。 在bankcustomer表上创建UPDATE触发器 修改前的数据可以从deleted表中获取 修改后的数据可以从inserted表中获取 插入时确保新数据有效 删除时记录操作日志 更新时验证金额是否合规CREATE TRIGGER trig_update_bank ON bankcustomer FOR UPDATE AS DECLARE @beforeMoney MONEY,@afterMoney MONEY SELECT @beforeMoney=currentMoney FROM deleted --先删除数据 SELECT @afterMoney=currentMoney FROM inserted --再更新数据 IF ABS(@afterMoney-@beforeMoney)>20000 BEGIN print '交易金额:'+convert(varchar(8), ABS(@afterMoney-@beforeMoney)) RAISERROR ('每笔交易不能超过2万元,交易失败',16,1) --raiserror用于抛出一个错误 ROLLBACK TRANSACTION --回滚事务,撤销交易 END GOUPDATE bankcustomer SET currentMoney = currentMoney + 30000 WHERE cardID = '1001 0001'; GO

【问题1】创建一个触发器Test1,要求每当在Student表中修改数据时,向客户端显示一条“记录已修改!”的消息。
CREATE TRIGGER Test1 ON Student FOR UPDATE AS PRINT '记录已修改!' GO UPDATE Student SET Pwd=‘112' WHERE StuNo='00000001’ GO 此时无论密码是否变化,只要使用了UPDATE,就会触发该触发器,如果想要根据内容是否变化,可以检查delected和inserted表中该字段是否一致【问题2】在Management Studio中查看触发器信息
简要步骤:StuXK——表student——触发器——右击Test1——修改(可查看也可修改)
FOR/AFTER/INSTEAD OF的比较
INSTEAD OF关键字表示替代原本的操作。比如,INSTEAD OF UPDATE 触发器意味着在触发器中定义的操作会完全替代原始的 UPDATE 操作。
【问题3】将上例中触发器中的FOR UPDATE改为INSTEAD OF UPDATE,查看执行结果有何不同。
ALTER TRIGGER Test1 ON Student INSTEAD OF UPDATE AS PRINT ‘不执行UPDATE操作,记录没有被修改!' GO UPDATE Student SET Pwd=‘223' WHERE StuNo='00000001' GO小结:
使用FOR/AFTER时,执行触发SQL语句(INSERT/UPDATE/DELETE):在触发SQL语句成功执行后,再执行触发器
使用INSTEAD OF时:执行触发器的判断条件,而后决定是否执行触发SQL语句(UPDATE)1. 触发时机
FOR/AFTER 触发器:在触发事件(如 INSERT、UPDATE、DELETE 操作)完成之后才会触发。相当于监控,事后诸葛亮。
INSTEAD OF 触发器:在触发事件执行之前触发。当你执行一条 UPDATE 语句时,INSTEAD OF 触发器会先拦截这个操作,根据触发器中的逻辑决定是否以及如何更新数据(也可以完全不更新,取决于触发器的判断条件)。2. 使用场景
FOR/AFTER 触发器:适用于需要在数据操作完成后进行一些后续处理的场景,如:
数据审计:记录数据的变更历史,包括谁在什么时间对哪些数据进行了修改。
数据同步:当一个表的数据发生变化时,同步更新其他相关表的数据。
业务规则验证:在数据操作完成后,检查数据是否符合某些业务规则,如果不符合则进行相应的处理。
INSTEAD OF 触发器:常用于以下场景:
视图操作:对不支持直接 INSERT、UPDATE 或 DELETE 操作的视图,通过 INSTEAD OF 触发器实现对视图的增删改操作,实际上是对底层基表进行相应的操作。
数据验证和预处理:在数据插入或更新之前,对数据进行验证和预处理,确保数据的合法性和一致性。
复杂业务逻辑处理:在执行某些操作之前,需要进行复杂的逻辑判断和处理,以决定是否执行该操作或如何执行。
INSTEAD OF触发器的设计 如果视图的数据来自于多个基表,则必须使用INSTEAD OF 触发器支持引用表中数据的写入、更新和删除操作。
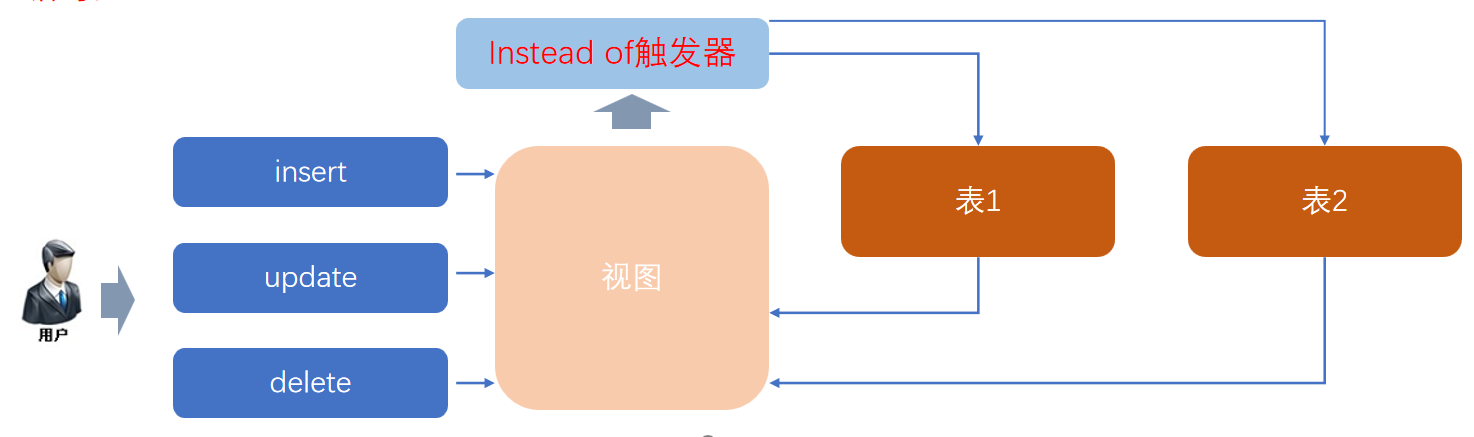
【例5】 在StuXK数据库中创建视图StuCou_view,包含学生学号、学生姓名、课程编号、课程名称、志愿号、报名状态等。说明:该视图依赖于表学生表、选课表和课程表,是不可更新视图。但可以在视图上创建INSTEAD OF触发器,当向视图中写入数据时向选课表写入数据,从而实现向视图写入数据的功能。
(1)创建视图 Create view StuCou_view AS Select Student.StuNo,StuName,Course.CouNo,CouName,WillOrder,State From Student,StuCou,Course Where Student.StuNo=StuCou.StuNo and StuCou.CouNo=Course.CouNo GO(2)创建INSTEAD OF触发器 CREATE TRIGGER TR_stuCou ON StuCou_view INSTEAD OF INSERT AS DECLARE @StuNo varchar(8),@couno varchar(3),@WillOrder int,@state varchar(8) SELECT @StuNo=StuNo,@CouNo=CouNo,@WillOrder=WillOrder,@state=state FROM inserted INSERT INTO StuCou(StuNo, CouNo, WillOrder,state) VALUES(@StuNo, @CouNo, @WillOrder,@state) GO INSERT INTO StuCou_view VALUES('00000009','张三','001','数据库原理与设计',2,'已报名')INSTEAD OF INSERT:
INSTEAD OF 是一种特殊类型的触发器,它会在触发事件(这里是 INSERT 操作)执行之前触发,并且会替代原本的操作。也就是说,当对 StuCou_view 视图执行 INSERT 操作时,不会直接向视图插入数据,而是执行触发器中的逻辑。
DECLARE @StuNo varchar(8), @CouNo varchar(3), @WillOrder int, @state varchar(8):
DECLARE 用于声明变量,这里声明了四个变量,分别用于存储学生编号、课程编号、选课顺序和选课状态。
SELECT @StuNo = StuNo, @CouNo = CouNo, @WillOrder = WillOrder, @state = state FROM inserted:
inserted 是一个特殊的表,在 INSERT 操作触发触发器时,inserted 表会存储要插入到视图中的数据。
这行代码将 inserted 表中的数据赋值给之前声明的变量。
INSERT INTO StuCou(StuNo, CouNo, WillOrder, state) VALUES(@StuNo, @CouNo, @WillOrder, @state):
将从 inserted 表中获取的数据插入到 StuCou 表中,实现了将对视图的插入操作转换为对实际表的插入操作。
1、对不支持直接 INSERT、UPDATE 或 DELETE 操作的视图,通过 INSTEAD OF 触发器实现对视图的增删改操作,实际上是对底层基表进行相应的操作。
INSTEAD OF 触发器就像一个 “翻译官”:
当对视图执行 INSERT/UPDATE/DELETE 时,它拦截操作。
按预设逻辑,将操作 “翻译” 为对底层基表的具体操作(如更新学生表、插入选课表等),从而实现对视图的间接增删改。
2、 对于不满足条件的数据,FOR/AFTER 触发器通过逻辑判断也可以对操作进行撤回。此时会报错。
【问题4】创建一个触发器SetWillNum,要求当写入、更新、删除StuCou表的选课记录时,能更新Course表中相应的报名人数。
CREATE TRIGGER SetWillNum ON StuCou FOR INSERT,UPDATE,DELETE AS UPDATE Course SET WillNum=WillNum+1 WHERE CouNo=(SELECT CouNo FROM INSERTED) UPDATE Course SET WillNum=WillNum-1 WHERE CouNo=(SELECT CouNo FROM DELETED) GO INSERT INTO StuCou VALUES('00000010','008',3,'报名',null);该触发器只适用于每次新增、删除一条记录的情况。
IF UPDATE的应用—列级UPDATE触发器
update触发器除了跟踪数据的变化外,还可以检查是否修改了某列的数据
使用if update(列)检测是否修改了某列
If update不响应delete操作【问题5】修改触发器Test1,要求每当student表中修改pwd列的数据时, 向客户端显示一条消息“密码已更改”的消息。 ALTER TRIGGER Test1 ON Student FOR UPDATE AS IF UPDATE(Pwd) PRINT '选课密码已修改!' GO【问题6】创建一个触发器TEST2,完成功能:每当在Student表中修改数据时, 将向客户端显示一条消息 '二次触发!'。 CREATE TRIGGER Test2 ON Student FOR UPDATE AS PRINT '二次触发!' GO
创建批量数据触发器
ALTER TRIGGER SetWillNum ON StuCou FOR INSERT, UPDATE, DELETE AS IF UPDATE(CouNo) UPDATE Course SET WillNum=(SELECT COUNT(*) FROM StuCou WHERE CouNo=Course.CouNo) GO处理多条记录的触发器简单、易维护,但每次都更新Course中每条记录的报名人数,效率不高
UPDATE Course 表示要对 Course 表进行更新操作。
SET WillNum = ... 用于指定要更新的列和更新的值。这里要更新的列是 WillNum,它代表课程的报名人数。
(SELECT COUNT(*) FROM StuCou WHERE CouNo = Course.CouNo) 是一个子查询,用于统计 StuCou 表中每个课程(通过 CouNo 关联)的记录数量,也就是每个课程的报名人数。然后将这个统计结果赋值给 Course 表中对应课程的 WillNum 列。
管理触发器
删除触发器 DROP TRIGGER trigger_name 说明:删除触发器所在的表时,SQL Server将会自动删除与该表相关的触发器 重命名触发器 sp_rename oldname, newname 禁用触发器 ALTER TABLE table_name DISABLE TRIGGER trigger_name 恢复使用触发器 ALTER TABLE table_name ENABLE TRIGGER trigger_name 显示数据库中有哪些触发器 SELECT * FROM sysobjects WHERE TYPE='TR'
使用触发器的注意事项:
CREATE TRIGGER要在单个批处理中执行(不能被分开执行)
ON table中的表格只能是一个(只能监测一个表格)
在同一条CREATE TRIGGER语句中,可以为多个事件( INSERT/DELETE/UPDATE同时定义相同的触发器操作)
可以为每个事件(INSERT/DELETE/UPDATE)创建多个触发器
DDL触发器
使用Create Trigger 命令创建DDL (建表库约束)触发器的语法:
Create Trigger 触发器名 on { ALL SERVER | DATABASE } --作用域 { FOR | AFTER } { 操作 } as 触发器功能 GO{ ALL SERVER | DATABASE }的 { 操作 } DATABASE操作有:CREATE_TABLE、ALTER_TABLE、 DROP_TABLE、CREATE_USER、CREATE_VIEW 等。 ALL SERVER操作有:CREATE_DATABASE、ALTER_DATABASE等。ON { ALL SERVER | DATABASE }
定义触发器的作用范围:
ALL SERVER:触发器作用于整个数据库服务器,响应服务器级操作(如创建数据库)(一栋大楼)。
DATABASE:触发器作用于当前数据库,仅响应库内操作(如创建表)(一个房间)。
{ FOR | AFTER } { 操作 }
FOR/AFTER(在 DDL 触发器中功能相近)表示触发时机:在指定的 DDL 操作执行后触发。
{ 操作 }:填写具体触发事件,如 CREATE_TABLE(创建表)、DROP_TABLE(删表)等。
AS后编写触发器触发后执行的逻辑,如记录日志、拦截非法操作等。
举例
【例1】 创建XK数据库作用域的DDL触发器,当删除一个表时,提示禁止该操作,然后回滚删除表的操作。
CREATE TRIGGER TR_DropTable ON DATABASE FOR DROP_TABLE AS PRINT '不能删除该表' ROLLBACK TRANSACTION GO【例2】 创建服务器作用域的DDL触发器,当删除一个数据库时,提示禁止该操作并回滚删除数据库的操作。
CREATE TRIGGER TR_DropDB ON ALL SERVER FOR DROP_DATABASE AS PRINT '不能删除该数据库' ROLLBACK TRANSACTION GO
删除DDL触发器使用DROP TRIGGER语句
语法格式: DROP TRIGGER 触发器1 [ ,...n ] ON { DATABASE | ALL SERVER }[ ; ]
【例3】 删除DDL触发器TR_DropTable。 DROP TRIGGER TR_DropTable ON DATABASE 【例4】 删除DDL触发器TR_DropDB。 DROP TRIGGER TR_DropDB ON ALL SERVER
创建和管理游标
游标由查询结果集和游标位置(可以理解为指向当前数据行的行指针)构成 对于游标来说,思维方式是面向行的。某些情况下,当穷尽while循环,子查询,临时表,表变量,自建函数或其他方式仍然无法实现某些查询时(使用之前的方法无法精确到某一行),使用游标。
游标:由查询结果集和游标位置(可以理解为指向当前数据行的行指针)所构成。
游标的概述
游标是一种访问机制,可以将游标看作一种特殊的指针,它可以指向与它相关联的结果集中的任意一行,以便对当前位置的行进行处理。
游标支持以下功能(核心功能):
1)在SELECT结果集中定位特定的数据行
2)对SELECT结果集中当前位置的数据行进行处理(显示、UPDATE、DELETE,不止能定位,还可以处理)
SQL Server支持两种类型的游标:
1)Transcact-SQL服务器游标
2)数据库应用程序编程接口(API)游标函数(主要用在客户端应用程序开发上,大型应用中)
这里介绍T-SQL服务器游标。
游标的使用
声明游标:定义游标,指定游标关联的查询结果集。
打开游标:激活游标,让其准备好操作数据。
使用游标:读取游标位置的数据,修改或删除游标位置的数据,可以和其他T-SQL语句配合灵活使用
关闭游标(与打开游标配对)
释放游标(与声明游标配对,此时释放分配给游标的所有资源)
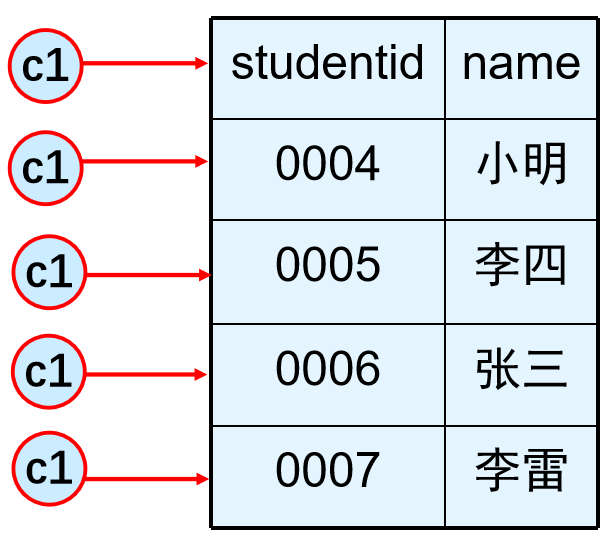
c1名字不变,指向的位置改变
声明游标
DECLARE cursor_name CURSOR [ LOCAL | GLOBAL ] [ FORWARD_ONLY | SCROLL ] [ READ_ONLY | SCROLL_LOCKS | OPTIMISTIC ] FOR select_statement [ FOR UPDATE [ OF column_name [ ,...n ] ] ]cursor:光标
FOR select_statement:For后跟 select语句,相当于给游标指定结果集(赋值)。
LOCAL和GLOBAL二选一: LOCAL意味着游标的生存周期只在批处理或函数或存储过程中可见,而GLOBAL意味着全局内有效;如果不指定游标作用域,默认作用域为GLOBAL
DECLARE @local_cursor1 CURSOR FOR SELECT EmployeeID, EmployeeName FROM Employees; DECLARE @local_cursor CURSOR; SET @local_cursor = CURSOR FOR SELECT col1, col2 FROM table; DECLARE global_cursor1 CURSOR FOR SELECT ProductID, ProductName FROM Products;FORWARD_ONLY 和 SCROLL 二选一:FORWARD_ONLY意味着游标只能从数据集开始向数据集结束的方向读取,FETCH NEXT是唯一的选项;而SCROLL支持游标在定义的数据集中向任何方向,或任何位置移动。
--------
READ_ONLY 、SCROLL_LOCKS、OPTIMISTIC 三选一 :我们均先使用READ_ONLY设定游标为只读,只能读取数据。READ_ONLY:
含义:READ_ONLY 选项将游标设置为只读模式。一旦游标被声明为只读,就不能通过该游标对结果集中的数据行执行更新(UPDATE)或删除(DELETE)操作,只能进行数据的读取。
使用场景:适用于只需要查看数据而不需要修改数据的场景,比如生成报表、进行数据统计等。因为只读游标不涉及数据修改,所以可以减少锁的使用,提高并发性能。SCROLL_LOCKS
含义:SCROLL_LOCKS 选项使用悲观并发控制策略。当游标以 SCROLL_LOCKS 模式声明时,在提取数据行时,数据库会对这些行进行锁定,以防止其他事务在当前事务完成之前对这些行进行修改或删除。这样可以确保在游标操作期间数据的一致性。
使用场景:适用于需要确保数据在操作期间不被其他事务修改的场景,比如在进行数据批量处理时,需要保证每一行数据在处理过程中不发生变化。OPTIMISTIC
含义:OPTIMISTIC选项采用乐观并发控制策略。在这种模式下,数据库不会在提取数据时对数据行进行锁定。当执行更新或删除操作时,数据库会检查自提取数据行以来,这些行是否被其他事务修改过。如果没有被修改,则允许更新或删除操作;如果被修改过,则会产生错误。
使用场景:适用于并发程度较高、数据冲突可能性较小的场景。因为乐观并发控制不需要在提取数据时加锁,所以可以提高并发性能。
--------
FOR UPDATE [OF colunm_name [,…n]]:设定游标允许对当前指向的结果集行数据进行修改,且受上一个参数的影响。如果给出OF column_name[,…n]参数,则只允许修改所给出的列。默认情况下可以修改所有列(不是READ_ONLY)。
DECLARE @EmpCursor CURSOR LOCAL -- 局部游标,作用域限于当前批处理 SCROLL -- 支持任意滚动(如向前、向后移动) OPTIMISTIC -- 乐观并发控制,更新时检查数据是否被修改 FOR SELECT EmpID, EmpName, Salary FROM Employees -- 定义游标作用的查询结果集 FOR UPDATE OF Salary; -- 允许更新 Salary 列
打开游标
打开游标,才能真正获得结果集,执行声明游标语句中的SELECT语句
OPEN cursor_name注意:当全局游标和局部游标变量重名时,默认会打开局部变量游标;指定GLOBAL时打开全局游标。
OPEN myCursor; -- 此时打开的是局部游标 OPEN GLOBAL myCursor;
使用游标
(1)从游标中获取某一行
FETCH [NEXT|PRIOR|FIRST|LAST|ABSOLUTE{n}|RELATIVE{n}] FROM cursor_name [INTO @variable_name[,…n]]第一行(FIRST),最后一行(LAST),下一行(NEXT),上一行(PRIOR),直接跳到某行(ABSOLUTE(n)),相对于目前跳几行(RELATIVE(n))。
注意:默认为NEXT;其它的则需要将游标声明为SCROLL
INTO @variable_name[,…n]:允许将当前行的指定列数据存放到所给出的局部变量列表中,从左到右要与游标SELECT结果集(给游标赋的值)中的列相对应,类型要匹配
FETCH FIRST FROM stuCursor INTO @ID, @Name;把第一行的数据存入两个变量中。 这里的局部变量个数要和前面的数据集的列数一样,且数据类型也要一样,一个局部变量只能存放一个数据(一行一列)。
(2)使用游标修改行(能确保修改的是游标当前指向的行)
更新操作 UPDATE 表名 SET 列名 = 表达式 [, 列名 = 表达式 ...] WHERE CURRENT OF 游标名; UPDATE Students SET Score = Score + 5 WHERE CURRENT OF stu_cursor; 删除操作 DELETE FROM 表名 WHERE CURRENT OF 游标名; DELETE FROM Students WHERE CURRENT OF stu_cursor;
(3)通过全局变量@@FETCH_STATUS 和 WHILE 循环配合,实现对游标结果集的遍历
全局变量@@FETCH_STATUS返回FETCH(获取数据)成功与否,其值为int:
0:FETCH语句成功
1:FETCH语句失败或此行不在结果集中
2:被提取的行不存在
WHILE @@FETCH_STATUS = 0 FETCH NEXT FROM cursor_name
关闭游标
与打开游标配对,用于关闭已打开的游标。关闭游标后,游标关联的结果集临时资源(如执行计划)会被释放,但游标本身仍在内存中保留定义,后续可通过 OPEN 命令再次打开使用。
CLOSE cursor_name
释放游标
与声明游标相配对,用于彻底释放游标占用的所有资源(包括内存空间等)。执行 DEALLOCATE 后,游标定义被删除,无法再通过 OPEN 重新打开。后续只能重新声明才能再次使用。
DEALLOCATE cursor_name
实例分析
创建基本游标
【问题1】声明一个名为CrsCourse的游标,利用该游标将课程编号为'002'的数据行的限选人数修改为22(学习从声明游标到最后释放游标的基本过程)。
--(1)使用DECLARE CURSOR语句声明游标, USE stuxk GO DECLARE CrsCourse CURSOR FOR SELECT * FROM Course ORDER BY CouNo GO --(2)使用OPEN语句打开游标。 OPEN CrsCourse --(3)使用FETCH语句,从游标中查询并返回数据行。 FETCH NEXT FROM CrsCourse --001的课程 FETCH NEXT FROM CrsCourse --002的课程,此时已知当前游标指向的是002课程,所以不需要判断 --(4)将当前数据行的限选人数修改为22 UPDATE Course SET LimitNum=22 WHERE CURRENT OF CrsCourse --(5)使用CLOSE语句关闭游标 CLOSE CrsCourse --(6)使用DEALLOCATE语句释放游标 DEALLOCATE CrsCourse GO
使用FETCH将结果存入变量
【问题2】使用FETCH将结果存入变量。
如果需要判断FETCH数据行中的某列数据如课程号是否为所需要的值,就需要将FETCH到的数据行保存到变量中,且在FETCH之前须先声明这些变量。
FETCH到变量的格式:FETCH [NEXT|PRIOR|FIRST|LAST] FROM cursor INTO @variable_name, ……说明:默认为NEXT;其它的则需要将游标声明为SCROLL。
当游标被打开时,行指针将指向该游标集第1行之前,如果要读取游标集中的第1行数据,必须移动行指针使其指向第1行。可以使用下列操作读取第1行数据:如:Fetch next from mycursor 或者 Fetch first from mycursor
--定义变量 DECLARE @CouNo nvarchar(3),@CouName nvarchar(30) DECLARE CrsCourse2 CURSOR FOR SELECT CouNo,CouName FROM Course ORDER BY CouNo OPEN CrsCourse2 --使用FETCH将值存入变量,注意各变量的顺序、数据类型、数目与游标相一致。 FETCH NEXT FROM CrsCourse2 INTO @CouNo,@CouName --利用变量打印输出 PRINT '课程号:'+@CouNo+'课程名称:'+@CouName CLOSE CrsCourse2 DEALLOCATE CrsCourse2 GO
使用@@FETCH_STATUS遍历结果集
【问题3】编写程序,使用游标逐行显示查询结果集(遍历)的每一行,使用@@FETCH_STATUS作为循环控制变量。
游标适用于需要遍历结果集这样的处理过程。它允许对结果集中的每一行执行不同的操作,而不是整个结果集执行同一操作的情况。
在财务系统中,计算每个客户的信用评级。不同客户信用评级计算规则可能不同, 需逐行处理客户数据。-游标 统计一个包含百万行数据的销售记录表中的总销售额, 使用集合操作(如 SELECT SUM(SalesAmount) FROM SalesRecords ) 能快速得到结果,而使用游标会花费大量时间逐行累加销售额,效率极低。--定义存入Fetch参数的变量 DECLARE @CouNo nvarchar(3),@CouName nvarchar(20) --定义游标 DECLARE CrsCourse CURSOR FOR SELECT CouNo,CouName FROM Course ORDER BY CouNo --打开游标 OPEN CrsCourse --取得第一行数据 FETCH NEXT FROM CrsCourse INTO @CouNo,@CouName --通过判断@@FETCH_STATUS进行循环 WHILE @@FETCH_STATUS=0 BEGIN --PRINT '课程号:' + @CouNo+'课程名称:' + @CouName SELECT @CouNo '课程号',@CouName '课程名称' --取得下一行数据 FETCH NEXT FROM CrsCourse INTO @CouNo,@CouName END --关闭游标 CLOSE CrsCourse --释放游标 DEALLOCATE CrsCourse GO
【练1】使用游标遍历Course表,输出报名人数最多的课程的信息(课程编号、课程名称、报名人数)
DECLARE @CouNo nvarchar(3),@CouName nvarchar(20),@willnum decimal(5,0) ,@max decimal(5,0) select @max= MAX(WillNum) from course --先找到选课数最多的数字 DECLARE CrsCourse3 CURSOR FOR SELECT CouNo,CouName,willnum FROM Course ORDER BY CouNo --打开游标 OPEN CrsCourse3 --取得第一行数据 FETCH NEXT FROM CrsCourse3 INTO @CouNo,@CouName,@willnum --通过判断@@FETCH_STATUS进行循环 WHILE @@FETCH_STATUS=0 BEGIN if @willnum=@max Select @CouNo '课程编号',@CouName '课程名称',@willnum '报名人数' FETCH NEXT FROM CrsCourse3 INTO @CouNo,@CouName,@willnum END --关闭游标 CLOSE CrsCourse3 --释放游标 DEALLOCATE CrsCourse3 GO使用集合操作--子查询 SELECT CouNo AS '课程编号', CouName AS '课程名称', WillNum AS '报名人数' FROM Course WHERE WillNum = (SELECT MAX(WillNum) FROM Course);对集合进行数据查询或处理最好不用游标。
【练2】使用游标遍历Course表,输出总报名人数最多的课程类的信息(课程类别、该类课程的总报名人数)
Declare Cur_course cursor For select kind,sum(willnum)'Sumwillnum' from course group by kind Order by sum(willnum) DESC GO Open Cur_course Fetch next from Cur_course --排在第一个的就是最多的 Close Cur_course Deallocate Cur_course GO
创建带游标的存储过程
在实际应用中,通常配合存储过程(类似定义的函数)使用游标,游标特别适合需遍历表这样的处理过程。如果能合理地将客户端循环处理表的代码转换为存储过程并使用游标来处理,将大大提高数据的处理速度。 用户只需调用存储过程,无需关注内部遍历细节,属于 “自动化处理数据”。
改【问题3】程序为带有游标的存储过程。
CREATE PROCEDURE P_PrintCouName AS DECLARE @CouNo nvarchar(3),@CouName nvarchar(20) DECLARE CrsCourse CURSOR FOR SELECT CouNo,CouName FROM Course ORDER BY CouNo --打开游标 OPEN CrsCourse --取得第一行数据 FETCH NEXT FROM CrsCourse INTO @CouNo,@CouName --通过判断@@FETCH_STATUS进行循环 WHILE @@FETCH_STATUS=0 BEGIN SELECT @CouNo '课程号',@CouName '课程名称' --取得下一行数据 FETCH NEXT FROM CrsCourse INTO @CouNo,@CouName END --关闭游标 CLOSE CrsCourse --释放游标 DEALLOCATE CrsCourse GO EXEC P_PrintCouName --调用存储过程 GO存储过程的封装特性使得代码可重复调用。
【练3】查询姓张同学的学号和姓名,按照姓名升序排序,要求显示为:
/*学号 姓名
02000011 张飞剑
02000046 张峰
………………
*/
SELECT StuNo '学号',StuName '姓名' FROM Student WHERE StuName LIKE '张%' ORDER BY StuName GO【练4】逐行显示姓张同学的学号和姓名,按照姓名升序排序,要求显示为:
/*学号 姓名
02000011 张飞剑
02000046 张峰
………………
*/
--步骤1:声明一个游标 DECLARE Student_Cur Cursor FOR SELECT StuNo '学号',StuName '姓名' FROM Student WHERE StuName LIKE '张%' ORDER BY StuName --步骤2:打开游标 OPEN Student_Cur FETCH NEXT FROM Student_Cur WHILE @@FETCH_STATUS=0 FETCH NEXT FROM Student_Cur --步骤4:关闭游标 CLOSE Student_Cur --步骤5:释放游标 DEALLOCATE Student_Cur GO
小结
游标特别适合需逐行处理数据的过程。
如何使用游标,如何在存储过程中应用游标。
能合理的将客户端循环处理表的代码转换为存储过程,并用游标来处理将有效提高数据的处理速度和降低网络流量。
事务和锁
管理事务
基本概念
数据库事务:是数据库管理系统执行过程中给的一个逻辑单位,由一个有限的数据库操作序列(一系列操作集合)构成。
一个数据库操作序列、一个不可分割的工作单位、恢复和并发控制的基本单位。
典型数据库事务(恢复)例如:
在银行活动中,由账户A转移资金金额X到账户B,是一个典型的银行数据库业务。
这个业务可以分解为两个动作:
从账户A中减掉金额X,在账户B中增加金额X,这两个动作就是一种不可分割的业务单位。
这种动作要么全做,要么都不做,只要有一个环节出现问题,就要回滚。即恢复初始状态
并发控制,例如:多个用户同时提交业务,需要锁来保证互相不干扰。
事务的ACID特性
保障了数据库事务的可靠性
要么全部不完成,原子性(Atomicity):整个事务中的所有操作,要么全部完成,不可能停滞在中间某个环节。
一致性(Consistency):事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。举例:转账前,A+B账户总金额为 1000元;转账事务完成后,无论资金如何转移,A+B的总金额仍为 1000元。事务确保数据从一个合法状态(总金额 1000)过渡到另一个合法状态,不会破坏业务规则。》隔离性(lsolation): 通常来说,一个事务的执行不能被其他事务干扰,用于并发控制。举例:用户A和用户B同时抢购同一张演唱会门票。隔离性确保A的购票事务完成(扣减库存、生成订单)后B 才会读取到最新库存,避免超卖,保证并发操作的数据正确性。
》持久性(Durability):一旦事务提交,则其所作的修改就会永久保存到数据中。举例:用户提交订单支付成功(事务提交),即使此时数据库服务器突然断电,重启后订单的支付状态、库存扣减等修改依然存在,确保数据持久有效。
自动提交事务:SQL Server的默认模式。它将每条单独的T-SQL语句视为一个事务(如SELECT、INSERT、UPDATE、DELETE 等),如果成功执行,则自动提交;如果错误,则自动回滚。无需显式使用BEGINTRANSACTION启动事务。
显示事务:用begin transaction明确指定事务的开始,由commit transaction提交事务、rollback transaction回滚事务
隐式事务:通过设置SET IMPLICIT_TRANSACTIONS ON 语句,将隐性事务模式设置为打开,下一个语句自动启动一个新事务(不需要BEGIN TRANSACTION),每个事务仍以COMMIT或ROLLBACK语句显式完成。再下一个SQL语句又将启动一个新事务。通过SET IMPLICIT TRANSACTIONS OFF把隐性事务模式关闭。三种事务分类的核心区别在于事务的控制方式:
自动提交是“一条语句一个事务”的默认模式;显示事务是开发者手动控制事务边界;隐式事务则是“自动开启事务,但手动结束”的中间模式,适用于需要批量处理但又不想频繁写BEGINTRANSACTION的场景。
事务的操作语句
Begin Transaction:标记事务开始。
Commit Transaction:事务已经成功执行,数据已经处理妥当。
Rollback Transaction:数据处理过程中出错,回滚到没有处理之前的数据状态,或回滚到事务内部的保存点。
Save Transaction:事务内部设置的保存点,就是事务可以不全部回滚,只回滚到这里,保证事务内部不出错的前提下。
begin tran:事务的开始可能是事物过程中最容易理解的概念。它唯一的目的就是表示一个单元的开始。如果由于某种原因,不能或者不想提交事务,那么这就是所有数据库活动将要回滚的起点。也就是说,数据库会忽略这个起点之后的最终没有提交的所有语句begin tran[saction] [事务名称|@事务变量][with mark[<'描述'>]] @事务变量指存储事务名称的变量。commit tran:事务的提交是一个事务的终点。当发出commit tran命令时,可以认为事务执行完毕。也就是说,事务所包含的所有Sql语句执行完毕,事务的影响现在是持久的并会继续,即使系统发生故障也不受影响(只要有备份或数据库文件没有被物理破坏就行)
commit tran[saction] [事务名称|@事务变量]rollback tran:rollback是进行事务回滚,从关联的begin语句开始发生的任何事情都会被忘记,即撤销该事务包含的所有操作。除了允许保存点外,rollback的语法看上去和begin或commit语句一样
ROLLBACK TRAN[saction] [事务名称|@事务变量]save tran:保存事务从本质上说就是创建书签(bookmark)。为书签建立一个名称,在建立了“书签”之后,可以在回滚中引用它。创建书签的好处是可以回滚到代码中的特定点上-只要为想要回滚到的那个保存点命名。
SAVE tran[saction] [保存点名称|@保存点变量]
【例】创建一个事务:把学号为00000001的选修课程号001改为005,把学号为00000002的选修课程号001改为005。以上两个操作任意一个操作失败,事务回滚,查看事务执行结果。
Use StuXK begin transaction t1_student update StuCou set CouNo='005'where StuNo='00000001' and CouNo='001' update StuCou set CouNo='005'where StuNo='00000002' and CouNo='001' if @@ERROR!=0 --@@ERROR 用于获取最后一个执行语句的错误代码。若 @@ERROR!=0(操作出错) rollback transaction t1_student else commit transaction t1_student select * from StuCou where StuNo='00000001'; select * from StuCou where StuNo='00000002';
【例】创建一个事务:把学号为00000001的选修课程号005改为001;把学号为00000002的选修课程号005改为001。第一个操作如果失败,事务回滚,如果成功则设定为保存点;第二个操作如果失败,则事务回滚到保存点,查看事务执行结果。
Use StuXK begin transaction t1_student update StuCou set CouNo='001'where StuNo='00000001' and CouNo='005' if @@ERROR!=0 rollback transaction t1_student else save transaction st1 update StuCou set CouNo='001'where StuNo='00000002' and CouNo='005' if @@ERROR!=0 rollback transaction st1 else commit transaction t1_student 当第一个执行成功第二个未执行成功,else则不会执行。
【例】使用ROLLBACK TRANSACTION回滚事务简单示例。定义一个事务,向StuCou表插入3行数据,并回滚撤销。想想:该题中的逻辑工作单元是?撤销事务,结果如何?
USE Xk GO --开始事务 BEGIN TRANSACTION INSERT StuCou(StuNo,COuNo,WillOrder,state) VALUES ('00000025','001',1,'报名') INSERT StuCou(StuNo,COuNo,WillOrder,state) VALUES ('00000025','002',2,'报名') INSERT StuCou(StuNo,COuNo,WillOrder,state) VALUES ('00000025','003',3,'报名') SELECT * FROM StuCou WHERE StuNo='00000025' --撤销事务 ROLLBACK TRANSACTION --(2) SELECT * FROM StuCou WHERE StuNo='00000025'回滚可以让数据库状态恢复到事务开始前,回滚本质是撤回,是执行了之后再撤回
【例】--在嵌套事务中只有在提交了最外层的事务后,数据才执行永久修改。
--①只提交内层事务 --②只提交外层事务
--(1)创建表testtran ,其中包括整型列A和字符型列B CREATE TABLE TestTran (A INT, B CHAR(3)) GO --(2)开始最外层事务tran1 BEGIN TRANSACTION Tran1 GO INSERT INTO TestTran VALUES (1, 'aaa') GO select * from TestTran --(3)开始内层事务tran2 BEGIN TRANSACTION Tran2 GO INSERT INTO TestTran VALUES (2, 'bbb') GO select * from TestTran --(4)开始内层事务tran3 BEGIN TRANSACTION Tran3 GO INSERT INTO TestTran VALUES (3, 'ccc') GO select * from TestTran --(5)提交事务tran3 COMMIT TRANSACTION Tran3 GO --(6)提交事务tran2 COMMIT TRANSACTION Tran2 GO --(7)提交事务tran1 --在提交了最外层的事务后,数据才执行永久修改。 COMMIT TRANSACTION Tran1 GO第二个事务在第一个事务的内部,第三个事务在第二个事务内部,只有当外部事务执行完毕,所有的事务才算执行完成。
【例】--只能撤销最外层的事务,不能撤销最内层事务,否则会导致错误。
--(1)创建表testtran ,其中包括整型列A和字符型列B CREATE TABLE TestTran (A INT, B CHAR(3)) GO --(2)开始最外层事务tran1 BEGIN TRANSACTION Tran1 GO INSERT INTO TestTran VALUES (1, 'aaa') GO --(3)开始事务tran2 BEGIN TRANSACTION Tran2 GO INSERT INTO TestTran VALUES (2, 'bbb') GO --(4)开始事务tran3 BEGIN TRANSACTION Tran3 GO INSERT INTO TestTran VALUES (3, 'ccc') GO --(5)执行如下SQL 语句进行测试比较 --ROLLBACK TRANSACTION Tran3 --ROLLBACK TRANSACTION Tran2 --(6)执行如下SQL 语句进行测试比较 ROLLBACK TRANSACTION Tran1 --或 ROLLBACK TRANSACTION --(7)表testtran仅仅是用于本例测试,所以应删除表TestTran DROP TABLE TestTran只有 ROLLBACK TRANSACTION Tran1(回滚最外层事务),才能成功撤销整个嵌套事务内的所有操作,回滚到内层事务,会找不到事务名称。
【例】启动隐式事务,执行相关更新操作(两个事务),然后关闭隐式事务
set implicit_transactions on use StuXK update StuCou set CouNo='005'where StuNo='00000001' and CouNo='001' update StuCou set CouNo='005'where StuNo='00000002' and CouNo='001' commit transaction update StuCou set CouNo='001'where StuNo='00000001' and CouNo='005' update StuCou set CouNo='001'where StuNo='00000002' and CouNo='005' commit transaction set implicit_transactions off --需要关闭隐式模式
并发和隔离级别
事务和并发的关系
一个数据库可能拥有多个访问用户,多个用户以并发方式访问数据库(订票)。数据库中的相同数据可能被多个事务同时访问,如果没有采取必要的隔离措施,就会导致各种并发问题,破坏数据的完整性,带来数据不一致的问题:
并发引起的数据不一致问题
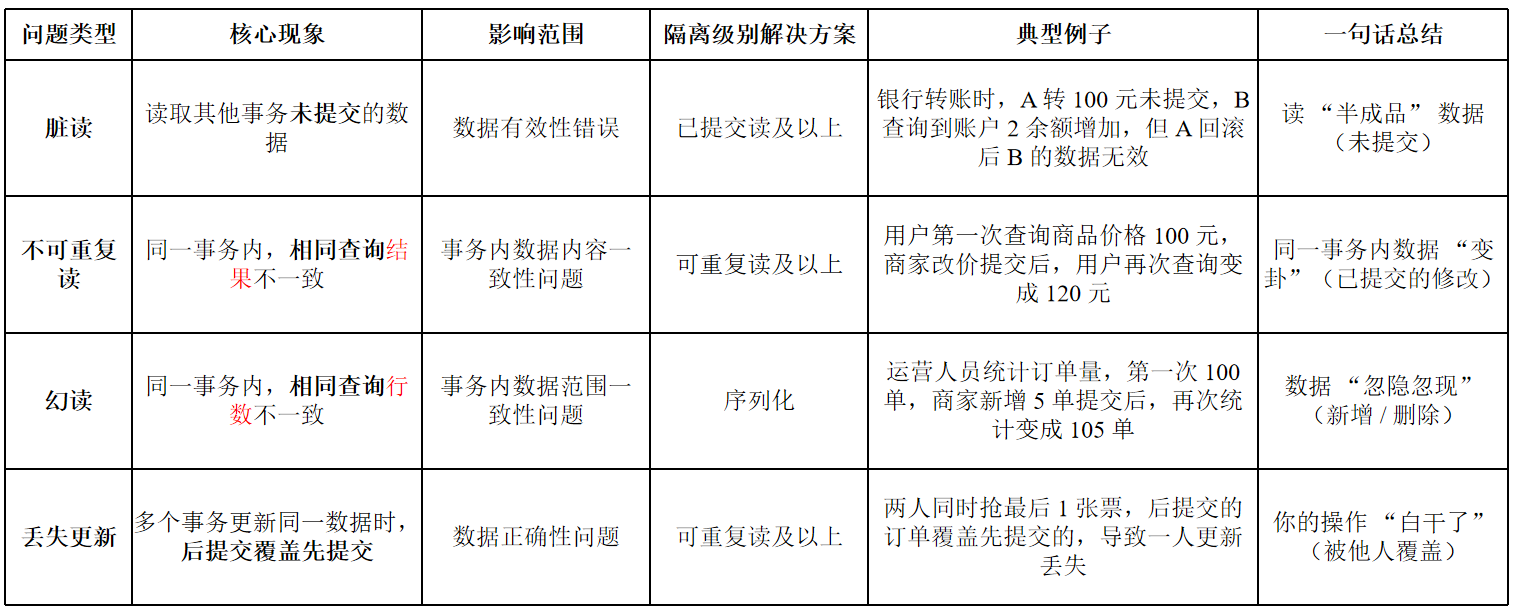
脏读:一个事务读取到了另外一个事务没有提交的数据
场景:事务 A 修改数据但未提交,事务 B 读取了该数据。若 A 回滚,B 读取到的数据是无效的。
例子:银行转账时,A 从账户 1 转 100 元到账户 2(未提交),B 查询账户 2 发现余额增加 100 元。但 A 最终回滚,B 的查询结果是错误的。
可以通过设置隔离确保事务 B 不会读取到事务 A 未提交的临时数据。不可重复读:同一事务内,相同查询多次执行结果不一致(因其他事务提交了修改,注意是修改)。
例子:以网购电脑为例,用户开启事务 A,首先查询某型号电脑价格为 6000 元。此时,商家因促销活动调整价格,通过事务 B 将价格改为 6200 元并提交。用户在事务 A 内(同一个事务)继续操作,进入付款流程时,系统再次查询价格确认,显示为 6200 元 —— 同一事务内,两次查询价格结果不同,这就是 “不可重复读”。
若用户操作采用 “可重复读” 隔离级别,相当于给商品价格 “加锁”。在事务 A 结束前,其他事务的改价操作无法生效。用户第一次查询价格为 6000 元,后续付款环节系统再次查询,价格依然是 6000 元,确保整个事务内价格始终一致,避免了 “不可重复读” 问题。
一个事务里可以有多个对同一个数据进行查询的语句,所以就可能有一个事务里对同一个数据查询得到的数据不一致的问题。
幻读:同一事务内,相同查询(一个事务内可以有多个对同一个数据查询的语句)多次执行结果的行数不一致(因其他事务插入 / 删除(注意不是修改)数据),已提交。
例子:外卖平台运营人员开启事务 A 统计某餐厅本月外卖订单量,第一次在事务A内查询显示 100 单。此时,餐厅商家的事务 B 处理新下单的 5 单外卖并提交记录。运营人员在事务 A 内第二次进行订单量查询,发现订单量变为 105 单 —— 新增的 5 单如同 “幻象” 出现,这就是幻读。 若运营人员的查询开启高隔离级别事务(如串行化),相当于给 “订单统计范围” 加 “围栏”。在事务 A 结束前,其他事务(如商家新增订单操作)无法插入数据。因此,运营人员在事务 A 内多次执行订单量查询,结果始终保持首次查询的 100 单,避免了幻读问题。
丢失更新:事务T1读取了数据,并执行了一些操作,然后更新数据。事务T2也做相同的事,则A和B更新数据时可能会覆盖对方的更新,从而引起错误
例子:热门演唱会售票,你(事务 A)和朋友(事务 B)同时抢最后 1 张票,两人均看到余票显示 “1 张”。若没事务控制,系统可能先处理你的订单,余票减为 0;但朋友的订单后提交,又覆盖成自己成功扣减。最终你的订单显示 “抢票失败”,辛苦操作因朋友的更新覆盖而 “丢失”,这就是典型的丢失更新 —— 双方都改同一数据,后提交的覆盖先提交的,导致部分操作结果消失。
数据库通过事务机制控制更新顺序,避免相互覆盖。
加上隔离之后,你(事务 A)先操作抢票,数据库立刻给这张票 “上把锁”,此时朋友(事务 B)只能等待,无法操作同一张票。 你完成订单(事务 A 提交),锁解开,朋友(事务 B)才能操作。 最终,要么你成功扣减余票(朋友后续看到无票),要么你取消(朋友操作时余票已恢复)。
SQL Server中的隔离级别
在并发情况下,如果没有采取必要的隔离措施,就会导致各种并发问题,像上面提到的脏读、不可重复读等等、幻读、丢失更新;使用不同的事务隔离级别,可以不同程度的解决这些问题。
SQL Server提供了多种隔离级别,隔离等级由低到高分别为:未提交读、已提交读、可重复读、和序列化
较低的隔离级别可以增强许多用户同时访问数据的能力,但也会增加并发带来的副作用
未提交读(Read Uncommited):可以读修改但未提交的,不能解决事务并发操作的脏读,不可重复读,幻读,丢失更新
已提交读(Read commited):提交了才能读取到,可以解决未提交读,不能解决不可重复读、幻读、丢失更新
可重复读(Repeatable Read):在已提交读的基础上,其它事务不能修改在当前事务完成之前当前事务读取的数据;可以解决脏读、不可重复读和丢失更新的问题(涉及数据修改),不能解决幻读(涉及增加或减少行)。
序列化(Serializable):最强的隔离级别,该级别锁定整个范围的键(不能修改或删除、写入),能解决事务并发操作的脏读、不可重复读、幻读、丢失更新问题
事务隔离主要就是对不同事务的读写之间进行隔离,通过什么来实现隔离?
通过锁来实现隔离
通过对事务的读写操作加锁情况的不同,划分出不同的事务隔离级别


管理锁
封锁类型
封锁技术是实现并发控制的主要方法
封锁的定义:约定当一个事务在对某个数据对象(可以是数据项、记录、数据集,甚至整个数据库)进行操作之前,必须获得相应的锁,以保证数据操作的正确性和一致性。
锁是数据库系统对数据对象(如记录、页、表)的访问控制机制,而非直接绑定到事务本身。
基本的封锁类型:
共享锁(又称为读锁和S锁)
排它锁(又称为写锁和X锁)
锁的使用场景
非事务场景:锁仅在语句执行期间有效,语句结束后自动释放。
事务场景:锁持续到事务提交 / 回滚(取决于隔离级别)。
封锁协议不能解决幻读,需要借助其他的规则。
排它锁(X锁/写锁):若事务T对数据对象A加上X锁,则只允许T读取和修改A,其他任何事务都不能再对A加任何类型的锁,直到T释放A上的锁为止(这保证了其他事务在T释放A上的锁之前不能再读取和修改A)
共享锁(S锁/读锁):若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁为止(这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改)
排它锁(X锁/写锁):你拿到一个笔记本,立刻给它上把锁(X 锁)。这时候,只有你能看这个笔记本,还能在上面写东西。其他人在你没解锁之前,连碰都不能碰 —— 既不能看里面写了啥,也不能拿它写字画画,必须等你用完把锁解开,别人才能使用笔记本电脑。 共享锁(S锁/读锁):你借了一本漫画书,给书加个锁(S 锁)。这时你可以看,其他同学也能一起看这本漫画(大家共享 “读” 的权利),但所有人都不能在漫画书上乱涂乱画、修改内容。只有等你把锁解开,别人才有可能对漫画书做进一步操作(比如修改)。兼容性矩阵
1. 请求锁类型:S 锁(读锁)
当前对象上现有锁类型(S 锁):
兼容(允许多个读):多个事务可同时对同一数据加 S 锁。例如,多个用户同时查询商品价格,都加 S 锁,彼此不冲突,支持并发读取。
当前对象上现有锁类型(X 锁):
互斥(不允许读):若数据已被 X 锁(写锁)锁定(如某事务正在修改商品价格),其他事务不能再加 S 锁。这是为了确保写操作时,数据不被读取干扰,避免脏读。
2. 请求锁类型:X 锁(写锁)
当前对象上现有锁类型(S 锁):
互斥(不允许写):若数据已被 S 锁锁定(有事务在读数据),其他事务不能加 X 锁。例如,用户正在读取商品库存时,系统不允许同时修改库存,保证读操作完成后再执行写操作,避免数据不一致。
当前对象上现有锁类型(X 锁):
互斥(不允许写):写操作具有排他性,同一时间只允许一个事务对数据加 X 锁。例如,两个事务同时尝试修改商品价格,需排队等待,确保修改操作原子性(事务的完整性)。
怎么加锁 1、非事务锁--锁仅在语句执行期间有效 -- 立即查询并加X锁,语句结束后释放 SELECT * FROM Product WHERE ProNo = '00003' WITH (XLOCK); -- 立即更新并加X锁 UPDATE Product SET Stocks = Stocks - 100 WHERE ProNo = '00003' WITH (XLOCK); 2、事务锁--通过 WITH (<lock_hint>) 子句指定锁类型 BEGIN TRANSACTION; -- 加共享锁(S锁),允许其他事务读但不允许写 SELECT * FROM Product WHERE ProNo = '00003' WITH (SLOCK); -- 加排他锁(X锁),禁止其他事务读写 SELECT * FROM Product WHERE ProNo = '00003' WITH (XLOCK); COMMIT TRANSACTION;

封锁协议(隔离级别)
通过封锁协议,可以保证合理得进行并发控制,保证数据的一致性。
封锁协议是指一定的封锁规则(针对锁的操作),比如何时开始封锁、封锁多长时间、何时释放等等
封锁协议类型:不同的封锁协议,可以解决并发可能遇到的不同的问题
一级封锁协议 二级封锁协议 三级封锁协议
一、
二、
三、
一旦确定了封锁协议(通过设置事务隔离级别),数据库会自动遵循相应的锁规则,无需手动添加锁提示。
-- 设置为一级封锁协议(READ UNCOMMITTED) SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; BEGIN TRANSACTION; -- 读取数据时不加锁(允许脏读) SELECT SUM(Amount) FROM Transactions; COMMIT; -- 无需显式设置(默认是 READ COMMITTED) BEGIN TRANSACTION; -- 读操作加共享锁(S 锁),读完立即释放 SELECT * FROM Orders WHERE OrderID = 123; COMMIT; -- 设置为三级封锁协议(REPEATABLE READ) SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; BEGIN TRANSACTION; -- 第一次读取库存 SELECT Stock FROM Inventory WHERE ProductID = 456; -- 模拟其他操作(如检查库存逻辑) -- 第二次读取库存,结果与第一次一致 SELECT Stock FROM Inventory WHERE ProductID = 456; COMMIT;




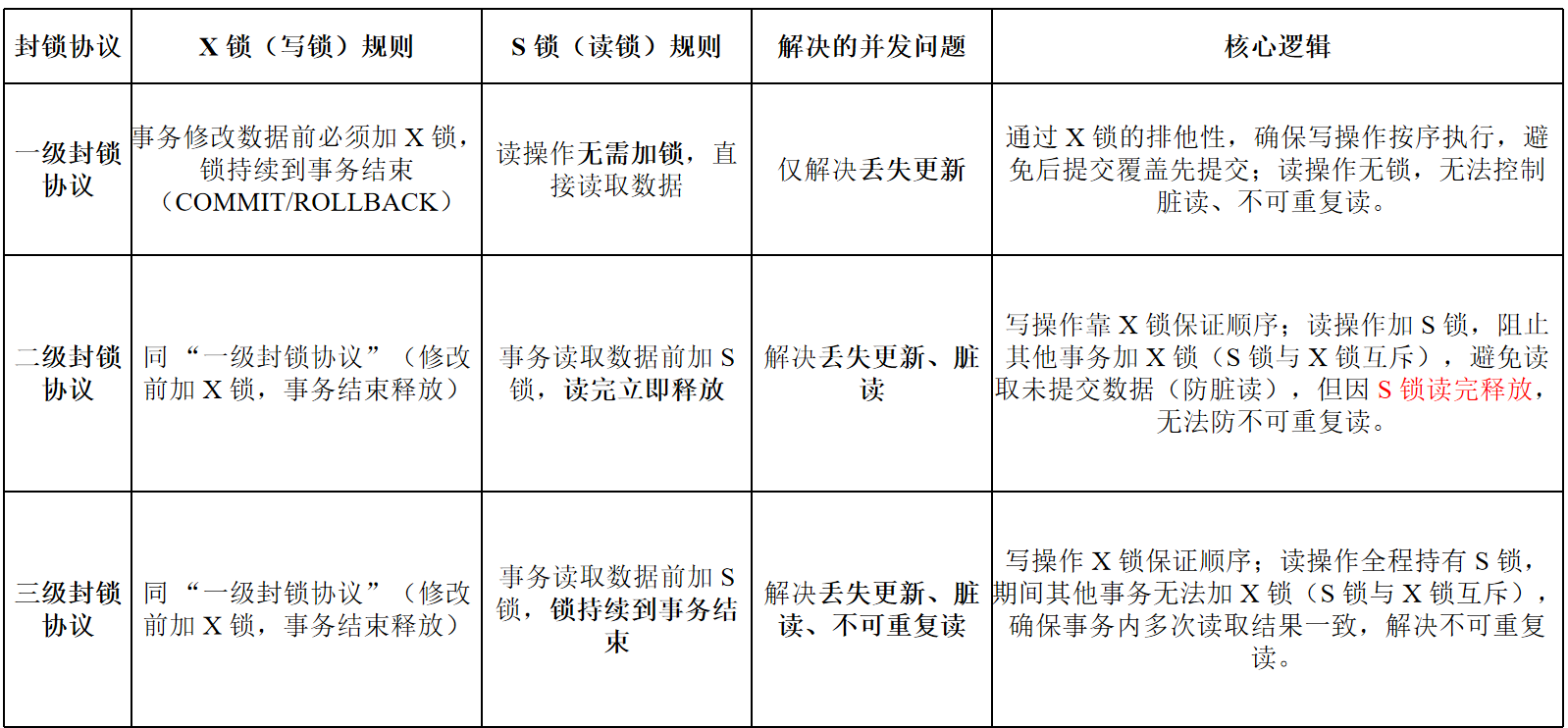
一级封锁协议
事务在修改数据之前必须先对其加X锁,直到事务结束才释放。(事务结束包括正常结束COMMIT和非正常结束ROLLBACK)
一级封锁协议可以防止丢失更新 但不能防止脏读(在读取数据时,其他事务可以修改该数据)和不可重复读(第二次读也之前也允许数据被修改)
(一级封锁协议下读取不受限制)
可以保证数据修改的先后顺序
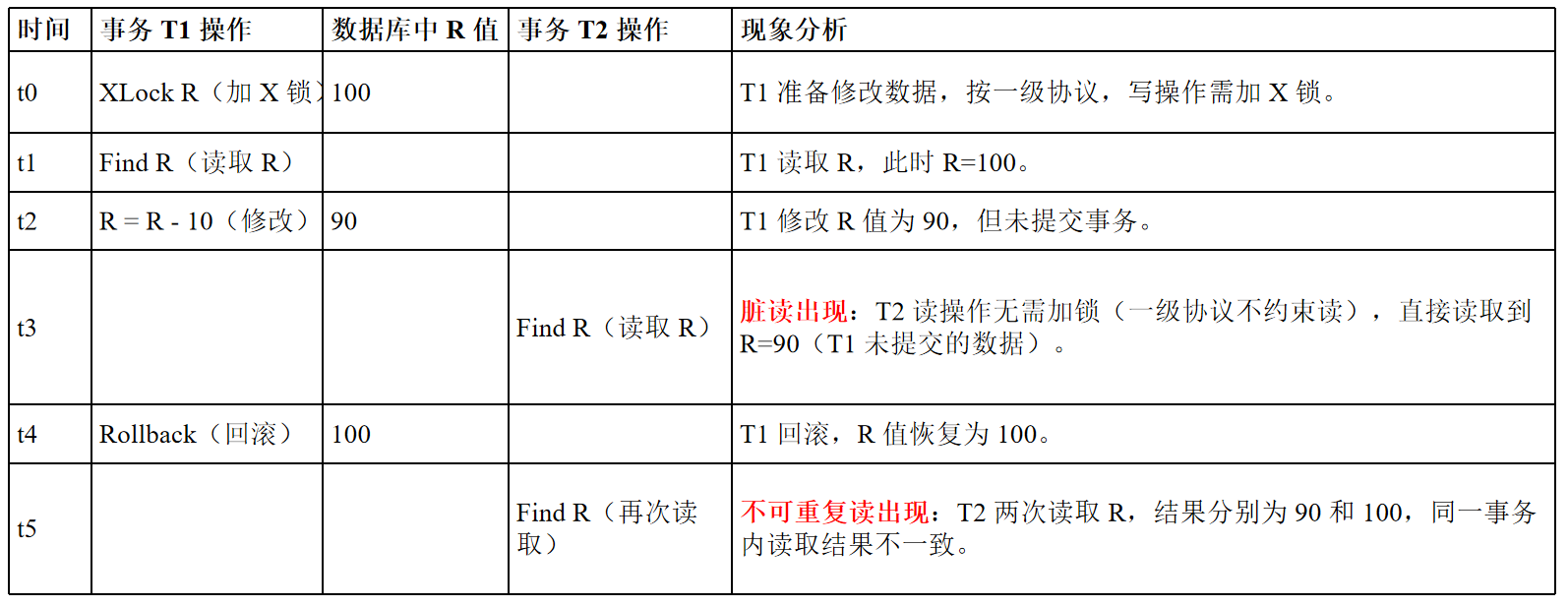
二级封锁协议
在一级封锁协议的基础上增加事务T在读取数据之前必须先对其加S锁,读完后即可释放S锁
二级封锁协议可以防止丢失更新、防止脏读(在读取前要加S锁,所以读不到90); 但不能防止不可重复读(第一次读取完就释放了S锁)
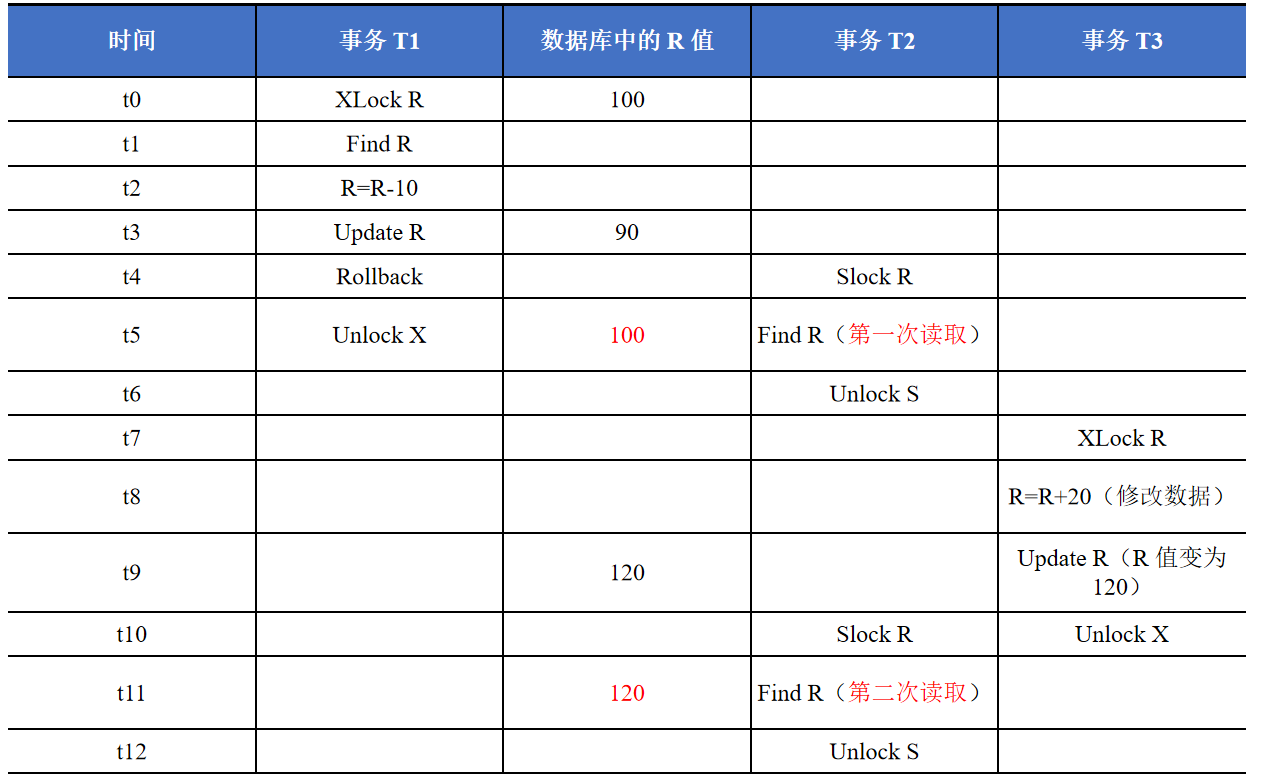
三级封锁协议
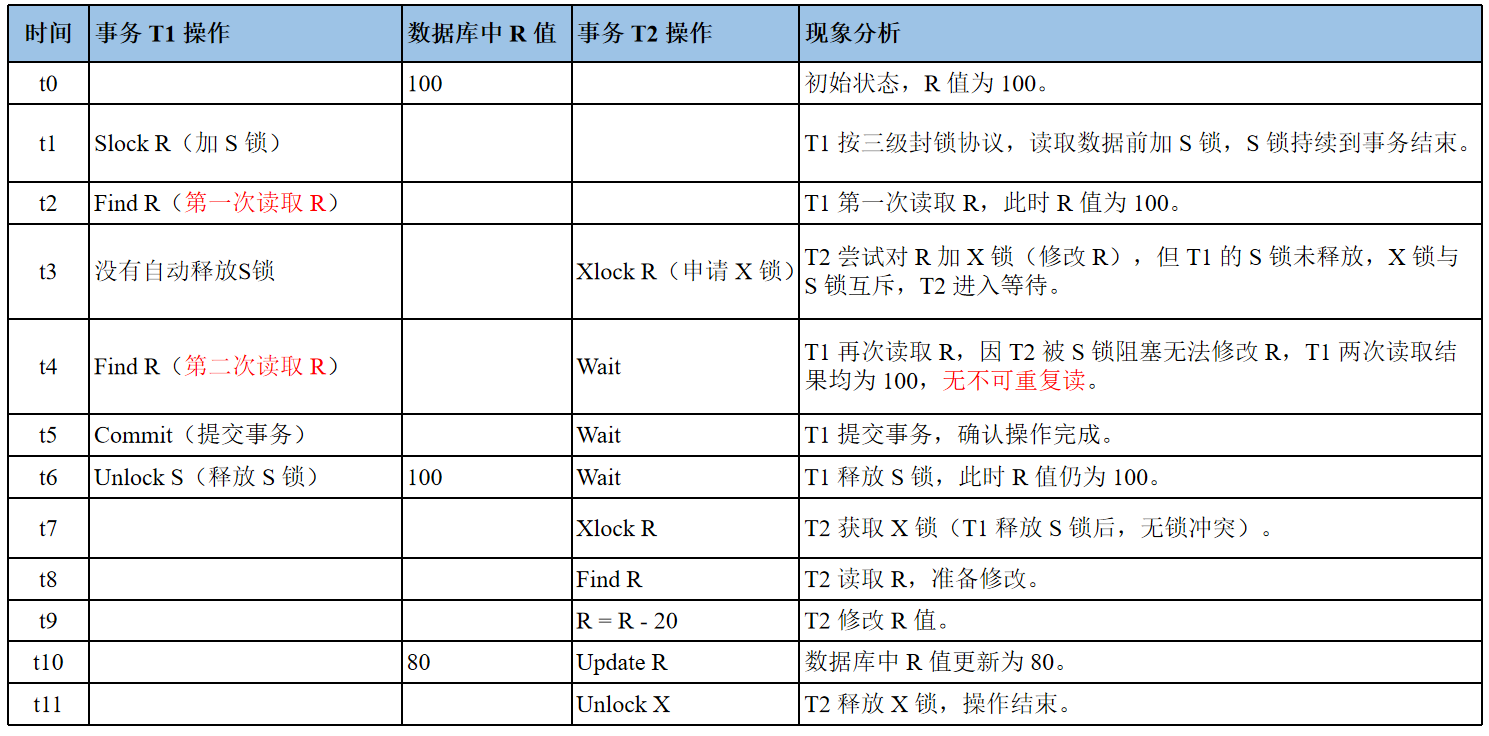
在一级封锁协议的基础上,事务T在读取数据之前必须先对其加S锁,读完之后不释放S锁,直到事务T结束才释放
三级封锁协议可以防止丢失更新、防止脏读、防止不可重复读
死锁的产生、解除和预防
死锁的概念
在同时处于等待状态的两个或多个事务中,其中的每一个在它能够进行之前,都等待着某个数据,而这个数据已被他们中的某个事务所封锁,这种状态叫做死锁。
每队汽车都占有一条道路,但都需要另外一队汽车所占有的另一条道路,因此互相阻塞,谁都无法前行,因此造成了死锁。
假设两个事务:
事务 T1:锁定数据 A,等待获取数据 B;
事务 T2:锁定数据 B,等待获取数据 A。
此时,T1 和 T2 形成循环等待:T1 等 T2 释放 B,T2 等 T1 释放 A,最终双方都无法推进,导致死锁。
死锁的产生
事务T1更新表 Student StuNo='003' 这条数据,请求X锁,成功。
事务T2更新表 Student StuNo=‘002’ 这条数据,请求X锁,成功(因为作用于不同的数据)。
3秒过后
事务T1更新表 Student StuNo=‘002’ 这条数据,请求X锁,由于事务T2占用着表 Student StuNo=‘002’ 这条数据,所以,事务T1等待(因为作用于相同的数据,互斥)。
事务T2更新表 Student StuNo=‘003’ 这条数据,请求X锁,由于事务T1占用着表 Student StuNo='003' 这条数据,所以,事务T2等待
死锁的产生条件
互斥条件:一个资源(数据)每次只能被一个进程使用。
请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
因为两者都是在一个事务里进行的步骤,所以此时两个事务都没有结束。
不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
死锁的诊断和解除
数据库搜索引擎会定期检测这种状况,一旦发现有死锁情况存在,会选择一个事务作为牺牲品。可以选择一个处理死锁代价最小的事务,将其撤销以解除死锁,使系统从死锁的状态中恢复。最简单最暴力的方法是重启。
在大型数据库中,高并发带来的死锁是不可避免的,尽管不能完全避免,但遵守特定的惯例可以将发生死锁的机会降至最低,有效预防死锁
使用sp_lock系统存储过程显示sql server中当前持有的所有锁的信息
USE master GO EXEC sp_lock GO
避免死锁的方法
按同一顺序访问对象: 按同一顺序访问对象也就是:第一个事务提交或回滚后,第二个事务继续进行,这样不会发生死锁。
避免事务中的用户交互: 避免编写包含用户交互的事务。
保持事务简短并在一个批处理中: 保持事务在一个批处理中,可以最小化事务的网络通信往返量,减少完成事务可能的延迟并释放锁。
使用低隔离级别:确定事务是否能在更低的隔离级别上运行。使用较低的隔离级别比使用较高的隔离级别持有共享锁的时间更短,减少了锁的征用。
SQL Server数据库安全管理
安全性是数据库管理系统的重要特征。能否提供全面、完整、有效、灵活的安全机制,往往是衡量 一个分布式数据库管理系统是否成熟的重要标志,也是用户选择合适的数据库产品的一个重要判断 指标。 Microsoft SQL Server 系列提供了一整套保护数据安全的机制,包括角色、架构、用户、权限等手段,可以有效地实现对系统访问和数据访问的控制。
SQL Server数据库 安全管理概述
三个关于安全性问题
SQL Server的安全性是建立在身份验证和访问许可两种安全机制上。
身份验证:用户是否具有连接SQL Server的权限
访问许可:用户是否可以登录数据库,使用数据库对象及对这些对象进行操作
通过身份验证并不代表能够访问SQL Server中的数据对象1. 身份验证:确认 “你是谁”
身份验证是数据库对用户身份的合法性检查。例如,用户输入正确的用户名、密码(或通过 Windows 身份验证等方式),SQL Server 验证通过后,允许用户连接到数据库系统。这一步仅证明用户有登录数据库的资格。
2. 权限授权:决定 “你能做什么”
即使通过身份验证,用户若想访问具体数据对象(如表、视图、存储过程等),还需具备对应的权限。例如:
若用户没有 SELECT 权限,即使登录成功,也无法查询表中的数据;
若没有 UPDATE 权限,就不能修改表中记录。
安全性是所有数据库管理系统的一个重要特征和研究方向。理解安全性问题是理解数据库管理系统安全性机制的前提。
第一个安全性问题:
当用户登录数据库系统时,如何确保只有合法的用户才能登录到系统中?这是一个最基本的安全性问题,也是数据库管理系统提供的基本功能。
在Microsoft SQL Server 系统中,通过身份验证模式和主体解决这个问题。
Windows验证模式:利用了Windows本身具备的管理登录、验证用户合法性的能力,允许SQL Server用户登录时使用Windows的用户名和口令。
混合验证模式:混合验证模式接受Windows授权用户和SQL授权用户。如果不是Windows操作系统的用户也希望使用SQL Server,那么应该选择混合验证模式。
SQL Server推荐使用Windows验证模式。
第二个安全性问题:
当用户登录到系统中,他可以执行哪些操作、使用哪些对象和资源?
在Microsoft SQL Server 中,通过安全对象和权限设置来解决这个问题。
层级化的主体和安全对象结构,SQL Server 实现了精细化的权限管理,确保用户仅能操作被授权的资源。
-------
主体(比如某个用户或角色)会向安全对象发起请求,比如 “我想查询这张表”。但能不能操作,由 SQL Server 的 权限设置 决定。比如:
给 “数据库用户” 开放某张表的 “查询权限”,这个用户才能查数据;
给 “固定数据库角色” 分配存储过程的 “执行权限”,角色里的成员才能运行这个存储过程。
通过这种结构,SQL Server 精准控制用户能操作哪些资源,确保安全性。----------------------
数据库用户、固定数据库角色、应用程序角色三者的区别:
数据库用户:员工进入大楼的 “专属门禁卡”
银行员工要进入 “数据大楼”(操作数据库),首先得有 “门禁卡”,这就是数据库用户。只有持有这张 “卡”(拥有数据库用户身份),员工才能合法进入大楼,否则连大楼的门都进不去。
固定数据库角色(如 db_editor):大楼内的 “权限区域许可”
员工凭 “门禁卡”(数据库用户)进入大楼后,并非能随意活动。若想进入 “修改客户信息表” 的区域(执行对应操作),需要加入 “固定数据库角色”(如 db_editor)。这就像大楼里的 “区域许可”,加入 db_editor 角色,相当于获得 “允许修改客户信息表” 的许可,员工才能在这个特定范围内工作(执行修改操作)。
应用程序角色:银行 APP 的 “专属功能通道”银行 APP 访问数据库,就像在大楼里有一条 “专属通道”,这条通道由应用程序角色定义。例如,APP 只能通过这条通道使用 “查询账户余额”“插入交易记录” 的功能(执行对应操作),其他区域(如用户隐私数据区)完全无法进入。这既让 APP 能正常提供服务(满足业务需求),又通过隔离权限保障了数据安全(防止 APP 权限滥用)。
第三个安全性问题:
数据库中的对象由谁所有?如果是由用户所有,那么当用户被删除时,其所拥有的对象怎么办,难道数据库中的对象可以没有所有者吗?
在数据库中,每个对象(如表、视图、存储过程等)都有明确的所有者(通常为创建该对象的用户)。当用户被删除时,若其拥有的对象不做处理,会导致对象无所有者,进而引发权限管理混乱(如无法确定谁有权限操作、维护这些对象),破坏数据库的安全性与完整性。因此,数据库管理系统需提供相应机制处理此类情况,例如:将对象所有权转移给其他用户(如管理员),或通过特定规则重新指定所有者,确保对象始终有归属,维持数据库权限体系与结构的一致性,避免因用户删除导致对象 “悬空” 而产生安全隐患与管理漏洞。
服务器与数据库权限体系的核心流程:
1、成功登录到服务器上(数据库软件运行在服务器操作系统之上)
2、成为数据库的合法用户(合法用户不一定能访问所有数据库,需通过权限分配获得对特定数据库、表、视图等对象的操作权限。)
3、拥有存取权限
管理登录账号和数据库用户
管理登录账号
什么是登录账号:为了访问SQL Server系统,用户必须提供正确的登录账号。这些登录账号既可以是Windows登录账号(通过Windows账号来登录sql server,相当于Windows已经信任sql server了),也可以是SQL Server登录账号(根据身份验证模式)。
什么是登录账号管理:登录账号管理包括查看登录名信息、创建登录名、设置密码策略、修改和删除登录名等。
注意,sa是一个默认的SQL Server登录名,拥有操作SQL Server系统的所有权限。该登录名不能被删除。当采用混合模式安装Microsoft SQL Server系统之后(同时能用 Windows 账号和 SQL Server 账号登录的模式),应该为sa指定一个密码,不然太不安全。就像为数据库的 “总控制室钥匙” 加上保护,确保只有合法用户能操控核心权限,
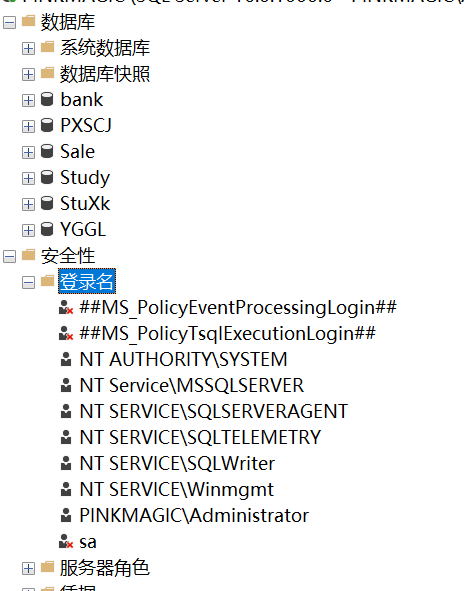
使用管理平台—查看登录账号
方法:数据库服务器——安全性——登录名
使用管理平台—创建登录账号
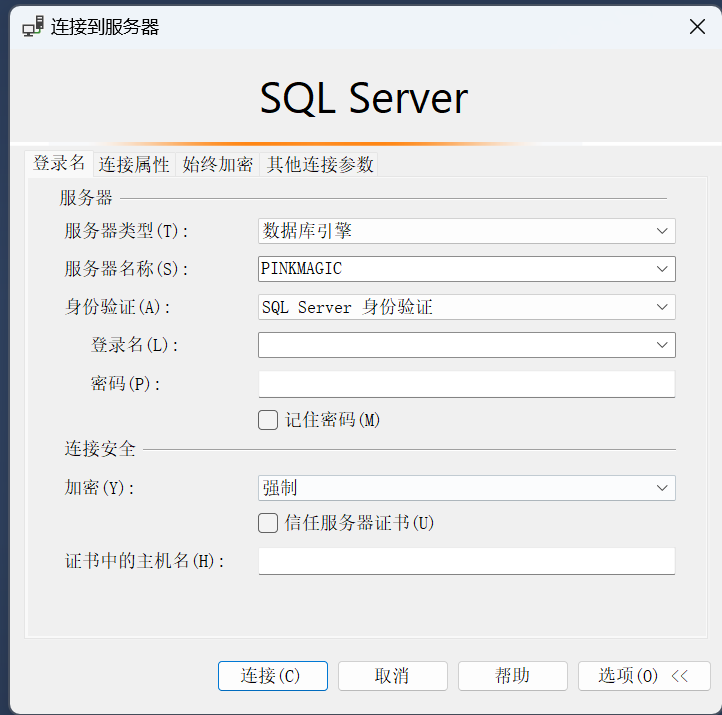
【例】使用Management Studio创建以SQL SERVER身份认证的登录账户User001。
【简要步骤】:对象资源管理器中展开服务器——安全性——右击“登录名”——“新建登录名”。
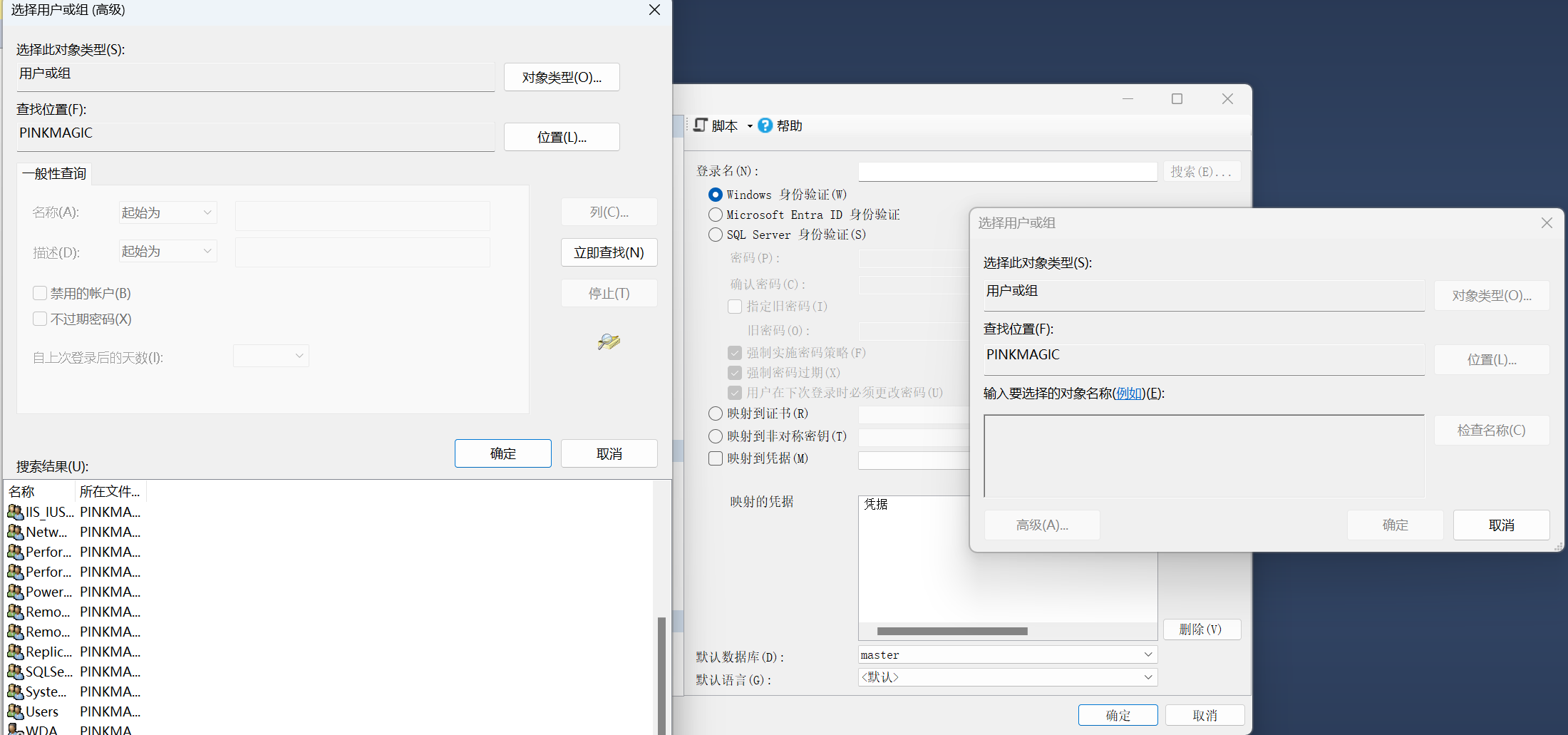
【例】使用Management Studio创建通过Windows身份认证的登录账户Win_user01。
注:需要先在Windows下创建用户Win_user01,密码‘001’.
【简要步骤】:对象资源管理器中展开服务器——安全性——右击“登录名”——“新建登录名”。
---------"搜索"——“选择用户或组”——“高级”——“立即查找”。前提:先在 Windows 系统创建用户 打开 Windows 的 “控制面板 → 用户账户”,创建用户 “Win_user01”,设置密码 “001”。

新用户和已有用户的区别:
新用户:创建后默认无任何操作权限(仅具备登录身份),需管理员手动分配权限(如查询某表、创建数据库等),才能执行具体操作。
已有用户:经过长期使用,可能已被多次授权,拥有明确的权限集合(如属于某个固定数据库角色,或被单独赋予特定对象的操作权限),可直接使用已授权的功能。
使用管理平台—删除登录账号
【例】使用Management Studio删除登录账户Win_user01。
【简要步骤】:对象资源管理器中展开服务器——安全性——展开“登录名”——右击“删除”。
使用SQL语句创建登录账号


【例1】 使用命令方式创建Windows登录名kfj(假设Windows用户kfj已经创建,本地计算机名为A51),默认数据库设为StuXK。
CREATE LOGIN [A51\kfj] FROM WINDOWS WITH DEFAULT_DATABASE= StuXK GO【例2】 创建SQL Server登录名tao,密码为123,默认数据库设为StuXK。
create login tao with password='123' WITH DEFAULT_DATABASE= StuXK GO
使用SQL语句删除登录账号
DROP LOGIN 登录名
【例4】 删除Windows登录名kfj。
DROP LOGIN [A51\kfj] GO
管理数据库用户
数据库用户是数据库级的主体,是登录名在数据库中的映射, 是在数据库中执行操作和活动的行动者,注意到:
每个登录账号在一个数据库中只能有一个用户账号,但每个登录账号可以在不同的数据库中各有一个用户账号。数据库用户可以与登录账号同名,也可以不相同
比如你登录电脑的账号是 “小明”(登录名),在 “班级数据库” 里,你可能用 “小明” 这个用户去操作,在 “学校数据库” 里,你可能用 “大明” 这个用户去操作。
在Microsoft SQL Server 中,数据库用户不能直接拥有表、视图等数据库对象,而是通过架构拥有这些对象,架构可以类比为一个盒子。
数据库用户管理包括创建用户、查看用户信息、修改用户、删除用户等
登录账号 VS 数据库用户
一个合法的登录账号只表明该账号可登录到SQL Server系统(大门门禁卡),但不能表明其可以对数据库数据和数据对象进行操作;只有当其拥有了数据库用户账号后(办公室卡),才能登录访问相应的数据库
一个登录账号总是与一个或多个数据库用户账号(这些账号分别存在于不同的数据库中)相对应,这样才可以访问数据库(否则将无法访问任何数据库)
查看数据库用户信息
如果希望查看数据库用户的信息,可以使用sys.database_principals目录视图。该目录视图包含了该数据库里所有数据库用户的名称、ID、类型、默认的架构、创建日期和最后修改日期等信息。一个数据库可以有多个数据库用户
关于dbo
dbo是数据库中的默认用户。dbo用户拥有在数据库中操作的所有权限。默认情况下,sa登录名在各数据库中对应的用户是dbo用户,好比 sa 拿着一把万能钥匙,打开每个数据库后,它在里面的身份就是这个数据库的 “大管家” dbo,能随意管理数据库里的一切。
所有者
第三个安全性问题:数据库中的对象由谁所有?如果是由用户所有,那么当用户被删除时,其所拥有的对象怎么办,难道数据库中的对象可以没有所有者吗?
在Microsoft SQL Server 中,这个问题是通过用户和架构分离来解决的。
用户并不拥有数据库对象,架构可以拥有数据库对象。用户通过架构来使用数据库对象。这种机制使得删除用户时不必修改数据库对象的所有者,提高了数据库对象的可管理性。数据库对象、架构和用户之间的这种关系如右图所示。
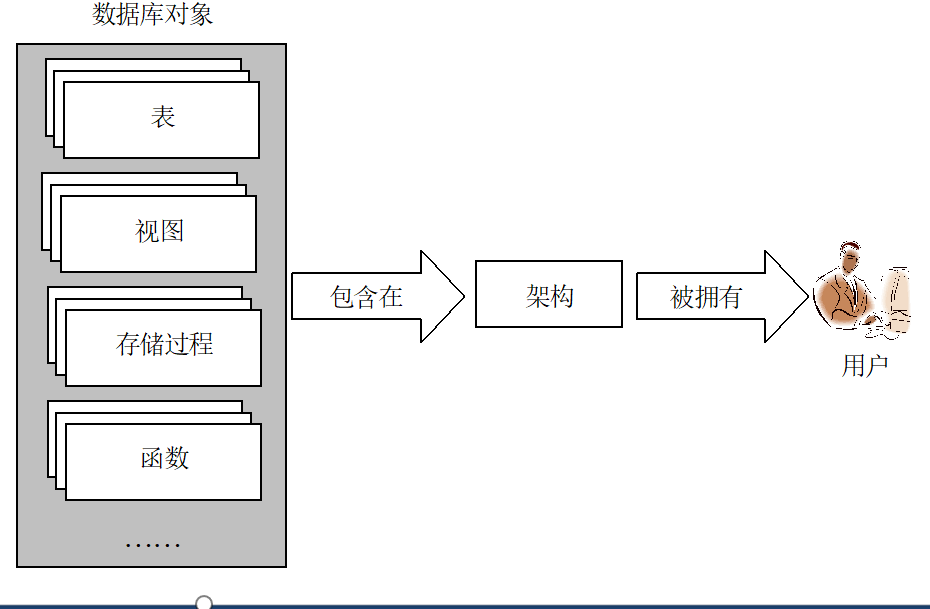
核心问题
数据库对象(如表、视图等)若直接由用户所有,当用户被删除时,其拥有的对象将面临归属混乱或管理难题,且理论上数据库对象不能没有所有者。
解决机制:用户与架构分离
架构拥有对象:在 SQL Server 中,数据库对象(表、视图、存储过程等)并非由用户直接拥有,而是由 架构 拥有。架构相当于一个 “容器”,用于归类和管理数据库对象。
用户通过架构使用对象:用户需通过架构来访问和使用其中的数据库对象。例如,用户要查询某张表,需通过该表所属的架构进行操作。
删除用户不影响对象归属:当删除用户时,由于对象归属于架构而非用户,因此无需修改对象的所有者。这大大提高了数据库对象的可管理性,避免因用户变动(如离职、权限调整)导致对象管理混乱。
类比理解
把架构看作 “文件夹”,数据库对象(表、视图等)是文件夹里的 “文件”,用户则是 “使用文件的人”。
即使 “人”(用户)离开,“文件夹”(架构)和 “文件”(对象)依然存在,且归属清晰,其他人仍可通过 “文件夹”(架构)正常使用 “文件”(对象),无需频繁调整文件的归属关系。
使用管理平台管理数据库用户
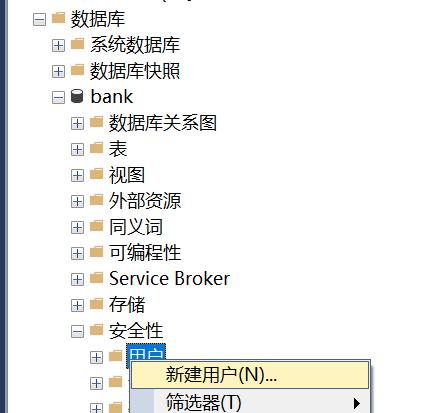
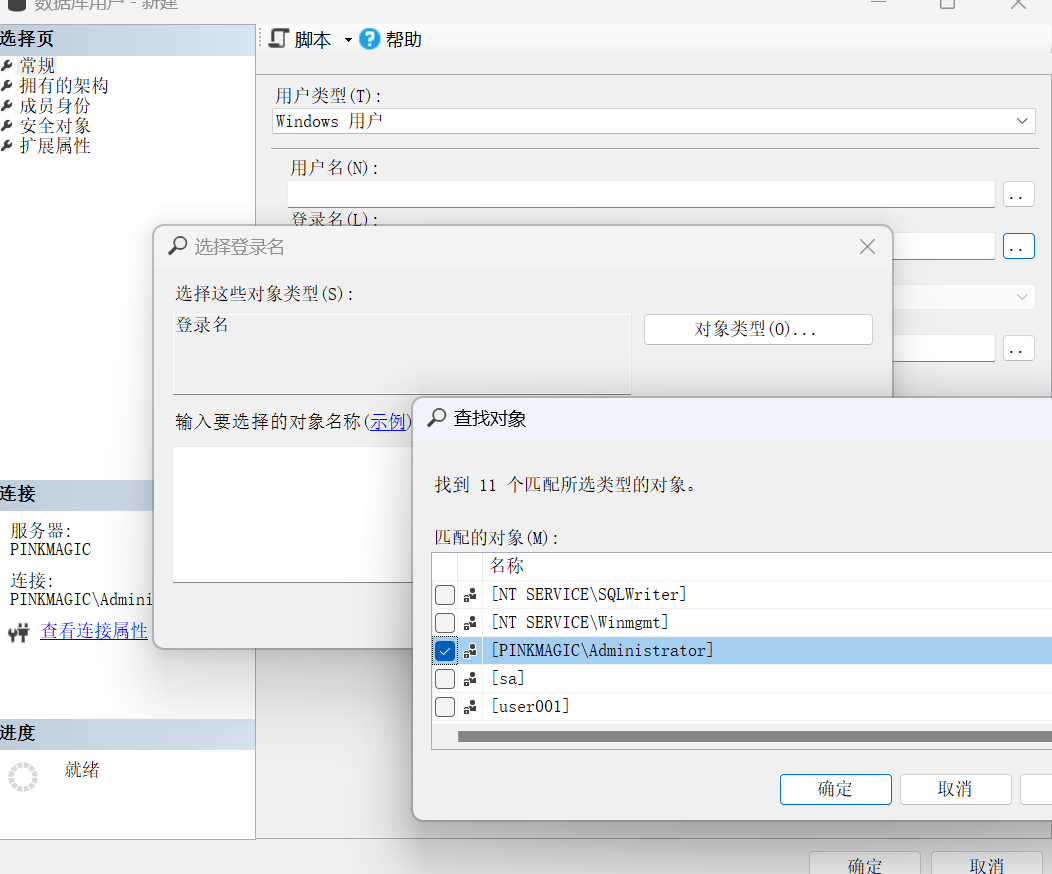
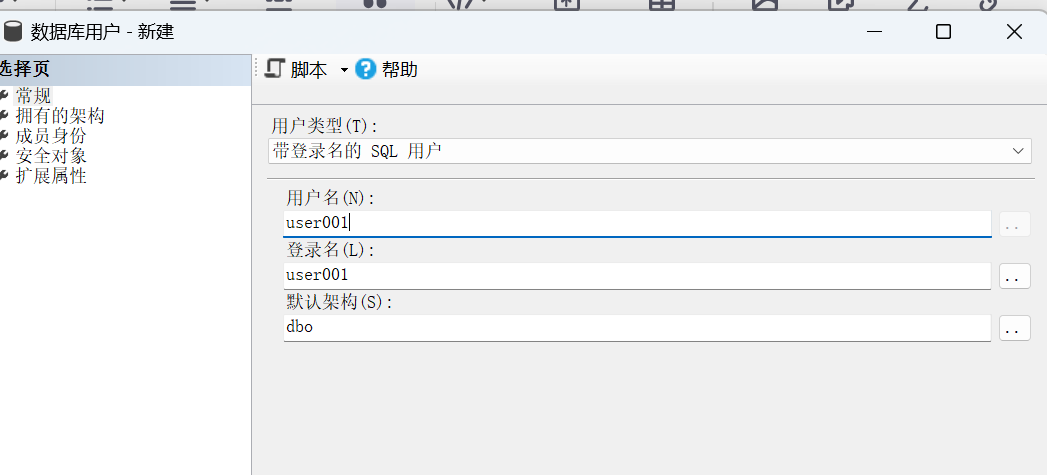
使用SQL语句创建数据库用户
可以使用CREATE USER语句在指定的数据库中创建用户。
由于用户是登录名在数据库中的映射,因此在创建用户时需要指定登录名。
CREATE USER 用户名 [{ FOR | FROM } { LOGIN 登录名 | CERTIFICATE cert_name | ASYMMETRIC KEY asym_key_name } | WITHOUT LOGIN ] [ WITH DEFAULT_SCHEMA = schema_name ]【例3】 创建StuXK数据库的数据库用户tao。
USE StuXK GO CREATE USER tao ----这里忽略了FOR LOGIN,则新的数据库用户将被映射到同名的 SQL Server 登录名。 ----创建用户名和登录名不同时,如为tao创建不同名称的用户名sql_tao: CREATE USER sql_tao FOR Login tao GO此时该用户已经有了数据库的登录权限,但还没有数据表的操作权限。
PS:如果已经创建了tao,上面语句则会提示:该登录已用另一个用户名开立账户。因为每个登录账号在一个数据库中只能有一个用户账号。

使用SQL语句删除数据库用户
DROP USER 数据库用户名
【例6】 删除SQL Server登录名user001。
DROP USER user001 GO
管理服务器角色与数据库角色
角色管理
数据库中很多用户的类型和权限基本相同,可以引入角色统一管理这些类似的用户
SQL Server可以通过角色统一管理服务器或数据库用户权限,通过修改角色权限来修改所有加入角色的用户的权限
服务器用户权限针对整个 SQL Server 实例,控制用户对服务器级资源的访问和操作(如创建数据库、管理登录名、备份整个服务器等)。
数据库用户权限仅针对单个数据库,控制用户对数据库内对象(如表、视图、存储过程等)的操作(如查询表、插入数据等)。
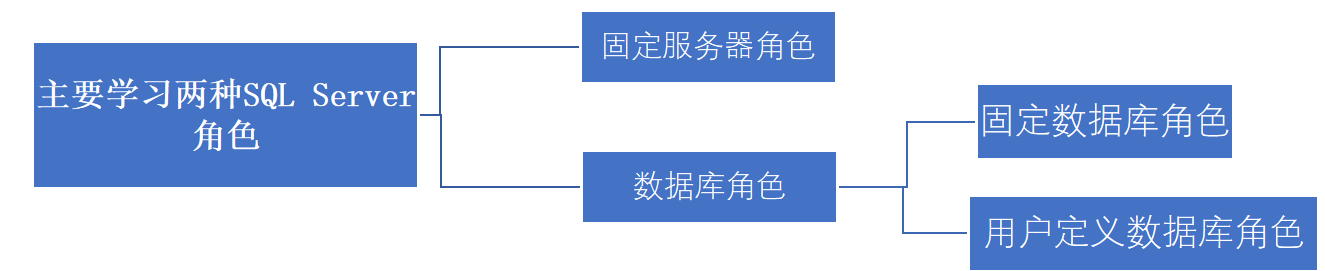
固定服务器角色管理
固定服务器角色的权限作用域为服务器范围
如果在SQL Server中创建一个登录名后,要赋予该登录者具有管理服务器的权限,此时可设置该登录名为服务器角色的成员
PS:服务器角色管理这块,我们主要学习固定服务器角色的管理固定服务器角色是 SQL Server 系统中在 服务器层次预先定义好的角色,这些角色具有特定的隐含权限,用于执行服务器级别的管理任务。它们在安装 SQL Server 时就已存在,无需手动创建,每个角色对应一组特定权限,将登录账户添加到固定服务器角色中,可使其获得该角色的权限,从而实现对服务器级资源和操作的统一管理,提升管理效率与安全性。
图中不带MS的是固定服务器角色。
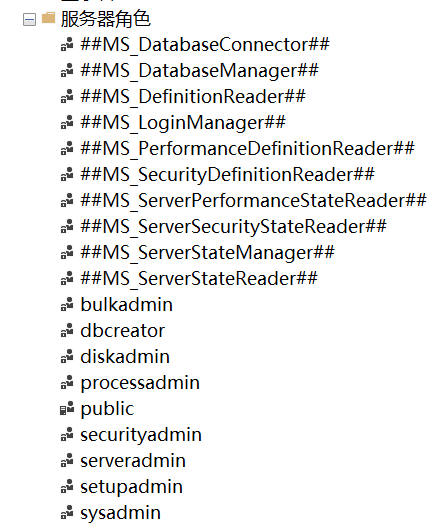
使用管理平台—添加服务器角色成员
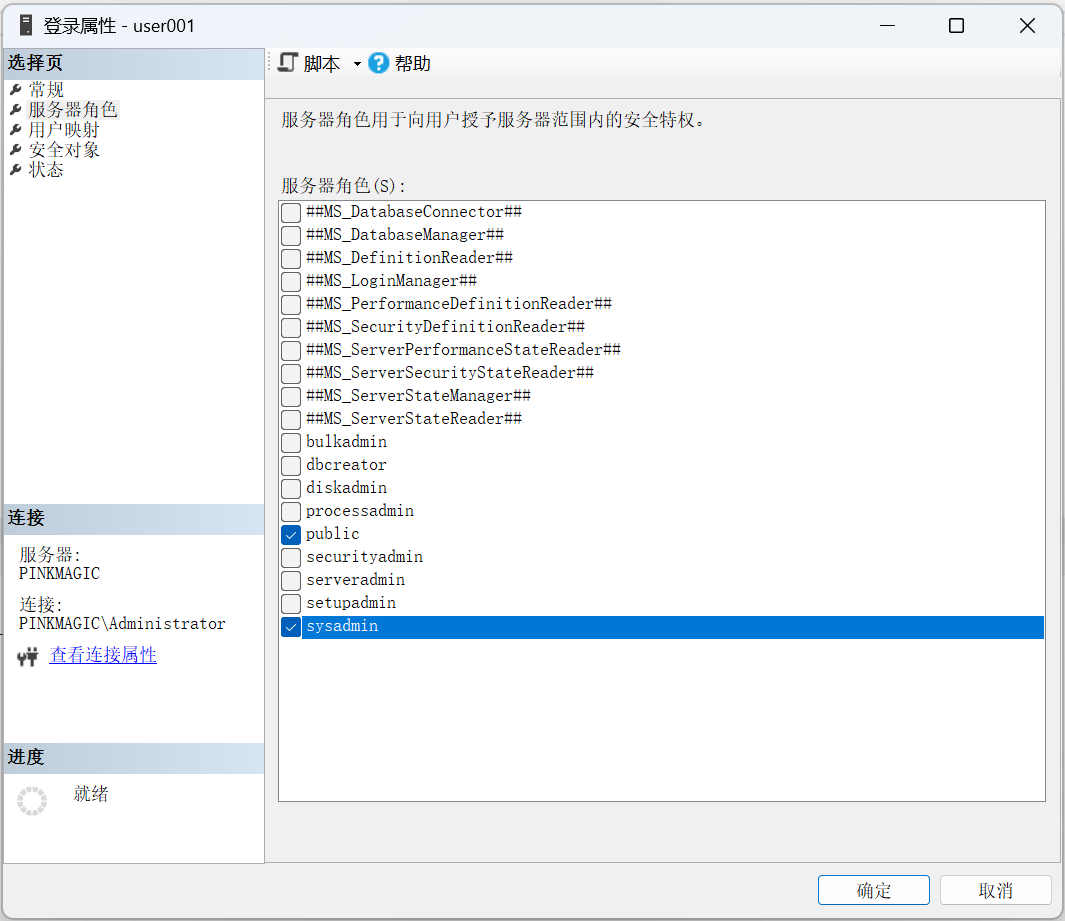
第1步 以系统管理员身份登录到SQL Server服务器,在“对象资源管理器”中展开“安全性”→“登录名”→选择登录名,双击或单击右键选择“属性”菜单项,打开“登录属性”窗口。
第2步 在打开的“登录属性”窗口中选择“服务器角色”选项页。在“登录属性”窗口右边列出了所有的固定服务器角色,用户可以根据需要,在服务器角色前的复选框中打勾,为登录名添加相应的服务器角色。单击“确定”按钮完成添加。
使用管理平台—删除服务器角色成员
取消打勾即可
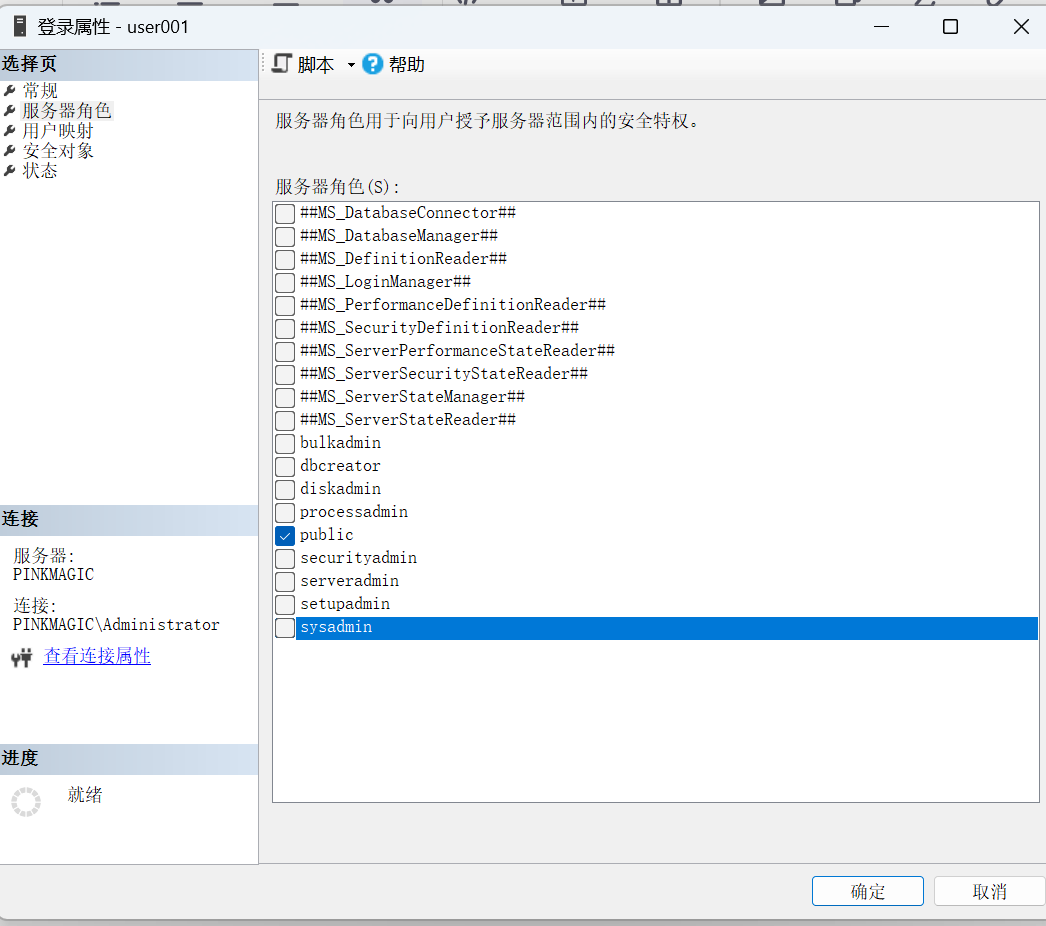
使用管理平台—服务器角色成员属性
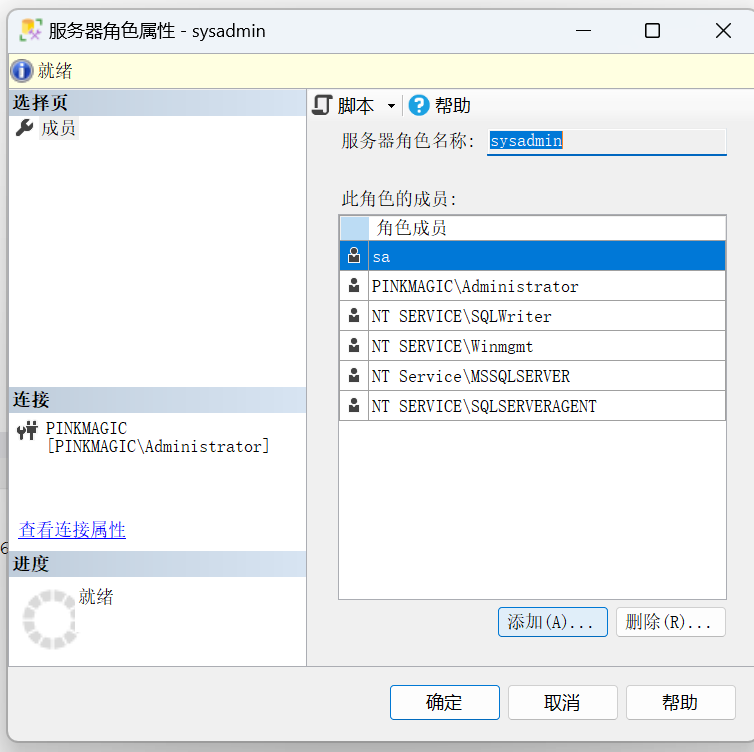
可直接在“服务器角色”上右键——属性——打开“服务器角色属性” 窗口
使用系统存储过程—添加固定服务器角色成员(一般不推荐)
利用系统存储过程sp_addsrvrolemember可将一登录名添加到某一固定服务器角色中,使其成为 固定服务器角色的成员
EXEC sp_addsrvrolemember [@loginame = ]'登录名' , [@rolename =]'固定服务器角色名'这里 sp_addsrvrolemember 是系统存储过程,EXEC 告诉数据库系统:“请执行这个存储过程,并按参数传递 '登录名' 和 '固定服务器角色名'。如果没有 EXEC,数据库系统无法识别这是对存储过程的调用。
【例7】 将用户user001添加到sysadmin固定服务器角色中。
EXEC sp_addsrvrolemember 'user001', 'sysadmin' GO
使用系统存储过程—删除固定服务器角色成员
EXEC sp_dropsrvrolemember [ @loginame = ] '登录名' , [ @rolename = ] '服务器角色名'服务器角色名默认值为NULL,必须是有效的角色名。
说明:
(1)不能删除sa登录名。(sa 是超级管理员,系统不让删。)
(2)不能从用户定义的事务内执行sp_dropsrvrolemember存储过程。
(3)sysadmin固定服务器角色的成员执行sp_dropsrvrolemember,可删除任意固定服务器角色中的登录名,
其他固定服务器角色的成员只可以删除相同固定服务器角色中的其他成员。比如你在 dbcreator 角色里,就只能删 dbcreator 里的其他成员,不能去动别的角色(如 sysadmin)的成员。
【例10】 从sysadmin固定服务器角色中删除SQL Server登录名tao。EXEC sp_dropsrvrolemember 'tao', 'sysadmin' GO
数据库角色管理|固定数据库角色
数据库角色是在数据库级别定义的;一个数据库角色只在其所在的数据库中有效,对其他数据库无效
数据库角色可分为固定数据库角色和用户定义数据库角色
固定数据库角色有其特定的权限,不能删除固定数据库角色(和固定服务器角色一样)
用户定义数据库角色是指用户定义创建的数据库角色

角色代表一系列操作,成员代表某一个具体的用户(拥有该角色下的操作)
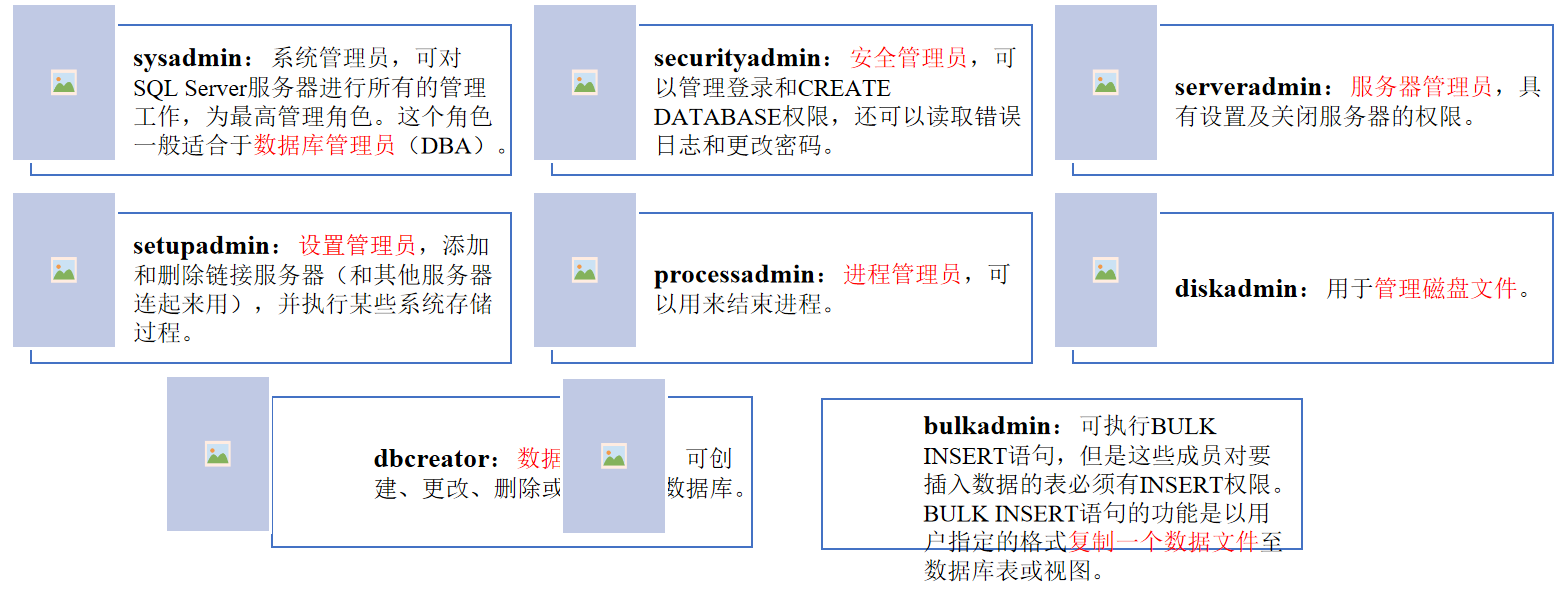
(1)db_owner:数据库所有者,这个数据库角色的成员可执行数据库的所有管理操作。
db_owner 固定数据库角色的成员:每个数据库的 “主管”,对所属数据库有全面管理权限。
数据库对象的所有者:比如某张表、某个视图的创建者或拥有者,对自己的对象有直接管理权限。都可授予、拒绝或废除某个用户或某个角色的权限。使用GRANT赋予执行T-SQL语句或对数据进行操作的权限;使用DENY拒绝权限,并防止指定的用户、组或角色从组和角色成员的关系中继承权限;使用REVOKE取消以前授予或拒绝的权限。
(2)db_accessadmin:数据库访问权限管理者,具有添加、删除数据库使用者、数据库角色和组的权限。
(3)db_securityadmin:数据库安全管理员,可管理数据库中的权限,如表的增加、删除、修改和查询等存取权限
(4)db_ddladmin:数据库DDL管理员,可增加、修改或删除数据库对象。
(5)db_backupoperator:数据库备份操作员,有执行数据库备份的权限。
(6)db_datareader:数据库数据读取者。
(7)db_datawriter:数据库数据写入者,具有对表进行增加、删修、修改的权限。
(8)db_denydatareader:数据库拒绝数据读取者,不能读取数据库中任何表的内容。
(9)db_denydatawriter:数据库拒绝数据写入者,不能对任何表进行增加、删修、修改操作。
(10)public:是一个特殊的数据库角色,每个数据库用户都是public角色的成员,因此不能将用户、组或角色指派为public角色的成员,也不能删除public角色的成员。通常将一些公共的权限赋给public角色。它是系统预设且具有独特的成员规则。每个数据库用户都会自动成为 public 角色的成员,这种成员关系是系统默认的,不能手动将用户、组或其他角色指派给它(无法额外添加成员),也不能删除其成员(因为所有用户都默认在其中)。通常将一些所有用户都需要的、公共的权限赋予 public 角色。
使用管理平台—添加固定数据库角色成员
第1步 以系统管理员身份登录到SQL Server服务器,在“对象资源管理器”中展开“数据库”→“StuXK”→“安全性”→“用户”→选择一个数据库用户,双击或单击右键选择“属性”菜单项,打开“数据库用户”窗口。
第2步 在打开的窗口中,在“常规”选项页中的“数据库角色成员身份”栏,用户可以根据需要,在数据库角色前的复选框中打勾,来为数据库用户添加相应的数据库角色。单击“确定”按钮完成添加。
同样,也可以直接在固定数据库角色(某一个角色)上右击——属性——打开“数据库角色属性”对话框,为固定数据库角色添加成员
使用管理平台—删除固定数据库角色成员
取消打勾
删除
使用系统存储过程—添加固定数据库角色成员
利用系统存储过程sp_addrolemember可以将一个数据库用户添加到某一固定数据库角色中,使其成为该固定数据库角色的成员。(语法上角色在前,账户在后)
sp_addrolemember [ @rolename = ] '数据库角色', [ @membername = ] 'security_account'security_account:添加到该角色的安全账户,可以是数据库用户或当前数据库角色
【例11】 将StuXK数据库上的数据库用户sql_test_user添加为固定数据库角色db_owner(数据库所有者)的成员。
EXEC sp_addrolemember 'db_owner', 'sql_test_user' GO
使用系统存储过程—删除固定数据库角色成员
EXEC sp_droprolemember [ @rolename = ] ‘数据库角色', [ @membername = ] 'security_account '【例12】 将数据库用户david从db_owner角色中去除。
EXEC sp_droprolemember 'db_owner', 'sql_test_user' GO
数据库角色管理|用户定义数据库角色
使用管理平台—创建用户定义数据库角色
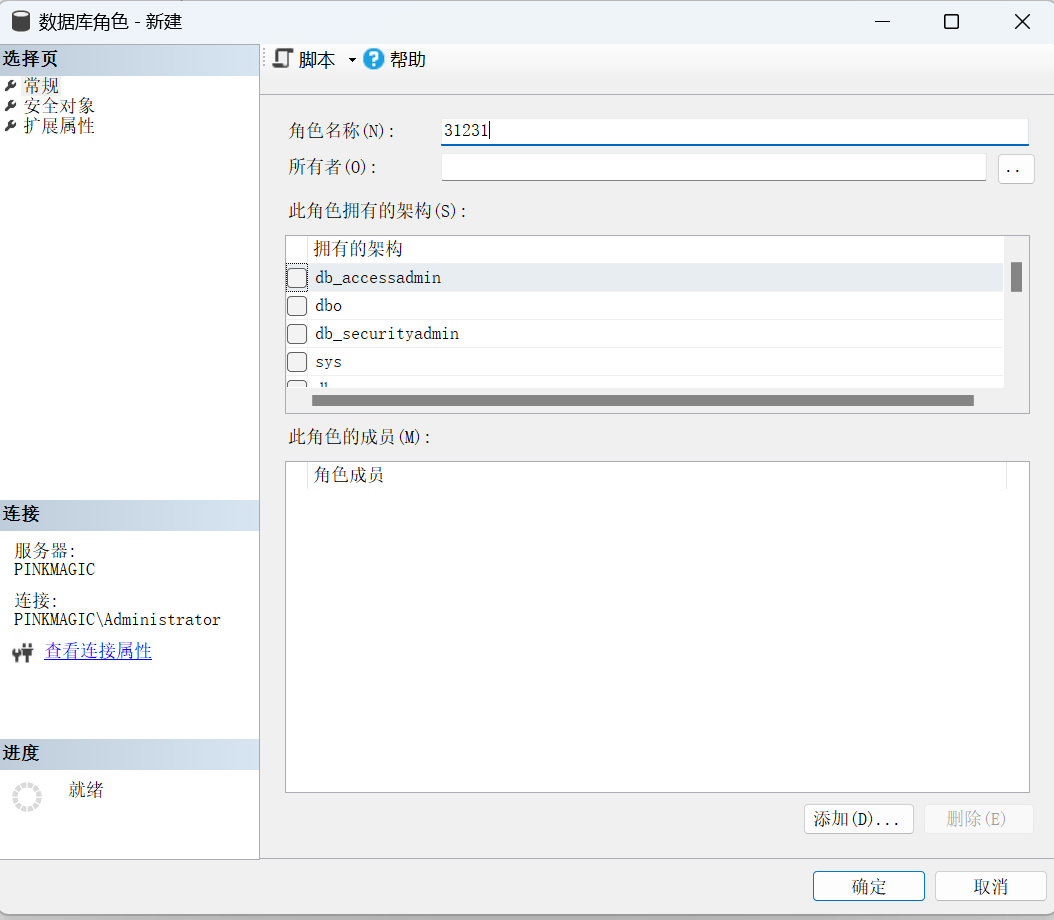
以系统管理员身份登录SQL Server→在“对象资源管理器”中展开“数据库”→选择要创建角色的数据库(如StuXK),展开其中的“安全性”→“角色”,右击鼠标,在弹出的快捷菜单中选择“新建”菜单项→在弹出的子菜单中选择“新建数据库角色”菜单项,如图10所示。进入“数据库角色-新建”窗口。

使用管理平台—为用户定义数据库角色添加/删除成员
使用管理平台—删除用户定义数据库角色
删除角色之前先要将相关的成员删除
使用SQL语句—创建用户定义数据库角色
CREATE ROLE 角色名 [ AUTHORIZATION 所有者 ]【例14】 在当前数据库中创建名为ROLE2的新角色,并指定dbo为该角色的所有者
CREATE ROLE ROLE2 AUTHORIZATION dbo GO
使用SQL语句—向用户定义数据库角色添加成员
向用户定义数据库角色添加成员也使用存储过程sp_ addrolemember
【例15】 将该数据库用户sql_test_user添加到ROLE2数据库角色中。 EXEC sp_addrolemember 'ROLE2', ' sql_test_user' GO 【例16】 将数据库角色ROLE2添加到ROLE1中。 EXEC sp_addrolemember 'ROLE1','ROLE2' GO
使用SQL语句—删除用户定义数据库角色的成员
将一个成员从数据库角色中去除也可使用系统存储过程sp_droprolemember。
将数据库角色ROLE2从ROLE1中删除。 EXEC sp_droprolemember 'ROLE1','ROLE2' GO
使用SQL语句—删除用户定义数据库角色
DROP ROLE 数据库角色名【例17】 删除数据库角色ROLE2。 DROP ROLE ROLE2 GO
数据库权限管理
数据库权限类型
权限:用来指定授权用户可以使用的数据库对象和这些授权用户可以对这些数据库对象执行的操作,这里的授权用户可以是用户或角色
SQL Server权限有三种类型:
(1)语句权限
(2)对象权限
(3)暗示性权限语句权限管控用户对数据库结构的操作能力(如创建表),对象权限管控用户对具体对象数据或功能的使用能力(如查询表、执行存储过程),二者共同构成数据库的权限管理体系,确保操作的安全性和规范性。
(1)语句权限:
创建数据库或数据库对象的权限;还包括备份数据库和事务日志的权限
包括:
CREATE DATABASE
CREATE DEFAULT
CREATE FUNCTION
CREATE PROCEDURE
CREATE RULE
CREATE TABLE
CREATE VIEW
BACKUP DATABASE
BACKUP LOG
(2)对象权限:
操作数据或执行存储过程的权限
包括: SELECT 表或视图 INSERT UPDATE DELETE EXECUTE 存储过程
(3)暗示性权限:
隐含的权限,指系统自行预定义,不需要授权等操作就有的权限
如sysadmin固定服务器角色成员自动继承在SQL Server中进行查看或者操作的全部权限。
数据库对象所有者也有暗示性权限,可以对所拥有的对象执行一切活动。如拥有表的用户可以查看、添加或删除数据,更改表定义,或控制允许其他用户对表进行操作的权限。
可使用管理平台实现语句权限、对象权限和暗示性权限的授权、拒绝、取消
也可使用Grant、Deny和Revoke语句对以上权限进行管理
Grant用于显式给用户或角色授权权限
Deny用于显式拒绝用户或角色使用某个权限
Revoke执行与Grant或Deny相反的操作,可以理解为取消
授予权限
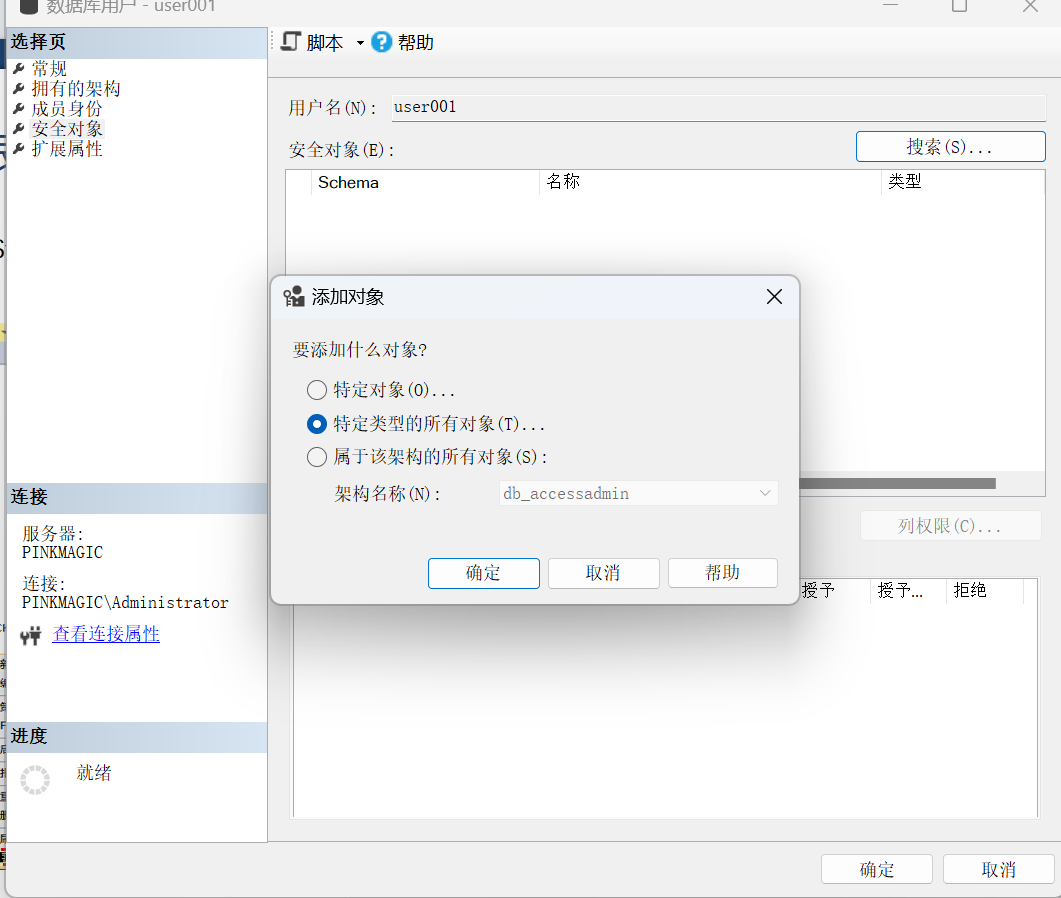
通过管理平台授予权限
对象资源管理器——StuXK——安全性——展开用户——右击某个用户——属性——安全对象——对象类型——表——浏览。
也可以通过数据库对象来设置用户权限
授予语句权限
利用GRANT语句可以给数据库用户或数据库角色授予数据库级别或对象级别的权限
GRANT {ALL|Statement[,...,n]} TO security_account[,...,n] 其中: ALL:所有权限 Statement:授予权限的语句 BACKUP DATABASE BACKUP LOG CREATE DATABASE CREATE DEFAULT CREATE FUNCTION CREATE PROCEDURE CREATE RULE CREATE TABLE CREATE VIEW security_account:被授予权限的安全账户。【例18】使用GRANT给用户user001授予CREATE TABLE(创建表)的权限。 GRANT CREATE TABLE TO user001 GO 【例19】将CREATE TABLE(创建表)的权限授予数据库角色ROLE2的所有成员。 GRANT CREATE TABLE TO role2
授予对象权限
利用GRANT语句可以给数据库用户或数据库角色授予数据库级别或对象级别的权限
GRANT {ALL|permission[,...,n]} { [(column[,...,n])] ON {table|view} |ON {table|view}[(column[,...,n])] |ON {stored_procedure|extended_procedure} |ON {user_defined_function} } TO security_account[,...,n][WITH GRANT OPTION]1、一般来说,不推荐使用grant all;permission权限包括:Select、Insert、Delete、Update、Execute等。
2、“on 要授予权限的安全对象”,这个 安全对象,可以是表或视图,也可以是存储过程、函数等,对于表或视图,还可指定列名。
3、可以带上with grant option关键字 ,表明被授权者有权将他获得的权限授予给其他的主体
【例19】在数据库StuXK中给public角色授予表Student的SELECT权限。然后,将其他的权限也授予用户sql_test_server ,使这两个用户具有对student表的UPDATE, DELETE操作权限。
GRANT SELECT ON Student TO public GO GRANT INSERT, UPDATE, DELETE ON Student TO sql_test_server【例20】在数据库StuXK中给public角色授予表Student的学号、姓名字段的SELECT权限
GRANT SELECT(Stuno,Stuname) ON Student TO public GO
禁止获得权限
使用DENY命令可以拒绝给当前数据库内的用户授予的权限,并防止数据库用户通过组或 角色成员资格继承权限
DENY { ALL [ PRIVILEGES ] } | permission [ ( column [ ,...n ] ) ] [ ,...n ] [ ON securable ] TO principal [ ,...n ] [ CASCADE] [ AS principal ]1、同样,不推荐使用 DENY ALL 语法;
2、“on 某个拒绝授予权限对象”,这个对象,可以是表或视图,也可以是存储过程、函数等,对于表或视图,还可指定列名
3、CASCADE关键字,指示拒绝授予指定主体该权限的同时,对该主体授予了该权限的所有其他主体,也拒绝授予该权限。当主体原先指定了With GRANT OPTION时,CASCADE为必选项
4、如果使用DENY语句禁止用户获得某个权限,那么以后将该用户添加到已得到该权限的组或角色时,该用户仍不能访问这个权限;
5、默认情况下,sysadmin、db_securityadmin角色成员和数据库对象所有者具有执行DENY的权限
【例22】对所有ROLE2角色成员拒绝CREATE TABLE权限。 DENY CREATE TABLE TO ROLE2 GO 【例】 对sql_test_user用户不允许使用CREATE VIEW和CREATE TABLE语句 DENY CREATE VIEW, CREATE TABLE TO sql_test_user
取消(删除)权限
使用revoke取消(删除)权限
REVOKE [ GRANT OPTION FOR ] { [ ALL [ PRIVILEGES ] ] | permission [ ( column [ ,...n ] ) ] [ ,...n ] } [ ON securable ] { TO | FROM } principal [ ,...n ] [ CASCADE] [ AS principal ]1、如果要取消的权限原先是通过with grant option授予的,在revoke上只指定cascade,会指定取消某主体的权限时,也将取消由该主体授权的其他安全账户的权限;
在revoke上同时指定grant option for和cascade子句,可消除grant中指定的with grant option设置的影响。即用户仍然有该权限,但是取消将该权限授予其他用户
2、如果要取消的权限原先没有通过with grant option设置授予,在revoke上只指定“grant option for”子句,会忽略grant option for,并照例取消权限
【例9】取消授予role2的建表语句权限。 REVOKE CREATE TABLE FROM role2 【例10】取消以前对sql_test_user授予或拒绝的在Student表上的SELECT权限 REVOKE CREATE VIEW,CREATE TABLE TO sql_test_user
数据库管理与维护
联机与脱机
什么是联机与脱机?他们都是数据库的某一种状态
当一个数据库处于可操作、可查询的状态时就是联机状态
一个数据库尽管可以看到其名字出现在数据库节点中,但对其不能执行任何有效的数据库操作时就是脱机状态
脱机从简单意义上来说,就是断开数据库跟所有人的连接,因为数据库连接已经中断,所以不能再访问已脱机的数据库脱机VS分离:两者都可以使数据库不能再被使用,脱机后只需联机就可以使用,而分离后需要附加才能使用
脱机与联机是相对的两个概念,它们表示数据库所处的一种状态,脱机状态时数据库是存在的,只是被关闭了,用户不能访问而已,要想访问可以设为联机状态。
分离与附加是相对的两个概念,分离后,数据库不存在,只存在数据库对应的mdf 或ndf 及ldf物理文件。要使用这些文件,可以在管理平台上附加它们。
脱机
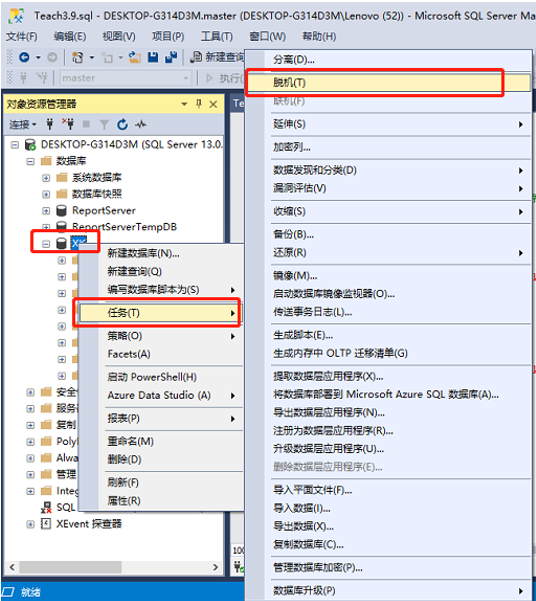
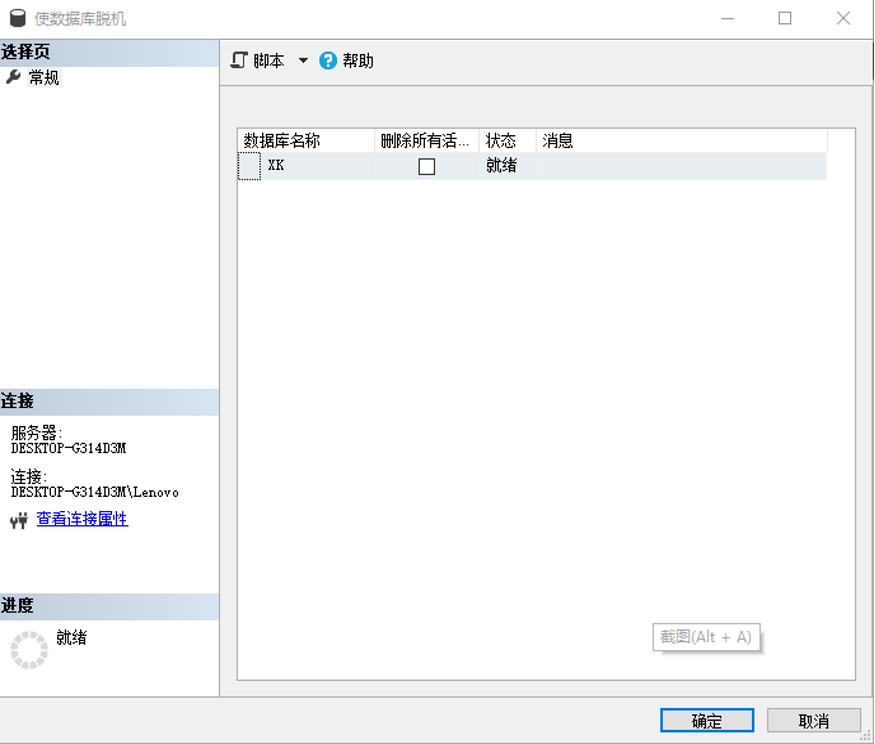
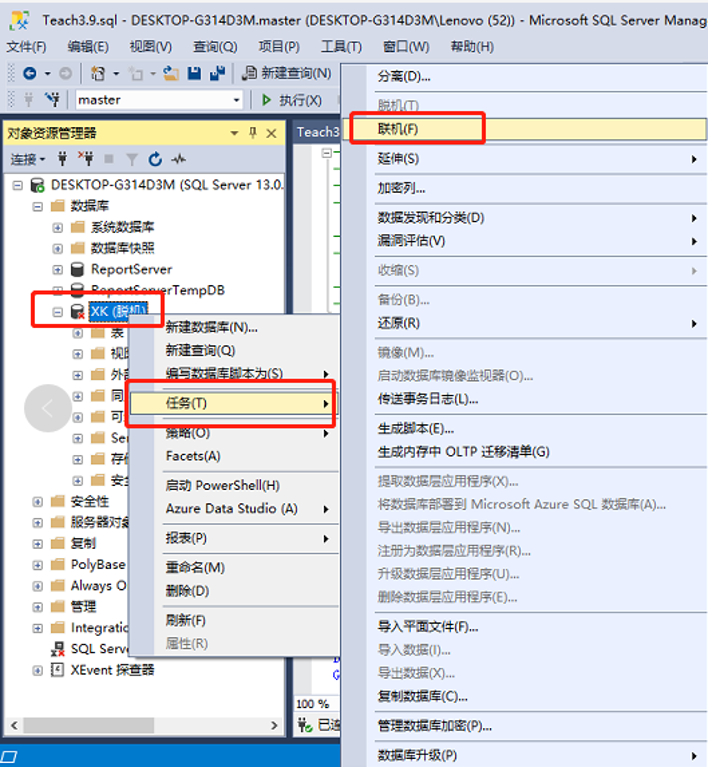
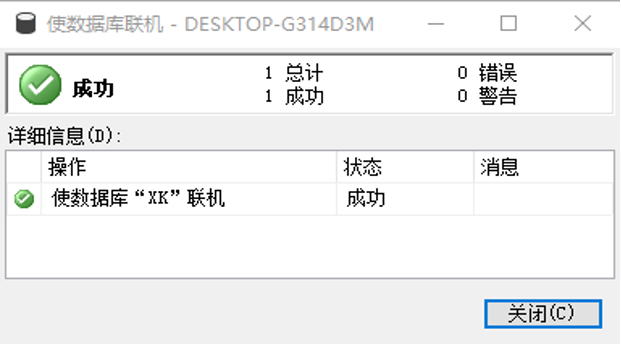
联机
数据库复制
使用复制数据库向导可以在服务器之间复制、移动数据库
【例】将StuXK数据库从当前数据库服务器复制到目标服务器上
注:1. 开启SQL Server代理服务(保证源主机和目标主机的代理服务都开启)
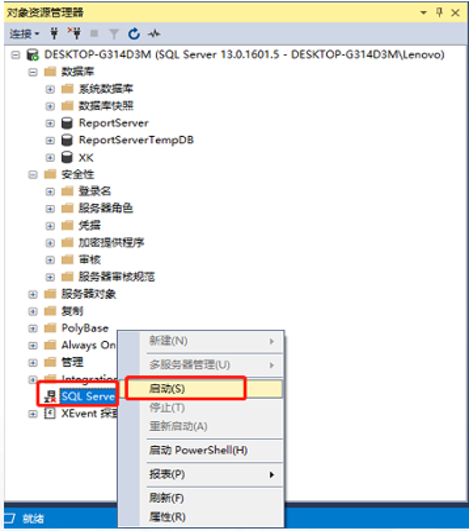
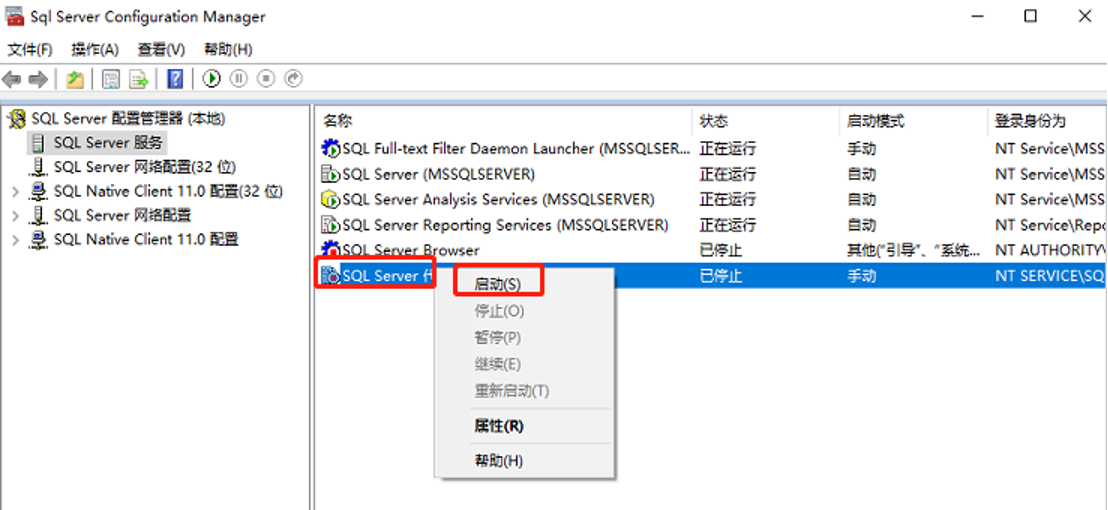
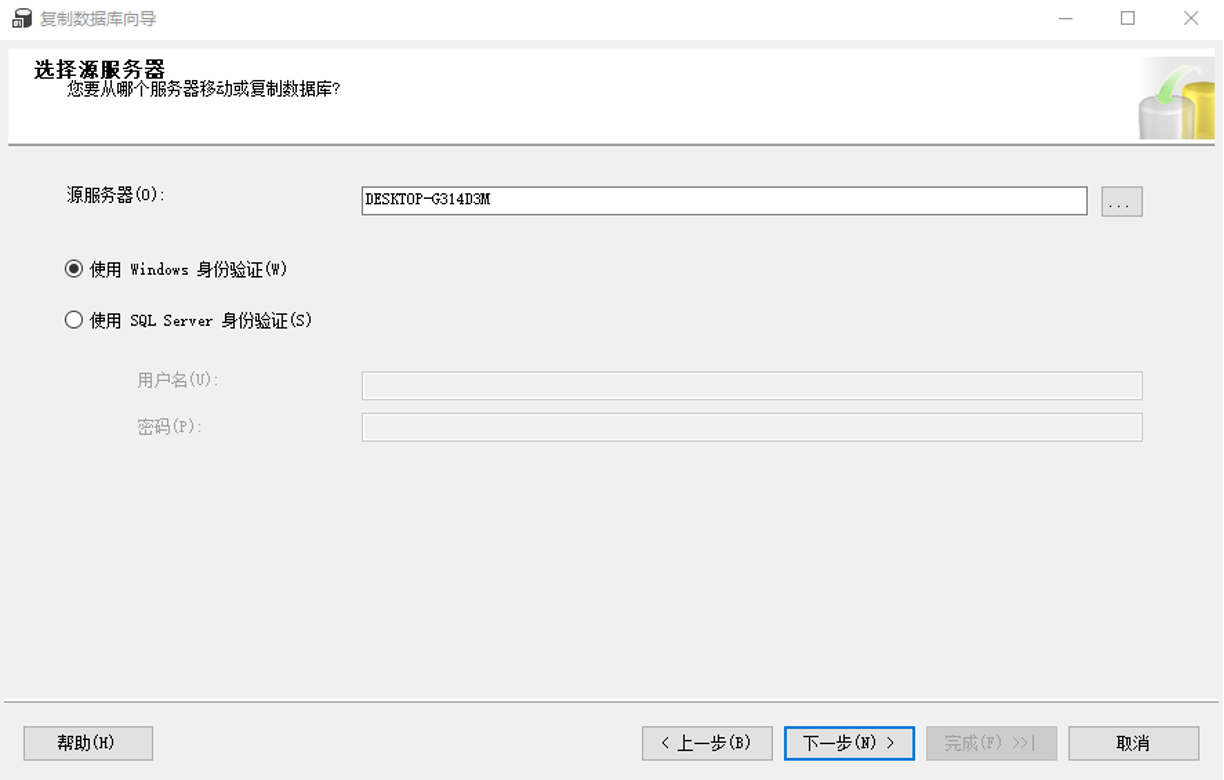
2. 保证源主机和目标主机数据库都能用SQL SERVER登录,即混合模式身份验证 如果源服务器/目标服务器是本地服务器,则身份验证方式可选择“使用Windows身份验证”或“使用SQL Server身份验证”,如果是远程服务器,则一般选择“使用SQL Server身份验证”
3.1.右键点击StuXK数据库,任务——复制数据库
3.2打开数据库复制向导窗口
3.3选择源服务器(windows和SQL Server身份验证都可以)
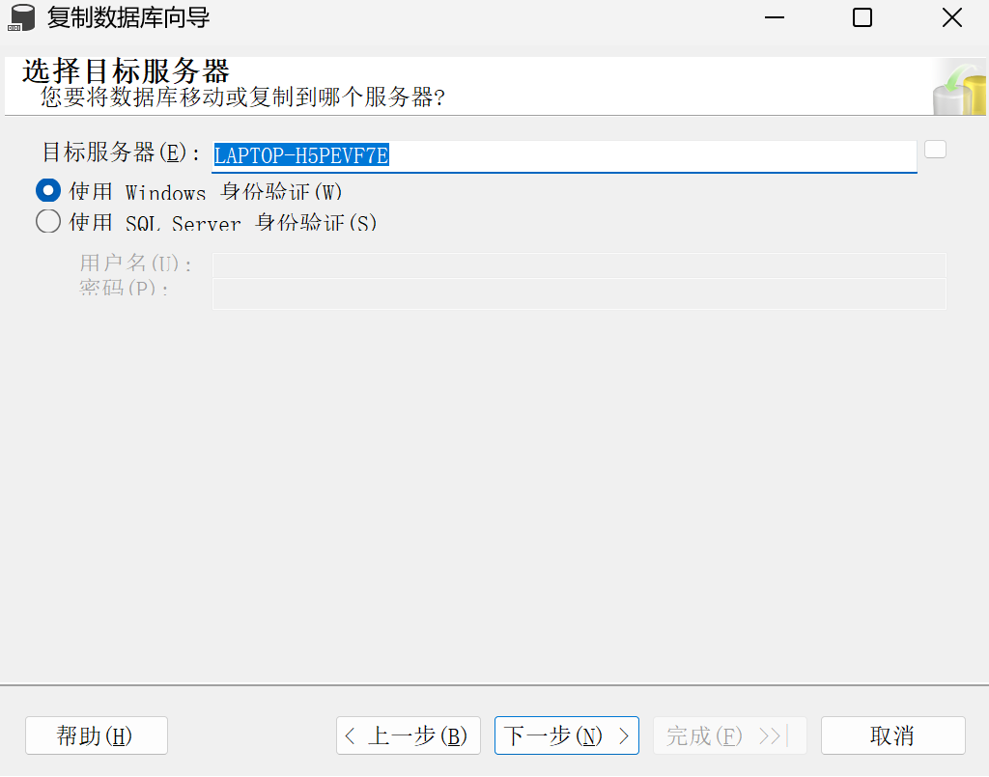
3.4选择目标服务器
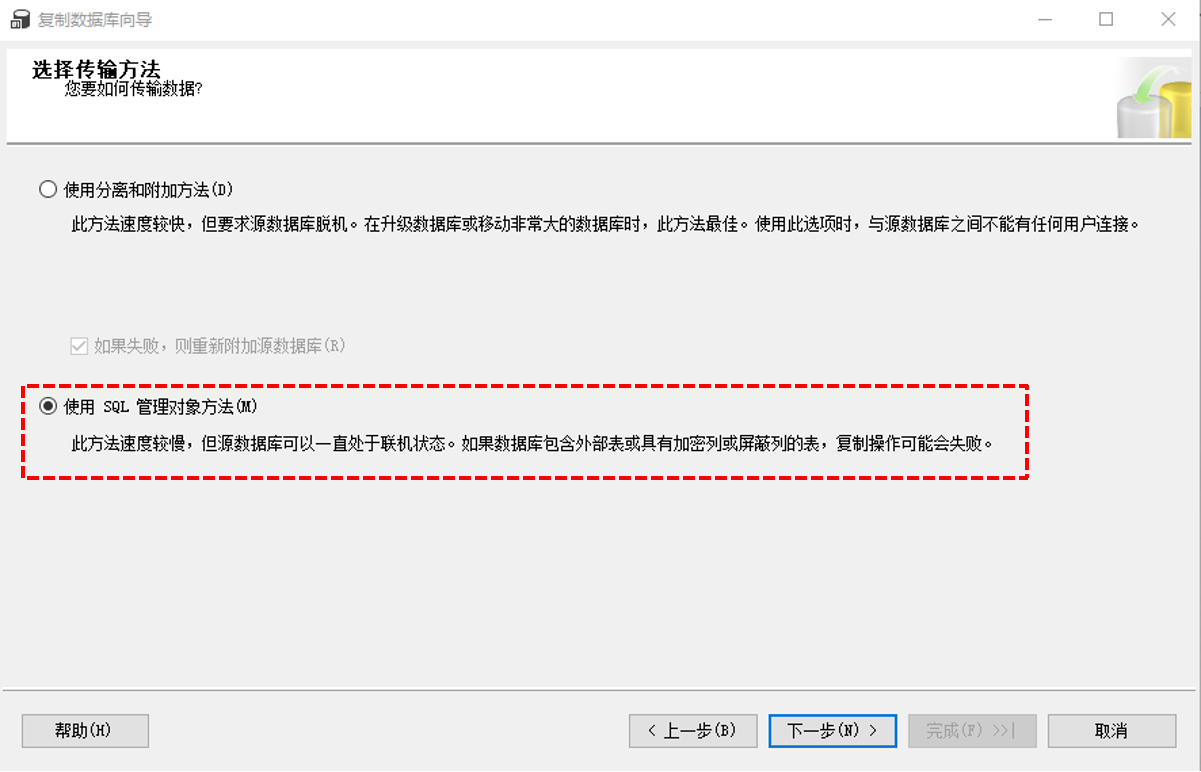
3.5选择传输方法
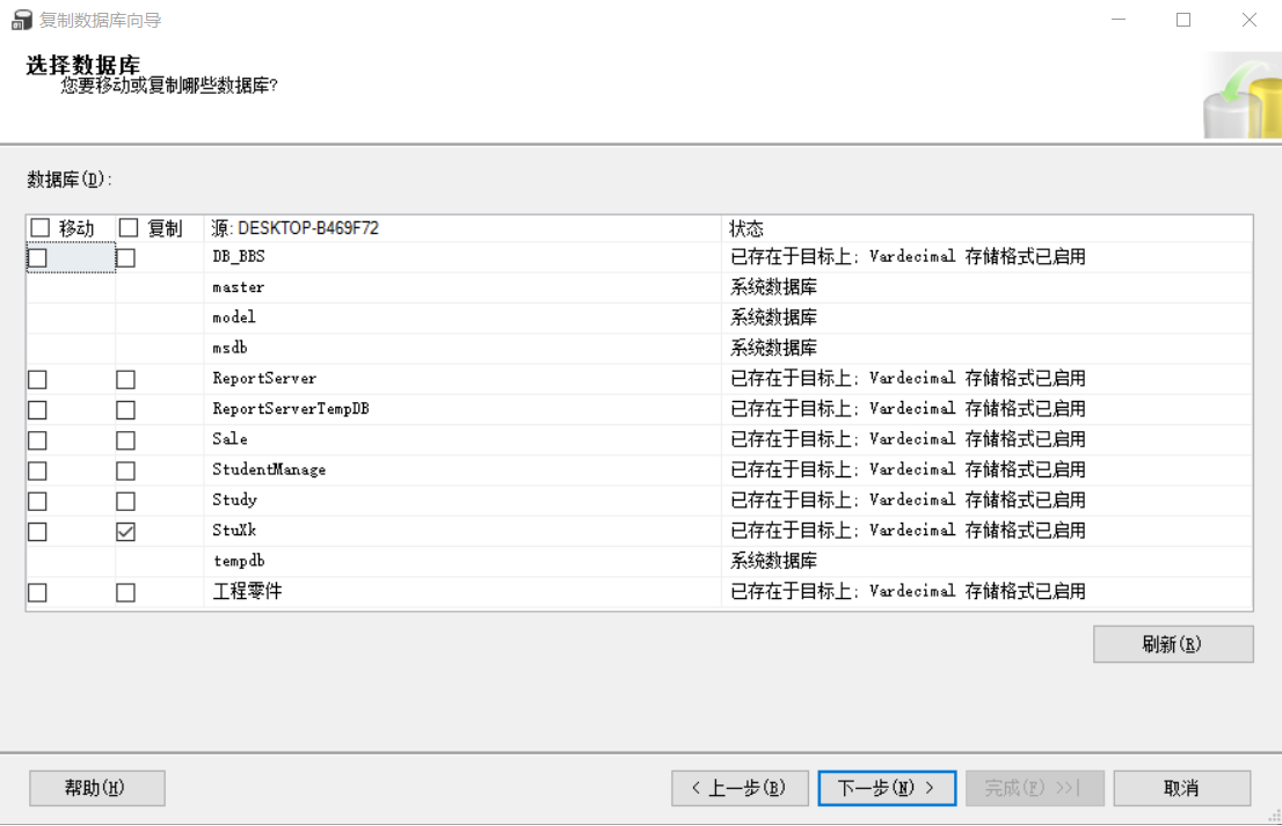
3.6选择数据库
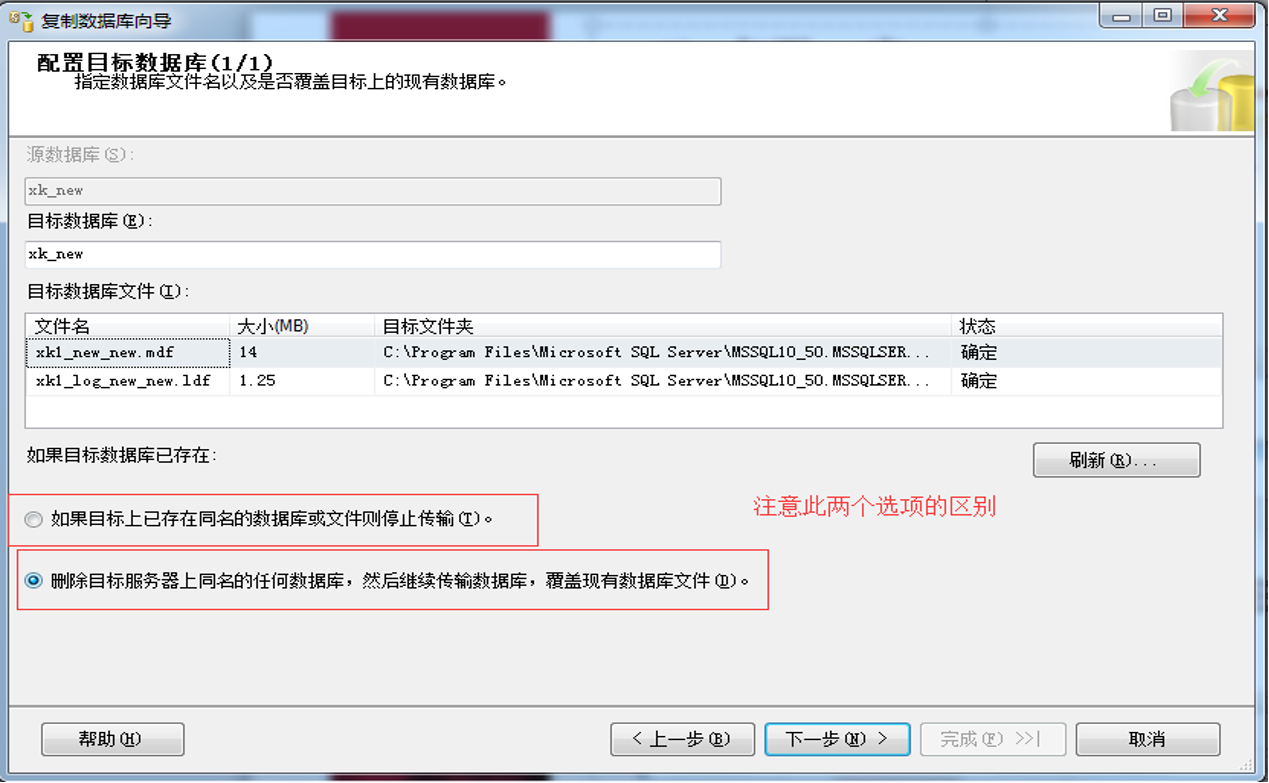
3.7配置目标数据库
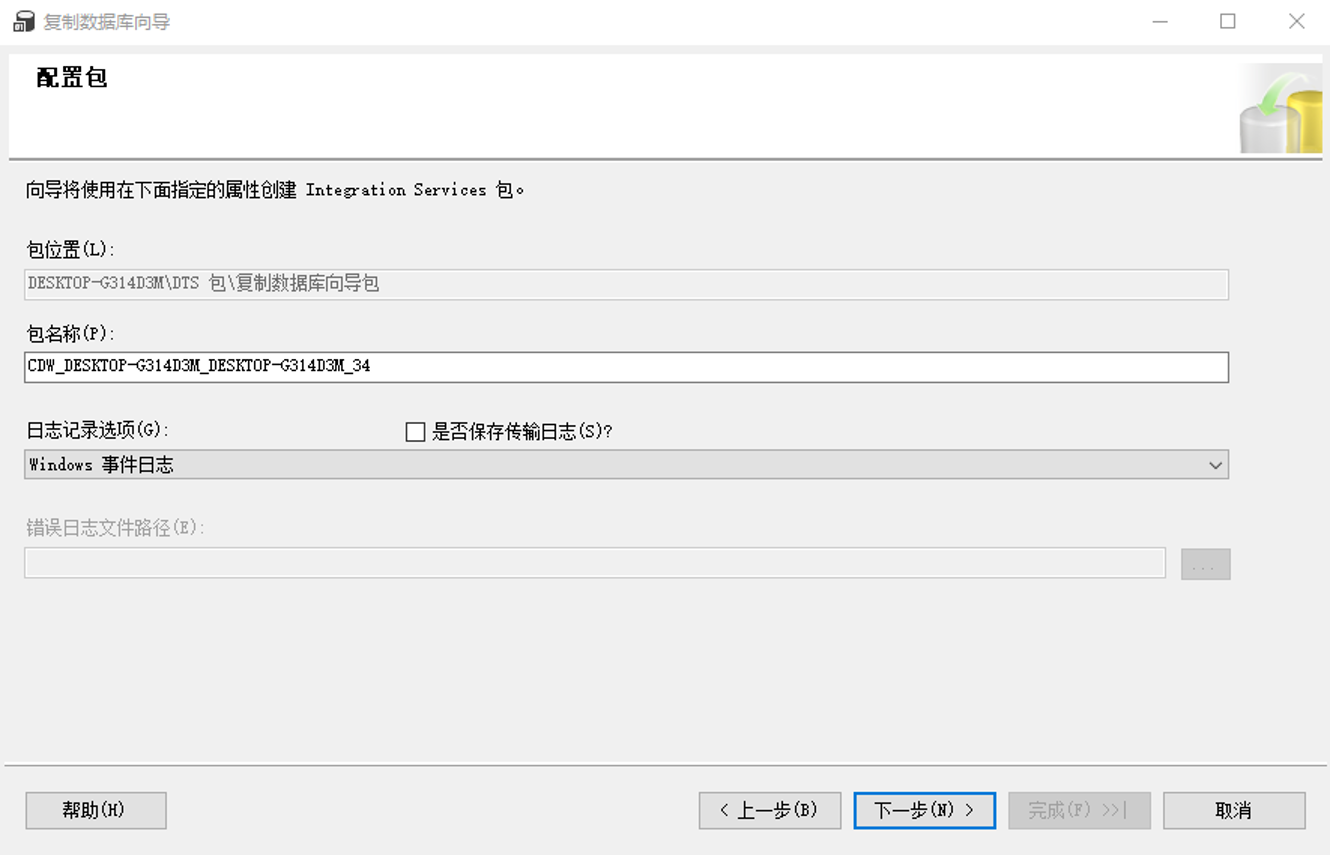
3.8配置包
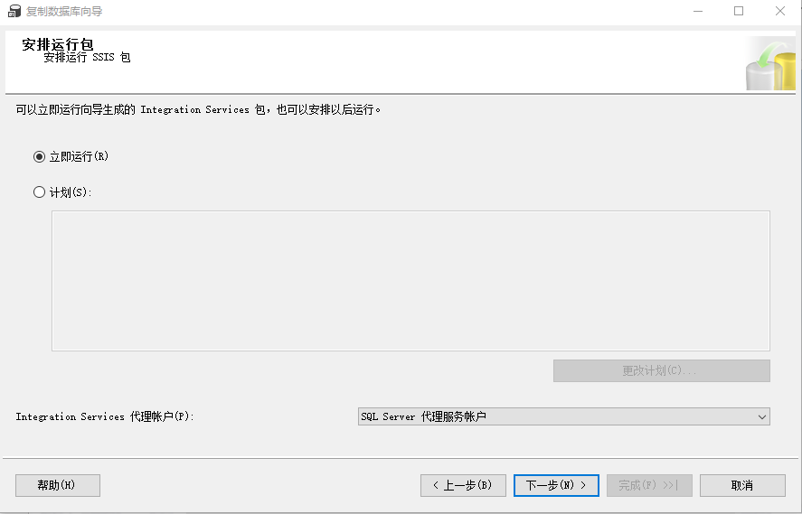
3.9安排运行包
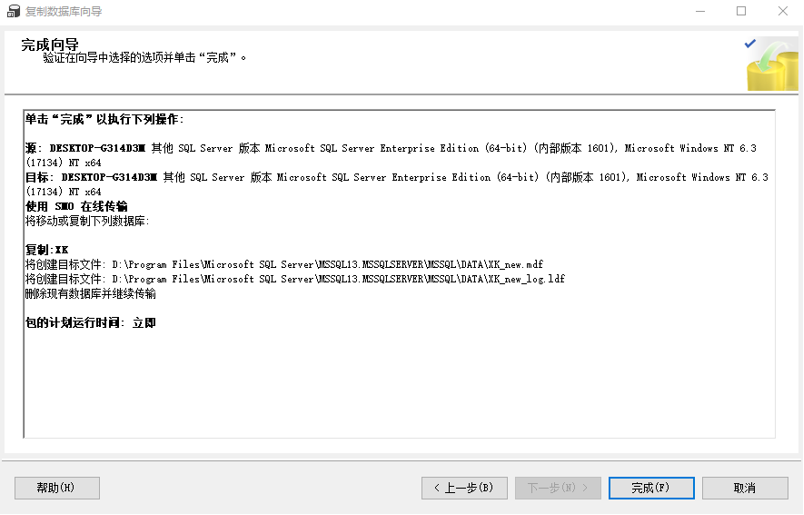
3.10完成向导
3.11完成数据库复制
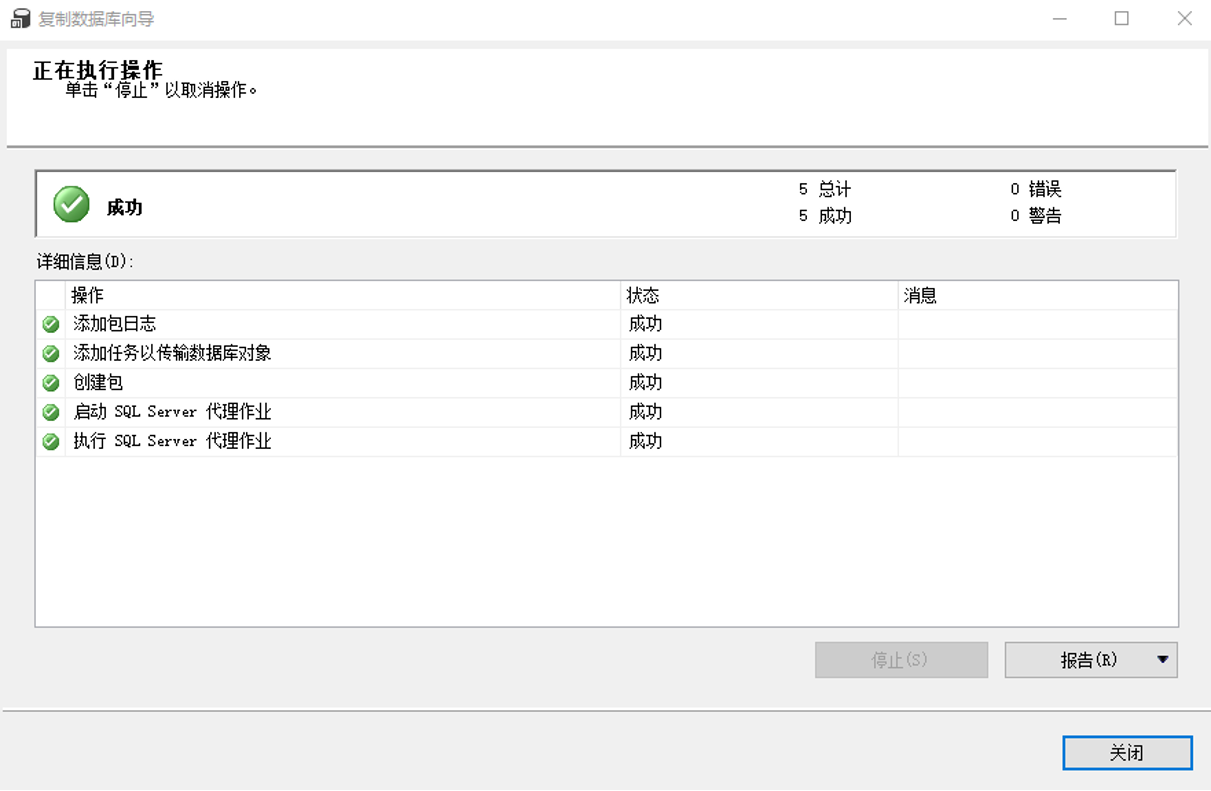
数据导入导出
数据转换服务DTS
可以从SQL Server、文本文件、Access 、Excel、OLE DB访问接口等源中导入或导出数据
【例】将StuXK数据库中的表或视图导出为EXCEL文件
(1)任务-导出数据
(2)选择数据源
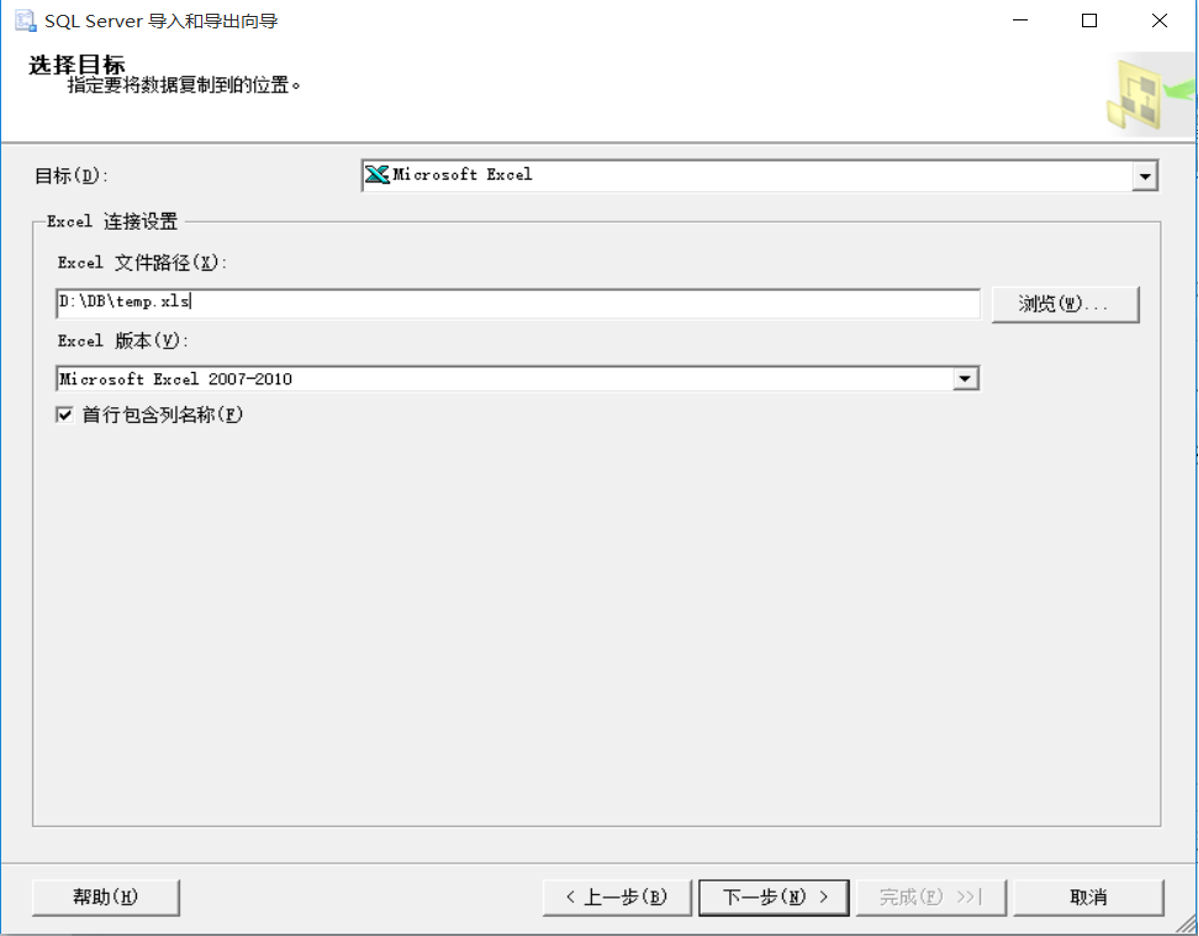
(3)选择目标
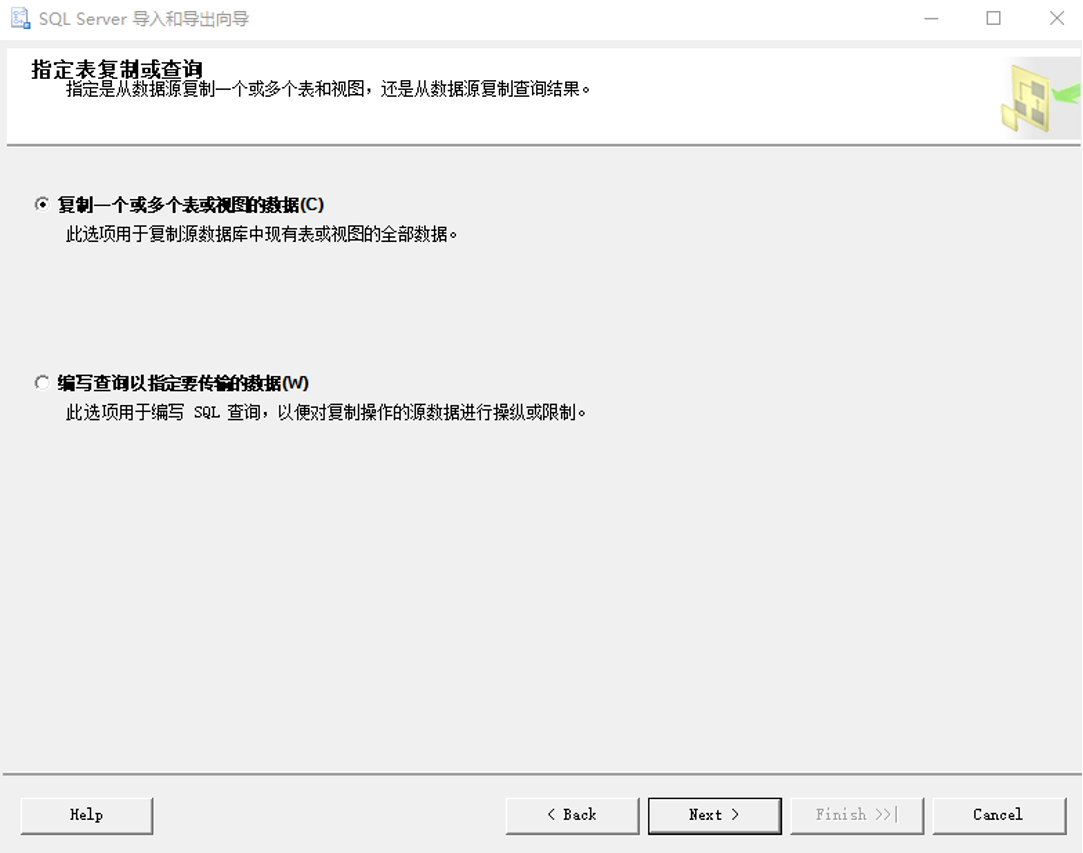
(4)指定表复制或查询
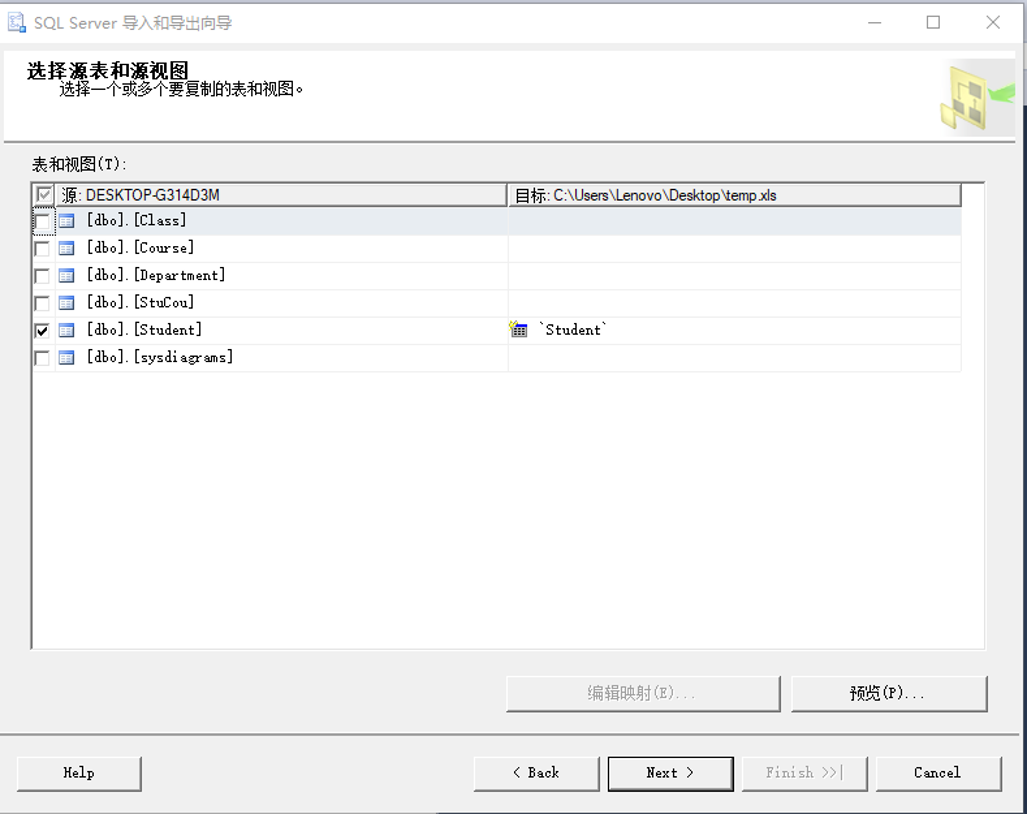
(5)选择源表和源视图
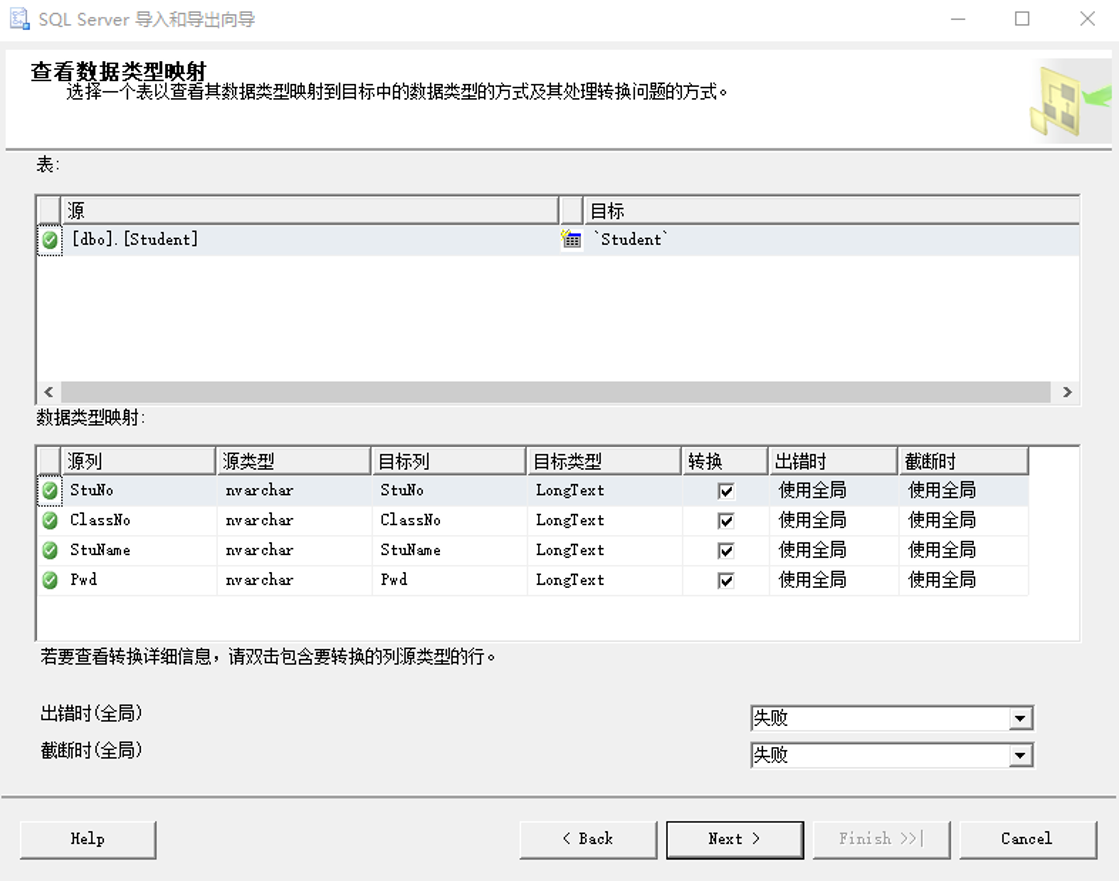
(6)查看数据类型映射
(7)保存并运行
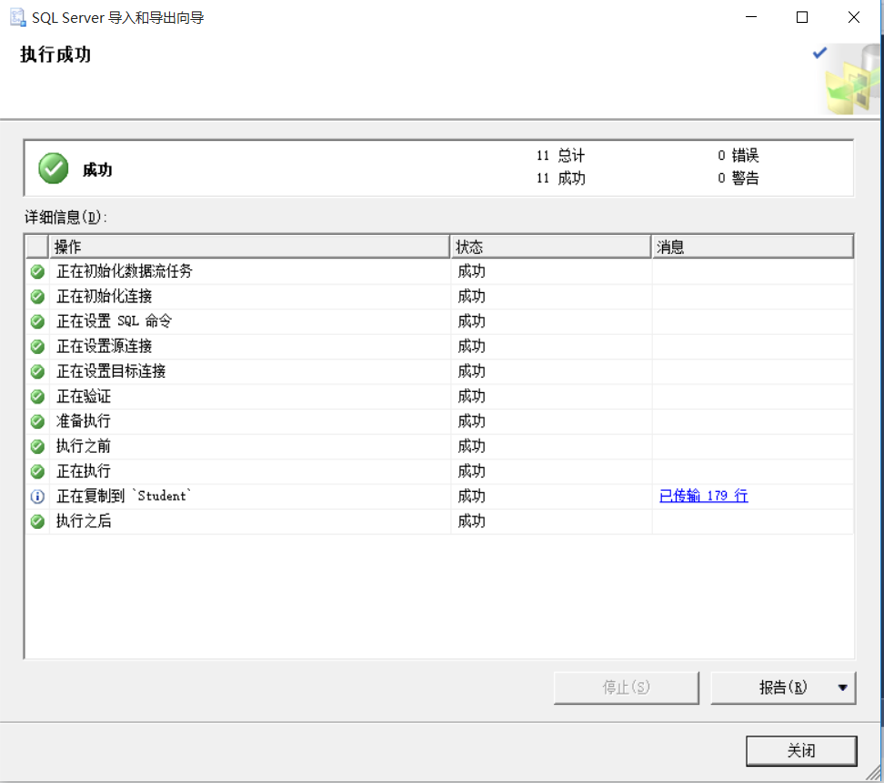
(8)执行成功
数据的导入
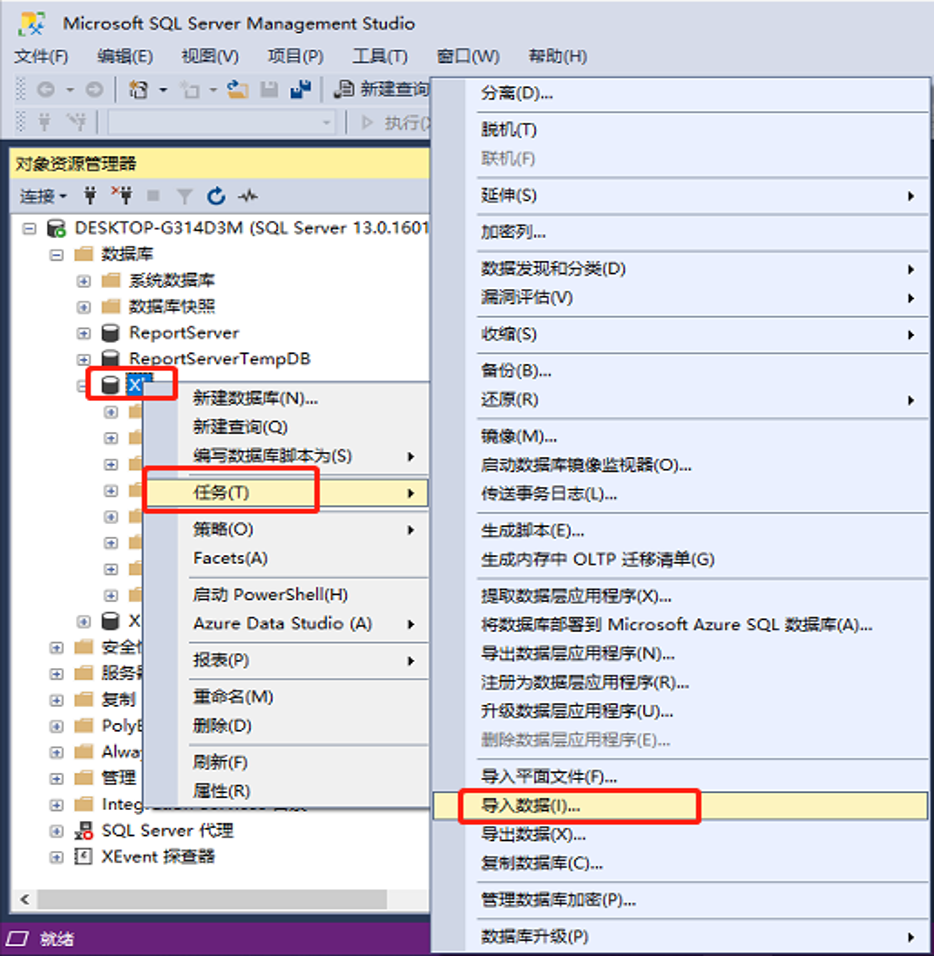
(1)任务-导入数据
注意:数据库表中的数据与导入的数据不能有重复的主键值,否则完成时会出现重复键的错误信息。
(2)选择数据源
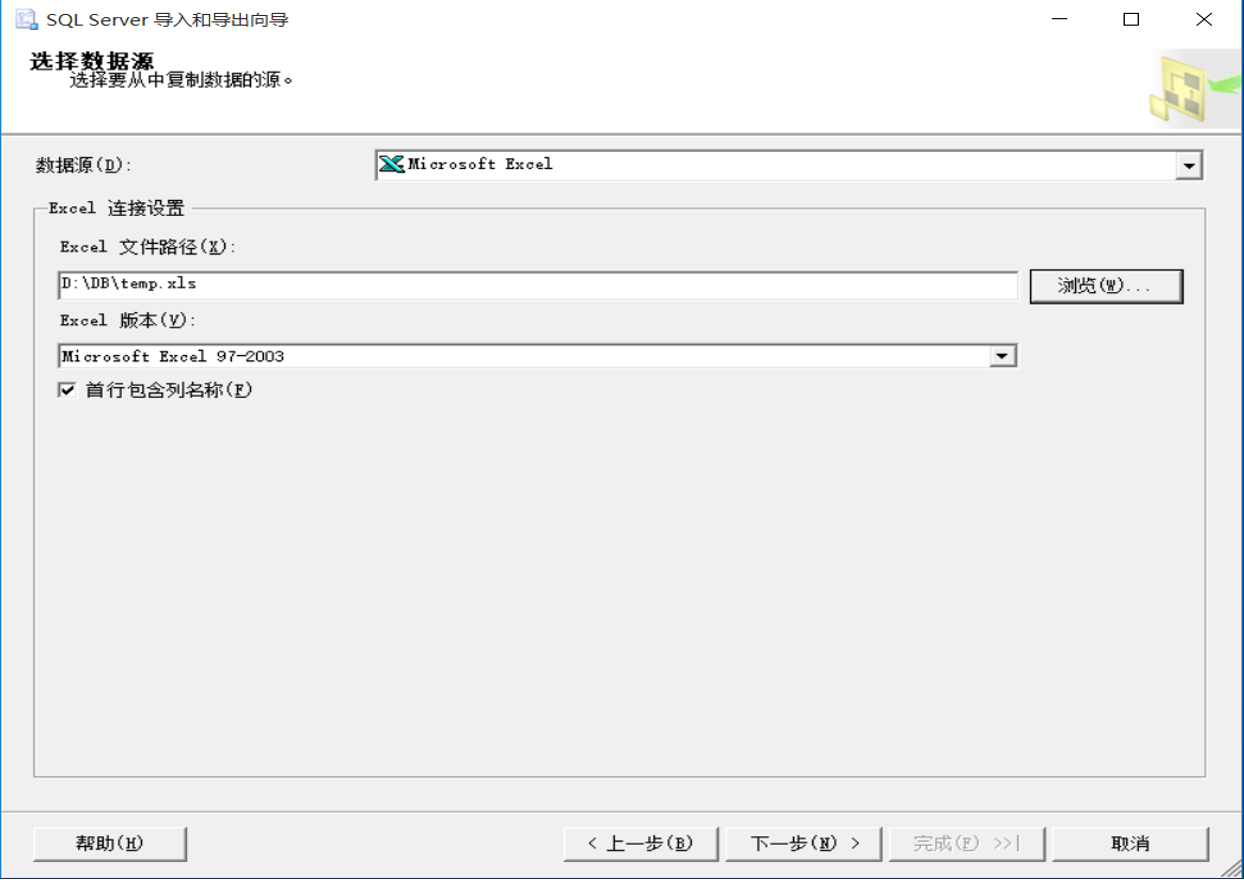
(3)选择目标
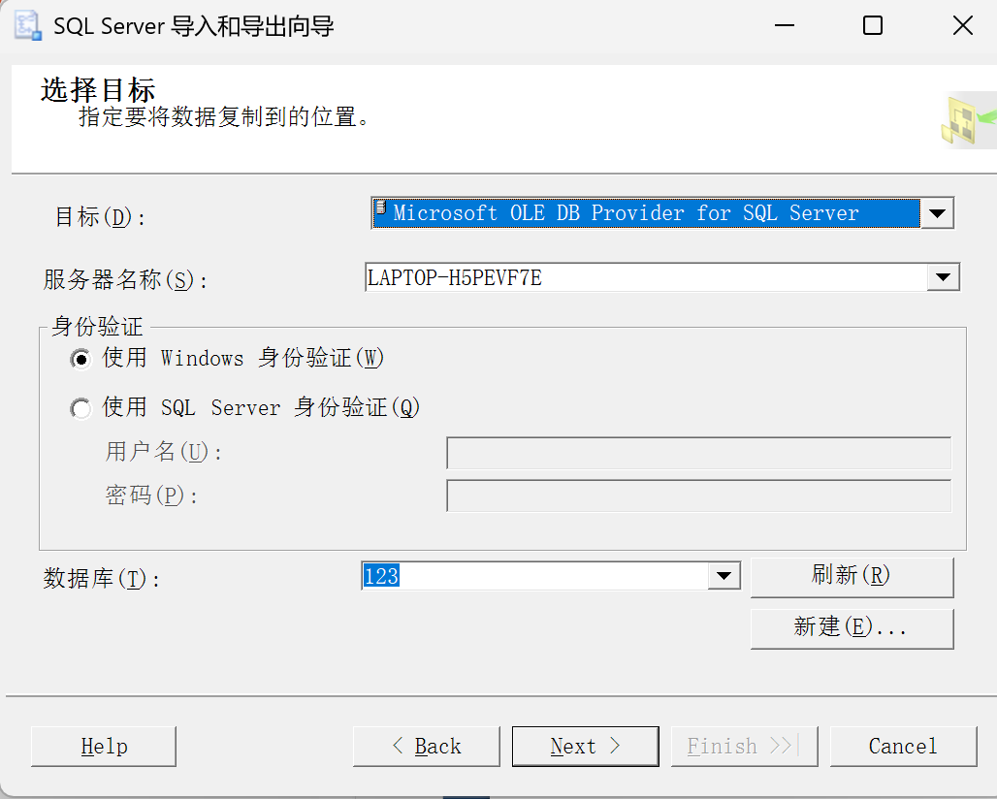
(4)指定表复制或查询
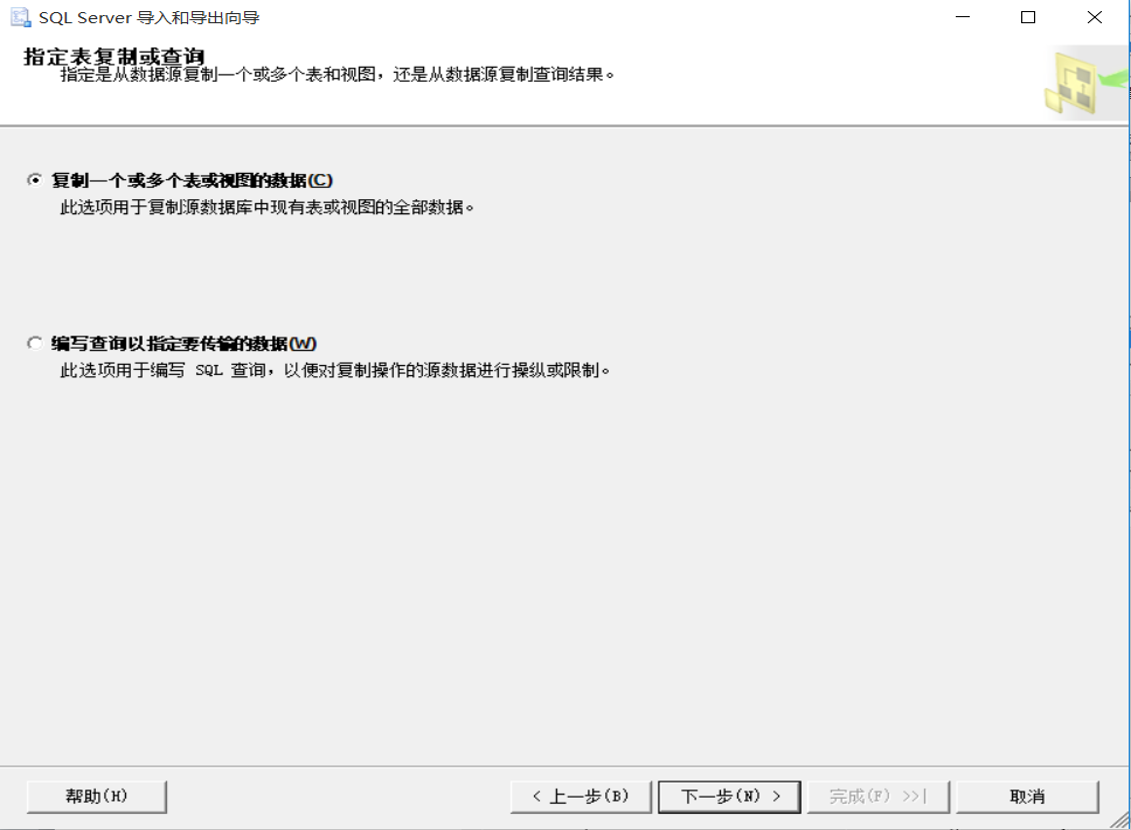
(5)选择源表和源视图
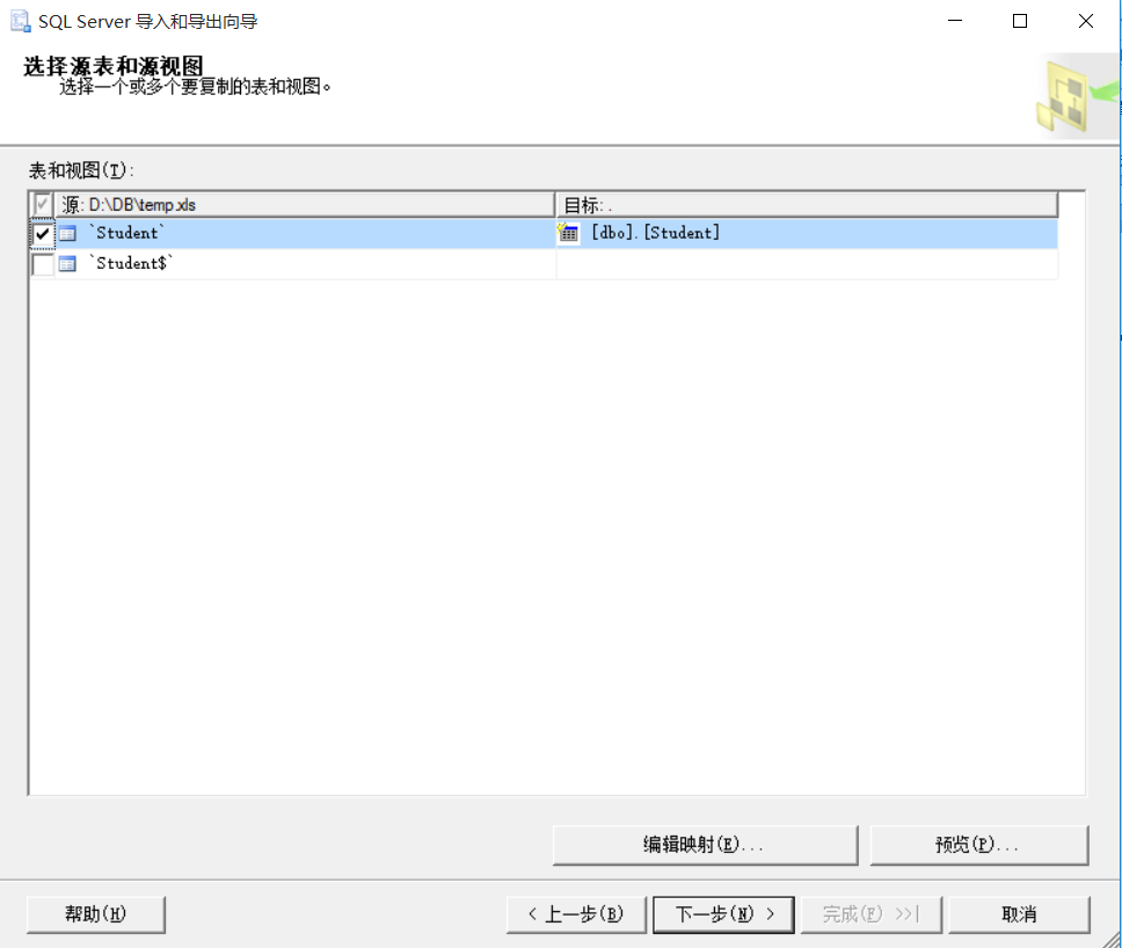
(6)保存并运行:立即运行
数据库备份与恢复
数据库备份概述
备份什么?
数据库需备份的内容可分为数据文件(又分为主要数据文件和次要数据文件)、日志文件两部分。
其中,数据文件中所存储的系统数据库是确保SQL Server 2016正常运行的重要依据,系统数据库必须被完全备份。谁可以做备份?
固定的服务器角色sysadmin(系统管理员)。
固定的数据库角色db_owner(数据库所有者)。
固定的数据库角色db_backupoperator(允许进行数据库备份的用户)。备份到哪里?
硬盘:是最常用的备份介质。硬盘可以用于备份本地文件,也可以用于备份网络文件。
磁带:是大容量的备份介质,磁带仅可备份本地文件。
备份时有哪些限制?SQL Server 2016在执行数据库备份的过程中,允许用户对数据库继续操作,但不允许用户在备份时执行下列操作:
创建或删除数据库文件;
创建索引;
不记日志的命令(BACKUP LOG WITH NO_LOG、WRITETEXT、UPDATETEXT、SELECT INTO、命令行实用程序、BCP命令)
什么时候备份?对于系统数据库和用户数据库,其备份时机是不同的。
系统数据库。当系统数据库master、msdb和model中的任何一个被修改以后,都要将其备份。
用户数据库。当创建数据库或加载数据库时,应备份数据库。当为数据库创建索引时,应备份数据库,以便恢复时大大节省时间。当清理了日志或执行了不记日志的T-SQL命令时,应备份数据库。
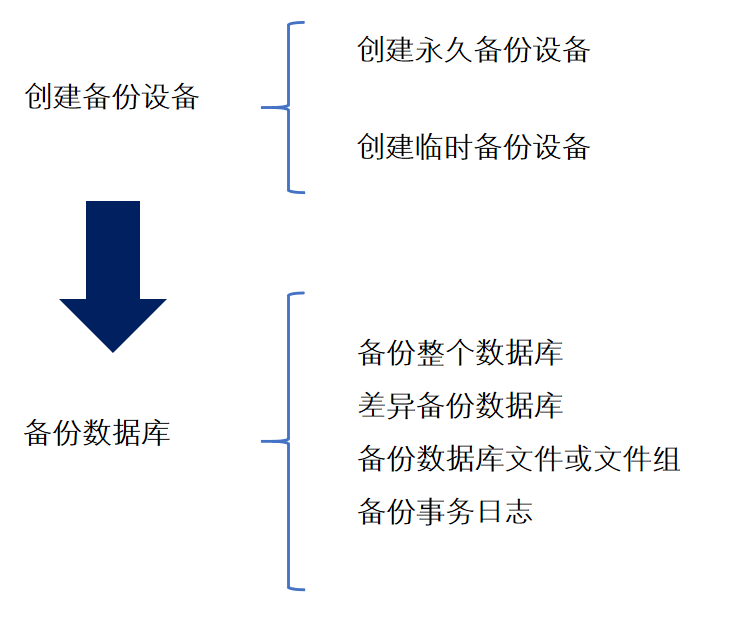
备份的类型
完全数据库备份:定期备份整个数据库,包括事务日志。主要优点是简单,备份是单一操作,可按一定的时间间隔预先设定
数据库和事务日志备份:不需很频繁地定期进行数据库备份,而是在两次完全数据库备份期间,进行事务日志备份
差异备份:差异备份只备份自上次数据库备份后发生更改的部分数据库,它用来扩充完全数据库备份或数据库和事务日志备份方法。
数据库文件或文件组备份:这种方法只备份特定的数据库文件或文件组,同时还要定期备份事务日志,这样在恢复时可以只还原已损坏的文件
恢复的准备工作
包括系统安全性检查和备份介质验证
备份文件或备份集名及描述信息
所使用的备份介质类型(磁带或磁盘等)
所使用的备份方法
执行备份的日期和时间
备份集的大小
数据库文件及日志文件的逻辑和物理文件名
备份文件的大小
恢复的模式
完整恢复:默认恢复模式。它会完整记录下操作数据的每一个步骤。使用该模式可以将整个数据库恢复到一个特定的时间点,这个时间点可以是最近一次可用的备份。
大容量日志恢复模式:是对完整恢复模式的补充。只记录必要的操作,不记录所有日志,节省日志文件的空间。由于日志记录不完整,一旦出现问题,数据将可能无法恢复。
简单恢复模式:数据库会自动删除不活动的日志。但因为没有事务日志备份,所以不能恢复到失败的时间点。适合数据安全不太高的数据库。该模式下,只能做完整和差异备份。
数据库备份操作
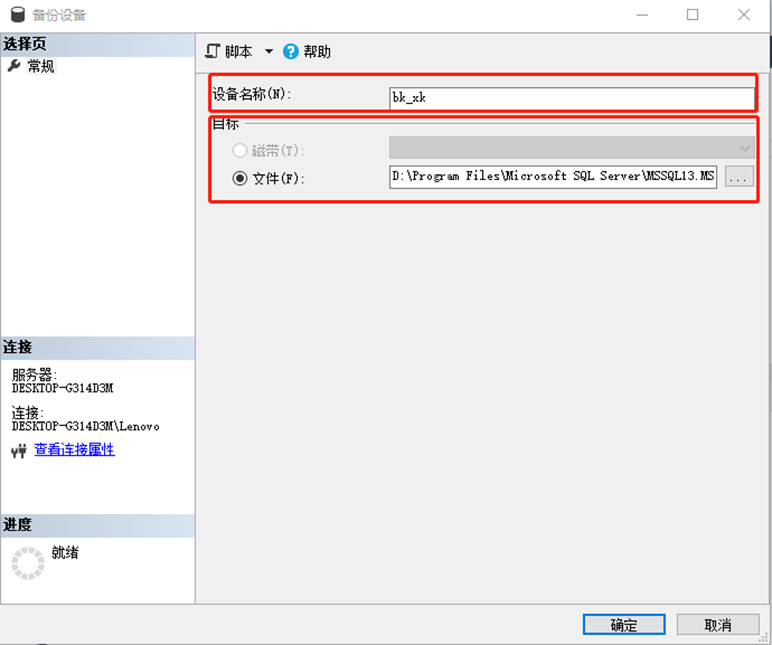
数据库备份操作—创建永久备份设备
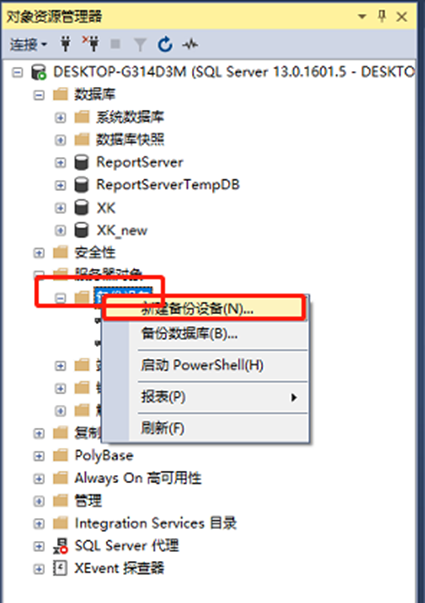
如果要使用备份设备的逻辑名来引用备份设备,就必须在使用它之前创建命名备份设备。当希望所创建的备份设备能够重新使用或设置系统自动备份数据库时,就要使用永久备份设备。
(1)使用系统存储过程sp_addumpdevice创建命名备份设备
EXEC sp_addumpdevice ’备份设备的类型名称’, ’备份设备的逻辑名称’, ’备份设备的物理名称’必须指定该命名备份设备的物理名和逻辑名,当在网络磁盘上创建命名备份设备时要说明网络磁盘文件路径名
SQL Server 2016将在系统数据库master的系统表sysdevices中创建该命名备份设备的物理名和逻辑名。
【例】使用逻辑名bk1在E盘中创建一个命名的备份设备 EXEC sp_addumpdevice ‘disk’, ‘bk1’, ‘E:\bk1.bak‘ --bk1为逻辑名(2)使用“对象资源管理器”创建永久备份设备
如果不准备重复使用备份设备,那么就可以使用临时备份设备。临时备份设备,顾名思义,
就是只作临时性存储之用,对这种设备只能使用物理名来引用。
BACKUP DATABASE 数据库名 TO { DISK | TAPE } = { 备份设备的物理路径 }SQL Server可以同时向多个备份设备写入数据,即进行并行的备份。并行备份将需备份的数据分别备份在多个设备上,这多个备份设备构成了备份集
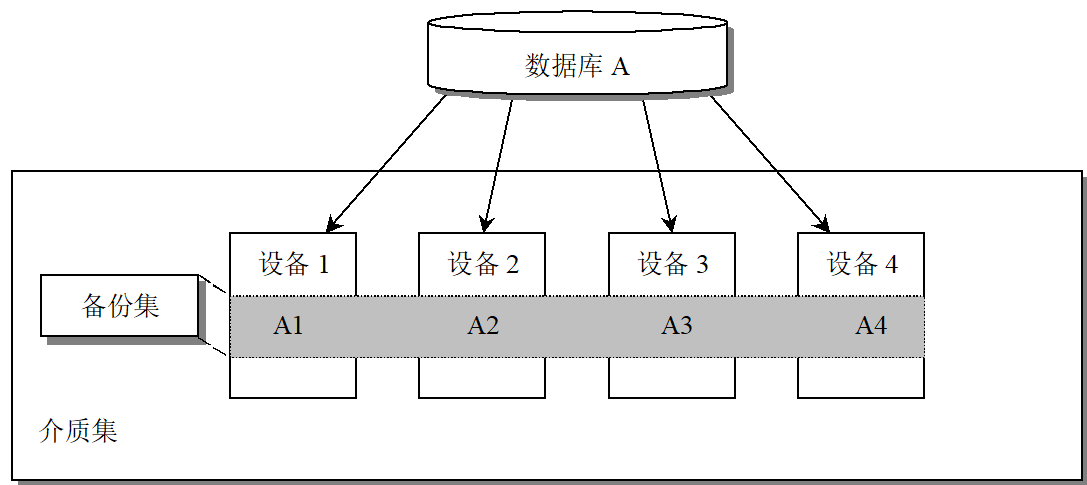
数据库备份操作—备份整个数据库
BACKUP DATABASE 数据库名 TO 备份设备【例】 使用逻辑名test1在E盘中创建一个命名的备份设备,并将数据库StuXK完全备份到该设备。
EXEC sp_addumpdevice 'disk' , 'test1', 'E:\test1.bak'
BACKUP DATABASE StuXK TO test1
数据库备份操作—差异备份数据库
BACKUP DATABASE 数据库名 TO 备份设备
With differential
【例】 创建临时备份设备E:\bk1,并在所创建的临时备份设备上进行差异备份。
BACKUP DATABASE StuXK TO
DISK ='E:\bk1.bak' WITH DIFFERENTIAL
数据库备份操作—备份数据库文件或文件组
BACKUP DATABASE 数据库名
FILE =文件 或 filegroup=文件组 TO 备份设备
【例】 设DT数据库有2个数据文件t1和t2,事务日志存储在文件tlog中。将文件t1备份到备份设备bkt1中,将事务日志文件备份到bklogt1中。
EXEC sp_addumpdevice 'disk', 'bkt1', 'E:\bkt1.bak'
EXEC sp_addumpdevice 'disk', 'bklogt1', 'E:\bklogt1.bak'
GO
BACKUP DATABASE DT FILE ='t1' TO bkt1
BACKUP LOG DT TO bklogt1
数据库备份操作—备份事务日志
BACKUP log 数据库名 TO 备份设备
(1)将事务日志中从前一次成功备份结束位置开始到当前事务日志的结尾处的内容进行备份
(2)标识事务日志中活动部分的开始,所谓事务日志的活动部分指从最近的检查点或最早的打开位置开始至事务日志的结尾处
【例】 创建一个命名的备份设备StuXKLOGBK,并备份StuXK数据库的事务日志。
EXEC sp_addumpdevice 'disk' , 'StuXKLOGBK' , 'E:\testlog.bak ‘
BACKUP LOG StuXK TO StuXKLOGBK
数据库恢复的准备
在进行数据库恢复之前,要校验有关备份集或备份介质的信息,其目的是确保数据库备份介质是有效的
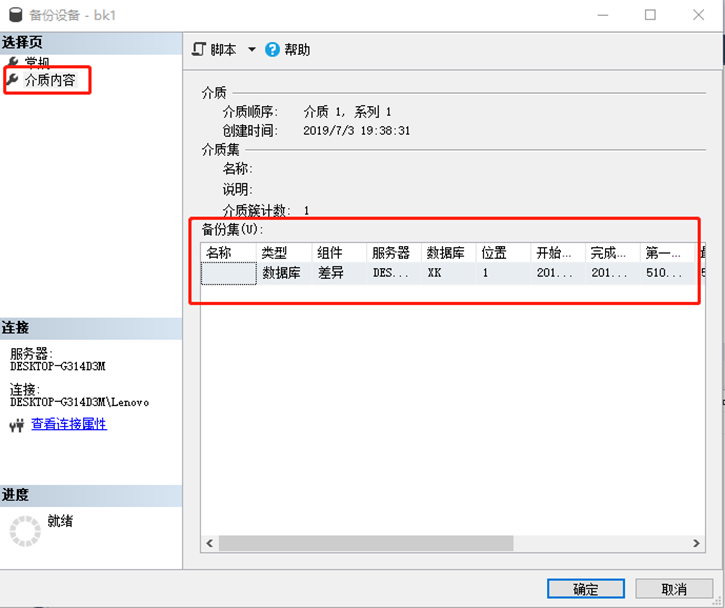
(1)使用管理平台查看备份介质的属性
(2)使用RESTORE HEADONLY、RESTORE FILELISTONLY、RESTORE LABEL ONLY等语句可以得到有关备份介质更详细的信息。
例如,RESTORE HEADERONLY语句的执行结果是在特定的备份设备上检索所有备份集的所有备份首部信息。
RESTORE HEADERONLY FROM 备份设备
恢复的模式—恢复整个数据库
恢复整个数据库时,SQL Server系统将重新创建数据库及与数据库相关的所有文件,并将文件存放在原来的位置。
RESTORE DATABASE 数据库名 FROM 备份设备
[ WITH
[ [ , ] FILE = { file_number | @file_number } ]
[ [ , ] { NORECOVERY | RECOVERY | STANDBY = undo_file_name } ]
[ [ , ] REPLACE ]
]
【例】 使用RESTORE语句从一个已存在的命名备份介质StuXKBK1(假设已经创建)中恢复整个数据库StuXK。
BACKUP DATABASE StuXK TO StuXKBK1 --先备份再恢复
RESTORE DATABASE StuXK
FROM StuXKBK1
WITH FILE=1, REPLACE
FILE是备份集1
恢复的模式—恢复数据库的部分内容
SQL Server提供了将数据库的部分内容还原到另一个位置的机制,以使损坏或丢失的数据可复制回原始数据库。
RESTORE 数据库名 FROM 备份设备
[ WITH PARTIAL
[ [ , ] { CHECKSUM | NO_CHECKSUM } ]
[ [ , ] { CONTINUE_AFTER_ERROR | STOP_ON_ERROR } ]
[ [ , ] FILE = { file_number | @file_number } ]
[ [ , ] MEDIANAME = { media_name | @media_name_variable } ]
恢复的模式—恢复特定的文件或文件组
若某个或某些文件被破坏或被误删除,可以从文件或文件组备份中进行恢复,
而不必进行整个数据库的恢复
RESTORE 数据库名 file=文件 或 filegroup=文件组 FROM 备份设备
恢复的模式—恢复事务日志
使用事务日志恢复,可将数据库恢复到指定的时间点;
注意:执行事务日志恢复必须在进行完全数据库恢复以后
RESTORE log 数据库名 FROM 备份设备
通过管理平台备份和还原
--【练1】将StuXK数据库进行备份。
--右击—StuXK—任务—备份。
--【练2】将备份的StuXK数据库进行还原。
--右击数据库—任务—还原。保证此数据库系统中不存在同名数据库。
数据库设计概述
1.系统需求分析:需求收集和分析,得到数据字典和数据流图
2.概念结构设计:对用户需求综合、归纳与抽象,形成概念模型,用E-R图表示
3.逻辑结构设计:将概念结构转换为某个DBMS所支持的数据模型
4.物理结构设计:为逻辑数据模型选取一个最适合应用环境的物理结构
5.数据库实施:建立数据库,编制与调试应用程序,组织数据入库,程序试运行对数据
6.数据库运行与维护:对数据库系统进行评价、调整与修改

















 2910
2910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









